Algoritme klasifikasi teks adalah inti dari berbagai sistem software yang memproses data teks dalam skala besar. Software email menggunakan klasifikasi teks untuk menentukan apakah email masuk dikirim ke kotak masuk atau difilter ke folder spam. Forum diskusi menggunakan klasifikasi teks untuk menentukan apakah komentar harus ditandai sebagai tidak pantas.
Ini adalah dua contoh klasifikasi topik, mengategorikan dokumen teks ke dalam salah satu rangkaian topik yang telah ditentukan. Dalam banyak masalah klasifikasi topik, kategorisasi ini terutama didasarkan pada kata kunci dalam teks.
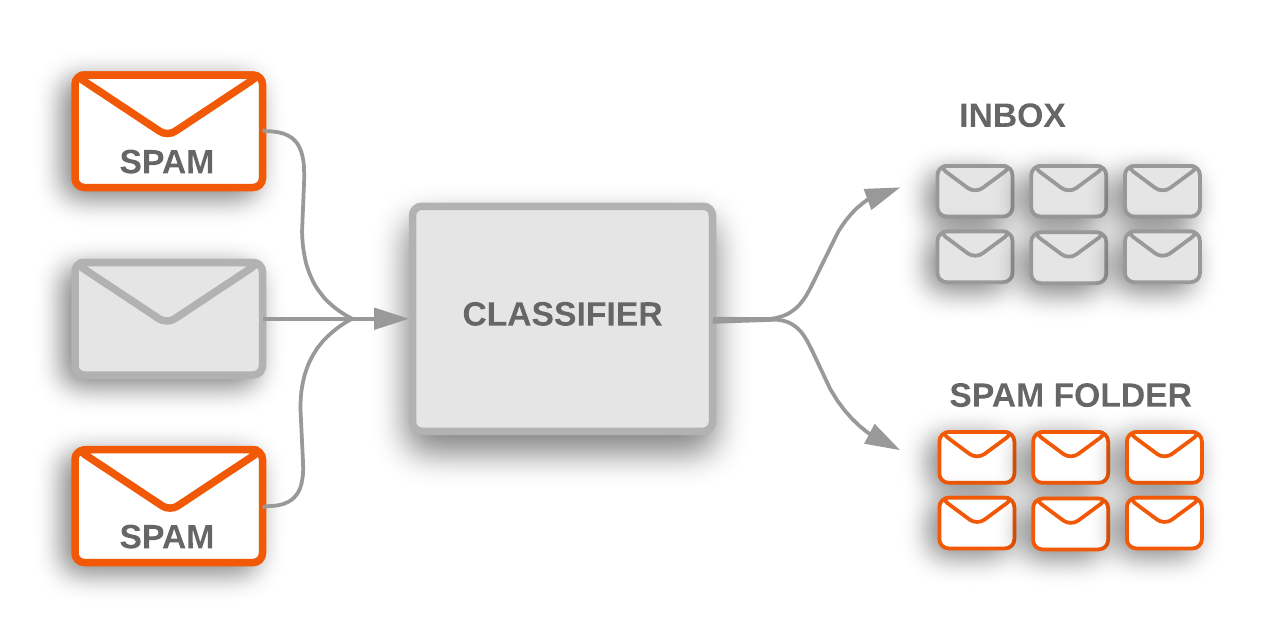
Gambar 1: Klasifikasi topik digunakan untuk menandai email spam masuk yang difilter ke folder spam.
Jenis klasifikasi teks yang umum lainnya adalah analisis minat, yang tujuannya untuk mengidentifikasi polaritas konten teks: jenis opini yang dinyatakan. Ini dapat berupa biner seperti rating suka/tidak suka, atau kumpulan opsi yang lebih terperinci, seperti rating bintang dari 1 sampai 5. Contoh analisis analisis meliputi analisis postingan Twitter untuk menentukan apakah orang-orang menyukai film Black Panther atau tidak, atau dengan mengekstrapolasi opini publik tentang merek sepatu Nike baru dari ulasan Walmart.
Panduan ini akan mengajari Anda beberapa praktik terbaik machine learning utama untuk menyelesaikan masalah klasifikasi teks. Berikut hal yang akan Anda pelajari:
- Alur kerja tingkat tinggi dan menyeluruh untuk menyelesaikan masalah klasifikasi teks menggunakan machine learning
- Cara memilih model yang tepat untuk masalah klasifikasi teks Anda
- Cara menerapkan model pilihan Anda menggunakan TensorFlow
Alur Kerja Klasifikasi Teks
Berikut adalah ringkasan tingkat tinggi tentang alur kerja yang digunakan untuk menyelesaikan masalah machine learning:
- Langkah 1: Kumpulkan Data
- Langkah 2: Pelajari Data Anda
- Langkah 2.5: Pilih Model*
- Langkah 3: Siapkan Data Anda
- Langkah 4: Build, Latih, dan Evaluasi Model Anda
- Langkah 5: Sesuaikan Hyperparameter
- Langkah 6: Deploy Model Anda

Gambar 2: Alur kerja untuk menyelesaikan masalah machine learning
Bagian berikut menjelaskan setiap langkah secara mendetail dan cara menerapkannya untuk data teks.