Untuk tujuan dokumen ini:
Tujuan utama pengembangan machine learning adalah untuk memaksimalkan kegunaan model yang di-deploy.
Anda biasanya dapat menggunakan langkah dan prinsip dasar yang sama di bagian ini untuk masalah ML apa pun.
Bagian ini membuat asumsi berikut:
- Anda sudah memiliki pipeline pelatihan yang berjalan sepenuhnya beserta konfigurasi yang memberikan hasil yang wajar.
- Anda memiliki resource komputasi yang cukup untuk melakukan eksperimen penyesuaian yang bermakna dan menjalankan setidaknya beberapa tugas pelatihan secara paralel.
Strategi penyesuaian inkremental
Rekomendasi: Mulai dengan konfigurasi sederhana. Kemudian, lakukan perbaikan secara bertahap sambil membangun pemahaman tentang masalah tersebut. Pastikan bahwa setiap peningkatan didasarkan pada bukti yang kuat.
Kami mengasumsikan bahwa sasaran Anda adalah menemukan konfigurasi yang memaksimalkan performa model Anda. Terkadang, tujuan Anda adalah memaksimalkan peningkatan model dengan batas waktu tetap. Dalam kasus lain, Anda dapat terus meningkatkan kualitas model tanpa batas; misalnya, terus meningkatkan kualitas model yang digunakan dalam produksi.
Pada prinsipnya, Anda dapat memaksimalkan performa dengan menggunakan algoritma untuk menelusuri seluruh ruang konfigurasi yang mungkin secara otomatis, tetapi ini bukan opsi yang praktis. Ruang konfigurasi yang mungkin sangat besar dan belum ada algoritma yang cukup canggih untuk menelusuri ruang ini secara efisien tanpa panduan manusia. Sebagian besar algoritma penelusuran otomatis mengandalkan ruang penelusuran yang dirancang secara manual yang menentukan kumpulan konfigurasi yang akan ditelusuri, dan ruang penelusuran ini dapat sangat penting.
Cara paling efektif untuk memaksimalkan performa adalah dengan memulai konfigurasi sederhana dan menambahkan fitur serta melakukan peningkatan secara bertahap sambil membangun insight tentang masalah tersebut.
Sebaiknya gunakan algoritma penelusuran otomatis di setiap putaran penyesuaian dan perbarui ruang penelusuran secara berkelanjutan seiring dengan bertambahnya pemahaman Anda. Saat menjelajah, Anda akan menemukan konfigurasi yang lebih baik dan lebih baik lagi secara alami, sehingga model "terbaik" Anda akan terus meningkat.
Istilah "peluncuran" mengacu pada update pada konfigurasi terbaik kami (yang mungkin atau mungkin tidak sesuai dengan peluncuran model produksi yang sebenarnya). Untuk setiap "peluncuran", Anda harus memastikan bahwa perubahan didasarkan pada bukti yang kuat—bukan hanya peluang acak berdasarkan konfigurasi yang beruntung—sehingga Anda tidak menambahkan kompleksitas yang tidak perlu ke pipeline pelatihan.
Pada level tinggi, strategi penyesuaian inkremental kami melibatkan pengulangan empat langkah berikut:
- Pilih sasaran untuk putaran eksperimen berikutnya. Pastikan cakupan sasaran sudah sesuai.
- Merancang putaran eksperimen berikutnya. Merancang dan menjalankan serangkaian eksperimen yang mengarah pada sasaran ini.
- Belajar dari hasil eksperimen. Mengevaluasi eksperimen berdasarkan checklist.
- Tentukan apakah akan menerapkan perubahan kandidat.
Bagian selanjutnya dalam bagian ini menjelaskan strategi ini secara mendetail.
Pilih sasaran untuk putaran eksperimen berikutnya
Jika Anda mencoba menambahkan beberapa fitur atau menjawab beberapa pertanyaan sekaligus, Anda mungkin tidak dapat memisahkan efek yang berbeda pada hasil. Contoh sasaran mencakup:
- Coba potensi peningkatan pada pipeline (misalnya, regularizer baru, pilihan praproses, dll.).
- Memahami dampak hyperparameter model tertentu (misalnya, fungsi aktivasi)
- Meminimalkan error validasi.
Prioritaskan progres jangka panjang daripada peningkatan kesalahan validasi jangka pendek
Ringkasan: Sebagian besar waktu, sasaran utama Anda adalah mendapatkan insight tentang masalah penyesuaian.
Sebaiknya habiskan sebagian besar waktu Anda untuk mendapatkan insight tentang masalah dan hanya sedikit waktu untuk fokus secara berlebihan dalam memaksimalkan performa pada set validasi. Dengan kata lain, habiskan sebagian besar waktu Anda untuk "eksplorasi" dan hanya sebagian kecil untuk "eksploitasi". Memahami masalah sangat penting untuk memaksimalkan performa akhir. Memprioritaskan insight daripada keuntungan jangka pendek akan membantu:
- Hindari meluncurkan perubahan yang tidak perlu yang terjadi dalam proses yang berperforma baik hanya karena kebetulan historis.
- Identifikasi hyperparameter yang paling sensitif terhadap error validasi, hyperparameter yang paling banyak berinteraksi dan oleh karena itu perlu disesuaikan ulang bersama-sama, dan hyperparameter yang relatif tidak sensitif terhadap perubahan lain sehingga dapat diperbaiki dalam eksperimen mendatang.
- Sarankan fitur baru potensial untuk dicoba, seperti regularizer baru jika overfitting menjadi masalah.
- Mengidentifikasi fitur yang tidak membantu dan oleh karena itu dapat dihapus, sehingga mengurangi kompleksitas eksperimen pada masa mendatang.
- Mengenali kapan peningkatan dari penyesuaian hyperparameter kemungkinan telah mencapai titik jenuh.
- Persempit ruang penelusuran di sekitar nilai optimal untuk meningkatkan efisiensi penyesuaian.
Pada akhirnya, Anda akan memahami masalahnya. Kemudian, Anda dapat berfokus sepenuhnya pada kesalahan validasi meskipun eksperimen tidak memberikan informasi maksimal tentang struktur masalah penyesuaian.
Mendesain putaran eksperimen berikutnya
Ringkasan: Identifikasi hyperparameter ilmiah, pengganggu, dan tetap untuk tujuan eksperimental. Buat urutan studi untuk membandingkan berbagai nilai hyperparameter ilmiah sambil mengoptimalkan hyperparameter pengganggu. Pilih ruang penelusuran hyperparameter pengganggu untuk menyeimbangkan biaya resource dengan nilai ilmiah.
Mengidentifikasi hyperparameter ilmiah, pengganggu, dan tetap
Untuk tujuan tertentu, semua hyperparameter termasuk dalam salah satu kategori berikut:
- Hyperparameter ilmiah adalah hyperparameter yang efeknya pada performa model ingin Anda ukur.
- Hyperparameter pengganggu adalah hyperparameter yang perlu dioptimalkan agar dapat membandingkan berbagai nilai hyperparameter ilmiah secara adil. Hyperparameter pengganggu mirip dengan parameter pengganggu dalam statistik.
- Hyperparameter tetap memiliki nilai konstan dalam putaran eksperimen saat ini. Nilai hyperparameter tetap tidak boleh berubah saat Anda membandingkan nilai hyperparameter ilmiah yang berbeda. Dengan memperbaiki hyperparameter tertentu untuk serangkaian eksperimen, Anda harus menerima bahwa kesimpulan yang diambil dari eksperimen mungkin tidak valid untuk setelan hyperparameter tetap lainnya. Dengan kata lain, hyperparameter tetap menciptakan peringatan untuk setiap kesimpulan yang Anda tarik dari eksperimen.
Misalnya, anggaplah tujuan Anda adalah sebagai berikut:
Menentukan apakah model dengan lebih banyak lapisan tersembunyi memiliki error validasi yang lebih rendah.
Dalam hal ini:
- Kecepatan pembelajaran adalah hyperparameter yang mengganggu karena Anda hanya dapat membandingkan model dengan jumlah lapisan tersembunyi yang berbeda secara adil jika kecepatan pembelajaran disesuaikan secara terpisah untuk setiap jumlah lapisan tersembunyi. (Tingkat pembelajaran yang optimal umumnya bergantung pada arsitektur model).
- Fungsi aktivasi dapat berupa hyperparameter tetap jika Anda telah menentukan dalam eksperimen sebelumnya bahwa fungsi aktivasi terbaik tidak sensitif terhadap kedalaman model. Atau, Anda bersedia membatasi kesimpulan tentang jumlah lapisan tersembunyi untuk mencakup fungsi aktivasi ini. Atau, ini bisa menjadi hyperparameter pengganggu jika Anda siap menyesuaikannya secara terpisah untuk setiap jumlah lapisan tersembunyi.
Hyperparameter tertentu dapat berupa hyperparameter ilmiah, hyperparameter pengganggu, atau hyperparameter tetap; penunjukan hyperparameter berubah bergantung pada tujuan eksperimental. Misalnya, fungsi aktivasi dapat berupa salah satu dari berikut ini:
- Hyperparameter ilmiah: Apakah ReLU atau tanh merupakan pilihan yang lebih baik untuk masalah kita?
- Hyperparameter pengganggu: Apakah model lima lapisan terbaik lebih baik daripada model enam lapisan terbaik jika Anda mengizinkan beberapa kemungkinan fungsi aktivasi yang berbeda?
- Hyperparameter tetap: Untuk jaringan ReLU, apakah penambahan normalisasi batch di posisi tertentu membantu?
Saat mendesain putaran eksperimen baru:
- Identifikasi hyperparameter ilmiah untuk sasaran eksperimental. (Pada tahap ini, Anda dapat menganggap semua hyperparameter lainnya sebagai hyperparameter pengganggu.)
- Mengonversi beberapa hyperparameter pengganggu menjadi hyperparameter tetap.
Dengan sumber daya yang tidak terbatas, Anda akan membiarkan semua hyperparameter non-ilmiah sebagai hyperparameter pengganggu sehingga kesimpulan yang Anda tarik dari eksperimen Anda bebas dari peringatan tentang nilai hyperparameter tetap. Namun, semakin banyak hyperparameter pengganggu yang Anda coba sesuaikan, semakin besar risiko Anda gagal menyesuaikannya dengan cukup baik untuk setiap setelan hyperparameter ilmiah dan akhirnya mencapai kesimpulan yang salah dari eksperimen Anda. Seperti yang dijelaskan di bagian selanjutnya, Anda dapat mengatasi risiko ini dengan meningkatkan anggaran komputasi. Namun, anggaran resource maksimum Anda sering kali lebih rendah daripada yang diperlukan untuk menyesuaikan semua hyperparameter non-ilmiah.
Sebaiknya konversi hyperparameter pengganggu menjadi hyperparameter tetap jika peringatan yang muncul akibat penetapannya lebih ringan daripada biaya menyertakannya sebagai hyperparameter pengganggu. Makin banyak hyperparameter pengganggu berinteraksi dengan hyperparameter ilmiah, makin merusak perbaikan nilainya. Misalnya, nilai terbaik dari kekuatan peluruhan bobot biasanya bergantung pada ukuran model, sehingga membandingkan ukuran model yang berbeda dengan asumsi satu nilai spesifik peluruhan bobot tidak akan terlalu bermanfaat.
Beberapa parameter pengoptimal
Sebagai aturan praktis, beberapa hyperparameter pengoptimal (misalnya, kecepatan pembelajaran, momentum, parameter jadwal kecepatan pembelajaran, beta Adam, dll.) adalah hyperparameter pengganggu karena cenderung berinteraksi paling banyak dengan perubahan lain. Hyperparameter pengoptimal ini jarang menjadi hyperparameter ilmiah karena sasaran seperti "berapa kecepatan pembelajaran terbaik untuk pipeline saat ini?" tidak memberikan banyak insight. Bagaimanapun, setelan terbaik dapat berubah dengan perubahan pipeline berikutnya.
Anda mungkin memperbaiki beberapa hyperparameter pengoptimal sesekali karena batasan resource atau bukti yang sangat kuat bahwa hyperparameter tersebut tidak berinteraksi dengan parameter ilmiah. Namun, secara umum Anda harus mengasumsikan bahwa Anda harus menyesuaikan hyperparameter pengoptimal secara terpisah untuk membuat perbandingan yang adil antara setelan hyperparameter ilmiah yang berbeda, dan oleh karena itu tidak boleh ditetapkan. Selain itu, tidak ada alasan apriori untuk memilih satu nilai hyperparameter pengoptimal daripada yang lain; misalnya, nilai hyperparameter pengoptimal biasanya tidak memengaruhi biaya komputasi penerusan atau gradien dengan cara apa pun.
Pilihan pengoptimal
Pilihan pengoptimal biasanya adalah:
- hyperparameter ilmiah
- hyperparameter tetap
Pengoptimal adalah hyperparameter ilmiah jika tujuan eksperimental Anda melibatkan perbandingan yang adil antara dua atau lebih pengoptimal yang berbeda. Contoh:
Tentukan pengoptimal mana yang menghasilkan error validasi terendah dalam jumlah langkah tertentu.
Atau, Anda dapat menjadikan pengoptimal sebagai hyperparameter tetap karena berbagai alasan, termasuk:
- Eksperimen sebelumnya menunjukkan bahwa pengoptimal terbaik untuk masalah penyesuaian Anda tidak sensitif terhadap hyperparameter ilmiah saat ini.
- Anda lebih suka membandingkan nilai hyperparameter ilmiah menggunakan pengoptimal ini karena kurva pelatihannya lebih mudah dipahami.
- Anda lebih suka menggunakan pengoptimal ini karena menggunakan lebih sedikit memori daripada alternatif lainnya.
Hyperparameter regularisasi
Hyperparameter yang diperkenalkan oleh teknik regularisasi biasanya merupakan hyperparameter pengganggu. Namun, pilihan apakah akan menyertakan teknik regularisasi atau tidak sama sekali adalah hyperparameter ilmiah atau tetap.
Misalnya, regularisasi dropout menambahkan kompleksitas kode. Oleh karena itu, saat memutuskan apakah akan menyertakan regularisasi dropout, Anda dapat menjadikan "tanpa dropout" vs "dropout" sebagai hyperparameter ilmiah, tetapi tingkat dropout sebagai hyperparameter pengganggu. Jika Anda memutuskan untuk menambahkan regularisasi dropout ke pipeline berdasarkan eksperimen ini, maka rasio dropout akan menjadi hiperparameter pengganggu dalam eksperimen mendatang.
Hyperparameter arsitektur
Hyperparameter arsitektur sering kali berupa hyperparameter ilmiah atau tetap karena perubahan arsitektur dapat memengaruhi biaya penayangan dan pelatihan, latensi, dan persyaratan memori. Misalnya, jumlah lapisan biasanya merupakan hyperparameter ilmiah atau tetap karena cenderung memiliki konsekuensi dramatis terhadap kecepatan pelatihan dan penggunaan memori.
Dependensi pada hyperparameter ilmiah
Dalam beberapa kasus, set hyperparameter pengganggu dan tetap bergantung pada nilai hyperparameter ilmiah. Misalnya, Anda mencoba menentukan pengoptimal mana dalam momentum Nesterov dan Adam yang menghasilkan kesalahan validasi terendah. Dalam hal ini:
- Hyperparameter ilmiah adalah pengoptimal, yang menggunakan nilai
{"Nesterov_momentum", "Adam"} - Nilai
optimizer="Nesterov_momentum"memperkenalkan hyperparameter{learning_rate, momentum}, yang mungkin merupakan hyperparameter pengganggu atau tetap. - Nilai
optimizer="Adam"memperkenalkan hyperparameter{learning_rate, beta1, beta2, epsilon}, yang mungkin berupa hyperparameter pengganggu atau tetap.
Hyperparameter yang hanya ada untuk nilai tertentu dari hyperparameter ilmiah disebut hyperparameter bersyarat.
Jangan menganggap dua hyperparameter bersyarat sama hanya karena
memiliki nama yang sama. Dalam contoh sebelumnya, hyperparameter bersyarat
yang disebut learning_rate adalah hyperparameter yang berbeda untuk
optimizer="Nesterov_momentum" daripada untuk optimizer="Adam". Perannya serupa
(meskipun tidak identik) dalam kedua algoritma, tetapi rentang nilai yang
berfungsi baik di setiap pengoptimal biasanya berbeda beberapa kali lipat.
Membuat serangkaian studi
Setelah mengidentifikasi hyperparameter ilmiah dan pengganggu, Anda harus mendesain studi atau urutan studi untuk mencapai tujuan eksperimental. Studi menentukan sekumpulan konfigurasi hyperparameter yang akan dijalankan untuk analisis berikutnya. Setiap konfigurasi disebut uji coba. Membuat studi biasanya melibatkan pemilihan hal berikut:
- Hyperparameter yang bervariasi di seluruh uji coba.
- Nilai yang dapat diambil oleh hyperparameter tersebut (ruang penelusuran).
- Jumlah uji coba.
- Algoritma penelusuran otomatis untuk mengambil sampel sebanyak itu dari ruang penelusuran.
Atau, Anda dapat membuat studi dengan menentukan set konfigurasi hyperparameter secara manual.
Tujuan studi ini adalah untuk secara bersamaan:
- Jalankan pipeline dengan nilai hyperparameter ilmiah yang berbeda.
- "Mengoptimalkan" (atau "mengoptimalkan") hyperparameter pengganggu sehingga perbandingan antara nilai hyperparameter ilmiah yang berbeda seadil mungkin.
Dalam kasus yang paling sederhana, Anda akan membuat studi terpisah untuk setiap konfigurasi parameter ilmiah, dengan setiap studi menyesuaikan hyperparameter pengganggu. Misalnya, jika sasaran Anda adalah memilih pengoptimal terbaik dari momentum Nesterov dan Adam, Anda dapat membuat dua studi:
- Satu studi yang
optimizer="Nesterov_momentum"dan hyperparameter pengganggu adalah{learning_rate, momentum} - Studi lain yang
optimizer="Adam"dan hyperparameter pengganggu adalah{learning_rate, beta1, beta2, epsilon}.
Anda akan membandingkan kedua pengoptimal dengan memilih uji coba berperforma terbaik dari setiap studi.
Anda dapat menggunakan algoritma pengoptimalan bebas gradien apa pun, termasuk metode seperti pengoptimalan Bayesian atau algoritma evolusioner, untuk mengoptimalkan hyperparameter pengganggu. Namun, kami lebih memilih menggunakan penelusuran kuasi-acak dalam fase penyesuaian eksplorasi karena berbagai keunggulan yang dimilikinya dalam setelan ini. Setelah eksplorasi selesai, sebaiknya gunakan software pengoptimalan Bayesian canggih (jika tersedia).
Pertimbangkan kasus yang lebih rumit saat Anda ingin membandingkan sejumlah besar nilai hyperparameter ilmiah, tetapi tidak praktis untuk melakukan banyak studi independen. Dalam hal ini, Anda dapat melakukan hal berikut:
- Sertakan parameter ilmiah dalam ruang penelusuran yang sama dengan hyperparameter pengganggu.
- Gunakan algoritma penelusuran untuk mengambil sampel nilai hyperparameter ilmiah dan pengganggu dalam satu studi.
Saat menggunakan pendekatan ini, hyperparameter bersyarat dapat menyebabkan masalah. Bagaimanapun, sulit untuk menentukan ruang penelusuran kecuali jika kumpulan hyperparameter pengganggu sama untuk semua nilai hyperparameter ilmiah. Dalam hal ini, preferensi kami untuk menggunakan penelusuran kuasi-acak daripada alat pengoptimalan kotak hitam yang lebih canggih menjadi lebih kuat, karena menjamin nilai hiperparameter ilmiah yang berbeda akan diambil sampelnya secara seragam. Terlepas dari algoritma penelusuran, pastikan algoritma tersebut menelusuri parameter ilmiah secara seragam.
Menemukan keseimbangan antara eksperimen yang informatif dan terjangkau
Saat mendesain studi atau rangkaian studi, alokasikan anggaran terbatas untuk mencapai tiga tujuan berikut secara memadai:
- Membandingkan nilai hiperparameter ilmiah yang cukup berbeda.
- Menyesuaikan hyperparameter pengganggu di ruang penelusuran yang cukup besar.
- Mensampel ruang penelusuran hyperparameter pengganggu secara cukup padat.
Semakin baik Anda mencapai ketiga sasaran ini, semakin banyak insight yang dapat Anda peroleh dari eksperimen. Membandingkan sebanyak mungkin nilai hyperparameter ilmiah akan memperluas cakupan insight yang Anda peroleh dari eksperimen.
Mencakup sebanyak mungkin hyperparameter pengganggu dan memungkinkan setiap hyperparameter pengganggu bervariasi dalam rentang seluas mungkin akan meningkatkan keyakinan bahwa nilai "baik" dari hyperparameter pengganggu ada di ruang penelusuran untuk setiap konfigurasi hyperparameter ilmiah. Jika tidak, Anda mungkin membuat perbandingan yang tidak adil antara nilai hyperparameter ilmiah dengan tidak menelusuri kemungkinan wilayah ruang hyperparameter pengganggu tempat nilai yang lebih baik mungkin berada untuk beberapa nilai parameter ilmiah.
Ambil sampel ruang penelusuran hyperparameter pengganggu sepadat mungkin. Dengan melakukannya, Anda akan lebih yakin bahwa prosedur penelusuran akan menemukan setelan yang baik untuk hyperparameter pengganggu yang ada di ruang penelusuran Anda. Jika tidak, Anda mungkin membuat perbandingan yang tidak adil antara nilai parameter ilmiah karena beberapa nilai lebih beruntung dengan pengambilan sampel hyperparameter pengganggu.
Sayangnya, peningkatan dalam salah satu dari tiga dimensi ini memerlukan salah satu dari hal berikut:
- Meningkatkan jumlah uji coba, sehingga meningkatkan biaya resource.
- Menemukan cara untuk menghemat resource dalam salah satu dimensi lainnya.
Setiap masalah memiliki keunikan dan batasan komputasinya sendiri, sehingga mengalokasikan resource untuk ketiga tujuan ini memerlukan tingkat pengetahuan domain tertentu. Setelah menjalankan studi, selalu coba pahami apakah studi tersebut menyetel hyperparameter pengganggu dengan cukup baik. Artinya, studi tersebut menelusuri ruang yang cukup besar secara ekstensif untuk membandingkan hiperparameter ilmiah secara adil (seperti yang dijelaskan lebih mendetail di bagian berikutnya).
Belajar dari hasil eksperimen
Rekomendasi: Selain mencoba mencapai tujuan ilmiah asli setiap grup eksperimen, periksa daftar pertanyaan tambahan. Jika Anda menemukan masalah, revisi dan jalankan kembali eksperimen.
Pada akhirnya, setiap grup eksperimen memiliki tujuan tertentu. Anda harus mengevaluasi bukti yang diberikan eksperimen terhadap sasaran tersebut. Namun, jika Anda mengajukan pertanyaan yang tepat, Anda sering kali dapat menemukan masalah yang perlu diperbaiki sebelum serangkaian eksperimen tertentu dapat mencapai tujuan awalnya. Jika tidak mengajukan pertanyaan ini, Anda mungkin menarik kesimpulan yang salah.
Karena menjalankan eksperimen bisa mahal, Anda juga harus mengekstrak insight berguna lainnya dari setiap grup eksperimen, meskipun insight ini tidak langsung relevan dengan sasaran saat ini.
Sebelum menganalisis serangkaian eksperimen tertentu untuk membuat kemajuan menuju tujuan awalnya, ajukan pertanyaan tambahan berikut kepada diri Anda:
- Apakah ruang penelusuran cukup besar? Jika titik optimal dari studi berada di dekat batas ruang penelusuran dalam satu atau beberapa dimensi, penelusuran mungkin tidak cukup luas. Dalam hal ini, jalankan studi lain dengan ruang penelusuran yang diperluas.
- Apakah Anda telah mengambil sampel poin yang cukup dari ruang penelusuran? Jika tidak, jalankan lebih banyak titik atau jangan terlalu ambisius dalam sasaran penyesuaian.
- Berapa fraksi uji coba dalam setiap studi yang tidak dapat dilakukan? Yaitu, uji coba mana yang berbeda, mendapatkan nilai kerugian yang sangat buruk, atau gagal dijalankan sama sekali karena melanggar beberapa batasan implisit? Jika sebagian besar titik dalam studi tidak dapat dilakukan, sesuaikan ruang penelusuran untuk menghindari pengambilan sampel titik tersebut, yang terkadang memerlukan reparameterisasi ruang penelusuran. Dalam beberapa kasus, sejumlah besar titik yang tidak mungkin dapat menunjukkan adanya bug dalam kode pelatihan.
- Apakah model menunjukkan masalah pengoptimalan?
- Apa yang dapat Anda pelajari dari kurva pelatihan uji coba terbaik? Misalnya, apakah uji coba terbaik memiliki kurva pelatihan yang konsisten dengan overfitting yang bermasalah?
Jika perlu, berdasarkan jawaban atas pertanyaan sebelumnya, perbaiki studi atau grup studi terbaru untuk meningkatkan ruang penelusuran dan/atau mengambil sampel uji coba lainnya, atau lakukan tindakan korektif lainnya.
Setelah menjawab pertanyaan sebelumnya, Anda dapat mengevaluasi bukti yang diberikan eksperimen terhadap sasaran awal Anda; misalnya, mengevaluasi apakah perubahan bermanfaat.
Mengidentifikasi batas ruang penelusuran yang buruk
Ruang penelusuran dianggap mencurigakan jika titik terbaik yang diambil sampelnya dari ruang tersebut dekat dengan batasnya. Anda mungkin menemukan titik yang lebih baik jika memperluas rentang penelusuran ke arah tersebut.
Untuk memeriksa batas ruang penelusuran, sebaiknya petakan uji coba yang telah selesai pada apa yang kami sebut plot sumbu hyperparameter dasar. Dalam visualisasi ini, kita memplot nilai objektif validasi versus salah satu hyperparameter (misalnya, kecepatan pembelajaran). Setiap titik pada plot sesuai dengan satu uji coba.
Nilai tujuan validasi untuk setiap uji coba biasanya adalah nilai terbaik yang dicapai selama pelatihan.

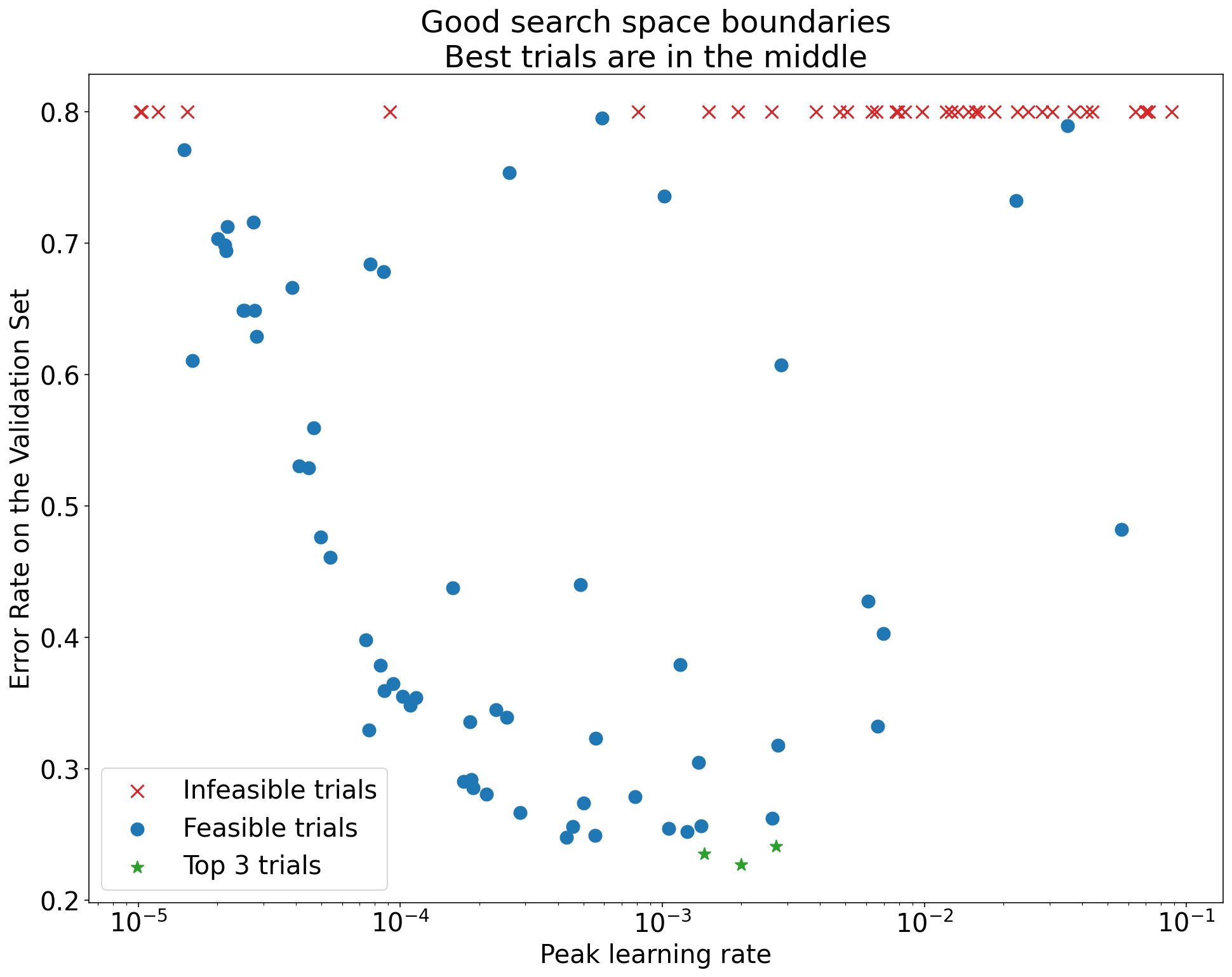
Gambar 1: Contoh batas ruang penelusuran yang buruk dan batas ruang penelusuran yang dapat diterima.
Plot dalam Gambar 1 menunjukkan rasio error (makin rendah makin baik) terhadap kecepatan pembelajaran awal. Jika titik terbaik mengelompok di dekat tepi ruang penelusuran (dalam beberapa dimensi), Anda mungkin perlu memperluas batas ruang penelusuran hingga titik terbaik yang diamati tidak lagi dekat dengan batas.
Sering kali, studi mencakup uji coba "tidak layak" yang berbeda atau mendapatkan hasil yang sangat buruk (ditandai dengan X merah pada Gambar 1). Jika semua uji coba tidak dapat dilakukan untuk laju pembelajaran yang lebih besar dari nilai batas tertentu, dan jika uji coba dengan performa terbaik memiliki laju pembelajaran di tepi wilayah tersebut, model mungkin mengalami masalah stabilitas yang mencegahnya mengakses laju pembelajaran yang lebih tinggi.
Tidak mengambil sampel titik yang cukup di ruang penelusuran
Secara umum, sangat sulit untuk mengetahui apakah ruang penelusuran telah disampel secara cukup padat. 🤖 Menjalankan lebih banyak uji coba lebih baik daripada menjalankan lebih sedikit uji coba, tetapi lebih banyak uji coba akan menimbulkan biaya tambahan yang jelas.
Karena sulit untuk mengetahui kapan Anda telah mengambil sampel yang cukup, sebaiknya:
- Mencoba produk yang sesuai dengan anggaran Anda.
- Mengalibrasi keyakinan intuitif Anda dengan berulang kali melihat berbagai plot sumbu hyperparameter dan mencoba memahami jumlah titik dalam region "baik" di ruang penelusuran.
Memeriksa kurva pelatihan
Ringkasan: Memeriksa kurva kerugian adalah cara mudah untuk mengidentifikasi mode kegagalan umum dan dapat membantu Anda memprioritaskan potensi tindakan berikutnya.
Dalam banyak kasus, tujuan utama eksperimen Anda hanya memerlukan pertimbangan kesalahan validasi setiap percobaan. Namun, berhati-hatilah saat mengurangi setiap uji coba menjadi satu angka karena fokus tersebut dapat menyembunyikan detail penting tentang apa yang terjadi di bawah permukaan. Untuk setiap studi, sebaiknya lihat kurva kerugian dari setidaknya beberapa uji coba terbaik. Meskipun tidak diperlukan untuk menangani tujuan eksperimental utama, memeriksa kurva kerugian (termasuk kerugian pelatihan dan kerugian validasi) adalah cara yang baik untuk mengidentifikasi mode kegagalan umum dan dapat membantu Anda memprioritaskan tindakan yang harus dilakukan selanjutnya.
Saat memeriksa kurva kerugian, fokus pada pertanyaan berikut:
Apakah ada uji coba yang menunjukkan kecocokan berlebih yang bermasalah? Overfitting yang bermasalah terjadi saat error validasi mulai meningkat selama pelatihan. Dalam setelan eksperimental tempat Anda mengoptimalkan hyperparameter pengganggu dengan memilih uji coba "terbaik" untuk setiap setelan hyperparameter ilmiah, periksa apakah ada masalah overfitting dalam setidaknya setiap uji coba terbaik yang sesuai dengan setelan hyperparameter ilmiah yang Anda bandingkan. Jika ada uji coba terbaik yang menunjukkan kecocokan berlebih yang bermasalah, lakukan salah satu atau kedua hal berikut:
- Jalankan kembali eksperimen dengan teknik regularisasi tambahan
- Sesuaikan kembali parameter regularisasi yang ada sebelum membandingkan nilai hyperparameter ilmiah. Hal ini mungkin tidak berlaku jika hyperparameter ilmiah mencakup parameter regularisasi, karena tidak akan mengejutkan jika setelan parameter regularisasi yang lemah menghasilkan overfitting yang bermasalah.
Mengurangi overfitting sering kali mudah dilakukan dengan menggunakan teknik regularisasi umum yang menambahkan kompleksitas kode minimal atau komputasi ekstra (misalnya, regularisasi dropout, perataan label, peluruhan bobot). Oleh karena itu, biasanya mudah untuk menambahkan satu atau beberapa eksperimen ini ke putaran eksperimen berikutnya. Misalnya, jika hyperparameter ilmiah adalah "jumlah lapisan tersembunyi" dan uji coba terbaik yang menggunakan jumlah lapisan tersembunyi terbesar menunjukkan overfitting yang bermasalah, sebaiknya coba lagi dengan regularisasi tambahan, bukan langsung memilih jumlah lapisan tersembunyi yang lebih kecil.
Meskipun tidak ada uji coba "terbaik" yang menunjukkan overfitting bermasalah, mungkin masih ada masalah jika terjadi di salah satu uji coba. Memilih uji coba terbaik akan menekan konfigurasi yang menunjukkan kecocokan berlebih yang bermasalah dan lebih memilih konfigurasi yang tidak bermasalah. Dengan kata lain, memilih uji coba terbaik akan lebih memilih konfigurasi dengan lebih banyak regularisasi. Namun, apa pun yang membuat pelatihan lebih buruk dapat bertindak sebagai regularizer, meskipun tidak dimaksudkan demikian. Misalnya, memilih kecepatan pembelajaran yang lebih kecil dapat meregularisasi pelatihan dengan menghambat proses pengoptimalan, tetapi biasanya kita tidak ingin memilih kecepatan pembelajaran dengan cara ini. Perhatikan bahwa uji coba "terbaik" untuk setiap setelan hyperparameter ilmiah dapat dipilih sedemikian rupa sehingga mendukung nilai "buruk" dari beberapa hyperparameter ilmiah atau pengganggu.
Apakah ada varians langkah demi langkah yang tinggi dalam error pelatihan atau validasi di akhir pelatihan? Jika demikian, hal ini dapat mengganggu kedua hal berikut:
- Kemampuan Anda untuk membandingkan berbagai nilai hyperparameter ilmiah. Hal ini karena setiap uji coba berakhir secara acak pada langkah "beruntung" atau "tidak beruntung".
- Kemampuan Anda untuk mereproduksi hasil uji coba terbaik dalam produksi. Hal ini karena model produksi mungkin tidak berakhir pada langkah "beruntung" yang sama seperti dalam studi.
Penyebab yang paling mungkin dari varians langkah demi langkah adalah:
- Varians batch karena pengambilan sampel contoh secara acak dari set pelatihan untuk setiap batch.
- Set validasi kecil
- Menggunakan kecepatan pembelajaran yang terlalu tinggi di akhir pelatihan.
Kemungkinan solusi meliputi:
- Meningkatkan ukuran batch.
- Mendapatkan lebih banyak data validasi.
- Menggunakan peluruhan kecepatan pembelajaran.
- Menggunakan perataan Polyak.
Apakah uji coba masih meningkat di akhir pelatihan? Jika demikian, Anda berada dalam rezim "terikat komputasi" dan mungkin akan mendapatkan manfaat dari peningkatan jumlah langkah pelatihan atau perubahan jadwal laju pembelajaran.
Apakah performa pada set pelatihan dan validasi sudah mencapai titik jenuh jauh sebelum langkah pelatihan akhir? Jika ya, hal ini menunjukkan bahwa Anda berada dalam rezim "tidak terikat komputasi" dan Anda mungkin dapat mengurangi jumlah langkah pelatihan.
Selain daftar ini, banyak perilaku tambahan dapat terlihat dari pemeriksaan kurva kerugian. Misalnya, peningkatan kerugian pelatihan selama pelatihan biasanya menunjukkan adanya bug dalam pipeline pelatihan.
Mendeteksi apakah perubahan berguna dengan plot isolasi

Gambar 2: Plot isolasi yang menyelidiki nilai terbaik peluruhan bobot untuk ResNet-50 yang dilatih di ImageNet.
Sering kali, tujuan serangkaian eksperimen adalah untuk membandingkan berbagai nilai hyperparameter ilmiah. Misalnya, Anda ingin menentukan nilai peluruhan bobot yang menghasilkan error validasi terbaik. Plot isolasi adalah kasus khusus dari plot sumbu hyperparameter dasar. Setiap titik pada plot isolasi sesuai dengan performa uji coba terbaik di beberapa (atau semua) hyperparameter pengganggu. Dengan kata lain, petakan performa model setelah "mengoptimalkan" hyperparameter yang mengganggu.
Plot isolasi menyederhanakan perbandingan setara antara nilai hyperparameter ilmiah yang berbeda. Misalnya, plot isolasi pada Gambar 2 mengungkapkan nilai peluruhan bobot yang menghasilkan performa validasi terbaik untuk konfigurasi ResNet-50 tertentu yang dilatih di ImageNet.
Jika tujuannya adalah untuk menentukan apakah akan menyertakan peluruhan bobot atau tidak, maka bandingkan titik terbaik dari plot ini dengan dasar tanpa peluruhan bobot. Untuk perbandingan yang adil, baseline juga harus memiliki kecepatan pembelajaran yang disesuaikan dengan baik.
Jika Anda memiliki data yang dihasilkan oleh penelusuran (kuasi)acak dan mempertimbangkan hyperparameter berkelanjutan untuk plot isolasi, Anda dapat memperkirakan plot isolasi dengan mengelompokkan nilai sumbu x dari plot sumbu hyperparameter dasar dan mengambil uji coba terbaik di setiap irisan vertikal yang ditentukan oleh kelompok.
Mengotomatiskan plot yang berguna secara umum
Semakin besar upaya yang diperlukan untuk membuat plot, semakin kecil kemungkinan Anda akan melihatnya sesering yang seharusnya. Oleh karena itu, sebaiknya siapkan infrastruktur Anda untuk menghasilkan sebanyak mungkin plot secara otomatis. Setidaknya, sebaiknya buat plot sumbu hyperparameter dasar secara otomatis untuk semua hyperparameter yang Anda variasikan dalam eksperimen.
Selain itu, sebaiknya buat kurva kerugian secara otomatis untuk semua percobaan. Selain itu, sebaiknya permudah untuk menemukan beberapa uji coba terbaik dari setiap studi dan memeriksa kurva kerugiannya.
Anda dapat menambahkan banyak potensi plot dan visualisasi berguna lainnya. Untuk memparafrasa Geoffrey Hinton:
Setiap kali Anda memetakan sesuatu yang baru, Anda akan mempelajari sesuatu yang baru.
Menentukan apakah akan menerapkan perubahan kandidat
Ringkasan: Saat memutuskan apakah akan melakukan perubahan pada model atau prosedur pelatihan kami atau mengadopsi konfigurasi hyperparameter baru, perhatikan berbagai sumber variasi dalam hasil Anda.
Saat mencoba meningkatkan kualitas model, perubahan kandidat tertentu mungkin awalnya mencapai error validasi yang lebih baik dibandingkan dengan konfigurasi yang ada. Namun, pengulangan eksperimen mungkin tidak menunjukkan keunggulan yang konsisten. Secara informal, sumber hasil yang tidak konsisten yang paling penting dapat dikelompokkan ke dalam kategori luas berikut:
- Varians prosedur pelatihan, varians pelatihan ulang, atau varians uji coba: variasi antara proses pelatihan yang menggunakan hyperparameter yang sama, tetapi dengan nilai awal acak yang berbeda. Misalnya, inisialisasi acak yang berbeda, pengacakan data pelatihan, mask dropout, pola operasi augmentasi data, dan pengurutan operasi aritmatika paralel adalah semua potensi sumber varians percobaan.
- Varians penelusuran hyperparameter, atau varians studi: variasi dalam hasil yang disebabkan oleh prosedur kami untuk memilih hyperparameter. Misalnya, Anda dapat menjalankan eksperimen yang sama dengan ruang penelusuran tertentu, tetapi dengan dua bibit yang berbeda untuk penelusuran kuasi-acak dan akhirnya memilih nilai hyperparameter yang berbeda.
- Pengumpulan data dan varians pengambilan sampel: varians dari segala jenis pemisahan acak ke dalam data pelatihan, validasi, dan pengujian atau varians karena proses pembuatan data pelatihan secara lebih umum.
Benar, Anda dapat membandingkan perkiraan tingkat error validasi pada set validasi terbatas menggunakan uji statistik yang cermat. Namun, sering kali varians uji coba saja dapat menghasilkan perbedaan yang signifikan secara statistik antara dua model terlatih yang berbeda yang menggunakan setelan hyperparameter yang sama.
Kami paling mengkhawatirkan varians studi saat mencoba membuat kesimpulan yang melampaui tingkat titik individual dalam ruang hyperparameter. Varians studi bergantung pada jumlah uji coba dan ruang penelusuran. Kami telah melihat kasus ketika varians studi lebih besar daripada varians uji coba dan kasus ketika varians studi jauh lebih kecil. Oleh karena itu, sebelum menerapkan perubahan kandidat, pertimbangkan untuk menjalankan uji coba terbaik sebanyak N kali untuk mengkarakterisasi varians uji coba run-to-run. Biasanya, Anda dapat lolos hanya dengan mengkarakterisasi ulang varians uji coba setelah perubahan besar pada pipeline, tetapi Anda mungkin memerlukan perkiraan yang lebih baru dalam beberapa kasus. Dalam aplikasi lain, mengkarakterisasi varians uji coba terlalu mahal untuk dilakukan.
Meskipun Anda hanya ingin menerapkan perubahan (termasuk konfigurasi hiperparameter baru) yang menghasilkan peningkatan nyata, menuntut kepastian lengkap bahwa perubahan tertentu membantu juga bukan jawaban yang tepat. Oleh karena itu, jika titik hyperparameter baru (atau perubahan lainnya) memberikan hasil yang lebih baik daripada dasar pengukuran (dengan mempertimbangkan varians pelatihan ulang dari titik baru dan dasar pengukuran sebaik mungkin), maka Anda sebaiknya mengadopsinya sebagai dasar pengukuran baru untuk perbandingan di masa mendatang. Namun, sebaiknya hanya terapkan perubahan yang menghasilkan peningkatan yang lebih besar daripada kompleksitas yang ditimbulkannya.
Setelah eksplorasi selesai
Ringkasan: Alat pengoptimalan Bayesian adalah opsi yang menarik setelah Anda selesai menelusuri ruang penelusuran yang baik dan telah memutuskan hyperparameter mana yang layak disesuaikan.
Pada akhirnya, prioritas Anda akan beralih dari mempelajari lebih lanjut masalah penyesuaian ke menghasilkan satu konfigurasi terbaik untuk diluncurkan atau digunakan. Pada saat itu, akan ada ruang penelusuran yang lebih baik yang dengan nyaman berisi wilayah lokal di sekitar uji coba terbaik yang diamati dan telah diambil sampelnya secara memadai. Pekerjaan eksplorasi Anda seharusnya telah mengungkapkan hyperparameter paling penting untuk disesuaikan dan rentang yang masuk akal yang dapat Anda gunakan untuk membuat ruang penelusuran untuk studi penyesuaian otomatis akhir menggunakan anggaran penyesuaian sebesar mungkin.
Karena Anda tidak lagi ingin memaksimalkan insight tentang masalah penyesuaian, banyak keuntungan penelusuran kuasi-acak tidak lagi berlaku. Oleh karena itu, Anda harus menggunakan alat pengoptimalan Bayesian untuk menemukan konfigurasi hyperparameter terbaik secara otomatis. Vizier Open Source menerapkan berbagai algoritma canggih untuk menyesuaikan model ML, termasuk algoritma Pengoptimalan Bayesian.
Misalkan ruang penelusuran berisi volume titik yang berbeda yang tidak sepele, yang berarti titik yang mendapatkan kerugian pelatihan NaN atau bahkan kerugian pelatihan yang lebih buruk dari rata-rata dengan banyak standar deviasi. Dalam hal ini, sebaiknya gunakan alat pengoptimalan black-box yang menangani uji coba yang berbeda dengan benar. (Lihat Pengoptimalan Bayesian dengan Batasan yang Tidak Diketahui untuk mengetahui cara terbaik mengatasi masalah ini.) Vizier Open Source mendukung penandaan titik-titik yang berbeda dengan menandai uji coba sebagai tidak layak, meskipun mungkin tidak menggunakan pendekatan pilihan kami dari Gelbart et al., bergantung pada cara konfigurasinya.
Setelah eksplorasi selesai, pertimbangkan untuk memeriksa performa pada set pengujian. Pada prinsipnya, Anda bahkan dapat menggabungkan set validasi ke dalam set pelatihan dan melatih ulang konfigurasi terbaik yang ditemukan dengan pengoptimalan Bayesian. Namun, hal ini hanya tepat jika tidak akan ada peluncuran di masa mendatang dengan beban kerja spesifik ini (misalnya, kompetisi Kaggle satu kali).