"जनरेटिव एडवर्सरी नेटवर्क" के नाम में "जनरेटिव" का क्या मतलब है? "जनरेटिव", आंकड़ों के ऐसे मॉडल की क्लास के बारे में बताता है जो डिसक्रिमिनेटिव मॉडल से अलग होते हैं.
अनौपचारिक तौर पर:
- जनरेटिव मॉडल, नए डेटा इंस्टेंस जनरेट कर सकते हैं.
- भेदभाव करने वाले मॉडल, अलग-अलग तरह के डेटा इंस्टेंस के बीच अंतर करते हैं.
जनरेटिव मॉडल, जानवरों की ऐसी नई फ़ोटो जनरेट कर सकता है जो असल जानवरों जैसी दिखती हैं. वहीं, डिस्क्रीमिनेटिव मॉडल, कुत्ते और बिल्ली में अंतर बता सकता है. जीएएन, जनरेटिव मॉडल का सिर्फ़ एक टाइप है.
ज़्यादा औपचारिक तौर पर, डेटा इंस्टेंस X का सेट और लेबल Y का सेट दिया गया है:
- जनरेटिव मॉडल, एक साथ होने की संभावना p(X, Y) को कैप्चर करते हैं. अगर कोई लेबल नहीं है, तो सिर्फ़ p(X) को कैप्चर किया जाता है.
- डिसक्रिमिनेटिव मॉडल, शर्त के साथ दी गई संभावना p(Y | X) को कैप्चर करते हैं.
जनरेटिव मॉडल में डेटा का डिस्ट्रिब्यूशन शामिल होता है. साथ ही, यह आपको बताता है कि किसी दिए गए उदाहरण की संभावना कितनी है. उदाहरण के लिए, किसी क्रम में अगले शब्द का अनुमान लगाने वाले मॉडल आम तौर पर जनरेटिव मॉडल होते हैं. ये आम तौर पर जीएएन (GAN) से ज़्यादा आसान होते हैं, क्योंकि ये शब्दों के क्रम में संभावना तय कर सकते हैं.
भेदभाव करने वाला मॉडल, इस सवाल को अनदेखा करता है कि किसी दिए गए इंस्टेंस की संभावना है या नहीं. यह सिर्फ़ आपको यह बताता है कि किसी इंस्टेंस पर लेबल लागू होने की संभावना कितनी है.
ध्यान दें कि यह एक सामान्य परिभाषा है. जनरेटिव मॉडल कई तरह के होते हैं. जीएएन, जनरेटिव मॉडल का सिर्फ़ एक टाइप है.
मॉडलिंग की संभावनाएं
दोनों तरह के मॉडल को, किसी संभावना को दिखाने वाला कोई नंबर नहीं दिखाना होता. डेटा के डिस्ट्रिब्यूशन को मॉडल करने के लिए, उस डिस्ट्रिब्यूशन की नकल की जा सकती है.
उदाहरण के लिए, फ़ैसला लेने वाले पेड़ जैसा कोई भेदभाव करने वाला क्लासिफ़ायर, किसी इंस्टेंस को लेबल कर सकता है. ऐसा करने के लिए, वह उस लेबल को कोई संभावना असाइन नहीं करता. ऐसा क्लासिफ़ायर अब भी एक मॉडल होगा, क्योंकि अनुमानित सभी लेबल का डिस्ट्रिब्यूशन, डेटा में लेबल के असल डिस्ट्रिब्यूशन का मॉडल होगा.
इसी तरह, जनरेटिव मॉडल किसी डिस्ट्रिब्यूशन का मॉडल बना सकता है. इसके लिए, वह ऐसा "नकली" डेटा जनरेट करता है जो असल डिस्ट्रिब्यूशन से लिया गया लगता है.
जनरेटिव मॉडल बनाना मुश्किल है
जनरेटिव मॉडल, मिलते-जुलते डिस्क्रीमिनेटिव मॉडल के मुकाबले ज़्यादा मुश्किल काम करते हैं. जनरेटिव मॉडल को ज़्यादा मॉडल बनाना पड़ता है.
इमेज के लिए जनरेटिव मॉडल, "नाव जैसी दिखने वाली चीज़ें, पानी जैसी दिखने वाली चीज़ों के पास दिख सकती हैं" और "आंखें, माथे पर नहीं दिख सकतीं" जैसे संबंधों को कैप्चर कर सकता है. ये बहुत मुश्किल डिस्ट्रिब्यूशन हैं.
इसके उलट, डिस्क्रीमिनेटिव मॉडल, सिर्फ़ कुछ अहम पैटर्न देखकर, "सैलबोट" या "सैलबोट नहीं" के बीच का अंतर जान सकता है. यह कई ऐसे कनेक्शन को अनदेखा कर सकता है जिन्हें जनरेटिव मॉडल को सही तरीके से समझना चाहिए.
डिस्क्रेमिनेटिव मॉडल, डेटा स्पेस में सीमाएं तय करने की कोशिश करते हैं. वहीं, जनरेटिव मॉडल, पूरे स्पेस में डेटा को कैसे रखा जाता है, यह मॉडल करने की कोशिश करते हैं. उदाहरण के लिए, नीचे दिए गए डायग्राम में, लिखे गए अंकों के लिए डिस्टिंक्टिव और जनरेटिव मॉडल दिखाए गए हैं:
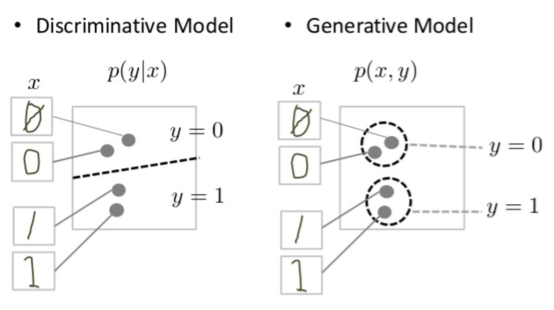
पहली इमेज: हाथ से लिखे गए अंकों के लिए, डिस्टिंक्टिव और जनरेटिव मॉडल.
डिस्क्रीमिनेटिव मॉडल, डेटा स्पेस में लाइन खींचकर, हाथ से लिखे गए 0 और 1 के बीच का अंतर बताने की कोशिश करता है. अगर यह लाइन सही तरीके से तय कर लेता है, तो यह 0 और 1 में अंतर कर सकता है. इसके लिए, यह ज़रूरी नहीं है कि लाइन के दोनों ओर डेटा स्पेस में, इंस्टेंस को सही जगह पर रखा गया हो.
इसके उलट, जनरेटिव मॉडल, डेटास्पेस में अपने असली वर्शन के करीब आने वाले अंक जनरेट करके, 1 और 0 जनरेट करने की कोशिश करता है. इसे पूरे डेटा स्पेस में डिस्ट्रिब्यूशन को मॉडल करना होगा.
जीएएन, ऐसे रिच मॉडल को ट्रेन करने का असरदार तरीका देते हैं, ताकि वे असल डिस्ट्रिब्यूशन से मिलते-जुलते हों. इनके काम करने का तरीका समझने के लिए, हमें जीएएन के बुनियादी स्ट्रक्चर को समझना होगा.
देखें कि आपने कितना समझा है: जनरेटिव बनाम डिस्क्रीमिनेटिव मॉडल
- छह तरफ़ वाले तीन पासे फेंके जाते हैं.
- रोल को किसी कॉन्स्टेंट w से गुणा करें.
- इसे 100 बार दोहराएं और सभी नतीजों का औसत निकालें.