بسیاری از مسائل نیاز به برآورد احتمال به عنوان خروجی دارند. رگرسیون لجستیک یک مکانیسم بسیار کارآمد برای محاسبه احتمالات است. از نظر عملی، می توانید از احتمال بازگشتی به یکی از دو روش زیر استفاده کنید:
اعمال "همانطور که هست". به عنوان مثال، اگر یک مدل پیشبینی هرزنامه، یک ایمیل را به عنوان ورودی دریافت کند و مقدار
0.932را خروجی کند، این به احتمال93.2%است که ایمیل اسپم است.به یک دسته باینری مانند
TrueیاFalse،SpamیاNot Spamتبدیل شده است.
این ماژول بر استفاده از خروجی مدل رگرسیون لجستیک همانطور که هست تمرکز دارد. در ماژول Classification ، نحوه تبدیل این خروجی را به یک دسته باینری خواهید آموخت.
تابع سیگموئید
ممکن است تعجب کنید که چگونه یک مدل رگرسیون لجستیک می تواند اطمینان حاصل کند که خروجی آن یک احتمال را نشان می دهد و همیشه مقداری بین 0 و 1 را خروجی می دهد. همانطور که اتفاق می افتد، خانواده ای از توابع به نام توابع لجستیک وجود دارد که خروجی آن همان ویژگی ها را دارد. تابع لجستیک استاندارد که به عنوان تابع سیگموئید نیز شناخته می شود ( سیگموئید به معنای "s شکل" است) دارای فرمول است:
\[f(x) = \frac{1}{1 + e^{-x}}\]
کجا:
- f(x) خروجی تابع سیگموئید است.
- e عدد اویلر است: یک ثابت ریاضی ≈ 2.71828.
- x ورودی تابع سیگموئید است.
شکل 1 نمودار مربوط به تابع سیگموئید را نشان می دهد.

با افزایش ورودی x ، خروجی تابع سیگموئید نزدیک می شود اما هرگز به 1 نمی رسد. به طور مشابه، با کاهش ورودی، خروجی تابع سیگموئید نزدیک می شود اما هرگز به 0 نمی رسد.
برای بررسی عمیقتر ریاضیات پشت تابع سیگموئید اینجا را کلیک کنید
جدول زیر مقادیر خروجی تابع سیگموئید را برای مقادیر ورودی در محدوده -7 تا 7 نشان می دهد. توجه داشته باشید که سیگموئید با چه سرعتی برای کاهش مقادیر ورودی منفی به 0 نزدیک می شود و سیگموئید با چه سرعتی برای افزایش مقادیر ورودی مثبت به 1 نزدیک می شود.
با این حال، مهم نیست که مقدار ورودی چقدر بزرگ یا کوچک باشد، خروجی همیشه بزرگتر از 0 و کمتر از 1 خواهد بود.
| ورودی | خروجی سیگموئید |
|---|---|
| -7 | 0.001 |
| -6 | 0.002 |
| -5 | 0.007 |
| -4 | 0.018 |
| -3 | 0.047 |
| -2 | 0.119 |
| -1 | 0.269 |
| 0 | 0.50 |
| 1 | 0.731 |
| 2 | 0.881 |
| 3 | 0.952 |
| 4 | 0.982 |
| 5 | 0.993 |
| 6 | 0.997 |
| 7 | 0.999 |
تبدیل خروجی خطی با استفاده از تابع سیگموئید
معادله زیر مؤلفه خطی یک مدل رگرسیون لجستیک را نشان می دهد:
\[z = b + w_1x_1 + w_2x_2 + \ldots + w_Nx_N\]
کجا:
- z خروجی معادله خطی است که به آن log odds نیز می گویند.
- b تعصب است.
- مقادیر w وزن های آموخته شده مدل هستند.
- مقادیر x مقادیر ویژگی برای یک مثال خاص هستند.
برای به دست آوردن پیشبینی رگرسیون لجستیک، مقدار z به تابع سیگموئید منتقل میشود و یک مقدار (احتمال) بین 0 و 1 به دست میآید:
\[y' = \frac{1}{1 + e^{-z}}\]
کجا:
- y' خروجی مدل رگرسیون لجستیک است.
- e عدد اویلر است: یک ثابت ریاضی ≈ 2.71828.
- z خروجی خطی است (همانطور که در معادله قبل محاسبه شد).
برای اطلاعات بیشتر در مورد log-shans اینجا را کلیک کنید
در معادله $z = b + w_1x_1 + w_2x_2 + \ldots + w_Nx_N$، z به عنوان log-odds نامیده میشود، زیرا اگر با تابع سیگموید زیر شروع کنید (که $y$ خروجی یک مدل رگرسیون لجستیک است که یک احتمال را نشان میدهد):
$$y = \frac{1}{1 + e^{-z}}$$
و سپس برای z حل کنید:
$$ z = \ln\left(\frac{y}{1-y}\right) $$
سپس z به عنوان لگاریتم طبیعی نسبت احتمالات دو نتیجه ممکن تعریف می شود: y و 1 – y .
شکل 2 نشان می دهد که چگونه خروجی خطی با استفاده از این محاسبات به خروجی رگرسیون لجستیک تبدیل می شود.
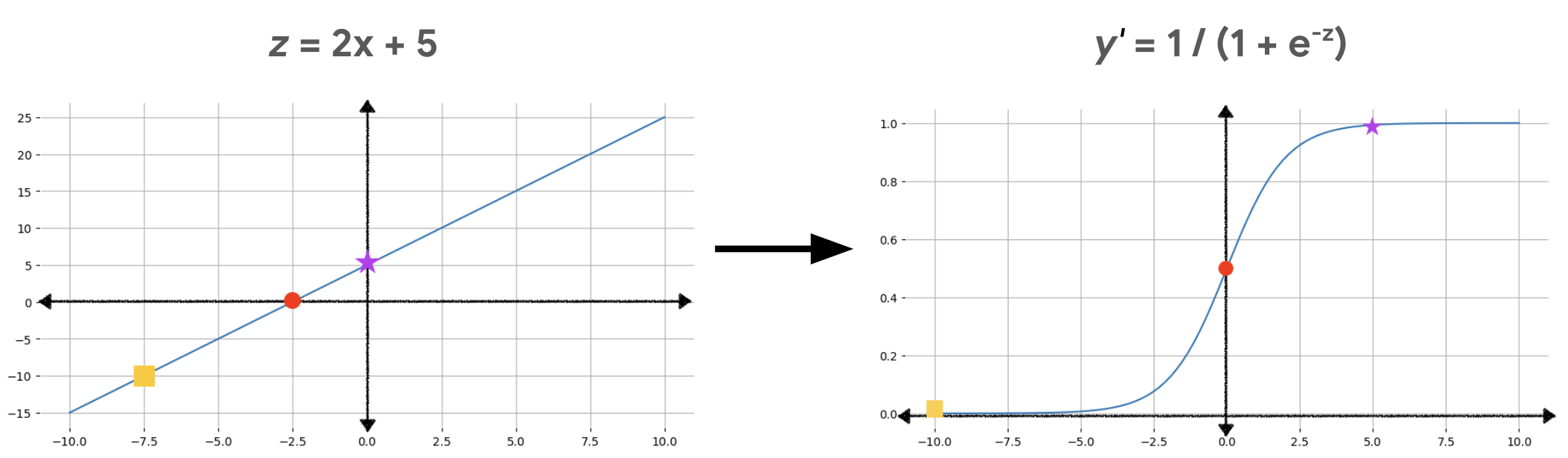
در شکل 2، یک معادله خطی ورودی تابع سیگموئید می شود که خط مستقیم را به شکل s خم می کند. توجه داشته باشید که معادله خطی می تواند مقادیر بسیار بزرگ یا بسیار کوچک z را خروجی دهد، اما خروجی تابع سیگموید، y'، همیشه بین 0 و 1، منحصر به فرد است. به عنوان مثال، مربع زرد در نمودار سمت چپ دارای مقدار az 10- است، اما تابع سیگموئید در نمودار سمت راست، 10- را به مقدار y 0.00004 نشان می دهد.
تمرین: درک خود را بررسی کنید
یک مدل رگرسیون لجستیک با سه ویژگی دارای سوگیری و وزن زیر است:
\[\begin{align} b &= 1 \\ w_1 &= 2 \\ w_2 &= -1 \\ w_3 &= 5 \end{align} \]
با توجه به مقادیر ورودی زیر:
\[\begin{align} x_1 &= 0 \\ x_2 &= 10 \\ x_3 &= 2 \end{align} \]
به دو سوال زیر پاسخ دهید.
همانطور که در شماره 1 در بالا محاسبه شد، شانس ورود برای مقادیر ورودی 1 است. وصل کردن آن مقدار برای z به تابع سیگموئید:
\(y = \frac{1}{1 + e^{-z}} = \frac{1}{1 + e^{-1}} = \frac{1}{1 + 0.367} = \frac{1}{1.367} = 0.731\)