Régression linéaire: descente de gradient
Restez organisé à l'aide des collections
Enregistrez et classez les contenus selon vos préférences.
La descente de gradient est une technique mathématique qui trouve de manière itérative les pondérations et le biais qui produisent le modèle avec la perte la plus faible. La descente de gradient trouve le meilleur poids et le meilleur biais en répétant le processus suivant pour un certain nombre d'itérations définies par l'utilisateur.
Le modèle commence l'entraînement avec des pondérations et des biais aléatoires proches de zéro, puis répète les étapes suivantes :
Calculez la perte avec le biais et le poids actuels.
Déterminez la direction dans laquelle déplacer les pondérations et le biais pour réduire la perte.
Déplacez légèrement les valeurs de pondération et de biais dans la direction qui réduit la perte.
Revenez à la première étape et répétez le processus jusqu'à ce que le modèle ne puisse plus réduire la perte.
Le schéma ci-dessous décrit les étapes itératives effectuées par la descente de gradient pour trouver les pondérations et le biais qui produisent le modèle avec la perte la plus faible.
Figure 11 : La descente de gradient est un processus itératif qui trouve les pondérations et le biais qui produisent le modèle avec la perte la plus faible.
Cliquez sur l'icône Plus pour en savoir plus sur les calculs mathématiques qui sous-tendent la descente de gradient.
Concrètement, nous pouvons parcourir les étapes de la descente de gradient en utilisant le petit ensemble de données sur l'efficacité énergétique suivant, qui comporte sept exemples, et la racine carrée de l'erreur quadratique moyenne (RMSE) comme métrique de perte :
Livres (fonctionnalité)
Milles par gallon (libellé)
3.5
18
3,69
15
3.44
18
3.43
16
4.34
15
4,42
14
2,37
24
Le modèle commence l'entraînement en définissant le poids et le biais sur zéro :
Cliquez sur l'icône Plus pour en savoir plus sur le calcul de la pente.
Pour obtenir la pente des lignes tangentes au poids et au biais, nous prenons la dérivée de la fonction de perte par rapport au poids et au biais, puis nous résolvons les équations.
Nous allons écrire l'équation pour faire une prédiction comme suit :
$ f_{w,b}(x) = (w*x)+b $.
Nous allons écrire la valeur réelle sous la forme suivante : $ y $.
Nous allons calculer l'erreur quadratique moyenne à l'aide de la formule suivante :
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
où $i$ représente le $ith$ exemple d'entraînement et $M$ représente le nombre d'exemples.
Dérivée du poids
La dérivée de la fonction de perte par rapport au poids s'écrit comme suit :
$ \frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
et est évaluée comme suit :
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2x_{(i)} $
Nous commençons par additionner chaque valeur prédite moins la valeur réelle, puis nous multiplions le résultat par deux fois la valeur de la caractéristique.
Nous divisons ensuite la somme par le nombre d'exemples.
Le résultat est la pente de la droite tangente à la valeur du poids.
Si nous résolvons cette équation avec un poids et un biais égaux à zéro, nous obtenons -119,7 pour la pente de la droite.
Dérivée du biais
La dérivée de la fonction de perte par rapport au biais s'écrit comme suit :
$ \frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
et est évaluée comme suit :
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2 $
Nous commençons par additionner chaque valeur prédite moins la valeur réelle, puis nous multiplions le résultat par deux. Nous divisons ensuite la somme par le nombre d'exemples. Le résultat est la pente de la droite tangente à la valeur du biais.
Si nous résolvons cette équation avec un poids et un biais égaux à zéro, nous obtenons -34,3 pour la pente de la droite.
Déplacez-vous légèrement dans la direction de la pente négative pour obtenir le prochain poids et le prochain biais. Pour l'instant, nous allons définir arbitrairement le "petit montant" sur 0,01 :
Utilisez le nouveau poids et le nouveau biais pour calculer la perte et recommencer. Si nous effectuons le processus pendant six itérations, nous obtenons les pondérations, les biais et les pertes suivants :
Itération
Poids
Biais
Perte (MSE)
1
0
0
303.71
2
1.20
0,34
170.84
3
2,05
0.59
103.17
4
2,66
0.78
68.70
5
3.09
0,91
51.13
6
3,40
1.01
42.17
Vous pouvez constater que la perte diminue à chaque mise à jour des pondérations et des biais.
Dans cet exemple, nous nous sommes arrêtés après six itérations. En pratique, un modèle s'entraîne jusqu'à ce qu'il converge.
Lorsqu'un modèle converge, les itérations supplémentaires ne réduisent plus la perte, car la descente de gradient a trouvé les pondérations et le biais qui minimisent presque la perte.
Si le modèle continue de s'entraîner après la convergence, la perte commence à fluctuer légèrement, car le modèle met constamment à jour les paramètres autour de leurs valeurs les plus basses. Il peut donc être difficile de vérifier que le modèle a réellement convergé. Pour confirmer que le modèle a convergé, vous devez continuer à l'entraîner jusqu'à ce que la perte se stabilise.
Convergence du modèle et courbes de perte
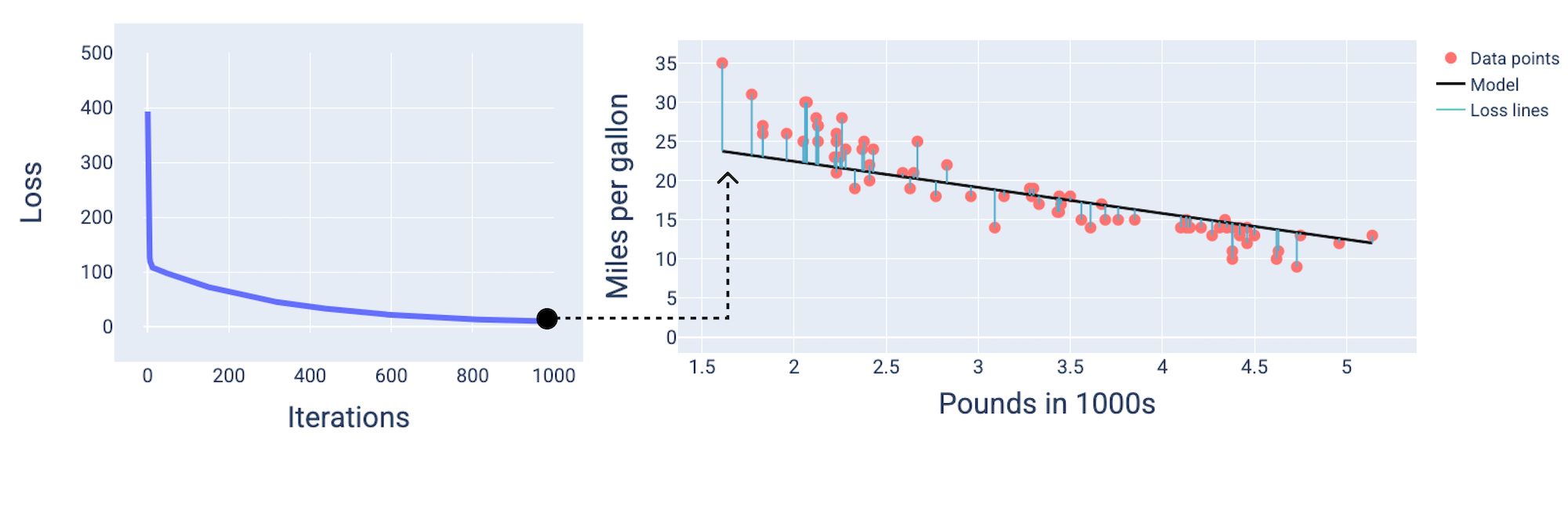
Lorsque vous entraînez un modèle, vous examinez souvent une courbe de perte pour déterminer si le modèle a convergé. La courbe de perte montre comment la perte évolue à mesure que le modèle s'entraîne. Voici à quoi ressemble une courbe de perte typique. La perte est représentée sur l'axe Y et les itérations sur l'axe X :
Figure 12. Courbe de perte montrant la convergence du modèle autour de la 1 000e itération.
Vous pouvez constater que la perte diminue considérablement au cours des premières itérations, puis diminue progressivement avant de se stabiliser autour de la 1 000e itération. Au bout de 1 000 itérations, nous pouvons être presque certains que le modèle a convergé.
Dans les figures suivantes, nous dessinons le modèle à trois moments du processus d'entraînement : au début, au milieu et à la fin. La visualisation de l'état du modèle à des moments précis du processus d'entraînement renforce le lien entre la mise à jour des pondérations et du biais, la réduction de la perte et la convergence du modèle.
Dans les figures, nous utilisons les pondérations et le biais dérivés à une itération particulière pour représenter le modèle. Dans le graphique avec les points de données et l'instantané du modèle, les lignes de perte bleues du modèle aux points de données indiquent la quantité de perte. Plus les lignes sont longues, plus les pertes sont importantes.
Dans la figure suivante, nous pouvons voir qu'autour de la deuxième itération, le modèle ne serait pas en mesure de faire de bonnes prédictions en raison de la perte élevée.
Figure 13. Courbe de perte et instantané du modèle au début du processus d'entraînement.
Aux alentours de la 400e itération, nous pouvons constater que la descente de gradient a trouvé le poids et le biais qui produisent un meilleur modèle.
Figure 14. Courbe de perte et instantané du modèle à mi-parcours de l'entraînement.
Aux alentours de la 1 000e itération, nous pouvons voir que le modèle a convergé, produisant un modèle avec la perte la plus faible possible.
Figure 15. Courbe de perte et instantané du modèle vers la fin du processus d'entraînement.
Exercice : Vérifier que vous avez bien compris
Quel est le rôle de la descente de gradient dans la régression linéaire ?
La descente de gradient est un processus itératif qui permet de trouver les meilleurs poids et biais pour minimiser la perte.
La descente de gradient permet de déterminer le type de perte à utiliser lors de l'entraînement d'un modèle, par exemple L1 ou L2.
La descente de gradient n'est pas impliquée dans la sélection d'une fonction de perte pour l'entraînement du modèle.
La descente de gradient supprime les valeurs aberrantes de l'ensemble de données pour aider le modèle à faire de meilleures prédictions.
La descente de gradient ne modifie pas l'ensemble de données.
Convergence et fonctions convexes
Les fonctions de perte pour les modèles linéaires produisent toujours une surface convexe. Grâce à cette propriété, lorsqu'un modèle de régression linéaire converge, nous savons qu'il a trouvé les pondérations et le biais qui produisent la perte la plus faible.
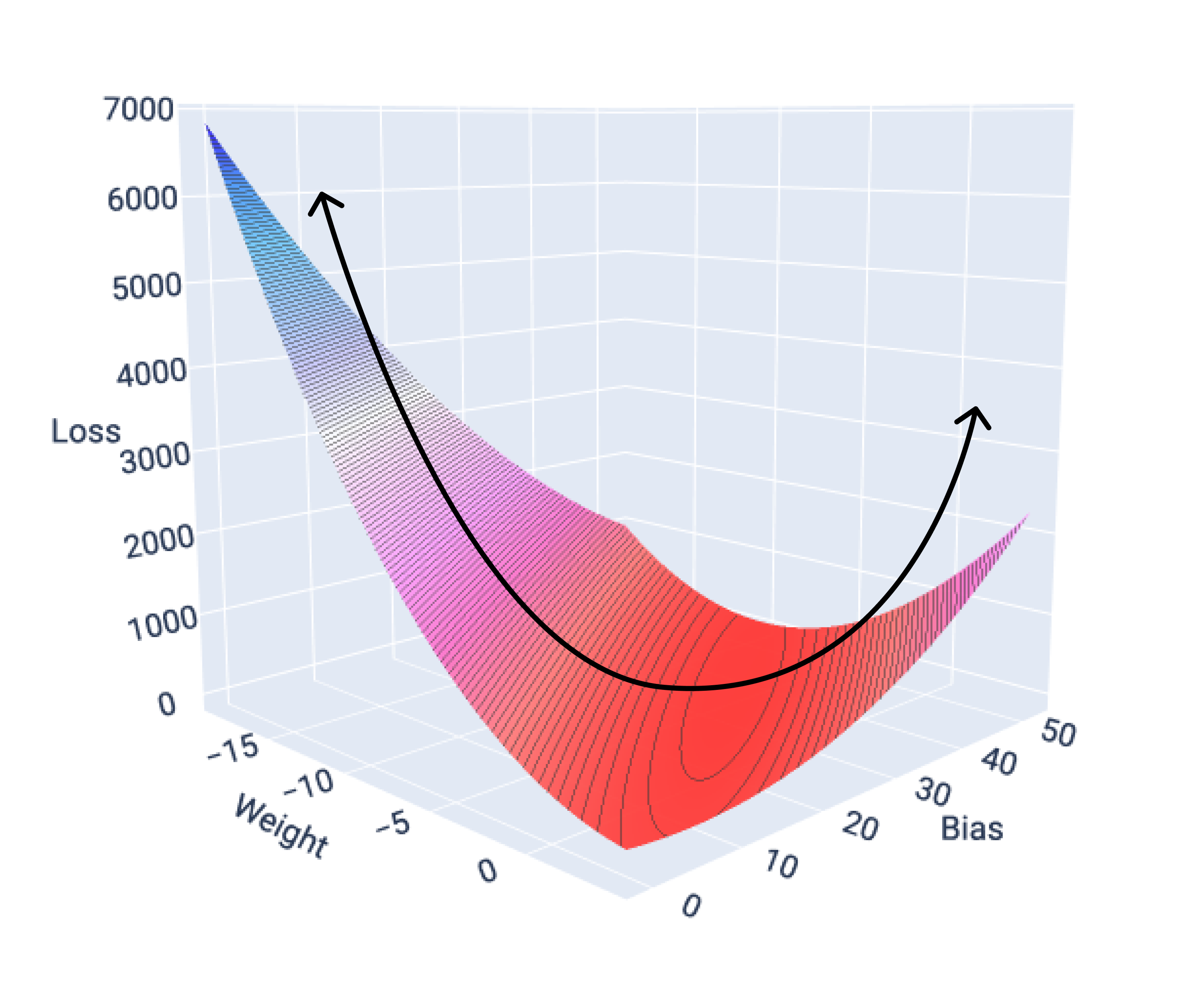
Si nous représentons graphiquement la surface de perte d'un modèle avec une caractéristique, nous pouvons voir sa forme convexe. Voici la surface de perte pour un ensemble de données hypothétique sur les kilomètres par gallon. Le poids est sur l'axe X, le biais sur l'axe Y et la perte sur l'axe Z :
Figure 16. Surface de perte montrant sa forme convexe.
Dans cet exemple, une pondération de -5,44 et un biais de 35,94 produisent la perte la plus faible (5,54) :
Figure 17 : Surface de perte montrant les valeurs de poids et de biais qui produisent la perte la plus faible.
Un modèle linéaire converge lorsqu'il a trouvé la perte minimale. Si nous représentions graphiquement les points de pondération et de biais lors de la descente de gradient, les points ressembleraient à une balle qui roule en bas d'une colline et s'arrête finalement au point où il n'y a plus de pente descendante.
Figure 18 : Graphique de perte montrant les points de descente de gradient s'arrêtant au point le plus bas du graphique.
Notez que les points de perte noirs créent la forme exacte de la courbe de perte : une forte diminution avant une pente douce jusqu'à ce qu'ils atteignent le point le plus bas de la surface de perte.
En utilisant les valeurs de pondération et de biais qui produisent la perte la plus faible (dans ce cas, une pondération de -5,44 et un biais de 35,94), nous pouvons représenter le modèle sous forme graphique pour voir dans quelle mesure il correspond aux données :
Figure 19. Modèle représenté à l'aide des valeurs de pondération et de biais qui produisent la perte la plus faible.
Il s'agit du meilleur modèle pour cet ensemble de données, car aucune autre valeur de poids et de biais ne produit un modèle avec une perte plus faible.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2026/02/03 (UTC).
[[["Facile à comprendre","easyToUnderstand","thumb-up"],["J'ai pu résoudre mon problème","solvedMyProblem","thumb-up"],["Autre","otherUp","thumb-up"]],[["Il n'y a pas l'information dont j'ai besoin","missingTheInformationINeed","thumb-down"],["Trop compliqué/Trop d'étapes","tooComplicatedTooManySteps","thumb-down"],["Obsolète","outOfDate","thumb-down"],["Problème de traduction","translationIssue","thumb-down"],["Mauvais exemple/Erreur de code","samplesCodeIssue","thumb-down"],["Autre","otherDown","thumb-down"]],["Dernière mise à jour le 2026/02/03 (UTC)."],[],[]]