Cuando se evalúa un modelo, las métricas se calculan en comparación con una prueba o validación completa no siempre brindan una imagen precisa de cuán justo es el modelo. En general, un buen rendimiento del modelo para la mayoría de los ejemplos puede enmascarar en un subconjunto minoritario de ejemplos, lo que puede dar lugar predicciones del modelo. Usar métricas de rendimiento agregadas, como precisión, recuperación, y exactitud no necesariamente para exponer estos problemas.
Podemos revisar nuestro modelo de admisiones y explorar algunas técnicas nuevas. para evaluar sus predicciones de sesgo, teniendo en cuenta la equidad.
Supongamos que el modelo de clasificación de admisiones selecciona 20 estudiantes para admitir universidad a partir de un conjunto de 100 candidatos, que pertenecen a dos grupos demográficos: el grupo mayoritario (azul, 80 estudiantes) y el grupo minoritario (naranja, 20 estudiantes).
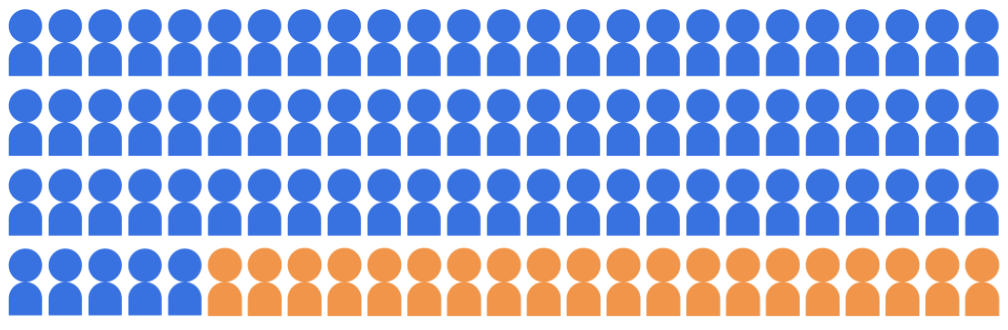
El modelo debe admitir a los estudiantes calificados de una manera justa para candidatos en ambos grupos demográficos.
¿Cómo debemos evaluar las predicciones del modelo en cuanto a la equidad? Hay una gran variedad de métricas que podemos considerar, cada una de las cuales proporciona una definición definición de "equidad". En las siguientes secciones, exploraremos estas métricas de equidad: paridad demográfica, igualdad de oportunidades, y equidad contrafáctica.