En esta página, se incluyen términos del glosario de métricas. Para consultar todos los términos del glosario, haz clic aquí.
A
exactitud
Es la cantidad de predicciones de clasificación correctas dividida por la cantidad total de predicciones. Es decir:
Por ejemplo, un modelo que realizó 40 predicciones correctas y 10 incorrectas tendría una precisión de:
La clasificación binaria proporciona nombres específicos para las diferentes categorías de predicciones correctas y predicciones incorrectas. Por lo tanto, la fórmula de exactitud para la clasificación binaria es la siguiente:
Donde:
- TP es la cantidad de verdaderos positivos (predicciones correctas).
- TN es la cantidad de verdaderos negativos (predicciones correctas).
- FP es la cantidad de falsos positivos (predicciones incorrectas).
- FN es la cantidad de falsos negativos (predicciones incorrectas).
Compara y contrasta la exactitud con la precisión y la recuperación.
Consulta Clasificación: Precisión, recuperación, exactitud y métricas relacionadas en el Curso intensivo de aprendizaje automático para obtener más información.
Área bajo la curva de PR
Consulta PR AUC (área bajo la curva de PR).
área bajo la curva ROC
Consulta AUC (área bajo la curva ROC).
AUC (área bajo la curva ROC)
Es un número entre 0.0 y 1.0 que representa la capacidad de un modelo de clasificación binaria para separar las clases positivas de las clases negativas. Cuanto más cerca esté el AUC de 1.0, mejor será la capacidad del modelo para separar las clases entre sí.
Por ejemplo, la siguiente ilustración muestra un modelo de clasificación que separa perfectamente las clases positivas (óvalos verdes) de las clases negativas (rectángulos morados). Este modelo irrealmente perfecto tiene un AUC de 1.0:

Por el contrario, la siguiente ilustración muestra los resultados de un modelo de clasificación que generó resultados aleatorios. Este modelo tiene un AUC de 0.5:

Sí, el modelo anterior tiene un AUC de 0.5, no de 0.0.
La mayoría de los modelos se encuentran en algún punto intermedio entre los dos extremos. Por ejemplo, el siguiente modelo separa los positivos de los negativos en cierta medida y, por lo tanto, tiene un AUC entre 0.5 y 1.0:

El AUC ignora cualquier valor que establezcas para el umbral de clasificación. En cambio, el AUC considera todos los umbrales de clasificación posibles.
Haz clic en el ícono para obtener información sobre la relación entre las curvas ROC y el AUC.
El AUC representa el área bajo una curva ROC. Por ejemplo, la curva ROC de un modelo que separa perfectamente los positivos de los negativos se ve de la siguiente manera:
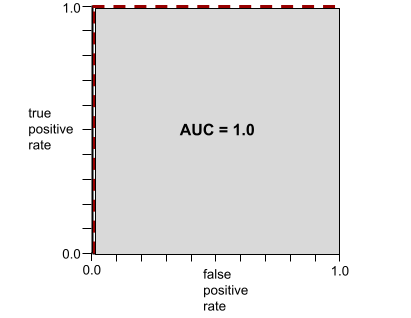
El AUC es el área de la región gris en la ilustración anterior. En este caso inusual, el área es simplemente la longitud de la región gris (1.0) multiplicada por el ancho de la región gris (1.0). Por lo tanto, el producto de 1.0 y 1.0 genera un AUC de exactamente 1.0, que es la puntuación de AUC más alta posible.
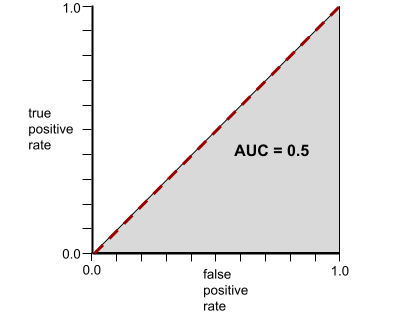
Por el contrario, la curva ROC para un modelo de clasificación que no puede separar las clases en absoluto es la siguiente. El área de esta región gris es 0.5.
Una curva ROC más típica se ve aproximadamente de la siguiente manera:
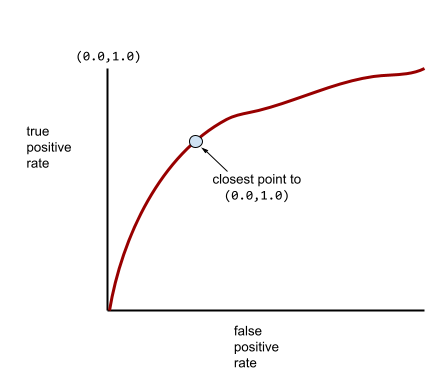
Calcular el área bajo esta curva de forma manual sería un trabajo arduo, por lo que, por lo general, un programa calcula la mayoría de los valores del AUC.
Para obtener más información, consulta Clasificación: ROC y AUC en el Curso intensivo de aprendizaje automático.
Precisión promedio en k
Es una métrica para resumir el rendimiento de un modelo en una sola instrucción que genera resultados clasificados, como una lista numerada de recomendaciones de libros. La precisión promedio en k es, bueno, el promedio de los valores de precisión en k para cada resultado relevante. Por lo tanto, la fórmula para la precisión promedio en k es la siguiente:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
Donde:
- \(n\) es la cantidad de elementos pertinentes en la lista.
Compara esto con la recuperación en k.
B
modelo de referencia
Un modelo que se usa como punto de referencia para comparar el rendimiento de otro modelo (por lo general, uno más complejo). Por ejemplo, un modelo de regresión logística podría servir como un buen modelo de referencia para un modelo profundo.
Para un problema en particular, el modelo de referencia ayuda a los desarrolladores a cuantificar el rendimiento mínimo esperado que debe alcanzar un modelo nuevo para que sea útil.
Preguntas booleanas (BoolQ)
Es un conjunto de datos para evaluar la competencia de un LLM a la hora de responder preguntas de sí o no. Cada uno de los desafíos del conjunto de datos tiene tres componentes:
- Una consulta
- Es un pasaje que implica la respuesta a la búsqueda.
- La respuesta correcta, que es sí o no.
Por ejemplo:
- Pregunta: ¿Hay alguna planta de energía nuclear en Michigan?
- Pasaje: …tres centrales nucleares suministran a Michigan alrededor del 30% de su electricidad.
- Respuesta correcta: Sí
Los investigadores recopilaron las preguntas de las búsquedas agregadas y anonimizadas de la Búsqueda de Google y, luego, usaron las páginas de Wikipedia para fundamentar la información.
Para obtener más información, consulta BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.
BoolQ es un componente del conjunto de SuperGLUE.
BoolQ
Abreviatura de Preguntas booleanas.
C
CB
Abreviatura de CommitmentBank.
Puntuación F de n-gramas de caracteres (ChrF)
Es una métrica para evaluar los modelos de traducción automática. La puntuación F de n-gramas de caracteres determina el grado en que los n-gramas en el texto de referencia se superponen con los n-gramas en el texto generado de un modelo de AA.
La puntuación F de n-gramas de caracteres es similar a las métricas de las familias ROUGE y BLEU, excepto que:
- La puntuación F de N-gramas de caracteres opera en N-gramas de caracteres.
- ROUGE y BLEU operan en N-gramas de palabras o tokens.
Elección de alternativas plausibles (COPA)
Es un conjunto de datos para evaluar qué tan bien un LLM puede identificar la mejor de dos respuestas alternativas a una premisa. Cada uno de los desafíos del conjunto de datos consta de tres componentes:
- Una premisa, que suele ser una afirmación seguida de una pregunta
- Dos respuestas posibles a la pregunta planteada en la premisa, una de las cuales es correcta y la otra incorrecta
- La respuesta correcta
Por ejemplo:
- Premisa: El hombre se quebró el dedo del pie. ¿Cuál fue la CAUSA de este problema?
- Respuestas posibles:
- Se le hizo un agujero en el calcetín.
- Se le cayó un martillo en el pie.
- Respuesta correcta: 2
COPA es un componente del conjunto de SuperGLUE.
CommitmentBank (CB)
Es un conjunto de datos para evaluar la competencia de un LLM a la hora de determinar si el autor de un pasaje cree en una cláusula objetivo dentro de ese pasaje. Cada entrada del conjunto de datos contiene lo siguiente:
- Un pasaje
- Una cláusula de destino dentro de ese pasaje
- Es un valor booleano que indica si el autor del pasaje cree que la cláusula objetivo
Por ejemplo:
- Pasaje: Qué divertido escuchar la risa de Artemisa. Es una niña muy seria. No sabía que tenía sentido del humor.
- Cláusula objetivo: Tenía sentido del humor.
- Booleano: Verdadero, lo que significa que el autor cree que la cláusula objetivo
CommitmentBank es un componente del conjunto de SuperGLUE.
COPA
Abreviatura de Choice of Plausible Alternatives.
costo
Sinónimo de pérdida.
Equidad contrafáctica
Es una métrica de equidad que verifica si un modelo de clasificación produce el mismo resultado para una persona que para otra idéntica a la primera, excepto en lo que respecta a uno o más atributos sensibles. Evaluar un modelo de clasificación para la equidad contrafáctica es un método para identificar posibles fuentes de sesgo en un modelo.
Consulta cualquiera de los siguientes vínculos para obtener más información:
- Equidad: Equidad contrafáctica en el Curso intensivo de aprendizaje automático.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness (Cuando los mundos chocan: Integración de diferentes suposiciones contrafácticas en la equidad)
entropía cruzada
Es una generalización de la pérdida de registro para problemas de clasificación de clases múltiples. La entropía cruzada cuantifica la diferencia entre dos distribuciones de probabilidad. Consulta también perplejidad.
Función de distribución acumulativa (FDA)
Es una función que define la frecuencia de las muestras menores o iguales que un valor objetivo. Por ejemplo, considera una distribución normal de valores continuos. Una CDF indica que, aproximadamente, el 50% de las muestras debe ser menor o igual que la media, y que, aproximadamente, el 84% de las muestras debe ser menor o igual que una desviación estándar por encima de la media.
D
Paridad demográfica
Es una métrica de equidad que se cumple si los resultados de la clasificación de un modelo no dependen de un atributo sensible determinado.
Por ejemplo, si tanto los liliputienses como los brobdingnagianos postulan a la Universidad de Glubbdubdrib, se logra la paridad demográfica si el porcentaje de liliputienses admitidos es el mismo que el porcentaje de brobdingnagianos admitidos, independientemente de si un grupo está, en promedio, más calificado que el otro.
Contrasta con la igualdad de probabilidades y la igualdad de oportunidades, que permiten que los resultados de la clasificación en conjunto dependan de atributos sensibles, pero no permiten que los resultados de la clasificación para ciertas etiquetas de verdad fundamental especificadas dependan de atributos sensibles. Consulta "Cómo combatir la discriminación con un aprendizaje automático más inteligente" para ver una visualización que explora las compensaciones cuando se optimiza la paridad demográfica.
Consulta Equidad: paridad demográfica en el Curso intensivo de aprendizaje automático para obtener más información.
E
Distancia de Earth Mover (EMD)
Es una medida de la similitud relativa de dos distribuciones. Cuanto menor sea la distancia de movimiento de tierra, más similares serán las distribuciones.
Distancia de edición
Es una medición de la similitud entre dos cadenas de texto. En el aprendizaje automático, la distancia de edición es útil por los siguientes motivos:
- La distancia de edición es fácil de calcular.
- La distancia de edición puede comparar dos cadenas que se sabe que son similares entre sí.
- La distancia de edición puede determinar el grado en que diferentes cadenas son similares a una cadena determinada.
Existen varias definiciones de distancia de edición, cada una con diferentes operaciones de cadenas. Consulta Distancia de Levenshtein para ver un ejemplo.
función de distribución acumulativa empírica (eCDF o EDF)
Es una función de distribución acumulativa basada en mediciones empíricas de un conjunto de datos real. El valor de la función en cualquier punto a lo largo del eje X es la fracción de observaciones en el conjunto de datos que son menores o iguales que el valor especificado.
entropía
En la teoría de la información, es una descripción de qué tan impredecible es una distribución de probabilidad. Como alternativa, la entropía también se define como la cantidad de información que contiene cada ejemplo. Una distribución tiene la mayor entropía posible cuando todos los valores de una variable aleatoria son igualmente probables.
La entropía de un conjunto con dos valores posibles "0" y "1" (por ejemplo, las etiquetas en un problema de clasificación binaria) tiene la siguiente fórmula:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
Donde:
- H es la entropía.
- p es la fracción de ejemplos de "1".
- q es la fracción de ejemplos "0". Ten en cuenta que q = (1 - p).
- log suele ser log2. En este caso, la unidad de entropía es un bit.
Por ejemplo, supongamos lo siguiente:
- 100 ejemplos contienen el valor "1".
- 300 ejemplos contienen el valor "0".
Por lo tanto, el valor de la entropía es el siguiente:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 bits por ejemplo
Un conjunto perfectamente equilibrado (por ejemplo, 200 "0" y 200 "1") tendría una entropía de 1.0 bits por ejemplo. A medida que un conjunto se vuelve más desequilibrado, su entropía se acerca a 0.0.
En los árboles de decisión, la entropía ayuda a formular la ganancia de información para ayudar al divisor a seleccionar las condiciones durante el crecimiento de un árbol de decisión de clasificación.
Compara la entropía con lo siguiente:
- impureza de Gini
- Función de pérdida de entropía cruzada
A menudo, la entropía se denomina entropía de Shannon.
Consulta Divisor exacto para la clasificación binaria con características numéricas en el curso de Bosques de decisión para obtener más información.
Igualdad de oportunidades
Es una métrica de equidad para evaluar si un modelo predice el resultado deseado con la misma precisión para todos los valores de un atributo sensible. En otras palabras, si el resultado deseable para un modelo es la clase positiva, el objetivo sería que la tasa de verdaderos positivos sea la misma para todos los grupos.
La igualdad de oportunidades se relaciona con la igualdad de probabilidades, que requiere que tanto las tasas de verdaderos positivos como las tasas de falsos positivos sean las mismas para todos los grupos.
Supongamos que la Universidad de Glubbdubdrib admite tanto a liliputienses como a brobdingnagianos en un programa riguroso de matemáticas. Las escuelas secundarias de Lilliput ofrecen un plan de estudios sólido de clases de matemáticas, y la gran mayoría de los estudiantes están calificados para el programa universitario. Las escuelas secundarias de Brobdingnag no ofrecen clases de matemáticas, por lo que muchos menos estudiantes están calificados. La igualdad de oportunidades se satisface para la etiqueta preferida de "admitido" con respecto a la nacionalidad (liliputiense o brobdingnagiana) si los estudiantes calificados tienen la misma probabilidad de ser admitidos, independientemente de si son liliputienses o brobdingnagianos.
Por ejemplo, supongamos que 100 liliputienses y 100 brobdingnagianos solicitan ingresar a la Universidad de Glubbdubdrib, y las decisiones de admisión se toman de la siguiente manera:
Tabla 1: Solicitantes de Lilliputian (el 90% cumple con los requisitos)
| Calificado | No cumple con los requisitos | |
|---|---|---|
| Admitida | 45 | 3 |
| Rechazado | 45 | 7 |
| Total | 90 | 10 |
|
Porcentaje de estudiantes calificados admitidos: 45/90 = 50% Porcentaje de estudiantes no calificados rechazados: 7/10 = 70% Porcentaje total de estudiantes de Lilliput admitidos: (45 + 3)/100 = 48% |
||
Tabla 2: Solicitantes brobdingnagianos (el 10% está calificado):
| Calificado | No cumple con los requisitos | |
|---|---|---|
| Admitida | 5 | 9 |
| Rechazado | 5 | 81 |
| Total | 10 | 90 |
|
Porcentaje de estudiantes calificados admitidos: 5/10 = 50% Porcentaje de estudiantes no calificados rechazados: 81/90 = 90% Porcentaje total de estudiantes de Brobdingnag admitidos: (5 + 9)/100 = 14% |
||
Los ejemplos anteriores satisfacen la igualdad de oportunidades para la aceptación de estudiantes calificados, ya que tanto los liliputienses como los brobdingnagianos calificados tienen un 50% de probabilidades de ser admitidos.
Si bien se satisface la igualdad de oportunidades, no se satisfacen las siguientes dos métricas de equidad:
- Paridad demográfica: Los liliputienses y los brobdingnagianos son admitidos en la universidad en diferentes proporciones: el 48% de los estudiantes liliputienses son admitidos, pero solo el 14% de los estudiantes brobdingnagianos.
- Probabilidades ecualizadas: Si bien los estudiantes calificados de Lilliput y Brobdingnag tienen la misma probabilidad de ser admitidos, no se cumple la restricción adicional de que los estudiantes no calificados de Lilliput y Brobdingnag tengan la misma probabilidad de ser rechazados. Los liliputienses no calificados tienen una tasa de rechazo del 70%, mientras que los brobdingnagianos no calificados tienen una tasa de rechazo del 90%.
Consulta Equidad: Igualdad de oportunidades en el Curso intensivo de aprendizaje automático para obtener más información.
Probabilidades ecualizadas
Es una métrica de equidad para evaluar si un modelo predice resultados con la misma precisión para todos los valores de un atributo sensible con respecto a la clase positiva y la clase negativa, no solo una clase o la otra de forma exclusiva. En otras palabras, tanto la tasa de verdaderos positivos como la tasa de falsos negativos deben ser iguales para todos los grupos.
La métrica de probabilidades igualadas se relaciona con la igualdad de oportunidades, que solo se enfoca en las tasas de error para una sola clase (positiva o negativa).
Por ejemplo, supongamos que la Universidad de Glubbdubdrib admite tanto a liliputienses como a brobdingnagianos en un riguroso programa de matemáticas. Las escuelas secundarias de Lilliput ofrecen un plan de estudios sólido de clases de matemáticas, y la gran mayoría de los estudiantes están calificados para el programa universitario. Las escuelas secundarias de Brobdingnag no ofrecen clases de matemáticas, por lo que muchos menos estudiantes están calificados. Se satisfacen las probabilidades igualadas siempre que, sin importar si un solicitante es liliputiense o brobdingnagiano, si está calificado, es igualmente probable que sea admitido en el programa y, si no está calificado, es igualmente probable que sea rechazado.
Supongamos que 100 liliputienses y 100 brobdingnagianos solicitan ingresar a la Universidad de Glubbdubdrib, y las decisiones de admisión se toman de la siguiente manera:
Tabla 3: Solicitantes de Lilliputian (el 90% cumple con los requisitos)
| Calificado | No cumple con los requisitos | |
|---|---|---|
| Admitida | 45 | 2 |
| Rechazado | 45 | 8 |
| Total | 90 | 10 |
|
Porcentaje de estudiantes calificados admitidos: 45/90 = 50% Porcentaje de estudiantes no calificados rechazados: 8/10 = 80% Porcentaje total de estudiantes de Lilliput admitidos: (45 + 2)/100 = 47% |
||
Tabla 4. Solicitantes brobdingnagianos (el 10% está calificado):
| Calificado | No cumple con los requisitos | |
|---|---|---|
| Admitida | 5 | 18 |
| Rechazado | 5 | 72 |
| Total | 10 | 90 |
|
Porcentaje de estudiantes calificados admitidos: 5/10 = 50% Porcentaje de estudiantes no calificados rechazados: 72/90 = 80% Porcentaje total de estudiantes de Brobdingnag admitidos: (5 + 18)/100 = 23% |
||
Se cumple la igualdad de probabilidades porque los estudiantes calificados de Liliput y Brobdingnag tienen un 50% de probabilidades de ser admitidos, y los estudiantes no calificados de Liliput y Brobdingnag tienen un 80% de probabilidades de ser rechazados.
Los estudiantes liliputienses y brobdingnagianos son admitidos en la Universidad de Glubbdubdrib en diferentes proporciones: el 47% de los estudiantes liliputienses son admitidos, y el 23% de los estudiantes brobdingnagianos son admitidos.La igualdad de probabilidades se define formalmente en "Equality of Opportunity in Supervised Learning" de la siguiente manera: "El predictor Ŷ satisface la igualdad de probabilidades con respecto al atributo protegido A y el resultado Y si Ŷ y A son independientes, condicionales a Y".
evals
Se usa principalmente como abreviatura de evaluaciones de LLM. En términos más generales, evals es la abreviatura de cualquier forma de evaluación.
sin conexión
Proceso para medir la calidad de un modelo o comparar diferentes modelos entre sí.
Para evaluar un modelo de aprendizaje automático supervisado, por lo general, lo comparas con un conjunto de validación y un conjunto de prueba. Evaluar un LLM suele implicar evaluaciones más amplias de calidad y seguridad.
concordancia exacta
Es una métrica de todo o nada en la que el resultado del modelo coincide con la verdad fundamental o el texto de referencia de forma exacta, o no coincide. Por ejemplo, si la verdad fundamental es naranja, el único resultado del modelo que satisface la concordancia exacta es naranja.
La concordancia exacta también puede evaluar modelos cuya salida es una secuencia (una lista de elementos clasificados). En general, la coincidencia exacta requiere que la lista clasificada generada coincida exactamente con la verdad fundamental, es decir, cada elemento de ambas listas debe estar en el mismo orden. Dicho esto, si la verdad fundamental consta de varias secuencias correctas, la concordancia exacta solo requiere que la salida del modelo coincida con una de las secuencias correctas.
Resumen extremo (xsum)
Es un conjunto de datos para evaluar la capacidad de un LLM de resumir un solo documento. Cada entrada del conjunto de datos consta de lo siguiente:
- Documento creado por la British Broadcasting Corporation (BBC).
- Un resumen de ese documento en una oración.
Para obtener más información, consulta Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization.
F
F1
Es una métrica de clasificación binaria "acumulada" que se basa en la precisión y la recuperación. Esta es la fórmula:
métrica de equidad
Una definición matemática de "equidad" que se pueda medir Algunas métricas de equidad de uso común incluyen las siguientes:
Muchas métricas de equidad son mutuamente excluyentes. Consulta la incompatibilidad de métricas de equidad.
falso negativo (FN)
Ejemplo en el que el modelo predice de manera incorrecta la clase negativa. Por ejemplo, el modelo predice que un mensaje de correo electrónico en particular no es spam (la clase negativa), pero ese mensaje de correo electrónico en realidad sí es spam.
tasa de falsos negativos
Proporción de ejemplos positivos reales para los que el modelo predijo erróneamente la clase negativa. La siguiente fórmula calcula la tasa de falsos negativos:
Para obtener más información, consulta Umbrales y la matriz de confusión en el Curso intensivo de aprendizaje automático.
Falso positivo (FP)
Ejemplo en el que el modelo predice de manera incorrecta la clase positiva. Por ejemplo, el modelo predice que un mensaje de correo electrónico en particular es spam (la clase positiva), pero ese mensaje de correo electrónico en realidad no es spam.
Para obtener más información, consulta Umbrales y la matriz de confusión en el Curso intensivo de aprendizaje automático.
tasa de falsos positivos (FPR)
Proporción de ejemplos negativos reales para los que el modelo predijo erróneamente la clase positiva. La siguiente fórmula calcula la tasa de falsos positivos:
La tasa de falsos positivos es el eje X en una curva ROC.
Para obtener más información, consulta Clasificación: ROC y AUC en el Curso intensivo de aprendizaje automático.
Importancia de los atributos
Sinónimo de importancia de las variables.
modelo de base
Un modelo previamente entrenado muy grande entrenado con un conjunto de entrenamiento enorme y diverso. Un modelo de base puede hacer lo siguiente:
- Responder bien a una amplia variedad de solicitudes
- Sirve como un modelo base para ajustes adicionales o cualquier otra personalización.
En otras palabras, un modelo de base ya es muy capaz en un sentido general, pero se puede personalizar aún más para que sea más útil para una tarea específica.
fracción de éxitos
Es una métrica para evaluar el texto generado de un modelo de AA. La fracción de éxitos es la cantidad de resultados de texto generados "correctos" dividida por la cantidad total de resultados de texto generados. Por ejemplo, si un modelo de lenguaje grande generó 10 bloques de código, de los cuales cinco fueron exitosos, la fracción de éxitos sería del 50%.
Si bien la fracción de éxitos es útil en general en todas las estadísticas, en el AA, esta métrica es principalmente útil para medir tareas verificables, como la generación de código o los problemas matemáticos.
G
Impureza de Gini
Es una métrica similar a la entropía. Los divisores usan valores derivados de la impureza de Gini o la entropía para componer condiciones para los árboles de decisión de clasificación. La ganancia de información se deriva de la entropía. No existe un término equivalente aceptado universalmente para la métrica derivada de la impureza de Gini. Sin embargo, esta métrica sin nombre es tan importante como la ganancia de información.
La impureza de Gini también se denomina índice de Gini o, simplemente, Gini.
H
Pérdida de bisagra
Es una familia de funciones de pérdida para la clasificación diseñadas para encontrar el límite de decisión lo más distante posible de cada ejemplo de entrenamiento, para así maximizar el margen entre los ejemplos y el límite. Las KSVM usan la pérdida de bisagra (o una función relacionada, como la pérdida de bisagra al cuadrado). Para la clasificación binaria, la función de pérdida de bisagra se define de la siguiente manera:
donde y es la etiqueta verdadera, ya sea -1 o +1, y y' es el resultado sin procesar del modelo de clasificación:
En consecuencia, un gráfico de la pérdida de bisagra en comparación con (y * y') se ve de la siguiente manera:

I
Incompatibilidad de métricas de equidad
La idea de que algunas nociones de equidad son mutuamente incompatibles y no se pueden satisfacer de manera simultánea. Como resultado, no existe una sola métrica universal para cuantificar la equidad que se pueda aplicar a todos los problemas de AA.
Si bien esto puede parecer desalentador, la incompatibilidad de las métricas de equidad no implica que los esfuerzos por lograr la equidad sean infructuosos. En cambio, sugiere que la equidad debe definirse de forma contextual para un problema de AA determinado, con el objetivo de evitar los daños específicos de sus casos de uso.
Consulta "On the (im)possibility of fairness" para obtener un análisis más detallado sobre la incompatibilidad de las métricas de equidad.
Equidad individual
Es una métrica de equidad que verifica si las personas similares se clasifican de manera similar. Por ejemplo, la Academia Brobdingnagian podría querer satisfacer la equidad individual garantizando que dos estudiantes con calificaciones idénticas y resultados de pruebas estandarizadas tengan la misma probabilidad de ser admitidos.
Ten en cuenta que la equidad individual depende por completo de cómo definas la "similitud" (en este caso, las calificaciones y los resultados de las pruebas), y puedes correr el riesgo de introducir nuevos problemas de equidad si tu métrica de similitud omite información importante (como el rigor del plan de estudios de un estudiante).
Consulta "Fairness Through Awareness" para obtener un análisis más detallado de la equidad individual.
Ganancia de información
En los bosques de decisión, es la diferencia entre la entropía de un nodo y la suma ponderada (según la cantidad de ejemplos) de la entropía de sus nodos secundarios. La entropía de un nodo es la entropía de los ejemplos en ese nodo.
Por ejemplo, considera los siguientes valores de entropía:
- entropía del nodo superior = 0.6
- entropía de un nodo secundario con 16 ejemplos relevantes = 0.2
- entropía de otro nodo secundario con 24 ejemplos relevantes = 0.1
Por lo tanto, el 40% de los ejemplos se encuentran en un nodo secundario y el 60% en el otro. Por lo tanto:
- Suma de entropía ponderada de los nodos secundarios = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
Por lo tanto, la ganancia de información es la siguiente:
- Ganancia de información = Entropía del nodo principal - Suma ponderada de la entropía de los nodos secundarios
- ganancia de información = 0.6 - 0.14 = 0.46
La mayoría de los divisores buscan crear condiciones que maximicen la ganancia de información.
Acuerdo entre evaluadores
Es una medición de la frecuencia con la que los evaluadores humanos coinciden cuando realizan una tarea. Si los evaluadores no están de acuerdo, es posible que deban mejorarse las instrucciones de la tarea. En algunas ocasiones, también se denomina acuerdo entre anotadores o fiabilidad entre evaluadores. Consulta también el coeficiente kappa de Cohen, que es una de las mediciones de acuerdo entre evaluadores más populares.
Consulta Datos categóricos: Problemas comunes en el Curso intensivo de aprendizaje automático para obtener más información.
L
Pérdida L1
Una función de pérdida que calcula el valor absoluto de la diferencia entre los valores de la etiqueta real y los valores que predice un modelo. Por ejemplo, aquí se muestra el cálculo de la pérdida L1 para un lote de cinco ejemplos:
| Valor real del ejemplo | Valor predicho del modelo | Valor absoluto del delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = pérdida L1 | ||
La pérdida L1 es menos sensible a los valores atípicos que la pérdida L2.
El error absoluto medio es la pérdida promedio de L1 por ejemplo.
Consulta Regresión lineal: Pérdida en el Curso intensivo de aprendizaje automático para obtener más información.
Pérdida L2
Es una función de pérdida que calcula el cuadrado de la diferencia entre los valores de la etiqueta real y los valores que predice un modelo. Por ejemplo, aquí se muestra el cálculo de la pérdida de L2 para un lote de cinco ejemplos:
| Valor real del ejemplo | Valor predicho del modelo | Cuadrado de delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = pérdida L2 | ||
Debido al componente cuadrático, la pérdida L2 amplifica la influencia de los valores atípicos. Es decir, la pérdida L2 reacciona de manera más severa a las predicciones incorrectas que la pérdida L1. Por ejemplo, la pérdida L1 para el lote anterior sería de 8 en lugar de 16. Ten en cuenta que un solo valor atípico representa 9 de los 16.
Los modelos de regresión suelen usar la pérdida L2 como función de pérdida.
El error cuadrático medio es la pérdida L2 promedio por ejemplo. La pérdida al cuadrado es otro nombre para la pérdida L2.
Para obtener más información, consulta Regresión logística: Pérdida y regularización en el Curso intensivo de aprendizaje automático.
Evaluaciones de LLM
Es un conjunto de métricas y comparativas para evaluar el rendimiento de los modelos de lenguaje grandes (LLM). A un alto nivel, las evaluaciones de LLM hacen lo siguiente:
- Ayudar a los investigadores a identificar áreas en las que los LLM necesitan mejorar
- Son útiles para comparar diferentes LLM y determinar el mejor LLM para una tarea en particular.
- Ayudar a garantizar que los LLM sean seguros y éticos para su uso
Consulta Modelos de lenguaje extenso (LLM) en el Curso intensivo de aprendizaje automático para obtener más información.
pérdida
Durante el entrenamiento de un modelo supervisado, se calcula una medida de qué tan lejos está la predicción de un modelo de su etiqueta.
Una función de pérdida calcula la pérdida.
Consulta Regresión lineal: Pérdida en el Curso intensivo de aprendizaje automático para obtener más información.
función de pérdida
Durante el entrenamiento o las pruebas, es una función matemática que calcula la pérdida en un lote de ejemplos. Una función de pérdida devuelve una pérdida menor para los modelos que realizan buenas predicciones que para los modelos que realizan predicciones deficientes.
Por lo general, el objetivo del entrenamiento es minimizar la pérdida que devuelve una función de pérdida.
Existen muchos tipos diferentes de funciones de pérdida. Elige la función de pérdida adecuada para el tipo de modelo que estás creando. Por ejemplo:
- La pérdida L2 (o error cuadrático medio) es la función de pérdida para la regresión lineal.
- La pérdida logística es la función de pérdida para la regresión logística.
M
MBPP
Abreviatura de Problemas de Python principalmente básicos.
Error absoluto medio (MAE)
Es la pérdida promedio por ejemplo cuando se usa la pérdida de L1. Calcula el error absoluto medio de la siguiente manera:
- Calcula la pérdida L1 para un lote.
- Divide la pérdida de L1 por la cantidad de ejemplos del lote.
Por ejemplo, considera el cálculo de la pérdida de L1 en el siguiente lote de cinco ejemplos:
| Valor real del ejemplo | Valor predicho del modelo | Pérdida (diferencia entre el valor real y el predicho) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = pérdida L1 | ||
Por lo tanto, la pérdida L1 es 8 y la cantidad de ejemplos es 5. Por lo tanto, el error absoluto medio es el siguiente:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Compara el error absoluto medio con el error cuadrático medio y la raíz cuadrada del error cuadrático medio.
Precisión media en k (mAP@k)
Es la media estadística de todas las puntuaciones de precisión promedio en k en un conjunto de datos de validación. Un uso de la precisión media promedio en k es evaluar la calidad de las recomendaciones que genera un sistema de recomendación.
Aunque la frase "promedio medio" suena redundante, el nombre de la métrica es apropiado. Después de todo, esta métrica encuentra la media de varios valores de precisión promedio en k.
Error cuadrático medio (ECM)
Es la pérdida promedio por ejemplo cuando se usa la pérdida L2. Calcula el error cuadrático medio de la siguiente manera:
- Calcula la pérdida L2 para un lote.
- Divide la pérdida L2 por la cantidad de ejemplos del lote.
Por ejemplo, considera la pérdida en el siguiente lote de cinco ejemplos:
| Valor real | Predicción del modelo | Pérdida | Pérdida al cuadrado |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = pérdida L2 | |||
Por lo tanto, el error cuadrático medio es el siguiente:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
El error cuadrático medio es un optimizador de entrenamiento popular, en especial para la regresión lineal.
Compara el error cuadrático medio con el error absoluto medio y la raíz cuadrada del error cuadrático medio.
TensorFlow Playground usa el error cuadrático medio para calcular los valores de pérdida.
métrica
Es una estadística que te interesa.
Un objetivo es una métrica que un sistema de aprendizaje automático intenta optimizar.
API de Metrics (tf.metrics)
Es una API de TensorFlow para evaluar modelos. Por ejemplo, tf.metrics.accuracy determina con qué frecuencia las predicciones de un modelo coinciden con las etiquetas.
Pérdida de minimax
Es una función de pérdida para las redes generativas adversarias, basada en la entropía cruzada entre la distribución de los datos generados y los datos reales.
La pérdida de Minimax se usa en el primer artículo para describir las redes adversarias generativas.
Consulta Funciones de pérdida en el curso de Redes Adversarias Generativas para obtener más información.
capacidad del modelo
Es la complejidad de los problemas que un modelo puede aprender. Mientras más complejos sean los problemas que un modelo puede aprender, mayor será la capacidad del modelo. La capacidad de un modelo generalmente aumenta con la cantidad de parámetros del modelo. Para obtener una definición formal de la capacidad de un modelo de clasificación, consulta Dimensión VC.
Mostly Basic Python Problems (MBPP)
Es un conjunto de datos para evaluar la competencia de un LLM en la generación de código de Python. Mostly Basic Python Problems proporciona alrededor de 1,000 problemas de programación obtenidos de fuentes externas. Cada problema del conjunto de datos contiene lo siguiente:
- Una descripción de la tarea
- Código de solución
- Tres casos de prueba automatizados
N
clase negativa
En la clasificación binaria, una clase se denomina positiva y la otra, negativa. La clase positiva es el elemento o evento que el modelo está probando, y la clase negativa es la otra posibilidad. Por ejemplo:
- La clase negativa en una prueba médica puede ser "no es un tumor".
- La clase negativa en un modelo de clasificación de correos electrónicos podría ser "no es spam".
Compara esto con la clase positiva.
O
objetivo
Es una métrica que tu algoritmo intenta optimizar.
función objetivo
Es la fórmula matemática o la métrica que un modelo intenta optimizar. Por ejemplo, la función objetivo para la regresión lineal suele ser la pérdida cuadrática media. Por lo tanto, cuando se entrena un modelo de regresión lineal, el objetivo es minimizar la pérdida cuadrática media.
En algunos casos, el objetivo es maximizar la función objetivo. Por ejemplo, si la función objetivo es la precisión, el objetivo es maximizar la precisión.
Consulta también pérdida.
P
Pase en k (pass@k)
Es una métrica para determinar la calidad del código (por ejemplo, Python) que genera un modelo de lenguaje grande. Más específicamente, Pass at k te indica la probabilidad de que al menos un bloque de código generado de los k bloques de código generados pase todas sus pruebas de unidades.
Los modelos de lenguaje grandes suelen tener dificultades para generar código adecuado para problemas de programación complejos. Los ingenieros de software se adaptan a este problema solicitando al modelo de lenguaje grande que genere varias (k) soluciones para el mismo problema. Luego, los ingenieros de software prueban cada una de las soluciones con pruebas de unidades. El cálculo de la aprobación en k depende del resultado de las pruebas de unidades:
- Si una o más de esas soluciones pasan la prueba de unidades, el LLM aprueba ese desafío de generación de código.
- Si ninguna de las soluciones pasa la prueba de unidades, el LLM falla en ese desafío de generación de código.
La fórmula para el pase en k es la siguiente:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
En general, los valores más altos de k producen puntuaciones más altas de aprobación en k; sin embargo, los valores más altos de k requieren más recursos de modelos grandes de lenguaje y pruebas de unidades.
rendimiento
Término sobrecargado con los siguientes significados:
- El significado estándar dentro de la ingeniería de software. Es decir, ¿qué tan rápidamente (o eficazmente) se ejecuta este software?
- El significado en el aprendizaje automático. Aquí, el rendimiento responde a la siguiente pregunta: ¿Qué tan correcto es este modelo? Es decir, ¿qué tan buenas son las predicciones del modelo?
Importancia de las variables por permutación
Es un tipo de importancia de la variable que evalúa el aumento en el error de predicción de un modelo después de permutar los valores del atributo. La importancia de las variables de permutación es una métrica independiente del modelo.
perplejidad
Medición de qué tan bien está logrando su tarea el modelo. Por ejemplo, supongamos que tu tarea es leer las primeras letras de una palabra que un usuario está escribiendo en el teclado de un teléfono y ofrecer una lista de posibles palabras para completar. La perplejidad, P, para esta tarea es aproximadamente la cantidad de suposiciones que debes ofrecer para que tu lista contenga la palabra real que el usuario intenta escribir.
La perplejidad está relacionada con la entropía cruzada de la siguiente manera:
clase positiva
Es la clase para la que realizas la prueba.
Por ejemplo, la clase positiva en un modelo de cáncer podría ser "tumor". La clase positiva en un modelo de clasificación de correos electrónicos puede ser "spam".
Compara esto con la clase negativa.
PR AUC (área bajo la curva de PR)
Es el área bajo la curva de precisión-recuperación interpolada, que se obtiene trazando los puntos (recuperación, precisión) para diferentes valores del umbral de clasificación.
precision
Es una métrica para los modelos de clasificación que responde la siguiente pregunta:
Cuando el modelo predijo la clase positiva, ¿qué porcentaje de las predicciones fueron correctas?
Esta es la fórmula:
Donde:
- Un verdadero positivo significa que el modelo predijo correctamente la clase positiva.
- Un falso positivo significa que el modelo predijo erróneamente la clase positiva.
Por ejemplo, supongamos que un modelo realizó 200 predicciones positivas. De estas 200 predicciones positivas, se obtuvieron los siguientes resultados:
- 150 fueron verdaderos positivos.
- 50 fueron falsos positivos.
En este caso, ocurre lo siguiente:
Compara esto con la exactitud y la recuperación.
Consulta Clasificación: Precisión, recuperación, exactitud y métricas relacionadas en el Curso intensivo de aprendizaje automático para obtener más información.
Precisión en k (precision@k)
Es una métrica para evaluar una lista de elementos clasificados (ordenados). La precisión en k identifica la fracción de los primeros k elementos de esa lista que son "relevantes". Es decir:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
El valor de k debe ser menor o igual que la longitud de la lista que se muestra. Ten en cuenta que la longitud de la lista devuelta no forma parte del cálculo.
La relevancia suele ser subjetiva. Incluso los evaluadores humanos expertos suelen no estar de acuerdo sobre qué elementos son relevantes.
Comparar con:
curva de precisión-recuperación
Curva de precisión en función de la recuperación en diferentes umbrales de clasificación.
sesgo de predicción
Es un valor que indica qué tan lejos está el promedio de las predicciones del promedio de las etiquetas en el conjunto de datos.
No se debe confundir con el término de sesgo en los modelos de aprendizaje automático ni con el sesgo en la ética y la equidad.
Paridad predictiva
Es una métrica de equidad que verifica si, para un modelo de clasificación determinado, las tasas de precisión son equivalentes para los subgrupos en consideración.
Por ejemplo, un modelo que predice la aceptación en la universidad satisfaría la paridad predictiva para la nacionalidad si su tasa de precisión es la misma para los liliputienses y los brobdingnagianos.
A veces, la paridad predictiva también se denomina paridad de la tasa predictiva.
Consulta "Explicación de las definiciones de equidad" (sección 3.2.1) para obtener un análisis más detallado de la paridad predictiva.
Paridad de tarifas predictiva
Otro nombre para la paridad predictiva.
función de densidad de probabilidad
Es una función que identifica la frecuencia con la que las muestras de datos tienen exactamente un valor determinado. Cuando los valores de un conjunto de datos son números de punto flotante continuos, rara vez se producen coincidencias exactas. Sin embargo, integrar una función de densidad de probabilidad desde el valor x hasta el valor y produce la frecuencia esperada de las muestras de datos entre x y y.
Por ejemplo, considera una distribución normal con una media de 200 y una desviación estándar de 30. Para determinar la frecuencia esperada de las muestras de datos que se encuentran dentro del rango de 211.4 a 218.7, puedes integrar la función de densidad de probabilidad para una distribución normal de 211.4 a 218.7.
R
Conjunto de datos de comprensión de lectura con razonamiento de sentido común (ReCoRD)
Es un conjunto de datos para evaluar la capacidad de un LLM de realizar razonamiento de sentido común. Cada ejemplo del conjunto de datos contiene tres componentes:
- Un párrafo o dos de un artículo de noticias
- Es una búsqueda en la que una de las entidades identificadas de forma explícita o implícita en el pasaje está enmascarada.
- La respuesta (el nombre de la entidad que pertenece a la máscara)
Consulta ReCoRD para ver una lista extensa de ejemplos.
ReCoRD es un componente del conjunto de SuperGLUE.
RealToxicityPrompts
Es un conjunto de datos que contiene un conjunto de inicios de oraciones que podrían incluir contenido tóxico. Usa este conjunto de datos para evaluar la capacidad de un LLM de generar texto no tóxico para completar la oración. Por lo general, se usa la API de Perspective para determinar qué tan bien se desempeñó el LLM en esta tarea.
Consulta RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models para obtener más detalles.
recall
Es una métrica para los modelos de clasificación que responde la siguiente pregunta:
Cuando la verdad fundamental era la clase positiva, ¿qué porcentaje de predicciones identificó correctamente el modelo como la clase positiva?
Esta es la fórmula:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
Donde:
- Un verdadero positivo significa que el modelo predijo correctamente la clase positiva.
- Un falso negativo significa que el modelo predijo erróneamente la clase negativa.
Por ejemplo, supongamos que tu modelo realizó 200 predicciones sobre ejemplos para los que la verdad fundamental era la clase positiva. De estas 200 predicciones, se cumplen las siguientes:
- 180 fueron verdaderos positivos.
- 20 fueron falsos negativos.
En este caso, ocurre lo siguiente:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Consulta Clasificación: Métricas de precisión, recuperación, exactitud y relacionadas para obtener más información.
Recuperación en k (recall@k)
Es una métrica para evaluar sistemas que generan una lista clasificada (ordenada) de elementos. La recuperación en k identifica la fracción de elementos pertinentes en los primeros k elementos de esa lista en relación con la cantidad total de elementos pertinentes devueltos.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Compara esto con la precisión en k.
Reconocimiento de la implicación textual (RTE)
Es un conjunto de datos para evaluar la capacidad de un LLM de determinar si una hipótesis se puede inferir (extraer lógicamente) de un pasaje de texto. Cada ejemplo en una evaluación de RTE consta de tres partes:
- Un pasaje, por lo general, de artículos de noticias o de Wikipedia
- Una hipótesis
- La respuesta correcta, que es una de las siguientes:
- Verdadero, lo que significa que la hipótesis puede deducirse del pasaje
- Falso, lo que significa que la hipótesis no se puede implicar a partir del pasaje
Por ejemplo:
- Texto: El euro es la moneda de la Unión Europea.
- Hipótesis: Francia usa el euro como moneda.
- Implicación: Verdadero, porque Francia forma parte de la Unión Europea.
RTE es un componente del conjunto de SuperGLUE.
ReCoRD
Abreviatura de Reading Comprehension with Commonsense Reasoning Dataset.
Curva ROC (característica operativa del receptor)
Es un gráfico de la tasa de verdaderos positivos en comparación con la tasa de falsos positivos para diferentes umbrales de clasificación en la clasificación binaria.
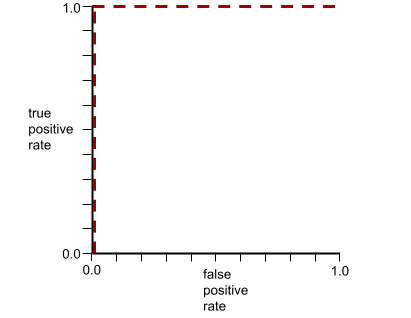
La forma de una curva ROC sugiere la capacidad de un modelo de clasificación binaria para separar las clases positivas de las negativas. Supongamos, por ejemplo, que un modelo de clasificación binaria separa perfectamente todas las clases negativas de todas las clases positivas:
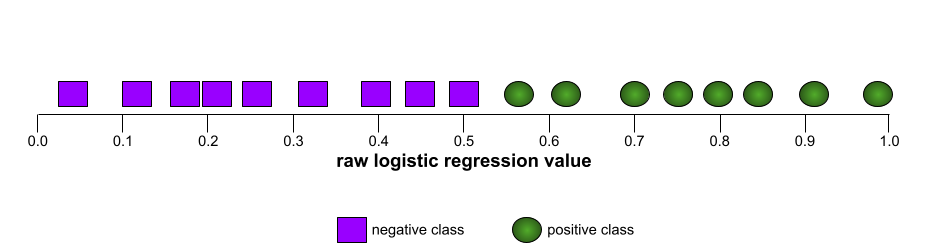
La curva ROC del modelo anterior se ve de la siguiente manera:
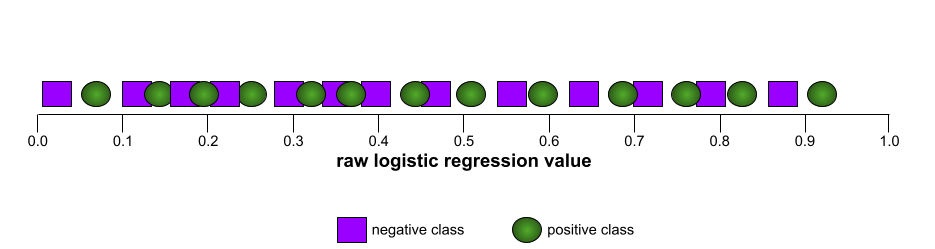
En cambio, en la siguiente ilustración, se grafican los valores de regresión logística sin procesar para un modelo terrible que no puede separar las clases negativas de las positivas:
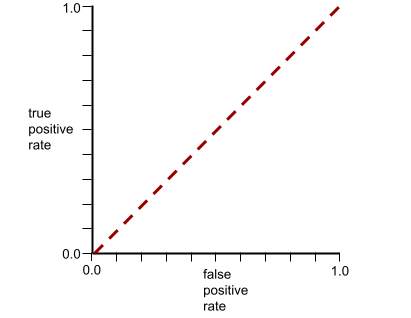
La curva ROC para este modelo se ve de la siguiente manera:
Mientras tanto, en el mundo real, la mayoría de los modelos de clasificación binaria separan las clases positivas y negativas en cierto grado, pero no de forma perfecta. Por lo tanto, una curva ROC típica se encuentra en algún punto entre los dos extremos:
En teoría, el punto de una curva ROC más cercano a (0.0, 1.0) identifica el umbral de clasificación ideal. Sin embargo, varios otros problemas del mundo real influyen en la selección del umbral de clasificación ideal. Por ejemplo, tal vez los falsos negativos causen mucho más dolor que los falsos positivos.
Una métrica numérica llamada AUC resume la curva ROC en un solo valor de punto flotante.
Raíz cuadrada del error cuadrático medio (RMSE)
Raíz cuadrada del error cuadrático medio.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Es una familia de métricas que evalúan los modelos de traducción automática y resumen automático. Las métricas de ROUGE determinan el grado en que un texto de referencia se superpone con el texto generado de un modelo de AA. Cada miembro de la familia ROUGE mide la superposición de una manera diferente. Las puntuaciones ROUGE más altas indican una mayor similitud entre el texto de referencia y el texto generado que las puntuaciones ROUGE más bajas.
Por lo general, cada miembro de la familia ROUGE genera las siguientes métricas:
- Precisión
- Recuperación
- F1
Para obtener detalles y ejemplos, consulta lo siguiente:
ROUGE-L
Es un miembro de la familia ROUGE que se enfoca en la longitud de la subsecuencia común más larga en el texto de referencia y el texto generado. Las siguientes fórmulas calculan la recuperación y la precisión de ROUGE-L:
Luego, puedes usar F1 para combinar la recuperación de ROUGE-L y la precisión de ROUGE-L en una sola métrica:
ROUGE-L ignora los saltos de línea en el texto de referencia y el texto generado, por lo que la subsecuencia común más larga podría abarcar varias oraciones. Cuando el texto de referencia y el texto generado involucran varias oraciones, ROUGE-Lsum, una variación de ROUGE-L, suele ser una mejor métrica. ROUGE-Lsum determina la subsecuencia común más larga para cada oración de un pasaje y, luego, calcula la media de esas subsecuencias comunes más largas.
ROUGE-N
Es un conjunto de métricas dentro de la familia ROUGE que compara los N-gramas compartidos de un tamaño determinado en el texto de referencia y el texto generado. Por ejemplo:
- ROUGE-1 mide la cantidad de tokens compartidos en el texto de referencia y el texto generado.
- ROUGE-2 mide la cantidad de bigramas (2-gramas) compartidos en el texto de referencia y el texto generado.
- ROUGE-3 mide la cantidad de trigramas (3-gramas) compartidos en el texto de referencia y el texto generado.
Puedes usar las siguientes fórmulas para calcular la recuperación de ROUGE-N y la precisión de ROUGE-N para cualquier miembro de la familia de ROUGE-N:
Luego, puedes usar F1 para combinar la recuperación de ROUGE-N y la precisión de ROUGE-N en una sola métrica:
ROUGE-S
Es una forma flexible de ROUGE-N que permite la correlación de skip-gramas. Es decir, ROUGE-N solo cuenta los n-gramas que coinciden exactamente, pero ROUGE-S también cuenta los n-gramas separados por una o más palabras. Por ejemplo, considera lo siguiente:
- Texto de referencia: Nubes blancas
- Texto generado: Nubes blancas y ondulantes
Cuando se calcula ROUGE-N, el 2-grama Nubes blancas no coincide con Nubes blancas y ondulantes. Sin embargo, cuando se calcula ROUGE-S, Nubes blancas sí coincide con Nubes blancas y ondulantes.
R al cuadrado
Es una métrica de regresión que indica qué parte de la variación en una etiqueta se debe a un atributo individual o a un conjunto de atributos. R al cuadrado es un valor entre 0 y 1 que puedes interpretar de la siguiente manera:
- Un R al cuadrado de 0 significa que ninguna variación de la etiqueta se debe al conjunto de atributos.
- Un R al cuadrado de 1 significa que toda la variación de la etiqueta se debe al conjunto de atributos.
- Un R al cuadrado de entre 0 y 1 indica en qué medida la variación de la etiqueta puede predecirse a partir de un atributo en particular o del conjunto de atributos. Por ejemplo, un R al cuadrado de 0.10 significa que el 10% de la varianza en la etiqueta se debe al conjunto de atributos, un R al cuadrado de 0.20 significa que el 20% se debe al conjunto de atributos, y así sucesivamente.
R al cuadrado es el cuadrado del coeficiente de correlación de Pearson entre los valores que predijo un modelo y la verdad fundamental.
RTE
Abreviatura de Recognizing Textual Entailment.
S
puntuación
Es la parte de un sistema de recomendación que proporciona un valor o una clasificación para cada elemento producido por la fase de generación de candidatos.
medida de similitud
En los algoritmos de agrupamiento en clústeres, es la métrica que se usa para determinar qué tan parecidos (cuán similares) son dos ejemplos cualesquiera.
dispersión
Es la cantidad de elementos establecidos en cero (o nulos) en un vector o una matriz dividida por la cantidad total de entradas en ese vector o matriz. Por ejemplo, considera una matriz de 100 elementos en la que 98 celdas contienen cero. El cálculo de la dispersión es el siguiente:
La esparcidad de atributos se refiere a la esparcidad de un vector de atributos, mientras que la esparcidad del modelo se refiere a la esparcidad de los pesos del modelo.
SQuAD
Es el acrónimo de Stanford Question Answering Dataset, que se presentó en el artículo SQuAD: 100,000+ Questions for Machine Comprehension of Text. Las preguntas de este conjunto de datos provienen de personas que hacen preguntas sobre artículos de Wikipedia. Algunas de las preguntas en SQuAD tienen respuestas, pero otras intencionalmente no las tienen. Por lo tanto, puedes usar SQuAD para evaluar la capacidad de un LLM para hacer lo siguiente:
- Responde las preguntas que se puedan responder.
- Identifica las preguntas que no se pueden responder.
Concordancia exacta en combinación con F1 son las métricas más comunes para evaluar los LLM en comparación con SQuAD.
pérdida de bisagra al cuadrado
Cuadrado de la pérdida de bisagra. La pérdida de bisagra al cuadrado penaliza los valores atípicos con mayor severidad que la pérdida de bisagra normal.
pérdida al cuadrado
Sinónimo de pérdida L2.
SuperGLUE
Es un conjunto de datos para calificar la capacidad general de un LLM para comprender y generar texto. El conjunto incluye los siguientes conjuntos de datos:
- Boolean Questions (BoolQ)
- CommitmentBank (CB)
- Elección de alternativas plausibles (COPA)
- Comprensión de lectura de varios enunciados (MultiRC)
- Conjunto de datos de comprensión de lectura con razonamiento de sentido común (ReCoRD)
- Reconocimiento de la implicación textual (RTE)
- Palabras en contexto (WiC)
- Winograd Schema Challenge (WSC)
Para obtener más detalles, consulta SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.
T
Pérdida de prueba
Es una métrica que representa la pérdida de un modelo en relación con el conjunto de prueba. Cuando compilas un modelo, por lo general, intentas minimizar la pérdida de la prueba. Esto se debe a que una pérdida de prueba baja es un indicador de calidad más sólido que una pérdida de entrenamiento baja o una pérdida de validación baja.
A veces, una gran brecha entre la pérdida de prueba y la pérdida de entrenamiento o la pérdida de validación sugiere que debes aumentar la tasa de regularización.
Precisión del top-k
Es el porcentaje de veces que aparece una "etiqueta objetivo" en las primeras k posiciones de las listas generadas. Las listas pueden ser recomendaciones personalizadas o una lista de elementos ordenados por softmax.
La precisión del Top-k también se conoce como precisión en k.
tóxico
Es el grado en que el contenido es abusivo, ofensivo o amenazante. Muchos modelos de aprendizaje automático pueden identificar, medir y clasificar la toxicidad. La mayoría de estos modelos identifican la toxicidad en función de varios parámetros, como el nivel de lenguaje abusivo y el nivel de lenguaje amenazante.
Pérdida de entrenamiento
Es una métrica que representa la pérdida de un modelo durante una iteración de entrenamiento en particular. Por ejemplo, supongamos que la función de pérdida es el error cuadrático medio. Quizás la pérdida del entrenamiento (el error cuadrático medio) para la décima iteración sea de 2.2 y la pérdida del entrenamiento para la iteración número 100 sea de 1.9.
Una curva de pérdida representa la pérdida de entrenamiento en función de la cantidad de iteraciones. Una curva de pérdida proporciona las siguientes sugerencias sobre el entrenamiento:
- Una pendiente descendente implica que el modelo está mejorando.
- Una pendiente ascendente implica que el modelo está empeorando.
- Una pendiente plana implica que el modelo alcanzó la convergencia.
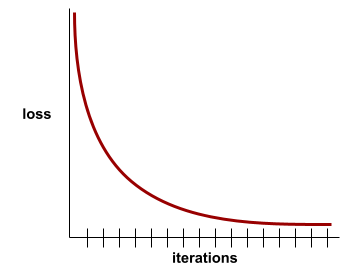
Por ejemplo, la siguiente curva de pérdida algo idealizada muestra lo siguiente:
- Una pendiente descendente pronunciada durante las iteraciones iniciales, lo que implica una mejora rápida del modelo
- Una pendiente que se aplana gradualmente (pero que sigue siendo descendente) hasta cerca del final del entrenamiento, lo que implica una mejora continua del modelo a un ritmo algo más lento que durante las iteraciones iniciales.
- Una pendiente plana hacia el final del entrenamiento, lo que sugiere convergencia.
Si bien la pérdida de entrenamiento es importante, también debes consultar la generalización.
Búsqueda de respuestas a preguntas de trivia
Son conjuntos de datos para evaluar la capacidad de un LLM de responder preguntas de trivia. Cada conjunto de datos contiene pares de preguntas y respuestas creados por entusiastas de las trivias. Diferentes fuentes fundamentan los distintos conjuntos de datos, incluidas las siguientes:
- Búsqueda web (TriviaQA)
- Wikipedia (TriviaQA_wiki)
Para obtener más información, consulta TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.
verdadero negativo (VN)
Ejemplo en el que el modelo predice correctamente la clase negativa. Por ejemplo, el modelo infiere que un mensaje de correo electrónico en particular no es spam y, en efecto, ese mensaje no es spam.
verdadero positivo (VP)
Ejemplo en el que el modelo predice correctamente la clase positiva. Por ejemplo, el modelo infiere que un mensaje de correo electrónico en particular es spam y realmente lo es.
tasa de verdaderos positivos (TVP)
Sinónimo de recuperación. Es decir:
La tasa de verdaderos positivos es el eje Y en una curva ROC.
Typologically Diverse Question Answering (TyDi QA)
Es un conjunto de datos grande para evaluar la competencia de un LLM a la hora de responder preguntas. El conjunto de datos contiene pares de preguntas y respuestas en muchos idiomas.
Para obtener más detalles, consulta TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages.
U
Tasa de reclamos no admitidos (UCR)
Es el porcentaje de afirmaciones en una respuesta que no están fundamentadas. Por ejemplo, si la respuesta de un LLM hace 10 afirmaciones, pero solo 1 está fundamentada, el UCR es del 90%.
Un UCR alto implica que un LLM alucina con demasiada frecuencia.
Consulta también precisión de la cita y recuperación de la cita.
V
Pérdida de validación
Es una métrica que representa la pérdida de un modelo en el conjunto de validación durante una iteración particular del entrenamiento.
Consulta también curva de generalización.
Importancia de las variables
Es un conjunto de puntuaciones que indica la importancia relativa de cada atributo para el modelo.
Por ejemplo, considera un árbol de decisión que estima los precios de las casas. Supongamos que este árbol de decisión usa tres atributos: tamaño, edad y estilo. Si se calcula que un conjunto de importancias de variables para las tres características es {tamaño=5.8, edad=2.5, estilo=4.7}, entonces el tamaño es más importante para el árbol de decisión que la edad o el estilo.
Existen diferentes métricas de importancia de las variables que pueden informar a los expertos en AA sobre diferentes aspectos de los modelos.
W
Pérdida de Wasserstein
Es una de las funciones de pérdida que se usan comúnmente en las redes adversarias generativas, basada en la distancia de movimiento de tierra entre la distribución de los datos generados y los datos reales.
WiC
Abreviatura de Words in Context.
WikiLingua (wiki_lingua)
Es un conjunto de datos para evaluar la capacidad de un LLM de resumir artículos cortos. WikiHow, una enciclopedia de artículos que explican cómo realizar diversas tareas, es la fuente escrita por humanos tanto para los artículos como para los resúmenes. Cada entrada del conjunto de datos consta de lo siguiente:
- Un artículo que se crea agregando cada paso de la versión en prosa (párrafo) de la lista numerada, sin incluir la oración inicial de cada paso.
- Un resumen de ese artículo, que consiste en la oración inicial de cada paso de la lista numerada.
Para obtener más información, consulta WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization.
Desafío de esquemas de Winograd (WSC)
Es un formato (o un conjunto de datos que se ajusta a ese formato) para evaluar la capacidad de un LLM de determinar la frase nominal a la que se refiere un pronombre.
Cada entrada en un Winograd Schema Challenge consta de lo siguiente:
- Un pasaje corto que contiene un pronombre objetivo
- Un pronombre objetivo
- Son las frases nominales candidatas, seguidas de la respuesta correcta (un valor booleano). Si el pronombre objetivo se refiere a este candidato, la respuesta es verdadero. Si el pronombre objetivo no se refiere a este candidato, la respuesta es False.
Por ejemplo:
- Pasaje: Mark le contó muchas mentiras a Pete sobre sí mismo, que Pete incluyó en su libro. Debería haber sido más sincero.
- Pronombre objetivo: Él
- Frases nominales candidatas:
- Mark: Verdadero, porque el pronombre objetivo se refiere a Mark
- Pete: Falso, porque el pronombre objetivo no se refiere a Peter.
El Winograd Schema Challenge es un componente del conjunto SuperGLUE.
Words in Context (WiC)
Es un conjunto de datos para evaluar qué tan bien un LLM usa el contexto para comprender palabras que tienen múltiples significados. Cada entrada del conjunto de datos contiene lo siguiente:
- Dos oraciones, cada una con la palabra objetivo
- La palabra objetivo
- La respuesta correcta (un valor booleano), donde:
- Verdadero significa que la palabra objetivo tiene el mismo significado en las dos oraciones.
- Falso significa que la palabra objetivo tiene un significado diferente en las dos oraciones.
Por ejemplo:
- Dos oraciones:
- Hay mucha basura en el lecho del río.
- Dejo un vaso de agua junto a mi cama cuando duermo.
- La palabra objetivo: cama
- Respuesta correcta: Falso, porque la palabra objetivo tiene un significado diferente en las dos oraciones.
Para obtener más detalles, consulta WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations.
Words in Context es un componente del conjunto SuperGLUE.
WSC
Abreviatura de Winograd Schema Challenge.
X
XL-Sum (xlsum)
Es un conjunto de datos para evaluar la competencia de un LLM en el resumen de texto. XL-Sum proporciona entradas en muchos idiomas. Cada entrada del conjunto de datos contiene lo siguiente:
- Un artículo de la British Broadcasting Company (BBC).
- Es un resumen del artículo escrito por su autor. Ten en cuenta que el resumen puede contener palabras o frases que no están presentes en el artículo.
Para obtener más detalles, consulta XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages.