جاسازی به نمایش برداری دادهها در فضای جاسازی گفته میشود. بهطورکلی، مدل با فراتابی کردن فضای بُعدبالای بردارهای دادههای اولیه در فضای بُعدپایینتر جاسازیهای بالقوه را پیدا میکند. برای مباحث مربوط به دادههای بُعدبالا در مقایسه با دادههای بُعدپایین، به واحد دادههای دستهبندیشده مراجعه کنید.
جاسازیها یادگیری ماشین براساس بردارهای ویژگی بزرگ را، ازجمله بردارهای پراکندهای که اقلام غذایی بحثشده در بخش قبلی را نشان میدهند، آسانتر میکنند. گاهی اوقات جایگاههای نسبی اقلام در فضای جاسازی رابطه معنایی بالقوه دارند، اما اغلب فرایند یافتن فضای بُعدپایینتر و جایگاههای نسبی در آن فضا، توسط انسان قابلتفسیر نیست و درک جاسازیهای حاصل دشوار است.
بااینحال، برای درک بهتر توسط انسان و برای اینکه نحوه نمایش اطلاعات توسط بردارهای جاسازی کمی مشخصتر شود، نمایش یکبعدی غذاهای زیر را درنظر بگیرید هاتداگ، پیتزا، سالاد، شاوارما، و سوپ بُرشچ در مقیاس «کمترین شباهت به ساندویچ» تا «بیشترین شباهت به ساندویچ». این بُعدِ واحد معیاری فرضی از «ساندویچی بودن» است.

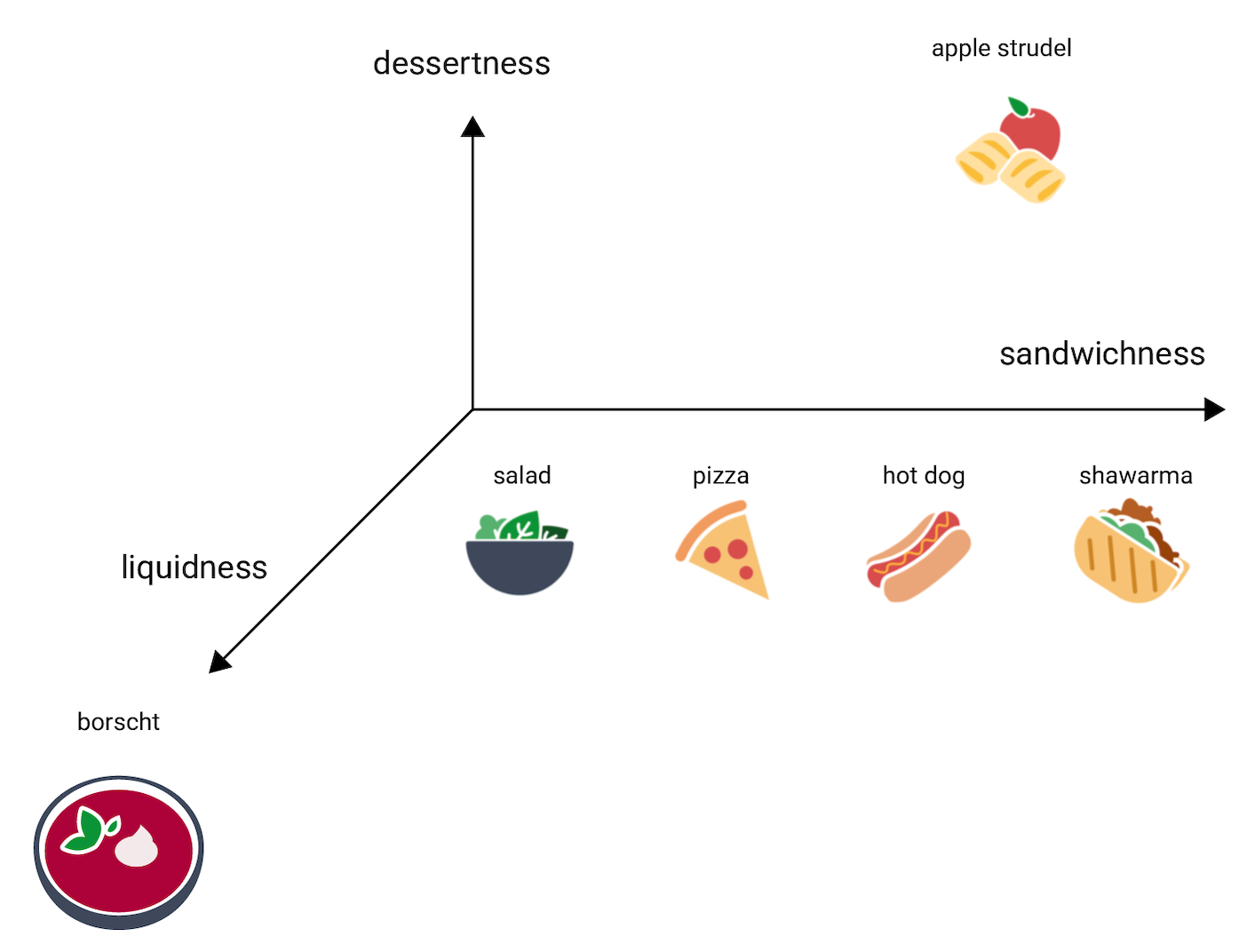
اشترودل سیب کجای این خط قرار میگیرد؟ شاید بتوان آن را بین hot dog و shawarma قرار داد. اما بهنظر میرسد اشترودل سیب بُعد دیگری از شیرین بودن یا دسر بودن را هم دارد که آن را از سایر گزینهها بسیار متفاوت میکند.
شکل زیر این مورد را با اضافه کردن بُعد «دسر بودن» نشان میدهد:

جاسازی هر قلم را در فضای n بعدی با اعداد n نقطه شناور (معمولاً در محدوده -۱ تا ۱ یا ۰ تا ۱) نشان میدهد. جاسازی در شکل ۳ هر غذا را در فضای یکبعدی با نقطه واحد نشان میدهد، درحالیکه شکل ۴ هر غذا را در فضای دوبعدی با دو نقطه نشان میدهد. در شکل ۴، «اشترودل سیب» در یکچهارم بالا سمت چپ در نمودار قرار دارد و میتواند به نقطه (۰٫۵، ۰٫۳) اختصاص داده شود، درحالیکه «هات داگ» در یکچهارم پایین سمت چپ نمودار قرار دارد و میتواند به نقطه (۰٫۲، -۰٫۵) اختصاص داده شود.
در جاسازی، فاصله بین هر دو مورد با قوانین ریاضی قابلمحاسبه است و میتوان آن را بهعنوان معیار شباهت نسبی بین آن دو مورد تفسیر کرد. دو چیزی که به هم نزدیک هستند، مانند shawarma و hot dog در شکل ۴، در نمایش دادهها در مدل، ارتباط نزدیکتری نسبتبه دو چیزی که از هم دورترند، مانند apple strudel و borscht، دارند.
همچنین توجه داشته باشید که در فضای دوبعدی در شکل ۴، apple strudel، نسبتبه فضای یکبعدی، بسیار دورتر از shawarma و hot dog است که منطقی است: آنقدر که هاتداگ و شاورما به یکدیگر شباهت دارند، apple strudel شباهت چندانی به هاتداگ یا شاورما ندارد.
حالا سوپ برشچ را درنظر بگیرید که نسبتبه سایر موارد بسیار مایعتر است. این امر نشاندهنده بعد سوم، یعنی مایع بودن یا میزان مایع بودن غذا است. با اضافه کردن آن بعد میتوانیم موارد را بهطور سهبعدی به این شکل نشان دهیم:
تانگیوان در کدام بخش از این فضای سهبعدی قرار میگیرد؟ این خوراکی سوپمانند است، مثل بُرشچ، و دسر شیرین است، مانند اشترودل سیب، و بدون شک ساندویچ نیست. یکی از جایگاههای ممکن:

به میزان اطلاعاتی که در این سه بعد بیان شده است توجه کنید. میتوانید تصور کنید که ابعاد بیشتر، مثلاً میزان گوشتی بودن یا پخته بودن غذا، اضافه شود هرچند دیداریسازی فضاهای ۴ بعدی، ۵ بعدی، و بالاتر دشوار است.
فضاهای جاسازی زندگی واقعی
در دنیای واقعی، فضاهای جاسازی d-بعدی هستند، که در آن d بسیار بالاتر از ۳ اما پایینتر از ابعاد دادهها است و روابط بین نقاط داده، لزوماً بهاندازه تصویرسازی ساختگی بالا، شهودی نیستند. (برای جاسازیهای واژه، d معمولاً ۲۵۶، ۵۱۲، یا ۱۰۲۴ است.۱)
در عمل، متخصص یادگیری ماشین معمولاً آن تکلیف خاص و تعداد ابعاد جاسازی را تعیین میکند. سپس مدل تلاش میکند تا در فضای جاسازی با تعداد ابعاد مشخص مثالهای آموزشی را به یکدیگر نزدیک کند یا، اگر d ثابت نباشد، تعداد ابعاد را تنظیم کند. ابعاد مجزا معمولاً بهاندازه «دسر بودن» یا «مایع بودن» قابل تفسیر نیستند. گاهی «معنای» آن قابل استنباط است، اما همیشه اینگونه نیست.
جاسازیهای معمولاً مختص تکلیف موردنظر هستند و وقتی تکلیف تغییر کند، با یکدیگر متفاوت خواهند بود. برای مثال، جاسازیهایی که توسط مدل طبقهبندی گیاهخواری در مقابل غیر گیاهخواری ایجاد میشوند، با جاسازیهایی که توسط مدل پیشنهاددهنده غذا براساس زمان روز یا فصل تولید میشوند متفاوت خواهند بود. مثلاً «غلات صبحانه» و «سوسیس صبحانه» احتمالاً در فضای جاسازی مدلِ مبتنی بر زمان روز به یکدیگر نزدیک خواهند بود، اما در فضای جاسازی مدل گیاهخواری درمقابل غیر گیاهخواری فاصله زیادی از هم خواهند داشت.
جاسازیهای ایستا
هرچند جاسازیها از تکلیفی به تکلیف دیگر متفاوت هستند، یکی از تکالیف کاربرد عمومی دارد: پیشبینی بافتار واژه. مدلهایی که برای پیشبینی بافتار واژه آموزش دیدهاند فرض میکنند که واژههایی که در بافتارهای مشابه ظاهر میشوند از نظر معنایی به هم مربوط هستند. برای مثال، دادههای آموزشیای که شامل جملات «آنها با الاغ به داخل گرند کنیون رفتند» و «آنها با اسب به داخل کنیون رفتند» باشد، نشان میدهد که واژه «اسب» در بافتارهای مشابه با «الاغ» ظاهر میشود. مشخص شده که جاسازیهایی که براساس شباهت معنایی باشند، برای بسیاری از تکالیف عمومی زبان بهخوبی عمل میکنند.
اگرچه مدل word2vec نمونهای قدیمیتر است و تا حد زیادی با مدلهای دیگر جایگزین شده است، همچنان برای اهداف توضیحی مفید است. word2vec روی مجموعهای از اسناد آموزش میبیند تا جاسازی کلی واحدی برای هر واژه بهدست آورد. زمانی که هر واژه یا نقطه داده دارای یک بردار جاسازی واحد باشد، به آن جاسازی ایستا گفته میشود. ویدیو زیر نمایشی سادهشده از آموزش word2vec را ارائه میدهد.
تحقیقات نشان میدهد که این جاسازیهای ایستا، پساز آموزش، تا حدی اطلاعات معنایی را کدبندی میکنند، بهویژه در روابط بین واژهها. به این معنا که واژههایی که در بافتهای مشابه بهکار میروند، در فضای جاسازی به یکدیگر نزدیکتر خواهند بود. بردارهای جاسازی خاص ایجادشده به مجموعهای که برای آموزش استفاده شده است بستگی خواهند داشت. برای جزئیات بیشتر، به T. Mikolov et al (2013), "Efficient estimation of word representations in vector space"، مراجعه کنید.
-
François Chollet, Deep Learning with Python (Shelter Island, NY: Manning, 2017), 6.1.2. ↩