このセクションでは、ML 集中講座の数値データの操作モジュールから、クラスタリングに最も関連性の高いデータ準備手順を確認します。
クラスタリングでは、2 つのサンプルのすべての特徴データを数値に結合して、2 つのサンプルの類似性を計算します。これを行うには、特徴のスケールが同じである必要があります。これは、正規化、変換、または分位の作成によって実現できます。分布を検査せずにデータを変換する場合は、デフォルトで分位を使用できます。
データの正規化
データを正規化することで、複数の特徴のデータを同じスケールに変換できます。
Z スコア
データセットが ガウス分布に近い形状をしている場合は、データの Z スコアを計算する必要があります。Z スコアは、値が平均からどの程度標準偏差しているかを示します。データセットが十分に大きくない場合は、Z スコアを使用することもできます。
手順については、Z スコア スケーリングをご覧ください。
次の図は、z スコア スケーリングの前後でのデータセットの 2 つの特徴を視覚化したものです。
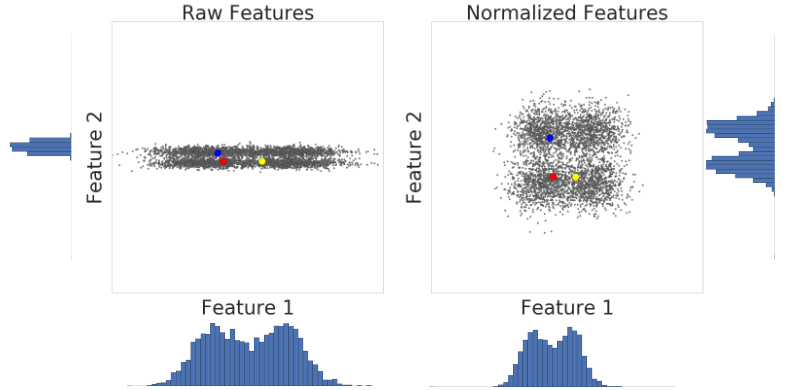
左側の正規化されていないデータセットでは、X 軸と Y 軸にそれぞれグラフ表示されている特徴 1 と特徴 2 のスケールが同じではありません。左側の赤色の例は、黄色よりも青色に近い、または類似しているように見える。右側の z スコア スケーリングでは、特徴 1 と特徴 2 のスケールが同じになり、赤色の例が黄色の例に近づいています。正規化されたデータセットでは、ポイント間の類似性をより正確に測定できます。
ログ変換
データセットが べき乗則分布に完全に準拠している場合(データが最小値に集中している場合)は、ログ変換を使用します。手順については、ログのスケーリングをご覧ください。
対数変換前後のべき乗データセットの可視化を次に示します。
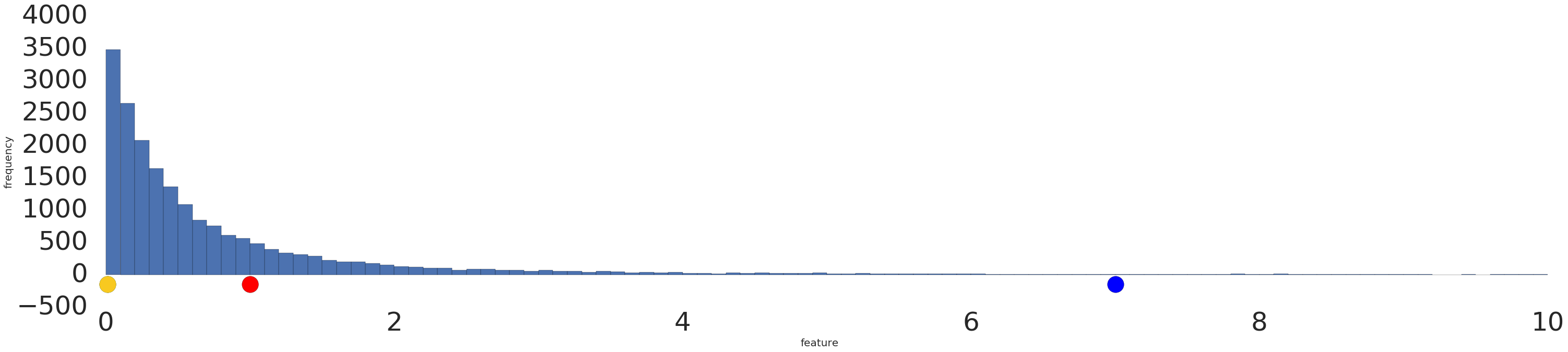
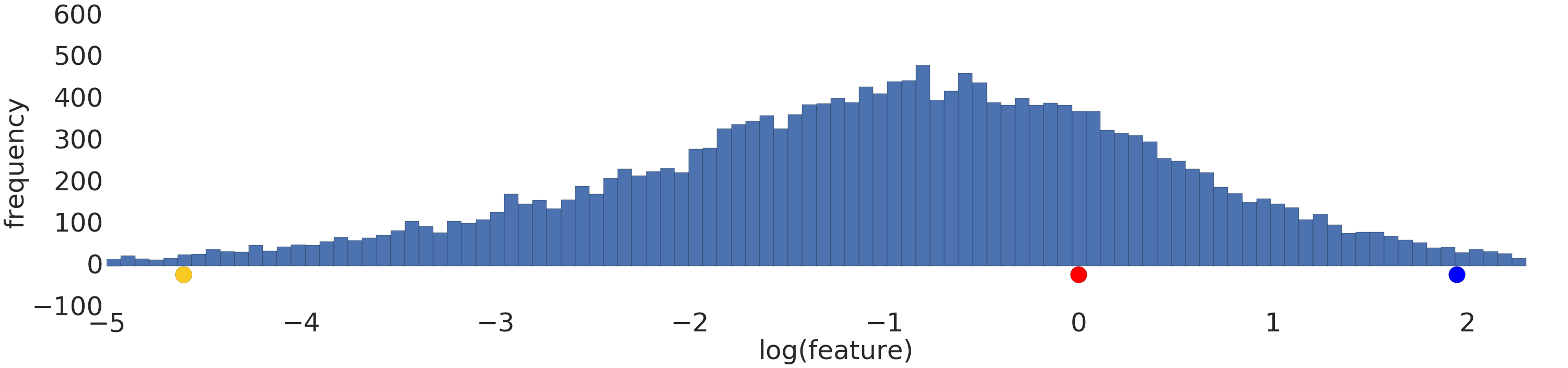
ログ スケーリング前(図 2)では、赤色の例は黄色に近い色で表示されます。ログ スケーリング後(図 3)、赤は青に近づきます。
分位
データセットが既知の分布に従わない場合は、データを四分位に分割すると効果的です。たとえば、次のデータセットについて考えてみましょう。

直感的には、2 つのサンプルの値に関係なく、その間にサンプルが少数しかない場合、2 つのサンプルは類似度が高くなります。その間にサンプルが多数ある場合は、類似度が低くなります。上記の可視化では、赤と黄色の間、または赤と青の間にあるサンプルの合計数を確認するのは困難です。
類似性に関するこの理解は、データセットを分位数(各サンプル数が同じ間隔)に分割し、各サンプルに分位数インデックスを割り当てることで得られます。手順については、分位バケット化をご覧ください。
前の分布を四分位に分割したものを次に示します。赤は黄色から 1 四分位、青から 3 四分位離れています。
![分位に変換されたデータを示すグラフ。線は 20 個の区間を表しています。]](https://developers.google.com/static/machine-learning/clustering/images/Quantize.png?hl=ja)
任意の数の分位を選択できます。 \(n\) ただし、分位が基になるデータを有意に表すためには、データセットに少なくとも\(10n\) 個のサンプルが必要です。十分なデータがない場合は、代わりに正規化します。
理解度を確認する
次の質問では、十分なデータがあり、分位を作成できることを前提としています。
質問 1
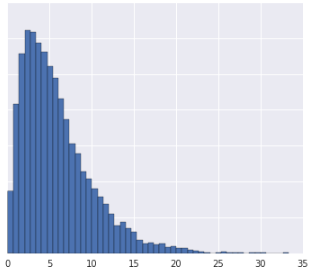
- データ分布はガウス分布です。
- データが現実世界で表す内容に関する分析情報があり、データが非線形に変換されるべきではないことを示唆している。
質問 2
データの欠落
データセットに特定の特徴の欠損値を含むサンプルが含まれているが、それらのサンプルがまれにしか発生しない場合は、これらのサンプルを削除できます。このような例が頻繁に発生する場合は、その特徴を完全に削除するか、機械学習モデルを使用して他の例から欠損値を予測します。たとえば、既存の特徴データでトレーニングされた回帰モデルを使用して、不足している数値データを推定できます。