Klastry są nienadzorowane, więc nie ma żadnej „prawda” do weryfikacji wyników. Brak informacji komplikuje ocenę jakości. Rzeczywiste zbiory danych nie należą zazwyczaj do oczywistych zbiorów przykładów, takich jak zbiory danych na rysunku 1.
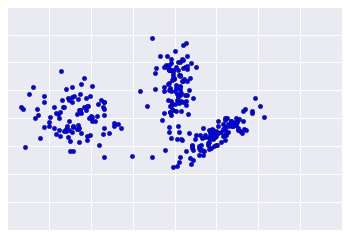
Rzeczywiste dane wyglądają podobnie jak na rysunku 2, przez co trudno jest ocenić jakość klastrów.
Schemat blokowy poniżej pokazuje, jak sprawdzić jakość klastra. W kolejnych sekcjach rozwiniemy podsumowanie.

Krok 1. Grupowanie
Sprawdzanie jakości klastra nie jest rygorystyczne, ponieważ nie ma do niego dostępu. Oto wskazówki, które możesz wielokrotnie zastosować, aby poprawić jakość klastrów.
Najpierw sprawdź, czy klastry wyglądają zgodnie z oczekiwaniami, a przykłady, które uważasz za podobne, pojawiają się w tym samym klastrze. Następnie zapoznaj się z tymi często używanymi danymi zgodnie z opisem w tych sekcjach:
- Moc zbioru
- Wielkość klastra
- Wydajność systemu nadrzędnego
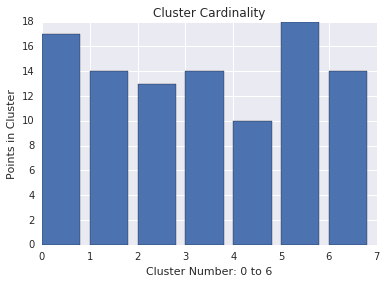
Kampanii zbioru
Moc zbioru w klastrze to liczba przykładów na klaster. Przeanalizuj moc zbioru dla wszystkich klastrów i zbadaj klastry, które są znacznymi wartościami odstającymi. Na przykład na rysunku 2 zbadamy klaster 5.
Siła klastra
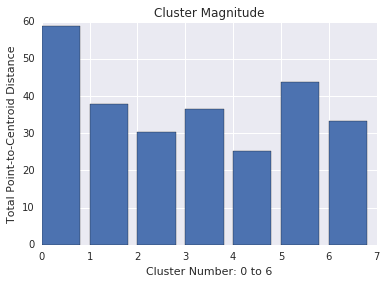
Wielkość klastra to suma odległości od wszystkich przykładów do centroida klastra. Podobnie jak w przypadku mocy zbioru, wielkość różnicy w klastrach i badać anomalie. Na przykład na rysunku 3 zbadamy numer 0 klastra.
Wielkość i moc zbioru
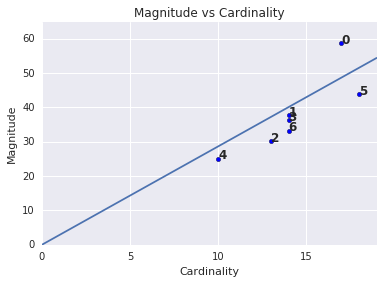
Zauważ, że większa moc zbioru pozwala zwykle uzyskać wyższą wielkość klastra, co ma sens. Klastry są nietypowe, gdy moc zbioru nie pasuje do wielkości w porównaniu do innych klastrów. Znajdź anomalie w klastrze, wyznaczając wielkość na moc zbioru. Na przykład na rysunku 4 dopasowanie wiersza do wskaźników klastra pokazuje, że numer 0 jest nietypowy.
Wydajność systemu Out-Stream
Wyjściowe klastry są często używane w drugorzędnych systemach uczących się, dlatego sprawdź, czy wydajność systemu się nie zmienia. Wpływ na wydajność niższego rzędu zapewnia rzeczywisty test jakości klastra. Wadą jest to, że sprawdzanie jest skomplikowane.
Pytania, które warto zbadać w przypadku wykrycia problemów
Jeśli napotkasz problemy, sprawdź przygotowanie danych i metodę podobieństwa, a potem zadaj sobie te pytania:
- Czy Twoje dane są skalowane?
- Czy wskaźnik podobieństwa jest prawidłowy?
- Czy Twój algorytm wykonuje istotne semantycznie operacje na danych?
- Czy Twoje założenia są zgodne z danymi?
Krok 2. Skuteczność pomiaru podobieństwa
Algorytm grupowania jest tak samo skuteczny jak Twój wskaźnik podobieństwa. Upewnij się, że Twoje podobieństwo zwraca rozsądne wyniki. Najprostszym sposobem jest określenie par przykładów, które są mniej lub bardziej podobne do innych. Następnie oblicz miarę podobieństwa dla każdej pary przykładów. Dopilnuj, aby współczynnik podobieństwa w przypadku większej liczby podobnych przykładów był wyższy niż wskaźnik podobieństwa w przypadku mniej podobnych przykładów.
Przykłady używane do sprawdzania podobieństwa powinny dotyczyć zbioru danych. Upewnij się, że wszystkie podobne przykłady są objęte pomiarem podobieństwa. Uważna weryfikacja pozwala zagwarantować spójne podobieństwo pomiaru (ręcznych lub nadzorowanych) w zbiorze danych. Jeśli w niektórych przypadkach pomiar podobieństwa jest niespójny, te przykłady nie będą grupowane z podobnymi przykładami.
Jeśli znajdziesz przykłady z niedokładnymi podobieństwami, oznacza to, że Twoje podobieństwo prawdopodobnie nie uwzględnia danych o cechach, które odróżniają te przykłady. Poeksperymentuj z pomiarem podobieństwa i określ, czy uzyskasz dokładniejsze dane.
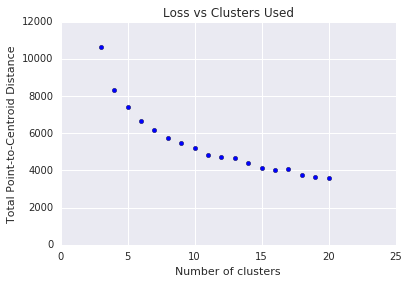
Krok 3. Optymalna liczba klastrów
K-MEs wymaga wcześniejszego określenia \(k\) klastrów. Jak określić optymalną wartość \(k\)? Uruchom algorytm zwiększania \(k\) i zanotuj sumę powiększenia klastra. W miarę jak \(k\) liczba klastrów się zmniejsza, a całkowity dystans maleje. Zapisz ten dystans od liczby klastrów.
Jak to widać na rysunku 4, zmniejszenie wartości \(k\)osłabia się wraz ze wzrostem \(k\). Matematycznie jest to mniej więcej \(k\) miejsce, w którym wartość na wykresie przekracza powyżej –1 (\(\theta > 135^{\circ}\)). Ta wskazówka nie wskazuje dokładnej wartości \(k\) , ale tylko wartość przybliżona. Optymalna wartość fazy to \(k\) 11. Jeśli wolisz bardziej szczegółowe klastry, możesz wybrać wyższą wartość, \(k\) korzystając z tego wykresu.