क्लस्टरिंग की निगरानी नहीं की जा रही है. इसलिए, नतीजों की पुष्टि करने के लिए कोई “सही” उपलब्ध नहीं है. सही जानकारी का मौजूद न होना, क्वालिटी के आकलन को आसान नहीं बनाता. इसके अलावा, असल दुनिया के डेटासेट आम तौर पर उदाहरण के तौर पर दिए गए उदाहरणों के ग्रुप में नहीं होते हैं, जैसा कि पहली इमेज में दिखाया गया है.
अफ़सोस है कि असल डेटा, इमेज 2 जैसा दिखता है. इसलिए, क्लस्टरिंग क्वालिटी का विज़ुअल आकलन करना मुश्किल हो जाता है.
नीचे दिया गया फ़्लोचार्ट आपके क्लस्टरिंग की क्वालिटी जांचने का तरीका बताता है. हम नीचे दिए गए सेक्शन में खास जानकारी को शामिल करेंगे.

पहला चरण: क्लस्टर बनाने की क्वालिटी
क्लस्टरिंग की क्वालिटी की जांच करना एक मुश्किल काम नहीं है, क्योंकि क्लस्टरिंग में “सच” की कमी है. यहां ऐसे दिशा-निर्देश दिए गए हैं जिन्हें आप क्लस्टरिंग की क्वालिटी को बेहतर बनाने के लिए बार-बार लागू कर सकते हैं.
सबसे पहले, विज़ुअल जांच करके देखें कि क्लस्टर उम्मीद के मुताबिक दिख रहे हैं और ये ऐसे उदाहरण हैं जो आपके हिसाब से एक ही क्लस्टर में दिखते हैं. इसके बाद, नीचे दिए गए सेक्शन में बताए गए आम तौर पर इस्तेमाल होने वाले ये मेट्रिक देखें:
- क्लस्टर घटकों की संख्या
- क्लस्टर की तीव्रता
- डाउनस्ट्रीम सिस्टम की परफ़ॉर्मेंस
क्लस्टर की संख्या
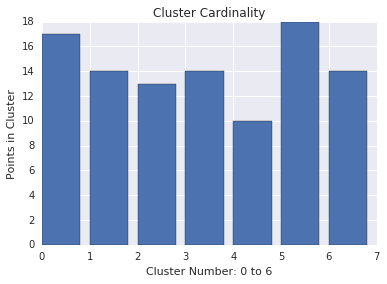
क्लस्टर घटकों की संख्या, हर क्लस्टर में उदाहरणों की संख्या है. सभी क्लस्टर के लिए क्लस्टर की घटकों की संख्या प्लॉट करें और उन क्लस्टर की जांच करें जो खास बाहरी गतिविधियों के लिए हैं. उदाहरण के लिए, चित्र 2 में, क्लस्टर नंबर 5 की जांच करें.
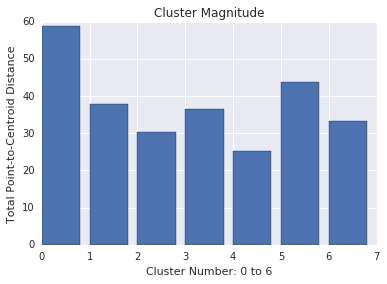
क्लस्टर की तीव्रता
क्लस्टर की तीव्रता, सभी उदाहरणों से क्लस्टर के केंद्र के बीच की दूरी का योग है. घटकों की संख्या की तरह, यह देखें कि अलग-अलग क्लस्टर में तीव्रता कितनी है. साथ ही, गड़बड़ियों की जांच भी करें. उदाहरण के लिए, चित्र 3 में, क्लस्टर नंबर 0 की जांच करें.
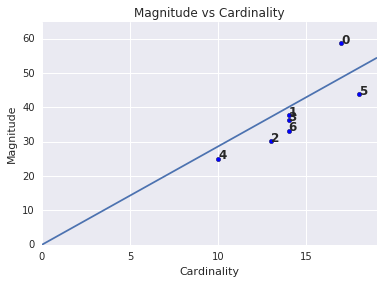
मैग्निट्यूड बनाम घटकों की संख्या
ध्यान रखें कि घटकों की ज़्यादा संख्या से ग्रुप का साइज़ बढ़ जाता है. यह काफ़ी आसान होता है. क्लस्टर तब अनियमित होते हैं, जब घटकों की संख्या अन्य क्लस्टर से मिलता-जुलता नहीं होता. घटकों की संख्या के आधार पर अनियमित क्लस्टर खोजें. उदाहरण के लिए, चित्र 4 में, क्लस्टर मेट्रिक की लाइन को फ़िट करने से पता चलता है कि क्लस्टर नंबर 0 असामान्य है.
डाउनस्ट्रीम सिस्टम की परफ़ॉर्मेंस
क्लस्टरिंग आउटपुट का इस्तेमाल, अक्सर डाउनस्ट्रीम एमएल सिस्टम में किया जाता है. इसलिए, देखें कि क्लस्टरिंग प्रोसेस में बदलाव होने पर, डाउनस्ट्रीम सिस्टम की परफ़ॉर्मेंस बेहतर हो या नहीं. आपके डाउनस्ट्रीम परफ़ॉर्मेंस पर असर, आपकी क्लस्टरिंग की क्वालिटी की असल दुनिया में जांच करता है. हालांकि, इस जांच का कोई नुकसान नहीं है. इसलिए, यह जांच करना मुश्किल होता है.
समस्याओं का पता लगाने की जांच करने के लिए सवाल
अगर आपको समस्याएं मिलती हैं, तो अपने डेटा को इकट्ठा करने के साथ-साथ उनकी तुलना करने के बारे में जानें. साथ ही, खुद से ये सवाल पूछें:
- क्या आपके डेटा को स्केल किया जाता है?
- क्या आपकी समानता का माप सही है?
- क्या आपका एल्गोरिदम, डेटा के हिसाब से शब्दों के हिसाब से काम कर रहा है?
- क्या आपके एल्गोरिदम के अनुमान, डेटा से मेल खाते हैं?
दूसरा चरण: मिलते-जुलते तरीके से परफ़ॉर्मेंस
क्लस्टरिंग एल्गोरिदम उतना ही अच्छा होता है जितना मिलता-जुलता माप है. पक्का करें कि आपकी समानता का आकलन करने पर सही नतीजे मिलते हैं. इसका सबसे आसान तरीका यह है कि उन उदाहरणों की पहचान की जाए जो दूसरे पेयर से ज़्यादा या कम मिलते-जुलते हैं. इसके बाद, उदाहरणों के हर जोड़े के लिए मिलते-जुलते माप का हिसाब लगाएं. पक्का करें कि मिलते-जुलते उदाहरणों के लिए, मिलते-जुलते माप का इस्तेमाल, कम मिलते-जुलते उदाहरणों के लिए, माप के माप से ज़्यादा है.
उदाहरण के तौर पर, यह देखने के लिए कि आपकी मिलती-जुलती माप का इस्तेमाल कैसे किया जाता है, डेटा सेट के बारे में बताना चाहिए. पक्का करें कि आपके सभी प्रॉडक्ट के डेटा के समानता का आकलन, आपके सभी उदाहरणों के लिए हो. ध्यान से पुष्टि करने से यह पक्का होता है कि मैन्युअल तरीके से या निगरानी में रखे गए आपके डेटा में, समानता का जो भी आकलन किया गया है वह पूरे डेटासेट में एक जैसा हो. अगर कुछ उदाहरणों में आपके मिलते-जुलते तरीके एक जैसे नहीं हैं, तो उन उदाहरणों को एक जैसे उदाहरणों के साथ नहीं रखा जाएगा.
अगर आपको ऐसे मिलते-जुलते उदाहरण मिलते हैं जो एक जैसे नहीं हैं, तो शायद आपके मिलते-जुलते माप का इस्तेमाल करके, ऐसे सुविधा के डेटा को कैप्चर नहीं किया जा सकता जो उन उदाहरणों में अंतर करता है. अपनी समानता का आकलन करके पता लगाएं कि आपको ज़्यादा सटीक समानताएं मिलती हैं या नहीं.
तीसरा चरण: क्लस्टर के लिए ऑप्टिमम संख्या
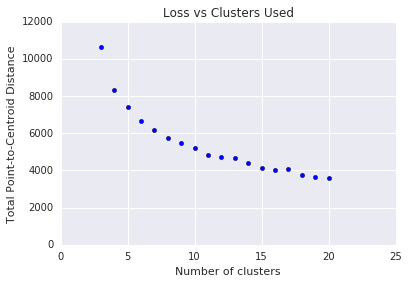
k-mens का इस्तेमाल करने के लिए, आपको \(k\) पहले क्लस्टर की संख्या तय करनी होगी. आप \(k\)के लिए सबसे सही वैल्यू कैसे तय करते हैं? एल्गोरिदम को बढ़ाने के लिए एल्गोरिदम चलाने की कोशिश करें \(k\) और क्लस्टर की तीव्रता का योग नोट करें. जैसे-जैसे \(k\) बढ़ता है, क्लस्टर छोटे होते जाते हैं और कुल दूरी घट जाती है. क्लस्टर की संख्या के मुकाबले इस दूरी को प्लॉट करें.
जैसा कि चित्र 4 में दिखाया गया है, किसी खास \(k\)स्थिति में, कमी में कमी बढ़ाई जाती है \(k\). गणित के हिसाब से, यह \(k\) है, जहां ढलान -1 से ऊपर होती है (\(\theta > 135^{\circ}\)). यह दिशा-निर्देश ऑप्टिमम \(k\) के लिए कोई सटीक वैल्यू बताता नहीं है. दिखाए गए प्लॉट के लिए, ऑप्टिमल \(k\) करीब 11 है. अगर आप ज़्यादा जानकारी वाले क्लस्टर देखना चाहते हैं, तो आप इस प्लॉट का इस्तेमाल दिशा-निर्देश के तौर पर करके, ज़्यादा \(k\) चुन सकते हैं.