
Develop Google Drive solutions.
Enhance the Google Drive experience
Insert interactive content, powered by your account data or an external service, with add-ons.
- Show a custom interface for uploading files from Drive into your third-party service.
- Enable users to quickly create files from custom templates.
Automate Google Drive with simple code
Anyone can use Apps Script to automate and enhance Google Drive in a web-based, low-code environment.
- Create Drive files based on Google Form submissions.
- Modify files in bulk.
- Populate a spreadsheet with file sharing info for audit.
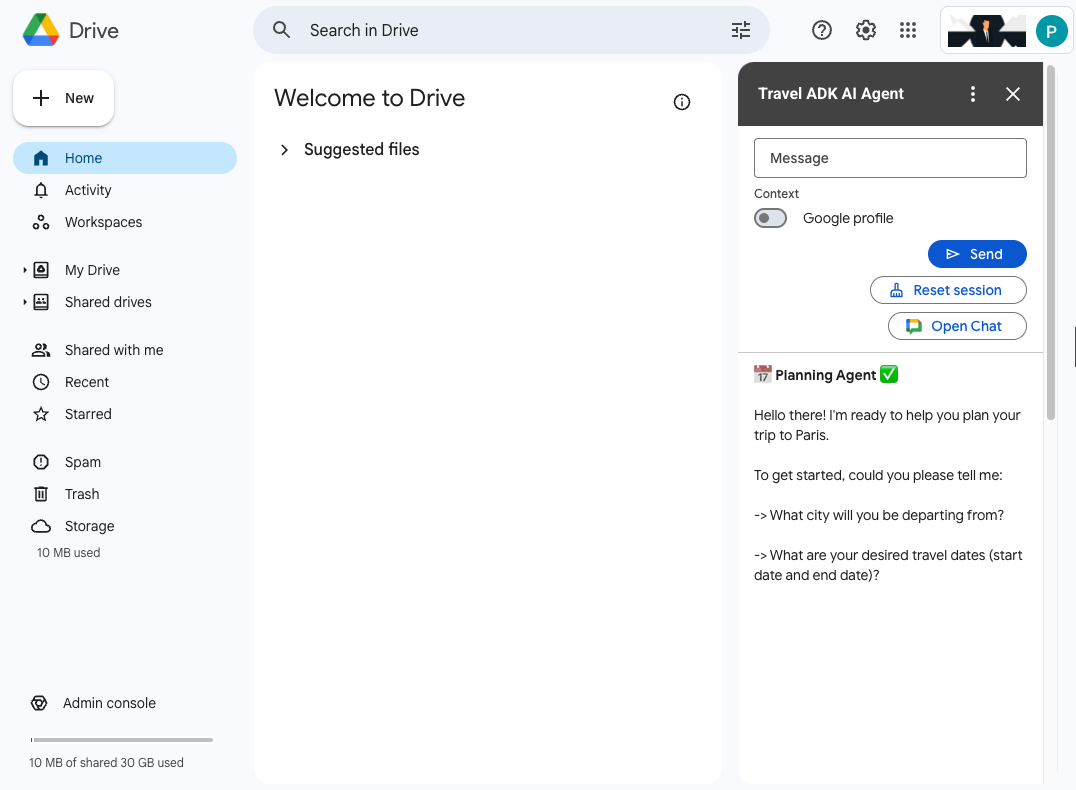
Build AI-powered Google Drive solutions
Discover and try Google Drive samples that help you get started with building AI features using AI models, agents, platforms, and more.
Travel Concierge agent
Build an AI agent add-on that integrates with ADK and Vertex AI Agent Engine.
Gemini Enterprise Agents
Build Gemini Enterprise agents that are tightly integrated with Workspace data stores, APIs, and add ons.
Vertex AI Agents
Build Vertex AI agents that are tightly integrated with Workspace data stores, APIs, and add ons.
All samples
Explore add-on samples by featured Google products, language, sample type, and type.
Connect your service to Google Drive
Use the REST APIs below to interact programmatically with Google Drive.
Drive API
Upload, download, share, and manage files stored in Google Drive.
Drive Activity API
Get info about user activity on files and folders.
Drive Labels API
Apply and manage labels on your Drive files and folders, and search for files using metadata terms defined by a custom label
taxonomy.
 |
Want to see the Google Drive API in action?
The Google Workspace Developers channel offers videos about tips, tricks, and the latest features.
|