Anleitung für C++
In den frühen Abschnitten dieses Anleitung das bereits vorgestellte Grundmaterial in den letzten beiden Modulen an und stellen weitere Informationen zu erweiterten Konzepten bereit. Unsere Der Schwerpunkt dieses Moduls liegt auf dem dynamischen Arbeitsspeicher und auf Objekten und Klassen. Darüber hinaus werden einige weiterführende Themen vorgestellt, wie Vererbung, Polymorphismus, Vorlagen, Ausnahmen und Namespaces. Diese werden wir später im C++-Kurs für Fortgeschrittene behandeln.
Objektorientiertes Design
Dies ist eine hervorragende Anleitung zum objektorientierten Design. Wir wenden die die hier im Projekt dieses Moduls vorgestellt wird.
Lernen anhand von Beispiel 3
In diesem Modul konzentrieren wir uns darauf, mehr Übung mit Verweisen, objektorientierte mehrdimensionale Arrays und Klassen/Objekte. Gehen Sie Folgendes durch: Beispiele. Wir können gar nicht oft genug betonen, dass der Schlüssel zum erfolgreichen Programmieren heißt Üben, Üben, Üben!Übung 1: Mehr Übung mit Pointern
Wenn Sie zusätzliche Übung mit Cursorn benötigen, lesen Sie dieser Ressource mit allen Aspekten von Verweisen und zahlreiche Programmbeispiele.
Was ist die Ausgabe des folgenden Programms? Führen Sie das Programm nicht aus, aber zeichnen Sie das Speicherbild, um die Ausgabe zu bestimmen.
void Unknown(int *p, int num);
void HardToFollow(int *p, int q, int *num);
void Unknown(int *p, int num) {
int *q;
q = #
*p = *q + 2;
num = 7;
}
void HardToFollow(int *p, int q, int *num) {
*p = q + *num;
*num = q;
num = p;
p = &q;
Unknown(num, *p);
}
main() {
int *q;
int trouble[3];
trouble[0] = 1;
q = &trouble[1];
*q = 2;
trouble[2] = 3;
HardToFollow(q, trouble[0], &trouble[2]);
Unknown(&trouble[0], *q);
cout << *q << " " << trouble[0] << " " << trouble[2];
}Sobald Sie die Ausgabe manuell ermittelt haben, führen Sie das Programm aus, um zu sehen, richtig.
Übung 2: Mehr Übung mit Kursen und Objekten
Wenn Sie noch mehr Übung mit Klassen und Objekten benötigen, hier ist eine Ressource, die die Implementierung von zwei kleinen Klassen durchläuft. Nimm etwas Zeit für die Trainings.
Übung 3: Mehrdimensionale Arrays
Sie könnten das folgende Programm in Betracht ziehen:
const int kStudents = 25;
const int kProblemSets = 10;
// This function returns the highest grade in the Problem Set array.
int get_high_grade(int *a, int cols, int row, int col) {
int i, j;
int highgrade = *a;
for (i = 0; i < row; i++)
for (j = 0; j < col; j++)
if (*(a + i * cols + j) > highgrade) // How does this line work?
highgrade = *(a + i*cols + j);
return highgrade;
}
int main() {
int grades[kStudents][kProblemSets] = {
{75, 70, 85, 72, 84},
{85, 92, 93, 96, 86},
{95, 90, 83, 76, 97},
{65, 62, 73, 84, 73}
};
int std_num = 4;
int ps_num = 5;
int highest;
highest = get_high_grade((int *)grades, kProblemSets, std_num, ps_num);
cout << "The highest problem set score in the class is " << highest << endl;
return 0;
}In diesem Programm gibt es eine Zeile mit der Bezeichnung „Wie funktioniert diese Linie?“. - Kannst du es herausbekommen? Hier finden Sie unsere Erklärung.
Schreibe ein Programm, das ein 3-Dim-Array initialisiert und die dritte Dimension ausfüllt mit der Summe aller drei Indexe. Hier finden Sie unsere Lösung.
Übung 4: Ein umfangreiches Designbeispiel für OO
Hier finden Sie eine detaillierte Beispiel für objektorientiertes Design, das die gesamte von Anfang bis Ende durch. Der endgültige Code wird in Java geschrieben. Programmiersprache, aber Sie werden sie lesen können, wenn Sie kommen.
Bitte nehmen Sie sich die Zeit, dieses Beispiel durchzugehen. Es ist eine großartige Illustration des Prozesses und der Designtools, die ihn unterstützen.
Einheitentest
Einführung
Tests sind ein wichtiger Bestandteil des Softwareentwicklungsprozesses. Ein Unittest ist eine spezielle Art von Test, bei dem die Funktionalität einer einzelnen, kleinen des Quellcodes.Einheitentests werden immer vom Engineering-Team durchgeführt. in der Regel zur selben Zeit bei der Codierung des Moduls. Die Testfahrer, die Sie die zum Testen der Composer- und Database-Klassen verwendet werden, sind Beispiele für Einheitentests.
Einheitentests haben die folgenden Eigenschaften. Der Werbetreibende…
- Eine Komponente isoliert testen
- sind deterministisch
- werden in der Regel einer einzelnen Klasse zugeordnet,
- Vermeidung von Abhängigkeiten von externen Ressourcen, z.B. Datenbanken, Dateien, Netzwerk
- schnell umsetzen
- können in beliebiger Reihenfolge ausgeführt werden
Es gibt automatisierte Frameworks und Methoden, Einheitlichkeit beim Testen von Einheiten in großen Softwareentwicklungsunternehmen zu berücksichtigen. Es gibt ausgefeilte Open-Source-Frameworks für Einheitentests, erfahren Sie später in dieser Lektion.
Die im Rahmen von Unittests durchgeführten Tests sind unten dargestellt.
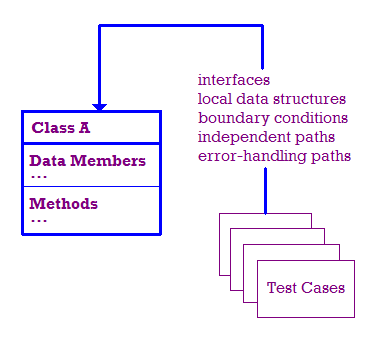
In einer idealen Welt testen wir Folgendes:
- Die Benutzeroberfläche des Moduls wird getestet, um sicherzustellen, dass Informationen ein- und ausfließen. korrekt sind.
- Lokale Datenstrukturen werden untersucht, um sicherzustellen, dass die Daten ordnungsgemäß gespeichert werden.
- Rahmenbedingungen werden getestet, um sicherzustellen, dass das Modul ordnungsgemäß funktioniert an den Grenzen, die die Verarbeitung beschränken.
- Wir testen unabhängige Pfade durch das Modul, um sicherzustellen, dass jeder Pfad und
Somit wird jede Anweisung im Modul mindestens einmal ausgeführt.
- Schließlich müssen wir überprüfen, ob Fehler ordnungsgemäß verarbeitet werden.
Codeabdeckung
In Wirklichkeit können wir keine vollständige „Codeabdeckung“ erreichen, mit unseren Tests. Die Codeabdeckung ist eine Analysemethode, die bestimmt, welche Teile einer Software System ausgeführt (abgedeckt) wurde und welche Teile nicht ausgeführt. Wenn wir versuchen, eine Abdeckung von 100% zu erreichen, Einheitentests als den eigentlichen Code schreiben! Überlegen Sie sich, ob Sie Tests für alle unabhängigen Pfade der folgenden Pfade. Dies kann schnell zu einem Exponentialproblem.
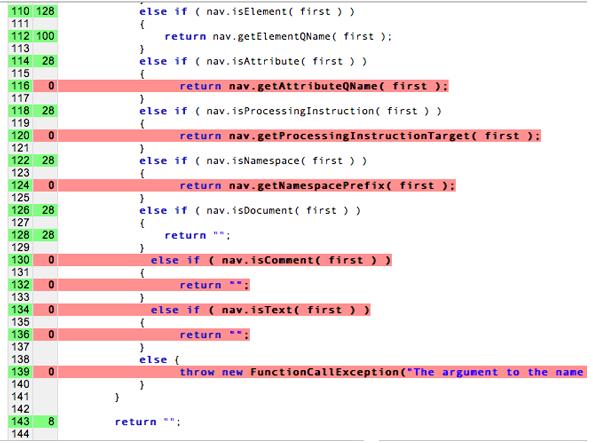
In diesem Diagramm werden die roten Linien nicht getestet, während die nicht gefärbten Linien getestet.
Anstatt eine Abdeckung von 100% zu versuchen, konzentrieren wir uns auf Tests, die uns ob das Modul ordnungsgemäß funktioniert. Wir führen Tests auf Dinge aus wie:
- Null-Fälle
- Bereichstests, z.B. Tests mit positiven/negativen Werten
- Sonderfälle
- Fehlerfälle
- Die Pfade testen, die die meiste Zeit am ehesten ausgeführt werden
Einheitentest-Frameworks
Die meisten Frameworks für Einheitentests verwenden Assertions, um Werte während der Ausführung Pfad. Assertions sind Anweisungen, mit denen geprüft wird, ob eine Bedingung erfüllt ist. Die Das Ergebnis einer Assertion kann ein Erfolg, ein nicht schwerwiegender oder ein schwerwiegender Fehler sein. Nachher eine Assertion ausgeführt wird, wird das Programm normal fortgesetzt, wenn das Ergebnis nicht schwerwiegenden Fehlers aufgetreten ist. Wenn ein schwerwiegender Fehler auftritt, wird abgebrochen.
Tests bestehen aus Code, der den Status einrichtet oder Ihr Modul manipuliert, mit einer Reihe von Assertions, die die erwarteten Ergebnisse verifizieren. Wenn alle Assertions in einem Test erfolgreich sind, d. h. geben Sie "true" zurück, dann ist der Test erfolgreich. sonst schlägt er fehl.
Ein Testfall enthält einen oder mehrere Tests. Wir gruppieren Tests in Testfällen, die Struktur des getesteten Codes widerspiegeln. In diesem Kurs werden wir CPPUnit als Framework für Einheitentests. Mit diesem Framework können wir Einheitentests in C++ und führen sie automatisch aus. So erhalten Sie einen Bericht über Erfolg oder Misserfolg. Tests durchführen.
CPPUnit-Installation
Laden Sie den CPPUnit-Code herunter von SourceForge verweisen. Suchen Sie ein geeignetes Verzeichnis und platzieren Sie die Datei tar.gz dort. Geben Sie dann folgenden Befehlen (in Linux, Unix) und ersetzen Sie dabei die entsprechende cppunit-Datei. Name:
gunzip filename.tar.gz tar -xvf filename.tar
Wenn Sie in Windows arbeiten, müssen Sie möglicherweise ein Dienstprogramm zum Extrahieren von tar.gz finden Dateien. Im nächsten Schritt werden die Bibliotheken kompiliert. Wechseln Sie in das Verzeichnis cppunit. Dort befindet sich die Datei INSTALL, die spezifische Anweisungen enthält. Normalerweise müssen Sie Folgendes ausführen:
./configure make install
Falls Probleme auftreten, sehen Sie in der INSTALL-Datei nach. Die Bibliotheken sind in der Regel im Verzeichnis „cppunit/src/cppunit“. Um zu überprüfen, ob die Kompilierung funktioniert hat, rufen Sie das Verzeichnis "cppunit/examples/simple" auf und geben Sie "make" ein. Wenn alles kompiliert ist, dann sind Sie startklar.
Es gibt eine hervorragende Anleitung, hier. Bitte lesen Sie diese Anleitung durch und erstellen Sie die komplexe Zahlenklasse und die zugehörigen Unittests. Das Verzeichnis cppunit/examples enthält mehrere zusätzliche Beispiele.
Warum muss ich das tun??
Einheitentests sind in der Branche aus verschiedenen Gründen von entscheidender Bedeutung. Sie sind einen Grund kennen: Wir brauchen eine Möglichkeit, unsere Arbeit zu überprüfen, während bei der Entwicklung von Code. Selbst wenn wir ein sehr kleines Programm entwickeln, schreiben Sie eine Art Checker oder Treiber, um sicherzustellen, dass unser Programm tut, was erwartet wird.
Aus langjähriger Erfahrung wissen Ingenieure, dass die Chancen, dass ein Programm funktioniert, beim ersten Versuch sehr klein sind. Einheitentests bauen auf dieser Idee auf, indem sie Tests die Programme selbstüberprüfen und wiederholbar sind. Die Assertions ersetzen die manuelle der Ausgabe von Daten. Da die Ergebnisse einfach zu interpretieren sind (Test besteht, können die Tests immer wieder durchgeführt werden, ein Sicherheitsnetz, das Ihren Code resistenter gegen Änderungen macht.
Konkret bedeutet das: Wenn Sie Ihren fertigen Code zum ersten Mal CVS funktioniert. Und es funktioniert noch eine Weile einwandfrei. Dann ändert jemand Ihren Code. Früher oder später, wenn jemand kaputtgeht Ihren Code. Glauben Sie, dass sie es selbst bemerken? Unwahrscheinlich. Aber wenn Sie Einheitentests schreiben, gibt es Systeme, die diese automatisch jeden Tag ausführen. Diese werden als Continuous-Integration-Systeme bezeichnet. Wenn dieser Techniker X Ihren Code beschädigt, sendet das System unangenehme E-Mails an sie, bis sie behoben sind. . Auch wenn Ingenieur X du bist!
Sie helfen Ihnen nicht nur bei der Softwareentwicklung und sorgen dafür, dass diese auch sicher bleibt. sind Einheitentests angesichts von Veränderungen:
- Erstellt eine ausführbare Spezifikation und eine synchrone Dokumentation mit dem Code. Mit anderen Worten: Sie können einen Einheitentest lesen, um zu erfahren, Verhalten, das das Modul unterstützt.
- Hilft Ihnen, die Anforderungen von der Implementierung zu trennen. Da Sie für eine extern sichtbares Verhalten haben, können Sie genau darüber nachdenken, anstatt Ideen zur Umsetzung des Verhaltens einzuführen.
- Unterstützt Experimente. Wenn Sie ein Sicherheitsnetz haben, das Sie warnt, das Verhalten eines Moduls überspringt, können Sie mit größerer Wahrscheinlichkeit Dinge ausprobieren. und Ihre Designs neu zu konfigurieren.
- Ihre Designs werden verbessert. Für das Schreiben gründlicher Einheitentests ist oft Folgendes erforderlich: um Ihren Code testbarer zu machen. Testbarer Code ist oft modularer als nicht testbarer Code Code.
- Sorgt für eine hohe Qualität. Ein kleiner Fehler in einem kritischen System kann Millionen von Dollar oder, noch schlimmer, die Zufriedenheit oder das Vertrauen der Nutzer zu verlieren. Die ein Sicherheitsnetz, das Einheitentests bieten, diese Möglichkeit verringern. Indem sie Insekten fangen können sich die QA-Teams auch auf komplexere und anspruchsvollere Aufgaben Fehlerszenarien zu erkennen, anstatt offensichtliche Fehler zu melden.
Nehmen Sie sich etwas Zeit, um Einheitentests mit CPPUnit für die Composer-Datenbankanwendung zu schreiben. Weitere Informationen finden Sie im Verzeichnis cppunit/examples/.
So funktioniert Google
EinführungStellen Sie sich einen Mönch im Mittelalter vor, der sich Tausende von Manuskripten in in den Archiven seines Klosters.„Wo ist der von Aristoteles...“

Zum Glück sind die Manuskripte nach Inhalt und Inschrift mit Sonderzeichen, die das Abrufen der in . Ohne eine solche Organisation wäre es sehr schwierig, relevante Manuskript.
Aktivität des Speicherns und Abrufens schriftlicher Informationen aus großen Sammlungen wird als Information Retrieval (IR) bezeichnet. Diese Aktivitäten haben sich im Laufe der Jahrhunderte wichtig, insbesondere bei Erfindungen wie Papier und Druck. drücken. Früher waren nur wenige Menschen damit beschäftigt. Jetzt Aber hunderte Millionen Menschen nutzen jedes Mal die Informationsabfrage, wenn sie eine Suchmaschine verwenden oder ihren Desktop durchsuchen.
Erste Schritte mit dem Informationsabruf

Dr. Seuss schrieb über einen Zeitraum von 30 Jahren 46 Kinderbücher. Seine Bücher erzählten, von Katzen, Kühen und Elefanten, von Wer ist, Grinsen und Lorax. Erinnerst du dich? Welche Kreaturen spielten in welcher Geschichte? Wenn Sie kein Elternteil sind, können nur Kinder in welchen Geschichten von Dr. Seuss die Kreaturen enthalten sind:
(COW und BEE) oder CROWS
Zur Lösung dieses Problems wenden wir einige klassische Abrufmodelle an. Problem.
Ein offensichtlicher Ansatz ist Brute-Force-Angriffe: Erfasse alle 46 Geschichten von Dr. Seuss und beginne Lesematerialien. Notieren Sie sich für jedes Buch, welches bzw. welche die Wörter COW und BEE enthalten, und und suchen Sie gleichzeitig nach Büchern, die das Wort CROWS enthalten. Computer sind viel schneller als wir. Wenn wir alle Texte aus den Büchern von Dr. Seuss haben, z. B. als Textdateien, können wir die Dateien mit grep durchgehen. Für eine kleiner Sammlung wie den Büchern von Dr. Seuss gut funktioniert, funktioniert diese Technik gut.
Es gibt jedoch viele Situationen, in denen wir mehr benötigen. Beispiel: Die Sammlung aller derzeit online verfügbaren Daten sind viel zu groß, um grep zu verarbeiten. Außerdem nur die Dokumente benötigen, die unserer Bedingung entsprechen, gewöhnen wir uns daran, nach Relevanz geordnet werden.
Neben grep können Sie auch einen Index der Dokumente in einer Sammlung bevor Sie die Suche durchführen. Ein Index in IR ähnelt einem Index am auf die Rückseite eines Lehrbuchs. Wir erstellen eine Liste aller Wörter (oder Begriffe) in den einzelnen Die Geschichte von Dr. Seuss, wobei Wörter wie „das“, „und“ und andere Verbindungen weggelassen werden, Präpositionen usw. (als Stoppwörter bezeichnet). Anschließend repräsentieren wir Informationen so zu übermitteln, dass die Begriffe und die Identifizierung die Geschichten, in denen sie sich befinden.
Eine mögliche Darstellung ist eine Matrix mit den Geschichten oben und die in jeder Zeile aufgeführten Begriffe. Eine „1“ in einer Spalte bedeutet, dass der Begriff in der Story für diese Spalte.
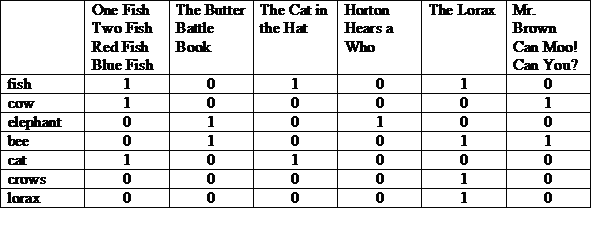
Wir können jede Zeile oder Spalte als Bitvektor betrachten. Der Bitvektor einer Zeile gibt in welchen Artikeln der Begriff vorkommt. Der Bitvektor einer Spalte gibt an, welche Begriffe in der Story erscheinen.
Zurück zu unserem ursprünglichen Problem:
(COW und BEE) oder CROWS
Wir nehmen die Bitvektoren für diese Terme und führen zuerst ein bitweises UND durch. Bitweises ODER auf das Ergebnis anwenden.
(100001 und 010011) oder 000010 = 000011
Die Antwort: „Herr Brauner Kann muu! Kannst du?“ und „The Lorax“. Dies ist eine Illustration Booleschen Abrufmodells, bei dem es sich um ein Modell vom Typ „Genau passend“ handelt.
Angenommen, wir würden die Matrix erweitern, um alle Geschichten von Dr. Seuss und alle die in den Storys relevant sind. Die Matrix würde erheblich wachsen und ein wichtiger Beobachtung ist, dass die meisten Einträge 0 wären. Eine Matrix ist wahrscheinlich nicht die beste Darstellung für den Index. Wir müssen eine Möglichkeit finden, nur die Eins zu speichern.
Einige Verbesserungen
Die in der IR verwendete Struktur zur Lösung dieses Problems wird als umgekehrter Index bezeichnet. Wir haben ein Wörterbuch mit Begriffen und erstellen dann für jeden Begriff eine Liste. die die Dokumente aufzeichnet, in denen der Begriff vorkommt. Diese Liste wird als Beiträge Liste enthalten. Eine einfach verknüpfte Liste eignet sich gut zur Darstellung dieser Struktur, wie im unten.
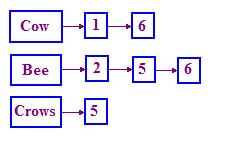
Wenn Sie mit verknüpften Listen nicht vertraut sind, suchen Sie einfach
in C++“. Es gibt viele Ressourcen, in denen erklärt wird, wie man
und wie sie verwendet werden. Dazu kommen wir in einem späteren Modul.
Beachten Sie, dass wir Dokument-IDs (DocIDs) anstelle des Namens der . Wir sortieren diese DocIDs auch, da dies die Verarbeitung von Anfragen erleichtert.
Wie wird eine Abfrage verarbeitet? Für die ursprüngliche Aufgabe suchen wir zunächst nach den COW-Plätzen. und dann auf die BEE-Postingsliste. Wir führen sie dann zusammen:
- Markierungen in beiden Listen beibehalten und die beiden Listen mit Einträgen durchgehen gleichzeitig.
- Vergleichen Sie bei jedem Schritt die DocID, auf die beide Zeiger verweisen.
- Wenn sie identisch sind, fügen Sie diese DocID in eine Ergebnisliste ein oder gehen Sie weiter zum Cursor. auf die kleinere docID.
So können wir einen umgekehrten Index erstellen:
- Weisen Sie jedem gewünschten Dokument eine DocID zu.
- Geben Sie für jedes Dokument die relevanten Begriffe an (Tokenisieren).
- Erstellen Sie für jeden Begriff einen Datensatz, der aus dem Begriff und der Dokument-ID besteht, gefunden wird, und eine Häufigkeit in diesem Dokument. Beachten Sie, dass mehrere Datensätze für einen bestimmten Begriff, wenn er in mehr als einem Dokument vorkommt.
- Sortieren Sie die Datensätze nach Begriff.
- Erstellen Sie das Wörterbuch und die Postenliste, indem Sie einzelne Datensätze für und die Datensätze für Begriffe, die häufiger vorkommen, als ein Dokument. Erstellen Sie eine verknüpfte Liste der DocIDs (in sortierter Reihenfolge). Jedes Term hat auch eine Frequenz, die die Summe der Frequenzen in allen Datensätzen ist für einen Begriff.
Das Projekt
Suchen Sie mehrere längere Klartext-Dokumente, mit denen Sie experimentieren können. Die einen umgekehrten Index aus den Dokumenten zu erstellen. beschrieben. Außerdem müssen Sie eine Schnittstelle für die Eingabe von Abfragen erstellen. und eine Suchmaschine zur Verarbeitung. Projektpartner finden Sie im Forum.
Hier ist ein möglicher Prozess zum Abschließen dieses Projekts:
- Als Erstes muss eine Strategie zur Identifizierung von Begriffen in den Dokumenten definiert werden. Erstellen Sie eine Liste aller Stoppwörter, die Ihnen einfallen, und schreiben Sie eine Funktion, liest die Wörter in den Dateien, speichert die Begriffe und eliminiert die Stoppwörter. Möglicherweise müssen Sie Ihrer Liste weitere Stoppwörter hinzufügen, während Sie die Liste der aus einer Iteration.
- Schreiben Sie CPPUnit-Testfälle, um Ihre Funktion zu testen, und ein Makefile, um alles zu übertragen für Ihren Build zu erstellen. Prüfen Sie Ihre Dateien im CSV-Format, mit Partnern zusammenarbeiten. Sie können sich darüber informieren, wie Sie Ihre CVS-Instanz öffnen können. für Remote-Engineers.
- Verarbeitung hinzufügen, um Standortdaten einzubeziehen, d. h., welche Datei und wo in der Datei ein Begriff enthält? Sie können eine Berechnung entwickeln, Seiten- oder Absatznummer.
- Schreiben Sie CPPUnit-Testfälle, um diese zusätzliche Funktionalität zu testen.
- Erstellen Sie einen umgekehrten Index und speichern Sie die Standortdaten im Datensatz jedes Begriffs.
- Schreibe mehr Testläufe.
- Entwerfen Sie eine Schnittstelle, über die Nutzende eine Abfrage eingeben können.
- Verarbeiten Sie mit dem oben beschriebenen Suchalgorithmus den umgekehrten Index und die Standortdaten an den Nutzer zurückgeben.
- Vergessen Sie nicht, auch in diesem letzten Teil Testfälle anzugeben.
Wie bei allen Projekten sollten Sie das Forum und den Chat nutzen, um Projektpartner zu finden. und Ideen zu teilen.
Eine Zusatzfunktion
Ein häufiger Verarbeitungsschritt in vielen IR-Systemen wird als Stammformreduktion bezeichnet. Die Der Grundgedanke hinter der Wortstämme besteht darin, dass Nutzer, die nach Informationen zum an Dokumenten mit Informationen wie „Abrufen“, „abruft“, „abrufen“ usw. Systeme können anfällig für Fehler sein, weil bis hin zu schlechtem Wortstamm, also ist dies ein bisschen schwierig. Beispiel: Eine Nutzerin, die sich für „Informationsabruf“ könnte ein Dokument mit dem Titel „Informationen zu Goldenen Retriever“ aufgrund von Wortstammerkennung. Ein nützlicher Algorithmus für die Wortstämme Porter-Algorithmus: