Einführung in Programmierung und C++
Diese Onlineanleitung wird mit fortgeschritteneren Konzepten fortgesetzt. Bitte lesen Sie Teil III. In diesem Modul konzentrieren wir uns auf die Verwendung von Zeigern und die ersten Schritte mit Objekten.
Lernen anhand von Beispiel 2
In diesem Modul konzentrieren wir uns darauf, mehr Übungen mit der Zerlegung, dem Verständnis von Zeigern und den ersten Schritten mit Objekten und Klassen zu sammeln. Gehen Sie die folgenden Beispiele durch. Schreiben Sie die Programme auf Wunsch selbst oder führen Sie die Experimente durch. Wir können gar nicht oft genug betonen, dass der Schlüssel zum erfolgreichen Programmieren darin besteht, Übung, Übung und Übung zu haben.
Beispiel 1: Mehr Zerlegungspraktiken
Betrachten Sie die folgende Ausgabe eines einfachen Spiels:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
Die erste Beobachtung ist der Einführungstext, der einmal pro Programm angezeigt wird. Ausführung. Wir benötigen einen Zufallszahlengenerator, um die feindliche Distanz für jedes Runde. Wir brauchen einen Mechanismus, um den Winkel vom Player zu erhalten. ist offensichtlich in einer Schleifenstruktur, da sich so lange wiederholt, bis wir den Feind treffen. Außerdem eine Funktion zur Berechnung von Entfernung und Winkel. Schließlich müssen wir den Überblick wie viele Schüsse erforderlich waren, um den Feind zu treffen, und wie viele Feinde wir haben während der Ausführung des Programms getroffen werden. Hier ist eine mögliche Gliederung für das Hauptprogramm.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
Die Fire-Prozedur übernimmt das Abspielen des Spiels. In dieser Funktion rufen wir einen Zufallszahlengenerator, um die feindliche Distanz zu ermitteln. den Input des Spielers einholen und berechnen, ob er den Feind getroffen hat oder nicht. Die Guard Condition on the Loop gibt an, wie nah wir dem Feind gekommen sind.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
Aufgrund der Aufrufe von cos() und sin() müssen Sie math.h einschließen. Ausprobieren Es ist eine gute Übung bei der Problemzerlegung und eine gute Methode, mit grundlegenden C++-Funktionen. Denken Sie daran, in jeder Funktion nur eine Aufgabe auszuführen. Dies ist die bislang ausgefeiltestes Programm, das wir bisher geschrieben haben. Zeit dafür zu haben.Hier finden Sie unsere Lösung.
Beispiel 2: Übung mit Pointern
Es gibt vier Dinge, die Sie bei der Arbeit mit Zeigern beachten sollten: <ph type="x-smartling-placeholder">- </ph>
- Mauszeiger sind Variablen, die Speicheradressen enthalten. Während ein Programm ausgeführt wird,
Alle Variablen werden im Arbeitsspeicher gespeichert, und zwar jede unter ihrer eigenen eindeutigen Adresse oder einem eigenen Speicherort.
Ein Pointer ist ein besonderer Variablentyp, der eine Speicheradresse statt
als ein Datenwert. So wie Daten bei Verwendung einer normalen Variablen geändert werden,
Der Wert der in einem Zeiger gespeicherten Adresse wird als Zeigervariable geändert.
manipuliert wird. Beispiel:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - Wir sagen normalerweise, dass ein Zeiger an den Speicherort, an dem es
(das „Pointee“). Im Beispiel oben zeigt „intptr“ auf den Pointee.
5.
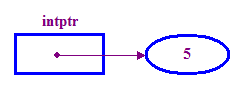
Beachten Sie, dass das neue Operator, um Speicher für unsere Ganzzahl zuzuweisen Pointee. Das müssen wir tun, bevor wir versuchen, auf den Pointee zuzugreifen.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.Der Operator * wird in C für die Dereferenzierung verwendet. Einer der häufigsten Fehler C/C++-Programmierer vergisst bei der Arbeit mit Zeigern, den Pointee. Dies kann manchmal zu einem Laufzeitabsturz führen, einen Speicherort im Arbeitsspeicher, der unbekannte Daten enthält. Wenn wir versuchen, können wir subtile Speicherbeschädigungen verursachen, wodurch es schwierig wird, den Fehler zu finden.
- Durch die Zuweisung von Zeigern zwischen zwei Zeigern zeigen sie auf denselben Zeige.
Die Zuweisung y = x; verweist y auf denselben Punkte wie x. Zeigerzuweisung
den Pointee nicht berührt. Es ändert sich nur ein Zeiger, sodass er dieselbe Position hat.
als weiteren Verweis. Nach der Zeigerzuweisung werden die beiden Zeiger geteilt. die
Pointee.

void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
Hier ist ein Trace dieses Codes:
| 1. Weisen Sie zwei Zeiger x und y zu. Das Zuweisen der Cursor keine Pointees zugewiesen. |  |
| 2. Ordnen Sie einen Pointee zu und legen Sie x so fest, dass er darauf zeigt. | 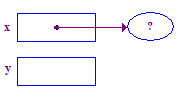 |
| 3. Entfernen Sie den Verweis x, um 42 in der Pointee zu speichern. Dies ist ein einfaches Beispiel des Dereferenzierungsvorgangs. Beginnen Sie bei x, folgen Sie dem Pfeil nach oben, um Zugriff zu erhalten den Pointee. | 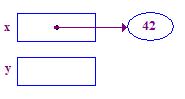 |
| 4. Versuchen Sie, den Verweis auf y zu entfernen, um 13 im Pointee zu speichern. Dies stürzt ab, weil keinen Pointee haben – ihm wurde keiner zugewiesen. | 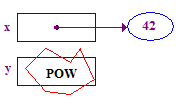 |
| 5. Zuweisen y = x; sodass y auf den Zeige von x zeigt. X und Y zeigen nun auf den gleichen Pointee - sie "teilen". | 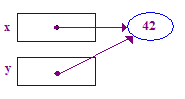 |
| 6. Versuchen Sie, den Verweis auf y zu entfernen, um 13 im Pointee zu speichern. Diesmal da die vorherige Aufgabe y einen Pointee erhalten hat. | 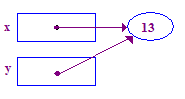 |
Bilder sind sehr hilfreich, um die Verwendung der Zeiger zu verstehen. Hier ist ein weiteres Beispiel.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
Beachten Sie, dass in diesem Beispiel nie Speicher mit der neuen . Wir haben eine normale Ganzzahlvariable deklariert und mithilfe von Zeigern bearbeitet.
In diesem Beispiel wird die Verwendung des Operators "delete" veranschaulicht, mit dem die Zuweisung von Heap-Speicher und wie wir sie komplexeren Strukturen zuweisen können. Wir werden in einer anderen Lektion. Für den Moment Stellen Sie sich den Heap als kostenlosen Speicher für laufende Programme vor.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
In diesem letzten Beispiel zeigen wir, wie Cursor verwendet werden, um Werte anhand von Verweisen zu übergeben. einer Funktion hinzugefügt. So ändern wir die Werte von Variablen innerhalb einer Funktion.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Würden wir das „&“ (&) in der Funktionsdefinition „Duplizieren“ auslassen, übergeben wir die Variablen „nach Wert“, d.h., der Wert die Variable. Alle Änderungen, die an der Variablen in der Funktion vorgenommen werden, ändern die Kopie. Die ursprüngliche Variable wird nicht geändert.
Wird eine Variable als Verweis übergeben, wird keine Kopie ihres Werts übergeben, übergeben wir die Adresse der Variablen an die Funktion. Jede Änderung, die ändern wir mit der lokalen Variablen die ursprünglich übergebene Variable.
Für C-Programmierer ist das eine ganz neue Art. Wir könnten dasselbe in C machen, Duplicate() wird deklariert wie Duplicate(int *x) In diesem Fall x ist ein Zeiger auf eine Ganzzahl, dann wird Duplicate() mit dem Argument &x (Adresse von x) aufgerufen und die Dereferenzierung von x in Duplicate() (siehe unten). C++ bietet jedoch eine einfachere Möglichkeit, Werte an Funktionen zu übergeben, indem obwohl das alte "C" dennoch funktioniert.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
Beachten Sie, dass wir bei C++-Referenzen weder die Adresse einer Variablen übergeben noch Müssen wir die Variable in der aufgerufenen Funktion dereferenzieren?
Was gibt das folgende Programm aus? Zeichne ein Bild deiner Erinnerung, um es herauszufinden.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} Starte das Programm, um zu sehen, ob du die richtige Antwort erhalten hast.
Beispiel 3: Werte anhand von Verweisen übergeben
Schreiben Sie eine Funktion namens Accelerator(), mit der die Geschwindigkeit eines Fahrzeugs und ein Betrag eingegeben werden. Die Funktion addiert den Betrag zur Beschleunigung des Fahrzeugs zur Geschwindigkeit. Der Geschwindigkeitsparameter muss als Referenz und der Betrag als Wert übergeben werden. Hier finden Sie unsere Lösung.
Beispiel 4: Klassen und Objekte
Betrachten Sie die folgende Klasse:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
Beachten Sie, dass die Variablen der Klassenmitglieder nachgestellten Unterstrich haben. Dies dient dazu, zwischen lokalen Variablen und Klassenvariablen zu unterscheiden.
Fügen Sie dieser Klasse eine Dekrement-Methode hinzu. Hier finden Sie unsere Lösung.
Die Wunder der Wissenschaft: Informatik
Übungen
Wie im ersten Modul dieses Kurses bieten wir keine Lösungen für Übungen und Projekte.
Denken Sie daran, dass ein gutes Programm...
... wird logisch in Funktionen zerlegt, bei denen eine Funktion nur eine Aufgabe erledigt.
... hat ein Hauptprogramm, das wie ein Entwurf des Programms liest.
... hat beschreibende Funktions-, Konstant- und Variablennamen.
...verwendet Konstanten, um jegliche „Magie“ zu vermeiden. im Programm gelernt haben.
... hat eine benutzerfreundliche Oberfläche.
Aufwärmübungen
- Übung 1
Die Ganzzahl 36 hat eine besondere Eigenschaft: Sie ist ein perfektes Quadrat. die Summe der Ganzzahlen von 1 bis 8. Die nächste solche Zahl ist 1225, 352 und die Summe der ganzen Zahlen von 1 bis 49 ist. Nächste Nummer finden also ein perfektes Quadrat und die Summe einer Reihe 1...n. Diese nächste Nummer kann größer als 32.767 sein. Sie können Bibliotheksfunktionen verwenden, die Sie kennen, (oder mathematische Formeln) nutzen, um die Ausführung Ihres Programms zu beschleunigen. Es ist auch möglich, dieses Programm mit for-Loops zu schreiben, um festzustellen, ob eine Zahl perfekt ist, Quadrat oder die Summe einer Reihe. (Hinweis: Je nach Rechner und Programm kann es eine Weile dauern, bis diese Zahl gefunden ist.)
- Übung 2
Ihr Buchladen benötigt Ihre Hilfe bei der Schätzung des Geschäfts für den nächsten Jahr. Die Erfahrung hat gezeigt, dass der Verkauf stark davon abhängt, ob ein Buch benötigt wird oder nicht. für einen Kurs oder nur optional, und ob er im Kurs verwendet wurde vorher. Ein neues erforderliches Lehrbuch wird an 90% der potenziellen Einschreibungen verkauft. aber wenn es schon einmal im Kurs verwendet wurde, werden nur 65% davon etwas kaufen. In ähnlicher Weise 40% der potenziellen Anmeldungen erwerben ein neues, optionales Lehrbuch. im Kurs bereits genutzt wurde, bevor nur 20% es kaufen werden. (Hinweis: „gebraucht“ bedeutet keine gebrauchten Bücher.)
Schreibe ein Programm, das eine Reihe von Büchern als Eingabe akzeptiert (bis der Nutzer eingibt). Sentinel). Für jedes Buch wird Folgendes angefordert: ein Code für das Buch, der Preis für ein einzelnes Exemplar das Buch, die aktuelle Anzahl der verfügbaren Bücher, die potenzielle Kursanmeldung, und Daten, die angeben, ob das Buch erforderlich/optional oder neu/in der Vergangenheit verwendet wurde. Als alle Eingabeinformationen in einem übersichtlichen Bildschirm zusammen mit wie viele Bücher bestellt werden müssen (falls vorhanden, beachten Sie, dass nur neue Bücher bestellt werden) die Gesamtkosten der einzelnen Bestellungen.
Nachdem alle Eingaben abgeschlossen sind, werden die Gesamtkosten für alle Buchbestellungen angezeigt. den erwarteten Gewinn, wenn das Geschäft 80% des Preises bezahlt. Da wir uns noch nicht Möglichkeiten für den Umgang mit einer großen Datenmenge besprochen, die in ein Programm einfließt (bei abgestimmt!), verarbeiten Sie einfach ein Buch nach dem anderen und zeigen den Ausgabebildschirm für dieses Buch an. Wenn der Benutzer alle Daten eingegeben hat, sollte Ihr Programm Gesamt- und Gewinnwerte.
Bevor Sie mit dem Schreiben von Code beginnen, nehmen Sie sich etwas Zeit, um über das Design dieses Programms nachzudenken. in eine Reihe von Funktionen zerlegen und eine "main()"-Funktion erstellen, die wie folgt einen Überblick über Ihre Lösung des Problems. Stellen Sie sicher, dass jede Funktion eine Aufgabe erfüllt.
Hier ist eine Beispielausgabe:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
Datenbankprojekt
In diesem Projekt erstellen wir ein voll funktionsfähiges C++ Programm, das ein einfaches Datenbankanwendung.
Mit unserem Programm können wir eine Datenbank mit Komponisten und relevanten Informationen verwalten. über sie. Zu den Programmfunktionen gehören:
- Die Möglichkeit, einen neuen Komponisten hinzuzufügen
- Die Möglichkeit, einen Komponisten zu bewerten (z.B. angeben, wie sehr wir einen Komponisten mögen oder nicht mögen) Musik des Komponisten)
- Die Möglichkeit, alle Komponisten in der Datenbank anzusehen
- Die Möglichkeit, sich alle Komponisten nach Rang anzusehen
„Es gibt zwei Möglichkeiten, Softwaredesign: Eine Möglichkeit besteht darin, es so einfach zu gestalten, Andererseits müssen die Daten so kompliziert gemacht werden, keine offensichtlichen Mängel. Die erste Methode ist weitaus schwieriger.“ – C.A.R. Hoare
Viele von uns haben mithilfe eines „verfahrenstechnischen“ Ansatz. Die zentrale Frage, mit der wir beginnen, lautet: „Was muss das Programm leisten?“. Mi. die Lösung eines Problems in Aufgaben zu zerlegen, die jeweils einen Teil das Problem zu lösen. Diese Aufgaben lassen sich Funktionen in unserem Programm zuordnen, die nacheinander aufgerufen werden. Main() oder anderen Funktionen. Diese Schritt-für-Schritt-Anleitung eignet sich die wir lösen müssen. Aber meistens sind unsere Programme nicht nur linear von Aufgaben oder Ereignissen.
Bei einem objektorientierten Ansatz (OO) beginnen wir mit der Frage: „Was für ein reales modelliere ich bestimmte Objekte?“ Anstatt ein Programm wie beschrieben in Aufgaben zu unterteilen, teilen wir sie in Modelle von physischen Objekten auf. Diese physischen Objekte haben ein Zustand, der durch eine Reihe von Attributen und eine Reihe von Verhaltensweisen oder Aktionen definiert wird, die sie ausführen können. Die Aktionen können den Status des Objekts ändern Aktionen anderer Objekte aufrufen Die Grundvoraussetzung ist, dass ein Objekt wie Aufgaben allein zu erledigen.
Beim OO-Design definieren wir physische Objekte in Form von Klassen und Objekten. Attribute und Verhaltensweisen. Ein OO-Programm enthält im Allgemeinen eine große Anzahl von Objekten. Viele dieser Objekte sind jedoch im Wesentlichen identisch. Hier einige Tipps:
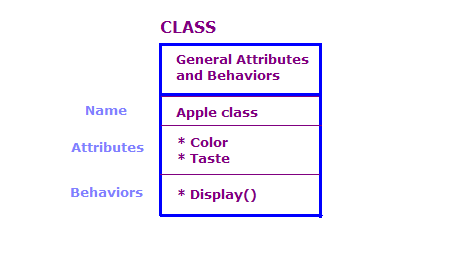
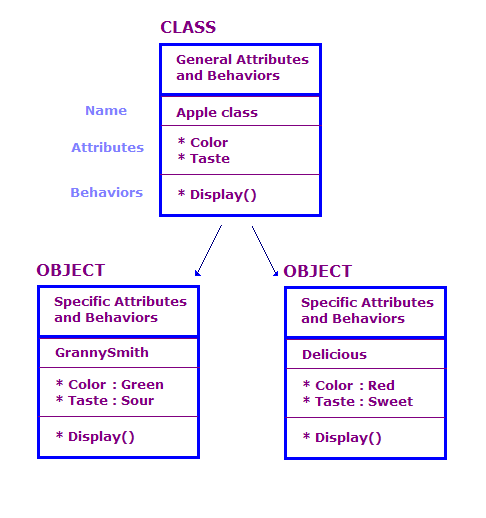
In diesem Diagramm haben wir zwei Objekte der Apple-Klasse definiert. Jedes Objekt hat dieselben Attribute und Aktionen wie die Klasse, aber das Objekt definiert die Attribute für eine bestimmte Apfelsorte. Darüber hinaus enthält das Display Aktion zeigt die Attribute für das jeweilige Objekt an, z.B. „Grün“ und „Sour“.
Ein OO-Design besteht aus einer Reihe von Klassen, den Daten, die mit diesen Klassen verknüpft sind, und die Aktionen, die die Klassen durchführen können. Außerdem müssen wir die wie verschiedene Klassen interagieren. Diese Interaktion kann von Objekten ausgeführt werden, einer Klasse, die Aktionen von Objekten anderer Klassen aufruft. Zum Beispiel eine AppleOutputer-Klasse haben, die die Farbe und den Geschmack eines Arrays ausgibt von Apple-Objekten, indem Sie die Display()-Methode jedes Apple-Objekts aufrufen.
Beim OO-Design sind folgende Schritte erforderlich:
- Identifizieren Sie die Klassen und definieren Sie allgemein, was ein Objekt der einzelnen Klassen ist. als Daten gespeichert werden und was ein Objekt tun kann.
- Die Datenelemente jeder Klasse definieren
- Die Aktionen jeder Klasse definieren und festlegen, wie einige Aktionen einer Klasse ausgeführt werden können
mithilfe von Aktionen anderer verwandter Klassen implementiert werden.
Bei einem großen System werden diese Schritte iterativ auf verschiedenen Detailebenen ausgeführt.
Für das Composer-Datenbanksystem benötigen wir eine Composer-Klasse, die alle die wir für einen einzelnen Composer speichern möchten. Ein Objekt dieser Klasse kann sich selbst hoch- oder herabstufen (ändernden Rang) und seine Attribute anzeigen.
Außerdem wird eine Sammlung von Composer-Objekten benötigt. Dafür definieren wir eine Datenbankklasse der die einzelnen Unterlagen verwaltet. Mit einem Objekt dieser Klasse können Composer-Objekte erstellen und einzelne Objekte anzeigen lassen, indem Sie die Anzeigeaktion des Composer-Objekt.
Schließlich benötigen wir eine Art von Benutzeroberfläche, um interaktive Operationen bereitzustellen. in der Datenbank. Dies ist eine Platzhalterklasse, d.h. wir wissen wirklich nicht, Benutzeroberfläche wird noch aussehen, aber wir wissen, dass wir eine brauchen werden. Vielleicht grafisch, vielleicht auch textbasiert. Fürs Erste definieren wir einen Platzhalter, die wir später ausfüllen können.
Nachdem wir nun die Klassen für die Composer-Datenbankanwendung identifiziert haben, definieren Sie als Nächstes die Attribute und Aktionen für die Klassen. In einem eine komplexe Anwendung, setzen wir uns mit Bleistift und Papier UML oder CRC-Karten oder außerhalb der Geschäftstätigkeit um die Klassenhierarchie und die Interaktion der Objekte darzustellen.
Für unsere Composer-Datenbank definieren wir eine Composer-Klasse, die die relevanten die wir in jedem Composer speichern möchten. Sie enthält auch Methoden zur Bearbeitung und die Daten anzuzeigen.
Die Datenbankklasse benötigt eine Struktur zur Aufnahme von Composer-Objekten. Wir müssen in der Lage sein, der Struktur ein neues Composer-Objekt hinzuzufügen ein bestimmtes Composer-Objekt abzurufen. Wir möchten auch alle Objekte anzeigen, in der Reihenfolge des Beitrags oder nach dem Ranking.
Die User Interface-Klasse implementiert eine menügesteuerte Schnittstelle mit Handlern, die in der Klasse "Datenbank" aufrufen.
Wenn die Klassen leicht verständlich sind und ihre Attribute und Aktionen eindeutig sind, wie in der Composer-Anwendung ist es relativ einfach, die Klassen zu entwerfen. Aber ob Sie Fragen dazu haben, wie die Klassen zusammenhängen und interagieren, zuerst skizzieren und die Details durcharbeiten, bevor Sie beginnen. zu programmieren.
Sobald wir ein klares Bild vom Design haben und es bewertet haben (mehr dazu definieren wir die Schnittstelle für jede Klasse. Wir kümmern uns nicht um die was sind die Attribute und Aktionen, eines Kurses“ Status und Aktionen sind auch für andere Klassen verfügbar.
In C++ definieren wir hierfür normalerweise eine Headerdatei für jede Klasse. Der Komponist -Klasse hat private Daten-Member für alle Daten, die wir in einem Composer speichern möchten. Wir benötigen Zugriffsfunktionen ("get"-Methoden) und Mutatoren ("set"-Methoden) sowie die primären Aktionen für den Kurs.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
Auch die Datenbankklasse ist unkompliziert.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
Wie Sie sehen, haben wir die komponistenspezifischen Daten sorgfältig in einem separaten . Wir hätten eine Struktur oder Klasse in die Datenbankklasse einfügen können, um die Composer-Eintrag erstellt und direkt darauf zugegriffen haben. Aber das wäre „Unter-Objektivierung“, d.h., wir modellieren nicht so sehr mit Objekten wie möglich.
Sie werden sehen, wenn Sie mit der Implementierung von Composer und Database beginnen. , dass eine separate Composer-Klasse viel übersichtlicher ist. Insbesondere separate atomare Vorgänge für ein Composer-Objekt vereinfachen die Implementierung erheblich. Display()-Methoden in der Datenbankklasse.
Natürlich gibt es auch so etwas wie „Über-Objektifizierung“, Wo? versuchen wir, alles zu einer Klasse zu machen, oder wir haben mehr Klassen, als wir benötigen. Es ist notwendig, um die richtige Balance zu finden, und Sie werden feststellen, unterschiedliche Meinungen haben.
Wenn Sie herausfinden möchten, ob Sie zu sehr oder zu wenig objektiv sind, indem Sie Ihre Klassendiagramme erstellen. Wie bereits erwähnt, ist es wichtig, einen Kurs bevor Sie mit dem Programmieren beginnen. Dies kann Ihnen bei der Analyse Ihres Ansatzes helfen. Eine gemeinsame Notation verwendet wird, UML (Unified Modeling Language) Nachdem Sie nun die Klassen für die Composer- und die Database-Objekte definiert haben, müssen wir eine Schnittstelle, über die Nutzende mit der Datenbank interagieren können. Ein einfaches Menü es funktioniert:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Wir könnten die Benutzeroberfläche als Klasse oder als verfahrenstechnisches Programm implementieren. Nicht Alles in einem C++-Programm muss eine Klasse sein. Wenn die Verarbeitung sequentiell ist, oder aufgabenorientiert, wie bei diesem Menüprogramm, kann es prozessbezogen implementiert werden. Es ist wichtig, es so zu implementieren, dass es ein „Platzhalter“, Wenn wir also irgendwann eine grafische Benutzeroberfläche erstellen möchten, Sie brauchen nur die Benutzeroberfläche zu ändern.
Zum Abschluss der Bewerbung müssen wir als Letztes ein Programm zum Testen der Klassen erstellen. Für die Composer-Klasse wollen wir ein "main()"-Programm, das Eingaben annimmt, ein composer-Objekt und zeigt es dann an, um sicherzustellen, dass die Klasse ordnungsgemäß funktioniert. Außerdem möchten wir alle Methoden der Composer-Klasse aufrufen.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Wir benötigen ein ähnliches Testprogramm für die Datenbankklasse.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
Diese einfachen Testprogramme sind ein guter erster Schritt, erfordern aber um die Ausgabe manuell zu überprüfen, um sicherzustellen, dass das Programm ordnungsgemäß funktioniert. Als ein System größer wird, erschwert die manuelle Ergebnisprüfung schnell unpraktisch. In einer nachfolgenden Lektion stellen wir Testprogramme zur Selbstkontrolle vor. von Einheitentests.
Das Design für unsere Anwendung ist nun fertig. Im nächsten Schritt implementieren Sie die CPP-Dateien für die Klassen und die Benutzeroberfläche.Um zu beginnen, fahren Sie fort und Kopieren Sie den oben gezeigten .h- und den Testtreibercode in Dateien, fügen Sie ihn ein und kompilieren Sie diese.Verwenden Sie Testfahrern, die eure Klassen testen. Implementieren Sie dann die folgende Schnittstelle:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Verwenden Sie die in der Datenbankklasse definierten Methoden, um die Benutzeroberfläche zu implementieren. Machen Sie Ihre Methoden fehlersicher. Ein Ranking sollte beispielsweise immer im Bereich 1–10. Lassen Sie auch nicht 101 Komponisten hinzufügen, es sei denn, Sie möchten die Datenstruktur in der Datenbankklasse.
Denken Sie daran: Ihr gesamter Code muss unseren Codierungskonventionen entsprechen, die wiederholt werden. hier für Sie:
- Jedes Programm, das wir schreiben, beginnt mit einem Kommentar in der Kopfzeile, in dem der Name der den Autor, seine Kontaktdaten, eine kurze Beschreibung und die Verwendung (falls zutreffend) Jede Funktion bzw. Methode beginnt mit einem Kommentar zum Vorgang und ihrer Verwendung.
- Wir fügen erklärende Kommentare in vollständigen Sätzen hinzu, wenn der Code nicht selbst dokumentieren, z. B. wenn die Verarbeitung schwierig, nicht offensichtlich ist, interessant oder wichtig sind.
- Verwenden Sie immer aussagekräftige Namen: Variablen sind kleingeschriebene Wörter, die durch _, wie in my_variable. In Funktions-/Methodennamen werden Großbuchstaben verwendet, wie in MyExcitingFunction(). Konstanten beginnen mit einem „k“ und verwenden Sie Großbuchstaben zum Markieren von Wörtern, wie in kDaysInWeek.
- Der Einzug ist ein Vielfaches von zwei. Die erste Ebene besteht aus zwei Leerzeichen. falls weiter Einrückung erforderlich. Wir verwenden vier Leerzeichen, sechs Leerzeichen usw.
Willkommen in der realen Welt!
In diesem Modul stellen wir zwei sehr wichtige Tools vor, die in den meisten Unternehmen. Das erste ist ein Build-Tool und das zweite das Konfigurationsmanagement. System. Beide Tools sind unverzichtbar in der industriellen Softwareentwicklung. arbeiten viele Engineers oft an einem großen System. Diese Tools helfen bei der Koordination und Änderungen an der Codebasis zu kontrollieren und eine effiziente Möglichkeit für die Kompilierung und die Verknüpfung eines Systems aus vielen Programm- und Header-Dateien.
Makefiles
Der Prozess der Programmerstellung wird in der Regel mit einem Build-Tool verwaltet, das und verknüpft die erforderlichen Dateien in der richtigen Reihenfolge. Häufig werden C++-Dateien Eine Funktion, die in einem Programm aufgerufen wird, befindet sich beispielsweise in einem anderen . Oder vielleicht wird eine Header-Datei von mehreren verschiedenen CPP-Dateien benötigt. A das Build-Tool die richtige Kompilierungsreihenfolge aus diesen Abhängigkeiten ermittelt. Damit Außerdem werden nur Dateien kompiliert, die seit dem letzten Build geändert wurden. Dadurch können Sie in Systemen, die aus Hunderten oder Tausenden von Dateien bestehen.
Ein Open-Source-Build-Tool namens Make wird häufig verwendet. Um mehr darüber zu erfahren, lesen Sie über diese Artikel. Prüfen Sie, ob Sie ein Abhängigkeitsdiagramm für die Composer-Datenbankanwendung erstellen können. und wandeln sie in ein Makefile um.Hier finden Sie unsere Lösung.
Konfigurationsverwaltungssysteme
Das zweite Tool in der industriellen Softwareentwicklung ist die Konfigurationsverwaltung. (CM). Wird verwendet, um Änderungen zu verwalten. Angenommen, Bob und Susan sind beide Tech-Schreibende und arbeiten an der Aktualisierung eines technischen Handbuchs. Während eines Meetings weist der Manager jedem Abschnitt des Dokuments zu, das aktualisiert werden soll.
Das technische Handbuch ist auf einem Computer gespeichert, auf den sowohl Robert als auch Susan zugreifen können. Ohne ein CM-Tool oder einen entsprechenden Prozess können viele Probleme auftreten. Eins dass der Computer, auf dem das Dokument gespeichert wird, so eingerichtet ist, Max und Susanne können nicht gleichzeitig an der Bedienungsanleitung arbeiten. Dies würde sich verlangsamen erheblich reduzieren.
Eine gefährlichere Situation entsteht, wenn der Speichercomputer das Dokument zulässt. von Bob und Susan gleichzeitig geöffnet. Folgendes könnte passieren:
- Max öffnet das Dokument auf seinem Computer und arbeitet an seinem Abschnitt.
- Susanne öffnet das Dokument auf ihrem Computer und arbeitet an ihrem Abschnitt.
- Max schließt seine Änderungen ab und speichert das Dokument auf dem Speichercomputer.
- Susan schließt die Änderungen ab und speichert das Dokument auf dem Computer.
Diese Abbildung zeigt das Problem, das auftreten kann, wenn keine Steuerelemente vorhanden sind des technischen Handbuchs. Wenn Susan ihre Änderungen speichert, überschreibt die von Bob erstellt.

Genau diese Art von Situation kann ein CM-System steuern. Mit einem Community Manager sehen Sie sich Bob und Susan an eine Kopie der technischen und arbeiten an ihnen. Wenn Bob die Änderungen überprüft, weiß das System, dass Susan ihr eigenes Exemplar gelesen hat. Wenn Susan Wojcicki ihre Kopie einschaut, zeigt das System analysiert die Änderungen, die Bob und Susan vorgenommen haben, und erstellt eine neue Version, führt die beiden Änderungssätze zusammen.
CM-Systeme bieten neben dem Verwalten gleichzeitiger Änderungen eine Reihe von Funktionen. oben. Viele Systeme speichern Archive aller Versionen eines Dokuments, angefangen beim ersten Zeitpunkt der Erstellung. Bei einem technischen Handbuch kann dies sehr hilfreich sein, Nutzende haben eine alte Version des Handbuchs und stellen Fragen an einen technischen Redakteur. Mit einem CM-System könnte der technische Redakteur auf die alte Version zugreifen um zu sehen, was der Nutzer sieht.
CM-Systeme sind besonders nützlich, um Änderungen an Software zu steuern. Ein solches werden als Software Configuration Management-Systeme (SCM) bezeichnet. Wenn Sie in Betracht ziehen, einer großen Softwareentwicklungsplattform Unternehmen und der großen Anzahl von Engineering-Fachleuten, die Änderungen vornehmen müssen, dass ein SCM-System von entscheidender Bedeutung ist.
Softwarekonfigurationsverwaltung
SCM-Systeme basieren auf einem einfachen Prinzip: den endgültigen Kopien Ihrer Dateien in einem zentralen Repository gespeichert. Die Leute bezahlen die Dateikopien aus dem Repository, diese Kopien zu bearbeiten und sie dann noch einmal einzureichen, wenn sie fertig sind. SCM Systeme verwalten und verfolgen Überarbeitungen von mehreren Personen auf einer einzigen Master-Instanz. festgelegt.
Alle SCM-Systeme bieten die folgenden grundlegenden Funktionen:
- Gleichzeitigkeitsmanagement
- Versionsverwaltung
- Synchronisierung
Sehen wir uns diese Funktionen einmal genauer an.
Gleichzeitigkeitsmanagement
Als Parallelität wird die gleichzeitige Bearbeitung einer Datei durch mehrere Personen bezeichnet. Bei einem großen Repository sollten auf einige Probleme hin.
Nehmen wir ein einfaches Beispiel aus dem Engineering-Bereich: Angenommen, wir erlauben Entwicklern, , um dieselbe Datei gleichzeitig in einem zentralen Repository mit Quellcode zu bearbeiten. Client1 und Client2 müssen gleichzeitig Änderungen an einer Datei vornehmen:
- Client1 öffnet bar.cpp.
- Client2 öffnet bar.cpp.
- Client1 ändert die Datei und speichert sie.
- Client2 ändert die Datei und speichert sie und überschreibt die Änderungen von Client1.
Das wollen wir natürlich nicht. Selbst wenn wir die Situation durch die beiden Ingenieure an separaten Kopien arbeiten anstatt direkt an einem Master festgelegt ist (wie in der nachfolgenden Abbildung), müssen die Kopien irgendwie abgeglichen werden. Meiste SCM-Systeme lösen dieses Problem, indem sie es mehreren Entwicklern ermöglichen, eine Datei zu prüfen. ("synchronisieren" oder "aktualisieren") und nehmen Sie bei Bedarf Änderungen vor. Die SCM führt das System Algorithmen aus, um die Änderungen zusammenzuführen, sobald die Dateien erneut überprüft werden. („Senden“ oder „Commit“) an das Repository senden.
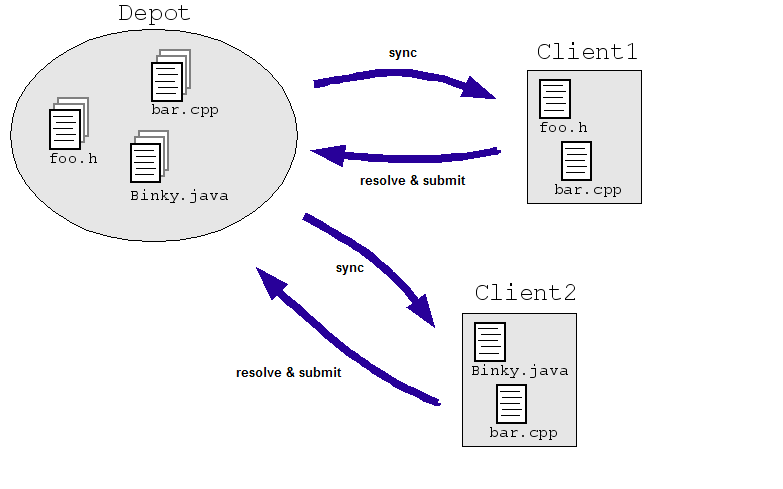
Diese Algorithmen können einfach sein. (Bitte die Entwickler, Änderungskonflikte zu beheben.) oder nicht ganz einfach (bestimmen, wie sich die in Konflikt stehenden Änderungen intelligent zusammenführen lassen) und nur einen Techniker fragen, wenn das System wirklich nicht weiterkommt).
Versionsverwaltung
Die Versionsverwaltung bezieht sich auf die Verfolgung von Dateiüberarbeitungen, wodurch es möglich ist, eine frühere Version der Datei neu erstellen oder ein Rollback darauf durchführen. Dies geschieht entweder indem Sie eine Archivkopie jeder Datei erstellen, wenn sie in das Repository eingecheckt wird, oder alle Änderungen speichern, die an einer Datei vorgenommen wurden. Wir können die Archive jederzeit verwenden, oder ändern Sie Informationen, um eine frühere Version zu erstellen. Versionsverwaltungssysteme können auch Protokollberichte darüber zu erstellen, wer Änderungen eingecheckt hat, wann und was passiert die Änderungen waren.
Synchronisierung
Bei einigen SCM-Systemen werden einzelne Dateien in das Repository eingecheckt und daraus entfernt. Mit leistungsstärkeren Systemen können Sie mehrere Dateien gleichzeitig ansehen. Ingenieure sich eine eigene, vollständige Kopie des Repositorys (oder Teile davon) und die Arbeit ansehen, bei Bedarf bearbeiten. Die Änderungen werden dann im Master-Repository festgehalten regelmäßig aktualisieren und ihre eigenen persönlichen Kopien aktualisieren, um über Änderungen auf dem Laufenden zu bleiben. die andere gemacht haben. Dieser Vorgang wird als Synchronisierung oder Aktualisierung bezeichnet.
Marinieren
Subversion (SVN) ist ein Open-Source-Versionsverwaltungssystem. Es hat alle die oben beschriebenen Funktionen nutzen.
SVN verwendet eine einfache Methode, wenn Konflikte auftreten. Ein Konflikt tritt auf, wenn zwei oder mehr Engineers unterschiedliche Änderungen am selben Bereich der Codebasis vornehmen senden beide ihre Änderungen. SVN warnt nur die Entwickler, dass es eine ist es Aufgabe der Ingenieure, diesen zu lösen.
In diesem Kurs verwenden wir SVN, Konfigurationsverwaltung. Solche Systeme sind in der Branche sehr verbreitet.
Der erste Schritt besteht darin, SVN auf Ihrem System zu installieren. Klicken Sie auf hier für Anleitung. Suchen Sie Ihr Betriebssystem und laden Sie das entsprechende Binärprogramm herunter.
Einige SVN-Terminologie
- Überarbeitung: Eine Änderung in einer Datei oder einem Satz von Dateien. Eine Überarbeitung ist ein "Snapshot" in einem sich ständig verändernden Projekt zu verstehen.
- Repository: Die Masterkopie, in der SVN den vollständigen Überarbeitungsverlauf eines Projekts speichert. Jedes Projekt hat ein Repository.
- Arbeitskopie: Die Kopie, in der ein Entwickler Änderungen an einem Projekt vornimmt. Es können viele Arbeitskopien eines bestimmten Projekts sein, die jeweils einem einzelnen Engineering-Team gehören.
- Auschecken: Fordern Sie eine Arbeitskopie aus dem Repository an. Eine Arbeitskopie dem Status des Projekts zum Zeitpunkt des Auscheckens entspricht.
- Commit: Zum Senden von Änderungen aus Ihrer Arbeitskopie an das zentrale Repository. Auch als „Einchecken“ oder „Senden“ bezeichnet.
- Update: Um die aus dem Repository in Ihre Arbeitskopie übertragen, oder um anzuzeigen, ob Ihre Arbeitskopie Änderungen ohne Commit enthält. Dies ist die wie oben beschrieben. Durch Aktualisieren/Synchronisieren wird Ihre Arbeitskopie mit der Repository-Kopie aktuell sind.
- Konflikt: Eine Situation, in der zwei Entwickler versuchen, Änderungen für denselben Bereich einer Datei. SVN weist auf Konflikte hin, aber die Entwickler müssen diese beheben.
- Protokollnachricht: Ein Kommentar, den Sie beim Commit an eine Überarbeitung anhängen und die beschreibt Ihre Änderungen. Das Protokoll enthält eine Zusammenfassung der Vorgänge in einem Projekt.
Nachdem Sie SVN installiert haben, werden wir einige grundlegende Befehle ausführen. Die müssen Sie als Erstes ein Repository in einem bestimmten Verzeichnis einrichten. Hier sind die Befehle:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
Mit dem Befehl import wird der Inhalt des Verzeichnisses mytree in den Verzeichnisprojekt im Repository. Wir können einen Blick auf das Verzeichnis Repository mit dem Befehl list
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
Beim Import wird keine Arbeitskopie erstellt. Dazu müssen Sie die Methode svn Checkout ein. Dadurch wird eine Arbeitskopie der Verzeichnisstruktur erstellt. Lassen Sie uns tun Sie das jetzt:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
Nachdem Sie nun über eine Arbeitskopie verfügen, können Sie Änderungen an den Dateien und Verzeichnissen vornehmen . Ihre Arbeitskopie ist genau wie jede andere Sammlung von Dateien und Verzeichnissen. - Sie können neue hinzufügen, bearbeiten, verschieben und sogar die gesamte Arbeitskopie. Wenn Sie Dateien in Ihrer Arbeitskopie kopieren und verschieben, müssen Sie svn copy und svn Move verwenden, statt Betriebssystembefehle. Um eine neue Datei hinzuzufügen, verwenden Sie svn add, um die Datei zu löschen. Für eine Datei verwenden Sie svn delete. Wenn Sie nur die Datei bearbeiten möchten, öffnen Sie -Datei mit Ihrem Editor und bearbeiten Sie weg!
Es gibt einige Standardverzeichnisnamen, die häufig in Verbindung mit Subversion verwendet werden. Der „Stamm“ Verzeichnis die die Hauptentwicklungslinie Ihres Projekts enthält. Ein „Zweige“ Verzeichnis enthält jede Zweigversion, an der Sie arbeiten.
$ svn list file:///usr/local/svn/repos /trunk /branches
Nehmen wir also an, Sie haben alle erforderlichen Änderungen an Ihrer Arbeitskopie vorgenommen und mit dem Repository synchronisieren möchten. Wenn viele andere Entwickler in diesem Bereich des Repositorys müssen, ist es wichtig, dass Sie Ihre Arbeitskopie auf dem neuesten Stand halten. Mit dem Befehl svn status können Sie sich die Änderungen anzeigen lassen, gemacht.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
Für den Statusbefehl gibt es viele Flags, mit denen diese Ausgabe gesteuert wird. Wenn Sie sich die einzelnen Änderungen in einer geänderten Datei ansehen möchten, verwenden Sie svn diff.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...Abschließend verwenden Sie den Befehl svn update, um Ihre Arbeitskopie aus dem Repository zu aktualisieren.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
An dieser Stelle kann es zu Konflikten kommen. In der obigen Ausgabe ist das „U“ bedeutet, Es wurden keine Änderungen an den Repository-Versionen dieser Dateien vorgenommen und es wurde ein Update erledigt wurde. Das „G“ bedeutet, dass eine Zusammenführung stattgefunden hat. Die Repository-Version hatte wurden geändert, aber die Änderungen stehen nicht in Konflikt mit Ihren. Das „C“ bedeutet, Konflikt. Das bedeutet, dass sich die Änderungen aus dem Repository mit Ihren überschnitten haben. und jetzt müssen Sie zwischen ihnen wählen.
Für jede Datei mit einem Konflikt werden in Subversion drei Dateien kopieren:
- file.mine: Dies ist die Datei, wie sie bereits in der Arbeitskopie vorhanden war. hat Ihre Arbeitskopie aktualisiert.
- file.rOLDREV: Dies ist die Datei, die Sie vor der Prüfung aus dem Repository und Ihre Änderungen vornehmen.
- file.rNEWREV: Diese Datei ist die aktuelle Version im Repository.
Es gibt drei Möglichkeiten, den Konflikt zu lösen:
- Gehen Sie die Dateien durch und führen Sie die Zusammenführung manuell durch.
- Kopieren Sie eine der von SVN erstellten temporären Dateien in Ihre Arbeitskopie.
- Führen Sie svn reset aus, um alle Änderungen zu verwerfen.
Sobald Sie den Konflikt gelöst haben, teilen Sie SVN mit, indem Sie svn erkannt ausführen. Dadurch werden die drei temporären Dateien entfernt und SVN sieht die Datei nicht mehr in einem Konfliktstatus
Als Letztes müssen Sie Ihre endgültige Version per Commit im Repository speichern. Dieses mit dem Befehl svn commit. Wenn Sie eine Änderung durchführen, müssen Sie ein, um eine Protokollnachricht mit einer Beschreibung Ihrer Änderungen bereitzustellen. Diese Lognachricht ist angehängt für die von Ihnen erstellte Überarbeitung.
svn commit -m "Update files to include new headers."
Es gibt noch viel mehr über SVN zu erfahren und wie es große Software unterstützen kann Engineering-Projekten. Im Web stehen umfangreiche Ressourcen zur Verfügung. eine Google-Suche nach "Subversion".
Erstellen Sie zur Übung ein Repository für Ihr Composer-Datenbanksystem und importieren Sie all Ihre Dateien. Sehen Sie sich dann eine funktionierende Kopie an und folgen Sie den beschriebenen Befehlen. oben.
Verweise
Anwendung: Eine Anatomiestudie
Sieh dir eSkeletons von der Universität an aus Texas in Austin