Nel tutorial precedente (Introduzione), abbiamo visto come gli incorporamenti satellitari acquisiscono le traiettorie annuali delle osservazioni satellitari e delle variabili climatiche. In questo modo, il set di dati è facilmente utilizzabile per la mappatura delle colture senza la necessità di modellare la fenologia delle colture. La mappatura dei tipi di colture è un'attività impegnativa che in genere richiede la modellazione della fenologia delle colture e la raccolta di campioni di campo per tutte le colture coltivate nella regione.
In questo tutorial, adotteremo un approccio di classificazione non supervisionata alla mappatura delle colture che ci consente di eseguire questa complessa attività senza fare affidamento sulle etichette dei campi. Questo metodo sfrutta la conoscenza locale della regione insieme alle statistiche aggregate sulle colture, che sono facilmente disponibili per molte parti del mondo.
Seleziona una regione
Per questo tutorial, creeremo una mappa del tipo di coltura per la contea di Cerro Gordo, Iowa. Questa contea si trova nella cintura del mais degli Stati Uniti, che ha due colture principali: mais e soia. Queste conoscenze locali sono importanti e ci aiuteranno a decidere i parametri chiave del nostro modello.
Iniziamo ottenendo il confine della contea scelta.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

Figura: regione selezionata
Prepara il set di dati di incorporamento satellitare
Successivamente, carichiamo il set di dati Satellite Embedding, filtriamo le immagini per l'anno scelto e creiamo un mosaico.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
Creare una maschera di colture
Per la nostra modellazione, dobbiamo escludere le aree non coltivate. Esistono molti set di dati globali e regionali che possono essere utilizzati per creare una maschera di ritaglio. ESA WorldCover o GFSAD Global Cropland Extent Product sono ottime scelte per i set di dati globali sulle colture. Un'aggiunta più recente è il prodotto ESA WorldCereal Active Cropland, che include la mappatura stagionale dei terreni coltivati attivi. Poiché la nostra regione si trova negli Stati Uniti, possiamo utilizzare un set di dati regionale più accurato, USDA NASS Cropland Data Layers (CDL), per ottenere una maschera delle colture.
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
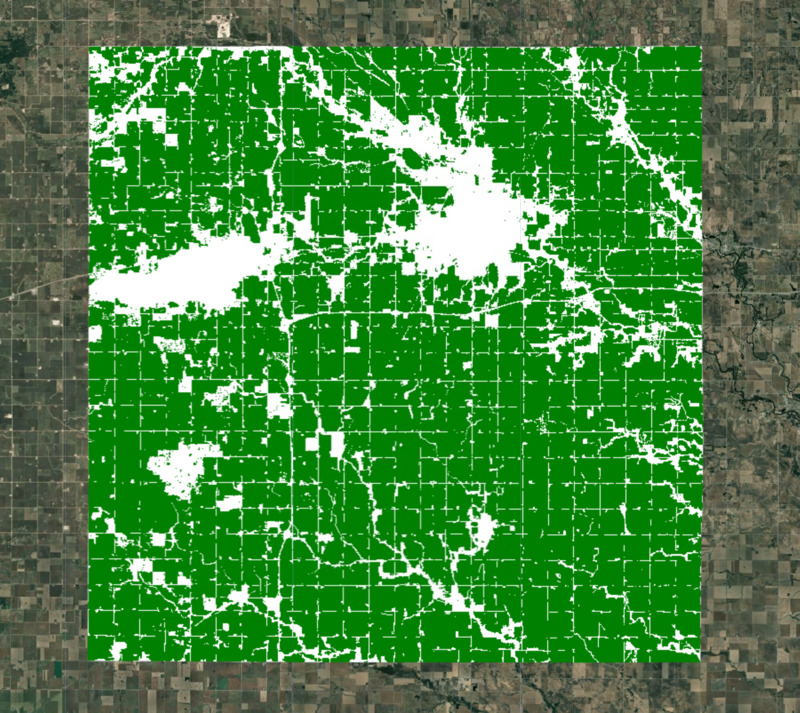
Figura: regione selezionata con maschera di terreni coltivati
Estrai esempi di addestramento
Applichiamo la maschera delle colture al mosaico degli incorporamenti. Ora rimangono tutti i pixel che rappresentano i terreni coltivati della contea.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
Dobbiamo prendere l'immagine dell'incorporamento satellitare e ottenere campioni casuali per addestrare un modello di clustering. Poiché la nostra regione di interesse contiene molti pixel mascherati, un semplice campionamento casuale potrebbe generare campioni con valori nulli. Per assicurarci di poter estrarre il numero desiderato di campioni non nulli, utilizziamo il campionamento stratificato per ottenere il numero desiderato di campioni nelle aree non mascherate.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
Esportare un campione in un asset (facoltativo)
L'estrazione dei campioni è un'operazione costosa dal punto di vista computazionale ed è una buona pratica esportare i campioni di addestramento estratti come asset e utilizzare gli asset esportati nei passaggi successivi. In questo modo, potrai superare gli errori Calcolo scaduto o Memoria utente superata quando lavori con regioni di grandi dimensioni.
Avvia l'attività di esportazione e attendi il completamento prima di procedere.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
Una volta completata l'attività di esportazione, possiamo leggere nuovamente i campioni estratti nel nostro codice come raccolta di caratteristiche.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
Visualizzare i campioni
Che tu abbia eseguito il campionamento in modo interattivo o esportato in una raccolta di funzionalità, ora avrai una variabile di addestramento con i punti di campionamento. Stampiamo il primo campione per ispezionarlo e aggiungere i nostri punti di addestramento al Map.
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

Figura: campioni casuali estratti per il clustering
Esegui il clustering non supervisionato
Ora possiamo addestrare un clusterizzatore e raggruppare i vettori di incorporamento 64D in un numero scelto di cluster distinti. In base alle nostre conoscenze locali, esistono due tipi principali di colture che rappresentano la maggior parte dell'area, mentre diverse altre colture coprono la frazione rimanente. Possiamo eseguire il clustering non supervisionato sull'incorporamento satellitare per ottenere cluster di pixel con traiettorie e pattern temporali simili. I pixel con caratteristiche spettrali e spaziali simili, nonché una fenologia simile, verranno raggruppati nello stesso cluster.
ee.Clusterer.wekaCascadeKMeans() ci consente di specificare un numero minimo e massimo di cluster e di trovare il numero ottimale di cluster in base ai dati di addestramento. Qui le nostre conoscenze locali si rivelano utili per decidere il numero minimo e massimo di cluster. Poiché prevediamo alcuni tipi distinti di cluster (mais, soia e diverse altre colture), possiamo utilizzare 4 come numero minimo di cluster e 5 come numero massimo di cluster. Potresti dover sperimentare con questi numeri per scoprire cosa funziona meglio per la tua regione.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
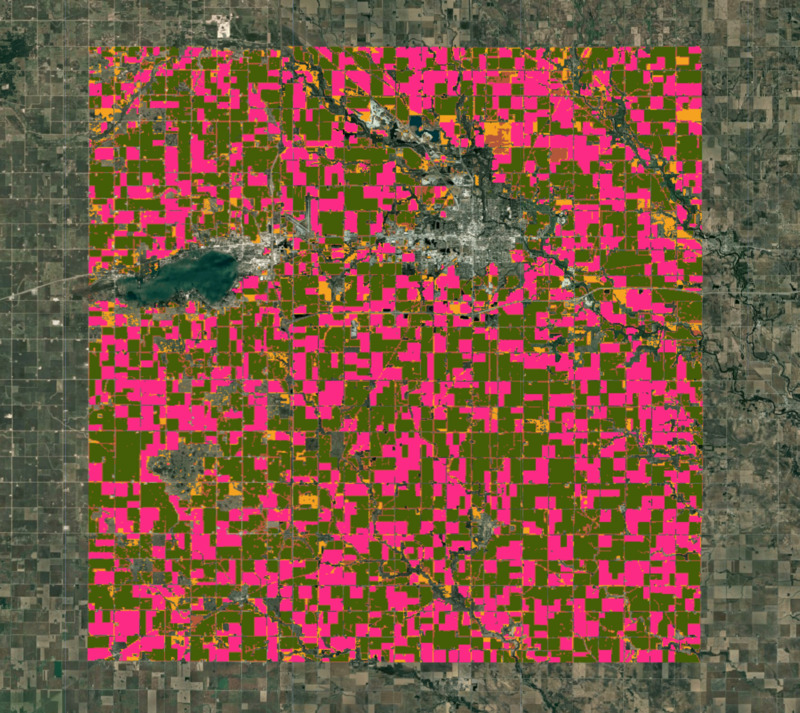
Figura: cluster ottenuti dalla classificazione non supervisionata
Assegnare etichette ai cluster
A un esame visivo, i cluster ottenuti nei passaggi precedenti corrispondono quasi perfettamente ai confini della fattoria visibili nell'immagine ad alta risoluzione. Sappiamo, grazie alle conoscenze locali, che i due cluster più grandi sono quelli di mais e soia. Calcoliamo le aree di ogni cluster nell'immagine.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
Selezioniamo i due cluster con l'area più ampia.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
Tuttavia, non sappiamo ancora quale cluster corrisponde a quale coltura. Se avessi alcuni campioni di campo di mais o soia, potresti sovrapporli ai cluster per capire le rispettive etichette. In assenza di campioni di campo, possiamo sfruttare le statistiche aggregate sui raccolti. In molte parti del mondo, le statistiche aggregate sui raccolti vengono raccolte e pubblicate regolarmente. Per gli Stati Uniti, il National Agricultural Statistics Service (NASS) dispone di statistiche dettagliate sulle colture per ogni contea e per ogni coltura principale. Per l'anno 2022, la contea di Cerro Gordo, Iowa, aveva una superficie coltivata a mais di 65.350 ettari e una superficie coltivata a soia di 44.720 ettari.
Grazie a queste informazioni, ora sappiamo che tra i primi due cluster, quello con l'area più grande sarà molto probabilmente il mais e l'altro la soia. Assegniamo queste etichette e confrontiamo le aree calcolate con le statistiche pubblicate.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
Creare una mappa delle colture
Ora conosciamo le etichette per ogni cluster e possiamo estrarre i pixel per ogni tipo di coltura e unirli per creare la mappa finale delle colture.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
Per facilitare l'interpretazione dei risultati, possiamo anche utilizzare gli elementi dell'interfaccia utente per creare e aggiungere una legenda alla mappa.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
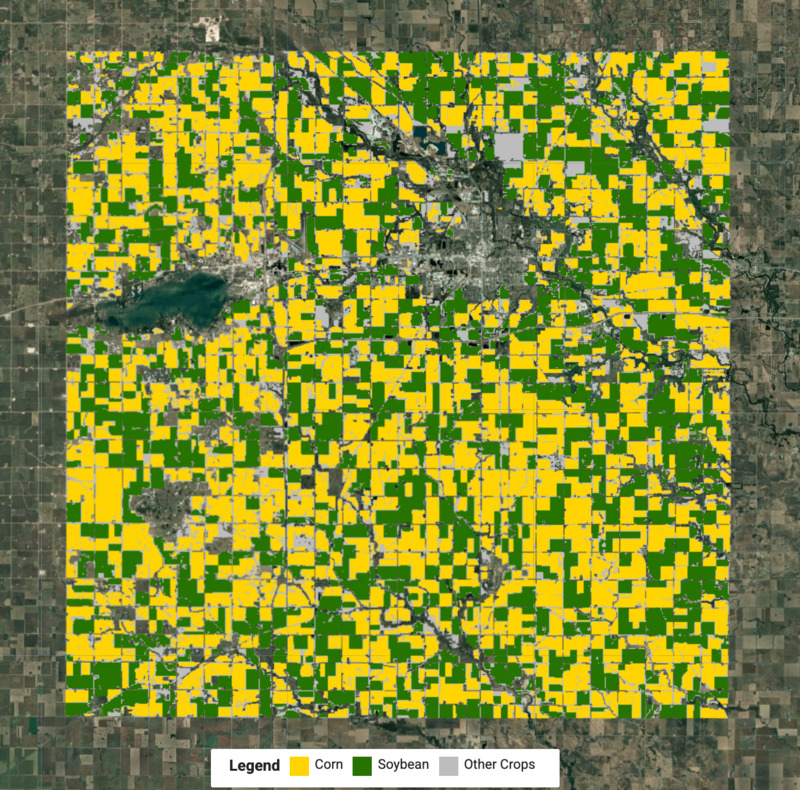
Figura: mappa delle colture rilevata con colture di mais e soia
Convalidare i risultati
Siamo riusciti a ottenere una mappa dei tipi di colture con il set di dati Satellite Embedding senza etichette di campo utilizzando solo le statistiche aggregate e le conoscenze locali della regione. Confrontiamo i nostri risultati con la mappa ufficiale dei tipi di colture dei CDL (Cropland Data Layers) dell'USDA NASS.
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

Figura: (a sinistra) ritaglio della mappa da incorporamenti satellitari (a destra) ritaglio della mappa da CDL
Sebbene ci siano discrepanze tra i nostri risultati e la mappa ufficiale, noterai che siamo riusciti a ottenere risultati piuttosto buoni con il minimo sforzo. Applicando passaggi di post-elaborazione ai risultati, possiamo rimuovere parte del rumore e colmare le lacune nell'output.
Prova lo script completo per questo tutorial nell'editor di codice di Earth Engine.