
1. ステークホルダーの分類
データセットのドキュメント化の透明性への取り組みを開始し、データカードを作成する前に、データセットのライフサイクル全体にわたる関係者を特定して招待することが重要です。コンテンツの作成時に、より強力な検討を行うために必要なものがすべて揃っているため、データカードを簡単に作成できます。
さまざまな部門のステークホルダーがデータセットのライフサイクル プロセスにどのように関与しているかを把握できるように、個々のステークホルダーについてよくある想定を明らかにする分類を作成しました。Google の分類は、データセットのライフサイクルに関与する 3 つのステークホルダー グループ(プロデューサー、エージェント、ユーザー)に分かれています。
この分類は、データセットとそのドキュメントに対するニーズと期待が常に変化する連続体を表しています。万能なソリューションはありません。
プロデューサー
プロデューサーは、データセットとドキュメントの作成者であり、データセットの収集、所有権、リリース、メンテナンスを担当します。
基本的には、プロデューサーはデータセットの作成と公開、リリース、導入、成功を担当するユーザーと考えることができます。
データ収集やラベル付けのために採用された個人やグループが、データ ライフサイクルのさまざまな時点で方法や解釈に関するアドバイスを提供することもあります。
コンテキストによっては、プロデューサーは現在および将来のチームメンバー、パートナー、クライアント、データホスティング プラットフォームを表すこともあります。これらはすべて、データセットのメンテナンス、保守、デプロイ、モニタリングを担当します。
エージェント
エージェントは、データセットのドキュメントやデータカード、その他の ML モデル関連のドキュメントを読み、説明されているデータセットや AI システムを自身や他者がどのように使用するかを決定する権限を持つステークホルダーです。
ドメインに応じて、エージェントは運用担当者または審査担当者の役割を担う可能性があります。たとえば、学術機関の研究者がデータセットの適切な使用状況を把握したい場合や、プロダクト チームのデータ サイエンティストがプロダクト統合に関連するデータセットの全体的な適合性を判断したい場合などです。
この区別は重要です。なぜなら、レビュー担当者には、データセットを直接使用することはないものの、業界コンサルタント、調査ジャーナリスト、コミュニティ代表者、法人など、データカードに関与する可能性のあるステークホルダーが含まれるためです。エージェントは、一般的なデータセットのドキュメントに記載されている情報を理解するための技術的な専門知識を持っている場合もあれば、持っていない場合もありますが、多くの場合、必要に応じて専門知識にアクセスできます。
ユーザー
ユーザーは、データセットでトレーニングされたモデルに依存するプロダクトを操作する個人または担当者です。
ユーザーは、プロダクト エクスペリエンスの一環としてデータの提供に同意する可能性がありますが、データセットに関しても、プロダクト エクスペリエンスに基づく説明と制御のセットを大幅に必要とするのが一般的です。
概要
次の表に、説明、責任、例、一般的なタスク別にステークホルダー グループをまとめます。
ステークホルダー グループ | 説明 | 責任 | 例 | 一般的なタスク |
プロデューサー | データセットやドキュメントを作成します。 | データセットの設計、作成、品質テスト、ドキュメント化、リリース、導入、メンテナンス、更新を行います。 | 研究者、データ サイエンティストとアナリスト、ソフトウェア エンジニア、プロダクト マネージャーとプログラム マネージャー | データセットの採用、開示、将来性、公平性とセキュリティ、改善 |
エージェント | 仕事、プロダクト、組織、コミュニティのためにデータセットを評価して使用する。 | データカードを使用しますが、データセット自体を操作することはできません。 | ML エンジニアまたはプロダクト エンジニア、研究者、サードパーティ ベンダー、専門家、業界、コンサルタント、ポリシー エキスパート、データ サービス プロバイダ、リーダーシップまたは管理職 | 複雑さの管理、責任の所在の明確化、トレードオフの実施、本番環境へのデプロイ、アーカイブ |
ユーザー | プロデューサーのデータセットを使用するエージェントが作成したプロダクト、デバイス、アプリを操作する。 | プロダクトを通じてデータを共有し、プロデューサーやエージェントに役立つシグナルを提供します。 | データ提供者、プロダクト ユーザー、ユーザー コホートの代表者 | プロダクトの使用、データとプライバシーの理解、フィードバックの提供、懸念事項の報告 |
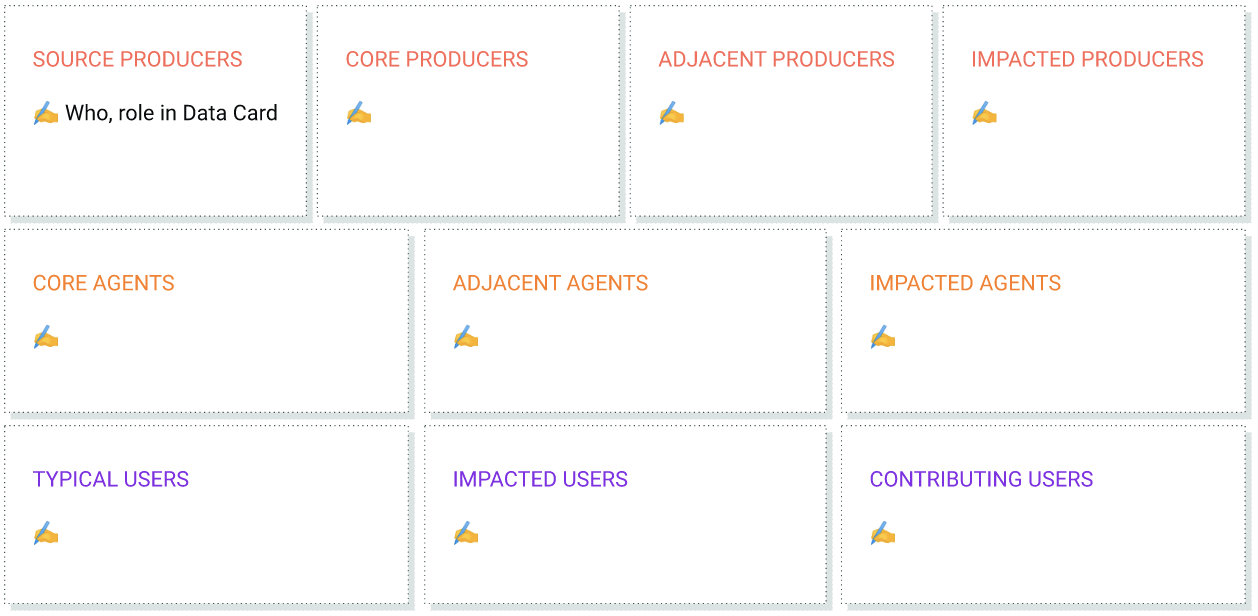
2. 関係者をマッピングする
分類に慣れたら、データセットのライフサイクルを確認して、基本的なマッピング アクティビティを通じてステークホルダーを特定します。アクティビティを進める中で、データセットやそのドキュメントにアクセスする可能性のあるユーザーをメモしておきます。また、関係者がデータカードにどのように貢献できるかについても検討します。
ステークホルダーをマッピングする手順は次のとおりです。
- データカードを作成するプロデューサーを一覧表示します。

- データカードを読み取って使用するエージェントをリストします。

- データカードに記載されているデータセットを使用するユーザーまたはデータセットの影響を受けるユーザーを一覧表示します。
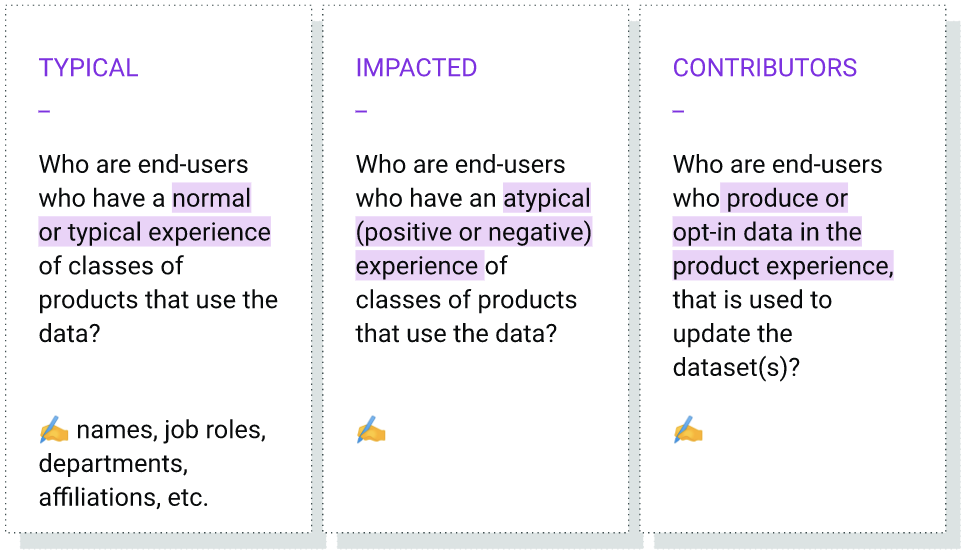
- 次のテンプレートを使用して、ステークホルダー、データカードの作成における役割、データカードの目的のマップを作成します。このマップを使用すると、データセット ドキュメントのダウンストリームのニーズを直感的に把握し、データセット ドキュメント プロセス全体で優先順位と責任を割り当てることができます。
3. エージェント情報ジャーニー(AIJ)
関係者をマッピングしたら、データカードでエージェント(主要な関係者)に伝えるべき重要な情報を特定し、エージェントが成功できるように準備します。
通常、ユーザーがテクノロジーを利用する際に経験する一連のプロセスをユーザー ジャーニーと呼びます。ただし、ここでは、十分な情報に基づいて意思決定を行うためにデータセットに関する十分な情報を取得する必要があるエージェントについて説明しているため、これらのエクスペリエンスをエージェント情報ジャーニー(AIJ)と呼びます。
AIJ の目的は、次のことを理解することです。
- エージェントがデータセットを必要とする可能性のあるタスク。
- エージェントがタスクを完了するために必要な情報。
- エージェントが情報を推論するプロセス。
AIJ には次のものが含まれます。

例
たとえば、エージェントの 1 人がデータ サイエンティストであるとします。データ サイエンティストの AIJ は次のようになります。
データ サイエンティストとして、データセットの構造を知りたいので、次のように質問します。
... データ形式は何ですか?
... データセットのモダリティは何ですか?
... データセットにはいくつの特徴がありますか?
... どのくらいの数の特徴が設計されているか?
... どの特徴が強く相関しているか?
... 構造に依存関係がある場合
プロダクト ポリシーを担当し、プロダクトの生産と開発に関するガイドラインを設定するエージェントの例を次に示します。
政策補佐官として、データがどのように誤用される可能性があるかを知りたいので、次のように質問します。
... データセットの意図された用途は何ですか?
... どのアプリケーションがデータセットの作成を促したか?
... データセットの危険な用途やリスクの高い用途として知られているものはありますか?
... 特定のグループに対するリスクは何ですか?
... このデータセットの想定される用途は、構成員にどのような影響を与えるか?
... 救済を求めるにはどうすればよいですか?
4. AIJ を作成する
- 次のプロンプトに基づいて、いくつかの AIJ を作成します。

- ステークホルダーを念頭に置いているだけでなく、データカードを読むことでステークホルダーが知りたいと思うであろう質問もいくつか用意していることに注目してください。つまり、データカードに含めるべき最終的な質問セットに一歩近づいたことになります。
5. 光学
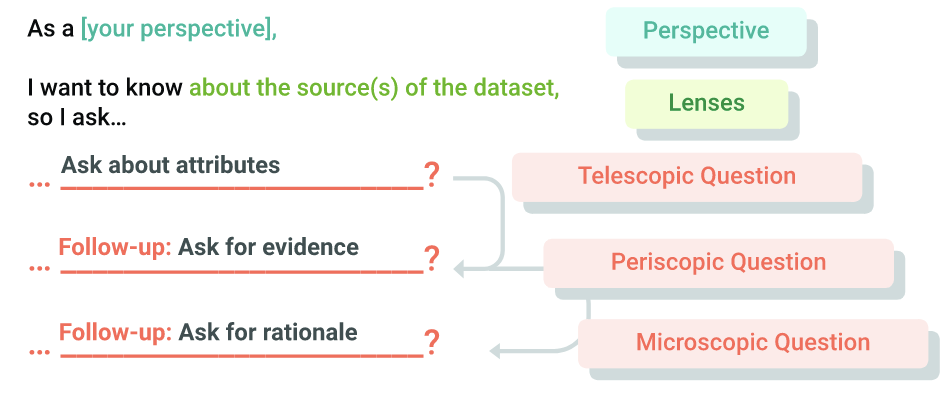
AIJ を説明する際に、視点、レンズ、スコープという用語が使用されていることに気づかれたかもしれません。これらの用語はすでに定義されていますが、実際には「光学」と呼ばれるガイド メタファーの一部です。これらは、エージェントがデータセットをどのように理解するかを考えるうえで役立つように作成されています。
スコープ
光学分野では、スコープはレンズとミラーを使用して、物質の特定、観察、拡大、反射、テストを行います。データセットのコンテキストでは、明らかな側面、明らかでない側面、見える側面、見えない側面を明らかにするために質問に焦点を当てて枠組みを設定するため、優れたメタファーです。
これをスコープと呼びます。スコープは、データセットを理解するために一連の質問を連続して行う手段です。さまざまな粒度のスコープを積み重ねることで、エージェントが透明性レポートを通じてデータセットを包括的に理解するのに役立つコンテンツを作成できます。
次の表に、フレームワークの 3 種類のスコープと、それぞれの説明、例、目的を示します。
スコープ | 説明 | 例 | 目的 |
伸縮式 | 複数のデータセットで一般的に見られる属性に関する質問。特性にタグを付けます。 | このデータセットには個人を特定できる情報(PII)が含まれていますか? | エージェントがデータカードや透明性アーティファクトを操作する際に役立つ追加情報を紹介し、コンテキストを設定します。 |
潜望鏡式 | プロデューサーのデータセットに固有の属性に関する質問。モニタリングについて説明します。 | PII を含む機能の数。 | 通常は、データセットの形状やサイズなどの運用情報や、ソースや意図などの機能情報の提供用に予約されています。 |
顕微鏡 | データセットの観測不可能な側面(意思決定、プロセス、影響など)に関する質問。 彼らは説明を要求します。 | このデータセットでは PII はどのように匿名化されましたか? | 意思決定の詳細な説明を求めたり、対応するペリスコープとテレスコープの質問に対する回答を規定する長いプロセス ドキュメントを要約したりします。 |
データカードの作成プロセス全体を通して、これら 3 種類のスコープを考慮することが重要です。望遠鏡のみのデータカードは、データセットに関する明らかな情報のみを記述し、固有の価値を追加しません。ペリスコープのみのデータカードは、コンテキスト、関連性、重要性に関する詳細がないため、技術的な内容になりすぎる可能性があります。顕微鏡のみのデータカードでは、エージェントが詳細に迷い込み、全体像を見失う可能性があります。
そのため、データカードの解釈は、これらのスコープ レベルの有無に大きく影響されます。これらの質問により、エージェントとプロデューサーはリスクを評価し、緩和策を計画し、必要に応じて、より優れたデータセットを作成する機会を特定できます。望遠鏡、潜望鏡、顕微鏡を組み合わせることで、多くの関係者が迷うことなくデータカードを操作できるように、有用な詳細情報を提供できます。
例
エージェント情報ジャーニー(AIJ)セクションでは、データ サイエンティスト向けの AIJ など、AIJ の例をいくつか紹介しました。この例をよく見ると、次の質問など、スコープごとにグループ化できる質問があることがわかります。
データ サイエンティストとして、データセットの構造を知りたいので、次のように質問します。
望遠
... データ形式は何ですか?
... データセットのモダリティは何ですか?
Periscopic
... データセットにはいくつの特徴がありますか?
... どのくらいの数の特徴が設計されているか?
顕微鏡
... どの特徴が強く相関しているか?
... 構造に依存関係がある場合
エージェントを念頭に置いて、望遠鏡、潜望鏡、顕微鏡の質問をすでにいくつか作成している可能性は十分にあります。
6. スコープを使用して AIJ を再構築する
- スコープを使用して AIJ を再構築するには、次のサンプル プロンプトを使用します。
7. 完了
これで、データカードの作成を開始しました。これで、質問を評価する準備が整いました。