
Dataflow は、ETL、バッチ コンピューティング、連続コンピューティングなど、広範なデータ処理パターンの開発と実行を行うことができる、統合型プログラミング モデルのマネージド サービスです。Dataflow はマネージド サービスであるため、リソースをオンデマンドで割り当てることにより、レイテンシを最小限に抑えつつ、リソースの利用効率を高いレベルで維持できます。
Dataflow モデルはバッチ処理とストリーム処理を組み合わせたもので、開発時に正確さ、費用、処理時間の折り合いを気にする必要がありません。この Codelab では、テキスト ファイル内での特定の単語の出現回数を調べる Dataflow パイプラインを実行する方法について説明します。
このチュートリアルは、https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven を基に作成されています。
学習内容
- Cloud Dataflow SDK を含む Maven プロジェクトを作成する
- Google Cloud Platform Console を使用してサンプル パイプラインを実行する
- 関連する Cloud Storage バケットとその中身を削除する
必要なもの
このチュートリアルの利用方法をお選びください。
Google Cloud Platform サービスのご利用経験についてどのように評価されますか?
セルフペース型の環境設定
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。Google Cloud Platform のコンソール(console.cloud.google.com)にログインし、新しいプロジェクトを作成します。



プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、このコードラボでは PROJECT_ID と呼びます。
次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
この Codelab の操作をすべて行っても、費用は数ドル程度です。ただし、その他のリソースを使いたい場合や、実行したままにしておきたいステップがある場合は、追加コストがかかる可能性があります(このドキュメントの最後にある「クリーンアップ」セクションをご覧ください)。
Google Cloud Platform の新規ユーザーは、300 ドル分の無料トライアルをご利用いただけます。
API を有効にする
画面の左上にあるメニュー アイコンをクリックします。

プルダウンから [API Manager] を選択します。

検索ボックスで「Google Compute Engine」を検索します。表示された結果リストで [Google Compute Engine API] をクリックします。
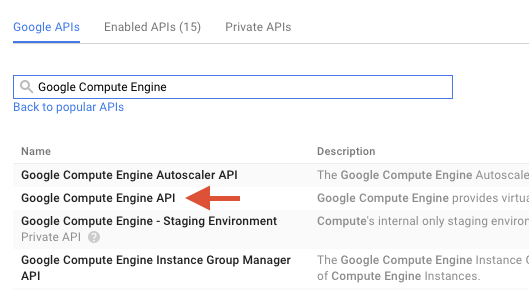
[Google Compute Engine] ページで、[有効にする] をクリックします。
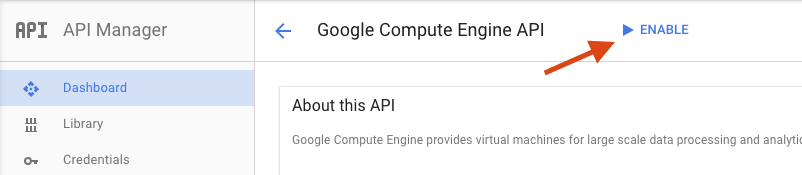
有効になったら、矢印をクリックして戻ります。
次の API を検索して有効にします。
- Google Dataflow API
- Stackdriver Logging API
- Google Cloud Storage
- Google Cloud Storage JSON API
- BigQuery API
- Google Cloud Pub/Sub API
- Google Cloud Datastore API
Google Cloud Platform Console で、画面左上のメニュー アイコンをクリックします。
下にスクロールして、[ストレージ] サブセクションで [Cloud Storage] を選択します。
Cloud Storage ブラウザが表示されます。現在 Cloud Storage バケットがないプロジェクトを使用している場合は、新しいバケットの作成を促すダイアログ ボックスが表示されます。
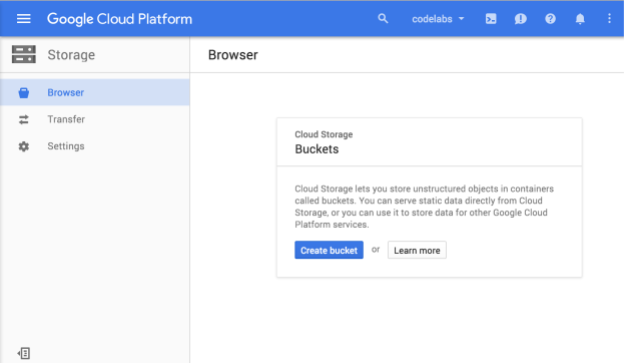
[バケットを作成] ボタンをクリックしてバケットを作成します。
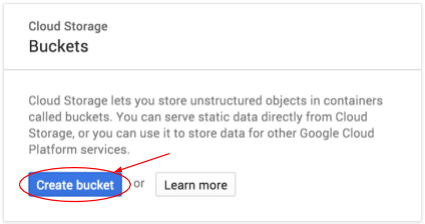
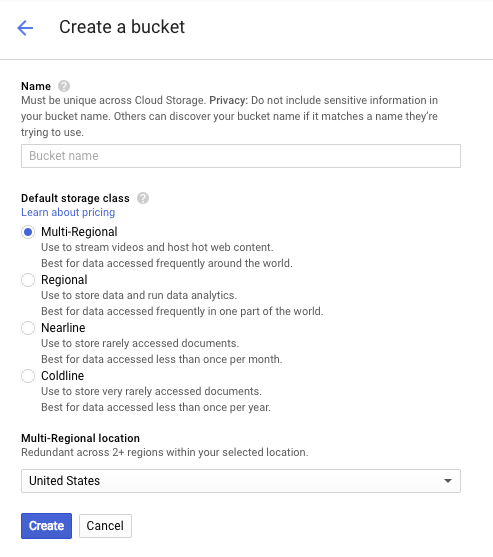
バケットの名前を入力します。ダイアログ ボックスに記載されているように、バケット名は Cloud Storage 全体で一意である必要があります。そのため、「test」のようなわかりやすい名前を選択すると、その名前のバケットがすでに作成されている可能性が高く、エラーが表示されます。
バケット名に使用できる文字に関するルールもあります。バケット名の先頭と末尾を文字または数字にし、中間にはダッシュのみを使用すれば問題ありません。特殊文字を使用しようとした場合や、バケット名の先頭または末尾に英数字以外の文字を使用しようとした場合は、ダイアログ ボックスにルールが表示されます。
バケットの一意の名前を入力して、[作成] をクリックします。すでに使用されているものを選択すると、上記のエラー メッセージが表示されます。バケットが正常に作成されると、ブラウザで新しい空のバケットが表示されます。
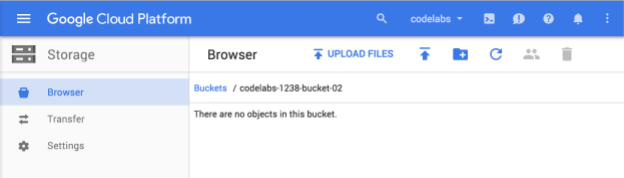
バケット名はすべてのプロジェクトで一意である必要があるため、表示されるバケット名は異なります。
Google Cloud Shell の有効化
GCP Console で右上のツールバーにある Cloud Shell アイコンをクリックします。

[Cloud Shell の起動] をクリックします。

プロビジョニングと環境への接続にはそれほど時間はかかりません。

この仮想マシンには、必要な開発ツールがすべて準備されています。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働するため、ネットワーク パフォーマンスが充実しており認証もスムーズです。このラボでの作業のほとんどは、ブラウザまたは Google Chromebook から実行できます。
Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自の PROJECT_ID が設定されています。
Cloud Shell で次のコマンドを実行して、認証されたことを確認します。
gcloud auth list
コマンド出力
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
コマンド出力
[core] project = <PROJECT_ID>
上記のようになっていない場合は、次のコマンドで設定できます。
gcloud config set project <PROJECT_ID>
コマンド出力
Updated property [core/project].
Cloud Shell が起動したら、Cloud Dataflow SDK for Java を含む Maven プロジェクトを作成して始めましょう。
シェルで次のように mvn archetype:generate コマンドを実行します。
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.exampleコマンドを実行すると、現在のディレクトリの下に first-dataflow という新しいディレクトリが表示されます。first-dataflow には、Cloud Dataflow SDK for Java とサンプル パイプラインを含む Maven プロジェクトが含まれています。
まず、プロジェクト ID と Cloud Storage バケット名を環境変数として保存します。環境変数にキーを保存するには、Cloud Shell で次のように入力します。<your_project_id> は、実際のプロジェクト ID に置き換えてください。
export PROJECT_ID=<your_project_id>次に、Cloud Storage バケットについても同様の操作を行います。<your_bucket_name> は、前の手順でバケットの作成に使用した一意の名前に置き換えます。
export BUCKET_NAME=<your_bucket_name>first-dataflow/ ディレクトリに移動します。
cd first-dataflow次は、WordCount という名前のパイプラインを実行します。このパイプラインは、テキストを読み取り、テキスト行を個別の単語にトークン化したうえで、各単語の出現頻度をカウントします。まず、パイプラインを実行します。実行中に、各ステップで何が行われているかを確認します。
シェルまたはターミナル ウィンドウで mvn compile exec:java コマンドを実行して、パイプラインを開始します。下のコマンドで指定している --project, --stagingLocation, と --output の各引数では、この手順の前半で設定した環境変数が参照されます。
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"ジョブが実行されている間に、ジョブリストでジョブを探します。
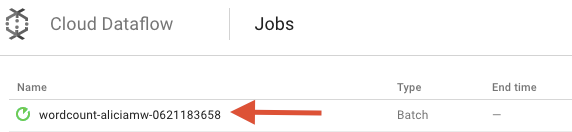
Google Cloud Platform Console で Cloud Dataflow Monitoring UI を開きます。wordcount ジョブが [実行中] のステータスで表示されます。

次に、パイプライン パラメータを見てみましょう。最初に、ジョブの名前をクリックします。
ジョブを選択すると、実行グラフが表示されます。パイプラインの実行グラフは、パイプライン内の各変換を、変換名といくつかのステータス情報を含むボックスとして表します。各ステップの右上隅にあるアイコンをクリックすると、詳細が表示されます。
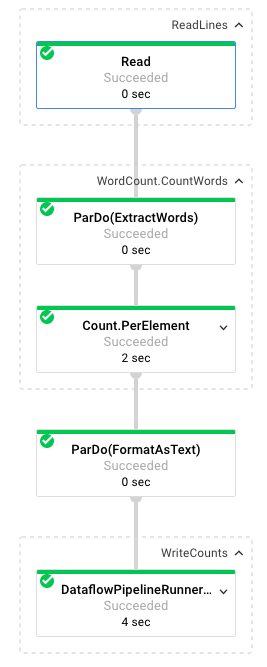
ここで、パイプラインの各ステップで行われるデータ変換について説明します。
- 読み取り: このステップでは、パイプラインは入力ソースから読み取ります。今回の入力ソースは、シェイクスピアの演劇、『リア王』のテキストがすべて含まれた Cloud Storage のテキスト ファイルです。パイプラインはファイルを 1 行ずつ読み取り、それぞれ
PCollectionを出力します。テキスト ファイルの各行は、コレクション内の要素です。 - CountWords:
CountWordsステップは 2 つのパートに分かれています。まず、ExtractWordsという名前の並列 do 関数(ParDo)を使用して、各行を個々の単語にトークン化します。ExtractWords の出力は、各要素が単語である新しい PCollection です。次のステップCountでは、Dataflow SDK によって提供される変換を利用します。この変換は、キーが一意の単語で、値がその単語の出現回数である Key-Value ペアを返します。CountWordsを実装するメソッドは次のとおりです。WordCount.java ファイル全体は GitHub で確認できます。
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText: これは、各 Key-Value ペアを出力可能な文字列に変換する書式設定関数です。これを実装する
FormatAsText変換は次のとおりです。
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts: このステップでは、出力可能な文字列を分割された複数のテキスト ファイルに書き込みます。
パイプラインからの出力結果は後ほど確認します。
次は、グラフの右側にある [概要] ページを確認します。ここには、mvn compile exec:java コマンドに指定したパイプライン パラメータが表示されます。
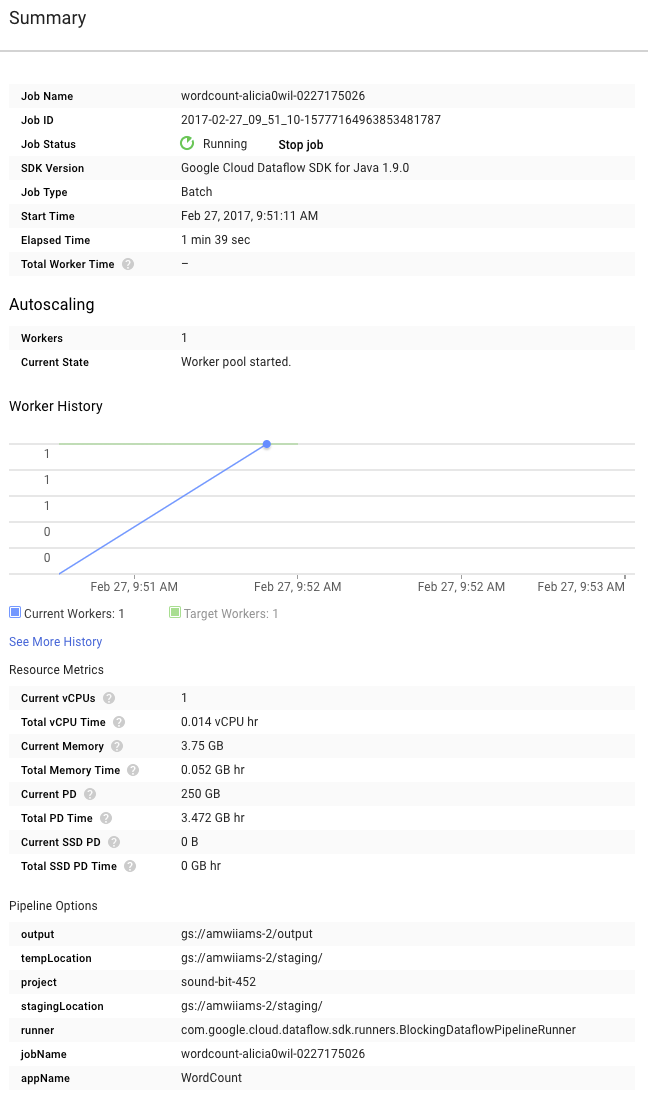
パイプラインの [カスタム カウンタ] も表示されます。今回の場合、このカウンタはこれまでの処理中に検出された空の行の数を示しています。アプリケーション固有の指標を追跡するために、パイプラインに新しいカウンタを追加できます。
[ログ] アイコンをクリックすると、特定のエラー メッセージが表示されます。

[ジョブログ] タブに表示されるメッセージは、[最小重要度] プルダウン メニューを使用してフィルタします。

ログタブの [ワーカーログ] ボタンを使用すると、パイプラインを実行する Compute Engine インスタンスのワーカーログを表示できます。ワーカーログには、コードで生成されるログ行と、それを実行している、Dataflow で生成されるコードが含まれます。
パイプラインの障害をデバッグしようとしている場合は、ワーカーログに追加のロギングがあり、問題の解決に役立つことがよくあります。これらのログはすべてのワーカーで集計され、フィルタリングと検索が可能です。
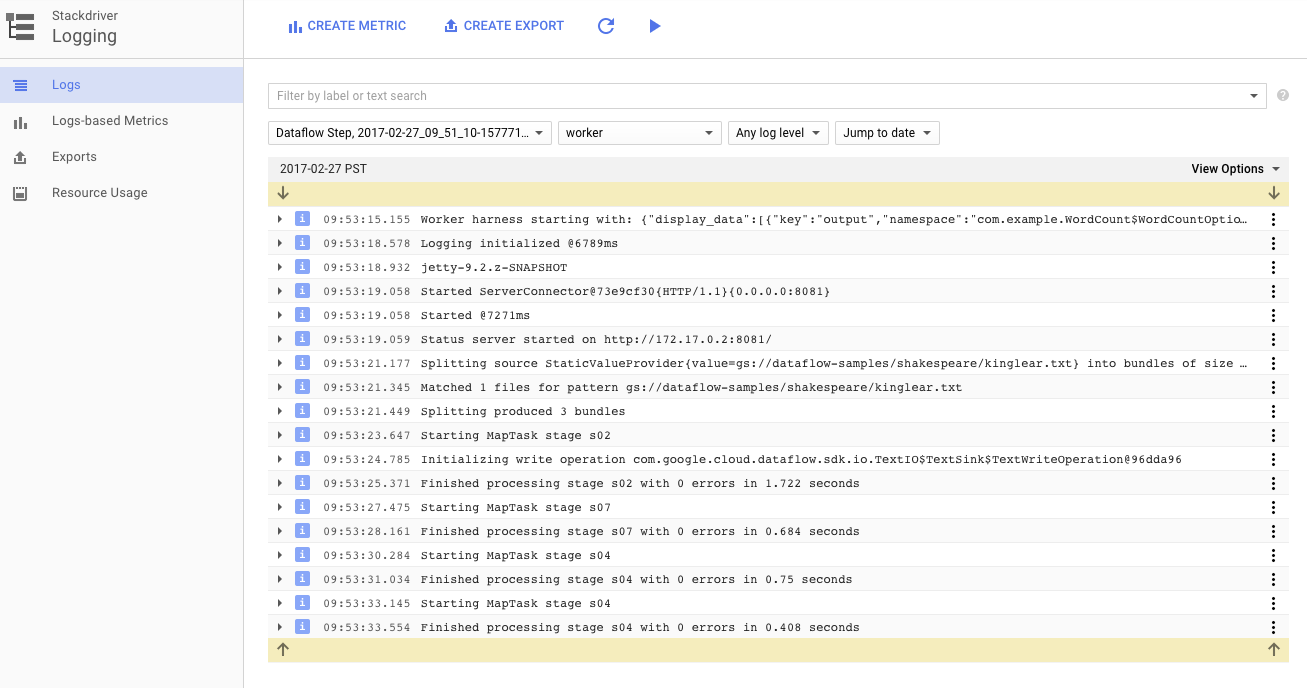
次のステップでは、ジョブが正常に実行されたことを確認します。
Google Cloud Platform Console で Cloud Dataflow Monitoring UI を開きます。
wordcount ジョブは、まずステータスが [実行中] と表示され、その後 [完了] に変わります。

ジョブの実行が完了するまでには約 3~4 分かかります。
パイプラインを実行したときに、出力バケットを指定しました。『リア王』に含まれる各単語の出現回数がどのようになっているのか、結果を見てみましょう。Google Cloud Platform Console で Cloud Storage ブラウザに戻ります。バケットに、ジョブによって作成された出力ファイルとステージング ファイルが表示されます。
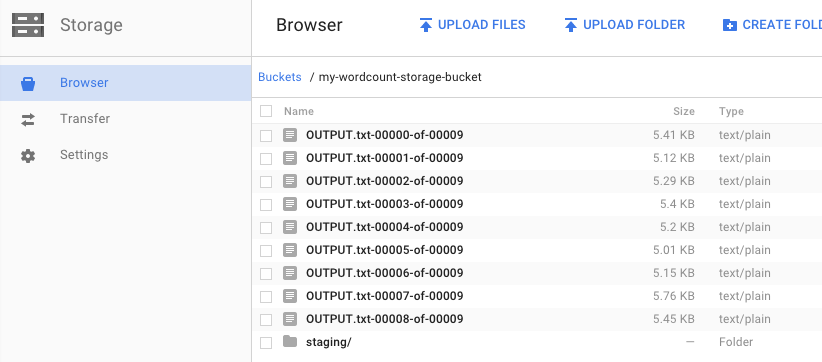
リソースは Google Cloud Platform Console からシャットダウンできます。
Google Cloud Platform Console で Cloud Storage ブラウザを開きます。
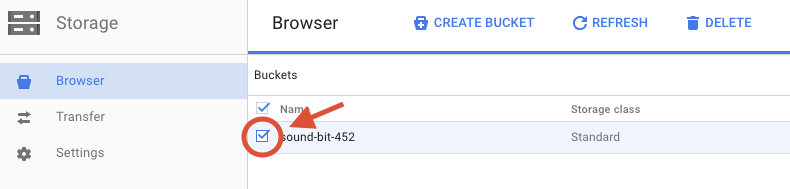
作成したバケットの横にあるチェックボックスをオンにします。
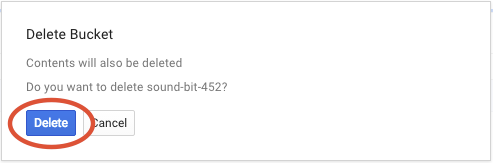
[削除] をクリックして、バケットとそのコンテンツを完全に削除します。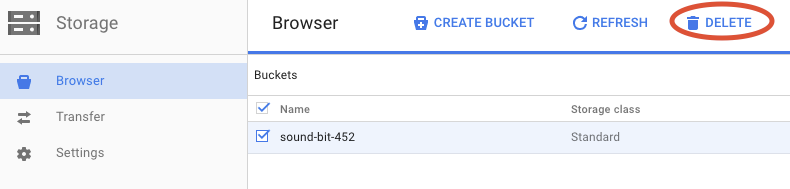
このラボでは、Cloud Dataflow SDK を含んだ Maven プロジェクトを作成し、Google Cloud Platform Console を使用してサンプル パイプラインを実行しました。また、関連する Cloud Storage バケットとその中身を削除する方法についても学習しました。
詳細
- Dataflow のドキュメント: https://cloud.google.com/dataflow/docs/
ライセンス
この作品は、クリエイティブ・コモンズの表示 3.0 汎用ライセンスと Apache 2.0 ライセンスにより使用許諾されています。