
यहां दिए गए सबसे सही तरीकों से, आपको निजता को ध्यान में रखकर और बेहतर परफ़ॉर्मेंस वाली क्वेरी बनाने के तरीके मिलेंगे. नॉइज़ मोड में क्वेरी चलाने के सबसे सही तरीकों के बारे में जानने के लिए, नॉइज़ इंजेक्शन में, क्वेरी के काम करने वाले और न करने वाले पैटर्न के बारे में सेक्शन देखें.
निजता और डेटा की सटीकता
सैंडबॉक्स डेटा पर क्वेरी डेवलप करना
सबसे सही तरीका: प्रोडक्शन में होने पर ही, प्रोडक्शन डेटा के लिए क्वेरी करें.
जब भी हो सके, क्वेरी डेवलप करने के दौरान सैंडबॉक्स डेटा का इस्तेमाल करें. सैंडबॉक्स डेटा का इस्तेमाल करने वाली नौकरियों से, क्वेरी के नतीजों को फ़िल्टर करने के लिए, अंतर की जांच के अतिरिक्त अवसर नहीं मिलते. इसके अलावा, निजता की जांच न होने की वजह से, सैंडबॉक्स क्वेरी तेज़ी से चलती हैं. इससे क्वेरी डेवलप करने के दौरान, ज़्यादा तेज़ी से बदलाव किए जा सकते हैं.
अगर आपको अपने असल डेटा पर क्वेरी डेवलप करनी हैं (जैसे, मैच टेबल का इस्तेमाल करते समय), तो पंक्तियों के ओवरलैप होने की संभावना को कम करने के लिए, तारीख की ऐसी सीमाएं और अन्य पैरामीटर चुनें जिनके ओवरलैप होने की संभावना कम हो. ऐसा क्वेरी के हर इटरेशन के लिए करें. आखिर में, डेटा की चुनी गई रेंज पर क्वेरी चलाएं.
पिछले नतीजों पर ध्यान से विचार करना
सबसे सही तरीका: हाल ही में चलाई गई क्वेरी के नतीजे के सेट में ओवरलैप होने की संभावना कम करें.
ध्यान रखें कि क्वेरी के नतीजों में बदलाव की दर से यह तय होगा कि निजता की जांच की वजह से, बाद में नतीजों को हटाए जाने की कितनी संभावना है. हाल ही में मिले नतीजों के सेट से काफ़ी हद तक मिलते-जुलते दूसरे नतीजों के सेट को हटा दिया जाएगा.
इसके बजाय, अपनी क्वेरी में तारीख की सीमा या कैंपेन आईडी जैसे मुख्य पैरामीटर में बदलाव करें, ताकि ओवरलैप होने की संभावना कम हो जाए.
आज के डेटा के बारे में क्वेरी न करें
सबसे सही तरीका: ऐसी कई क्वेरी न चलाएं जिनके लिए खत्म होने की तारीख आज की हो.
आज की तारीख को खत्म होने वाली कई क्वेरी चलाने पर, अक्सर पंक्तियों को फ़िल्टर किया जाता है. यह दिशा-निर्देश, कल के डेटा पर आधी रात के तुरंत बाद क्वेरी चलाने पर भी लागू होता है.
एक ही डेटा के लिए, ज़रूरत से ज़्यादा बार क्वेरी न करें
सबसे सही तरीके:
- शुरू और खत्म होने की तारीखें आस-पास की चुनें.
- ओवरलैप होने वाली विंडो पर क्वेरी करने के बजाय, डेटा के अलग-अलग सेट पर क्वेरी चलाएं. इसके बाद, BigQuery में नतीजों को इकट्ठा करें.
- अपनी क्वेरी को फिर से चलाने के बजाय, सेव किए गए नतीजों का इस्तेमाल करें.
- क्वेरी की जा रही हर तारीख की सीमा के लिए, अस्थायी टेबल बनाएं.
Ads Data Hub, एक ही डेटा को क्वेरी करने की कुल संख्या को सीमित करता है. इसलिए, आपको किसी दिए गए डेटा को ऐक्सेस करने की संख्या को सीमित करने की कोशिश करनी चाहिए.
एक ही क्वेरी में ज़रूरत से ज़्यादा एग्रीगेशन का इस्तेमाल न करें
सबसे सही तरीके:
- क्वेरी में एग्रीगेशन की संख्या कम करें
- क्वेरी को फिर से लिखें, ताकि एग्रीगेशन को एक साथ जोड़ा जा सके
Ads Data Hub, सबक्वेरी में इस्तेमाल किए जा सकने वाले क्रॉस-यूज़र एग्रीगेशन की संख्या को 100 तक सीमित करता है. इसलिए, हमारा सुझाव है कि आप ऐसी क्वेरी लिखें जिनसे ज़्यादा पंक्तियां मिलती हों. साथ ही, उनमें फ़ोकस की गई ग्रुपिंग कुंजियां और सामान्य एग्रीगेशन शामिल हों. इसके बजाय, ऐसी क्वेरी न लिखें जिनमें ज़्यादा कॉलम हों. साथ ही, उनमें ब्रॉड ग्रुपिंग कुंजियां और जटिल एग्रीगेशन शामिल हों. इस पैटर्न का इस्तेमाल नहीं करना चाहिए:
SELECT
COUNTIF(field_1 = a_1 AND field_2 = b_1) AS cnt_1,
COUNTIF(field_1 = a_2 AND field_2 = b_2) AS cnt_2
FROM
table
एक ही फ़ील्ड के सेट के आधार पर इवेंट की गिनती करने वाली क्वेरी को GROUP BY स्टेटमेंट का इस्तेमाल करके फिर से लिखा जाना चाहिए.
SELECT
field_1,
field_2,
COUNT(1) AS cnt
FROM
table
GROUP BY
1, 2
BigQuery में भी नतीजे को इसी तरह से एग्रीगेट किया जा सकता है.
ऐसी क्वेरी जिनमें किसी ऐरे से कॉलम बनाए जाते हैं और बाद में उन्हें एग्रीगेट किया जाता है उन्हें फिर से लिखा जाना चाहिए, ताकि इन चरणों को मर्ज किया जा सके.
SELECT
COUNTIF(a_1) AS cnt_1,
COUNTIF(a_2) AS cnt_2
FROM
(SELECT
1 IN UNNEST(field) AS a_1,
2 IN UNNEST(field) AS a_2,
FROM
table)
पिछली क्वेरी को इस तरह से फिर से लिखा जा सकता है:
SELECT f, COUNT(1) FROM table, UNNEST(field) AS f GROUP BY 1
अलग-अलग एग्रीगेशन में फ़ील्ड के अलग-अलग कॉम्बिनेशन का इस्तेमाल करने वाली क्वेरी को, ज़्यादा फ़ोकस वाली कई क्वेरी में फिर से लिखा जा सकता है.
SELECT
COUNTIF(field_1 = a_1) AS cnt_a_1,
COUNTIF(field_1 = b_1) AS cnt_b_1,
COUNTIF(field_2 = a_2) AS cnt_a_2,
COUNTIF(field_2 = b_2) AS cnt_b_2,
FROM table
पिछली क्वेरी को इन हिस्सों में बांटा जा सकता है:
SELECT
field_1, COUNT(*) AS cnt
FROM table
GROUP BY 1
और
SELECT
field_2, COUNT(*) AS cnt
FROM table
GROUP BY 1
इन नतीजों को अलग-अलग क्वेरी में बांटा जा सकता है. इसके अलावा, एक ही क्वेरी में टेबल बनाई और जोड़ी जा सकती हैं. अगर स्कीमा एक जैसे हैं, तो उन्हें UNION के साथ भी जोड़ा जा सकता है.
सदस्यता लेने की सुविधा को ऑप्टिमाइज़ करना और इसके बारे में समझना
सबसे सही तरीका: क्लिक या कन्वर्ज़न को इंप्रेशन से जोड़ने के लिए, INNER JOIN के बजाय LEFT JOIN का इस्तेमाल करें.
सभी इंप्रेशन, क्लिक या कन्वर्ज़न से जुड़े नहीं होते. इसलिए, अगर आपको इंप्रेशन पर INNER JOIN क्लिक या कन्वर्ज़न मिलते हैं, तो क्लिक या कन्वर्ज़न से जुड़े न होने वाले इंप्रेशन को आपके नतीजों से फ़िल्टर कर दिया जाएगा.
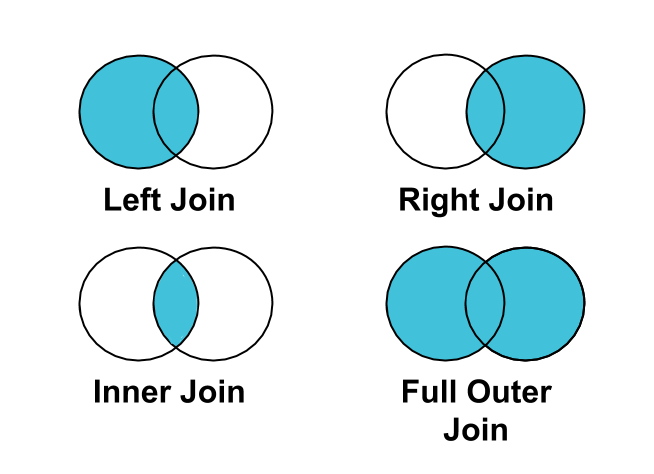
BigQuery में कुछ फ़ाइनल नतीजों को जोड़ना
सबसे सही तरीका: Ads Data Hub की ऐसी क्वेरी से बचें जो एग्रीगेट किए गए नतीजों को जोड़ती हैं. इसके बजाय, दो अलग-अलग क्वेरी लिखें और BigQuery में नतीजों को जोड़ें.
जिन लाइनों में एग्रीगेशन से जुड़ी ज़रूरी शर्तें पूरी नहीं होती हैं उन्हें आपके नतीजों से फ़िल्टर कर दिया जाता है. इसलिए, अगर आपकी क्वेरी में, कम एग्रीगेट की गई लाइन को ज़्यादा एग्रीगेट की गई लाइन के साथ जोड़ा जाता है, तो नतीजे वाली लाइन को फ़िल्टर कर दिया जाएगा. इसके अलावा, Ads Data Hub में एक से ज़्यादा एग्रीगेशन वाली क्वेरी कम परफ़ॉर्म करती हैं.
Ads Data Hub से मिली कई एग्रीगेशन क्वेरी के नतीजों को BigQuery में जोड़ा जा सकता है. सामान्य क्वेरी का इस्तेमाल करके कैलकुलेट किए गए नतीजे, फ़ाइनल स्कीमा शेयर करेंगे.
नीचे दी गई क्वेरी, Ads Data Hub के अलग-अलग नतीजों (campaign_data_123 और campaign_data_456) को लेती है और उन्हें BigQuery में जोड़ती है:
SELECT t1.campaign_id, t1.city, t1.X, t2.Y
FROM `campaign_data_123` AS t1
FULL JOIN `campaign_data_456` AS t2
USING (campaign_id, city)
फ़िल्टर की गई लाइन की खास जानकारी का इस्तेमाल करना
सबसे सही तरीका: अपनी क्वेरी में, फ़िल्टर की गई लाइन की खास जानकारी जोड़ें.
फ़िल्टर की गई लाइन की खास जानकारी में, निजता की जांच की वजह से फ़िल्टर किए गए डेटा का मिलान किया जाता है. फ़िल्टर की गई लाइनों के डेटा को जोड़कर, 'अन्य' लाइन में जोड़ दिया जाता है. फ़िल्टर किए गए डेटा का आगे विश्लेषण नहीं किया जा सकता. हालांकि, इससे यह पता चलता है कि नतीजों से कितना डेटा फ़िल्टर किया गया था.
ऐसे उपयोगकर्ता आईडी के लिए खाता जिन्हें शून्य कर दिया गया है
सबसे सही तरीका: अपने नतीजों में, शून्य किए गए यूज़र आईडी को शामिल करें.
एंड-यूज़र का आईडी कई वजहों से 0 पर सेट किया जा सकता है. जैसे, लोगों की दिलचस्पी के मुताबिक विज्ञापन दिखाने की सुविधा से ऑप्ट आउट करना, नियमों का पालन करने से जुड़ी वजहें वगैरह. इसलिए, कई उपयोगकर्ताओं से मिलने वाले डेटा को 0 के user_id पर सेट किया जाएगा.
अगर आपको कुल इंप्रेशन या क्लिक जैसे डेटा के कुल योग को समझना है, तो आपको इन इवेंट को शामिल करना चाहिए. हालांकि, इस डेटा से ग्राहकों के बारे में अहम जानकारी नहीं मिलती. इसलिए, अगर आपको इस तरह का विश्लेषण करना है, तो इस डेटा को फ़िल्टर किया जाना चाहिए.
अपनी क्वेरी में WHERE user_id != "0" जोड़कर, इस डेटा को अपने नतीजों से हटाया जा सकता है.
परफ़ॉर्मेंस
रीएग्रीगेशन से बचना
सबसे सही तरीका: उपयोगकर्ताओं के डेटा को कई बार एग्रीगेट करने से बचें.
ऐसी क्वेरी जिनमें पहले से एग्रीगेट किए गए नतीजों को शामिल किया जाता है उन्हें प्रोसेस करने के लिए ज़्यादा संसाधनों की ज़रूरत होती है. जैसे, एक से ज़्यादा GROUP BY वाली क्वेरी या नेस्ट किए गए एग्रीगेशन वाली क्वेरी.
अक्सर, एग्रीगेशन की कई लेयर वाली क्वेरी को अलग-अलग किया जा सकता है. इससे परफ़ॉर्मेंस बेहतर होती है. आपको प्रोसेसिंग के दौरान, इवेंट या उपयोगकर्ता लेवल पर लाइनों को बनाए रखने की कोशिश करनी चाहिए. इसके बाद, उन्हें एक एग्रीगेशन के साथ जोड़ना चाहिए.
इन पैटर्न का इस्तेमाल नहीं करना चाहिए:
SELECT SUM(count)
FROM
(SELECT campaign_id, COUNT(0) AS count FROM ... GROUP BY 1)
एग्रीगेशन की कई लेयर का इस्तेमाल करने वाली क्वेरी को फिर से लिखा जाना चाहिए, ताकि एग्रीगेशन की एक लेयर का इस्तेमाल किया जा सके.
(SELECT ... GROUP BY ... )
JOIN USING (...)
(SELECT ... GROUP BY ... )
जिन क्वेरी को आसानी से अलग-अलग हिस्सों में बांटा जा सकता है उन्हें अलग-अलग हिस्सों में बांटना चाहिए. BigQuery में नतीजों को जोड़ा जा सकता है.
BigQuery के लिए ऑप्टिमाइज़ करना
आम तौर पर, कम काम करने वाली क्वेरी बेहतर परफ़ॉर्म करती हैं. क्वेरी की परफ़ॉर्मेंस का आकलन करते समय, ज़रूरी काम की मात्रा इन बातों पर निर्भर करती है:
- इनपुट डेटा और डेटा सोर्स (I/O): आपकी क्वेरी कितने बाइट डेटा को पढ़ती है?
- नोड के बीच कम्यूनिकेशन (शफ़लिंग): आपकी क्वेरी अगले चरण में कितने बाइट पास करती है?
- कैलकुलेशन: आपकी क्वेरी को सीपीयू के कितने काम की ज़रूरत है?
- आउटपुट (मटेरियलाइज़ेशन): आपकी क्वेरी कितने बाइट लिखती है?
- क्वेरी एंटी-पैटर्न: क्या आपकी क्वेरी, एसक्यूएल के सबसे सही तरीकों का पालन कर रही हैं?
अगर क्वेरी को एक्ज़ीक्यूट करने में सेवा स्तर के समझौतों का पालन नहीं किया जा रहा है या संसाधन खत्म होने या टाइम आउट होने की वजह से गड़बड़ियां आ रही हैं, तो इन बातों पर ध्यान दें:
- फिर से हिसाब लगाने के बजाय, पिछली क्वेरी के नतीजों का इस्तेमाल करना. उदाहरण के लिए, आपका हफ़्ते का कुल डेटा, BigQuery में एक दिन की सात एग्रीगेट क्वेरी के योग के बराबर हो सकता है.
- क्वेरी को लॉजिकल सबक्वेरी में बांटना (जैसे, कई जॉइन को कई क्वेरी में बांटना) या प्रोसेस किए जा रहे डेटा के सेट को सीमित करना. BigQuery में, अलग-अलग जॉब के नतीजों को एक ही डेटासेट में मिलाया जा सकता है. इससे संसाधनों के इस्तेमाल की समस्या को हल करने में मदद मिल सकती है. हालांकि, इससे आपकी क्वेरी के नतीजे मिलने में देरी हो सकती है.
- अगर आपको BigQuery में संसाधन की सीमा से ज़्यादा होने की वजह से गड़बड़ियां मिल रही हैं, तो अपनी क्वेरी को कई BigQuery क्वेरी में बांटने के लिए, अस्थायी टेबल का इस्तेमाल करें.
- एक क्वेरी में कम टेबल रेफ़रंस करें. ऐसा इसलिए, क्योंकि इससे ज़्यादा मेमोरी का इस्तेमाल होता है और आपकी क्वेरी फ़ेल हो सकती है.
- क्वेरी को इस तरह से फिर से लिखना कि वे कम उपयोगकर्ता टेबल में शामिल हों.
- क्वेरी को फिर से लिखना, ताकि एक ही टेबल को बार-बार न जोड़ा जाए.
क्वेरी सलाहकार
अगर आपका एसक्यूएल मान्य है, लेकिन इससे निजता से जुड़ी समस्याएं हो सकती हैं, तो क्वेरी सलाहकार क्वेरी डेवलप करने की प्रोसेस के दौरान कार्रवाई करने लायक सलाह देता है. इससे आपको अवांछित नतीजों से बचने में मदद मिलती है.
क्वेरी एडवाइज़र का इस्तेमाल करने के लिए:
- यूज़र इंटरफ़ेस (यूआई). सुझाव, क्वेरी एडिटर में क्वेरी टेक्स्ट के ऊपर दिखेंगे.
- एपीआई.
customers.analysisQueries.validateतरीके का इस्तेमाल करें.