
Schemat Google Cloud Search to struktura JSON, która definiuje obiekty, właściwości i opcje indeksowania danych oraz wysyłania zapytań o nie. Łącznik treści używa zarejestrowanego schematu do strukturyzowania i indeksowania danych repozytorium.
Schemat tworzysz, przekazując do interfejsu API obiekt schematu JSON. Przed indeksowaniem danych musisz zarejestrować schemat dla każdego repozytorium.
W tym dokumencie opisujemy podstawy tworzenia schematów. Aby zoptymalizować wyszukiwanie, zapoznaj się z artykułem Poprawianie jakości wyszukiwania.
Tworzenie schematu
Aby utworzyć schemat Cloud Search, wykonaj te czynności:
- Określanie oczekiwanych zachowań użytkowników
- Inicjowanie źródła danych
- Określ obiekty
- Definiowanie właściwości obiektu
- Rejestrowanie schematu
- Indeksowanie danych
- Testowanie schematu
- Dostosowywanie schematu
Określanie oczekiwanych zachowań użytkowników
Przewidywanie sposobu wyszukiwania przez użytkowników pomaga określić strategię dotyczącą schematu. W przypadku bazy danych filmów użytkownicy mogą wyszukiwać hasło „filmy z Robertem Redfordem”. Twój schemat musi obsługiwać zapytania dotyczące filmów z określonym aktorem.
Aby dostosować schemat do zachowań użytkowników:
- Oceniaj różne zapytania od różnych użytkowników.
- Identyfikuj logiczne zbiory danych, czyli obiekty, takie jak „film”.
- Identyfikuj właściwości (atrybuty) takie jak tytuł czy data premiery.
- Określ prawidłowe wartości właściwości, np. „Poszukiwacze zaginionej arki”.
- Określ potrzeby w zakresie sortowania i rankingu, np. kolejność chronologiczna lub oceny odbiorców.
- Określ właściwości kontekstu, takie jak stanowisko, aby ulepszyć sugestie autouzupełniania.
- Wymień te obiekty, właściwości i przykładowe wartości. Użyj tej listy, aby określić opcje operatora.
Inicjowanie źródła danych
Źródło danych reprezentuje zindeksowane dane repozytorium przechowywane w Google Cloud. Zobacz Zarządzanie zewnętrznymi źródłami danych. Gdy użytkownik kliknie wynik, Cloud Search przekieruje go do elementu, używając adresu URL z żądania indeksowania.
Określ obiekty
Obiekt to podstawowa jednostka schematu. Struktury logiczne, takie jak „film” lub „osoba”, są obiektami. Każdy obiekt ma właściwości, takie jak tytuł, czas trwania czy nazwa.
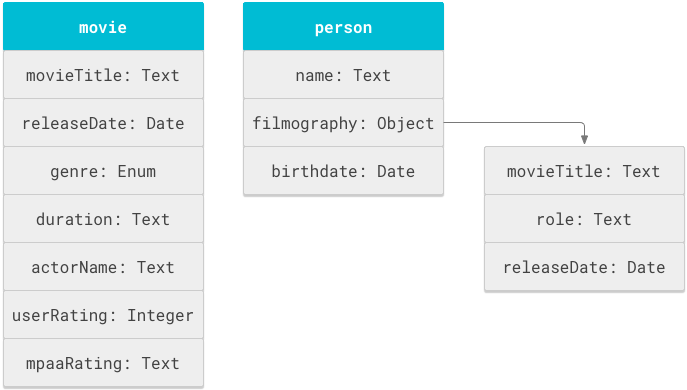
Schema to lista definicji obiektów w tagu objectDefinitions.
{
"objectDefinitions": [
{ "name": "movie" },
{ "name": "person" }
]
}
Używaj unikalnych nazw dla każdego obiektu, np. movie. Usługa schematu używa tych nazw jako kluczy. Zobacz ObjectDefinition.
Określanie właściwości obiektu
Zdefiniuj właściwości, takie jak tytuł i data premiery, w sekcji propertyDefinitions. Używaj
options
w przypadku
freshnessOptions
(ranking) i displayOptions
(etykiety interfejsu).
{
"objectDefinitions": [{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": { "operatorName": "title" }
},
"displayOptions": { "displayLabel": "Title" }
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}]
}
PropertyDefinition zawiera:
- Ciąg znaków
name. - Opcje niezależne od typu (np.
isReturnable). - Typ i opcje specyficzne dla typu (np.
textPropertyOptions). operatorOptions– operatory wyszukiwania.displayOptionsw przypadku etykiet interfejsu.
Możesz używać tych samych nazw właściwości w różnych obiektach. Na przykład movieTitle może pojawić się w filmografii zarówno obiektu movie, jak i obiektu person.
Dodawanie opcji niezależnych od typu
PropertyDefinition zawiera opcje logiczne, które umożliwiają skonfigurowanie funkcji wyszukiwania dla usługi niezależnie od jej typu. Te opcje są domyślnie ustawione na false i muszą być ustawione na true, aby można było z nich korzystać.
isReturnable: ustaw natrue, jeśli dane usługi mają być zwracane w wynikach wyszukiwania za pomocą interfejsu Query API. Właściwości, których nie można zwrócić, mogą być używane do wyszukiwania lub określania rankingu bez pojawiania się w wynikach.isRepeatable: ustaw natrue, jeśli właściwość może mieć wiele wartości. Na przykład film ma jedną datę premiery, ale wielu aktorów.isSortable: ustaw natrue, jeśli właściwość może być używana do sortowania. Nie może mieć wartościtrue, jeśliisRepeatablema wartośćtruelub jeśli właściwość znajduje się w powtarzalnym obiekcie podrzędnym.isFacetable: ustaw natrue, jeśli właściwość może być używana do generowania aspektów (atrybutów używanych do zawężania wyników wyszukiwania).- Wymaga, aby wartość
isReturnablebyła równatrue. - Obsługiwane tylko w przypadku właściwości typu wyliczeniowego, logicznego i tekstowego.
- Wymaga, aby wartość
isWildcardSearchable: ustaw wartośćtrue, aby umożliwić użytkownikom przeprowadzanie wyszukiwań z symbolami wieloznacznymi w tej właściwości. Ta opcja jest dostępna tylko w przypadku właściwości tekstowych, a jej działanie zależy od ustawieniaexactMatchWithOperator:- Jeśli
exactMatchWithOperatortotrue: wartość tekstowa jest traktowana jako pojedynczy token. Zapytanie takie jakscience-*pasuje do wartościscience-fiction. - Jeśli
exactMatchWithOperatorma wartośćfalse: wartość tekstowa jest tokenizowana. Zapytanie takie jaksci*lubfi*pasuje doscience-fiction, alescience-*już nie.
- Jeśli
Określ typ
Ustaw typ danych, definiując odpowiedni obiekt opcji właściwości (np. textPropertyOptions). Jeśli znasz wszystkie możliwe wartości, użyj wyliczeń (enumPropertyOptions). Usługa może mieć tylko 1 typ danych.
Definiowanie opcji operatora
operatorOptions wyjaśnij, jak właściwość działa jako operator wyszukiwania;
Każdy operatorOptions musi mieć operatorName (np. title). Jest to parametr, który użytkownicy wpisują w zapytaniach (np. title:titanic). Używaj intuicyjnych nazw i udostępniaj je użytkownikom.
Możesz udostępniać operatorName w usługach tego samego typu. Zapytania
używające tej nazwy pobierają wyniki ze wszystkich pasujących usług.
Właściwości, według których można sortować, mogą obejmować lessThanOperatorName i greaterThanOperatorName w przypadku zapytań porównawczych. Właściwości tekstu mogą używać exactMatchWithOperator, aby traktować całą wartość jako pojedynczy token.
Dodawanie opcji wyświetlania
Opcjonalna sekcja displayOptions zawiera displayLabel. Jest to przyjazna dla użytkownika etykieta wyświetlana w wynikach wyszukiwania.
Dodawanie operatorów filtrowania sugestii
Użyj suggestionFilteringOperators[], aby zdefiniować właściwość, która filtruje sugestie autouzupełniania (np. filtrowanie sugestii filmów według preferowanego gatunku użytkownika). Możesz zdefiniować tylko 1 filtr sugestii.
Rejestrowanie schematu
Zarejestruj schemat w usłudze schematów za pomocą identyfikatora źródła danych. Wyślij żądanie UpdateSchema:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
Użyj validateOnly: true, aby przetestować schemat bez rejestrowania go.
Indeksowanie danych
Po rejestracji wypełnij źródło danych za pomocą wywołań Index, zwykle za pomocą łącznika.
Przykładowa prośba o zindeksowanie:
{
"name": "datasource/<data_source_id>/items/titanic",
"metadata": {
"title": "Titanic",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [{
"name": "movieTitle",
"textValues": { "values": ["Titanic"] }
}]
}
},
"itemType": "CONTENT_ITEM"
}
Testowanie schematu
Przed wdrożeniem w środowisku produkcyjnym przetestuj małe repozytorium. Utwórz listę ACL, która ogranicza wyniki do użytkownika testowego.
- Ogólne zapytanie: wyszukaj ciąg znaków (np. „titanic”), aby zobaczyć wszystkie pasujące elementy.
- Zapytanie z operatorem: użyj operatora (np.
actor:Zane), aby ograniczyć wyniki.
Dostosowywanie schematu
Monitoruj opinie użytkowników i dostosowuj schemat. Możesz indeksować nowe pola lub zmieniać nazwy operatorów, aby były bardziej intuicyjne.
Ponowne indeksowanie po zmianie schematu
Nie musisz ponownie indeksować, aby wprowadzić zmiany w tych elementach:
- Nazwy operatorów.
- Limity liczbowe.
- Uporządkowany ranking.
- odświeżania lub opcji wyświetlania.
Musisz ponownie zindeksować:
- dodawanie i usuwanie usług lub obiektów;
- Zmienianie
isReturnable,isFacetablelubisSortablenatrue. - Oznaczanie usługi
isSuggestable.
Niedozwolone zmiany właściwości
Zmiany, które powodują uszkodzenie indeksu lub niespójne wyniki, są niedozwolone. Obejmują one:
- Typ danych lub nazwa właściwości.
exactMatchWithOperatorlubretrievalImportance.
Wprowadzanie złożonych zmian w schemacie
Aby wprowadzić niedozwoloną zmianę, przenieś właściwości ze starej definicji do nowej:
- Dodaj do schematu nową właściwość o innej nazwie.
- Zarejestruj schemat z nowymi i starymi właściwościami.
- Wypełnij indeks, używając tylko nowej właściwości.
- Usuń starą właściwość ze schematu.
- Zaktualizuj kod zapytania, aby używać nowej nazwy usługi.
Cloud Search przechowuje usunięte elementy przez 30 dni, aby zapobiec problemom z ponownym wykorzystaniem.
Ograniczenia rozmiaru
- Maksymalnie 10 obiektów najwyższego poziomu.
- Maksymalna głębokość to 10 poziomów.
- Maksymalnie 1000 pól na obiekt (w tym pola zagnieżdżone).
Następne kroki
- Utwórz interfejs wyszukiwania.
- Popraw jakość wyszukiwania
- Strukturyzuj schemat, aby zapewnić optymalną interpretację zapytań.
- Określ synonimy.