Découvrez la signification du bruit, où il est ajouté et son impact sur vos mesures.
Les rapports de synthèse sont le résultat du regroupement de rapports agrégables. Lorsque les rapports agrégables sont regroupés par un collecteur et traités par le service d'agrégation, du bruit (une quantité aléatoire de données) est ajouté aux rapports récapitulatifs générés. Du bruit est ajouté pour protéger la confidentialité des utilisateurs. L'objectif de ce mécanisme est de disposer d'un framework compatible avec les mesures à confidentialité différentielle.
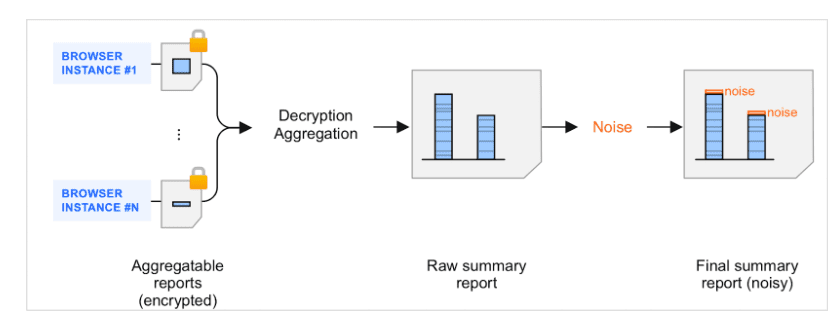
Présentation du bruit dans les rapports récapitulatifs
Bien que l'ajout de bruit ne fasse généralement pas partie de la mesure des annonces aujourd'hui, il arrive souvent qu'il ne modifie pas sensiblement la façon dont vous interprétez vos résultats.
Il peut être utile d'y penser de la manière suivante : Seriez-vous confiant de prendre une décision sur la base d'une certaine donnée si ces données ne comportent pas de bruit ?
Par exemple, un annonceur peut-il modifier en toute confiance la stratégie ou les budgets de sa campagne si la campagne A enregistre 15 conversions et la campagne B en enregistre 16 ?
Si la réponse est non, le bruit n'a pas d'importance.
Vous devez configurer votre utilisation de l'API de la manière suivante:
- La réponse à la question ci-dessus est oui.
- Le bruit est géré de manière à ne pas avoir d'impact significatif sur votre capacité à prendre une décision basée sur certaines données. Voici comment procéder: pour un nombre minimal attendu de conversions, vous devez maintenir le bruit de la métrique collectée en dessous d'un certain pourcentage.
Dans cette section et les suivantes, nous décrirons les stratégies pour atteindre 2.
Concepts fondamentaux
Le service d'agrégation ajoute du bruit une fois à chaque valeur récapitulative, c'est-à-dire une fois par clé, chaque fois qu'un rapport de synthèse est demandé.
Ces valeurs de bruit sont tirées de manière aléatoire à partir d'une distribution de probabilité spécifique, discutée ci-dessous.
Tous les éléments qui ont un impact sur le bruit reposent sur deux concepts principaux.
La répartition du bruit (voir les détails ci-dessous) est la même quelle que soit la valeur récapitulative, faible ou élevée. Par conséquent, plus la valeur de résumé est élevée, moins le bruit est susceptible d'avoir un impact par rapport à cette valeur.
Par exemple, supposons qu'une valeur totale d'achat agrégée de 20 000 $et une valeur totale d'achat agrégée de 200 $soient toutes deux sujettes au bruit sélectionné à partir de la même distribution.
Supposons que le bruit de cette distribution varie approximativement entre -100 et +100.
- Pour la valeur d'achat récapitulative de 20 000 $, le bruit varie entre 0 et 100/20 000=0,5%.
- Pour la valeur d'achat récapitulative de 200 $, le bruit varie entre 0 et 100/200=50%.
Par conséquent, le bruit est susceptible d'avoir un impact plus faible sur la valeur d'achat agrégée de 20 000 $que sur la valeur d'achat de 200 $. Concernant le bruit, un montant de 20 000 $ est susceptible d'être moins bruyant, c'est-à-dire qu'il présente probablement un rapport signal/bruit plus élevé.
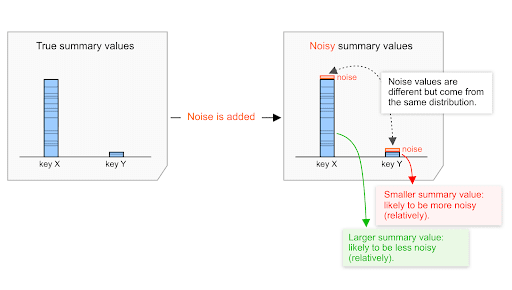
Cela a quelques implications pratiques importantes qui sont décrites dans la section suivante. Ce mécanisme fait partie de la conception de l'API, et les implications pratiques sont à long terme. Elles continueront à jouer un rôle important lorsque les technologies publicitaires conçoivent et évaluent diverses stratégies d'agrégation.
Bien que le bruit soit tiré de la même distribution quelle que soit la valeur récapitulative, cette distribution dépend de plusieurs paramètres. L'un de ces paramètres, epsilon, pourrait être modifié par les technologies publicitaires au cours de la phase d'évaluation afin d'évaluer différents ajustements d'utilité et de confidentialité. Toutefois, cette possibilité d'ajuster epsilon est considérée comme temporaire. N'hésitez pas à nous faire part de vos commentaires sur vos cas d'utilisation et les valeurs d'epsilon qui fonctionnent bien.
Bien qu'une entreprise de technologie publicitaire ne contrôle pas directement la façon dont le bruit est ajouté, elle peut influencer son impact sur ses données de mesure. Dans les sections suivantes, nous verrons comment influencer le bruit dans la pratique.
Avant cela, examinons de plus près la façon dont le bruit est appliqué.
Zoom avant: mode d'application du bruit
Une répartition du bruit
Le bruit est extrait de la distribution de Laplace, avec les paramètres suivants:
- Une moyenne (
μ) de 0. Cela signifie que la valeur de bruit la plus probable est 0 (aucun bruit ajouté), et que la valeur du bruit est aussi susceptible d'être plus faible que l'original qu'elle l'est d'être supérieure (ce que l'on appelle parfois un niveau de bruit impartial). - Un paramètre d'échelle de
b = CONTRIBUTION_BUDGET/epsilon.CONTRIBUTION_BUDGETest défini dans le navigateur.epsilonest corrigé dans le serveur d'agrégation.
Le diagramme suivant illustre la fonction de densité de probabilité pour une distribution de Laplace avec μ=0, b = 20:
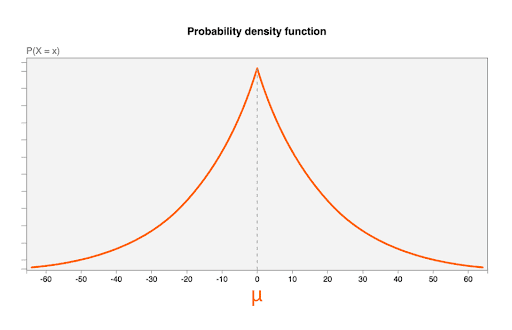
Des valeurs de bruit aléatoires, une distribution de bruit
Supposons qu'une technologie publicitaire demande des rapports récapitulatifs pour deux clés d'agrégation, key1 et key2.
Le service d'agrégation sélectionne deux valeurs de bruit x1 et x2, en suivant la même répartition du bruit. x1 est ajouté à la valeur récapitulative de la clé 1 et x2 à la valeur récapitulative de la clé 2.
Dans les diagrammes, nous représenterons les valeurs de bruit comme identiques. Il s'agit d'une simplification. En réalité, les valeurs de bruit varient, car elles sont tirées de manière aléatoire à partir de la distribution.
Cela montre que les valeurs de bruit proviennent toutes de la même distribution et sont indépendantes de la valeur récapitulative à laquelle elles s'appliquent.
Autres propriétés du bruit
Le bruit est appliqué à chaque valeur récapitulative, y compris les valeurs vides (0).
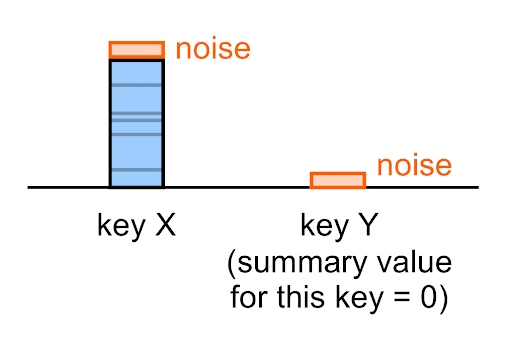
Par exemple, même si la valeur de résumé "true" pour une clé donnée est 0, la valeur de résumé du bruit que vous verrez dans le rapport de synthèse pour cette clé ne sera (probablement) pas 0.
Le bruit peut être un nombre positif ou négatif.
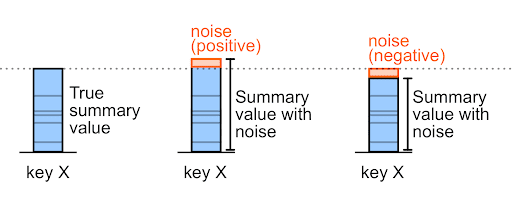
Par exemple, pour un achat avant bruit de 327 000, le bruit peut être de +6 000 ou de -6 000 (il s'agit d'exemples de valeurs arbitraires).
Évaluer le bruit
Calcul de l'écart-type du bruit
L'écart type du bruit est le suivant:
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2)
Exemple
Avec epsilon = 10, l'écart-type du bruit est le suivant:
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2) = (65,536/10)*sqrt(2) = 9,267
Évaluer les cas où les différences de mesure sont importantes
Comme vous connaissez l'écart type du bruit ajouté à chaque valeur générée par le service d'agrégation, vous pouvez déterminer des seuils appropriés à des fins de comparaison afin de déterminer si les différences observées peuvent être dues au bruit.
Par exemple, si le bruit ajouté à une valeur est d'environ +/- 10 (en tenant compte de l'ajustement) et que la différence de valeur entre deux campagnes est supérieure à 100, vous pouvez probablement en conclure que la différence de valeur mesurée entre chaque campagne n'est pas due uniquement au bruit.
Interagir et partager des commentaires
Vous pouvez participer et tester cette API.
- Découvrez les rapports agrégables et le service d'agrégation, posez des questions et suggérez des commentaires.
- Consultez les guides sur l'attribution de rapports.
- Posez des questions et participez à des discussions dans le dépôt de l'assistance Privacy Sandbox pour les développeurs.
Étapes suivantes
- Pour savoir quelles variables vous pouvez contrôler pour améliorer le rapport signal/bruit, consultez Utiliser le bruit.
- Pour vous aider à planifier vos stratégies de création de rapports d'agrégation, consultez Tester les décisions de conception des rapports récapitulatifs.
- Essayez l'atelier sur le bruit.