Cette section explique comment utiliser Meridian pour planifier des scénarios, y compris comment intégrer des données et des hypothèses sur l'avenir dans les scénarios d'optimisation du budget.
Pour optimiser un futur budget, Meridian prévoit le résultat incrémental en fonction d'un ensemble d'hypothèses sur l'avenir. Meridian ne prédit pas la valeur du résultat futur en soi, mais uniquement la partie incrémentale. Pour en savoir plus, consultez Pourquoi Meridian ne prévoit-il pas de résultats.
Qu'est-ce que la planification de scénarios ?
La planification de scénarios est une analyse MMM qui peut intégrer des hypothèses sur l'avenir. Pour l'analyse post-modélisation (ROI, courbes de réponse et optimisation du budget, par exemple), Meridian utilise les données historiques pour formuler des hypothèses par défaut. Ces hypothèses sont parfois raisonnables pour la planification future, mais pas toujours. De nouvelles données peuvent être intégrées à l'analyse pour modifier les hypothèses si nécessaire.
Voici quelques exemples de différences entre les stratégies futures et historiques.
- Coût par unité média : le coût par unité média sur un canal a peut-être changé ou devrait normalement changer. Consultez les exemples de code 1 et 2.
- Revenus par unité de KPI : les revenus par KPI (par exemple, le prix unitaire ou la valeur vie) ont peut-être changé ou devraient normalement changer. Consultez l'exemple de code 3.
- Modèle de diffusion : il est possible que vos modèles de diffusion historiques et futurs ne correspondent pas. Par exemple, vous avez peut-être introduit un nouveau canal média pendant la période d'entraînement du modèle. Le modèle de diffusion historique du nouveau canal peut contenir des zéros ou afficher une tendance à l'augmentation qui n'est pas censée se poursuivre. Consultez l'exemple de code 4.
Métriques d'analyse post-modélisation
La planification de scénarios affecte les définitions de métriques, mais pas l'estimation des paramètres. Pour illustrer ces concepts, prenons un cas hypothétique où la méthode des moindres carrés ordinaires est utilisée pour estimer l'effet curatif d'un médicament, où nous supposons que la posologie en mg (X) affecte linéairement le résultat (Y), comme dans le modèle suivant :
\[ Y = \alpha + X \beta + \epsilon \ . \]
L'effet curatif dépend du coefficient de dosage $\beta$, qui est un paramètre estimé à partir d'un ensemble de données observé. Il peut avoir de nombreuses définitions de métriques possibles. Par exemple, vous pouvez définir l'effet d'un médicament comme la variation attendue du résultat causée par une dose de 10 mg ($10 \beta$) ou une dose de 15 mg ($15 \beta$). Vous pouvez estimer les deux définitions de l'effet curatif à l'aide du même modèle et de la même estimation du coefficient $\hat{\beta}$.
Dans Meridian, la définition des métriques d'analyse post-modélisation dépend des caractéristiques de certaines données. Par exemple, le ROI dépend d'une période spécifiée, d'un ensemble de zones géographiques, d'un modèle de diffusion (répartition relative des unités média entre les zones géographiques et les périodes), du nombre total d'unités média par canal, du coût par unité média et des revenus par KPI. Les autres métriques d'analyse post-modélisation incluent le résultat attendu, le résultat incrémental, le ROI marginal, le CPKI, les courbes de réponse et la répartition optimale du budget. Par défaut, ces métriques sont définies à l'aide d'input_data transmis à Meridian. Toutefois, new_data peut être fourni pour spécifier d'autres définitions de métriques. Le tableau 1 indique les propriétés de données qui affectent la définition de chaque métrique.
| Période | Ensemble de zones géographiques | Modèle de diffusion | Nombre total d'unités média par canal | Coût par unité média | Revenus par KPI (le cas échéant) | Valeurs de contrôle | |
|---|---|---|---|---|---|---|---|
expected_outcome |
X | X | X | X | X | X | |
incremental_outcome |
X | X | X | X | X | ||
roi, marginal_roi et cpik |
X | X | X | X | X | X | |
response_curves |
X | X | X | X | X | ||
BudgetOptimizer.optimize |
X | X | X | ‡ | X | X |
‡ L'optimisation du budget utilise le nombre total d'unités média par canal (en combinaison avec les hypothèses de modèle de diffusion fixe et de coût par unité média) pour attribuer un budget total par défaut (optimisation du budget fixe uniquement) et des limites de budget au niveau du canal. Si ces paramètres sont remplacés à l'aide des arguments
budgetetpct_of_spenddeBudgetOptimizer.optimize, le nombre total d'unités média par canal n'aura aucune incidence sur l'optimisation.
L'estimation de chaque métrique d'analyse post-modélisation dépend de la distribution a posteriori des paramètres du modèle. La distribution a posteriori est liée à l'input_data transmis au constructeur d'objet Meridian (sauf le KPI pour les zones géographiques et les périodes spécifiées dans ModelSpec.holdout_id). La distribution a posteriori est estimée lorsque sample_posterior est appelé, et cette estimation est utilisée pour toutes les analyses post-modélisation.
Argument new_data
La valeur par défaut de chaque propriété de données du tableau 1 est dérivée d'input_data transmis à Meridian. Dans l'analyse post-modélisation, l'utilisateur peut remplacer les données d'entrée à l'aide de l'argument new_data disponible dans la plupart des méthodes. Chaque méthode n'utilise qu'un sous-ensemble des attributs new_data. Le tableau 2 indique les attributs new_data utilisés par chaque méthode.
new_data utilisés par chaque méthode
media, reach et frequency |
revenue_per_kpi |
media_spend et rf_spend |
organic_media, organic_reach, organic_frequency et non_media_treatments |
controls |
time |
La dimension temporelle doit correspondre à input_data |
|
|---|---|---|---|---|---|---|---|
expected_outcome |
X | X | X | X | Oui | ||
incremental_outcome |
X | X | X | Non | |||
roi, cpik et marginal_roi |
X | X | X | Non | |||
response_curves |
X | X | X | X | Non | ||
BudgetOptimizer.optimize |
X | X | X | X | Non |
Les propriétés de données sont dérivées de new_data de la même manière que les données d'entrée. Par exemple, le coût par unité média est calculé pour chaque zone géographique et chaque période en divisant les dépenses par les unités média.
Si la période de new_data correspond à celle des données d'entrée, vous n'avez pas besoin de spécifier tous les attributs new_data utilisés par la méthode que vous appelez. Vous pouvez fournir n'importe quel sous-ensemble d'attributs et ceux restants seront obtenus à partir des données d'entrée.
Toutefois, si la période de new_data est différente de celle des données d'entrée, vous devrez transmettre tous les attributs new_data utilisés par la méthode que vous appelez. Tous les attributs new_data doivent avoir la même dimension temporelle.
Seule la méthode expected_outcome exige que la dimension temporelle corresponde aux données d'entrée.
Les méthodes response_curves et optimize nécessitent également que des libellés de date soient transmis à new_data.time si la dimension temporelle ne correspond pas aux données d'entrée. Les libellés de date n'ont aucune incidence sur les calculs, mais ils sont utilisés pour les libellés d'axe dans certaines visualisations.
Méthode d'aide pour créer new_data afin d'optimiser le budget
Il peut sembler contre-intuitif que les dépenses au niveau du canal soient à la fois une sortie et une entrée new_data de BudgetOptimizer.optimize. La sortie correspond à l'allocation optimale des dépenses, tandis que les dépenses d'entrée sont utilisées avec les entrées d'unités média afin de définir un coût supposé par unité média pour chaque zone géographique et chaque période. L'entrée des dépenses permet également de définir le budget total d'un scénario d'optimisation à budget fixe et les limites de budget au niveau du canal. Toutefois, ces valeurs peuvent être remplacées à l'aide des arguments budget et pct_of_spend.
La méthode optimizer.create_optimization_tensors est disponible pour les utilisateurs qui préfèrent saisir directement les données de coût par unité média. Elle permet de créer un objet new_data destiné spécifiquement à être transmis à la méthode BudgetOptimizer.optimize à l'aide des options de données d'entrée suivantes.
Canaux sans couverture ni fréquence :
- Unités média et coût par unité média
- Dépenses et coût par unité média
Canaux avec couverture et fréquence lorsque use_optimal_frequency=True :
- Impressions et coût par impression
- Dépenses et coût par impression
Canaux avec couverture et fréquence lorsque use_optimal_frequency=False :
- Impressions, fréquence et coût par impression
- Dépenses, fréquence et coût par impression
Exemples illustratifs
L'objectif de cette section est d'expliquer comment les calculs sont effectués pour les principales fonctions d'analyse post-modélisation : Analyzer.incremental_outcome, Analyzer.roi, Analyzer.response_curves et BudgetOptimizer.optimize.
Plus précisément, ces exemples montrent comment le calcul de chaque méthode est effectué à l'aide d'input_data et de new_data. Dans ces exemples, input_data inclut une "période de pré-modélisation" pour les données des unités média, contrairement à new_data. La "période de pré-modélisation" contient des données sur les unités média antérieures à la première période de la "période de modélisation", ce qui permet au modèle de prendre correctement en compte l'effet différé de ces unités. Lorsque new_data couvre une période différente de celle d'input_data (comme dans ces exemples), les données des unités média doivent comporter le même nombre de périodes que toutes les autres nouvelles données.
En plus de new_data, chacune de ces méthodes comporte un argument selected_times. Ces arguments personnalisent la définition de la métrique de sortie, et non l'estimation des paramètres (pour en savoir plus, consultez Qu'est-ce que la planification de scénarios ?).
La méthode Analyzer.incremental_outcome comporte également un argument media_selected_times qui permet de personnaliser davantage la définition du résultat incrémental. Cet argument offre à Analyzer.incremental_outcome plus de flexibilité que les autres méthodes. Les autres méthodes ne comportent pas cet argument, car leurs calculs impliquent de faire correspondre le résultat incrémental à un coût associé, ce qui peut être ambigu lorsque selected_times et media_selected_times sont personnalisables. Toutefois, vous pouvez associer manuellement la sortie incremental_outcome aux données de coût pour créer des définitions de ROI personnalisées, par exemple.
Dans un modèle au niveau géographique, chaque zone géographique possède son propre résultat incrémental, son propre ROI et sa propre courbe de réponse. Vous pouvez considérer que chaque exemple représente une seule zone géographique.
Les résultats au niveau national sont obtenus en agrégeant les données des zones géographiques. Chacune de ces méthodes comporte un argument selected_geos, qui permet à l'utilisateur de spécifier un sous-ensemble de zones géographiques à inclure dans la définition de la métrique.
Résultat incrémental
Pour chaque canal média, la méthode incremental_outcome compare le résultat attendu dans deux scénarios contrefactuels. Dans le premier scénario, les unités média sont définies sur les valeurs historiques. Dans le second, les unités média sont définies sur zéro pour toutes les périodes ou certaines d'entre elles.
L'argument media_selected_times détermine les périodes pendant lesquelles les unités média sont définies sur zéro.
L'argument selected_times détermine la période pendant laquelle le résultat incrémental est mesuré.
Utiliser input_data
Par défaut, la définition du résultat incrémental définit media_selected_times sur toutes les périodes, y compris la "période de modélisation" et la "période de pré-modélisation".
Les unités média input_data peuvent éventuellement inclure une "période de pré-modélisation", ce qui permet au modèle de prendre correctement en compte l'effet différé de ces unités.
La valeur par défaut selected_times correspond à toutes les périodes de la "période de modélisation", ce qui signifie que le résultat incrémental est agrégé pour toutes les périodes de la "période de modélisation".
L'input_data peut contenir des unités média pendant une "période de pré-modélisation" pour tenir compte des effets différés. La "période de pré-modélisation" ne contient aucune donnée, à l'exception des unités média. C'est la raison pour laquelle les cellules sont vides dans l'illustration.
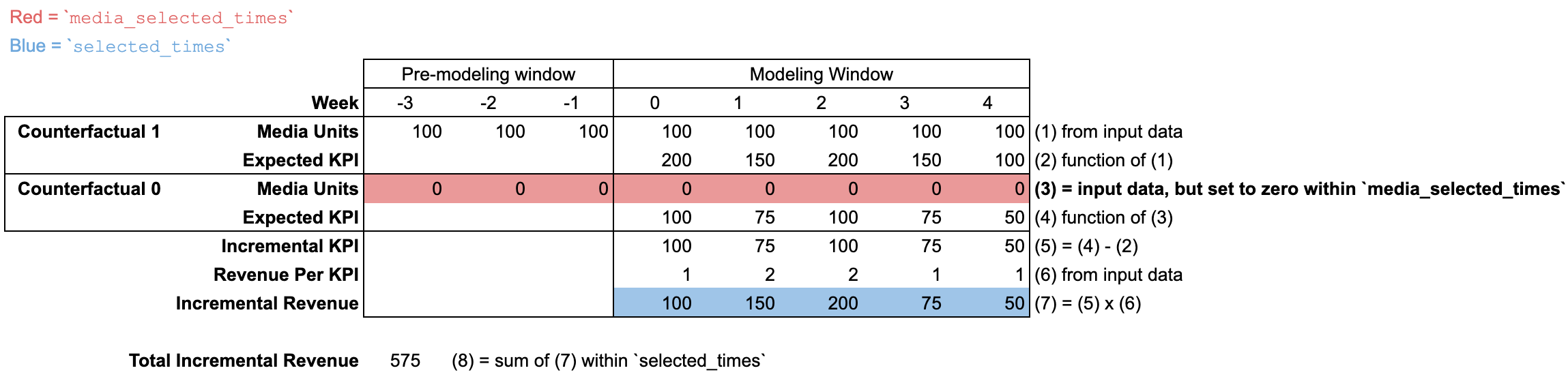
Utiliser input_data lorsque selected_times et media_selected_times sont modifiés
Pour comprendre l'utilisation de new_data dans incremental_outcome et d'autres méthodes, il est important de comprendre les arguments selected_times et media_selected_times.
Dans cet exemple, media_selected_times est défini sur une seule période (semaine 0).
Pendant ce temps, selected_times correspond aux semaines 0 à 3. Cet exemple illustre un scénario où max_lag est défini sur 3 dans ModelSpec. Le résultat incrémental doit donc être nul pour les quatre semaines et les suivantes. Par conséquent, cette combinaison de media_selected_times et selected_times permet de capturer l'intégralité de l'impact à long terme des unités média de la semaine 0.
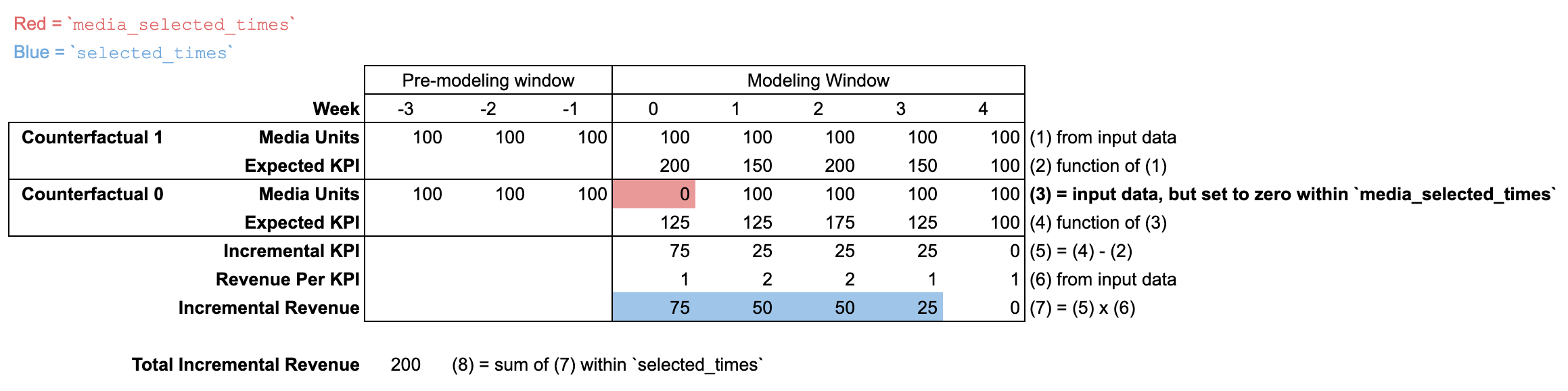
Utiliser new_data avec une nouvelle période
Lorsque new_data est transmis avec un nombre de périodes différent de celui d'input_data, il n'y a pas de "période de pré-modélisation". On suppose que les unités média sont nulles pour toutes les périodes antérieures à la période new_data.
Par défaut, la définition du résultat incrémental définit media_selected_times et selected_times sur toutes les périodes de la période new_data.
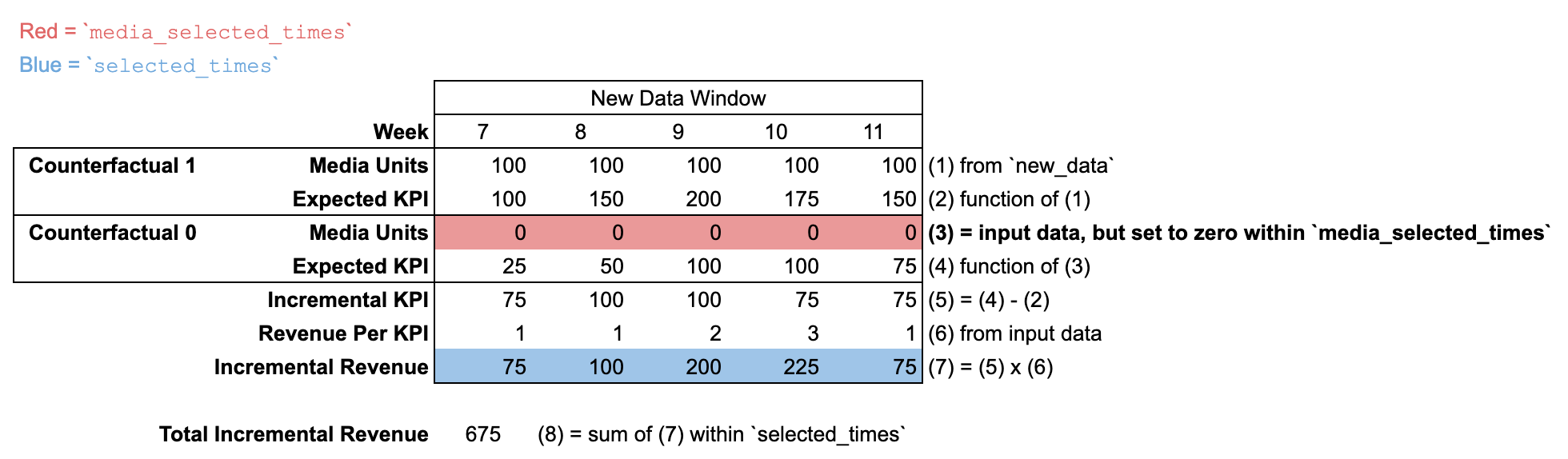
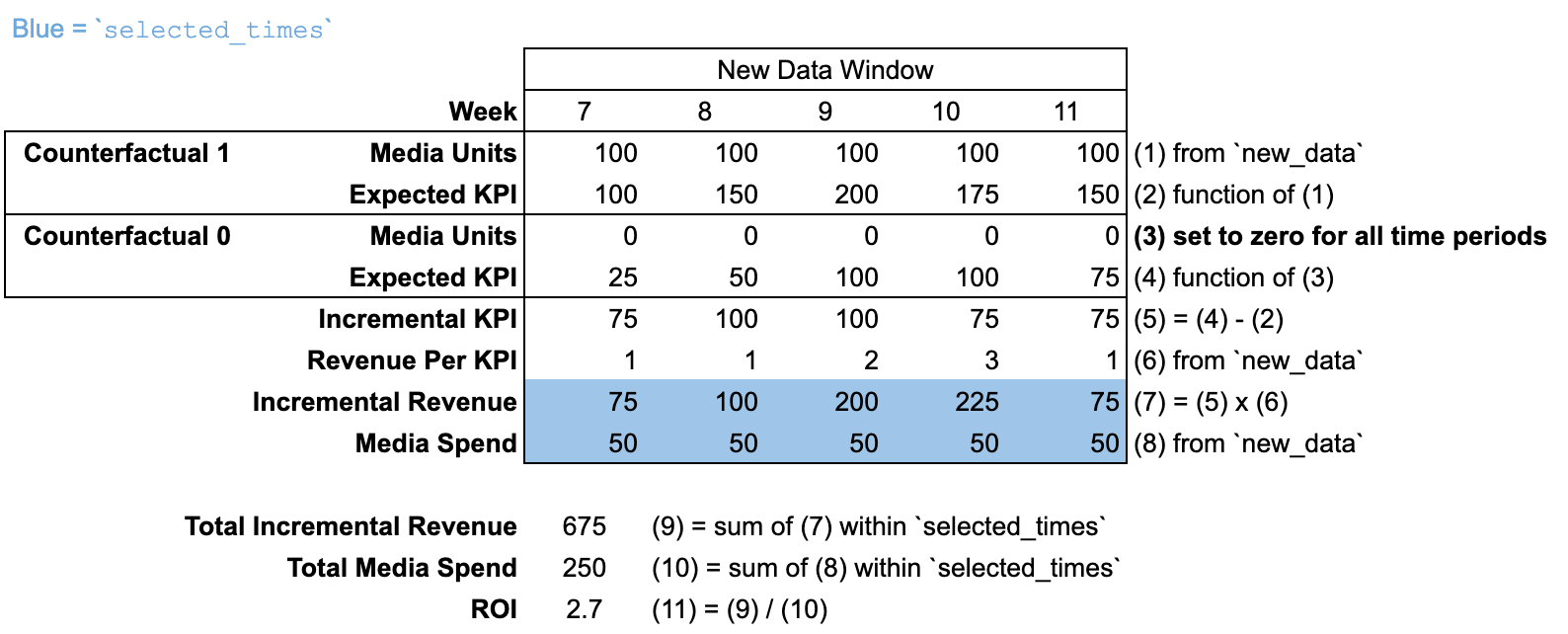
ROI
Pour chaque canal média, la méthode roi divise le résultat incrémental généré au cours de selected_times par les dépenses au cours de selected_times. La méthode roi ne comporte aucun argument media_selected_times. Le résultat incrémental compare le contrefactuel où les unités média sont définies sur les valeurs historiques par rapport au contrefactuel, où les unités média sont définies sur zéro pour toutes les périodes.
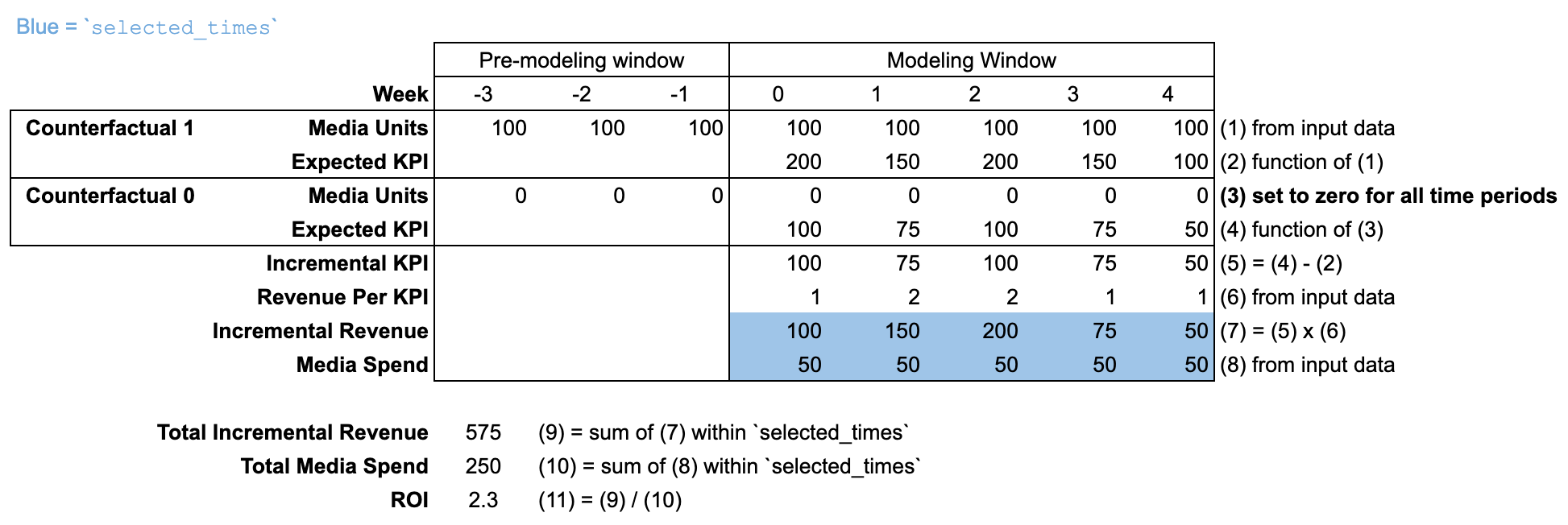
Utiliser input_data
Par défaut, selected_times est défini sur l'intégralité de la "période de modélisation". Le contrefactuel définit les unités média sur zéro pour toutes les périodes dans la "période de modélisation" et la "période précédant la modélisation".
Utiliser new_data avec une nouvelle période
Lorsque new_data est transmis avec un nombre de périodes différent de celui d'input_data, il n'y a pas de "période de pré-modélisation". On suppose que les unités média sont nulles pour toutes les périodes antérieures à la période new_data.
Courbes de réponse et optimisation du budget
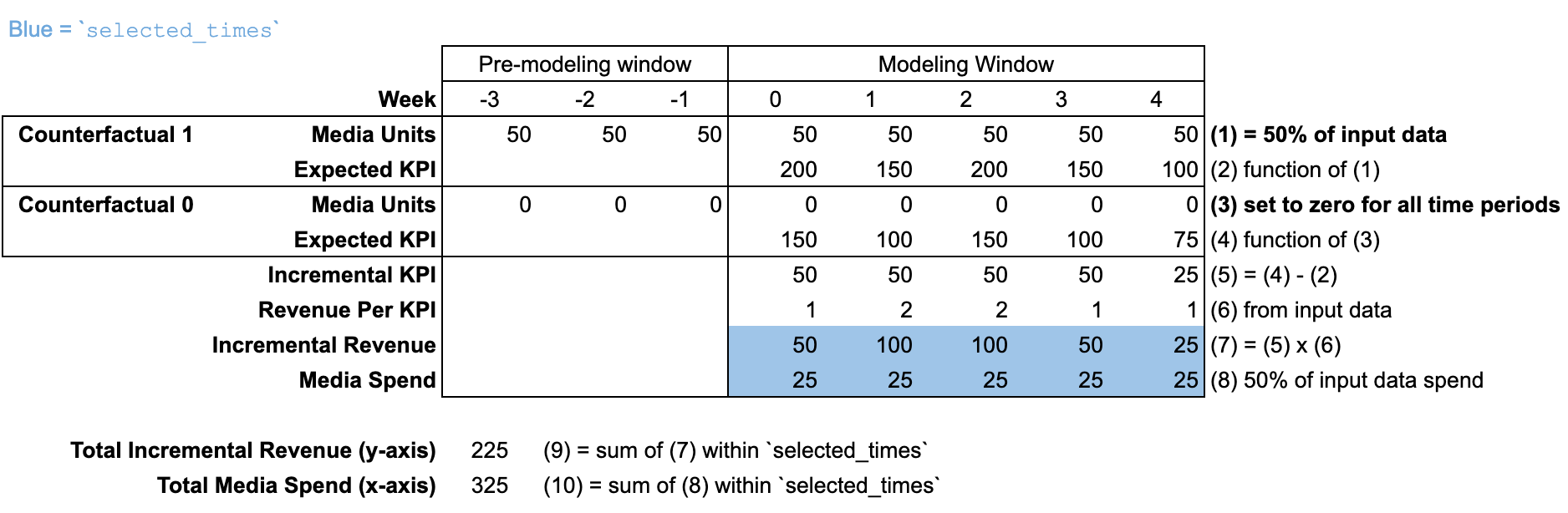
La méthode response_curves est semblable à roi, car le résultat et les dépenses incrémentaux sont tous deux agrégés sur selected_times, qui est défini sur l'ensemble de la "période de modélisation" par défaut. Chaque point de l'axe X de la courbe de réponse correspond à un pourcentage des dépenses historiques dans la plage selected_times. Cette méthode calcule le résultat incrémental correspondant (axe Y) en ajustant les unités média historiques en fonction du même facteur. Le facteur de scaling est appliqué aux unités média de la "période de modélisation" et de la "période de pré-modélisation".
L'optimisation du budget est basée sur les courbes de réponse. La même illustration s'applique donc à la fois aux courbes de réponse et à l'optimisation du budget. Notez que l'argument selected_times est devenu obsolète pour BudgetOptimizer.optimize, qui utilise désormais les arguments start_date et end_date.
Utiliser input_data
Par défaut, selected_times est défini sur l'intégralité de la "période de modélisation". Les unités média définis par le contrefactuel sont ajustés pour toutes les périodes dans la "période de modélisation" et la "période de pré-modélisation".
Dans cette illustration, la courbe de réponse est calculée à 50 % du budget input_data.
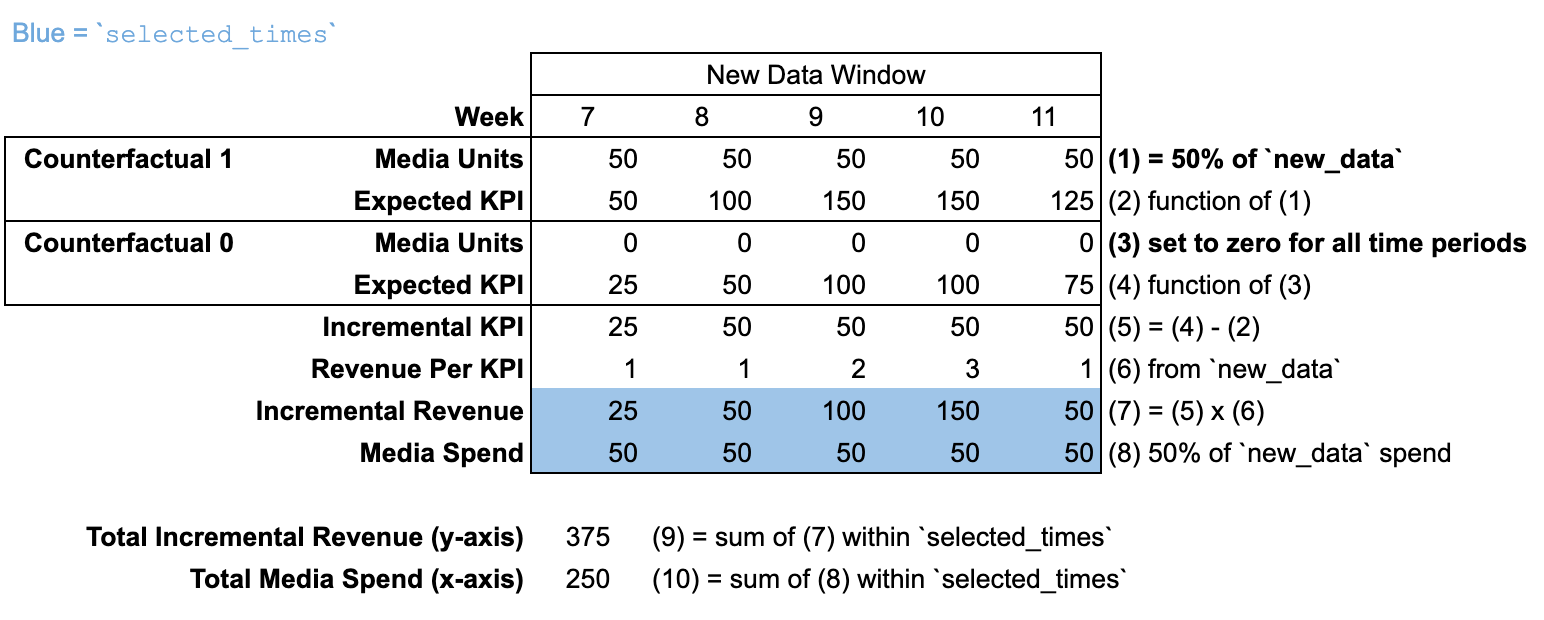
Utiliser new_data avec une nouvelle période
Lorsque new_data est transmis avec un nombre de périodes différent de celui d'input_data, il n'y a pas de "période de pré-modélisation". On suppose que les unités média sont nulles pour toutes les périodes antérieures à la période new_data.
Dans cette illustration, la courbe de réponse est calculée à 50 % du budget new_data.
Exemples de code d'optimisation du budget
Les exemples suivants illustrent l'efficacité de new_data pour optimiser le budget et planifier de futurs scénarios. À des fins d'illustration, chaque exemple se concentre sur un attribut clé des données d'entrée qui peut être modifié à l'aide de new_data. Toutefois, toutes ces hypothèses (et d'autres) peuvent être combinées dans un même scénario d'optimisation.
Imaginons que vous souhaitiez optimiser votre budget pour un prochain trimestre dont le modèle de diffusion, le coût par unité média et les revenus par KPI devraient être semblables à ceux du dernier trimestre des données d'entrée. Vous pouvez utiliser le dernier trimestre de données d'entrée pour représenter le scénario à venir et ajuster les aspects censés changer. Chacun des exemples en est l'illustration.
Dans des scénarios futurs plus complexes, il peut être préférable de remplacer entièrement les données d'entrée par de nouvelles données. Pour ce faire, vous pouvez construire les tableaux au format Python ou charger les données à partir d'un fichier CSV.
Dans ces exemples, il existe trois canaux média. Le KPI est exprimé en unités vendues et revenue_per_kpi est fourni. À des fins d'illustration, chaque exemple exécute un scénario d'optimisation basé sur le quatrième trimestre 2024. Un élément clé du scénario est modifié dans chaque exemple, et l'argument new_data est utilisé pour intégrer la modification.
Le code de chaque exemple part du principe qu'un modèle Meridian a été initialisé en tant que mmm, que la méthode sample_posterior a été appelée et qu'un BudgetOptimizer a été initialisé en tant qu'opt.
mmm = model.Meridian(...)
mmm.sample_posterior(...)
opt = optimizer.BudgetOptimizer(mmm)
Exemple 1 : Nouveau coût par unité média pour un seul canal
Imaginons que le coût par unité média sur le premier canal soit censé doubler dans un avenir proche. Vous souhaitez donc doubler le coût par unité média supposé de ce canal dans l'optimisation. Pour ce faire, vous pouvez créer un tableau de dépenses qui correspond aux données d'entrée, sauf que les dépenses sont doublées pour le premier canal. Le tableau est transmis au constructeur DataTensors, qui est à son tour envoyé à l'argument new_data de l'optimisation.
Modifier media_spend affecte également le budget total par défaut pour l'optimisation à budget fixe, ainsi que les limites de dépenses par défaut. Ces valeurs par défaut peuvent être remplacées à l'aide des arguments d'optimisation budget et pct_of_spend.
Il est important de connaître ces arguments et de les personnaliser si nécessaire.
# Create `new_data` from `input_data`, but double the spend for channel 0.
new_spend = mmm.input_data.media_spend
new_spend[:, :, 0] *= 2
new_data = analyzer.DataTensors(media_spend=new_spend)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
Exemple 2 : Nouveau coût par média pour tous les canaux
Imaginons que le coût par unité média soit censé changer dans un avenir proche pour tous les canaux. Vous souhaitez donc modifier le coût par unité média supposé de tous les canaux dans l'optimisation. Pour chaque canal, le coût anticipé est une constante connue, qui est la même pour les zones géographiques et les périodes. La méthode d'aide create_optimization_tensors, qui crée un objet DataTensors, est pratique pour cette tâche, car le coût par unité média (cpmu) est une entrée directe.
La méthode create_optimization_tensors nécessite de transmettre tous les arguments d'optimisation. Vous pouvez transmettre media ou media_spend (avec la dimension géographique et temporelle) pour spécifier le modèle de diffusion. La dimension temporelle de tous les arguments de create_optimization_tensors doit correspondre (media ne peut pas inclure de périodes supplémentaires pour les effets différés).
# Create `new_data` using the helper method. The cost per media unit (cpmu) is
# set to a constant value for each channel.
new_cpmu = np.array([0.1, 0.2, 0.5])
media_excl_lag = mmm.input_data.media[:, -mmm.n_times:, :]
new_data = opt.create_optimization_tensors(
time=mmm.input_data.time,
cpmu=new_cpmu,
media=media_excl_lag,
revenue_per_kpi=mmm.input_data.revenue_per_kpi,
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
La même tâche peut être accomplie en créant directement l'objet DataTensors. Pour ce faire, les dépenses sont calculées en ajustant les unités média de chaque canal en fonction du coût par unité média pour ce canal.
# Create `new_data` without the helper method.
# In this example, `mmm.n_media_times > mmm.n_times` because the `media` data
# contains additional lag history. These time periods are discarded to create
# the new spend data.
media_excl_lag = mmm.input_data.media[:, -mmm.n_times:, :]
new_spend = media_excl_lag * np.array([0.1, 0.2, 0.5])
new_data = analyzer.DataTensors(media_spend=new_spend)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
Exemple 3 : Nouveaux revenus par KPI
Supposons que les revenus par KPI (par exemple, le prix unitaire ou la valeur vie) soient censés changer prochainement. La nouvelle hypothèse de revenus par KPI peut être intégrée à l'optimisation. Pour être clair, cela modifiera les revenus supposés générés par unité de KPI incrémental, mais pas l'adéquation du modèle sur le KPI lui-même.
# Create `new_data` from `input_data`, but double the revenue per kpi.
new_data = analyzer.DataTensors(
revenue_per_kpi=mmm.input_data.revenue_per_kpi * 2
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
Exemple 4 : Nouveau modèle de diffusion
Vous envisagez peut-être d'utiliser un autre modèle de diffusion à venir (répartition relative des unités média entre les zones géographiques ou les périodes). C'est généralement utile si vous prévoyez de transférer du budget d'une zone géographique à une autre ou que vous souhaitez tenir compte d'un nouveau canal média introduit pendant la période des données d'entrée. Lorsqu'un nouveau canal est ajouté, le modèle de diffusion historique ne comporte aucune unité média avant la période où le canal a été introduit. Si vous prévoyez d'exécuter le nouveau canal en continu à l'avenir, les zéros du modèle de diffusion doivent être remplacés par d'autres valeurs pour mieux refléter le modèle de diffusion prévu à l'avenir.
Dans cet exemple, imaginons que le premier canal média ait été introduit au cours du quatrième trimestre 2024. Peut-être que les dépenses étaient nulles au début du trimestre et qu'elles ont augmenté au cours de celui-ci. Toutefois, vous prévoyez de définir à l'avenir un nombre constant d'unités média par personne dans les zones géographiques et au cours des périodes. L'argument media de DataTensors permet de spécifier le modèle de diffusion. Lorsque vous spécifiez cet argument pour un modèle géographique, il est souvent préférable de tenir compte du modèle de diffusion prévu en termes d'unités média par personne.
Le nombre exact d'unités média par personne (100 dans cet exemple) n'a aucune incidence sur le modèle de diffusion. Le modèle de diffusion correspond à la répartition relative des unités média dans les zones géographiques et au cours des périodes. Par exemple, le même modèle de diffusion pourrait être obtenu en attribuant 10 unités par personne. Toutefois, les unités média affectent également l'hypothèse de coût par unité média, qui est dérivée du ratio des dépenses par unité média dans chaque zone géographique et pendant chaque période. Dans cet exemple, les nouvelles données de dépenses sont transmises pour obtenir un coût par unité média de 0,1 pour toutes les zones géographiques et périodes.
Modifier media_spend affecte également le budget total par défaut pour l'optimisation à budget fixe, ainsi que les limites de dépenses par défaut. Ces valeurs par défaut peuvent être remplacées à l'aide des arguments d'optimisation budget et pct_of_spend.
Il est important de connaître ces arguments et de les personnaliser si nécessaire.
# Create new media units data from the input data, but set the media units per
# capita to 100 for channel 0 for all geos and time periods.
new_media = mmm.input_data.media.values
new_media[:, :, 0] = 100 * mmm.input_data.population.values[:, None]
# Set a cost per media unit of 0.1 for channel 0 for all geos and time periods.
new_media_spend = mmm.input_data.media_spend.values
new_media_spend[:, :, 0] = 0.1 * new_media[:, -mmm.n_times:, 0]
new_data = analyzer.DataTensors(
media=new_media,
media_spend=new_spend,
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
Pourquoi Meridian ne prévoit-il pas de résultats ?
Meridian n'a pas besoin de prévoir le résultat attendu à l'avenir pour que son inférence causale soit utile à la future planification. En fait, Meridian propose des méthodes pour vous aider à effectuer vos futures planifications, y compris la classe Optimizer et de nombreuses méthodes telles que roi, marginal_roi et incremental_outcome. L'argument new_data de ces méthodes permet d'utiliser l'inférence causale de Meridian afin d'estimer les quantités pour n'importe quelle exécution média ou n'importe quel modèle de diffusion hypothétique, y compris une exécution future.
L'objectif de Meridian est l'inférence causale. Plus précisément, le but est de déduire le résultat incrémental que les variables de traitement ont sur le résultat. En utilisant les termes du glossaire, nous simplifions la définition du résultat incrémental comme suit :
\[ \text{Incremental Outcome} = \text{Expected Outcome} - \text{Counterfactual} \]
où la signification du contrefactuel dépend du type de traitement. Pour en savoir plus, consultez le glossaire et la définition des résultats incrémentaux.
Les variables de contrôle ont une influence sur le résultat attendu, mais pas sur le résultat incrémental (à l'exception de l'effet des variables de contrôle sur la suppression des biais des effets média). En effet, le modèle Meridian spécifie que les variables de contrôle ont un effet additif sur le résultat attendu et le contrefactuel, qui s'annule dans la différence. Pour prévoir le résultat attendu, nous devons prévoir les données des variables de contrôle. Cela peut être assez difficile, car de nombreuses variables de contrôle sont très bruitées, imprévisibles et impossibles à maîtriser par un annonceur. La prévision des données des variables de contrôle serait indépendante des objectifs d'inférence causale de Meridian, car nous pouvons déduire le résultat incrémental, et même l'optimiser, sans nécessairement prévoir le résultat attendu.
De même, les effets temporels, qui sont paramétrés par des nœuds, sont additifs. Par conséquent, le "résultat attendu" et le "contrefactuel" dépendent des valeurs des nœuds, mais pas le "résultat incrémental". L'approche de Meridian basée sur les nœuds pour modéliser les tendances temporelles n'est pas conçue pour la prévision. Elle est plutôt destinée à offrir un modèle beaucoup plus flexible pour les modèles temporels, ce qui la rend adaptée au problème d'inférence causale.