Esta sección abarca la manera de usar Meridian para la planificación de situaciones, lo que incluye cómo incorporar datos y suposiciones sobre el futuro en situaciones de optimización del presupuesto.
Como parte de la optimización del presupuesto futuro, Meridian prevé el resultado incremental según un conjunto de suposiciones sobre el futuro. Meridian no predice el valor del resultado futuro propiamente dicho, sino solo la parte incremental. Para obtener más detalles, consulta Por qué Meridian no hace previsiones de resultados.
¿Qué es la planificación de situaciones?
La planificación de situaciones es un análisis de MMM que puede incorporar suposiciones sobre el futuro. Para el análisis posterior al modelado, como el ROI, las curvas de respuesta y la optimización del presupuesto, Meridian utiliza datos históricos para hacer suposiciones predeterminadas. A veces esas suposiciones son razonables para la planificación de situaciones futuras, pero no siempre es así. Se pueden incorporar al análisis datos nuevos para modificar las suposiciones según sea necesario.
Algunas formas en que las estrategias futuras podrían diferir de las históricas son las que se presentan a continuación.
- Costo por unidad de medios: Es posible que el costo por unidad de medios en un canal haya cambiado o que se prevea que cambiará (consulta el código: ejemplo 1 y ejemplo 2).
- Ingresos por unidad de KPI: Es posible que los ingresos por KPI (p. ej., el precio por unidad o el valor del ciclo de vida del cliente) hayan cambiado o que se prevea que cambiarán (consulta el código: ejemplo 3).
- Patrón de distribución: Es posible que tus patrones de distribución históricos y futuros no coincidan. Por ejemplo, tal vez hayas introducido un nuevo canal de medios durante el período de entrenamiento del modelo. El patrón de distribución histórico del canal nuevo podría incluir ceros o mostrar una tendencia de "adaptación" que no se espera que continúe (consulta el código: ejemplo 4).
Métricas de análisis posterior al modelado
La planificación de situaciones afecta las definiciones de las métricas, pero no la estimación de los parámetros. Para comprender estos conceptos, considera un caso hipotético en el que se usan mínimos cuadrados ordinarios para estimar el efecto terapéutico de un medicamento y se plantea la hipótesis de que la dosis en mg (X) afecta de forma lineal el resultado (Y), de forma tal que en el modelo:
\[ Y = \alpha + X \beta + \epsilon \ . \]
El efecto terapéutico depende del coeficiente $\beta$ de la dosis, un parámetro estimado a partir de un conjunto de datos observado, y puede tener muchas definiciones de métricas posibles. Por ejemplo, puedes definir el efecto del medicamento como la variación prevista en el resultado a raíz del uso de una dosis de 10 mg ($10 \beta$) o una dosis de 15 mg ($15 \beta$). En tal situación, puedes estimar ambas definiciones del efecto terapéutico usando el mismo modelo y la misma estimación del coeficiente $\hat{\beta}$.
En Meridian, la definición de las métricas de análisis posterior al modelado depende de ciertas características de los datos. Por ejemplo, el ROI depende del intervalo de tiempo especificado, el conjunto de ubicaciones geográficas, el patrón de distribución (distribución relativa de las unidades de medios en las ubicaciones geográficas y los períodos), las unidades de medios totales por canal, el costo por unidad de medios y los ingresos por KPI. Otras métricas de análisis posterior al modelado incluyen el resultado esperado, el resultado incremental, el ROI marginal, el CPIK, las curvas de respuesta y la asignación óptima del presupuesto. De forma predeterminada, estas métricas se definen con el argumento input_data que se pasa a Meridian; sin embargo, se puede proporcionar new_data para especificar definiciones alternativas de las métricas. La tabla 1 incluye una lista que indica cuáles de las propiedades de datos afectan la definición de cada métrica.
| Intervalo de tiempo | Conjunto de ubicaciones geográficas | Patrón de distribución | Unidades de medios totales por canal | Costo por unidad de medios | Ingresos por KPI (si corresponde) | Valores de control | |
|---|---|---|---|---|---|---|---|
expected_outcome |
X | X | X | X | X | X | |
incremental_outcome |
X | X | X | X | X | ||
roi, marginal_roi, cpik |
X | X | X | X | X | X | |
response_curves |
X | X | X | X | X | ||
BudgetOptimizer.optimize |
X | X | X | ‡ | X | X |
‡ La optimización del presupuesto utiliza las unidades de medios totales por canal (en combinación con las suposiciones del patrón de distribución y el costo por unidad de medios como datos fijos) para asignar un presupuesto total predeterminado (optimización del presupuesto fijo solamente) y restricciones de presupuesto a nivel del canal. Si se anulan estos parámetros de configuración con los argumentos
budgetypct_of_spenddeBudgetOptimizer.optimize, las unidades de medios totales por canal no afectarán la optimización.
La estimación de cada métrica de análisis posterior al modelado depende de la distribución a posteriori de los parámetros del modelo. La distribución a posteriori es condicional al argumento input_data que se pasa al constructor del objeto Meridian (excluyendo el KPI para las ubicaciones geográficas y los períodos especificados en ModelSpec.holdout_id). La distribución a posteriori se estima cuando se llama a sample_posterior, y esta estimación se utiliza en todo el análisis posterior al modelado.
Argumento new_data
El valor predeterminado de cada propiedad de datos incluida en la tabla 1 se deriva del argumento input_data que se pasa a Meridian. En el análisis posterior al modelado, el usuario puede anular los datos de entrada con el argumento new_data que está disponible en la mayoría de los métodos. Cada método utiliza solo un subconjunto de los atributos de new_data. La tabla 2 indica los atributos de new_data que utiliza cada método.
new_data utilizados por cada métodomedia, reach, frequency |
revenue_per_kpi |
media_spend, rf_spend |
organic_media, organic_reach, organic_frequency, non_media_treatments |
controls |
time |
La dimensión de tiempo debe coincidir con input_data |
|
|---|---|---|---|---|---|---|---|
expected_outcome |
X | X | X | X | sí | ||
incremental_outcome |
X | X | X | no | |||
roi, cpik, marginal_roi |
X | X | X | no | |||
response_curves |
X | X | X | X | no | ||
BudgetOptimizer.optimize |
X | X | X | X | no |
Las propiedades de datos se derivan del argumento new_data de la misma manera en que lo hacen de los datos de entrada. Por ejemplo, el costo por unidad de medios se calcula para cada ubicación geográfica y período dividiendo la inversión por las unidades de medios.
Si el intervalo de tiempo de new_data coincide con el de los datos de entrada, no es necesario que especifiques todos los atributos de new_data que utiliza el método al que llamas. Puedes proporcionar cualquier subconjunto de los atributos, y los restantes se obtendrán de los datos de entrada.
Sin embargo, si el intervalo de tiempo de new_data es diferente del indicado en los datos de entrada, debes pasar todos los atributos de new_data utilizados por el método al que llamas. Todos los atributos de new_data deben tener la misma dimensión de tiempo.
Solo el método expected_outcome requiere que la dimensión de tiempo coincida con los datos de entrada.
Los métodos response_curves y optimize exigen que también se pasen etiquetas de fecha a new_data.time si la dimensión de tiempo no coincide con los datos de entrada. Las etiquetas de datos no afectan los cálculos, pero se utilizan para las etiquetas de los ejes en determinadas visualizaciones.
Método auxiliar para crear new_data para la optimización del presupuesto
Puede parecer contradictorio que la inversión a nivel del canal haga referencia tanto a datos de salida como a datos de entrada de new_data para BudgetOptimizer.optimize. Los datos de salida corresponden a la asignación óptima de la inversión, mientras que la inversión ingresada se utiliza junto con los datos de entrada de las unidades de medios para establecer un costo supuesto por unidad de medios para cada ubicación geográfica y período. Los datos de entrada de la inversión también se utilizan para establecer el presupuesto total en una situación de optimización del presupuesto fijo y para determinar las restricciones de presupuesto a nivel del canal, pero estos parámetros se pueden anular con los argumentos budget y pct_of_spend.
El método optimizer.create_optimization_tensors está disponible para los usuarios que prefieren ingresar los datos del costo por unidad de medios directamente. Este método crea un objeto new_data específicamente para pasarlo al método BudgetOptimizer.optimize con las siguientes opciones de datos de entrada.
Canales sin datos de alcance y frecuencia:
- unidades de medios y costo por unidad de medios
- inversión y costo por unidad de medios
Canales con datos de alcance y frecuencia cuando use_optimal_frequency=True:
- impresiones y costo por impresión
- inversión y costo por impresión
Canales con datos de alcance y frecuencia cuando use_optimal_frequency=False:
- impresiones, frecuencia y costo por impresión
- inversión, frecuencia y costo por impresión
Ejemplos ilustrativos
El objetivo de esta sección es explicar cómo se realizan los cálculos para las funciones de análisis posterior al modelado más importantes: Analyzer.incremental_outcome, Analyzer.roi, Analyzer.response_curves y BudgetOptimizer.optimize.
En particular, estos ejemplos muestran cómo se realiza el cálculo de cada método con input_data y new_data. En estos ejemplos, el argumento input_data incluye una "ventana previa al modelado" para los datos de las unidades de medios, mientras que el argumento new_data no la incluye. Esa ventana contiene datos de las unidades de medios que son anteriores al primer período correspondiente a la "ventana del modelado", lo que permite que el modelo tenga en cuenta de forma adecuada el efecto rezagado de esas unidades. Cuando new_data abarca un intervalo de tiempo diferente del indicado en input_data (tal como sucede en estos ejemplos), los datos de las unidades de medios deben incluir la misma cantidad de períodos que todos los demás datos nuevos.
Además del argumento new_data, cada uno de estos métodos incluye un argumento selected_times. Estos argumentos personalizan la definición de la métrica de salida, no la estimación de los parámetros (para obtener más información, consulta ¿Qué es la planificación de situaciones?).
El método Analyzer.incremental_outcome también tiene un argumento media_selected_times que permite personalizar aún más la definición del resultado incremental. Este argumento hace que Analyzer.incremental_outcome tenga más flexibilidad que los otros métodos. Estos últimos no incluyen ese argumento porque sus cálculos implican la correlación del resultado incremental con algún costo asociado, lo que puede resultar ambiguo cuando selected_times y media_selected_times son personalizables. Sin embargo, puedes vincular manualmente los datos de salida de incremental_outcome con los datos de costos para crear, por ejemplo, definiciones personalizadas del ROI.
En un modelo a nivel geográfico, cada ubicación geográfica tiene su propio resultado incremental, ROI y curva de respuesta. Puedes considerar que cada ejemplo representa una sola ubicación geográfica.
Los resultados a nivel nacional se obtienen agregando los datos de todas las ubicaciones geográficas. Cada uno de estos métodos tiene un argumento selected_geos, que permite que el usuario especifique un subconjunto de ubicaciones geográficas para incluir en la definición de la métrica.
Resultado incremental
Para cada canal de medios, el método incremental_outcome compara el resultado esperado en dos situaciones contrafácticas: en una de ellas, las unidades de medios se establecen en los valores históricos y, en la otra, se establecen en cero para algunos o todos los períodos.
El argumento media_selected_times determina los períodos durante los que las unidades de medios se establecen en cero.
El argumento selected_times determina el intervalo de tiempo durante el que se mide el resultado incremental.
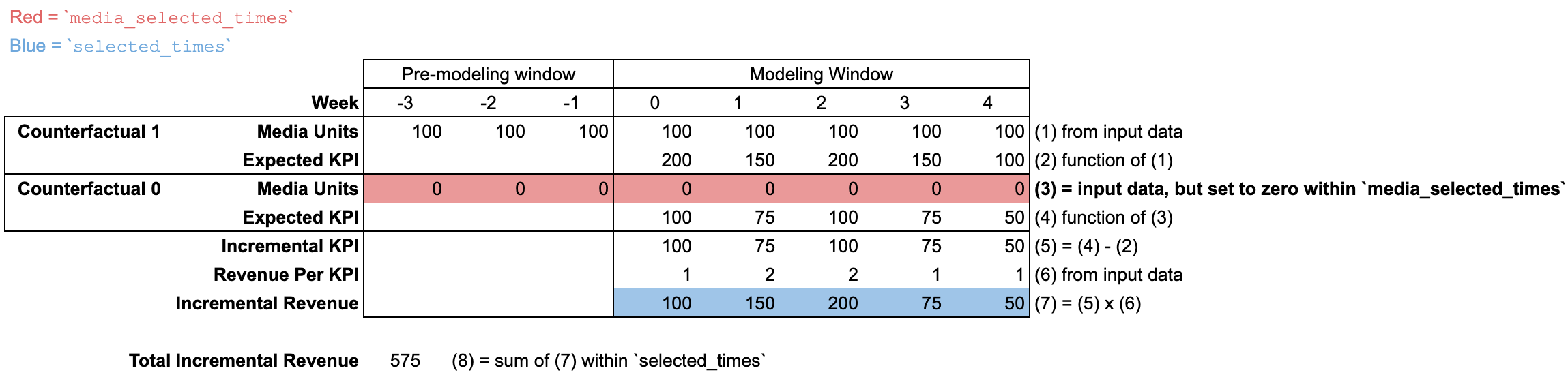
Uso de input_data
La definición predeterminada del resultado incremental establece media_selected_times para que abarque todos los períodos, lo que incluye la "ventana previa al modelado" y la "ventana del modelado"
(de manera opcional, las unidades de medios de input_data pueden incluir una ventana previa para permitir que el modelo tenga en cuenta de forma adecuada el efecto rezagado de esas unidades).
El argumento selected_times predeterminado incluye todos los períodos de la "ventana del modelado", lo que significa que el resultado incremental se considera de forma agregada a lo largo de todos los períodos de esa ventana.
El argumento input_data puede incluir unidades de medios durante una "ventana previa al modelado" para tener en cuenta los efectos rezagados, pero esa ventana no contiene ningún dato, excepto las unidades de medios. Por este motivo, las celdas se muestran en blanco en la ilustración.
Uso de input_data con argumentos selected_times y media_selected_times modificados
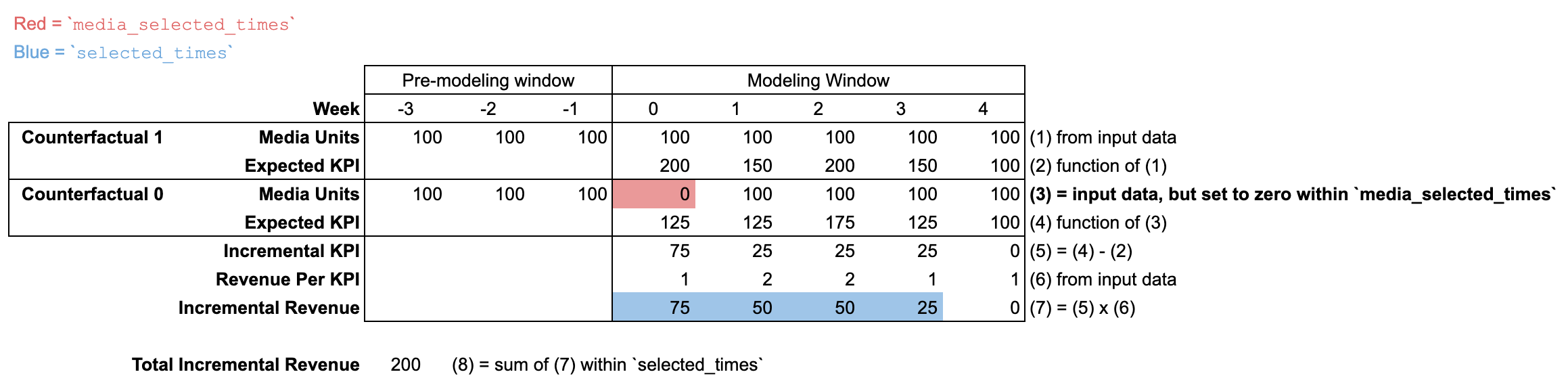
Para determinar el uso de new_data en incremental_outcome y otros métodos, es importante comprender los argumentos selected_times y media_selected_times.
En este ejemplo, media_selected_times se establece en un solo período (la semana 0).
A su vez, selected_times se establece para que abarque las semanas 0 a 3. El ejemplo ilustra una situación en la que max_lag se establece en 3 en ModelSpec, por lo que el resultado incremental debe ser cero para la semana 4 y las subsiguientes. Como resultado, esta combinación de media_selected_times y selected_times capta el impacto total a largo plazo de las unidades de medios de la semana 0.
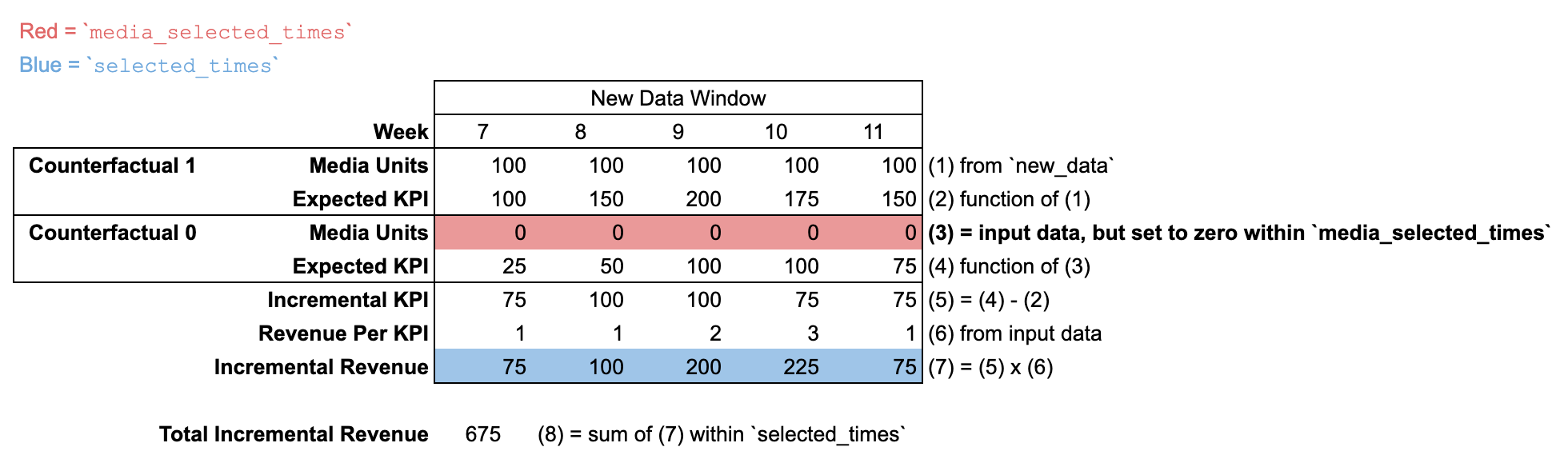
Uso de new_data con una nueva ventana de tiempo
Cuando se pasa el argumento new_data con una cantidad de períodos diferente de la indicada en input_data, no se incluye ninguna "ventana previa al modelado". En tal caso, se supone que las unidades de medios están establecidas en cero para todos los períodos anteriores a la ventana de tiempo de new_data.
La definición predeterminada del resultado incremental establece media_selected_times y selected_times para que abarquen todos los períodos de la ventana de tiempo de new_data.
ROI
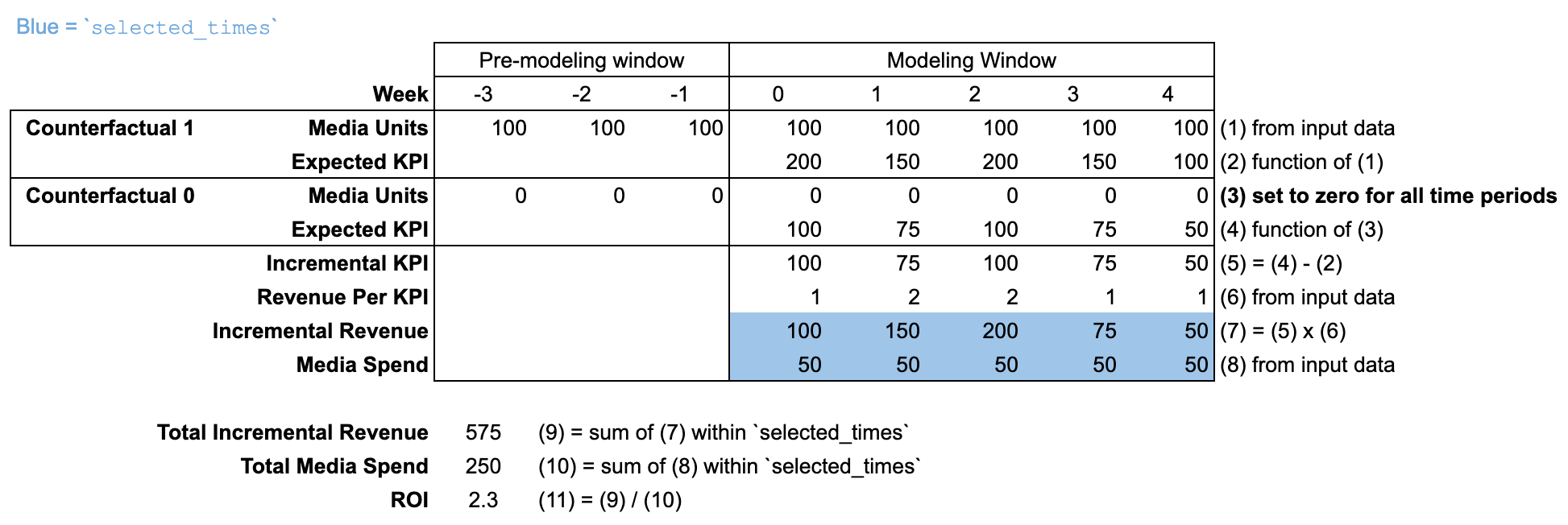
Para cada canal de medios, el método roi divide el resultado incremental generado durante selected_times por la inversión durante selected_times. El método roi no incluye un argumento media_selected_times. El resultado incremental compara las dos situaciones contrafácticas: por un lado, unidades de medios establecidas en valores históricos y, por otro, unidades de medios establecidas en cero para todos los períodos.
Uso de input_data
De forma predeterminada, el argumento selected_times se establece para que abarque toda la "ventana del modelado". La situación contrafáctica establece las unidades de medios en cero para todos los períodos de la "ventana previa al modelado" y la "ventana del modelado".
Uso de new_data con una nueva ventana de tiempo
Cuando se pasa el argumento new_data con una cantidad de períodos diferente de la indicada en input_data, no se incluye ninguna "ventana previa al modelado". En tal caso, se supone que las unidades de medios están establecidas en cero para todos los períodos anteriores a la ventana de tiempo de new_data.
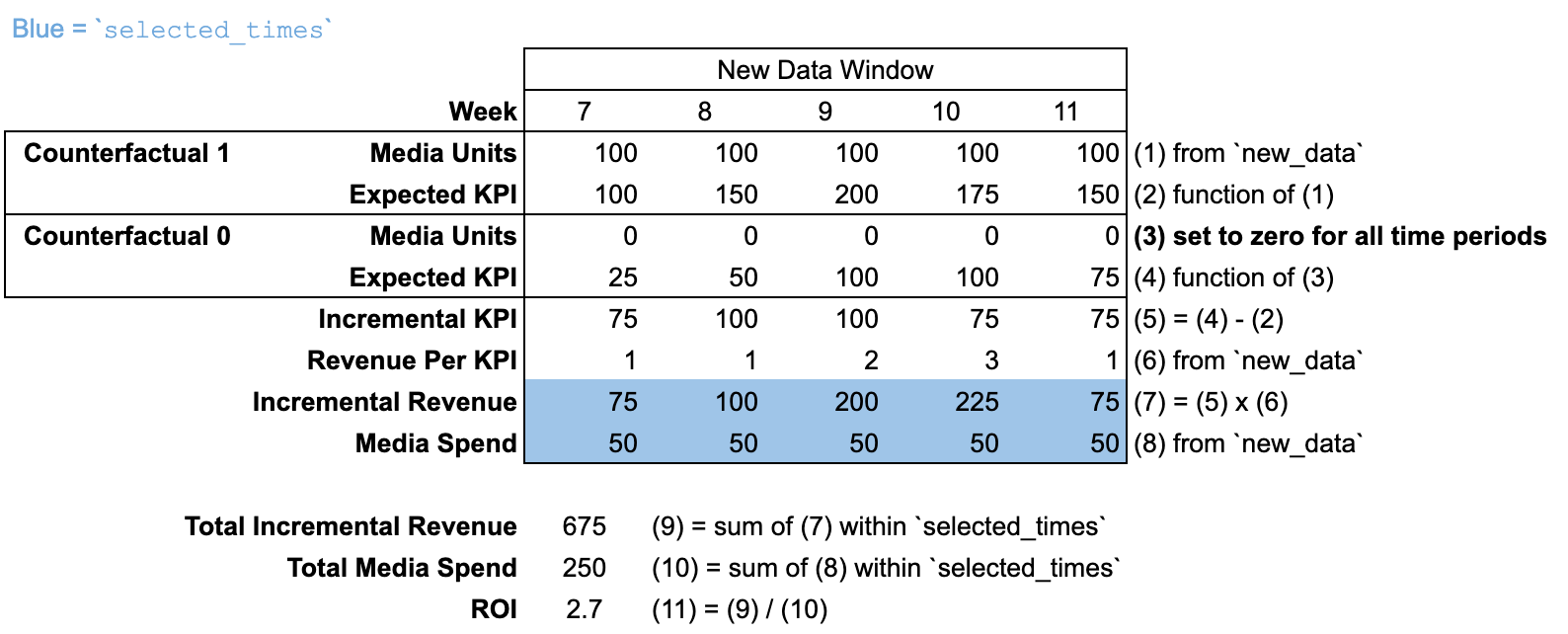
Curvas de respuesta y optimización del presupuesto
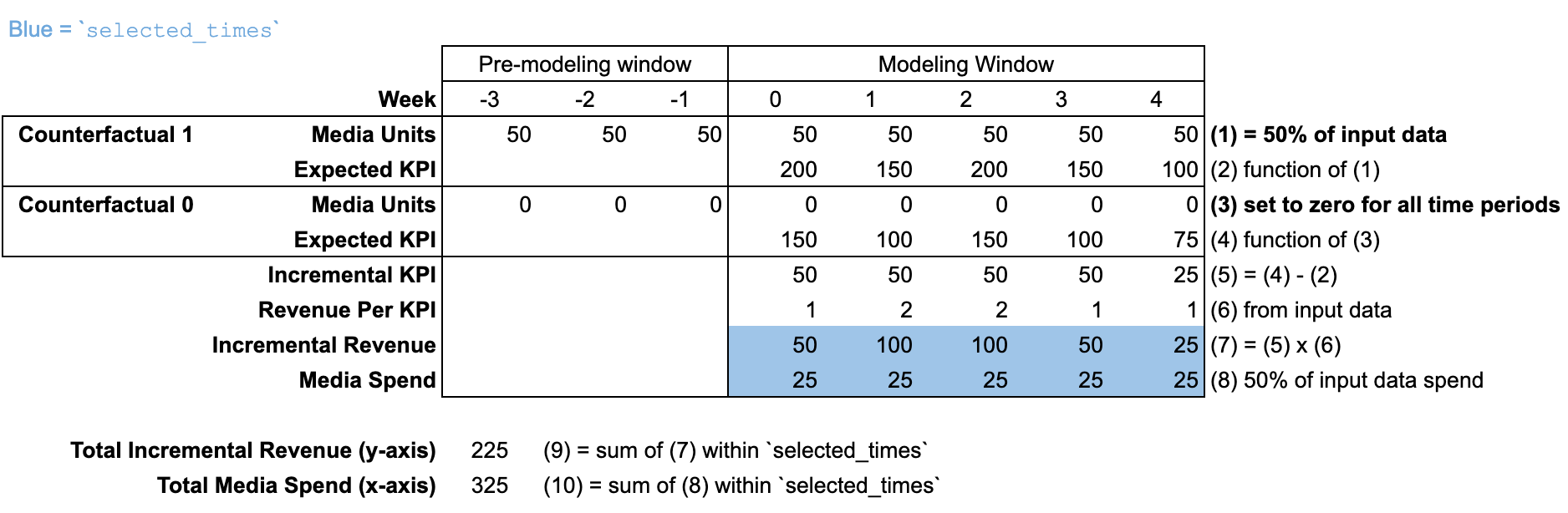
El método response_curves es similar a roi, ya que el resultado incremental y la inversión se consideran de forma agregada en el argumento selected_times, que se establece para que abarque toda la "ventana del modelado" de forma predeterminada. Cada punto del eje X de la curva de respuesta representa un determinado porcentaje de la inversión histórica dentro del intervalo de selected_times. Este método calcula el resultado incremental correspondiente (eje Y) escalando las unidades de medios históricas por el mismo factor. El factor de escala se aplica a las unidades de medios de la "ventana previa al modelado" y la "ventana del modelado".
La optimización del presupuesto se basa en las curvas de respuesta; por lo tanto, la misma ilustración se aplica a la optimización y las curvas. Ten en cuenta que el argumento selected_times dejó de estar disponible en BudgetOptimizer.optimize, que ahora incluye los argumentos start_date y end_date.
Uso de input_data
De forma predeterminada, el argumento selected_times se establece para que abarque toda la "ventana del modelado". La situación contrafáctica establece las unidades de medios y se escalan para todos los períodos de la "ventana previa al modelado" y la "ventana del modelado".
En esta ilustración, la curva de respuesta se calcula al 50% del presupuesto incluido en input_data.
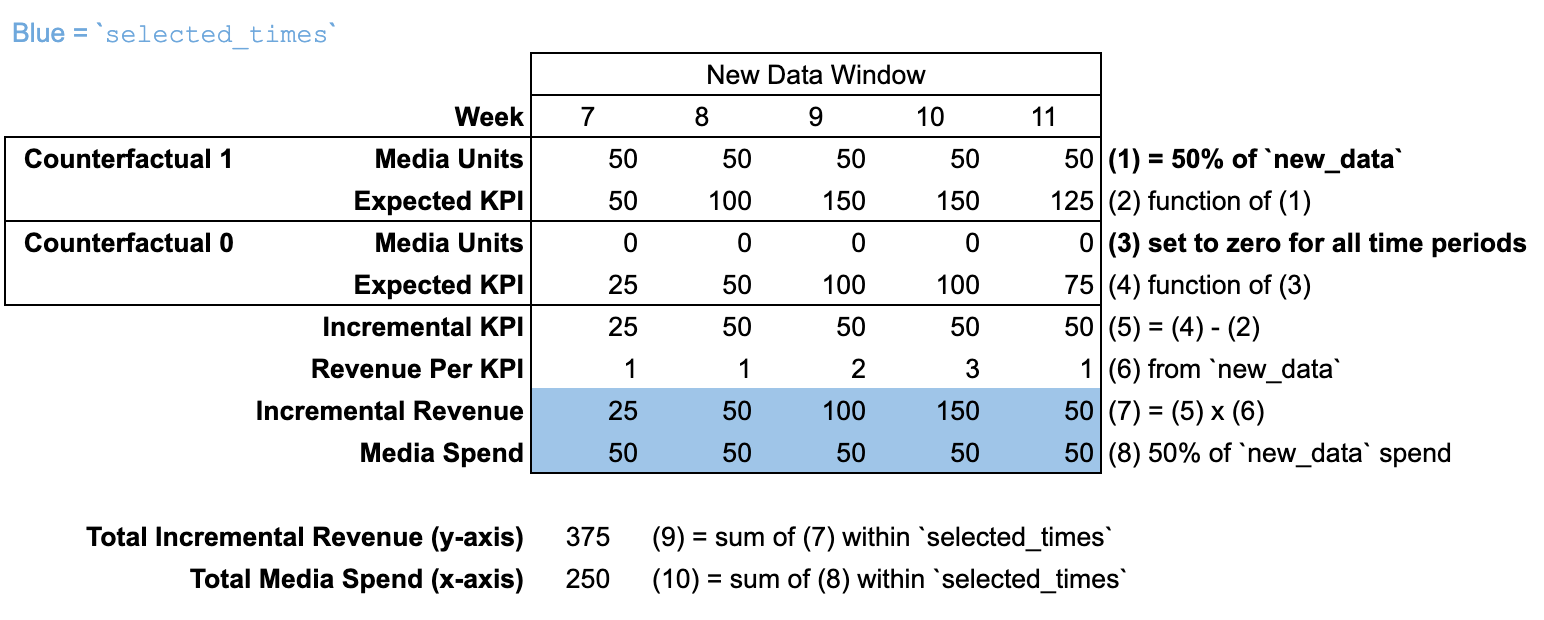
Uso de new_data con una nueva ventana de tiempo
Cuando se pasa el argumento new_data con una cantidad de períodos diferente de la indicada en input_data, no se incluye ninguna "ventana previa al modelado". En tal caso, se supone que las unidades de medios están establecidas en cero para todos los períodos anteriores a la ventana de tiempo de new_data.
En esta ilustración, la curva de respuesta se calcula al 50% del presupuesto incluido en new_data.
Ejemplos de código de optimización del presupuesto
Los siguientes ejemplos ilustran la utilidad del argumento new_data para la optimización del presupuesto y la planificación de situaciones futuras. A modo de ilustración, cada ejemplo se centra en un atributo clave de los datos de entrada que se pueden modificar con new_data. Sin embargo, todas estas suposiciones (y también otras) se pueden combinar en una única situación de optimización.
Imagina que deseas optimizar tu presupuesto para un trimestre futuro en el que se prevé que el patrón de distribución, el costo por unidad de medios y los ingresos por KPI sean similares a los incluidos en los datos de entrada del último trimestre. Puedes usar esos datos del último trimestre para representar la situación futura y ajustar los aspectos que se espera que cambien. Esta optimización se ilustra en cada uno de los ejemplos.
Para las situaciones futuras más complicadas, tal vez sea mejor reemplazar por completo los datos de entrada por datos nuevos. Para hacerlo, puedes construir los arrays en Python o cargar los datos desde un archivo CSV.
En estos ejemplos, hay tres canales de medios. El KPI corresponde a las unidades de ventas, y se incluye el atributo revenue_per_kpi. A modo de ilustración, cada ejemplo ejecuta una situación de optimización que se basa en el cuarto trimestre de 2024. Un elemento clave de la situación se modifica en cada ejemplo, y el argumento new_data se utiliza para incorporar el cambio.
El código de cada ejemplo supone que se inicializó un modelo Meridian como mmm, se llamó al método sample_posterior y se inicializó BudgetOptimizer como opt.
mmm = model.Meridian(...)
mmm.sample_posterior(...)
opt = optimizer.BudgetOptimizer(mmm)
Ejemplo 1: Nuevo costo por unidad de medios para un solo canal
Supongamos que está previsto que, en un futuro próximo, se duplique el costo por unidad de medios en el primer canal, por lo que deseas duplicar el costo supuesto por unidad de medios de ese canal en la optimización. Para hacerlo, crea un array de inversión que coincida con los datos de entrada, pero con la inversión duplicada para el primer canal. El array se pasa al constructor DataTensors, que a su vez se pasa al argumento new_data de la optimización.
Modificar el atributo media_spend también afecta el presupuesto total predeterminado para la optimización del presupuesto fijo, así como las restricciones de inversión predeterminadas. Estos parámetros de configuración predeterminada se pueden anular con los argumentos de optimización budget y pct_of_spend.
Es importante comprender estos argumentos y personalizarlos según sea necesario.
# Create `new_data` from `input_data`, but double the spend for channel 0.
new_spend = mmm.input_data.media_spend
new_spend[:, :, 0] *= 2
new_data = analyzer.DataTensors(media_spend=new_spend)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
Ejemplo 2: Nuevo costo por medio para todos los canales
Supongamos que está previsto que, en un futuro próximo, cambie el costo por unidad de medios para todos los canales, por lo que deseas cambiar el costo supuesto por unidad de medios de esos canales en la optimización. Para cada canal, el costo previsto es una constante conocida que es invariable en las ubicaciones geográficas y los períodos. El método auxiliar create_optimization_tensors, que crea un objeto DataTensors, es conveniente para esta tarea porque el costo por unidad de medios (cpmu) se basa en datos de entrada directos.
El método create_optimization_tensors requiere que se pasen todos los argumentos de optimización. Se puede pasar media o media_spend (con la dimensión geográfica y de tiempo) para especificar el patrón de distribución. La dimensión de tiempo de todos los argumentos de create_optimization_tensors debe coincidir (media no puede incluir períodos adicionales para los efectos rezagados).
# Create `new_data` using the helper method. The cost per media unit (cpmu) is
# set to a constant value for each channel.
new_cpmu = np.array([0.1, 0.2, 0.5])
media_excl_lag = mmm.input_data.media[:, -mmm.n_times:, :]
new_data = opt.create_optimization_tensors(
time=mmm.input_data.time,
cpmu=new_cpmu,
media=media_excl_lag,
revenue_per_kpi=mmm.input_data.revenue_per_kpi,
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
La misma tarea se podría realizar creando el objeto DataTensors directamente. En este caso, la inversión se calcula escalando las unidades de medios de cada canal por el costo por unidad de medios de ese canal.
# Create `new_data` without the helper method.
# In this example, `mmm.n_media_times > mmm.n_times` because the `media` data
# contains additional lag history. These time periods are discarded to create
# the new spend data.
media_excl_lag = mmm.input_data.media[:, -mmm.n_times:, :]
new_spend = media_excl_lag * np.array([0.1, 0.2, 0.5])
new_data = analyzer.DataTensors(media_spend=new_spend)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
Ejemplo 3: Nuevos ingresos por KPI
Supongamos que está previsto que, en un futuro próximo, cambien los ingresos por KPI (p. ej., el precio por unidad o el valor del ciclo de vida del cliente). La suposición acerca de los nuevos ingresos por KPI se puede incorporar en la optimización. A título de aclaración, así cambiarán los ingresos supuestos que se generan por unidad de KPI incremental, pero no se modificará el ajuste del modelo en el KPI propiamente dicho.
# Create `new_data` from `input_data`, but double the revenue per kpi.
new_data = analyzer.DataTensors(
revenue_per_kpi=mmm.input_data.revenue_per_kpi * 2
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
Ejemplo 4: Nuevo patrón de distribución
Tal vez estés considerando usar otro patrón de distribución (asignación relativa de las unidades de medios a las ubicaciones geográficas o los períodos). Un motivo común para hacerlo es si piensas transferir presupuesto de una ubicación geográfica a otra. Otro motivo común es la necesidad de tener en cuenta un nuevo canal de medios introducido durante la ventana correspondiente a los datos de entrada. Cuando se introduce un nuevo canal, el patrón de distribución histórico muestra unidades de medios establecidas en cero antes del período en que se introdujo el canal. Si piensas ejecutar el nuevo canal de forma constante en el futuro, los ceros incluidos en el patrón de distribución se deberían reemplazar por otros valores para reflejar mejor el patrón futuro.
En este ejemplo, supongamos que el primer canal de medios se introdujo durante el cuarto trimestre de 2024. Quizás la inversión haya sido nula inicialmente y haya ido aumentando a lo largo del trimestre. Aun así, prevés que, en el futuro, establecerás unidades de medios per cápita constantes en las ubicaciones geográficas y los períodos. El argumento media de DataTensors se utiliza para especificar el patrón de distribución. Al especificar ese argumento para un modelo geográfico, suele ser mejor tener en cuenta el patrón de distribución previsto en términos de unidades de medios per cápita.
La cantidad exacta de unidades de medios per cápita (100 en este ejemplo) no afecta el patrón de distribución. Este patrón representa la asignación relativa de las unidades de medios a las ubicaciones geográficas y los períodos, por lo que se podría conseguir el mismo patrón, por ejemplo, asignando 10 unidades per cápita. Sin embargo, las unidades de medios también afectan la suposición del costo por unidad de medios, y esa suposición se deriva del ratio de inversión por unidad de medios en cada ubicación geográfica y período. En este ejemplo, los nuevos datos de inversión se pasan para obtener un costo por unidad de medios de 0.1 para todas las ubicaciones geográficas y todos los períodos.
Modificar el atributo media_spend también afecta el presupuesto total predeterminado para la optimización del presupuesto fijo, así como las restricciones de inversión predeterminadas. Estos parámetros de configuración predeterminada se pueden anular con los argumentos de optimización budget y pct_of_spend.
Es importante comprender estos argumentos y personalizarlos según sea necesario.
# Create new media units data from the input data, but set the media units per
# capita to 100 for channel 0 for all geos and time periods.
new_media = mmm.input_data.media.values
new_media[:, :, 0] = 100 * mmm.input_data.population.values[:, None]
# Set a cost per media unit of 0.1 for channel 0 for all geos and time periods.
new_media_spend = mmm.input_data.media_spend.values
new_media_spend[:, :, 0] = 0.1 * new_media[:, -mmm.n_times:, 0]
new_data = analyzer.DataTensors(
media=new_media,
media_spend=new_spend,
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
Por qué Meridian no hace previsiones de resultados
Meridian no necesita hacer previsiones del resultado esperado en el futuro para que su inferencia causal sea útil para la planificación de situaciones futuras. De hecho, Meridian incluye métodos que ayudan en ese tipo de planificación; por ejemplo, la clase Optimizer y muchos otros métodos, como roi, marginal_roi y incremental_outcome. En estos métodos, el argumento new_data permite aprovechar la inferencia causal de Meridian para estimar las cantidades en cualquier ejecución hipotética de medios o patrón de distribución, lo que incluye la ejecución futura.
El objetivo de Meridian es la inferencia causal. Más precisamente, el objetivo es inferir el resultado incremental que surge de las variables de tratamiento. En términos extraídos del Glosario, simplificamos la definición del resultado incremental de la siguiente manera:
\[ \text{Incremental Outcome} = \text{Expected Outcome} - \text{Counterfactual} \]
donde el significado de situación contrafáctica depende del tipo de tratamiento (consulta el Glosario para obtener más información, sobre todo la definición de resultado incremental para conocer este concepto con más precisión).
Las variables de control influyen en el resultado esperado, pero no en el resultado incremental (más allá de la influencia que ejercen los controles en la reducción del sesgo de los efectos de los medios). Esto se debe a que el modelo Meridian especifica que las variables de control tienen un efecto aditivo tanto en el "resultado esperado" como en la "situación contrafáctica", lo que se anula al obtener la diferencia. Una previsión del resultado esperado nos forzaría a prever los datos de control, y esto puede resultar bastante difícil, ya que muchos controles son demasiado ruidosos, impredecibles y están completamente fuera del dominio de un anunciante. La previsión de los datos de control sería ortogonal para los objetivos de inferencia causal de Meridian, dado que podemos inferir y hasta optimizar el resultado incremental, sin hacer necesariamente ninguna previsión del resultado esperado.
Del mismo modo, los efectos temporales, parametrizados por nudos, son aditivos. En consecuencia, el "resultado esperado" y la "situación contrafáctica" dependen de los valores de nudos, pero el "resultado incremental" no. El enfoque de Meridian basado en nudos para modelar patrones temporales no está diseñado para las previsiones. Por el contrario, está diseñado para ofrecer un modelo mucho más flexible para los patrones temporales, lo que lo convierte en una solución adecuada para el problema de la inferencia causal.