マーケティング ミックス モデリングの一般的な課題は、モデルの結果にビジネスの複雑な現実をいかに反映させるかということです。メリディアンでは、高度なベイズ機能である事前分布を使ってこの課題に対処します。このページでは、事前分布の概要、事前分布がメリディアンの手法の基盤となる理由、事前分布を使用する際の重要な考慮事項について説明します。
事前分布とは
「事前分布」とは、データ分析の前にモデルに提供する情報です。ビジネスの知識、業種別ベンチマーク、過去のテスト結果に基づいて、有用な事前情報や専門的なアドバイスをモデルに提供することを目的とします。この関係はベイズ統計の中核を成し、概要は次のとおりです。
\[ \underset{\text{(the model)}}{\text{Posterior}} \propto \underset{\text{(the data)}}{\text{Likelihood}} \cdot \underset{\text{(your belief)}}{\text{Prior}} \]
モデルの事後分布では、初期の信念(事前分布)と、データのもっともらしさ(尤度)の両方を考慮して推定値を算出します。事前分布によりモデルに現実のビジネスの状況が反映されて安定します。
メリディアンの主な特長は、重要なビジネス指標を直接使用できることです。メリディアンは、抽象的な回帰係数に関する事前分布情報を必要とせず、費用対効果(ROI)、限界費用対効果(mROI)、貢献度(%)などの具体的で測定可能な指標に関する事前分布情報を組み込めるように構成されています。
事前分布は、以下を含むさまざまなソースから取得できます。
- 過去のインクリメンタリティ テスト(リフト検証や地域テストなど)の結果
- 業種別ベンチマーク
- 以前のマーケティング ミックス モデリング(MMM)の結果
- チームが持つ専門分野の知識
これらがなくても、問題はありません。メリディアンには、出発点となるデフォルト値が組み込まれています。
分布の観点から事前分布を理解する
事前分布を直感的に理解するために、ビジネスの知見を MMM の事前分布に変換する方法の例をいくつかご紹介します。
事前分布の見方
事前分布は確率分布として表されます。分布では、ROI などのパラメータで取りうるすべての値に密度(相対尤度)を割り当てます。x 軸上における 2 点間の曲線の下の面積は、真の値がその範囲内に収まる確率を表します。たとえば、次の分布プロットは、値が -1~1 になる確率が、その範囲外になる確率よりもはるかに可能性が高いことを示しています。平均 = 0、標準偏差 = 1 の正規分布の場合、真の値が -1~1 の間になる確率は 68.3% です。
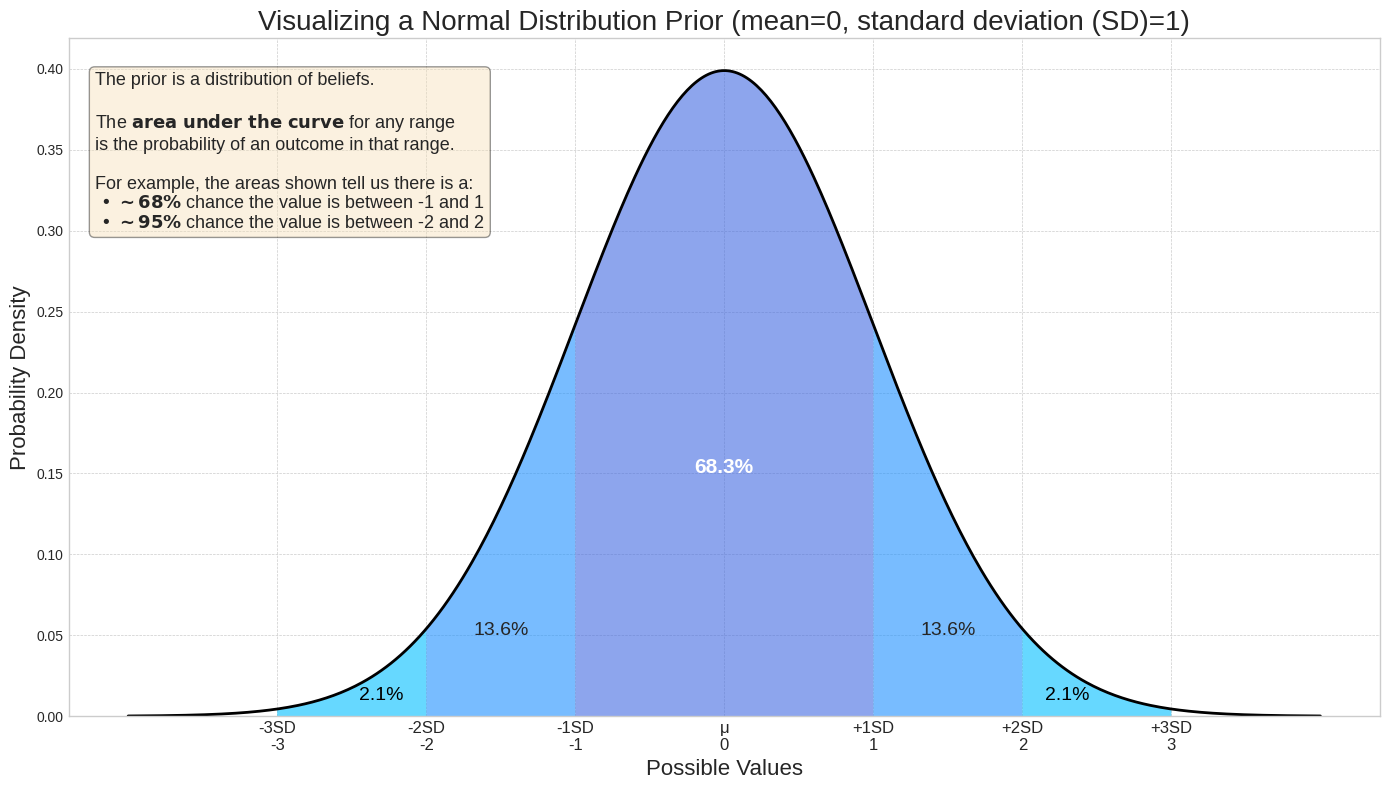
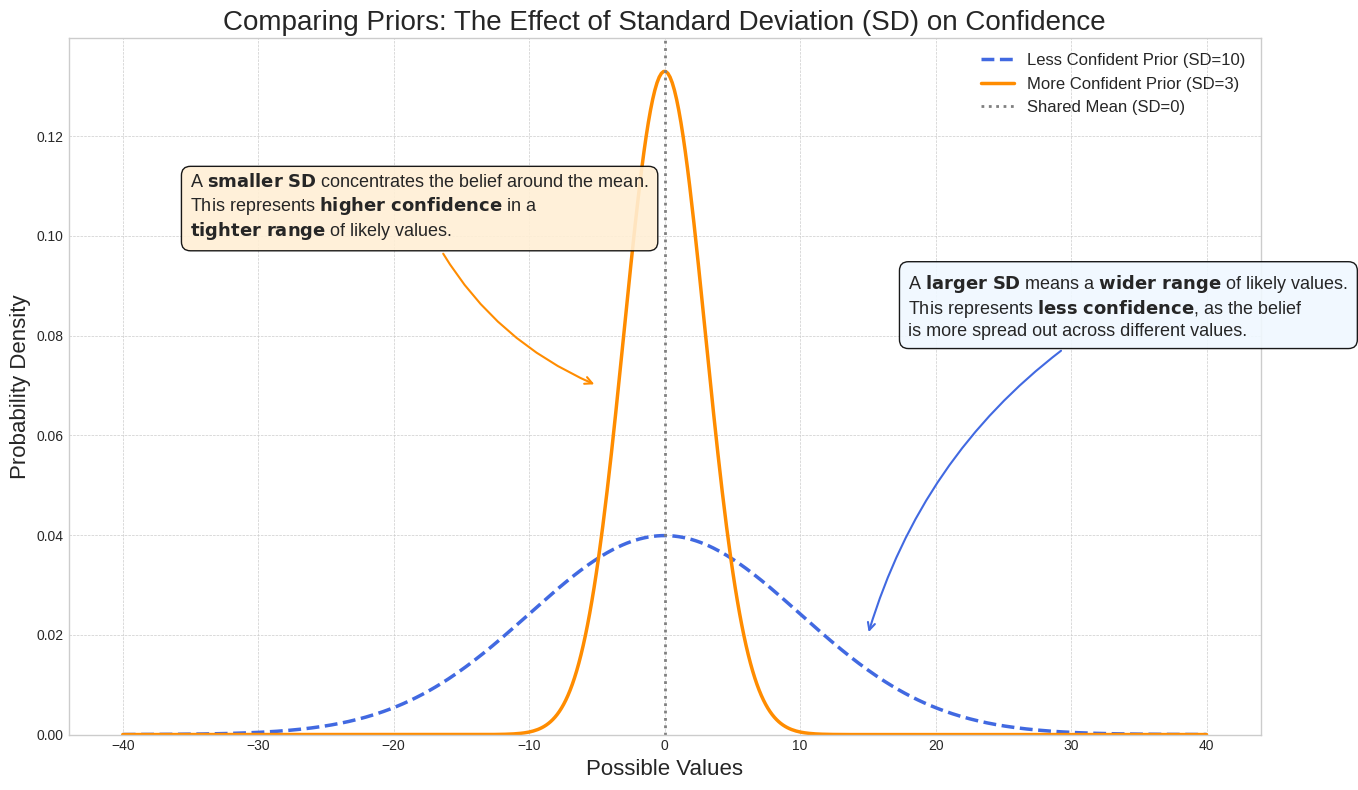
標準偏差が信頼度に与える影響
標準偏差は分布のばらつきとパラメータ値の信頼度を示します。標準偏差が小さいほど、確率がパラメータ値の周辺に集中し、信頼度が高いことを示します。一方、標準偏差が大きいほど、確率が分散し、不確実性が高くなります。
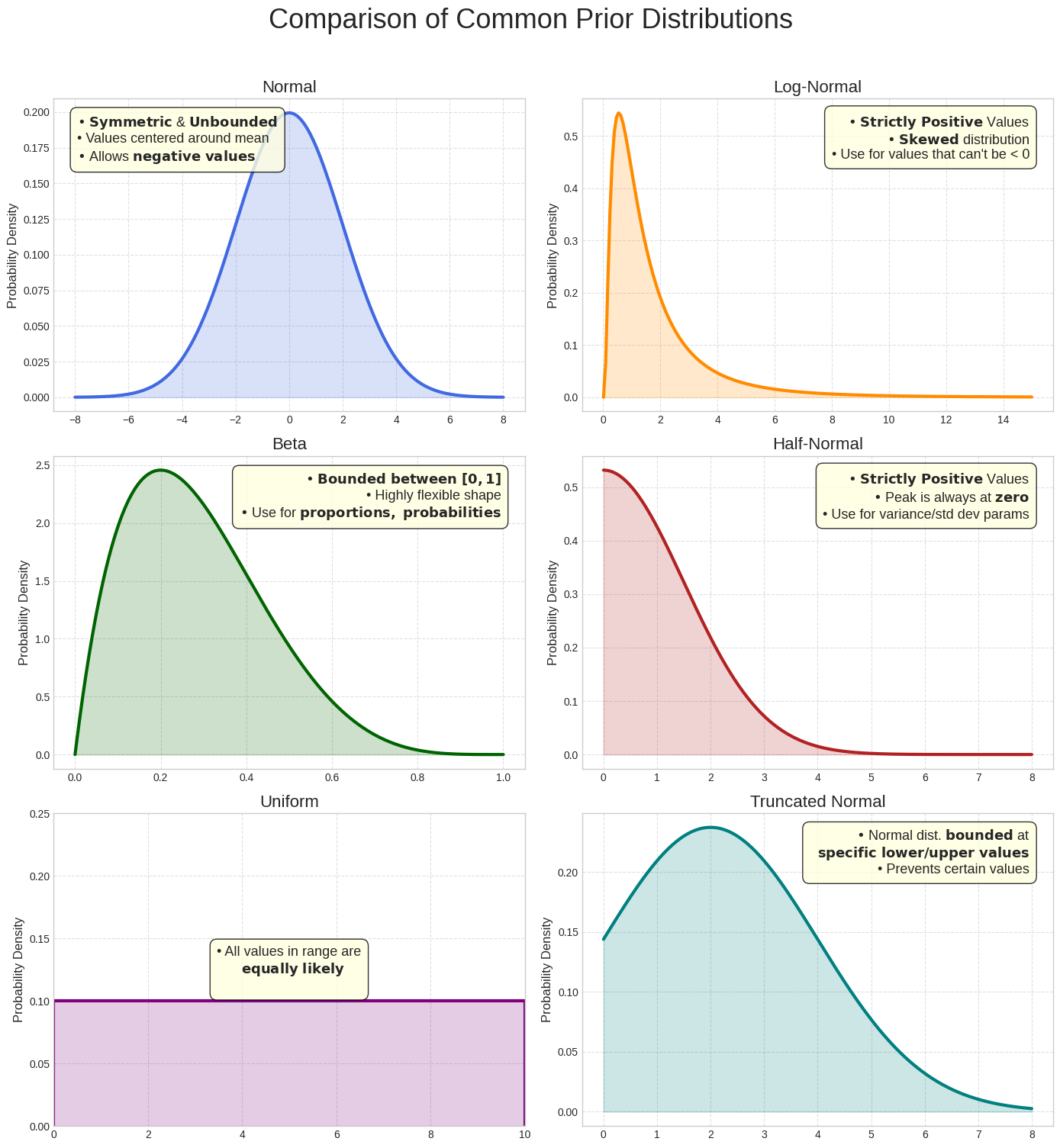
一般的な事前分布の比較
正規分布は有用ですが、モデル化するパラメータによっては他の分布のほうが適している場合もあります。たとえば、ROI は正の値になるので、多くの場合、負の値を許容する正規分布よりも、正の値にのみ確率を割り当てる分布(対数正規分布や半正規分布など)の方が適しています。メリディアンでは、いくつかの一般的な分布が使用され、モデリングするパラメータの特性に最適な分布を選択できます。
コードの例: 信頼度と不確実性
これは、3 つの異なる有料メディア チャネルの ROI について、異なるレベルの信念をコードで表す方法を示しています。
from meridian.model import prior_distribution
# --- Channel 1: High Confidence ---
# You have strong experiment results showing ROI is consistently around 1.2.
# You use a small standard deviation (0.2) to reflect your high confidence.
strong_prior_channel_1 = prior_distribution.lognormal_dist_from_mean_std(
mean=1.2,
std=0.2
)
# --- Channel 2: Low Confidence ---
# You have weaker experiment results showing ROI is around 1.0.
# You use a larger standard deviation (0.9) to reflect your weaker confidence in
# the experiment result than for Channel 1.
weak_prior_channel_2 = prior_distribution.lognormal_dist_from_mean_std(
mean=1.0,
std=0.9
)
# --- Channel 3: Confidence in a range ---
# You believe there's a 95% chance the ROI is between 2.0 and 6.0.
range_prior_channel_3 = prior_distribution.lognormal_dist_from_range(
low=2.0,
high=6.0,
mass_percent=0.95
)
# You would then assign these distributions to their respective channels
# when you configure your model.
prior_config = prior_distribution.PriorDistribution(
roi_m=[strong_prior_channel_1, weaker_prior_channel_2, range_prior_channel_3]
)
事前分布をグラフにする
事前分布をプロットするのは簡単で、事前分布がビジネスに関する知見と一致していることを確認できます。
from matplotlib import pyplot as plt
from meridian.model import prior_distribution
import numpy as np
# Define the LogNormal distribution
lognormal_dist = prior_distribution.lognormal_dist_from_mean_std(2.0, 0.5)
# Plot a histogram of samples from the LogNormal distribution
plt.hist(lognormal_dist.sample(1000))
事前分布が重要な理由
事前分布は単なる技術的な機能ではなく、信頼して行動できる因果推定値を得るための基盤です。
- 少ないデータで、よりもっともらしく、安定性の高い結果が得られる: 集計されたマーケティング データは、まばらであったり、ノイズを含んでいたりする可能性があります。事前分布には安定化効果があり、モデルの結果のもっともらしさが高まるため、限られたデータに基づいて誤った結論に達することが少なくなります。
ビジネスの現実が反映されている: 事前分布は、ブランドリフト調査などの信頼できるソースからの情報を組み込むことで安定化効果が得られます。モデルは組み込まれた情報に基づいて調整されるため、関係者からの信頼が高まります。 自社のビジネスについて、多くの場合なんらかの知見を持っていることがあります。たとえば、自社の業界では ROI が 6.0 を超えることはほぼないという知見を持っている場合があります。この知見を事前分布にコード化することで、テストのハードデータがない場合でも、モデルの結果をより現実的な方向に導くことができます。
知見に基づくモデル制御: メリディアンには、事前分布を設定する直感的な方法が用意されています。これは、モデルとの会話に似ています。抽象的なパラメータを調整するのではなく、わかりやすい言葉でガイダンスを提供できます。たとえば、「私のチャネルの費用対効果は 1.5 程度であるという確信があります」とモデルに伝えることができます。