यह पुष्टि करने के बाद कि आपकी समस्या सबसे अच्छे तरीके से हल हो गई है, एमएल या जनरेटिव एआई की मदद से, अब आप अपनी समस्या को मशीन लर्निंग (एमएल) के तौर पर दिखाने के लिए तैयार हैं. नीचे दिए गए टास्क पूरे करके, मशीन लर्निंग की शर्तों का इस्तेमाल करके कोई समस्या तैयार करें:
- सही नतीजा और मॉडल का लक्ष्य तय करें.
- मॉडल के आउटपुट की पहचान करें.
- सफलता की मेट्रिक तय करें.
आदर्श नतीजा और मॉडल का लक्ष्य तय करना
एमएल मॉडल के बिना, सबसे सही नतीजा क्या होगा? अन्य शब्दों में, वह सटीक टास्क है जो आपको अपने प्रॉडक्ट या सुविधा से करवाना है? यह पहले जैसा ही है लक्ष्य बताएं में पहले से तय किया गया स्टेटमेंट सेक्शन में जाएं.
अपने लक्ष्य के बारे में साफ़ तौर पर बताएं और मॉडल के लक्ष्य को सही नतीजे पाएं करने की इच्छा है. नीचे दी गई टेबल में, सटीक नतीजों और लक्ष्य तय करता है:
| ऐप्लिकेशन | सही नतीजा | मॉडल का लक्ष्य |
|---|---|---|
| मौसम की जानकारी देने वाला ऐप्लिकेशन | किसी भौगोलिक क्षेत्र के लिए छह घंटे की बढ़ोतरी से वर्षा की गणना करें. | खास भौगोलिक क्षेत्रों के लिए, छह घंटों में बारिश होने की मात्रा का अनुमान लगाएं. |
| फ़ैशन ऐप्लिकेशन | शर्ट के अलग-अलग डिज़ाइन जनरेट करें. | टेक्स्ट और इमेज से, शर्ट की तीन तरह की डिज़ाइन जनरेट करें. जहां टेक्स्ट की स्टाइल और रंग के बारे में बताया गया है और इमेज शर्ट (टी-शर्ट, बटन-अप, पोलो). |
| वीडियो ऐप्लिकेशन | काम के वीडियो के सुझाव देना. | यह अनुमान लगाना कि कोई उपयोगकर्ता किसी वीडियो पर क्लिक करेगा या नहीं. |
| मेल ऐप्लिकेशन | स्पैम का पता लगाएं. | अनुमान लगाएं कि कोई ईमेल स्पैम है या नहीं. |
| वित्तीय ऐप्लिकेशन | खबरों के एक से ज़्यादा स्रोतों से वित्तीय जानकारी हासिल करने के लिए. | ऐप्लिकेशन की मदद से, मुख्य वित्तीय रुझानों के बारे में 50 शब्दों में खास जानकारी जनरेट करें पिछले सात दिन. |
| मैप ऐप्लिकेशन | यात्रा में लगने वाले समय का हिसाब लगाएं. | दो बिंदुओं के बीच यात्रा करने में कितना समय लगेगा. |
| बैंकिंग ऐप्लिकेशन | धोखाधड़ी वाले लेन-देन की पहचान करना. | अनुमान लगाएं कि क्या कार्ड धारक ने लेन-देन किया था. |
| डाइनिंग ऐप्लिकेशन | रेस्टोरेंट के मेन्यू से पकवान की पहचान करें. | बताएं कि रेस्टोरेंट किस तरह का है. |
| ई-कॉमर्स ऐप्लिकेशन | कंपनी के प्रॉडक्ट के बारे में, ग्राहक सहायता टीम के सवालों के जवाब जनरेट करना. | संगठन की भावनाओं और भावनाओं का विश्लेषण करके, जवाब जनरेट करें नॉलेज बेस. |
अपनी ज़रूरत के हिसाब से आउटपुट की पहचान करें
मॉडल प्रकार की आपकी पसंद आपकी समस्या. मॉडल का आउटपुट, बेहतरीन नतीजा मिलेगा. इसलिए, सबसे पहले "मुझे अपना सवाल हल करने के लिए, किस तरह का आउटपुट देना चाहिए?"
अगर आपको किसी चीज़ को कैटगरी में बांटना है या संख्या वाला अनुमान लगाना है, तो अनुमानित एमएल का इस्तेमाल करें. अगर आपको नया कॉन्टेंट या आउटपुट जनरेट करना है, तो तो हो सकता है कि आप जनरेटिव एआई का इस्तेमाल करें.
नीचे दी गई टेबल में, अनुमानित एमएल और जनरेटिव एआई के आउटपुट की सूची दी गई है:
| एमएल सिस्टम | आउटपुट का उदाहरण | |
|---|---|---|
| क्लासिफ़िकेशन | बाइनरी | किसी ईमेल को स्पैम के तौर पर मार्क करना या उसे स्पैम नहीं तय करना. |
| एक से ज़्यादा क्लास वाला सिंगल-लेबल | किसी इमेज में किसी जानवर को अलग-अलग कैटगरी में बांटें. | |
| मल्टी-क्लास मल्टी-लेबल | एक इमेज में सभी जानवरों को अलग-अलग ग्रुप में बांटें. | |
| अंकों में | यूनिडायमेंशनल रिग्रेशन | अनुमान लगाएं कि किसी वीडियो को कितने व्यू मिलेंगे. |
| मल्टीडायमेंशनल रिग्रेशन | ब्लड प्रेशर, हृदय दर, और कोलेस्ट्रॉल के स्तर का अनुमान लगाना कोई व्यक्ति. |
| मॉडल प्रकार | आउटपुट का उदाहरण |
|---|---|
| टेक्स्ट |
किसी लेख की खास जानकारी दो. ग्राहकों की समीक्षाओं का जवाब दें. दस्तावेज़ों को अंग्रेज़ी से मैंडरिन में अनुवाद करें. प्रॉडक्ट की जानकारी लिखें. कानूनी दस्तावेज़ों का विश्लेषण करें.
|
| इमेज |
मार्केटिंग इमेज बनाएं. फ़ोटो में विज़ुअल इफ़ेक्ट इस्तेमाल करना. प्रॉडक्ट के अलग-अलग डिज़ाइन जनरेट करें.
|
| ऑडियो |
किसी खास लहजे में डायलॉग जनरेट करें.
किसी खास शैली का संगीत कंपोज़िशन जनरेट करें. जैसे,
जैज़.
|
| वीडियो |
असल लगने वाले वीडियो जनरेट करें.
वीडियो फ़ुटेज का विश्लेषण करें और विज़ुअल इफ़ेक्ट इस्तेमाल करें.
|
| मल्टीमोडल | कई तरह के वीडियो बनाएं, जैसे कि टेक्स्ट कैप्शन वाला वीडियो. |
क्लासिफ़िकेशन
क्लासिफ़िकेशन मॉडल यह अनुमान लगाता है कि इनपुट डेटा किस कैटगरी से जुड़ा है. उदाहरण के लिए, ऑडियंस को A, B या C की कैटगरी में रखा जाना चाहिए.
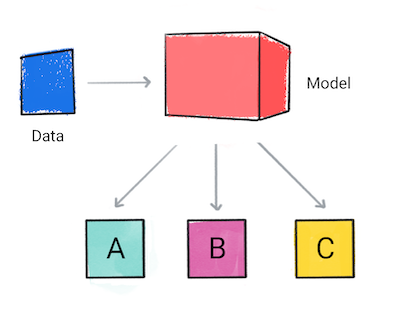
पहला डायग्राम. ऐसा क्लासिफ़िकेशन मॉडल जो अनुमान लगाता है.
मॉडल के अनुमान के आधार पर, आपका ऐप्लिकेशन फ़ैसला ले सकता है. उदाहरण के लिए, अगर अनुमान है कैटगरी A, फिर X करें; अगर अनुमान कैटगरी B है, तो ऐसा करो, Y; अगर अनुमान कैटगरी C है, तो Z लिखें. कुछ मामलों में, अनुमान ऐप्लिकेशन का आउटपुट है.
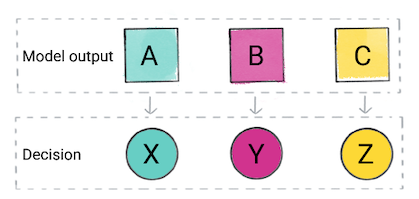
दूसरा डायग्राम. क्लासिफ़िकेशन मॉडल के आउटपुट का इस्तेमाल, प्रॉडक्ट कोड में इन कामों के लिए किया जा रहा है: उस व्यक्ति के बारे में फ़ैसला लें.
रिग्रेशन
रिग्रेशन मॉडल ने अनुमान लगाया है एक संख्यात्मक मान होता है.
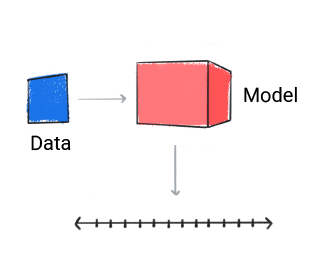
तीसरी इमेज. रिग्रेशन मॉडल, जो अंकों के आधार पर अनुमान लगाता है.
मॉडल के अनुमान के आधार पर, आपका ऐप्लिकेशन फ़ैसला ले सकता है. उदाहरण के लिए, अगर अनुमान, रेंज A में आता है, तो X करें; अगर अनुमान रेंज में आता है B, और Y; अगर अनुमान रेंज C में आता है, तो Z करें. कुछ मामलों में, सुझाव ऐप्लिकेशन का आउटपुट है.
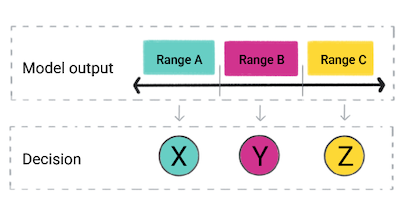
चौथी इमेज. किसी रिग्रेशन मॉडल के आउटपुट का इस्तेमाल, प्रॉडक्ट कोड में किया जा रहा है फ़ैसला लेने में मदद मिलती है.
यह उदाहरण देखें:
कैश मेमोरी में सेव करना वीडियो की अनुमानित लोकप्रियता के आधार पर तय किया जा सकता है. दूसरे शब्दों में, अगर आपका मॉडल अगर यह अनुमान लगाता है कि कोई वीडियो लोकप्रिय होगा, तो आपको उसे दर्शकों को तुरंत दिखाना है. यहां की यात्रा पर हूं ऐसा करने पर, आप ज़्यादा असरदार और महंगे कैश का इस्तेमाल करेंगे. अन्य वीडियो के लिए, आप किसी अन्य कैश मेमोरी का इस्तेमाल करेंगे. आपके कैश मेमोरी में सेव होने की शर्तें नीचे दी गई हैं:
- अगर किसी वीडियो को 50 या उससे ज़्यादा व्यू मिलने का अनुमान है, तो आपके विज्ञापन कैश मेमोरी.
- अगर किसी वीडियो को 30 से 50 व्यू मिलने का अनुमान है, तो आपको कैश मेमोरी.
- अगर वीडियो को 30 से कम व्यू मिलने का अनुमान है, तो वीडियो.
आपको लगता है कि रिग्रेशन मॉडल सही तरीका है, क्योंकि संख्या वाली वैल्यू—व्यू की संख्या. हालांकि, रिग्रेशन की ट्रेनिंग के दौरान तो आपको पता चलता है कि यह उसी तरह का उत्पादन करता है 28 और 32 के अनुमान के लिए, घटना जिन्हें 30 व्यू मिले हैं. दूसरे शब्दों में कहें, तो भले ही आपके ऐप्लिकेशन में अगर अनुमान 28 बनाम 32 है, तो मॉडल दोनों अनुमान उतना ही अच्छा होता है.
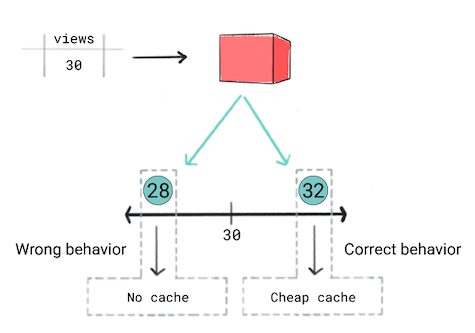
पांचवी इमेज. रिग्रेशन मॉडल को ट्रेनिंग देना.
रिग्रेशन मॉडल को प्रॉडक्ट के तय थ्रेशोल्ड की जानकारी नहीं होती. इसलिए, अगर आपके ऐप्लिकेशन के काम करने के तरीके में काफ़ी बदलाव आया है, क्योंकि रिग्रेशन मॉडल के अनुमान लगाते समय, आपको क्लासिफ़िकेशन मॉडल का इस्तेमाल करें.
ऐसी स्थिति में, किसी क्लासिफ़िकेशन मॉडल से सही व्यवहार होगा क्योंकि क्लासिफ़िकेशन मॉडल की वजह से, 32 के मुकाबले 28. सीधे तौर पर कहा जाए, तो क्लासिफ़िकेशन मॉडल डिफ़ॉल्ट रूप से थ्रेशोल्ड तय करते हैं.
यह स्थिति दो अहम बातों को हाइलाइट करती है:
फ़ैसले का अनुमान लगाएं. जब मुमकिन हो, तब अनुमान लगाएं कि आपका ऐप्लिकेशन कौनसा फ़ैसला लेगा लेना. वीडियो के उदाहरण में, क्लासिफ़िकेशन मॉडल यह फ़ैसला लेने के लिए कि वीडियो को किन कैटगरी में बांटा गया है, "कैश मेमोरी उपलब्ध नहीं है" "सस्ते कैश मेमोरी में सेव करता है," और "महंगी कैश मेमोरी है." मॉडल से अपने ऐप्लिकेशन के व्यवहार को छिपाने से आपके ऐप्लिकेशन की वजह से गलत व्यवहार हो सकता है.
समस्या से जुड़ी वजहों को समझें. अगर आपका ऐप्लिकेशन अलग-अलग थ्रेशोल्ड के आधार पर कार्रवाई करें. इससे यह पता चलता है कि आपके कारोबार के लिए ये थ्रेशोल्ड फ़िक्स्ड या डाइनैमिक होने चाहिए.
- डाइनैमिक थ्रेशोल्ड: अगर थ्रेशोल्ड डाइनैमिक हैं, तो रिग्रेशन मॉडल का इस्तेमाल करें और अपने ऐप्लिकेशन के कोड में थ्रेशोल्ड की सीमाएं सेट करें. इससे आपको आसानी से थ्रेशोल्ड को अपडेट कर दें, लेकिन मॉडल को उचित बनाते हुए भी सुझाव.
- तय थ्रेशोल्ड: अगर थ्रेशोल्ड तय हैं, तो क्लासिफ़िकेशन मॉडल का इस्तेमाल करें और थ्रेशोल्ड की सीमाओं के आधार पर अपने डेटासेट को लेबल करें.
आम तौर पर, कैश मेमोरी को मैनेज करने की ज़्यादातर सुविधाएं डाइनैमिक होती हैं और उनके थ्रेशोल्ड बदल जाते हैं समय के साथ. इसलिए, चूंकि यह विशिष्ट रूप से एक कैशिंग समस्या है, इसलिए रिग्रेशन मॉडल सबसे सही विकल्प है. हालांकि, कई समस्याओं के लिए, तय की गई सीमाओं को ठीक किया जाएगा. इससे क्लासिफ़िकेशन मॉडल सबसे अच्छा समाधान बन जाएगा.
आइए, एक और उदाहरण देखें. अगर आपको मौसम की जानकारी देने वाला ऐसा ऐप्लिकेशन बनाना है जिसका
सही नतीजे यह है कि उपयोगकर्ताओं को यह बताया जाए कि अगले छह घंटों में कितनी बारिश होगी.
तो आपके पास ऐसे रिग्रेशन मॉडल का इस्तेमाल करने का विकल्प है जो precipitation_amount. लेबल का अनुमान लगाता है
| सही नतीजा | सही लेबल |
|---|---|
| उपयोगकर्ताओं को बताएं कि उनके इलाके में कितनी बारिश होगी अगले छह घंटे. | precipitation_amount
|
मौसम की जानकारी देने वाले ऐप्लिकेशन के उदाहरण में, लेबल सीधे तौर पर सही नतीजों के बारे में बताता है.
हालांकि, कुछ मामलों में, एक-से-एक का संबंध स्पष्ट नहीं होता है
सही परिणाम और लेबल चुनें. उदाहरण के लिए, वीडियो ऐप्लिकेशन में सबसे सही नतीजा यह होगा कि
ताकि आपको काम के वीडियो के सुझाव मिल सकें. हालांकि, डेटासेट में
useful_to_user. अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है
| सही नतीजा | सही लेबल |
|---|---|
| काम के वीडियो के सुझाव देना. | ? |
इसलिए, आपको एक प्रॉक्सी लेबल मिलना चाहिए.
प्रॉक्सी लेबल
प्रॉक्सी लेबल का विकल्प
जो डेटासेट में मौजूद नहीं हैं. प्रॉक्सी लेबल की ज़रूरत तब पड़ती है, जब आप
इसका अनुमान लगाया जा सकता है कि आपको क्या अनुमान लगाना है. वीडियो ऐप्लिकेशन में, हम सीधे तौर पर
यह आकलन किया जा सकता है कि उपयोगकर्ता को कोई वीडियो काम का लगेगा या नहीं. यह बहुत अच्छा होता अगर
डेटासेट में एक useful सुविधा थी और उपयोगकर्ताओं ने जो वीडियो मिले उन्हें मार्क किया
डेटासेट उपयोगी नहीं है, लेकिन डेटासेट के साथ काम नहीं करने की वजह से हमें एक प्रॉक्सी लेबल की ज़रूरत होगी,
उपयोगिता के विकल्प.
उपयोगिता के लिए एक प्रॉक्सी लेबल, यह हो सकता है कि उपयोगकर्ता शेयर या पसंद करेगा या नहीं वीडियो.
| सही नतीजा | प्रॉक्सी लेबल |
|---|---|
| काम के वीडियो के सुझाव देना. | shared OR liked |
प्रॉक्सी लेबल इस्तेमाल करते समय सावधानी बरतें, क्योंकि ये आपकी ज़रूरत के हिसाब से नहीं मापते अनुमान लगाने के लिए. उदाहरण के लिए, नीचे दी गई टेबल में संभावित समस्याओं के बारे में बताया गया है काम के वीडियो का सुझाव देने के लिए प्रॉक्सी लेबल:
| प्रॉक्सी लेबल | गड़बड़ी |
|---|---|
| यह अनुमान लगाना कि क्या उपयोगकर्ता "पसंद करें" बटन पर क्लिक करेगा बटन. | ज़्यादातर उपयोगकर्ता कभी भी "पसंद करें" पर क्लिक नहीं करते. |
| यह अनुमान लगाएं कि कोई वीडियो लोकप्रिय होगा या नहीं. | आपकी पसंद के हिसाब से नहीं है. ऐसा हो सकता है कि कुछ दर्शकों को लोकप्रिय वीडियो पसंद न आएं. |
| यह अनुमान लगाएं कि उपयोगकर्ता इस वीडियो को शेयर करेगा या नहीं. | कुछ लोग वीडियो शेयर नहीं करते. कभी-कभी, लोग वीडियो इसलिए शेयर करते हैं, क्योंकि तो वे उन्हें पसंद नहीं करते. |
| अनुमान लगाएं कि उपयोगकर्ता, 'चलाएं' पर क्लिक करेगा या नहीं. | क्लिकबेट को बढ़ाती है. |
| अनुमान लगाएं कि वे वीडियो को कितनी देर तक देखते हैं. | कम अवधि के वीडियो के मुकाबले, लंबी अवधि के वीडियो को ज़्यादा पसंद किया जाता है. |
| अनुमान लगाएं कि उपयोगकर्ता वीडियो को कितनी बार फिर से देखता है. | "फिर से देखे जाने वाले" के पक्ष में वीडियो की शैलियों पर बने ऐसे वीडियो जिन्हें फिर से नहीं देखा जा सकता. |
कोई भी प्रॉक्सी लेबल आपके बेहतरीन नतीजे का अच्छा विकल्प नहीं हो सकता. सभी यह काम करेंगे कोई समस्या हो सकती है. वह विकल्प चुनें जिसमें आपके लिए सबसे कम समस्याएं हों इस्तेमाल का उदाहरण.
अपनी समझ को परखें
जेनरेशन
ज़्यादातर मामलों में, आपको अपने जनरेटिव मॉडल को ट्रेनिंग नहीं देनी होगी, क्योंकि ऐसा करना इसके लिए, बहुत ज़्यादा ट्रेनिंग डेटा और कंप्यूटेशनल रिसॉर्स की ज़रूरत पड़ती है. इसके बजाय, आपके पास पहले से ट्रेन किए गए जनरेटिव मॉडल को पसंद के मुताबिक बनाने का विकल्प होगा. जनरेटिव मॉडल को पाने के लिए नहीं दिया है, तो आपको इनमें से एक या ज़्यादा तरीकों का इस्तेमाल करना पड़ सकता है तकनीकें:
डिस्टिलेशन. बनाने के लिए बड़े मॉडल का छोटा वर्शन है, तो सिंथेटिक लेबल वाला डेटासेट जनरेट किया जा सकता है उस बड़े मॉडल से ली होगी जिसका इस्तेमाल आपने छोटे मॉडल को ट्रेनिंग देने के लिए किया है. जनरेटिव एआई आम तौर पर, ये मॉडल बहुत बड़े होते हैं और इनमें बहुत सारे संसाधन खर्च होते हैं. जैसे, और बिजली). डिस्टिलेशन की मदद से, कम संसाधनों में कम संसाधन खर्च होते हैं मॉडल की मदद से, बड़े मॉडल की परफ़ॉर्मेंस का अनुमान लगा सकते हैं.
फ़ाइन-ट्यूनिंग या पैरामीटर की बेहतर ट्यूनिंग. किसी टास्क के लिए मॉडल की परफ़ॉर्मेंस को बेहतर बनाने के लिए, आपको मॉडल को ऐसे डेटासेट पर ट्रेनिंग दें जिसमें आपके आउटपुट टाइप के उदाहरण हों करना है.
प्रॉम्प्ट इंजीनियरिंग. यहां की यात्रा पर हूं मॉडल को कोई खास टास्क करने के लिए कहें या एक खास फ़ॉर्मैट में आउटपुट देते हैं, तो मॉडल को अपनी पसंद के टास्क के बारे में बताते हैं किया जा सकता है या बताया जा सकता है कि आउटपुट को कैसे फ़ॉर्मैट किया जाए. दूसरे शब्दों में, प्रॉम्प्ट में आम भाषा में, टास्क को पूरा करने के निर्देश शामिल हो सकते हैं या दिखाने के लिए उदाहरण के तौर पर दिया गया हो.
उदाहरण के लिए, अगर आपको लेखों के बारे में कम शब्दों में खास जानकारी चाहिए, तो फ़ॉलो किया जा रहा है:
Produce 100-word summaries for each article.अगर आपको मॉडल से किसी खास रीडिंग लेवल के लिए टेक्स्ट जनरेट करना है, तो यह जानकारी डालें:
All the output should be at a reading level for a 12-year-old.अगर आपको मॉडल से किसी खास फ़ॉर्मैट में आउटपुट देना है, तो आउटपुट को फ़ॉर्मैट करने का तरीका बताएं—उदाहरण के लिए, " खोज के नतीजे टेबल में दिखते हैं"—या आप टास्क को दिखा सकते हैं और उन्हें उदाहरण देकर देखें. उदाहरण के लिए, यह जानकारी डालें:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
मॉडल की डिस्टिलेशन और फ़ाइन-ट्यूनिंग, पैरामीटर. प्रॉम्प्ट इंजीनियरिंग मॉडल के पैरामीटर अपडेट नहीं करता. इसके बजाय, प्रॉम्प्ट इंजीनियरिंग से मॉडल, प्रॉम्प्ट के कॉन्टेक्स्ट से मनचाहा आउटपुट पाने का तरीका सीखेगा.
कुछ मामलों में, आपको टेस्ट डेटासेट का इस्तेमाल जानी-पहचानी वैल्यू के लिए जनरेटिव मॉडल का आउटपुट जनरेट होता है. उदाहरण के लिए, मॉडल के जवाब, इंसानों से जनरेट किए गए जवाबों से मिलते-जुलते होते हैं या कोई व्यक्ति इन्हें रेटिंग देता है उस मॉडल का सारांश बहुत अच्छा हो.
जनरेटिव एआई का इस्तेमाल, अनुमानित एमएल को लागू करने के लिए भी किया जा सकता है समाधान, जैसे कि क्लासिफ़िकेशन या रिग्रेशन. उदाहरण के लिए, प्राकृतिक भाषा के बारे में अच्छी समझ होने की वजह से, बड़े लैंग्वेज मॉडल (एलएलएम) अक्सर, टेक्स्ट की कैटगरी तय करने वाले टास्क, अनुमानित एमएल (मशीन लर्निंग) की तुलना में बेहतर परफ़ॉर्म कर सकते हैं किसी खास टास्क के लिए ट्रेन किया गया हो.
सक्सेस मेट्रिक तय करें
वे मेट्रिक तय करें जिनका इस्तेमाल करके, यह तय किया जा सकेगा कि मशीन लर्निंग को लागू किया जाएगा या नहीं हो गया है. सफलता मेट्रिक से पता चलता है कि आपको किस चीज़ की परवाह है, जैसे कि यूज़र ऐक्टिविटी या उचित कार्रवाई करने में उपयोगकर्ताओं की मदद करना. जैसे, ऐसे वीडियो देखना जिन्हें वे उपयोगी. सफलता मेट्रिक, मॉडल के आकलन मेट्रिक से अलग होती हैं, जैसे सटीक होना, सटीक, फिर से कॉल करें या AUC.
उदाहरण के लिए, मौसम की जानकारी देने वाले ऐप्लिकेशन की सफलता और फ़ेलियर मेट्रिक इस तरह से तय की जा सकती है निम्न:
| हो गया | उपयोगकर्ता "क्या बारिश होगी?" वेबसाइट को 50 प्रतिशत ज़्यादा दिखाया जाता है पहले नहीं मिलती थी. |
|---|---|
| फ़ेल | उपयोगकर्ता "क्या बारिश होगी?" सुविधा से ज़्यादा बार नहीं से पहले. |
वीडियो ऐप्लिकेशन की मेट्रिक इस तरह से तय की जा सकती हैं:
| हो गया | उपयोगकर्ता साइट पर औसतन 20 प्रतिशत ज़्यादा समय बिताते हैं. |
|---|---|
| फ़ेल | उपयोगकर्ता पहले के मुकाबले साइट पर औसतन ज़्यादा समय बिताते हैं. |
हमारा सुझाव है कि आप एक महत्वाकांक्षी सफलता मेट्रिक तय करें. ज़्यादा महत्वाकांक्षाओं की वजह से फ़र्क़ पड़ सकता है सफलता और असफलता के बीच का अंतर देखें. उदाहरण के लिए, उपयोगकर्ता औसत रूप से साइट पर पहले की तुलना में 10 प्रतिशत ज़्यादा समय, न तो सफलता का नतीजा होता है और न ही असफल. ज़्यादा अहम बात यह नहीं है कि तय नहीं किया गया अंतर क्या है.
इसके और होने की संभावना, आपके मॉडल की क्षमता के हिसाब से होती है—या सफलता की परिभाषा से कहीं ज़्यादा. उदाहरण के लिए, मॉडल की ' , तो निम्न प्रश्न पर विचार करें: क्या मॉडल में सुधार करने से आपको आपके तय किए गए लक्ष्यों के हिसाब से सही हैं? उदाहरण के लिए, किसी मॉडल का मेट्रिक का आकलन किया जा सकता है, लेकिन यह आपको सफलता के मानदंड के करीब नहीं ले जाता है. कि एक बेहतरीन मॉडल के साथ भी, आप उन सफल मानदंडों को पूरा नहीं कर पाएंगे तय किया गया है. दूसरी ओर, किसी मॉडल का आकलन करने वाली मेट्रिक खराब हो सकती है, लेकिन आप अपनी सफलता के मानदंडों के करीब पहुंच जाते हैं, जो यह दर्शाता है कि मॉडल को बेहतर बनाने में आपको सफलता के करीब ले जाता है.
नीचे दिए गए डाइमेंशन को ध्यान में रखकर यह तय किया जा सकता है कि मॉडल सही है या नहीं बेहतर:
यह बेहतर नहीं है, लेकिन आगे बढ़ें. मॉडल का उपयोग प्रोडक्शन एनवायरमेंट के लिए तैयार किया गया है, लेकिन समय के साथ इसमें काफ़ी सुधार हो सकता है.
बहुत बढ़िया. जारी रखें. मॉडल का इस्तेमाल प्रोडक्शन में किया जा सकता है किया गया है. इसे और बेहतर बनाया जा सकता है.
अच्छा है, लेकिन इसे बेहतर नहीं बनाया जा सकता. यह मॉडल प्रोडक्शन में है लेकिन यह उतना ही अच्छा है जितना हो सकता है.
यह काफ़ी नहीं है, और ऐसा कभी नहीं हो पाएगा. मॉडल का उपयोग ऐसा हो सकता है कि यह मॉडल बिना किसी ट्रेनिंग के उपलब्ध हो और इसे प्रोडक्शन एनवायरमेंट के लिए बनाया गया हो.
मॉडल को बेहतर बनाने के लिए, फिर से आकलन करें कि क्या संसाधनों में बढ़ोतरी हुई है, जैसे, इंजीनियरिंग समय और लागत का हिसाब लगाने के लिए, ताकि मॉडल.
सफलता और विफलता की मेट्रिक तय करने के बाद, आपको यह तय करना होगा कि आप उन्हें नापेंगे. उदाहरण के लिए, अपनी सफलता की मेट्रिक को छह को मेज़र किया जा सकता है लागू करने के दिन, छह हफ़्ते या छह महीने बाद.
फ़ेलियर मेट्रिक का विश्लेषण करते समय, यह पता लगाने की कोशिश करें कि सिस्टम क्यों विफल हुआ. इसके लिए उदाहरण के लिए, मॉडल यह अनुमान लगा सकता है कि उपयोगकर्ता किन वीडियो पर क्लिक करेंगे, मॉडल, क्लिकबेट वाले ऐसे टाइटल का सुझाव देना शुरू कर सकता है जिनकी वजह से उपयोगकर्ता का जुड़ाव बढ़ता है बीच में ही छोड़ दें. मौसम की जानकारी देने वाले ऐप्लिकेशन के उदाहरण में, यह मॉडल तब सटीक अनुमान लगा सकता है, जब बारिश होगी, लेकिन बहुत बड़े इलाके में बारिश होगी.
अपनी समझ को परखें
एक फ़ैशन फ़र्म ज़्यादा कपड़े बेचना चाहती है. कोई व्यक्ति, ML का इस्तेमाल करने का सुझाव देता है तय करें कि फ़र्म को कौनसे कपड़े बनाने चाहिए. उन्हें लगता है कि वे किस तरह के कपड़े फ़ैशन में हैं, यह तय करने के लिए मॉडल को ट्रेनिंग दें. इस तारीख के बाद तो वे मॉडल को ट्रेनिंग देते हैं, ताकि वे तय करने के लिए इसे अपने कैटलॉग में लागू कर सकें कौनसे कपड़े बनाने हैं.
उन्हें मशीन लर्निंग का इस्तेमाल करते हुए अपनी समस्या को कैसे फ़्रेम करना चाहिए?
आदर्श नतीजा: जानें कि कौनसे प्रॉडक्ट बनाने हैं.
मॉडल का लक्ष्य: अनुमान लगाना कि कपड़े के कौनसे लेख फ़ैशन.
मॉडल आउटपुट: बाइनरी क्लासिफ़िकेशन, in_fashion,
not_in_fashion
सफलता की मेट्रिक: सत्तर प्रतिशत या उससे ज़्यादा कपड़े बेचें बनाया गया.
बेहतर नतीजे: तय करें कि कितना कपड़ा और सामान ऑर्डर करना है.
मॉडल का लक्ष्य: अनुमान लगाएं कि हर आइटम का कितना हिस्सा बनाना है.
मॉडल आउटपुट: बाइनरी क्लासिफ़िकेशन, make,
do_not_make
सफलता की मेट्रिक: सत्तर प्रतिशत या उससे ज़्यादा कपड़े बेचें बनाया गया.