Después de verificar que el problema se resuelve mejor con una consulta predictiva, o un enfoque de IA generativa, ya puedes plantear tu problema en términos de AA. Realizas las siguientes tareas para encarar un problema en términos del AA:
- Definir el resultado ideal y el objetivo del modelo
- Identifica la salida del modelo.
- Definir métricas de éxito.
Definir el resultado ideal y el objetivo del modelo
Más allá del modelo de AA, ¿cuál es el resultado ideal? En otras palabras, ¿cuál es la tarea exacta que quieres que realice tu producto o función? Esto es igual declaración que definiste anteriormente en la sección Establece el objetivo. sección.
Conecta el objetivo del modelo con el resultado ideal definiendo explícitamente lo que que desea que haga el modelo. La siguiente tabla indica los resultados ideales y las objetivo del modelo para apps hipotéticas:
| Aplicaciones | Resultado ideal | Objetivo del modelo |
|---|---|---|
| App de Clima | Calcula las precipitaciones en incrementos de seis horas para una región geográfica. | Predecir cantidades de precipitaciones de seis horas para regiones geográficas específicas |
| App de moda | Generar una variedad de diseños de camisas. | Generar tres variedades de diseño de camisas a partir de texto y una imagen donde el texto indica el estilo y el color y la imagen es el tipo de camiseta (camiseta, camisa abotonada, polo). |
| App de video | Recomienda videos útiles. | Predice si un usuario hará clic en un video. |
| App de correo electrónico | Detectar spam | Predice si un correo electrónico es spam o no. |
| App financiera | Resumir información financiera de varias fuentes de noticias | Genera resúmenes de 50 palabras de las principales tendencias financieras de la los últimos siete días. |
| App de mapas | Calcula la duración del viaje. | Predice cuánto tiempo tardará en viajar entre dos puntos. |
| App de banca | Identificar transacciones fraudulentas | Predice si el titular de la tarjeta realizó una transacción. |
| App de restaurantes | Identificar el tipo de cocina según el menú de un restaurante. | Predice el tipo de restaurante. |
| App de comercio electrónico | Generar respuestas de asistencia al cliente sobre los productos de la empresa. | Generar respuestas con análisis de opiniones y los en tu base de conocimiento. |
Identifica el resultado que necesitas
Tu elección del tipo de modelo depende del contexto específico y las limitaciones de tu problema. La salida del modelo debe realizar la tarea definida en el resultado ideal. Por lo tanto, la primera pregunta a responder es “¿Qué tipo de resultado necesito para resolver mi problema?”
Si necesitas clasificar algo o hacer una predicción numérica, probablemente usan AA predictivo. Si necesitas generar contenido nuevo o producir resultados relacionadas con la comprensión del lenguaje natural, probablemente usarás la IA generativa.
En las siguientes tablas, se enumeran los resultados del AA predictivo y la IA generativa:
| Sistema de AA | Resultado de ejemplo | |
|---|---|---|
| Clasificación | Binaria | Clasificar un correo electrónico como spam o no spam |
| Etiqueta única de varias clases | Clasificar un animal en una imagen | |
| Etiquetas múltiples de clases múltiples | Clasificar todos los animales de una imagen | |
| Numérico | Regresión unidimensional | Predecir la cantidad de vistas que obtendrá un video |
| Regresión multidimensional | Predecir la presión arterial, la frecuencia cardíaca y los niveles de colesterol para de una persona. |
| Tipo de modelo | Resultado de ejemplo |
|---|---|
| Texto |
Resume un artículo. Responder las opiniones de los clientes Traduce documentos del inglés al mandarín. Escribe descripciones de productos. Analiza documentos legales.
|
| Imagen |
Producir imágenes de marketing Aplicar efectos visuales a las fotos Generar variaciones en el diseño del producto.
|
| Audio |
Genera diálogo con un acento específico.
Genera una composición musical corta de un género específico, como
jazz.
|
| Video |
Genera videos de aspecto realista.
Analizar material de video y aplicar efectos visuales
|
| Multimodal | Produce varios tipos de salida, como un video con subtítulos. |
Clasificación
Un modelo de clasificación que predice la categoría a la que pertenecen los datos de entrada; por ejemplo, si una entrada deben clasificarse como A, B o C.
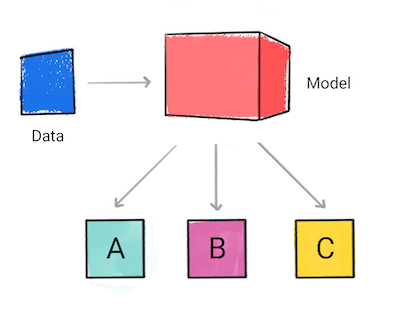
Figura 1: Un modelo de clasificación que realiza predicciones.
Según la predicción del modelo, tu app podría tomar una decisión. Por ejemplo, que la predicción sea de categoría A, entonces hacer X; Si la predicción pertenece a la categoría B, hacer, Y; Si la predicción corresponde a la categoría C, hacer Z. En algunos casos, la predicción is el resultado de la app.
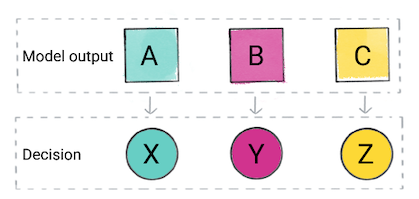
Figura 2: El resultado de un modelo de clasificación que se usa en el código del producto para a tomar una decisión.
Regresión
Un modelo de regresión predice un valor numérico.
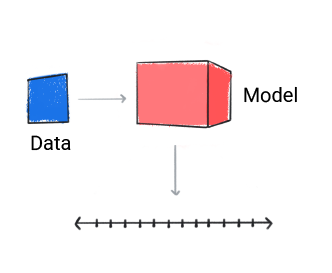
Figura 3: Modelo de regresión que realiza una predicción numérica.
Según la predicción del modelo, tu app podría tomar una decisión. Por ejemplo, la predicción se encuentra dentro del rango A, hace X; si la predicción se encuentra dentro del rango B, hacer Y; si la predicción se encuentra dentro del rango C, haz Z. En algunos casos, el predicción es el resultado de la app.
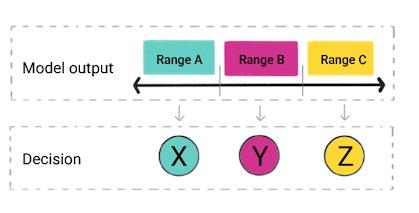
Figura 4: El resultado de un modelo de regresión que se usa en el código del producto para crear una decisión.
Considera la siguiente situación:
Quieres almacenar en caché según su popularidad prevista. En otras palabras, si tu modelo que predice que un video será popular, debes mostrarlo rápidamente a los usuarios. Para por lo tanto, usarás la caché más costosa y eficaz. Para otros videos, utilizarás una caché diferente. Tus criterios de almacenamiento en caché son los siguientes:
- Si se predice que un video alcanzará 50 vistas o más, utilizarás el costoso la caché.
- Si se predice que un video tendrá entre 30 y 50 vistas, utilizarás la la caché.
- Si se predice que el video tendrá menos de 30 vistas, no almacenarás en caché el video.
Piensas que un modelo de regresión es el enfoque correcto porque estarás prediciendo un valor numérico, la cantidad de vistas. Sin embargo, cuando entrenes la regresión te das cuenta de que produce la misma loss para una predicción de 28 y 32 para los videos que tienen 30 vistas. En otras palabras, aunque tu app tendrá un diseño un comportamiento diferente si la predicción es de 28 frente a 32, el modelo considera predicciones similares así por igual.
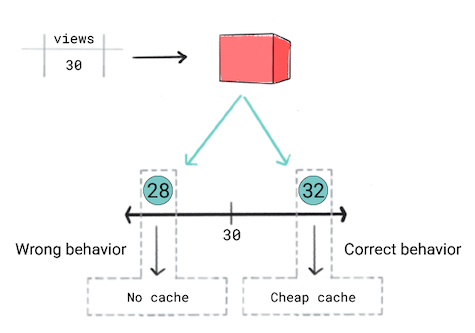
Figura 5: Entrenar un modelo de regresión
Los modelos de regresión no conocen los umbrales definidos por el producto. Por lo tanto, si tu el comportamiento de una aplicación cambia considerablemente debido a pequeñas diferencias en una de las predicciones del modelo de regresión, deberías considerar de clasificación de modelos.
En esta situación, un modelo de clasificación produciría el comportamiento correcto ya que un modelo de clasificación produciría una pérdida más alta para una predicción entre 28 y 32. En cierto sentido, los modelos de clasificación producen umbrales de forma predeterminada.
Este escenario destaca dos puntos importantes:
Predecir la decisión Cuando sea posible, predice la decisión que tomará tu app realizar. En el ejemplo del video, un modelo de clasificación predeciría la si las categorías en las que clasificaba los videos no tuvieran caché, "barato caché", y una "caché costosa". Ocultar el comportamiento de tu app al modelo hacen que tu app produzca un comportamiento incorrecto.
Comprende las limitaciones del problema. Si tu app tiene diferente acciones basadas en diferentes umbrales, determina si esos umbrales fijas o dinámicas.
- Umbrales dinámicos: Si los umbrales son dinámicos, usa un modelo de regresión. y establecer los límites de los umbrales en el código de la app. Esto te permite fácilmente actualizar los umbrales y, al mismo tiempo, hacer que el modelo tome decisiones predicciones.
- Umbrales fijos: Si los umbrales son fijos, usa un modelo de clasificación. y etiquetar tus conjuntos de datos según los límites de los umbrales.
En general, la mayor parte del aprovisionamiento de caché es dinámico y los umbrales cambian. con el tiempo. Debido a que este es específicamente un problema de almacenamiento en caché, de regresión lineal es la mejor opción. Sin embargo, para muchos problemas, el de clasificación se fijarán, lo que hará que el modelo de clasificación sea la mejor solución.
Veamos otro ejemplo. Si compilas una app meteorológica cuyo
el resultado ideal es informar a los usuarios
cuánto lloverá en las próximas seis horas
podrías usar un modelo de regresión que prediga la etiqueta precipitation_amount.
| Resultado ideal | Etiqueta ideal |
|---|---|
| Indicarles a los usuarios cuánto lloverá en su área en las próximas seis horas. | precipitation_amount
|
En el ejemplo de la app meteorológica, la etiqueta aborda directamente el resultado ideal.
Sin embargo, en algunos casos, la relación uno a uno no es evidente entre los
resultado ideal y la etiqueta. Por ejemplo, en la aplicación de video, el resultado ideal es
para recomendar videos útiles. Sin embargo, no hay una etiqueta
en el conjunto de datos llamada
useful_to_user.
| Resultado ideal | Etiqueta ideal |
|---|---|
| Recomienda videos útiles. | ? |
Por lo tanto, debes encontrar una etiqueta de proxy.
Etiquetas de proxy
Etiquetas de proxy para reemplazar
las etiquetas que no están en el conjunto de datos. Las etiquetas de proxy son necesarias cuando no se puede
medir directamente lo que quieres predecir. En la app de video, no podemos
medir si un usuario encontrará útil o no un video. Sería estupendo que el
conjunto de datos tenía un atributo useful, y los usuarios marcaron todos los videos que encontraron
útil, pero como el conjunto de datos no, necesitaremos una etiqueta de proxy
sustitutos de la utilidad.
Una etiqueta de proxy de utilidad puede ser si el usuario compartirá o no le gustará el video.
| Resultado ideal | Etiqueta de proxy |
|---|---|
| Recomienda videos útiles. | shared OR liked |
Ten cuidado con las etiquetas de proxy porque no miden directamente lo que quieres. para predecir. Por ejemplo, en la siguiente tabla se describen los problemas con los Etiquetas de proxy para Recomienda videos útiles:
| Etiqueta de proxy | Problema |
|---|---|
| Predice si el usuario hará clic en el botón “me gusta” . | La mayoría de los usuarios nunca hacen clic en "me gusta". |
| Predice si un video será popular. | No personalizado. Es posible que a algunos usuarios no les gusten los videos populares. |
| Predice si el usuario compartirá el video. | Algunos usuarios no comparten videos. A veces, las personas comparten videos no les gustan. |
| Predice si el usuario hará clic en reproducir. | Maximiza los ciberanzuelos. |
| Predice por cuánto tiempo miran el video. | Prioriza los videos largos de manera diferenciada por los videos cortos. |
| Predice cuántas veces el usuario volverá a mirar el video. | Favoritas que puedan volver a mirar en lugar de videos de géneros que no se pueden volver a mirar. |
Ninguna etiqueta de proxy puede ser un sustituto perfecto de tu resultado ideal. Todos los tener problemas potenciales. Elige la que tenga menos problemas para tu para tu caso de uso específico.
Comprueba tu comprensión
Generación
En la mayoría de los casos, no entrenarás tu propio modelo generativo porque, requiere cantidades masivas de datos de entrenamiento y recursos de procesamiento. En cambio, personalizarás un modelo generativo previamente entrenado. Para lograr que un modelo generativo generan los resultados deseados, es posible que debas usar una o más de las siguientes opciones técnicas:
Destilación. Para crear un para una versión más pequeña de un modelo más grande, se genera un conjunto de datos sintético con etiquetas del modelo más grande que se usa para entrenar el más pequeño. Generativa Los modelos suelen ser gigantes y consumen una cantidad considerable de recursos (como la memoria y la electricidad). La síntesis permite a los objetos más pequeños que consumen menos recursos para aproximar el rendimiento del modelo más grande.
Ajuste o ajuste eficiente de parámetros. Para mejorar el rendimiento de un modelo en una tarea específica, debes entrenar el modelo con un conjunto de datos que contenga ejemplos del tipo de salida que queremos producir.
Ingeniería de instrucciones. Para para que el modelo realice una tarea específica para producir resultados en un formato específico, debes indicarle al modelo la tarea que deseas. que haga o explique cómo quieres que el resultado tenga el formato. En otras palabras, el instrucción puede incluir instrucciones en lenguaje natural sobre cómo realizar la tarea o ejemplos ilustrativos con los resultados deseados.
Por ejemplo, si quieres resúmenes cortos de artículos, puedes ingresar el lo siguiente:
Produce 100-word summaries for each article.Si quieres que el modelo genere texto para un nivel de lectura específico, puedes ingresar lo siguiente:
All the output should be at a reading level for a 12-year-old.Si quieres que el modelo proporcione su salida en un formato específico, puedes explicar cómo se debe formatear el resultado; por ejemplo, "formatear el resultados en una tabla", o podrías demostrar la tarea dándole ejemplos. Por ejemplo, podrías ingresar lo siguiente:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
Resumen y ajuste actualizado parámetros. Ingeniería de instrucciones no actualiza los parámetros del modelo. En cambio, la ingeniería de instrucciones ayuda al modelo aprende a producir el resultado deseado a partir del contexto de la instrucción.
En algunos casos, también necesitarás conjunto de datos de prueba para evaluar la salida del modelo generativo frente a valores conocidos, p. ej., comprobar que los resúmenes del modelo son similares a los generados por humanos que los resúmenes del modelo sean de calidad.
La IA generativa también puede usarse para implementar AA predictivo como clasificación o regresión. Por ejemplo, debido a su profundo conocimiento del lenguaje natural, modelos grandes de lenguaje (LLM) puede realizar con frecuencia tareas de clasificación de texto mejor que el AA predictivo entrenado para la tarea específica.
Definir las métricas de éxito
Definir las métricas que usarás para determinar si la implementación del AA es exitoso. Las métricas de éxito definen lo que te importa, como la participación o Ayudar a los usuarios a realizar las acciones adecuadas, como mirar videos que encuentran útiles. Las métricas de éxito difieren de las métricas de evaluación del modelo, como exactitud, precisión, recuperación AUC.
Por ejemplo, las métricas de éxito y fracaso de la app meteorológica podrían definirse como lo siguiente:
| Listo | Los usuarios abren la app de "¿Lloverá?", un 50% más de frecuencia que antes. |
|---|---|
| Falla | Los usuarios abren la app de "¿Lloverá?", atributo no con una frecuencia máxima antes. |
Las métricas de la app de video pueden definirse de la siguiente manera:
| Listo | Los usuarios pasan, en promedio, un 20% más de tiempo en el sitio. |
|---|---|
| Falla | En promedio, los usuarios no pasan más tiempo que antes en el sitio web. |
Recomendamos definir métricas de éxito ambiciosas. Las grandes ambiciones pueden generar brechas entre el éxito y el fracaso. Por ejemplo, los usuarios que invierten en promedio Un 10% más de tiempo en el sitio que antes no significa tener éxito ni fracaso. La brecha indefinida no es lo importante.
Lo importante es la capacidad de tu modelo para acercarse superar, la definición del éxito. Por ejemplo, cuando analices el estado considera la siguiente pregunta: ¿Crees que mejorar el modelo a los criterios de éxito definidos? Por ejemplo, un modelo podría tener una gran métricas de evaluación, pero no acercarte a tus criterios de éxito, lo que indica que incluso con un modelo perfecto, no cumplirías con los criterios de éxito que definido. Por otro lado, un modelo puede tener métricas de evaluación deficientes, pero te acerca más a tus criterios de éxito, lo que indica que mejorar el modelo te acercarán al éxito.
Las siguientes son dimensiones que se deben tener en cuenta para determinar si el modelo vale la pena mejorando:
No es lo suficientemente bueno, pero continúa. El modelo no debe usarse en una de producción, pero con el tiempo podría mejorarse significativamente.
Suficientemente bien, y continúa. El modelo podría usarse en un entorno en el entorno de producción y podría mejorarse aún más.
Es suficiente, pero no se puede mejorar. El modelo se encuentra en producción de procesamiento, pero probablemente sea tan bueno como sea posible.
No es lo suficientemente bueno y nunca lo será. El modelo no debe usarse en una entorno de producción y probablemente ningún entrenamiento llegará allí.
Cuando decidas mejorar el modelo, vuelve a evaluar si el aumento de los recursos, como el tiempo de ingeniería y los costos de procesamiento, justifican la mejora prevista de el modelo.
Después de definir las métricas de éxito y fracaso, debes determinar con qué frecuencia los medirás. Por ejemplo, podrías medir las métricas de éxito seis días, seis semanas o seis meses después de implementar el sistema.
Cuando analices las métricas de fallas, intenta determinar por qué falló el sistema. Para ejemplo, el modelo podría predecir en qué videos harán clic los usuarios, pero podría comenzar a recomendar títulos de ciberanzuelo que hagan que la participación del usuario a abandonarlo. En el ejemplo de la app meteorológica, el modelo podría predecir con exactitud lloverá, pero en una región geográfica demasiado grande.
Comprueba tu comprensión
Una empresa de moda quiere vender más ropa. Alguien sugiere usar el AA para determinar qué ropa debe fabricar la empresa. Creen que pueden entrenar un modelo para determinar qué tipo de ropa está de moda. Después del entrenan el modelo, quieren aplicarlo a su catálogo para decidir qué ropa hacer.
¿Cómo debería plantear su problema en términos del AA?
Resultado ideal: Determina qué productos fabricar.
Objetivo del modelo: Predecir qué prendas de ropa están en a la moda.
Salida del modelo: clasificación binaria, in_fashion,
not_in_fashion
Métricas de éxito: Vender el setenta por ciento o más de la ropa en la nube.
Resultado ideal: Determina la cantidad de tela y suministros que deseas pedir.
Objetivo del modelo: Predecir qué cantidad de cada artículo se fabricará.
Salida del modelo: clasificación binaria, make,
do_not_make
Métricas de éxito: Vender el setenta por ciento o más de la ropa en la nube.