Saiba como o Google desenvolveu o modelo de classificação de imagem de última geração para pesquisa no Google Fotos. Faça um curso intensivo sobre redes neurais convolucionais e crie seu próprio classificador de imagens para distinguir fotos de gatos de fotos de cães.
Pré-requisitos
Curso intensivo de machine learning ou experiência equivalente com as noções básicas de ML
Proficiência em noções básicas de programação e alguma experiência em programação em Python.
Introdução
Em maio de 2013, o Google lançou a pesquisa de fotos pessoais, oferecendo aos usuários a capacidade de recuperar fotos nas bibliotecas com base nos objetos presentes nessas imagens.
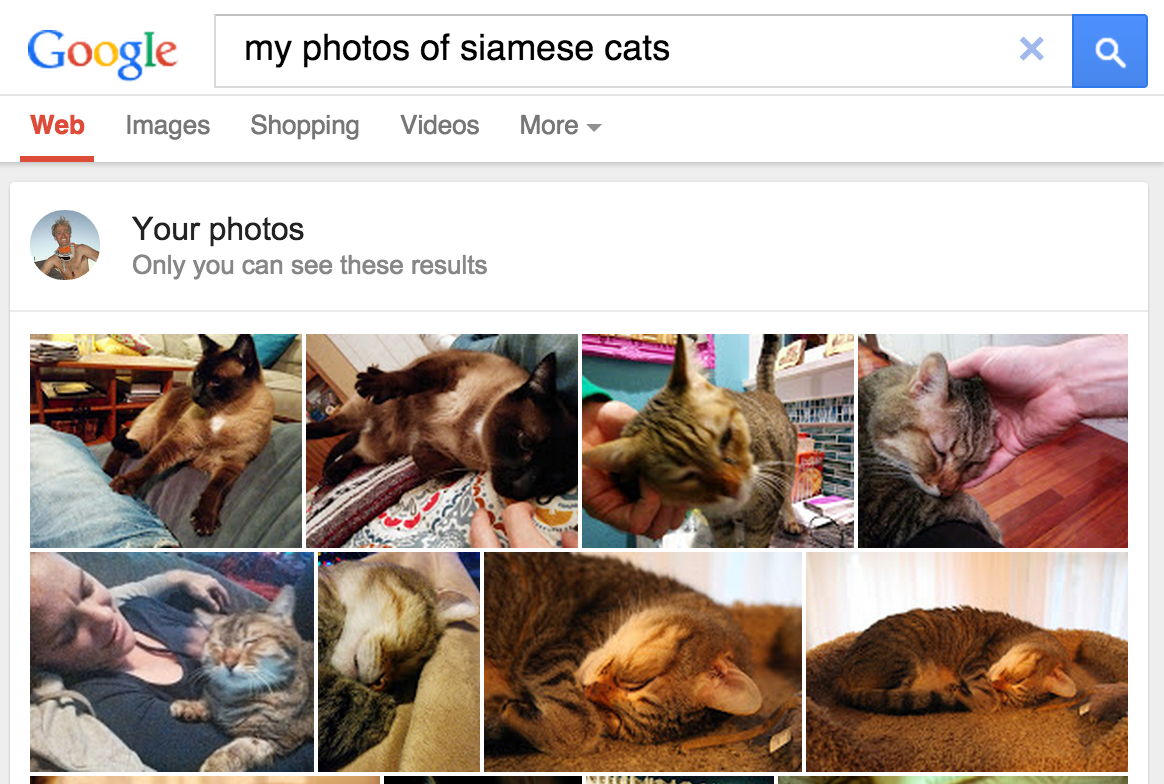 Figura 1. a pesquisa do Google Fotos por
gatos siames entrega os produtos.
Figura 1. a pesquisa do Google Fotos por
gatos siames entrega os produtos.
O recurso, mais tarde incorporado ao Google Fotos em 2015, foi amplamente percebido como um divisor de águas, uma prova de conceito de que o software de visão computacional poderia classificar as imagens em padrões humanos, agregando valor de várias maneiras:
- Os usuários não precisavam mais marcar fotos com rótulos como "quot;praia" para categorizar o conteúdo de imagens. Isso elimina uma tarefa manual que poderia ser bastante tediosa ao gerenciar conjuntos de centenas ou milhares de imagens.
- Os usuários podem explorar a coleção de fotos de novas maneiras, usando termos de pesquisa para localizar fotos com objetos que talvez nunca tenham sido marcados. Por exemplo, eles podem pesquisar "quot;palm tree" para exibir todas as fotos de férias que têm palmeiras no fundo.
- É possível que o software possa "ver" distinções fiscais que os próprios usuários finais podem não conseguir perceber (por exemplo, distinguir gatos siamês e abyssinianos), aumentando o conhecimento dos usuários.
Como funciona a classificação de imagens
A classificação de imagens é um problema de aprendizado supervisionado: defina um conjunto de classes de destino (objetos para identificar em imagens) e treine um modelo para reconhecê-las usando fotos de exemplo rotuladas. Os primeiros modelos de visão computacional dependiam de dados brutos de pixel como entrada para o modelo. No entanto, como mostrado na Figura 2, os dados brutos de pixel por si só não fornecem uma representação suficientemente estável para abranger as diversas variações de um objeto, como capturadas em uma imagem. A posição do objeto, o plano de fundo atrás do objeto, a iluminação ambiente, o ângulo da câmera e o foco da câmera podem produzir flutuação nos dados de pixel brutos. Essas diferenças são significativas o suficiente para que não possam ser corrigidas usando médias ponderadas dos valores de RGB do pixel.
 Figura 2. Esquerda: os gatos podem ser capturados em uma foto em várias posições, com diferentes cenários e condições de iluminação. Correto: em média, os dados de pixels para essa variedade não produzem informações significativas.
Figura 2. Esquerda: os gatos podem ser capturados em uma foto em várias posições, com diferentes cenários e condições de iluminação. Correto: em média, os dados de pixels para essa variedade não produzem informações significativas.
Para modelar objetos de maneira mais flexível, os modelos clássicos de visão computacional adicionaram novos recursos derivados de dados de pixel, como histogramas de cores, texturas e formas. A desvantagem dessa abordagem era que a engenharia de atributos se tornou um fardo real, já que havia muitas entradas para ajustar. Para um classificador de gato, quais cores foram mais relevantes? As definições de forma precisam ser flexíveis? Como os recursos precisavam ser ajustados dessa forma, criar modelos robustos foi muito desafiador e a precisão foi prejudicada.