Esta página contém termos do glossário de Fundamentos de ML. Para conferir todos os termos do glossário, clique aqui.
A
precisão
O número de previsões de classificação corretas dividido pelo número total de previsões. Ou seja:
Por exemplo, um modelo que fez 40 previsões corretas e 10 incorretas teria uma acurácia de:
A classificação binária fornece nomes específicos para as diferentes categorias de previsões corretas e incorretas. Assim, a fórmula de acurácia para classificação binária é a seguinte:
em que:
- TP é o número de verdadeiros positivos (previsões corretas).
- TN é o número de verdadeiros negativos (previsões corretas).
- FP é o número de falsos positivos (previsões incorretas).
- FN é o número de falsos negativos (previsões incorretas).
Compare e contraste a acurácia com a precisão e o recall.
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas no Curso intensivo de machine learning para mais informações.
função de ativação
Uma função que permite que as redes neurais aprendam relações não lineares (complexas) entre os recursos e o rótulo.
As funções de ativação mais usadas incluem:
Os gráficos das funções de ativação nunca são linhas retas únicas. Por exemplo, o gráfico da função de ativação ReLU consiste em duas linhas retas:

Um gráfico da função de ativação sigmoide tem esta aparência:

Clique no ícone para ver um exemplo.
Em uma rede neural, as funções de ativação manipulam a soma ponderada de todas as entradas para um neurônio. Para calcular uma soma ponderada, o neurônio adiciona os produtos dos valores e ponderações relevantes. Por exemplo, suponha que a entrada relevante para um neurônio consista no seguinte:
| valor de entrada | peso de entrada |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
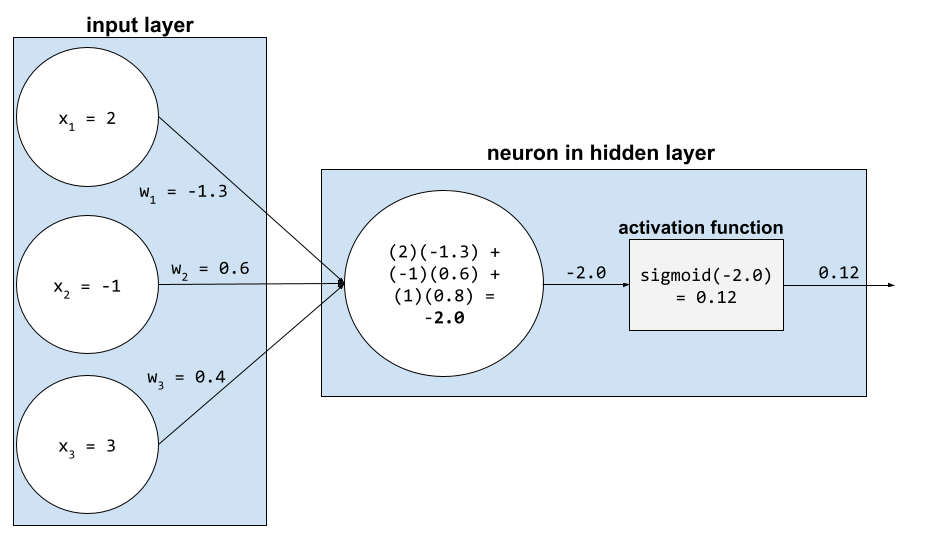
Consulte Redes neurais: funções de ativação no Curso intensivo de machine learning para mais informações.
inteligência artificial
Um programa ou modelo não humano que pode resolver tarefas sofisticadas. Por exemplo, programas ou modelos que traduzem texto ou que identificam doenças usando imagens radiológicas usam inteligência artificial.
Formalmente, o aprendizado de máquina é um subcampo da inteligência artificial. Mas, nos últimos anos, algumas organizações começaram a usar os termos inteligência artificial e aprendizado de máquina como sinônimos.
AUC (área sob a curva ROC)
Um número entre 0,0 e 1,0 que representa a capacidade de um modelo de classificação binária separar classes positivas de classes negativas. Quanto mais perto de 1,0 a AUC estiver, melhor será a capacidade do modelo de distinguir as classes.
Por exemplo, a ilustração a seguir mostra um modelo de classificação que separa perfeitamente as classes positivas (ovais verdes) das negativas (retângulos roxos). Esse modelo irrealisticamente perfeito tem uma AUC de 1,0:

Por outro lado, a ilustração a seguir mostra os resultados de um modelo de classificação que gerou resultados aleatórios. Esse modelo tem uma AUC de 0,5:

Sim, o modelo anterior tem uma AUC de 0,5, não de 0,0.
A maioria dos modelos está em algum lugar entre os dois extremos. Por exemplo, o modelo a seguir separa positivos de negativos de alguma forma e, portanto, tem uma AUC entre 0,5 e 1,0:

A AUC ignora qualquer valor definido para o limiar de classificação. Em vez disso, a AUC considera todos os limiares de classificação possíveis.
Clique no ícone para saber mais sobre a relação entre AUC e curvas ROC.
A AUC representa a área sob uma curva ROC. Por exemplo, a curva ROC de um modelo que separa perfeitamente positivos de negativos tem esta aparência:
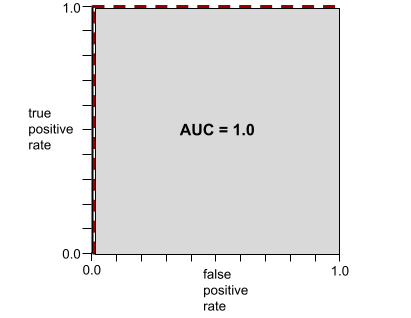
A AUC é a área da região cinza na ilustração anterior. Nesse caso incomum, a área é simplesmente o comprimento da região cinza (1,0) multiplicado pela largura da região cinza (1,0). Portanto, o produto de 1,0 e 1,0 gera uma AUC de exatamente 1,0, que é a pontuação mais alta possível.
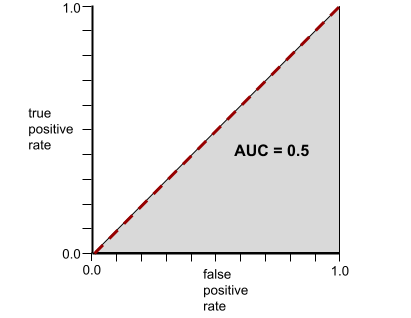
Por outro lado, a curva ROC de um modelo de classificação que não consegue separar classes é assim: A área dessa região cinza é 0,5.
Uma curva ROC mais típica tem aproximadamente esta aparência:
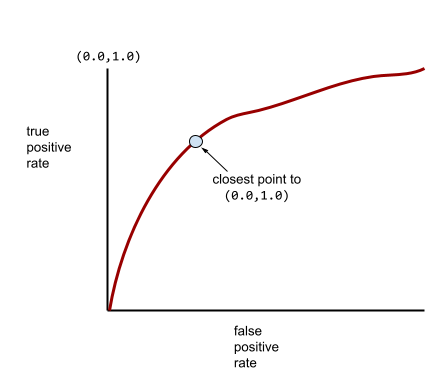
Calcular a área abaixo dessa curva manualmente seria trabalhoso. Por isso, um programa geralmente calcula a maioria dos valores de AUC.
Consulte Classificação: ROC e AUC no Curso intensivo de machine learning para mais informações.
B
retropropagação
O algoritmo que implementa o gradiente descendente em redes neurais.
O treinamento de uma rede neural envolve muitas iterações do seguinte ciclo de duas passagens:
- Durante a passagem direta, o sistema processa um lote de exemplos para gerar previsões. O sistema compara cada previsão com cada valor de rótulo. A diferença entre a previsão e o valor do rótulo é a perda desse exemplo. O sistema agrega as perdas de todos os exemplos para calcular a perda total do lote atual.
- Durante a passagem para trás (backpropagation), o sistema reduz a perda ajustando os pesos de todos os neurônios em todas as camadas escondidas.
As redes neurais geralmente contêm muitos neurônios em várias camadas ocultas. Cada um desses neurônios contribui para a perda geral de maneiras diferentes. A retropropagação determina se é necessário aumentar ou diminuir os pesos aplicados a neurônios específicos.
A taxa de aprendizado é um multiplicador que controla o grau em que cada transmissão para trás aumenta ou diminui cada peso. Uma taxa de aprendizado grande aumenta ou diminui cada peso mais do que uma taxa pequena.
Em termos de cálculo, a retropropagação implementa a regra da cadeia do cálculo. Ou seja, a retropropagação calcula a derivada parcial do erro em relação a cada parâmetro.
Há alguns anos, os profissionais de ML precisavam escrever código para implementar a retropropagação. As APIs de ML modernas, como o Keras, implementam a retropropagação para você. Ufa.
Consulte Redes neurais no Curso intensivo de machine learning para mais informações.
lote
O conjunto de exemplos usados em uma iteração de treinamento. O tamanho do lote determina o número de exemplos em um lote.
Consulte época para uma explicação de como um lote se relaciona a uma época.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
tamanho do lote
O número de exemplos em um lote. Por exemplo, se o tamanho do lote for 100, o modelo vai processar 100 exemplos por iteração.
Confira a seguir algumas estratégias de tamanho de lote conhecidas:
- Gradiente descendente estocástico (GDE), em que o tamanho do lote é 1.
- Lote completo, em que o tamanho do lote é o número de exemplos em todo o conjunto de treinamento. Por exemplo, se o conjunto de treinamento tiver um milhão de exemplos, o tamanho do lote será um milhão de exemplos. O lote completo geralmente é uma estratégia ineficiente.
- minilote, em que o tamanho do lote geralmente fica entre 10 e 1.000. O mini-batch geralmente é a estratégia mais eficiente.
Para saber mais, consulte os seguintes artigos:
- Sistemas de ML de produção: inferência estática x dinâmica no Curso intensivo de machine learning.
- Manual de ajuste do aprendizado profundo.
viés (ética/justiça)
1. Estereótipos, preconceito ou favoritismo em relação a algumas coisas, pessoas ou grupos. Esses vieses podem afetar a coleta e a interpretação de dados, o design de um sistema e a forma como os usuários interagem com ele. Algumas formas desse tipo de viés incluem:
- Viés de automação
- viés de confirmação
- Viés do experimentador
- viés de atribuição a grupos
- viés implícito
- viés de grupo
- Viés de homogeneidade externa ao grupo
2. Erro sistemático introduzido por um procedimento de amostragem ou relatório. Algumas formas desse tipo de viés incluem:
- viés de convergência
- viés de não resposta
- viés de participação
- viés de relatório
- vício de amostragem
- viés de seleção
Não confundir com o termo de viés em modelos de machine learning ou o viés de previsão.
Consulte Imparcialidade: tipos de viés no Curso intensivo de machine learning para mais informações.
viés (matemática) ou termo de viés
Uma interceptação ou um deslocamento de uma origem. O viés é um parâmetro nos modelos de machine learning, simbolizado por um dos seguintes elementos:
- b
- w0
Por exemplo, o viés é o b na seguinte fórmula:
Em uma linha bidimensional simples, o viés significa "intercepto y". Por exemplo, o viés da linha na ilustração a seguir é 2.
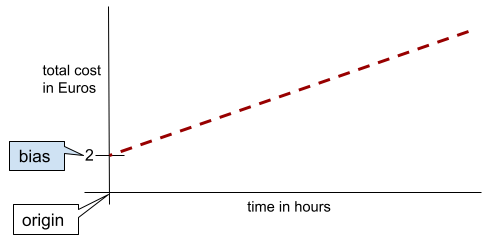
O viés existe porque nem todos os modelos começam na origem (0,0). Por exemplo, suponha que um parque de diversões custe 2 euros para entrar e mais 0,5 euro por hora de permanência de um cliente. Portanto, um modelo que mapeia o custo total tem um viés de 2, porque o menor custo é de 2 euros.
Não confunda viés com viés em ética e justiça ou viés de previsão.
Consulte Regressão linear no Curso intensivo de machine learning para mais informações.
classificação binária
Um tipo de tarefa de classificação que prevê uma de duas classes mutuamente exclusivas:
Por exemplo, os dois modelos de aprendizado de máquina a seguir realizam classificação binária:
- Um modelo que determina se as mensagens de e-mail são spam (a classe positiva) ou não spam (a classe negativa).
- Um modelo que avalia sintomas médicos para determinar se uma pessoa tem uma doença específica (a classe positiva) ou não (a classe negativa).
Contraste com a classificação multiclasse.
Consulte também regressão logística e limiar de classificação.
Consulte Classificação no Curso intensivo de machine learning para mais informações.
agrupamento por classes
Converter um único atributo em vários atributos binários chamados de buckets ou classes, normalmente com base em um intervalo de valores. O atributo cortado geralmente é um atributo de valor contínuo.
Por exemplo, em vez de representar a temperatura como um único atributo de usar pontos flutuantes contínuo, você pode dividir intervalos de temperatura em intervalos discretos, como:
- <= 10 graus Celsius seria o grupo "frio".
- 11 a 24 graus Celsius seria o intervalo "temperado".
- >= 25 graus Celsius seria o grupo "quente".
O modelo vai tratar todos os valores no mesmo bucket de forma idêntica. Por exemplo, os valores 13 e 22 estão no bucket "temperado", então o modelo trata os dois valores de forma idêntica.
Consulte Dados numéricos: discretização no Curso intensivo de machine learning para mais informações.
C
dados categóricos
Atributos com um conjunto específico de valores possíveis. Por exemplo, considere um recurso categórico chamado traffic-light-state, que só pode ter um dos três valores possíveis a seguir:
redyellowgreen
Ao representar traffic-light-state como um atributo categórico, um modelo pode aprender os diferentes impactos de red, green e yellow no comportamento do motorista.
Às vezes, os recursos categóricos são chamados de recursos discretos.
Contraste com dados numéricos.
Consulte Como trabalhar com dados categóricos no Curso intensivo de machine learning para mais informações.
classe
Uma categoria a que um rótulo pode pertencer. Exemplo:
- Em um modelo de classificação binária que detecta spam, as duas classes podem ser spam e não spam.
- Em um modelo de classificação multiclasse que identifica raças de cachorros, as classes podem ser poodle, beagle, pug, e assim por diante.
Um modelo de classificação prevê uma classe. Já um modelo de regressão prevê um número, não uma classe.
Consulte Classificação no Curso intensivo de machine learning para mais informações.
modelo de classificação
Um modelo cuja previsão é uma classe. Por exemplo, todos os modelos a seguir são de classificação:
- Um modelo que prevê o idioma de uma frase de entrada (francês? Espanhol? Italiano?).
- Um modelo que prevê espécies de árvores (bordo? Carvalho? Baobá?).
- Um modelo que prevê a classe positiva ou negativa para uma condição médica específica.
Já os modelos de regressão preveem números, não classes.
Dois tipos comuns de modelos de classificação são:
limiar de classificação
Em uma classificação binária, um número entre 0 e 1 que converte a saída bruta de um modelo de regressão logística em uma previsão da classe positiva ou da classe negativa. O limite de classificação é um valor escolhido por um humano, não pelo treinamento de modelo.
Um modelo de regressão logística gera um valor bruto entre 0 e 1. Em seguida:
- Se esse valor bruto for maior que o limite de classificação, a classe positiva será prevista.
- Se esse valor bruto for menor que o limiar de classificação, a classe negativa será prevista.
Por exemplo, suponha que o limite de classificação seja 0,8. Se o valor bruto for 0,9, o modelo vai prever a classe positiva. Se o valor bruto for 0,7, o modelo vai prever a classe negativa.
A escolha do limite de classificação influencia muito o número de falsos positivos e falsos negativos.
Consulte Limiares e a matriz de confusão no Curso intensivo de machine learning para mais informações.
classificador
Um termo informal para um modelo de classificação.
conjunto de dados não balanceado
Um conjunto de dados para uma classificação em que o número total de rótulos de cada classe é significativamente diferente. Por exemplo, considere um conjunto de dados de classificação binária cujos dois rótulos são divididos da seguinte maneira:
- 1.000.000 de rótulos negativos
- 10 rótulos positivos
A proporção de rótulos negativos para positivos é de 100.000 para 1. Portanto, esse é um conjunto de dados não balanceado.
Em contraste, o conjunto de dados a seguir é balanceado por classe porque a proporção de rótulos negativos para positivos é relativamente próxima de 1:
- 517 rótulos negativos
- 483 rótulos positivos
Os conjuntos de dados de várias classes também podem ser desbalanceados. Por exemplo, o seguinte conjunto de dados de classificação multiclasse também é desbalanceado porque um rótulo tem muito mais exemplos do que os outros dois:
- 1.000.000 de rótulos com a classe "verde"
- 200 rótulos com a classe "roxo"
- 350 rótulos com a classe "orange"
O treinamento de conjuntos de dados não balanceados pode apresentar desafios especiais. Consulte Conjuntos de dados desequilibrados no Curso intensivo de machine learning para mais detalhes.
Consulte também entropia, classe majoritária e classe minoritária.
corte
Uma técnica para processar outliers fazendo uma ou ambas as ações a seguir:
- Reduzir os valores de recursos que são maiores que um limite máximo até esse limite.
- Aumentar os valores de recursos que estão abaixo de um limite mínimo até esse limite.
Por exemplo, suponha que menos de 0,5% dos valores de um determinado atributo estejam fora do intervalo de 40 a 60. Nesse caso, faça o seguinte:
- Corte todos os valores acima de 60 (o limite máximo) para que sejam exatamente 60.
- Corte todos os valores abaixo de 40 (o limite mínimo) para que sejam exatamente 40.
Os outliers podem danificar os modelos, às vezes causando um estouro de pesos durante o treinamento. Alguns outliers também podem prejudicar muito métricas como acurácia. O corte é uma técnica comum para limitar os danos.
O truncamento de gradiente força os valores de gradiente dentro de um intervalo designado durante o treinamento.
Consulte Dados numéricos: normalização no Curso intensivo de machine learning para mais informações.
matriz de confusão
Uma tabela NxN que resume o número de previsões corretas e incorretas feitas por um modelo de classificação. Por exemplo, considere a seguinte matriz de confusão para um modelo de classificação binária:
| Tumor (previsto) | Não tumor (previsto) | |
|---|---|---|
| Tumor (informações empíricas) | 18 (VP) | 1 (FN) |
| Não tumor (informações empíricas) | 6 (FP) | 452 (VN) |
A matriz de confusão acima mostra o seguinte:
- Das 19 previsões em que a informação empírica era "Tumor", o modelo classificou corretamente 18 e incorretamente 1.
- Das 458 previsões em que a verdade fundamental era "Não tumor", o modelo classificou corretamente 452 e incorretamente 6.
A matriz de confusão para um problema de classificação multiclasse pode ajudar a identificar padrões de erros. Por exemplo, considere a seguinte matriz de confusão para um modelo de classificação multiclasse de três classes que categoriza três tipos diferentes de íris (Virginica, Versicolor e Setosa). Quando a verdade fundamental era Virginica, a matriz de confusão mostra que o modelo tinha muito mais probabilidade de prever Versicolor do que Setosa por engano:
| Setosa (prevista) | Versicolor (previsto) | Virginica (prevista) | |
|---|---|---|---|
| Setosa (informações empíricas) | 88 | 12 | 0 |
| Versicolor (informações empíricas) | 6 | 141 | 7 |
| Virginica (informações empíricas) | 2 | 27 | 109 |
Como outro exemplo, uma matriz de confusão pode revelar que um modelo treinado para reconhecer dígitos manuscritos tende a prever erroneamente 9 em vez de 4 ou 1 em vez de 7.
As matrizes de confusão contêm informações suficientes para calcular várias métricas de performance, incluindo precisão e recall.
atributo de valor contínuo
Um recurso que usa pontos flutuantes com um intervalo infinito de valores possíveis, como temperatura ou peso.
Contraste com o atributo discreto.
convergência
Um estado alcançado quando os valores de perda mudam muito pouco ou nada a cada iteração. Por exemplo, a curva de perda a seguir sugere convergência em torno de 700 iterações:
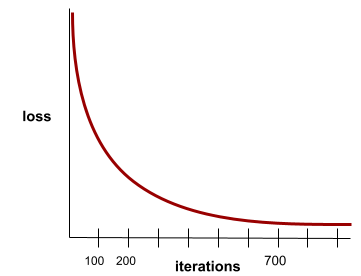
Um modelo converge quando um treinamento adicional não melhora o modelo.
No aprendizado profundo, os valores de perda às vezes permanecem constantes ou quase assim por muitas iterações antes de finalmente diminuírem. Durante um longo período de valores de perda constantes, você pode ter temporariamente uma falsa sensação de convergência.
Consulte também parada antecipada.
Consulte Convergência do modelo e curvas de perda no Curso intensivo de machine learning para mais informações.
D
DataFrame
Um tipo de dados pandas popular para representar conjuntos de dados na memória.
Um DataFrame é análogo a uma tabela ou planilha. Cada coluna de um DataFrame tem um nome (um cabeçalho), e cada linha é identificada por um número exclusivo.
Cada coluna em um DataFrame é estruturada como uma matriz 2D, exceto que cada coluna pode receber um tipo de dados próprio.
Consulte também a página de referência oficial do pandas.DataFrame.
conjunto de dados
Uma coleção de dados brutos, geralmente (mas não exclusivamente) organizada em um dos seguintes formatos:
- uma planilha
- um arquivo no formato CSV (valores separados por vírgula)
modelo profundo
Uma rede neural que contém mais de uma camada escondida.
Um modelo profundo também é chamado de rede neural profunda.
Contraste com o modelo esparso.
atributo denso
Uma característica em que a maioria ou todos os valores são diferentes de zero, geralmente um Tensor de valores de usar pontos flutuantes. Por exemplo, o tensor de 10 elementos a seguir é denso porque 9 dos valores são diferentes de zero:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Contraste com o atributo esparso.
profundidade
A soma do seguinte em uma rede neural:
- o número de camadas ocultas
- o número de camadas de saída, que geralmente é 1
- o número de camadas de embedding
Por exemplo, uma rede neural com cinco camadas escondidas e uma de saída tem uma profundidade de 6.
A camada de entrada não influencia a profundidade.
atributo discreto
Um recurso com um conjunto finito de valores possíveis. Por exemplo, um atributo cujos valores só podem ser animal, vegetal ou mineral é um atributo discreto (ou categórico).
Contraste com o atributo de valor contínuo.
dinâmico
Algo feito com frequência ou de forma contínua. Os termos dinâmico e on-line são sinônimos em machine learning. Confira a seguir usos comuns de dinâmico e on-line no aprendizado de máquina:
- Um modelo dinâmico (ou modelo on-line) é um modelo que é treinado novamente com frequência ou de forma contínua.
- O treinamento dinâmico (ou treinamento on-line) é o processo de treinamento frequente ou contínuo.
- A inferência dinâmica (ou inferência on-line) é o processo de gerar previsões sob demanda.
modelo dinâmico
Um modelo que é treinado novamente com frequência (talvez até continuamente). Um modelo dinâmico é um "aprendiz permanente" que se adapta constantemente aos dados em evolução. Um modelo dinâmico também é conhecido como um modelo on-line.
Contraste com o modelo estático.
E
parada antecipada
Um método de regularização que envolve encerrar o treinamento antes que a perda de treinamento pare de diminuir. Na parada antecipada, você interrompe intencionalmente o treinamento do modelo quando a perda em um conjunto de dados de validação começa a aumentar, ou seja, quando o desempenho de generalização piora.
Contraste com o encerramento antecipado.
camada de embedding
Uma camada escondida especial que treina em um recurso categórico de alta dimensão para aprender gradualmente um vetor de embedding de dimensão inferior. Uma camada de incorporação permite que uma rede neural seja treinada de maneira muito mais eficiente do que apenas com o recurso categórico de alta dimensão.
Por exemplo, o Earth atualmente é compatível com cerca de 73.000 espécies de árvores. Suponha que a espécie de árvore seja um recurso no seu modelo. Assim, a camada de entrada dele inclui um vetor one-hot com 73.000 elementos.
Por exemplo, talvez baobab seja representado assim:

Uma matriz de 73.000 elementos é muito longa. Se você não adicionar uma camada de incorporação ao modelo, o treinamento vai levar muito tempo devido à multiplicação de 72.999 zeros. Talvez você escolha que a camada de embedding tenha 12 dimensões. Como consequência, a camada de incorporação vai aprender gradualmente um novo vetor de incorporação para cada espécie de árvore.
Em algumas situações, o hashing é uma alternativa razoável a uma camada de incorporação.
Consulte Embeddings no Curso intensivo de machine learning para mais informações.
época
Uma passagem completa de treinamento em todo o conjunto de treinamento, de modo que cada exemplo seja processado uma vez.
Uma época representa N/tamanho do lote
iterações de treinamento, em que N é o número total de exemplos.
Por exemplo, suponha que:
- O conjunto de dados consiste em 1.000 exemplos.
- O tamanho do lote é de 50 exemplos.
Portanto, uma única época requer 20 iterações:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
exemplo
Os valores de uma linha de atributos e possivelmente um rótulo. Os exemplos de aprendizado supervisionado se enquadram em duas categorias gerais:
- Um exemplo rotulado consiste em um ou mais atributos e um rótulo. Exemplos rotulados são usados durante o treinamento.
- Um exemplo não-rotulado consiste em um ou mais atributos, mas sem rótulo. Exemplos sem rótulo são usados durante a inferência.
Por exemplo, suponha que você esteja treinando um modelo para determinar a influência das condições climáticas nas notas dos estudantes. Confira três exemplos rotulados:
| Recursos | Rótulo | ||
|---|---|---|---|
| Temperatura | Umidade | Pressão | Pontuação do teste |
| 15 | 47 | 998 | Boa |
| 19 | 34 | 1020 | Excelente |
| 18 | 92 | 1012 | Ruim |
Confira três exemplos sem rótulo:
| Temperatura | Umidade | Pressão | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
A linha de um conjunto de dados geralmente é a origem bruta de um exemplo. Ou seja, um exemplo geralmente consiste em um subconjunto das colunas no conjunto de dados. Além disso, os recursos em um exemplo também podem incluir recursos sintéticos, como cruzamentos de recursos.
Consulte Aprendizado supervisionado no curso Introdução ao machine learning para mais informações.
F
falso negativo (FN)
Um exemplo em que o modelo prevê incorretamente a classe negativa. Por exemplo, o modelo prevê que uma determinada mensagem de e-mail não é spam (a classe negativa), mas na verdade é spam.
falso positivo (FP)
Um exemplo em que o modelo prevê incorretamente a classe positiva. Por exemplo, o modelo prevê que uma determinada mensagem de e-mail é spam (a classe positiva), mas que essa mensagem não é spam.
Consulte Limiares e a matriz de confusão no Curso intensivo de machine learning para mais informações.
taxa de falso positivo (FPR)
A proporção de exemplos negativos reais para os quais o modelo previu incorretamente a classe positiva. A fórmula a seguir calcula a taxa de falsos positivos:
A taxa de falso positivo é o eixo x em uma curva ROC.
Consulte Classificação: ROC e AUC no Curso intensivo de machine learning para mais informações.
recurso
Uma variável de entrada para um modelo de machine learning. Um exemplo consiste em um ou mais atributos. Por exemplo, suponha que você esteja treinando um modelo para determinar a influência das condições climáticas nas notas dos estudantes. A tabela a seguir mostra três exemplos, cada um com três recursos e um rótulo:
| Recursos | Rótulo | ||
|---|---|---|---|
| Temperatura | Umidade | Pressão | Pontuação do teste |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Contraste com o rótulo.
Consulte Aprendizado supervisionado no curso "Introdução ao machine learning" para mais informações.
cruzamento de atributos
Um atributo sintético formado pelo "cruzamento" de atributos categóricos ou agrupados por classes.
Por exemplo, considere um modelo de "previsão de clima" que representa a temperatura em um dos quatro segmentos a seguir:
freezingchillytemperatewarm
e representa a velocidade do vento em um dos três buckets a seguir:
stilllightwindy
Sem cruzamentos de atributos, o modelo linear é treinado de forma independente em cada um dos sete intervalos anteriores. Assim, o modelo é treinado em freezing de forma independente do treinamento em windy.
Como alternativa, você pode criar um cruzamento de atributos de temperatura e velocidade do vento. Esse atributo sintético teria os seguintes 12 valores possíveis:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Graças aos cruzamentos de atributos, o modelo pode aprender as diferenças de humor entre um dia freezing-windy e um dia freezing-still.
Se você criar um atributo sintético com base em dois atributos que têm muitos intervalos diferentes, o cruzamento de atributos resultante terá um grande número de combinações possíveis. Por exemplo, se um atributo tiver 1.000 intervalos e o outro tiver 2.000, o cruzamento de atributos resultante terá 2.000.000 de intervalos.
Formalmente, uma combinação é um produto cartesiano.
As combinações de atributos são usadas principalmente com modelos lineares e raramente com redes neurais.
Consulte Dados categóricos: combinações de recursos no Curso intensivo de machine learning para mais informações.
engenharia de atributos
Um processo que envolve as seguintes etapas:
- Determinar quais recursos podem ser úteis no treinamento de um modelo.
- Converter dados brutos do conjunto de dados em versões eficientes desses atributos.
Por exemplo, você pode determinar que temperature é um recurso útil. Depois, teste o agrupamento em intervalos para otimizar o que o modelo pode aprender com diferentes intervalos de temperature.
A engenharia de atributos às vezes é chamada de extração de atributos ou criação de atributos.
Consulte Dados numéricos: como um modelo ingere dados usando vetores de recursos no Curso intensivo de machine learning para mais informações.
conjunto de atributos
O grupo de atributos em que seu modelo de machine learning é treinado. Por exemplo, um conjunto de atributos simples para um modelo que prevê preços de imóveis pode consistir em código postal, tamanho e condição da propriedade.
vetor de atributos
A matriz de valores de recurso que compõem um exemplo. O vetor de recursos é inserido durante o treinamento e a inferência. Por exemplo, o vetor de recursos de um modelo com dois recursos discretos pode ser:
[0.92, 0.56]
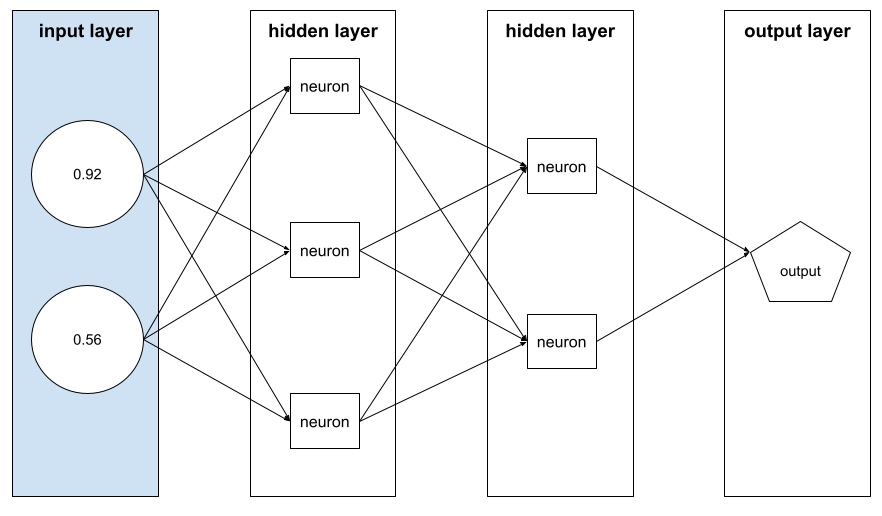
Cada exemplo fornece valores diferentes para o vetor de atributos. Portanto, o vetor de atributos do próximo exemplo pode ser algo como:
[0.73, 0.49]
A engenharia de atributos determina como representar atributos no vetor de atributos. Por exemplo, um atributo categórico binário com cinco valores possíveis pode ser representado com codificação one-hot. Nesse caso, a parte do vetor de recursos para um exemplo específico consistiria em quatro zeros e um único 1,0 na terceira posição, da seguinte forma:
[0.0, 0.0, 1.0, 0.0, 0.0]
Como outro exemplo, suponha que seu modelo consista em três recursos:
- um atributo categórico binário com cinco valores possíveis representados com codificação one-hot. Por exemplo:
[0.0, 1.0, 0.0, 0.0, 0.0] - outro atributo categórico binário com três valores possíveis representados
com codificação one-hot. Por exemplo:
[0.0, 0.0, 1.0] - um recurso de ponto flutuante, por exemplo:
8.3.
Nesse caso, o vetor de atributos de cada exemplo seria representado por nove valores. Considerando os valores de exemplo na lista anterior, o vetor de recursos seria:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Consulte Dados numéricos: como um modelo ingere dados usando vetores de recursos no Curso intensivo de machine learning para mais informações.
ciclo de feedback
Em machine learning, uma situação em que as previsões de um modelo influenciam os dados de treinamento do mesmo modelo ou de outro. Por exemplo, um modelo que recomenda filmes influencia os filmes que as pessoas assistem, o que, por sua vez, influencia os modelos de recomendação de filmes subsequentes.
Consulte Sistemas de ML de produção: perguntas a fazer no Curso intensivo de machine learning para mais informações.
G
generalização
A capacidade de um modelo de fazer previsões corretas sobre dados novos e nunca vistos antes. Um modelo que pode generalizar é o oposto de um modelo que está overfitting.
Consulte Generalização no Curso intensivo de machine learning para mais informações.
curva de generalização
Um gráfico da perda de treinamento e da perda de validação como uma função do número de iterações.
Uma curva de generalização pode ajudar a detectar possível overfitting. Por exemplo, a curva de generalização a seguir sugere overfitting porque a perda de validação acaba se tornando significativamente maior do que a perda de treinamento.
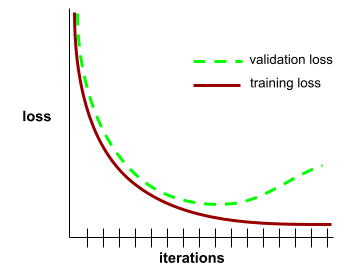
Consulte Generalização no Curso intensivo de machine learning para mais informações.
gradiente descendente
Uma técnica matemática para minimizar a perda. O gradiente descendente ajusta iterativamente os pesos e os vieses, encontrando gradualmente a melhor combinação para minimizar a perda.
O gradiente descendente é muito mais antigo que o aprendizado de máquina.
Consulte Regressão linear: gradiente descendente no Curso intensivo de machine learning para mais informações.
informações empíricas
Realidade.
O que realmente aconteceu.
Por exemplo, considere um modelo de classificação binária que prevê se um estudante do primeiro ano da universidade vai se formar em até seis anos. A verdade fundamental para esse modelo é se o estudante se formou ou não em seis anos.
H
camada escondida
Uma camada em uma rede neural entre a camada de entrada (os recursos) e a camada final (a previsão). Cada camada escondida consiste em um ou mais neurônios. Por exemplo, a rede neural a seguir contém duas camadas ocultas, a primeira com três neurônios e a segunda com dois:
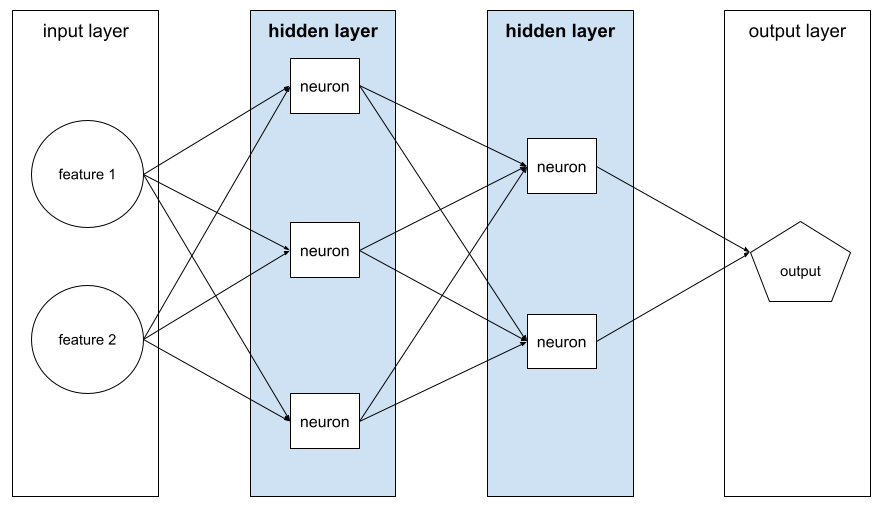
Uma rede neural profunda contém mais de uma camada escondida. Por exemplo, a ilustração anterior é uma rede neural profunda porque o modelo contém duas camadas ocultas.
Consulte Redes neurais: nós e camadas ocultas no Curso intensivo de machine learning para mais informações.
hiperparâmetro
As variáveis que você ou um serviço de ajuste de hiperparâmetros ajustam durante execuções sucessivas de treinamento de um modelo. Por exemplo, a taxa de aprendizado é um hiperparâmetro. Você pode definir a taxa de aprendizado como 0,01 antes de uma sessão de treinamento. Se você determinar que 0,01 é muito alto, talvez defina a taxa de aprendizado como 0,003 para a próxima sessão de treinamento.
Já os parâmetros são os vários pesos e vieses que o modelo aprende durante o treinamento.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
I
independente e identicamente distribuído (i.i.d)
Dados extraídos de uma distribuição que não muda e em que cada valor extraído não depende de valores extraídos anteriormente. Uma variável i.i.d. é o gás ideal do aprendizado de máquina: uma construção matemática útil, mas quase nunca encontrada exatamente no mundo real. Por exemplo, a distribuição de visitantes em uma página da Web pode ser i.i.d. em um breve período. Ou seja, a distribuição não muda durante esse período, e a visita de uma pessoa é geralmente independente da visita de outra. No entanto, se você ampliar esse período, poderão aparecer diferenças sazonais nos visitantes da página da Web.
Consulte também não estacionariedade.
inferência
No machine learning tradicional, o processo de fazer previsões aplicando um modelo treinado a exemplos sem rótulo. Consulte Aprendizado supervisionado no curso "Introdução ao ML" para saber mais.
Em modelos de linguagem grandes, a inferência é o processo de usar um modelo treinado para gerar uma resposta a um comando.
A inferência tem um significado um pouco diferente em estatística. Consulte o artigo da Wikipédia sobre inferência estatística para mais detalhes.
camada de entrada
A camada de uma rede neural que contém o vetor de atributos. Ou seja, a camada de entrada fornece exemplos para treinamento ou inferência. Por exemplo, a camada de entrada na rede neural a seguir consiste em dois recursos:
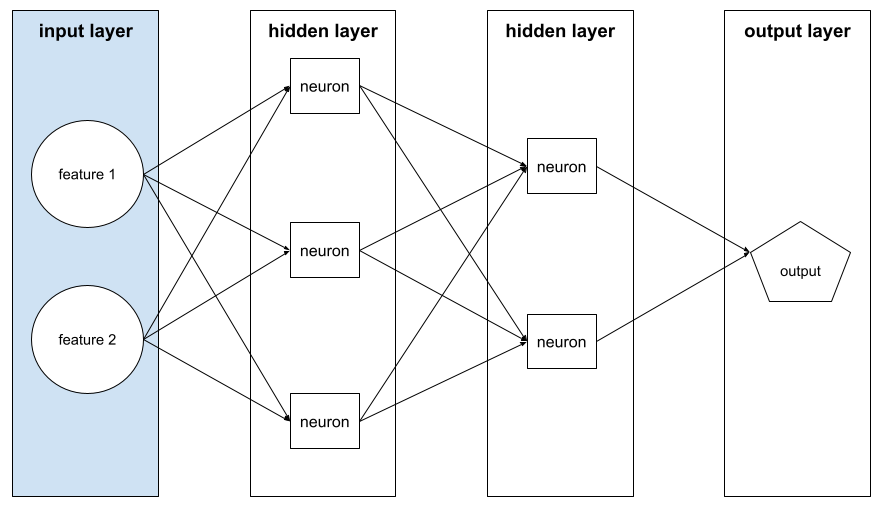
interpretabilidade
A capacidade de explicar ou apresentar o raciocínio de um modelo de ML em termos compreensíveis para as pessoas.
A maioria dos modelos de regressão linear, por exemplo, é altamente interpretável. Basta observar os pesos treinados para cada recurso. As florestas de decisão também são altamente interpretáveis. Porém, alguns modelos precisam de uma visualização sofisticada para se tornarem interpretáveis.
Você pode usar a Ferramenta de aprendizado de interpretabilidade (LIT) para interpretar modelos de ML.
iteração
Uma única atualização dos parâmetros de um modelo (os pesos e vieses do modelo) durante o treinamento. O tamanho do lote determina quantos exemplos o modelo processa em uma única iteração. Por exemplo, se o tamanho do lote for 20, o modelo vai processar 20 exemplos antes de ajustar os parâmetros.
Ao treinar uma rede neural, uma única iteração envolve as duas transmissões a seguir:
- Uma transmissão direta para avaliar a perda em um único lote.
- Uma transmissão de volta (backpropagation) para ajustar os parâmetros do modelo com base na perda e na taxa de aprendizado.
Consulte Descida de gradiente no Curso intensivo de machine learning para mais informações.
L
Regularização L0
Um tipo de regularização que penaliza o número total de ponderações diferentes de zero em um modelo. Por exemplo, um modelo com 11 pesos diferentes de zero seria mais penalizado do que um modelo semelhante com 10 pesos diferentes de zero.
A regularização L0 às vezes é chamada de regularização da norma L0.
Perda L1
Uma função de perda que calcula o valor absoluto da diferença entre os valores reais de rótulo e os valores previstos por um modelo. Por exemplo, este é o cálculo da perda L1 para um lote de cinco exemplos:
| Valor real do exemplo | Valor previsto do modelo | Valor absoluto de delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = perda L1 | ||
A perda L1 é menos sensível a outliers do que a perda L2.
O erro médio absoluto é a perda média L1 por exemplo.
Consulte Regressão linear: perda no Curso intensivo de machine learning para mais informações.
Regularização L1
Um tipo de regularização que penaliza ponderações na proporção à soma do valor absoluto das ponderações. A regularização L1 ajuda a levar os pesos de atributos irrelevantes ou pouco relevantes para exatamente 0. Um atributo com um peso de 0 é removido do modelo.
Contraste com a regularização L2.
Perda L2
Uma função de perda que calcula o quadrado da diferença entre os valores reais de rótulo e os valores previstos por um modelo. Por exemplo, este é o cálculo da perda L2 para um lote de cinco exemplos:
| Valor real do exemplo | Valor previsto do modelo | Quadrado de delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = perda L2 | ||
Devido ao uso de quadrados, a perda L2 aumenta a influência de outliers. Ou seja, a perda L2 reage mais fortemente a previsões ruins do que a perda L1. Por exemplo, a perda L1 para o lote anterior seria 8 em vez de 16. Uma única conta atípica representa 9 das 16.
Modelos de regressão geralmente usam a perda L2 como função de perda.
O erro quadrático médio é a perda média de L2 por exemplo. Perda quadrática é outro nome para perda L2.
Consulte Regressão logística: perda e regularização no Curso intensivo de machine learning para mais informações.
Regularização L2
Um tipo de regularização que penaliza ponderações na proporção à soma dos quadrados das ponderações. A regularização L2 ajuda a aproximar de zero os pesos outliers (aqueles com valores positivos altos ou negativos baixos), mas não exatamente zero. Os recursos com valores muito próximos de 0 permanecem no modelo, mas não influenciam muito a previsão dele.
A regularização L2 sempre melhora a generalização em modelos lineares.
Contraste com a regularização L1.
Consulte Overfitting: regularização L2 no Curso intensivo de machine learning para mais informações.
o rótulo.
Em machine learning supervisionado, a parte "resposta" ou "resultado" de um exemplo.
Cada exemplo rotulado consiste em um ou mais atributos e um rótulo. Por exemplo, em um conjunto de dados de detecção de spam, o rótulo provavelmente seria "spam" ou "não spam". Em um conjunto de dados de precipitação, o rótulo pode ser a quantidade de chuva que caiu durante um determinado período.
Consulte Aprendizado supervisionado em "Introdução ao machine learning" para mais informações.
exemplo rotulado
Um exemplo que contém um ou mais atributos e um rótulo. Por exemplo, a tabela a seguir mostra três exemplos rotulados de um modelo de avaliação de imóveis, cada um com três recursos e um rótulo:
| Número de quartos | Número de banheiros | Idade da casa | Preço da casa (rótulo) |
|---|---|---|---|
| 3 | 2 | 15 | US$ 345.000 |
| 2 | 1 | 72 | US$ 179.000 |
| 4 | 2 | 34 | US$ 392.000 |
No machine learning supervisionado, os modelos são treinados com exemplos rotulados e fazem previsões com exemplos sem rótulo.
Contraste exemplos rotulados com exemplos não rotulados.
Consulte Aprendizado supervisionado em "Introdução ao machine learning" para mais informações.
lambda
Sinônimo de taxa de regularização.
Lambda é um termo sobrecarregado. Aqui, estamos nos concentrando na definição do termo em regularização.
layer
Um conjunto de neurônios em uma rede neural. Confira três tipos comuns de camadas:
- A camada de entrada, que fornece valores para todos os recursos.
- Uma ou mais camadas ocultas, que encontram relações não lineares entre os atributos e o rótulo.
- A camada final, que fornece a previsão.
Por exemplo, a ilustração a seguir mostra uma rede neural com uma camada de entrada, duas camadas ocultas e uma camada final:

No TensorFlow, as camadas também são funções Python que recebem tensores e opções de configuração como entrada e produzem outros tensores como saída.
taxa de aprendizado
Um número de usar pontos flutuantes que informa ao algoritmo de gradiente descendente a intensidade com que ajustar pesos e vieses em cada iteração. Por exemplo, uma taxa de aprendizado de 0,3 ajustaria os pesos e os vieses três vezes mais do que uma taxa de 0,1.
A taxa de aprendizado é um hiperparâmetro fundamental. Se você definir a taxa de aprendizado muito baixa, o treinamento vai levar muito tempo. Se você definir uma taxa de aprendizado muito alta, o gradiente descendente terá dificuldade em alcançar a convergência.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
linear
Uma relação entre duas ou mais variáveis que pode ser representada apenas por adição e multiplicação.
O gráfico de uma relação linear é uma linha.
Contraste com não linear.
modelo linear
Um modelo que atribui um peso por atributo para fazer previsões. Os modelos lineares também incorporam um vies. Em contraste, a relação entre recursos e previsões em modelos profundos geralmente é não linear.
Os modelos lineares geralmente são mais fáceis de treinar e mais interpretáveis do que os modelos de aprendizado profundo. No entanto, os modelos profundos podem aprender relações complexas entre atributos.
A regressão linear e a regressão logística são dois tipos de modelos lineares.
regressão linear
Um tipo de modelo de machine learning em que as duas condições a seguir são verdadeiras:
- O modelo é linear.
- A previsão é um valor de ponto flutuante. Essa é a parte de regressão da regressão linear.
Compare a regressão linear com a regressão logística. Além disso, compare a regressão de contraste com a classificação.
Consulte Regressão linear no Curso intensivo de machine learning para mais informações.
regressão logística
Um tipo de modelo de regressão que prevê uma probabilidade. Os modelos de regressão logística têm as seguintes características:
- O rótulo é categórico. O termo regressão logística geralmente se refere à regressão logística binária, ou seja, a um modelo que calcula probabilidades para rótulos com dois valores possíveis. Uma variante menos comum, a regressão logística multinomial, calcula probabilidades para rótulos com mais de dois valores possíveis.
- A função de perda durante o treinamento é a Log Perda. Várias unidades de perda de entropia podem ser colocadas em paralelo para rótulos com mais de dois valores possíveis.
- O modelo tem uma arquitetura linear, não uma rede neural profunda. No entanto, o restante dessa definição também se aplica a modelos profundos que preveem probabilidades para rótulos categóricos.
Por exemplo, considere um modelo de regressão logística que calcula a probabilidade de um e-mail de entrada ser spam ou não. Durante a inferência, suponha que o modelo preveja 0,72. Portanto, o modelo está estimando:
- Uma chance de 72% de o e-mail ser spam.
- Uma chance de 28% de o e-mail não ser spam.
Um modelo de regressão logística usa a seguinte arquitetura de duas etapas:
- O modelo gera uma previsão bruta (y') aplicando uma função linear de atributos de entrada.
- O modelo usa essa previsão bruta como entrada para uma função sigmoide, que converte a previsão bruta em um valor entre 0 e 1, exclusivo.
Como qualquer modelo de regressão, um modelo de regressão logística prevê um número. No entanto, esse número geralmente faz parte de um modelo de classificação binária da seguinte forma:
- Se o número previsto for maior que o limite de classificação, o modelo de classificação binária vai prever a classe positiva.
- Se o número previsto for menor que o limite de classificação, o modelo de classificação binária vai prever a classe negativa.
Consulte Regressão logística no Curso intensivo de machine learning para mais informações.
Log Perda
A função de perda usada na regressão logística binária.
Consulte Regressão logística: perda e regularização no Curso intensivo de machine learning para mais informações.
log-odds
O logaritmo de probabilidades de algum evento.
perda
Durante o treinamento de um modelo supervisionado, uma medida de quanto uma previsão do modelo se distancia do rótulo.
Uma função de perda calcula a perda.
Consulte Regressão linear: perda no Curso intensivo de machine learning para mais informações.
curva de perda
Um gráfico da perda como uma função do número de iterações de treinamento. O gráfico a seguir mostra uma curva de perda típica:
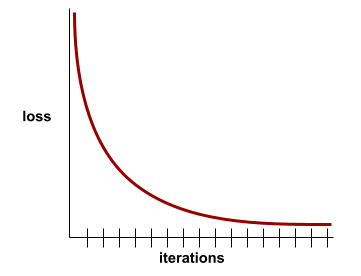
As curvas de perda ajudam a determinar quando o modelo está converging ou overfitting.
As curvas de perda podem representar todos os seguintes tipos de perda:
Consulte também a curva de generalização.
Consulte Overfitting: interpretando curvas de perda no Curso intensivo de machine learning para mais informações.
função de perda
Durante o treinamento ou teste, uma função matemática que calcula a perda em um lote de exemplos. Uma função de perda retorna uma perda menor para modelos que fazem boas previsões do que para modelos que fazem previsões ruins.
O objetivo do treinamento geralmente é minimizar a perda retornada por uma função de perda.
Existem muitos tipos diferentes de funções de perda. Escolha a função de perda adequada para o tipo de modelo que você está criando. Exemplo:
- A perda L2 (ou erro quadrático médio) é a função de perda da regressão linear.
- A Log Perda é a função de perda para regressão logística.
M
machine learning
Um programa ou sistema que treina um modelo com base em dados de entrada. O modelo treinado pode fazer previsões úteis com dados novos (nunca acessados) coletados da mesma distribuição usada para treinamento dele.
O aprendizado de máquina também faz referência ao campo que estuda esses programas ou sistemas.
Consulte o curso Introdução ao machine learning para mais informações.
classe majoritária
O rótulo mais comum em um conjunto de dados não balanceado. Por exemplo, em um conjunto de dados com 99% de rótulos negativos e 1% de rótulos positivos, os rótulos negativos são a classe majoritária.
Contraste com a classe minoritária.
Consulte Conjuntos de dados: conjuntos de dados desequilibrados no Curso intensivo de machine learning para mais informações.
minilote
Um subconjunto pequeno e selecionado aleatoriamente de um lote processado em uma iteração. O tamanho do lote de um minilote geralmente fica entre 10 e 1.000 exemplos.
Por exemplo, suponha que o conjunto de treinamento inteiro (o lote completo) consista em 1.000 exemplos. Suponha também que você defina o tamanho do lote de cada minilote como 20. Portanto, cada iteração determina a perda em 20 exemplos aleatórios dos 1.000 e ajusta os pesos e vieses de acordo.
É muito mais eficiente calcular a perda em um minilote do que em todos os exemplos do lote completo.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
classe minoritária
O rótulo menos comum em um conjunto de dados não balanceado. Por exemplo, em um conjunto de dados com 99% de rótulos negativos e 1% de rótulos positivos, os rótulos positivos são a classe minoritária.
Contraste com a classe majoritária.
Consulte Conjuntos de dados: conjuntos de dados desequilibrados no Curso intensivo de machine learning para mais informações.
modelo
Em geral, qualquer construção matemática que processe dados de entrada e retorne uma saída. Em outras palavras, um modelo é o conjunto de parâmetros e a estrutura necessários para que um sistema faça previsões. No aprendizado de máquina supervisionado, um modelo usa um exemplo como entrada e infere uma previsão como saída. No machine learning supervisionado, os modelos são um pouco diferentes. Exemplo:
- Um modelo de regressão linear consiste em um conjunto de pesos e um bias.
- Um modelo de rede neural consiste em:
- Um conjunto de camadas ocultas, cada uma contendo um ou mais neurônios.
- Os pesos e o viés associados a cada neurônio.
- Um modelo de árvore de decisão consiste em:
- O formato da árvore, ou seja, o padrão em que as condições e as folhas estão conectadas.
- As condições e as folhas.
É possível salvar, restaurar ou fazer cópias de um modelo.
O aprendizado de máquina sem supervisão também gera modelos, geralmente uma função que pode mapear um exemplo de entrada para o cluster mais adequado.
classificação multiclasse
No aprendizado supervisionado, um problema de classificação em que o conjunto de dados contém mais de duas classes de rótulos. Por exemplo, os rótulos no conjunto de dados Iris precisam ser de uma das três classes a seguir:
- Iris setosa
- Iris virginica
- Iris versicolor
Um modelo treinado no conjunto de dados Iris que prevê o tipo de íris em novos exemplos está realizando uma classificação multiclasse.
Em contraste, os problemas de classificação que distinguem exatamente duas classes são modelos de classificação binária. Por exemplo, um modelo de e-mail que prevê spam ou não spam é um modelo de classificação binária.
Em problemas de clusterização, a classificação multiclasse se refere a mais de dois clusters.
Consulte Redes neurais: classificação multiclasse no Curso intensivo de machine learning para mais informações.
N
classe negativa
Na classificação binária, uma classe é chamada de positiva e a outra de negativa. A classe positiva é o objeto ou evento que o modelo está testando, e a classe negativa é a outra possibilidade. Exemplo:
- A classe negativa em um teste médico pode ser "sem tumor".
- A classe negativa em um modelo de classificação de e-mail pode ser "não é spam".
Contraste com a classe positiva.
do feedforward
Um modelo que contenha pelo menos uma camada escondida. Uma rede neural profunda é um tipo de rede neural que contém mais de uma camada escondida. Por exemplo, o diagrama a seguir mostra uma rede neural profunda com duas camadas ocultas.
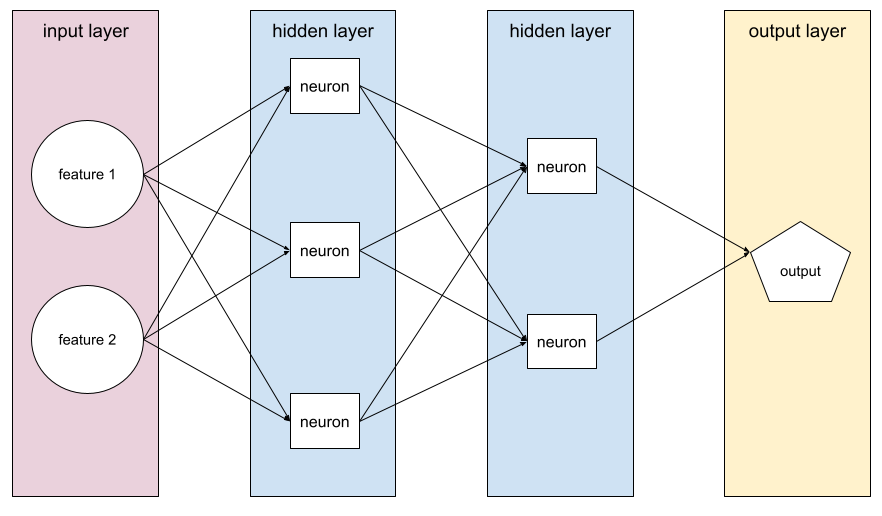
Cada neurônio em uma rede neural se conecta a todos os nós na próxima camada. Por exemplo, no diagrama anterior, observe que cada um dos três neurônios na primeira camada escondida se conecta separadamente aos dois neurônios na segunda camada escondida.
As redes neurais implementadas em computadores às vezes são chamadas de redes neurais artificiais para diferenciá-las das redes neurais encontradas em cérebros e outros sistemas nervosos.
Algumas redes neurais podem imitar relações não lineares extremamente complexas entre diferentes recursos e o rótulo.
Consulte também rede neural convolucional e rede neural recorrente.
Consulte Redes neurais no Curso intensivo de machine learning para mais informações.
neurônio
Em machine learning, uma unidade distinta em uma camada escondida de uma rede neural. Cada neurônio realiza as seguintes ações em duas etapas:
- Calcula a soma ponderada dos valores de entrada multiplicados pelos pesos correspondentes.
- Transmite a soma ponderada como entrada para uma função de ativação.
Um neurônio na primeira camada escondida aceita entradas dos valores de recursos na camada de entrada. Um neurônio em qualquer camada escondida além da primeira aceita entradas dos neurônios na camada escondida anterior. Por exemplo, um neurônio na segunda camada escondida aceita entradas dos neurônios na primeira camada escondida.
A ilustração a seguir destaca dois neurônios e as respectivas entradas.
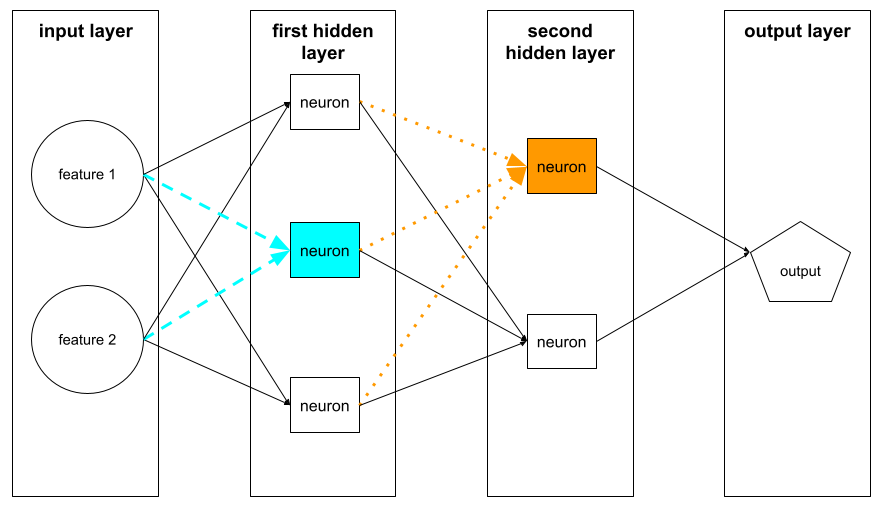
Um neurônio em uma rede neural imita o comportamento dos neurônios no cérebro e em outras partes do sistema nervoso.
nó (rede neural)
Um neurônio em uma camada escondida.
Consulte Redes neurais no Curso intensivo de machine learning para mais informações.
não linear
Uma relação entre duas ou mais variáveis que não pode ser representada apenas por adição e multiplicação. Uma relação linear pode ser representada como uma linha, mas uma relação não linear não. Por exemplo, considere dois modelos que relacionam um único atributo a um único rótulo. O modelo à esquerda é linear, e o modelo à direita é não linear:

Consulte Redes neurais: nós e camadas ocultas no Curso intensivo de machine learning para testar diferentes tipos de funções não lineares.
não estacionariedade
Uma característica cujos valores mudam em uma ou mais dimensões, geralmente o tempo. Por exemplo, considere os seguintes exemplos de não estacionariedade:
- O número de maiôs vendidos em uma loja específica varia de acordo com a estação.
- A quantidade de uma determinada fruta colhida em uma região específica é zero durante grande parte do ano, mas grande por um breve período.
- Devido às mudanças climáticas, as temperaturas médias anuais estão mudando.
Contraste com a estacionariedade.
normalização
Em termos gerais, o processo de conversão do intervalo real de valores de uma variável em um intervalo padrão, como:
- -1 a +1
- 0 a 1
- Valores Z (aproximadamente de -3 a +3)
Por exemplo, suponha que o intervalo real de valores de um determinado recurso seja de 800 a 2.400. Como parte da engenharia de recursos, é possível normalizar os valores reais para um intervalo padrão, como de -1 a +1.
A normalização é uma tarefa comum na engenharia de recursos. Normalmente, os modelos são treinados mais rápido (e produzem previsões melhores) quando cada atributo numérico no vetor de atributos tem aproximadamente o mesmo intervalo.
Consulte também Normalização de pontuação Z.
Consulte Dados numéricos: normalização no Curso intensivo de machine learning para mais informações.
dados numéricos
Atributos representados como números inteiros ou de valor real. Por exemplo, um modelo de avaliação de imóveis provavelmente representaria o tamanho de uma casa (em pés quadrados ou metros quadrados) como dados numéricos. Representar um atributo como dados numéricos indica que os valores do atributo têm uma relação matemática com o rótulo. Ou seja, o número de metros quadrados em uma casa provavelmente tem alguma relação matemática com o valor dela.
Nem todos os dados de números inteiros devem ser representados como dados numéricos. Por exemplo, os códigos postais em algumas partes do mundo são números inteiros. No entanto, eles não devem ser representados como dados numéricos em modelos. Isso porque um código postal de 20000 não é duas vezes (ou metade) tão potente quanto um código postal de 10000. Além disso, embora códigos postais diferentes sejam correlacionados a valores imobiliários diferentes, não podemos presumir que os valores imobiliários no código postal 20000 sejam duas vezes mais valiosos do que os valores imobiliários no código postal 10000.
Em vez disso, eles devem ser representados como dados categóricos.
Às vezes, os recursos numéricos são chamados de recursos contínuos.
Consulte Como trabalhar com dados numéricos no Curso intensivo de machine learning para mais informações.
O
off-line
Sinônimo de static.
inferência off-line
O processo de um modelo gerar um lote de previsões e depois armazenar em cache (salvar) essas previsões. Os apps podem acessar a previsão inferida do cache em vez de executar o modelo novamente.
Por exemplo, considere um modelo que gera previsões do tempo locais (previsões) a cada quatro horas. Depois de cada execução do modelo, o sistema armazena em cache todas as previsões do tempo locais. Os apps de clima recuperam as previsões do cache.
A inferência off-line também é chamada de inferência estática.
Contraste com a inferência on-line. Consulte Sistemas de ML de produção: inferência estática x dinâmica no Curso intensivo de machine learning para mais informações.
codificação one-hot
Representar dados categóricos como um vetor em que:
- Um elemento é definido como 1.
- Todos os outros elementos são definidos como 0.
A codificação one-hot é usada com frequência para representar strings ou identificadores que têm um conjunto finito de valores possíveis.
Por exemplo, suponha que um determinado recurso categórico chamado Scandinavia tenha cinco valores possíveis:
- "Dinamarca"
- "Suécia"
- "Noruega"
- "Finlândia"
- "Islândia"
A codificação one-hot pode representar cada um dos cinco valores da seguinte forma:
| País | Vetor | ||||
|---|---|---|---|---|---|
| "Dinamarca" | 1 | 0 | 0 | 0 | 0 |
| "Suécia" | 0 | 1 | 0 | 0 | 0 |
| "Noruega" | 0 | 0 | 1 | 0 | 0 |
| "Finlândia" | 0 | 0 | 0 | 1 | 0 |
| "Islândia" | 0 | 0 | 0 | 0 | 1 |
Graças à codificação one-hot, um modelo pode aprender diferentes conexões com base em cada um dos cinco países.
Representar um atributo como dados numéricos é uma alternativa à codificação one-hot. Infelizmente, representar os países escandinavos numericamente não é uma boa escolha. Por exemplo, considere a seguinte representação numérica:
- "Dinamarca" é 0
- "Suécia" é 1
- "Noruega" é 2
- "Finlândia" é 3
- "Islândia" é 4
Com a codificação numérica, um modelo interpretaria os números brutos matematicamente e tentaria treinar com eles. No entanto, a Islândia não é o dobro (ou metade) de algo em comparação com a Noruega, então o modelo chegaria a conclusões estranhas.
Consulte Dados categóricos: vocabulário e codificação one-hot no Curso intensivo de machine learning para mais informações.
um-contra-todos
Dado um problema de classificação com N classes, uma solução que consiste em N modelos separados de classificação binária, um para cada resultado possível. Por exemplo, considerando um modelo que classifica exemplos como animal, vegetal ou mineral, uma solução de um contra todos forneceria os três modelos de classificação binária separados a seguir:
- animal x não animal
- vegetal x não vegetal
- mineral x não mineral
on-line
Sinônimo de dynamic.
inferência on-line
Gerar previsões sob demanda. Por exemplo, suponha que um app transmita uma entrada para um modelo e emita uma solicitação de previsão. Um sistema que usa inferência on-line responde à solicitação executando o modelo e retornando a previsão ao app.
Contraste com a inferência off-line.
Consulte Sistemas de ML de produção: inferência estática x dinâmica no Curso intensivo de machine learning para mais informações.
camada final
A camada "final" de uma rede neural. A camada final contém a previsão.
A ilustração a seguir mostra uma pequena rede neural profunda com uma camada de entrada, duas camadas ocultas e uma camada final:
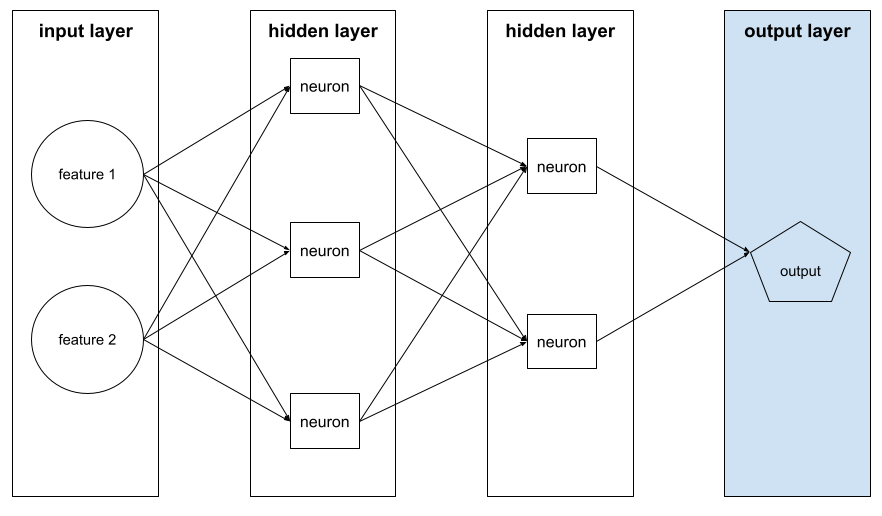
overfitting
Criar um modelo que corresponda aos dados de treinamento de forma tão próxima que não consiga fazer previsões corretas sobre novos dados.
A regularização pode reduzir o overfitting. O treinamento em um conjunto de treinamento grande e diversificado também pode reduzir o overfitting.
Consulte Overfitting no Curso intensivo de machine learning para mais informações.
P
pandas
Uma API de análise de dados orientada por colunas criada com base no numpy. Muitos frameworks de aprendizado de máquina, incluindo o TensorFlow, aceitam estruturas de dados do pandas como entradas. Consulte a documentação do pandas para mais detalhes.
parâmetro
Os pesos e vieses que um modelo aprende durante o treinamento. Por exemplo, em um modelo de regressão linear, os parâmetros consistem na tendência (b) e em todos os pesos (w1, w2 etc.) na seguinte fórmula:
Já os hiperparâmetros são os valores que você (ou um serviço de ajuste de hiperparâmetros) fornece ao modelo. Por exemplo, a taxa de aprendizado é um hiperparâmetro.
classe positiva
A classe que você está testando.
Por exemplo, a classe positiva em um modelo de câncer pode ser "tumor". A classe positiva em um modelo de classificação de e-mail pode ser "spam".
Contraste com a classe negativa.
pós-processamento
Ajustar a saída de um modelo depois que ele foi executado. O pós-processamento pode ser usado para aplicar restrições de justiça sem modificar os modelos.
Por exemplo, é possível aplicar pós-processamento a um modelo de classificação binária definindo um limiar de classificação para que a igualdade de oportunidades seja mantida para algum atributo. Para isso, verifique se a taxa de verdadeiro positivo é igual para todas os valores desse atributo.
precision
Uma métrica para modelos de classificação que responde à seguinte pergunta:
Quando o modelo previu a classe positiva, qual foi a porcentagem de previsões corretas?
Esta é a fórmula:
em que:
- verdadeiro positivo significa que o modelo previu corretamente a classe positiva.
- falso positivo significa que o modelo previu incorretamente a classe positiva.
Por exemplo, suponha que um modelo tenha feito 200 previsões positivas. Das 200 previsões positivas:
- 150 eram verdadeiros positivos.
- 50 eram falsos positivos.
Neste caso:
Contraste com acurácia e recall.
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas no Curso intensivo de machine learning para mais informações.
previsão
A saída de um modelo. Exemplo:
- A previsão de um modelo de classificação binária é a classe positiva ou a classe negativa.
- A previsão de um modelo de classificação multiclasse é uma classe.
- A previsão de um modelo de regressão linear é um número.
rotulação indireta
Dados usados para aproximar rótulos não disponíveis diretamente em um conjunto de dados.
Por exemplo, suponha que você precise treinar um modelo para prever o nível de estresse dos funcionários. Seu conjunto de dados tem muitos recursos preditivos, mas não tem um rótulo chamado nível de estresse. Sem se intimidar, você escolhe "acidentes de trabalho" como um rótulo substituto para o nível de estresse. Afinal, funcionários sob alto estresse sofrem mais acidentes do que funcionários tranquilos. Ou será que não? Talvez os acidentes de trabalho aumentem e diminuam por vários motivos.
Como segundo exemplo, suponha que você queira que está chovendo? seja um rótulo booleano para seu conjunto de dados, mas ele não contém dados de chuva. Se houver fotos disponíveis, você poderá estabelecer imagens de pessoas carregando guarda-chuvas como um rótulo substituto para está chovendo? Esse é um bom marcador indireto? Talvez, mas pessoas de algumas culturas podem ter mais probabilidade de carregar guarda-chuvas para se proteger do sol do que da chuva.
A rotulação indireta geralmente é imperfeita. Sempre que possível, escolha rótulos reais em vez de rotulação indireta. No entanto, quando um rótulo real está ausente, escolha o rótulo substituto com muito cuidado, selecionando o candidato menos ruim.
Consulte Conjuntos de dados: rótulos no Curso intensivo de machine learning para mais informações.
R
RAG
Abreviação de geração aumentada por recuperação.
rotulador
Uma pessoa que fornece rótulos para exemplos. "Anotador" é outro nome para avaliador.
Consulte Dados categóricos: problemas comuns no Curso intensivo de machine learning para mais informações.
recall
Uma métrica para modelos de classificação que responde à seguinte pergunta:
Quando a informação empírica era a classe positiva, qual porcentagem de previsões o modelo identificou corretamente como a classe positiva?
Esta é a fórmula:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
em que:
- verdadeiro positivo significa que o modelo previu corretamente a classe positiva.
- Um falso negativo significa que o modelo previu incorretamente a classe negativa.
Por exemplo, suponha que seu modelo tenha feito 200 previsões em exemplos para os quais a verdade fundamental era a classe positiva. Das 200 previsões:
- 180 eram verdadeiros positivos.
- 20 eram falsos negativos.
Neste caso:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Consulte Classificação: acurácia, recall, precisão e métricas relacionadas para mais informações.
Unidade linear retificada (ReLU)
Uma função de ativação com o seguinte comportamento:
- Se a entrada for negativa ou zero, a saída será 0.
- Se a entrada for positiva, a saída será igual à entrada.
Exemplo:
- Se a entrada for -3, a saída será 0.
- Se a entrada for +3, a saída será 3,0.
Confira um gráfico da ReLU:
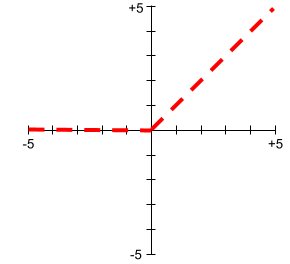
A ReLU é uma função de ativação muito conhecida. Apesar do comportamento simples, a ReLU ainda permite que uma rede neural aprenda relações não lineares entre atributos e o rótulo.
modelo de regressão
Informalmente, um modelo que gera uma previsão numérica. Em contraste, um modelo de classificação gera uma previsão de classe. Por exemplo, todos os modelos a seguir são de regressão:
- Um modelo que prevê o valor de uma determinada casa em euros, como 423.000.
- Um modelo que prevê a expectativa de vida de uma determinada árvore em anos, como 23,2.
- Um modelo que prevê a quantidade de chuva em polegadas que vai cair em uma cidade nas próximas seis horas, como 0,18.
Dois tipos comuns de modelos de regressão são:
- Regressão linear, que encontra a linha que melhor se ajusta aos valores de rótulo e aos recursos.
- Regressão logística, que gera uma probabilidade entre 0,0 e 1,0 que um sistema normalmente mapeia para uma previsão de classe.
Nem todo modelo que gera previsões numéricas é um modelo de regressão. Em alguns casos, uma previsão numérica é apenas um modelo de classificação que tem nomes de classes numéricos. Por exemplo, um modelo que prevê um código postal numérico é um modelo de classificação, não um modelo de regressão.
regularização
Qualquer mecanismo que reduza o overfitting. Os tipos mais usados de regularização incluem:
- Regularização L1
- Regularização de L2
- regularização por dropout
- parada antecipada: não é um método formal de regularização, mas pode limitar o overfitting de maneira eficaz.
A regularização também pode ser definida como a penalidade na complexidade de um modelo.
Consulte Overfitting: complexidade do modelo no Curso intensivo de machine learning para mais informações.
taxa de regularização
Um número que especifica a importância relativa da regularização durante o treinamento. Aumentar a taxa de regularização reduz o overfitting, mas pode diminuir o poder preditivo do modelo. Por outro lado, reduzir ou omitir a taxa de regularização aumenta o overfitting.
Consulte Overfitting: regularização L2 no Curso intensivo de machine learning para mais informações.
ReLU
Abreviação de Unidade Linear Retificada.
geração aumentada por recuperação (RAG)
Uma técnica para melhorar a qualidade da saída de um modelo de linguagem grande (LLM), embasando o resultado com fontes de conhecimento recuperadas após o treinamento do modelo. A RAG melhora a acurácia das respostas do LLM ao fornecer ao LLM treinado acesso a informações recuperadas de bases de conhecimento ou documentos confiáveis.
Alguns motivos comuns para usar a geração aumentada por recuperação:
- Aumentar a acurácia factual das respostas geradas por um modelo.
- Dar ao modelo acesso a conhecimentos com os quais ele não foi treinado.
- Mudar o conhecimento usado pelo modelo.
- Permitir que o modelo cite fontes.
Por exemplo, suponha que um app de química use a API PaLM para gerar resumos relacionados a consultas do usuário. Quando o back-end do app recebe uma consulta, ele:
- Pesquisa ("recupera") dados relevantes para a consulta do usuário.
- Adiciona ("aumenta") os dados de química relevantes à consulta do usuário.
- Instrui o LLM a criar um resumo com base nos dados anexados.
Curva ROC
Um gráfico da taxa de verdadeiro positivo em relação à taxa de falso positivo para diferentes limiares de classificação na classificação binária.
O formato de uma curva ROC sugere a capacidade de um modelo de classificação binária de separar classes positivas de negativas. Suponha, por exemplo, que um modelo de classificação binária separe perfeitamente todas as classes negativas de todas as classes positivas:

A curva ROC do modelo anterior é assim:

Em contraste, a ilustração a seguir mostra os valores brutos de regressão logística para um modelo ruim que não consegue separar classes negativas de positivas:
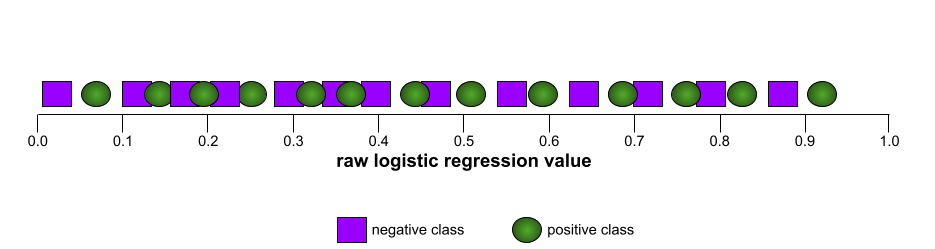
A curva ROC para esse modelo é assim:
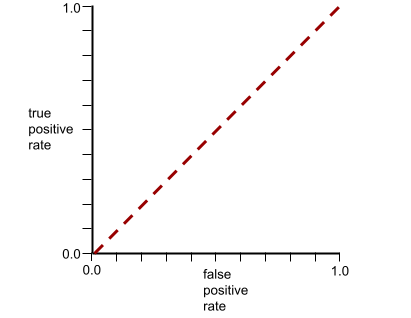
Enquanto isso, no mundo real, a maioria dos modelos de classificação binária separa as classes positivas e negativas até certo ponto, mas geralmente não de forma perfeita. Assim, uma curva ROC típica fica entre os dois extremos:
O ponto em uma curva ROC mais próximo de (0,0, 1,0) identifica teoricamente o limite de classificação ideal. No entanto, vários outros problemas do mundo real influenciam a seleção do limite de classificação ideal. Por exemplo, talvez os falsos negativos causem muito mais problemas do que os falsos positivos.
Uma métrica numérica chamada AUC resume a curva ROC em um único valor de ponto flutuante.
Raiz do erro quadrático médio (RMSE)
A raiz quadrada do erro quadrático médio.
S
função sigmoide
Uma função matemática que "comprime" um valor de entrada em um intervalo restrito, geralmente de 0 a 1 ou de -1 a +1. Ou seja, você pode transmitir qualquer número (dois, um milhão, um bilhão negativo, o que for) para uma sigmoide, e a saída ainda estará no intervalo restrito. Um gráfico da função de ativação sigmoide tem esta aparência:
A função sigmoide tem vários usos no aprendizado de máquina, incluindo:
- Converter a saída bruta de um modelo de regressão logística ou multinomial em uma probabilidade.
- Atuando como uma função de ativação em algumas redes neurais.
softmax
Uma função que determina probabilidades para cada classe possível em um modelo de classificação multiclasse. As probabilidades somam exatamente 1,0. Por exemplo, a tabela a seguir mostra como o softmax distribui várias probabilidades:
| A imagem é um(a)... | Probabilidade |
|---|---|
| cachorro | 0,85 |
| gato | .13 |
| cavalo | .02 |
A softmax também é chamada de softmax completa.
Contraste com a amostragem de candidatos.
Consulte Redes neurais: classificação multiclasse no Curso intensivo de machine learning para mais informações.
atributo esparso
Um atributo cujos valores são predominantemente zero ou vazios. Por exemplo, um recurso que contém um único valor 1 e um milhão de valores 0 é esparso. Por outro lado, um atributo denso tem valores que predominantemente não são zero nem vazios.
Em machine learning, um número surpreendente de atributos são esparsos. Os atributos categóricos geralmente são esparsos. Por exemplo, das 300 espécies de árvores possíveis em uma floresta, um único exemplo pode identificar apenas um bordo. Ou, dos milhões de vídeos possíveis em uma biblioteca, um único exemplo pode identificar apenas "Casablanca".
Em um modelo, geralmente representamos atributos esparsos com codificação one-hot. Se a codificação one-hot for grande, coloque uma camada de incorporação em cima dela para aumentar a eficiência.
representação esparsa
Armazenar apenas as posições de elementos diferentes de zero em um atributo esparso.
Por exemplo, suponha que um recurso categórico chamado species identifique as 36 espécies de árvores em uma floresta específica. Além disso, suponha que cada exemplo identifique apenas uma espécie.
Você pode usar um vetor one-hot para representar as espécies de árvores em cada exemplo.
Um vetor one-hot teria um único 1 (para representar a espécie de árvore específica no exemplo) e 35 0s (para representar as 35 espécies de árvores não incluídas no exemplo). Assim, a representação one-hot de maple pode ser semelhante a esta:

Como alternativa, a representação esparsa simplesmente identificaria a posição da espécie específica. Se maple estiver na posição 24, a representação esparsa de maple será simplesmente:
24
A representação esparsa é muito mais compacta do que a representação one-hot.
Clique no ícone para ver um exemplo um pouco mais complexo.
Suponha que cada exemplo no seu modelo precise representar as palavras, mas não a ordem delas, em uma frase em inglês. O inglês tem cerca de 170.000 palavras, então é um recurso categórico com aproximadamente 170.000 elementos. A maioria das frases em inglês usa uma fração extremamente pequena dessas 170.000 palavras. Portanto, o conjunto de palavras em um único exemplo quase certamente será de dados esparsos.
Considere a seguinte frase:
My dog is a great dog
Você pode usar uma variante de vetor one-hot para representar as palavras nesta frase. Nessa variante, várias células no vetor podem conter um valor diferente de zero. Além disso, nessa variante, uma célula pode conter um número inteiro diferente de um. Embora as palavras "my", "is", "a" e "great" apareçam apenas uma vez na frase, a palavra "dog" aparece duas vezes. Usar essa variante de vetores one-hot para representar as palavras nesta frase gera o seguinte vetor de 170.000 elementos:

Uma representação esparsa da mesma frase seria simplesmente:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Consulte Como trabalhar com dados categóricos no Curso intensivo de machine learning para mais informações.
vetor esparso
Um vetor com valores principalmente iguais a zero. Consulte também recurso esparso e esparsidade.
perda quadrática
Sinônimo de perda L2.
static
Algo feito uma vez em vez de continuamente. Os termos estático e off-line são sinônimos. Confira a seguir usos comuns de estático e off-line no aprendizado de máquina:
- Um modelo estático (ou modelo off-line) é treinado uma vez e usado por um tempo.
- O treinamento estático (ou treinamento off-line) é o processo de treinamento de um modelo estático.
- A inferência estática (ou inferência off-line) é um processo em que um modelo gera um lote de previsões por vez.
Contraste com dinâmico.
inferência estática
Sinônimo de inferência off-line.
estacionariedade
Um recurso cujos valores não mudam em uma ou mais dimensões, geralmente o tempo. Por exemplo, um recurso cujos valores parecem quase iguais em 2021 e 2023 apresenta estacionaridade.
No mundo real, pouquíssimos recursos apresentam estacionaridade. Até mesmo recursos sinônimos de estabilidade, como o nível do mar, mudam com o tempo.
Contraste com não estacionariedade.
gradiente descendente estocástico (GDE)
Um algoritmo de gradiente descendente em que o tamanho do lote é um. Em outras palavras, o SGD treina em um único exemplo escolhido de maneira uniforme e aleatória de um conjunto de treinamento.
Consulte Regressão linear: hiperparâmetros no Curso intensivo de machine learning para mais informações.
machine learning supervisionado
Treinar um modelo com base em atributos e os respectivos rótulos. O machine learning supervisionado é análogo a aprender um assunto estudando um conjunto de perguntas e respostas correspondentes. Depois de dominar a relação entre perguntas e respostas, um estudante pode responder a novas perguntas (nunca vistas antes) sobre o mesmo tema.
Compare com o machine learning sem supervisão.
Consulte Aprendizado supervisionado no curso "Introdução ao ML" para mais informações.
atributo sintético
Um atributo que não está presente entre os atributos de entrada, mas é montado com base em um ou mais deles. Os métodos para criar recursos sintéticos incluem:
- Agrupamento por classes de um atributo de valor contínuo em classes de intervalo.
- Criar um cruzamento de atributos.
- Multiplicar (ou dividir) um valor de atributo por outro(s) ou por si mesmo. Por exemplo, se
aebforem recursos de entrada, os seguintes serão exemplos de recursos sintéticos:- ab
- a2
- Aplicar uma função transcendental a um valor de recurso. Por exemplo, se
cfor um recurso de entrada, os seguintes serão exemplos de recursos sintéticos:- sin(c)
- ln(c)
Os atributos criados apenas por normalização ou escalonamento não são considerados sintéticos.
T
perda de teste
Uma métrica que representa a perda de um modelo em relação ao conjunto de teste. Ao criar um modelo, geralmente você tenta minimizar a perda de teste. Isso porque uma perda de teste baixa é um indicador de qualidade mais forte do que uma perda de treinamento ou validação baixa.
Uma grande diferença entre a perda de teste e a perda de treinamento ou validação às vezes sugere que você precisa aumentar a taxa de regularização.
treinamento
O processo de determinar os parâmetros (pesos e vieses) ideais que compõem um modelo. Durante o treinamento, um sistema lê exemplos e ajusta gradualmente os parâmetros. O treinamento usa cada exemplo de algumas vezes a bilhões de vezes.
Consulte Aprendizado supervisionado no curso "Introdução ao ML" para mais informações.
perda de treinamento
Uma métrica que representa a perda de um modelo durante uma iteração de treinamento específica. Por exemplo, suponha que a função de perda seja erro quadrático médio. Talvez a perda de treinamento (o erro quadrático médio) da 10ª iteração seja 2,2, e a perda de treinamento da 100ª iteração seja 1,9.
Uma curva de perda representa a perda de treinamento em relação ao número de iterações. Uma curva de perda fornece as seguintes dicas sobre o treinamento:
- Uma inclinação para baixo significa que o modelo está melhorando.
- Uma inclinação para cima significa que o modelo está piorando.
- Uma inclinação plana significa que o modelo atingiu a convergência.
Por exemplo, a curva de perda um pouco idealizada a seguir mostra:
- Uma inclinação acentuada para baixo durante as iterações iniciais, o que implica uma melhoria rápida do modelo.
- Uma inclinação gradualmente mais plana (mas ainda descendente) até perto do fim do treinamento, o que implica uma melhoria contínua do modelo em um ritmo um pouco mais lento do que durante as iterações iniciais.
- Uma inclinação plana no final do treinamento, o que sugere convergência.
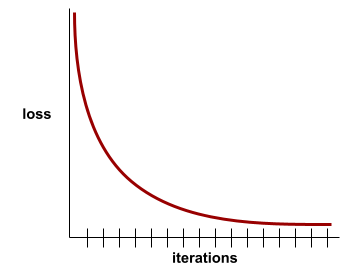
Embora a perda de treinamento seja importante, consulte também a generalização.
desvio entre treinamento e disponibilização
A diferença entre o desempenho de um modelo durante o treinamento e o desempenho do mesmo modelo durante a disponibilização.
conjunto de treinamento
O subconjunto do conjunto de dados usado para treinar um modelo.
Tradicionalmente, os exemplos no conjunto de dados são divididos nos três subconjuntos distintos a seguir:
- um conjunto de treinamento
- um conjunto de validação
- um conjunto de teste
O ideal é que cada exemplo no conjunto de dados pertença a apenas um dos subconjuntos anteriores. Por exemplo, um único exemplo não pode pertencer aos conjuntos de treinamento e validação.
Consulte Conjuntos de dados: dividindo o conjunto de dados original no Curso intensivo de machine learning para mais informações.
verdadeiro negativo (VN)
Um exemplo em que o modelo prevê corretamente a classe negativa. Por exemplo, o modelo deduz que uma determinada mensagem de e-mail não é spam, e essa mensagem realmente não é spam.
verdadeiro positivo (VP)
Um exemplo em que o modelo prevê corretamente a classe positiva. Por exemplo, o modelo infere que uma determinada mensagem de e-mail é spam, e ela realmente é.
taxa de verdadeiro positivo (TVP)
Sinônimo de recall. Ou seja:
A taxa de verdadeiro positivo é o eixo y em uma curva ROC.
U
underfitting
Produzir um modelo com capacidade preditiva ruim porque ele não capturou totalmente a complexidade dos dados de treinamento. Muitos problemas podem causar subajuste, incluindo:
- Treinamento com o conjunto errado de recursos.
- Treinar por poucas épocas ou com uma taxa de aprendizado muito baixa.
- Treinamento com uma taxa de regularização muito alta.
- Fornecer poucas camadas ocultas em uma rede neural profunda.
Consulte Overfitting no Curso intensivo de machine learning para mais informações.
exemplo não-rotulado
Um exemplo que contém atributos, mas nenhum rótulo. Por exemplo, a tabela a seguir mostra três exemplos não rotulados de um modelo de avaliação de imóveis, cada um com três recursos, mas sem valor da casa:
| Número de quartos | Número de banheiros | Idade da casa |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
No machine learning supervisionado, os modelos são treinados com exemplos rotulados e fazem previsões com exemplos sem rótulo.
No aprendizado semi-supervisionado e não supervisionado, exemplos sem rótulo são usados durante o treinamento.
Contraste um exemplo não-rotulado com um exemplo rotulado.
machine learning sem supervisão
Treinar um modelo para encontrar padrões em um conjunto de dados, geralmente um conjunto não rotulado.
O uso mais comum do aprendizado de máquina sem supervisão é agrupar dados em grupos de exemplos semelhantes. Por exemplo, um algoritmo de aprendizado de máquina não supervisionado pode agrupar músicas com base em várias propriedades da música. Os clusters resultantes podem se tornar uma entrada para outros algoritmos de aprendizado de máquina (por exemplo, para um serviço de recomendação de músicas). O clustering pode ajudar quando os rótulos úteis são escassos ou ausentes. Por exemplo, em domínios como combate a abusos e fraudes, os clusters podem ajudar as pessoas a entender melhor os dados.
Contraste com o aprendizado de máquina supervisionado.
Consulte O que é machine learning? no curso de introdução ao ML para mais informações.
V
validação
A avaliação inicial da qualidade de um modelo. A validação verifica a qualidade das previsões de um modelo em relação ao conjunto de validação.
Como o conjunto de validação é diferente do conjunto de treinamento, a validação ajuda a evitar o overfitting.
Pense na avaliação do modelo em relação ao conjunto de validação como a primeira rodada de testes e na avaliação do modelo em relação ao conjunto de teste como a segunda rodada.
perda de validação
Uma métrica que representa a perda de um modelo no conjunto de validação durante uma iteração específica do treinamento.
Consulte também a curva de generalização.
conjunto de validação
O subconjunto do conjunto de dados que realiza a avaliação inicial em relação a um modelo treinado. Normalmente, você avalia o modelo treinado em relação ao conjunto de validação várias vezes antes de avaliar o modelo em relação ao conjunto de teste.
Tradicionalmente, você divide os exemplos no conjunto de dados nos três subconjuntos distintos a seguir:
- um conjunto de treinamento
- um conjunto de validação
- um conjunto de teste
O ideal é que cada exemplo no conjunto de dados pertença a apenas um dos subconjuntos anteriores. Por exemplo, um único exemplo não pode pertencer aos conjuntos de treinamento e validação.
Consulte Conjuntos de dados: dividindo o conjunto de dados original no Curso intensivo de machine learning para mais informações.
W
peso
Um valor que um modelo multiplica por outro valor. O treinamento é o processo de determinar os pesos ideais de um modelo. A inferência é o processo de usar esses pesos aprendidos para fazer previsões.
Consulte Regressão linear no Curso intensivo de machine learning para mais informações.
soma de pesos
A soma de todos os valores de entrada relevantes multiplicados pelos pesos correspondentes. Por exemplo, suponha que as entradas relevantes consistam no seguinte:
| valor de entrada | peso de entrada |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
Portanto, a soma ponderada é:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Uma soma ponderada é o argumento de entrada de uma função de ativação.
Z
Normalização de valor Z
Uma técnica de dimensionamento que substitui um valor bruto de recurso por um valor de usar pontos flutuantes que representa o número de desvios padrão da média desse recurso. Por exemplo, considere um recurso cuja média é 800 e o desvio padrão é 100. A tabela a seguir mostra como a normalização por pontuação Z mapearia o valor bruto para a pontuação Z:
| Valor bruto | Valor Z |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
O modelo de machine learning é treinado nos escores Z desse recurso em vez dos valores brutos.
Consulte Dados numéricos: normalização no Curso intensivo de machine learning para mais informações.