Découvrez comment Google a développé un modèle de classification d'images à la pointe de la technologie pour la recherche Google Photos. Suivez un cours d'initiation aux réseaux de neurones convolutifs, puis créez votre propre classificateur d'images pour distinguer les photos de chats des photos de chiens.
Prérequis
Cours d'initiation au Machine Learning ou expérience équivalente avec les principes de base du ML
Maîtrise des bases de la programmation et expérience en codage en Python
Introduction
En mai 2013, Google a lancé la recherche de photos personnelles, qui permet aux utilisateurs de récupérer des photos dans leurs bibliothèques en fonction des objets présents dans ces images.
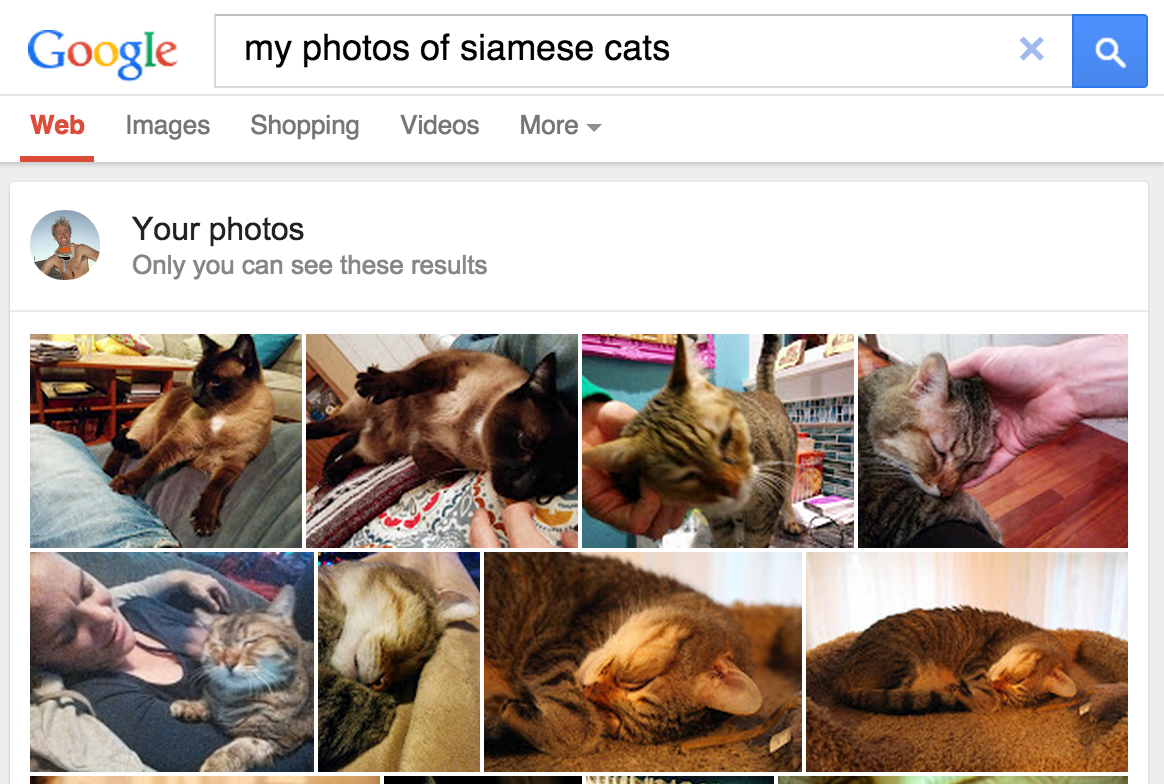 Figure 1. Google Photos lance une recherche sur "chats siamois" !
Figure 1. Google Photos lance une recherche sur "chats siamois" !
La fonctionnalité, intégrée ultérieurement dans Google Photos en 2015, a été largement perçue comme révolutionnaire, une preuve que les logiciels de vision par ordinateur pouvaient classer des images selon les normes humaines, en ajoutant de la valeur de plusieurs manières:
- Les utilisateurs n'avaient plus besoin d'étiqueter les photos avec des libellés tels que "plage" pour catégoriser le contenu des images, éliminant ainsi une tâche manuelle qui pouvait devenir fastidieuse lors de la gestion d'ensembles de centaines ou de milliers d'images.
- Les utilisateurs pouvaient explorer leur collection de nouvelles façons en utilisant des termes de recherche pour localiser des photos contenant des objets qu'ils n'auraient peut-être jamais tagués. Par exemple, ils peuvent rechercher "palmier" pour afficher toutes leurs photos de vacances avec des palmiers en arrière-plan.
- Le logiciel pourrait "voir" les distinctions taxinomiques que les utilisateurs finaux eux-mêmes pourraient ne pas percevoir (par exemple, distinguer les chats siamois et abyssins), améliorant ainsi efficacement les connaissances des utilisateurs sur le domaine.
Fonctionnement de la classification d'images
La classification d'images est un problème d'apprentissage supervisé: définissez un ensemble de classes cibles (objets à identifier dans les images) et entraînez un modèle à les reconnaître à l'aide d'exemples de photos étiquetées. Les premiers modèles de vision par ordinateur s'appuyaient sur les données de pixels brutes en entrée. Toutefois, comme le montre la figure 2, les données de pixels brutes seules ne fournissent pas une représentation suffisamment stable pour couvrir les innombrables variantes d'un objet capturées dans une image. La position de l'objet, l'arrière-plan derrière l'objet, l'éclairage ambiant, l'angle de la caméra et la mise au point peuvent fluctuer dans les données de pixels bruts. Ces différences sont suffisamment importantes pour ne pas pouvoir être corrigées en prenant des moyennes pondérées des valeurs de RVB en pixels.
 Figure 2. À gauche: les chats peuvent être photographiés dans différentes postures, avec différents arrière-plans et conditions d'éclairage. À droite: calculer la moyenne des données de pixels pour prendre en compte cette variété ne génère aucune information significative.
Figure 2. À gauche: les chats peuvent être photographiés dans différentes postures, avec différents arrière-plans et conditions d'éclairage. À droite: calculer la moyenne des données de pixels pour prendre en compte cette variété ne génère aucune information significative.
Pour modéliser les objets de manière plus flexible, les modèles classiques de vision par ordinateur ont ajouté de nouvelles caractéristiques dérivées des données de pixels, telles que les histogrammes de couleur, les textures et les formes. L'inconvénient de cette approche était que l'extraction de caractéristiques devenait un véritable calvaire en raison du nombre important d'entrées à modifier. Pour un classificateur de chats, quelles couleurs étaient les plus pertinentes ? Les définitions de formes doivent-elles être flexibles ? Comme les caractéristiques devaient être ajustées avec précision, la création de modèles robustes était assez difficile, et la précision en souffrait.