Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
フィードバックを送信
理解度を確認する
コレクションでコンテンツを整理
必要に応じて、コンテンツの保存と分類を行います。
以下の質問は、ML のコアコンセプトの理解を深めるのに役立ちます。
予測力
教師あり ML モデルは、ラベル付きの例を含むデータセットを使用してトレーニングされます。モデルは、特徴からラベルを予測する方法を学習します。ただし、データセット内のすべての特徴に予測力があるわけではありません。場合によっては、ラベルの
予測子として機能する特徴はごくわずかです。以下のデータセットでは、価格をラベルとして使用し
残りの列を特徴として使用します。
車の価格を最も予測できる可能性が高い特徴を 3 つ選択してください。
Make_model、year、miles。
車のメーカー/モデル、年式、走行距離は、車の価格を最も予測できる可能性が高い特徴です。
Color、height、make_model。
車の高さと色は、車の価格を予測するのに適した特徴ではありません。
Miles、gearbox、make_model。
ギアボックスは、価格の主な予測子ではありません。
Tire_size、wheel_base、year。
タイヤサイズとホイールベースは、車の価格を予測するのに適した特徴ではありません。
教師あり学習と教師なし学習
問題に応じて、教師ありアプローチまたは教師なしアプローチを使用します。
たとえば、予測する値やカテゴリが事前にわかっている場合は、
教師あり学習を使用します。ただし、データセットに
関連する例のセグメンテーションやグループ化が含まれているかどうかを確認する場合は、
教師なし学習を使用します。
オンライン ショッピング ウェブサイトのユーザーのデータセットがあり、それには
次の列が含まれているとします。
サイトにアクセスするユーザーのタイプを把握するには、
教師あり学習と教師なし学習のどちらを使用しますか?
教師なし学習。
モデルに関連する顧客のグループをクラスタリングする必要があるため、
教師なし学習を使用します。モデルがユーザーをクラスタリングしたら、
各クラスタに「割引を求める人」、「お得な情報を探す人」、「サーファー」、「ロイヤル」、「放浪者」などの名前を付けます。
教師あり学習。ユーザーが属するクラス
を予測しようとしているため。
教師あり学習では、データセットに予測するラベルが含まれている必要があります。データセットには、ユーザーのカテゴリを参照するラベルはありません。
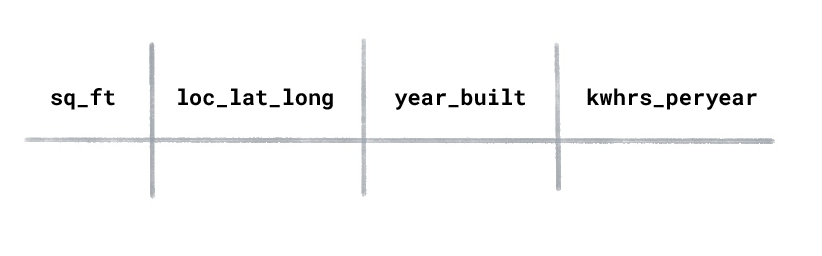
次の列を含む住宅のエネルギー使用量データセットがあるとします。
新築住宅の年間使用電力量(キロワット時)を予測するには、どのような ML を使用しますか?
教師あり学習。
教師あり学習は、ラベル付きの例でトレーニングされます。このデータセットでは、
「年間使用電力量」がラベルになります。これは、
モデルに予測させる値であるためです。特徴は、
「面積」、「場所」、「築年数」になります。
教師なし学習。
教師なし学習では、ラベルなしの例を使用します。この例では、
「年間使用電力量」がラベルになります。これは、
モデルに予測させる値であるためです。
次の列を含むフライト データセットがあるとします。
飛行機のチケットの費用を予測する場合は、
回帰と分類のどちらを使用しますか?
分類
分類モデルの出力は離散値(
通常は単語)です。この場合、飛行機のチケットの費用は
数値です。
データセットに基づいて、飛行機のチケットの費用を
「高」、「平均」、「低」に分類する分類モデルをトレーニングできますか?
はい。ただし、最初に
airplane_ticket_cost 列の数値をカテゴリ値に変換する必要があります。
データセットから分類モデルを作成できます。
次のような操作を行います。
出発空港から
目的地の空港までのチケットの平均費用を調べます。
「高」、「平均」、「低」を構成するしきい値を決定します。
予測費用をしきい値と比較し、値が該当するカテゴリを出力します。
いいえ。分類モデルを作成することはできません。
の値はカテゴリではなく数値です。airplane_ticket_cost
少し手間をかければ、分類
モデルを作成できます。
いいえ。分類モデルは、
spam または not_spam など、2 つのカテゴリのみを予測します。このモデルでは、
3 つのカテゴリを予測する必要があります。
分類モデルは複数のカテゴリを予測できます。これらは
マルチクラス分類モデルと呼ばれます。
トレーニングと評価
モデルをトレーニングしたら、
ラベル付きの例を含むデータセットを使用してモデルを評価し、モデルの予測値をラベルの
実際の値と比較します。
この質問に対する最適な回答を 2 つ選択してください。
モデルの予測が大きく外れている場合、予測を改善するにはどうすればよいですか?
モデルを再トレーニングしますが、ラベルの予測力が最も高いと思われる特徴のみを使用します。
特徴の数を減らして予測力を高めてモデルを再トレーニングすると、より正確な予測を行うモデルを作成できます。
予測が大きく外れているモデルを修正することはできません。
予測が外れているモデルを修正することは可能です。ほとんどのモデルでは、有用な予測を行うまで複数回
のトレーニングが必要です。
より大規模で多様なデータセットを使用してモデルを再トレーニングします。
より多くの例と幅広い値を含むデータセットでトレーニングされたモデルは、特徴とラベルの関係に対する汎化されたソリューションが優れているため、より正確な予測を行うことができます。
別のトレーニング アプローチを試します。たとえば、教師ありアプローチを使用した場合は、教師なしアプローチを試します。
別のトレーニング アプローチでは、より正確な予測を行うことはできません。
これで、ML の次のステップに進む準備ができました。
フィードバックを送信
特に記載のない限り、このページのコンテンツはクリエイティブ・コモンズの表示 4.0 ライセンス により使用許諾されます。コードサンプルは Apache 2.0 ライセンス により使用許諾されます。詳しくは、Google Developers サイトのポリシー をご覧ください。Java は Oracle および関連会社の登録商標です。
最終更新日 2026-01-05 UTC。
ご意見をお聞かせください
[[["わかりやすい","easyToUnderstand","thumb-up"],["問題の解決に役立った","solvedMyProblem","thumb-up"],["その他","otherUp","thumb-up"]],[["必要な情報がない","missingTheInformationINeed","thumb-down"],["複雑すぎる / 手順が多すぎる","tooComplicatedTooManySteps","thumb-down"],["最新ではない","outOfDate","thumb-down"],["翻訳に関する問題","translationIssue","thumb-down"],["サンプル / コードに問題がある","samplesCodeIssue","thumb-down"],["その他","otherDown","thumb-down"]],["最終更新日 2026-01-05 UTC。"],[],[]]