教師あり学習のタスクは明確に定義されており、スパムの特定や降水量の予測など、さまざまなシナリオに適用できます。
教師あり学習の基本コンセプト
教師あり ML は、次のコアコンセプトに基づいています。
- データ
- モデル
- トレーニング
- 評価
- 推論
データ
データは ML の原動力です。データは、テーブルに保存された単語や数値の形式で提供されるか、画像や音声ファイルでキャプチャされたピクセルや波形の値として提供されます。関連データはデータセットに保存されます。たとえば、次のようなデータセットがあるとします。
- 猫の画像
- 住宅価格
- お天気情報
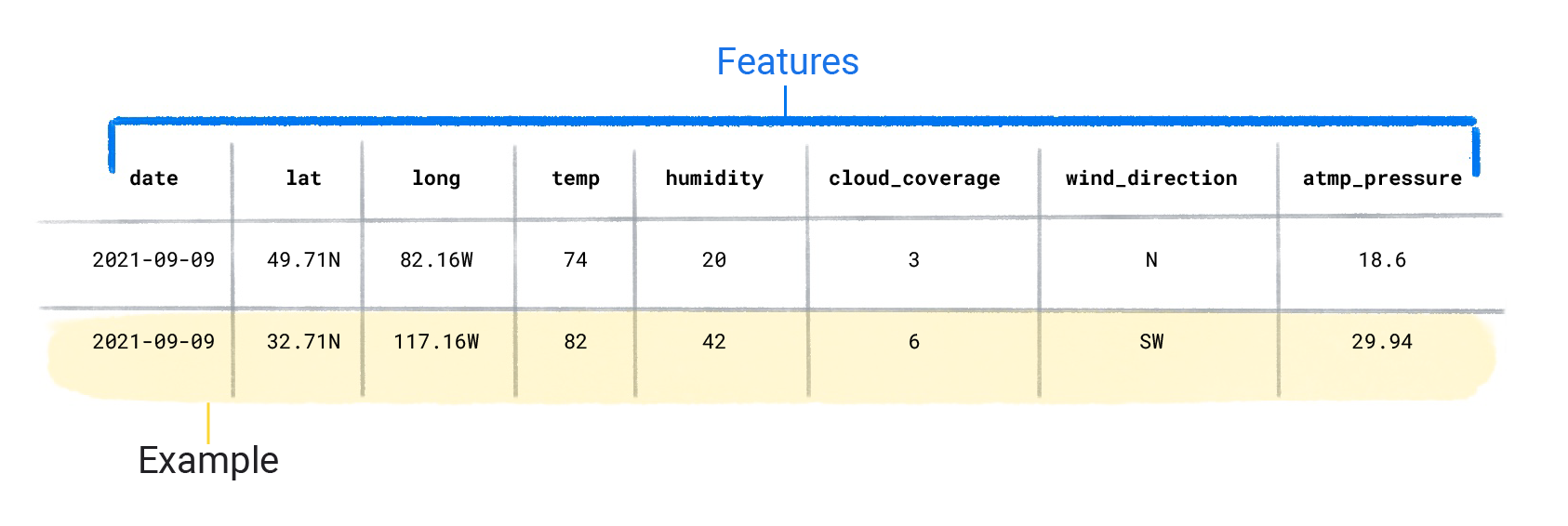
データセットは、特徴量とラベルを含む個々の例で構成されています。スプレッドシートの 1 つの行に似ていると考えるとわかりやすいでしょう。特徴量は、教師ありモデルがラベルの予測に使用する値です。ラベルは「解答」またはモデルに予測させる値です。降雨を予測する天気モデルでは、特徴として緯度、経度、気温、湿度、雲量、風向き、気圧などがあります。ラベルは「降水量」です。
特徴とラベルの両方を含む例は、ラベル付きの例と呼ばれます。
ラベル付きの 2 つの例

一方、ラベルなしの例には特徴は含まれますが、ラベルは含まれません。モデルを作成すると、モデルは特徴からラベルを予測します。
ラベルのない 2 つの例
データセットの特性
データセットは、サイズと多様性によって特徴付けられます。サイズはサンプル数を示します。多様性とは、それらの例がカバーする範囲を示します。優れたデータセットは、大規模で多様性が高いものです。
データセットは、大規模で多様なデータセット、大規模で多様性のないデータセット、小規模で多様性の高いデータセットのいずれかです。つまり、大規模なデータセットでも十分な多様性が保証されるわけではありません。また、多様性の高いデータセットでも十分なサンプルが保証されるわけではありません。
たとえば、データセットには 100 年間分のデータが含まれていても、7 月のデータのみが含まれている場合があります。このデータセットを使用して 1 月の降雨量を予測すると、予測の精度が低下します。逆に、データセットは数年間のみを対象としているものの、すべての月が含まれている場合があります。このデータセットには変動を考慮するのに十分な年数が含まれていないため、予測の精度が低くなる可能性があります。
理解度を確認する
データセットは、特徴の数によっても特徴付けることができます。たとえば、一部の気象データセットには、衛星画像から雲量の値まで、数百の特徴が含まれている場合があります。他のデータセットには、湿度、気圧、気温など、3 ~ 4 つの特徴しか含まれていない場合があります。特徴量が多いデータセットは、モデルが追加のパターンを発見し、より正確な予測を行うのに役立ちます。ただし、特徴量が多いデータセットであっても、一部の特徴量がラベルと因果関係がない可能性があるため、必ずしも予測精度の高いモデルが生成されるとは限りません。
モデル
教師あり学習では、モデルは特定の入力特徴パターンから特定の出力ラベル値への数学的な関係を定義する複雑な数値の集合です。モデルはトレーニングを通じてこれらのパターンを検出します。
トレーニング
教師ありモデルが予測を行うには、トレーニングが必要です。モデルをトレーニングするには、ラベル付きの例を含むデータセットをモデルに提供します。このモデルの目的は、特徴からラベルを予測するための最適なソリューションを導き出すことです。モデルは、予測値をラベルの実際の値と比較して、最適なソリューションを探します。予測値と実際の値の差(損失として定義)に基づいて、モデルはソリューションを徐々に更新します。つまり、モデルは特徴とラベルの間の数学的な関係を学習して、未知のデータに対して最適な予測を行うことができます。
たとえば、モデルが雨を 1.15 inches と予測したが、実際の値が .75 inches だった場合、モデルはソリューションを変更して、予測が .75 inches に近づくようにします。モデルは、データセット内の各サンプル(場合によっては複数回)を調べた後、各サンプルに対して平均で最良の予測を行うソリューションに到達します。
次の例は、モデルのトレーニングを示しています。
モデルはラベル付きの単一の例を取り込み、予測を提供します。
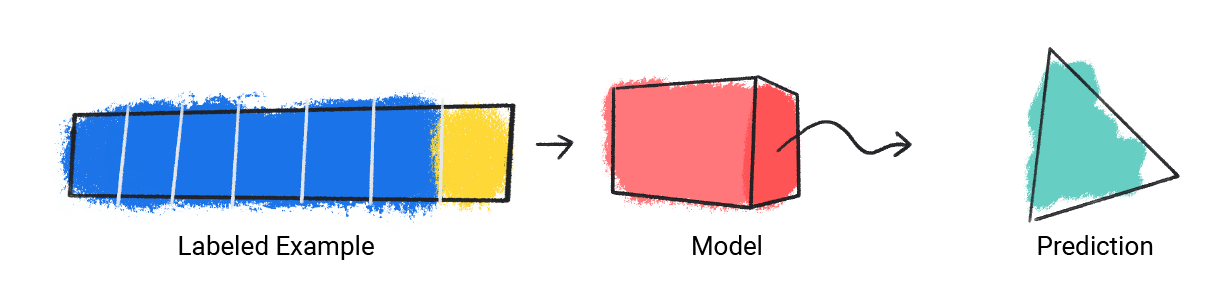
図 1. ラベル付きの例から予測を行う ML モデル。
モデルは予測値と実際の値を比較し、ソリューションを更新します。
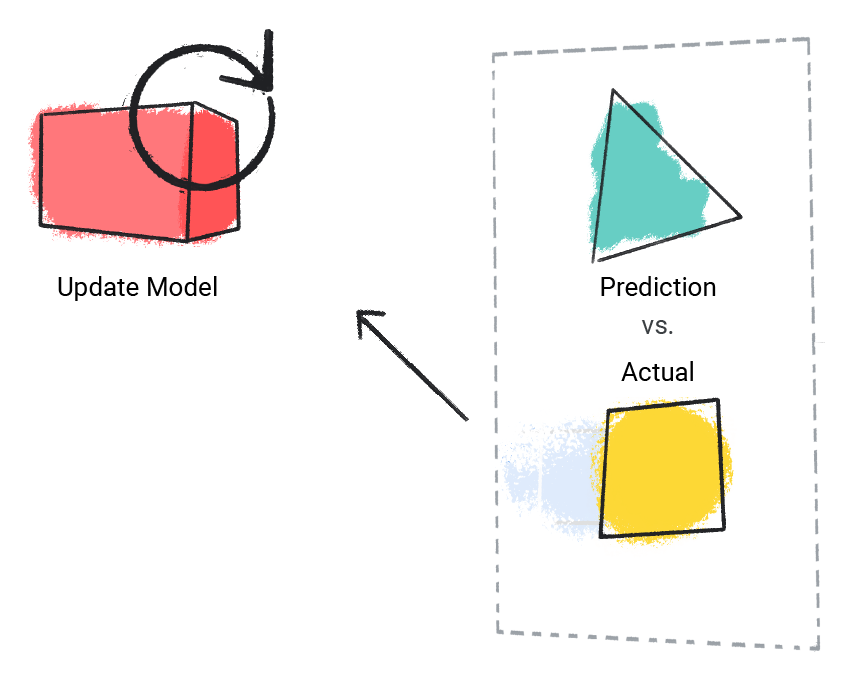
図 2. 予測値を更新する ML モデル。
モデルは、データセット内のラベル付きの例ごとにこのプロセスを繰り返します。
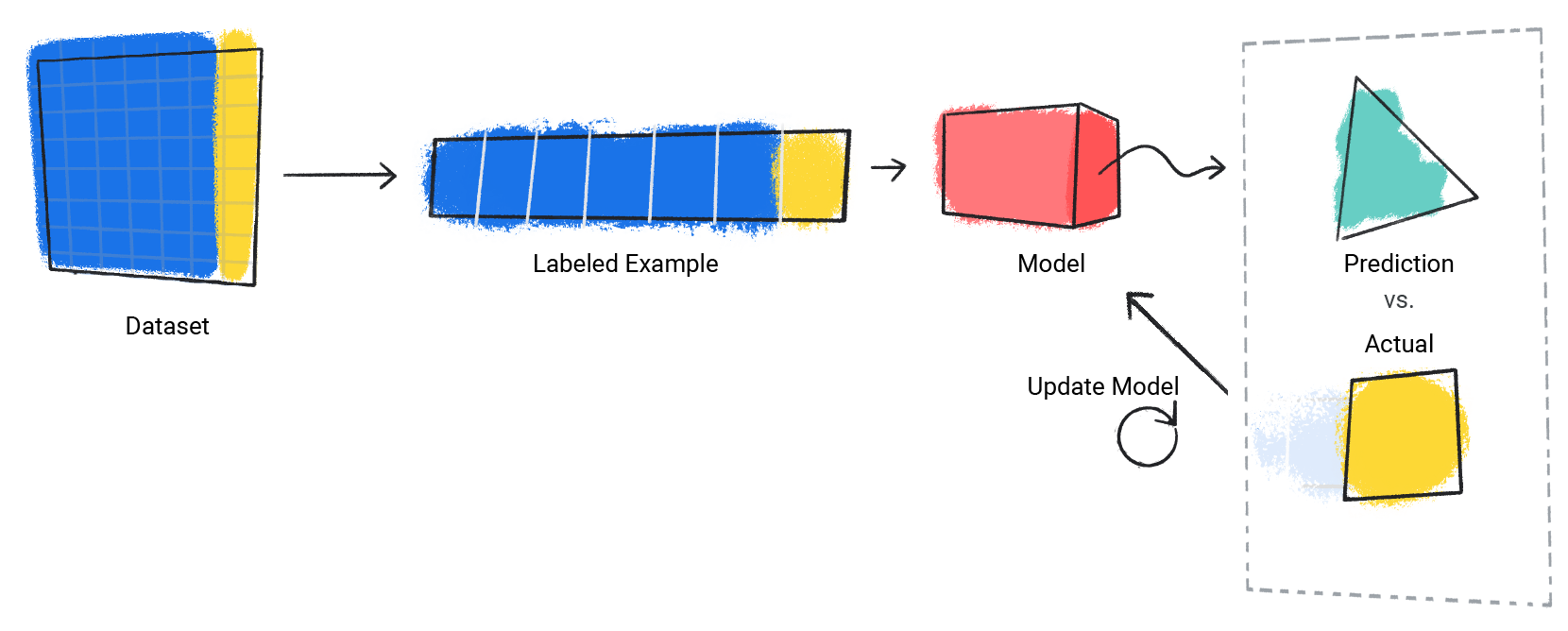
図 3. トレーニング データセット内のラベル付きサンプルごとに予測を更新する ML モデル。
このようにして、モデルは特徴とラベルの間の正しい関係を徐々に学習します。この段階的な理解が、大規模で多様なデータセットから優れたモデルが生成される理由でもあります。モデルは、値の範囲が広いより多くのデータを見て、特徴とラベルの関係をより正確に理解しています。
トレーニング中に、ML 担当者は、モデルが予測に使用する構成と特徴を微調整できます。たとえば、特定の特徴は他の特徴よりも予測力が高くなります。したがって、ML 担当者は、トレーニング中にモデルが使用する特徴を選択できます。たとえば、天気データセットに特徴として time_of_day が含まれているとします。この場合、ML 担当者はトレーニング中に time_of_day を追加または削除して、モデルが time_of_day の有無にかかわらずより良い予測を行うかどうかを確認できます。
評価
トレーニング済みモデルを評価して、学習の程度を判断します。モデルを評価する際は、ラベル付きデータセットを使用しますが、モデルにはデータセットの特徴のみを提供します。次に、モデルの予測とラベルの真の値を比較します。
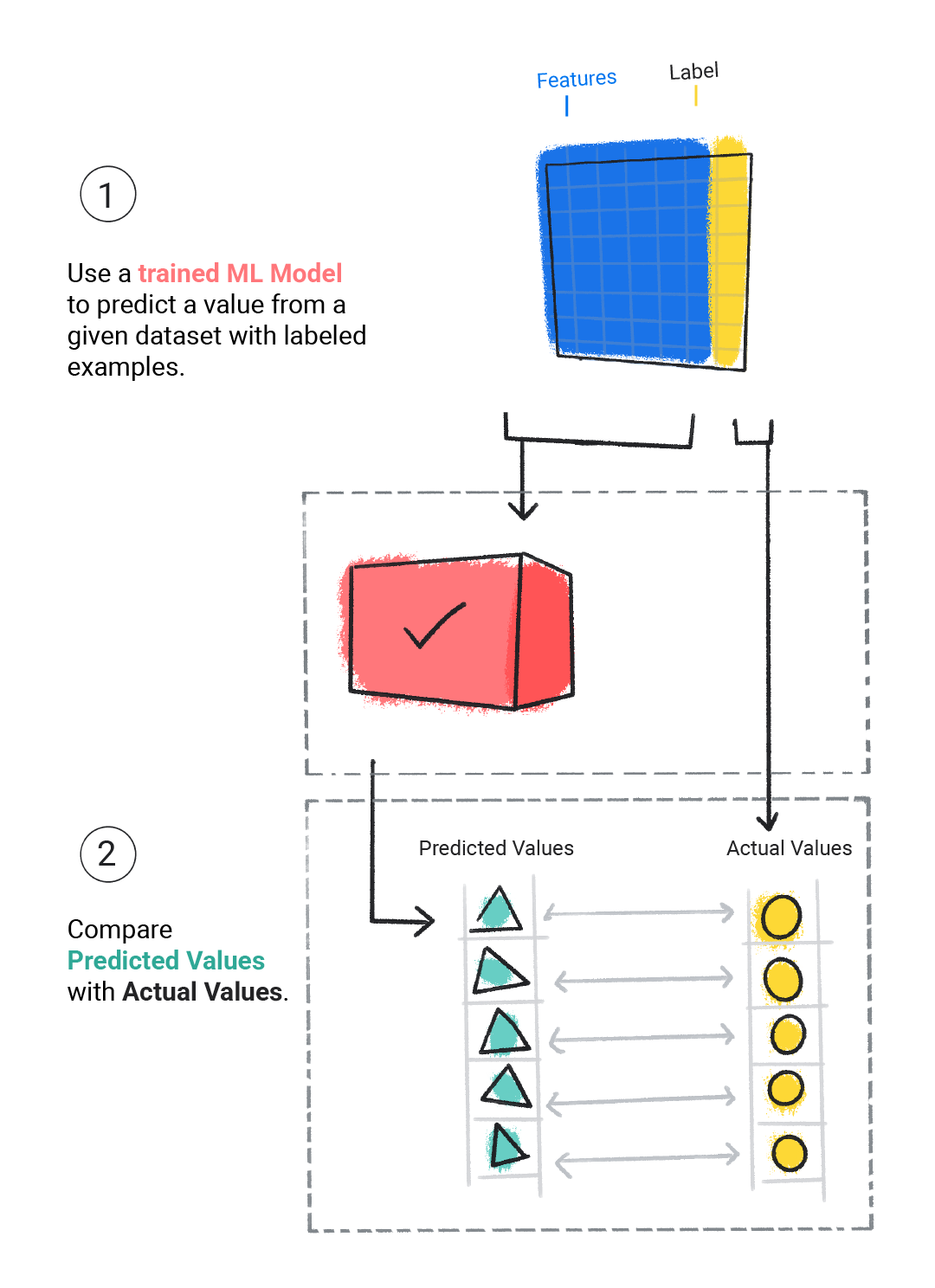
図 4. 予測値を実際の値と比較して ML モデルを評価する。
モデルの予測に応じて、実際のアプリケーションにモデルをデプロイする前に、さらにトレーニングと評価を行う場合があります。
理解度を確認する
推論
モデルの評価結果に満足したら、モデルを使用してラベルのないサンプルに対して予測(推論)を行うことができます。天気アプリの例では、モデルに現在の気象条件(温度、気圧、相対湿度など)を入力すると、降水量が予測されます。