Las tareas del aprendizaje supervisado están bien definidas y se pueden aplicar a una gran variedad de situaciones, como identificar spam o predecir precipitaciones.
Conceptos básicos del aprendizaje supervisado
El aprendizaje automático supervisado se basa en los siguientes conceptos principales:
- Datos
- Modelo
- Capacitación
- Evaluación
- Inferencia
Datos
Los datos son la fuerza impulsora del AA. Los datos se presentan en forma de palabras y números almacenados en tablas, o como los valores de píxeles y formas de onda capturados en imágenes y archivos de audio. Almacenamos datos relacionados en conjuntos de datos. Por ejemplo, podríamos tener un conjunto de datos con lo siguiente:
- Imágenes de gatos
- Precios de las viviendas
- Información del clima
Los conjuntos de datos se componen de ejemplos individuales que contienen atributos y una etiqueta. Puedes pensar en un ejemplo similar a una sola fila en una hoja de cálculo. Los atributos son los valores que un modelo supervisado usa para predecir la etiqueta. La etiqueta es la "respuesta" o el valor que queremos que el modelo prediga. En un modelo meteorológico que predice las precipitaciones, las características podrían ser la latitud, la longitud, la temperatura, la humedad, la cobertura de nubes, la dirección del viento y la presión atmosférica. La etiqueta sería cantidad de lluvia.
Los ejemplos que contienen atributos y una etiqueta se denominan ejemplos etiquetados.
Dos ejemplos etiquetados

Por el contrario, los ejemplos sin etiqueta contienen atributos, pero no etiquetas. Después de crear un modelo, este predice la etiqueta a partir de los atributos.
Dos ejemplos sin etiqueta
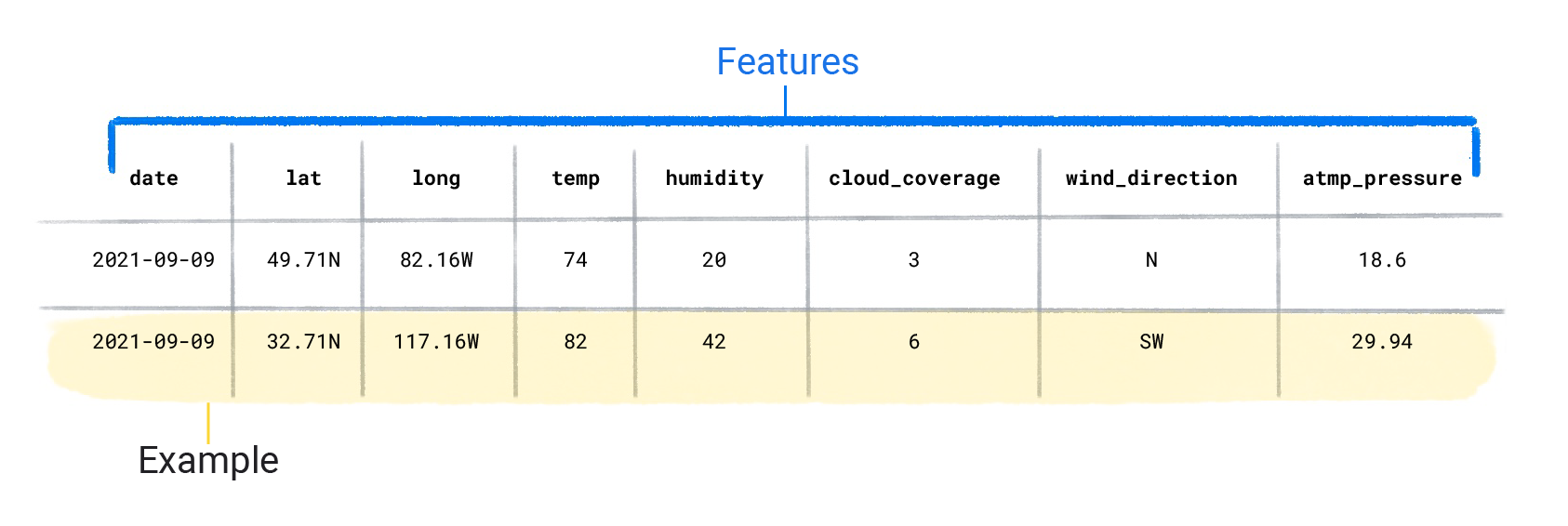
Características del conjunto de datos
Un conjunto de datos se caracteriza por su tamaño y diversidad. El tamaño indica la cantidad de ejemplos. La diversidad indica el rango que abarcan esos ejemplos. Los buenos conjuntos de datos son grandes y muy diversos.
Los conjuntos de datos pueden ser grandes y diversos, grandes pero no diversos, o pequeños pero muy diversos. En otras palabras, un conjunto de datos grande no garantiza una diversidad suficiente, y un conjunto de datos muy diverso no garantiza ejemplos suficientes.
Por ejemplo, un conjunto de datos puede contener datos de 100 años, pero solo para el mes de julio. El uso de este conjunto de datos para predecir las precipitaciones en enero generaría predicciones deficientes. Por el contrario, un conjunto de datos puede abarcar solo algunos años, pero contener todos los meses. Este conjunto de datos podría producir predicciones deficientes porque no contiene suficientes años para explicar la variabilidad.
Comprueba tu comprensión
Un conjunto de datos también se puede caracterizar por la cantidad de atributos que tiene. Por ejemplo, algunos conjuntos de datos meteorológicos pueden contener cientos de componentes, desde imágenes satelitales hasta valores de cobertura de nubes. Otros conjuntos de datos pueden contener solo tres o cuatro componentes, como la humedad, la presión atmosférica y la temperatura. Los conjuntos de datos con más atributos pueden ayudar a un modelo a descubrir patrones adicionales y realizar mejores predicciones. Sin embargo, los conjuntos de datos con más atributos no siempre producen modelos que realizan mejores predicciones, ya que algunos atributos pueden no tener una relación causal con la etiqueta.
Modelo
En el aprendizaje supervisado, un modelo es la colección compleja de números que definen la relación matemática de patrones de atributos de entrada específicos a valores de etiquetas de salida específicos. El modelo descubre estos patrones a través del entrenamiento.
Capacitación
Antes de que un modelo supervisado pueda realizar predicciones, debe entrenarse. Para entrenar un modelo, le damos un conjunto de datos con ejemplos etiquetados. El objetivo del modelo es encontrar la mejor solución para predecir las etiquetas a partir de los atributos. El modelo encuentra la mejor solución comparando su valor previsto con el valor real de la etiqueta. En función de la diferencia entre los valores previstos y reales, que se define como la pérdida, el modelo actualiza gradualmente su solución. En otras palabras, el modelo aprende la relación matemática entre los atributos y la etiqueta para poder realizar las mejores predicciones en datos que no se han visto.
Por ejemplo, si el modelo predijo 1.15 inches de lluvia, pero el valor real era .75 inches, el modelo modifica su solución para que su predicción esté más cerca de .75 inches. Después de que el modelo analiza cada ejemplo del conjunto de datos (en algunos casos, varias veces), llega a una solución que realiza las mejores predicciones, en promedio, para cada uno de los ejemplos.
A continuación, se muestra cómo entrenar un modelo:
El modelo toma un solo ejemplo etiquetado y proporciona una predicción.
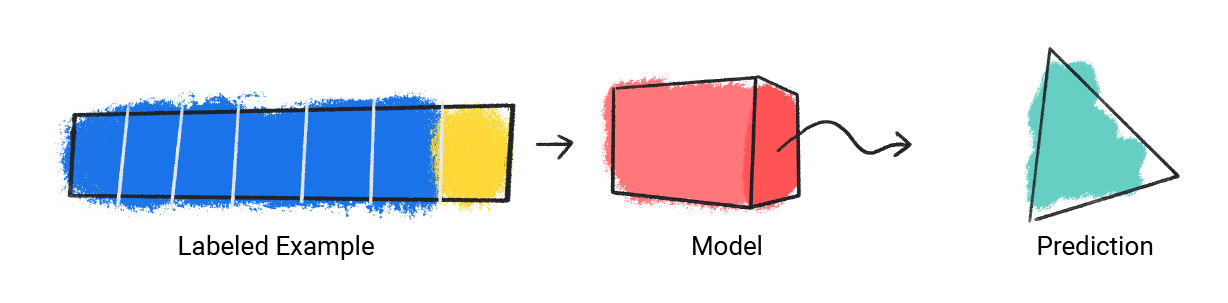
Figura 1. Un modelo de AA que hace una predicción a partir de un ejemplo etiquetado.
El modelo compara su valor predicho con el valor real y actualiza su solución.
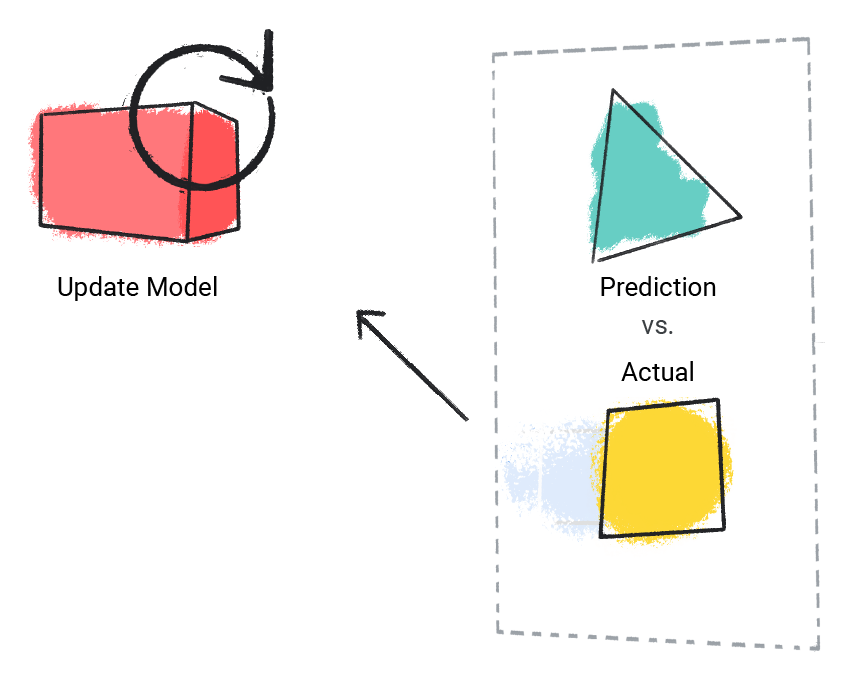
Figura 2. Un modelo de AA que actualiza su valor previsto.
El modelo repite este proceso para cada ejemplo etiquetado en el conjunto de datos.
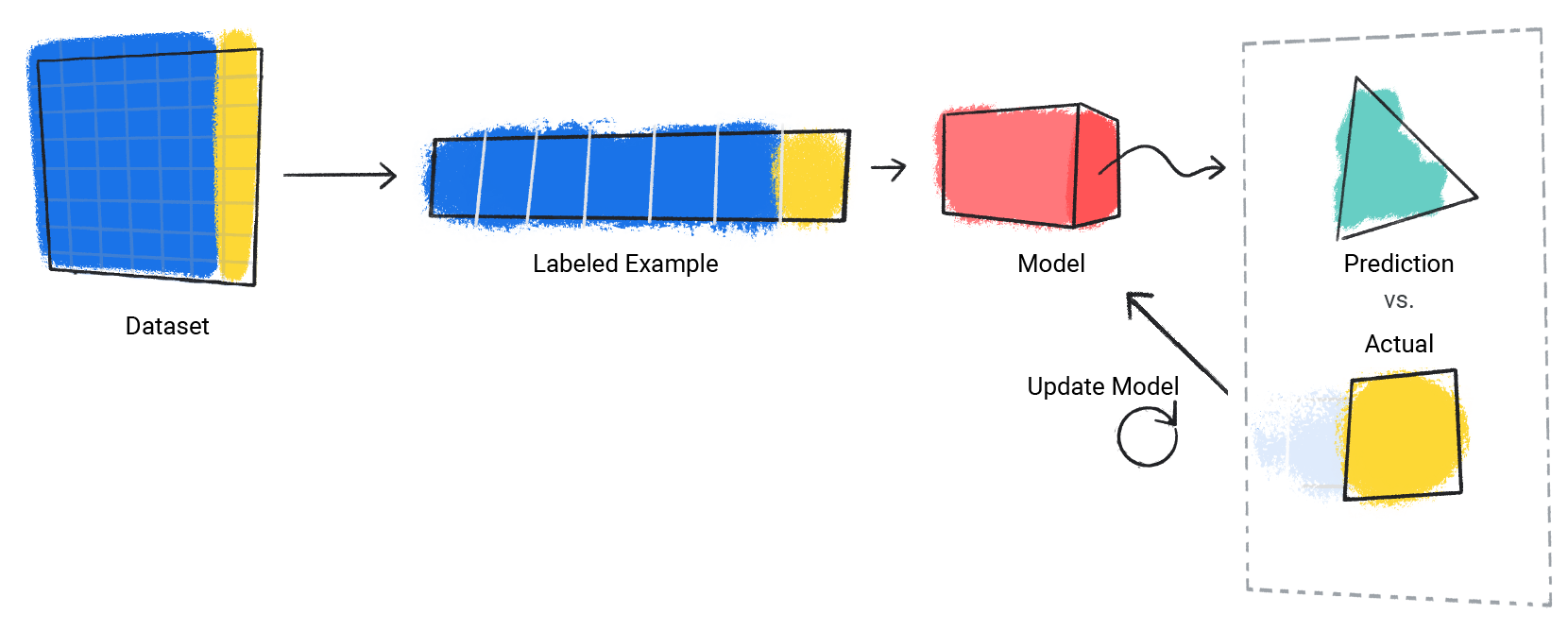
Figura 3. Un modelo de AA que actualiza sus predicciones para cada ejemplo etiquetado en el conjunto de datos de entrenamiento.
De esta manera, el modelo aprende gradualmente la relación correcta entre los atributos y la etiqueta. Esta comprensión gradual también es la razón por la que los conjuntos de datos grandes y diversos producen un mejor modelo. El modelo vio más datos con un rango más amplio de valores y definió mejor su comprensión de la relación entre los atributos y la etiqueta.
Durante el entrenamiento, los profesionales del AA pueden hacer ajustes sutiles a las configuraciones y funciones que usa el modelo para hacer predicciones. Por ejemplo, ciertos atributos tienen más poder predictivo que otros. Por lo tanto, los profesionales de la AA
pueden seleccionar qué atributos usa el modelo durante el entrenamiento. Por ejemplo, supongamos que un conjunto de datos del clima contienetime_of_day como atributo. En este caso, un profesional del AA puede agregar o quitar time_of_day durante el entrenamiento para ver si el modelo hace mejores predicciones con o sin él.
Evaluación
Evaluamos un modelo entrenado para determinar qué tan bien aprendió. Cuando evaluamos un modelo, usamos un conjunto de datos etiquetado, pero solo le damos al modelo las características del conjunto de datos. Luego, comparamos las predicciones del modelo con los valores reales de la etiqueta.
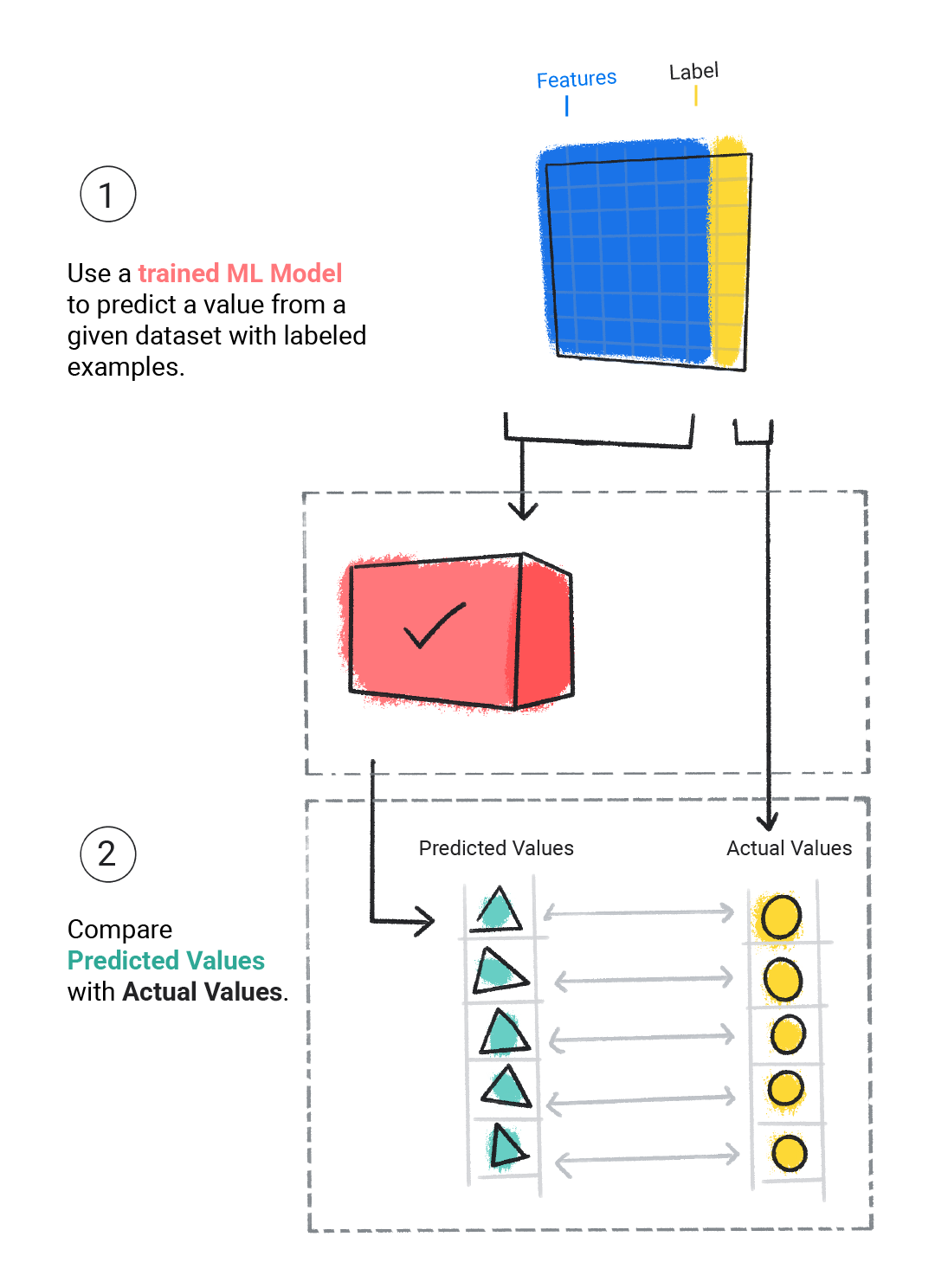
Figura 4. Evaluar un modelo de AA comparando sus predicciones con los valores reales
Según las predicciones del modelo, es posible que realicemos más entrenamiento y evaluación antes de implementarlo en una aplicación real.
Comprueba tu comprensión
Inferencia
Una vez que estemos conformes con los resultados de la evaluación del modelo, podremos usarlo para realizar predicciones, llamadas inferencias, en ejemplos sin etiqueta. En el ejemplo de la app del clima, le proporcionaríamos al modelo las condiciones climáticas actuales, como la temperatura, la presión atmosférica y la humedad relativa, y este predeciría la cantidad de lluvia.