তত্ত্বাবধানে শিক্ষার কাজগুলি সু-সংজ্ঞায়িত করা হয়েছে এবং বিভিন্ন পরিস্থিতিতে প্রয়োগ করা যেতে পারে-যেমন স্প্যাম সনাক্ত করা বা বৃষ্টিপাতের পূর্বাভাস দেওয়া।
ভিত্তিগত তত্ত্বাবধানে শেখার ধারণা
তত্ত্বাবধানে মেশিন লার্নিং নিম্নলিখিত মূল ধারণাগুলির উপর ভিত্তি করে:
- ডেটা
- মডেল
- প্রশিক্ষণ
- মূল্যায়ন করছে
- অনুমান
ডেটা
ডেটা হল ML এর চালিকা শক্তি। ডেটা টেবিলে সংরক্ষিত শব্দ এবং সংখ্যার আকারে বা ছবি এবং অডিও ফাইলগুলিতে ধারণ করা পিক্সেল এবং তরঙ্গরূপের মান হিসাবে আসে। আমরা ডেটাসেটে সম্পর্কিত ডেটা সংরক্ষণ করি। উদাহরণস্বরূপ, আমাদের নিম্নলিখিতগুলির একটি ডেটাসেট থাকতে পারে:
- বিড়ালের ছবি
- হাউজিং দাম
- আবহাওয়ার তথ্য
ডেটাসেটগুলি স্বতন্ত্র উদাহরণ দিয়ে গঠিত যাতে বৈশিষ্ট্য এবং একটি লেবেল থাকে। আপনি একটি স্প্রেডশীটে একটি একক সারির অনুরূপ একটি উদাহরণ মনে করতে পারেন। বৈশিষ্ট্যগুলি হল সেই মানগুলি যা একটি তত্ত্বাবধানে থাকা মডেল লেবেলের পূর্বাভাস দিতে ব্যবহার করে৷ লেবেল হল "উত্তর" বা যে মানটি আমরা মডেলটি ভবিষ্যদ্বাণী করতে চাই। একটি আবহাওয়া মডেল যা বৃষ্টিপাতের পূর্বাভাস দেয়, বৈশিষ্ট্যগুলি হতে পারে অক্ষাংশ , দ্রাঘিমাংশ , তাপমাত্রা , আর্দ্রতা , মেঘের আবরণ , বাতাসের দিক এবং বায়ুমণ্ডলীয় চাপ । লেবেল হবে বৃষ্টিপাতের পরিমাণ ।
যে উদাহরণগুলিতে বৈশিষ্ট্য এবং একটি লেবেল উভয়ই রয়েছে তাকে লেবেলযুক্ত উদাহরণ বলা হয়।
দুটি লেবেল উদাহরণ

বিপরীতে, লেবেলবিহীন উদাহরণে বৈশিষ্ট্য রয়েছে, কিন্তু কোনো লেবেল নেই। আপনি একটি মডেল তৈরি করার পরে, মডেল বৈশিষ্ট্য থেকে লেবেল ভবিষ্যদ্বাণী করে।
দুটি লেবেলবিহীন উদাহরণ
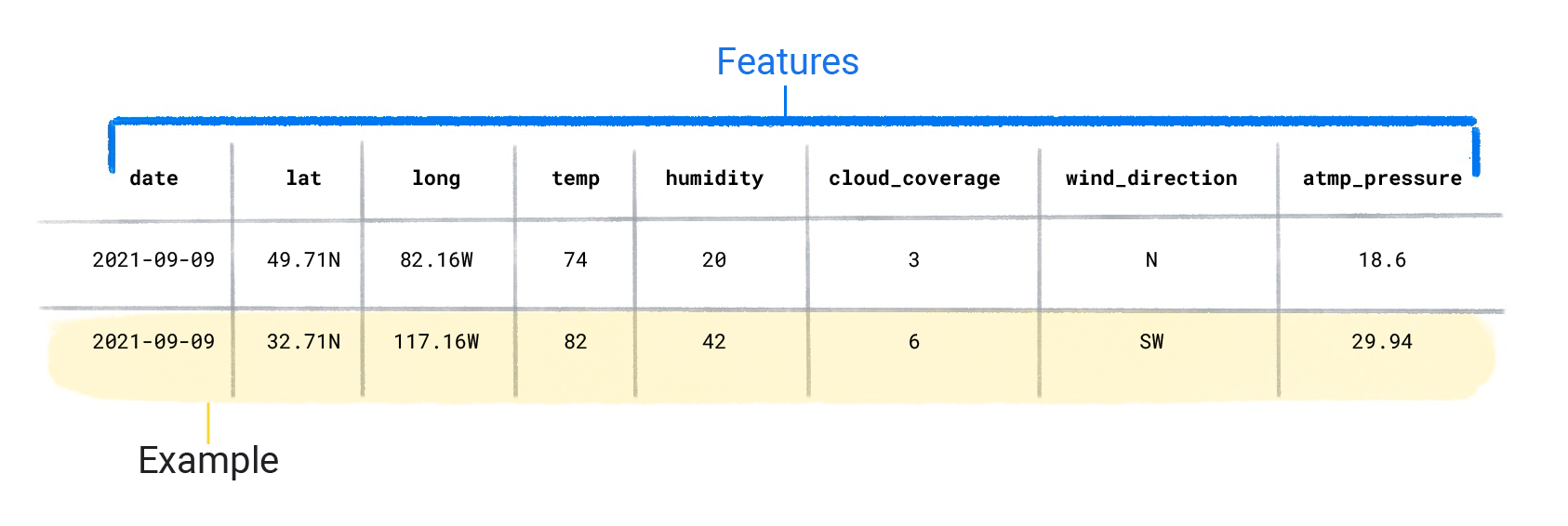
ডেটাসেটের বৈশিষ্ট্য
একটি ডেটাসেট এর আকার এবং বৈচিত্র্য দ্বারা চিহ্নিত করা হয়। আকার উদাহরণের সংখ্যা নির্দেশ করে। বৈচিত্র্য সেই উদাহরণগুলির কভার পরিসীমা নির্দেশ করে৷ ভাল ডেটাসেটগুলি উভয়ই বড় এবং অত্যন্ত বৈচিত্র্যময়।
ডেটাসেটগুলি বড় এবং বৈচিত্র্যময়, বা বড় কিন্তু বৈচিত্র্যময় নয়, বা ছোট কিন্তু অত্যন্ত বৈচিত্র্যময় হতে পারে। অন্য কথায়, একটি বড় ডেটাসেট যথেষ্ট বৈচিত্র্যের গ্যারান্টি দেয় না, এবং একটি ডেটাসেট যা অত্যন্ত বৈচিত্র্যপূর্ণ তা যথেষ্ট উদাহরণের গ্যারান্টি দেয় না।
উদাহরণস্বরূপ, একটি ডেটাসেটে 100 বছরের মূল্যের ডেটা থাকতে পারে, তবে শুধুমাত্র জুলাই মাসের জন্য। জানুয়ারিতে বৃষ্টিপাতের পূর্বাভাস দিতে এই ডেটাসেট ব্যবহার করলে খারাপ ভবিষ্যদ্বাণী তৈরি হবে। বিপরীতভাবে, একটি ডেটাসেট শুধুমাত্র কয়েক বছর কভার করতে পারে তবে প্রতি মাসে ধারণ করতে পারে। এই ডেটাসেটটি খারাপ ভবিষ্যদ্বাণী তৈরি করতে পারে কারণ এতে পরিবর্তনশীলতার জন্য যথেষ্ট বছর থাকে না।
আপনার বোঝার পরীক্ষা করুন
একটি ডেটাসেট এর বৈশিষ্ট্যগুলির সংখ্যা দ্বারাও চিহ্নিত করা যেতে পারে। উদাহরণস্বরূপ, কিছু আবহাওয়া ডেটাসেটে শত শত বৈশিষ্ট্য থাকতে পারে, স্যাটেলাইট চিত্র থেকে ক্লাউড কভারেজ মান পর্যন্ত। অন্যান্য ডেটাসেটে আর্দ্রতা, বায়ুমণ্ডলীয় চাপ এবং তাপমাত্রার মতো মাত্র তিন বা চারটি বৈশিষ্ট্য থাকতে পারে। আরও বৈশিষ্ট্য সহ ডেটাসেটগুলি একটি মডেলকে অতিরিক্ত নিদর্শনগুলি আবিষ্কার করতে এবং আরও ভাল ভবিষ্যদ্বাণী করতে সহায়তা করতে পারে। যাইহোক, আরও বৈশিষ্ট্যযুক্ত ডেটাসেটগুলি সর্বদা এমন মডেল তৈরি করে না যা আরও ভাল ভবিষ্যদ্বাণী করে কারণ কিছু বৈশিষ্ট্যের লেবেলের সাথে কোনও কার্যকারণ সম্পর্ক থাকতে পারে না।
মডেল
তত্ত্বাবধানে শেখার ক্ষেত্রে, একটি মডেল হল সংখ্যার জটিল সংগ্রহ যা নির্দিষ্ট ইনপুট বৈশিষ্ট্য নিদর্শন থেকে নির্দিষ্ট আউটপুট লেবেল মানগুলির মধ্যে গাণিতিক সম্পর্ককে সংজ্ঞায়িত করে। মডেলটি প্রশিক্ষণের মাধ্যমে এই নিদর্শনগুলি আবিষ্কার করে।
প্রশিক্ষণ
একটি তত্ত্বাবধানে মডেল ভবিষ্যদ্বাণী করতে পারে আগে, এটি প্রশিক্ষিত করা আবশ্যক. একটি মডেলকে প্রশিক্ষণ দিতে, আমরা মডেলটিকে লেবেলযুক্ত উদাহরণ সহ একটি ডেটাসেট দিই। মডেলের লক্ষ্য হল বৈশিষ্ট্যগুলি থেকে লেবেলগুলির পূর্বাভাস দেওয়ার জন্য সর্বোত্তম সমাধান বের করা৷ মডেলটি লেবেলের প্রকৃত মানের সাথে তার পূর্বাভাসিত মান তুলনা করে সর্বোত্তম সমাধান খুঁজে পায়। ভবিষ্যদ্বাণী করা এবং প্রকৃত মানগুলির মধ্যে পার্থক্যের উপর ভিত্তি করে - ক্ষতি হিসাবে সংজ্ঞায়িত - মডেলটি ধীরে ধীরে তার সমাধান আপডেট করে৷ অন্য কথায়, মডেলটি বৈশিষ্ট্য এবং লেবেলের মধ্যে গাণিতিক সম্পর্ক শিখেছে যাতে এটি অদেখা ডেটাতে সেরা ভবিষ্যদ্বাণী করতে পারে।
উদাহরণস্বরূপ, যদি মডেলটি 1.15 inches বৃষ্টির পূর্বাভাস দেয়, কিন্তু প্রকৃত মান ছিল .75 inches , মডেলটি তার সমাধানটি পরিবর্তন করে তাই এর পূর্বাভাস .75 inches কাছাকাছি। মডেলটি ডেটাসেটের প্রতিটি উদাহরণের দিকে নজর দেওয়ার পরে - কিছু ক্ষেত্রে, একাধিকবার - এটি এমন একটি সমাধানে পৌঁছে যা প্রতিটি উদাহরণের জন্য গড়ে সর্বোত্তম ভবিষ্যদ্বাণী করে৷
নিম্নলিখিত একটি মডেল প্রশিক্ষণ প্রদর্শন করে:
মডেলটি একটি একক লেবেলযুক্ত উদাহরণ নেয় এবং একটি ভবিষ্যদ্বাণী প্রদান করে।
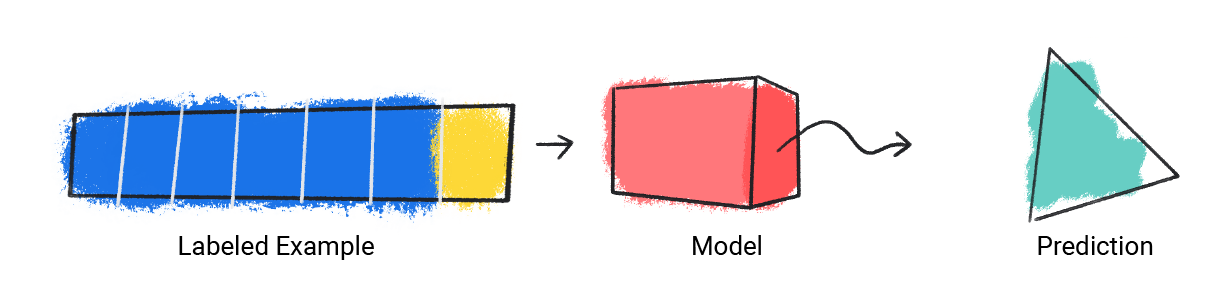
চিত্র 1 । একটি এমএল মডেল একটি লেবেলযুক্ত উদাহরণ থেকে একটি ভবিষ্যদ্বাণী করছে৷
মডেলটি তার পূর্বাভাসিত মানটিকে প্রকৃত মানের সাথে তুলনা করে এবং এর সমাধান আপডেট করে।
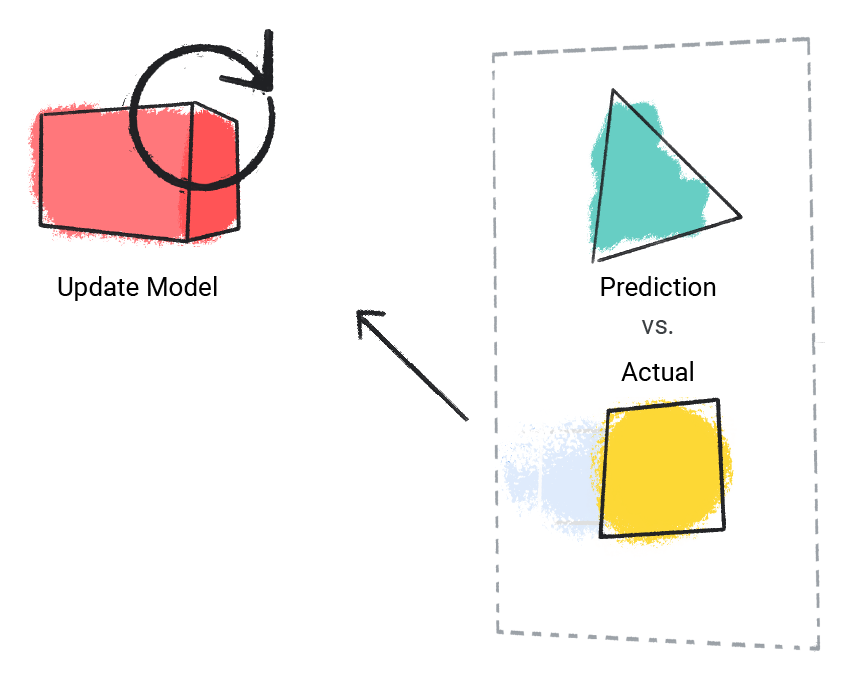
চিত্র 2 । একটি ML মডেল তার পূর্বাভাসিত মান আপডেট করছে।
মডেলটি ডেটাসেটের প্রতিটি লেবেলযুক্ত উদাহরণের জন্য এই প্রক্রিয়াটি পুনরাবৃত্তি করে।
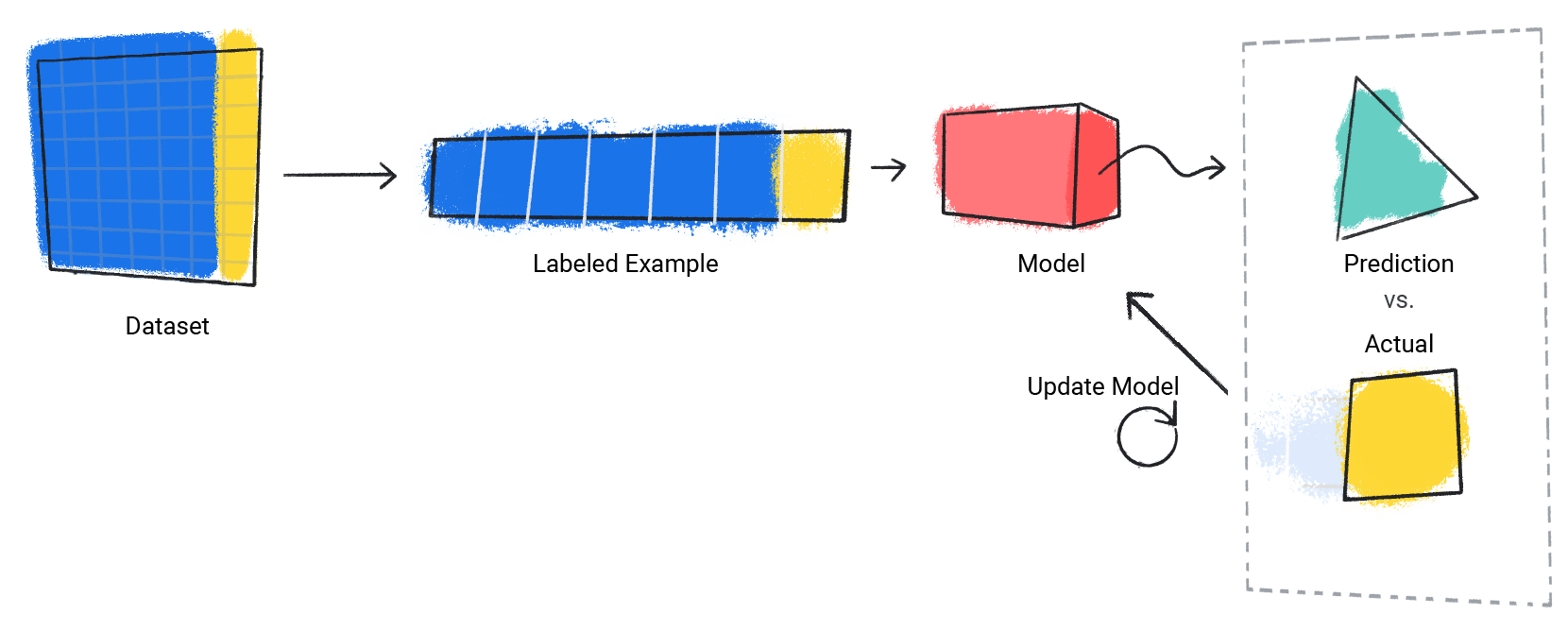
চিত্র 3 । প্রশিক্ষণ ডেটাসেটে প্রতিটি লেবেলযুক্ত উদাহরণের জন্য একটি ML মডেল তার ভবিষ্যদ্বাণী আপডেট করছে।
এইভাবে, মডেল ধীরে ধীরে বৈশিষ্ট্য এবং লেবেলের মধ্যে সঠিক সম্পর্ক শিখে। এই ধীরে ধীরে বোঝার কারণেই বড় এবং বৈচিত্র্যময় ডেটাসেটগুলি আরও ভাল মডেল তৈরি করে। মডেলটি মানগুলির বিস্তৃত পরিসরের সাথে আরও ডেটা দেখেছে এবং বৈশিষ্ট্য এবং লেবেলের মধ্যে সম্পর্কের বোঝার পরিমার্জন করেছে৷
প্রশিক্ষণের সময়, এমএল অনুশীলনকারীরা ভবিষ্যদ্বাণী করতে মডেল ব্যবহার করে কনফিগারেশন এবং বৈশিষ্ট্যগুলিতে সূক্ষ্ম সমন্বয় করতে পারে। উদাহরণস্বরূপ, কিছু বৈশিষ্ট্য অন্যদের তুলনায় বেশি ভবিষ্যদ্বাণী করার ক্ষমতা রাখে। অতএব, এমএল অনুশীলনকারীরা প্রশিক্ষণের সময় মডেলটি কোন বৈশিষ্ট্যগুলি ব্যবহার করবে তা নির্বাচন করতে পারে। উদাহরণস্বরূপ, ধরুন একটি আবহাওয়া ডেটাসেটে একটি বৈশিষ্ট্য হিসাবে time_of_day রয়েছে। এই ক্ষেত্রে, একজন এমএল অনুশীলনকারী প্রশিক্ষণের time_of_day যোগ বা অপসারণ করতে পারেন যাতে মডেলটি এটির সাথে বা ছাড়া আরও ভাল ভবিষ্যদ্বাণী করে কিনা।
মূল্যায়ন করছে
আমরা একটি প্রশিক্ষিত মডেল মূল্যায়ন করি এটি কতটা ভালভাবে শিখেছে তা নির্ধারণ করতে। যখন আমরা একটি মডেল মূল্যায়ন করি, আমরা একটি লেবেলযুক্ত ডেটাসেট ব্যবহার করি, কিন্তু আমরা শুধুমাত্র মডেলটিকে ডেটাসেটের বৈশিষ্ট্যগুলি দেই। তারপরে আমরা লেবেলের প্রকৃত মানগুলির সাথে মডেলের ভবিষ্যদ্বাণীগুলির তুলনা করি৷
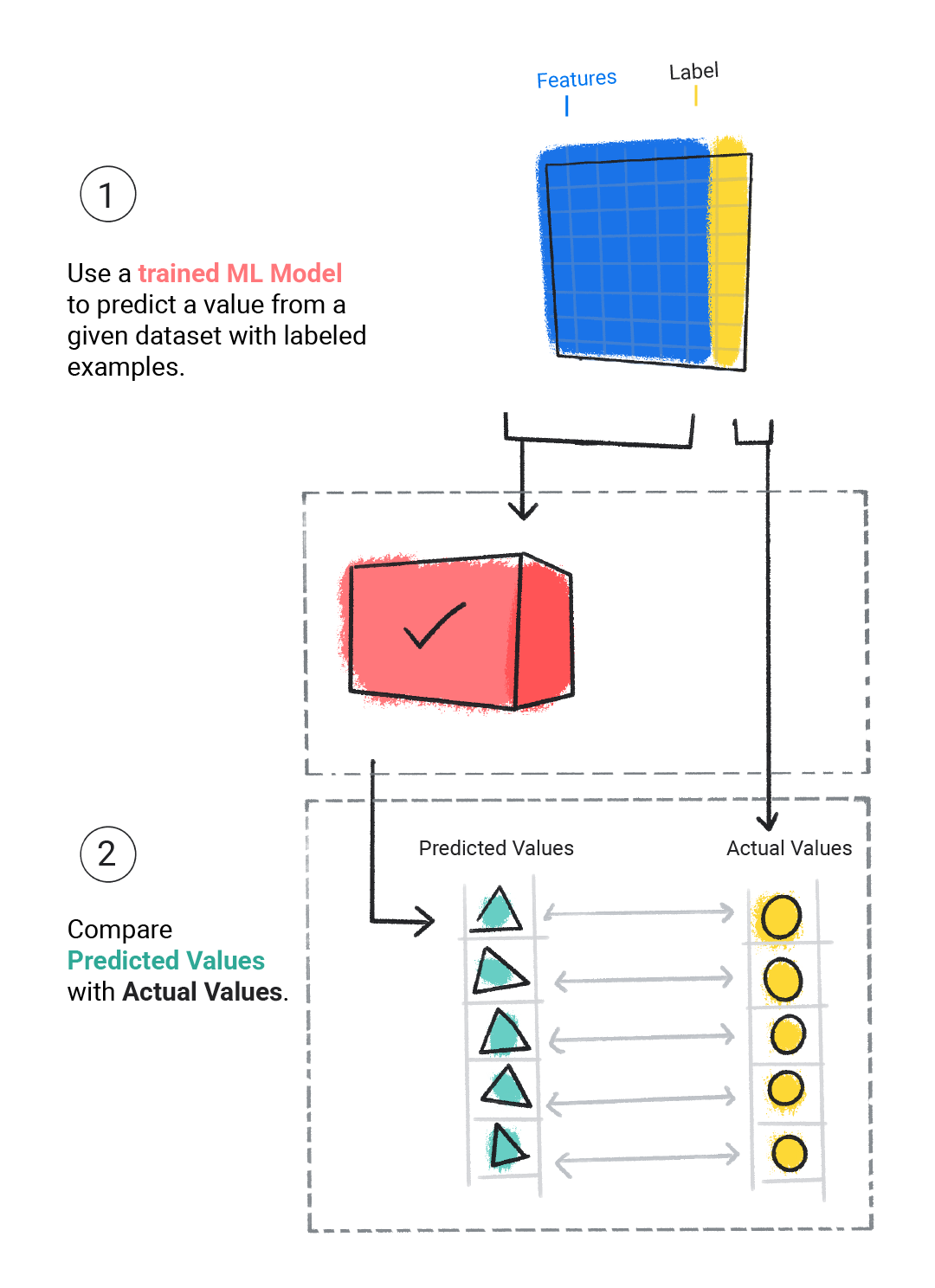
চিত্র 4 । প্রকৃত মানের সাথে তার পূর্বাভাস তুলনা করে একটি ML মডেলের মূল্যায়ন করা।
মডেলের ভবিষ্যদ্বাণীগুলির উপর নির্ভর করে, আমরা বাস্তব-বিশ্বের অ্যাপ্লিকেশনে মডেল স্থাপন করার আগে আরও প্রশিক্ষণ এবং মূল্যায়ন করতে পারি।
আপনার বোঝার পরীক্ষা করুন
অনুমান
একবার আমরা মডেলের মূল্যায়নের ফলাফলে সন্তুষ্ট হলে, লেবেলবিহীন উদাহরণে আমরা ভবিষ্যদ্বাণী করতে মডেলটিকে ব্যবহার করতে পারি, যাকে অনুমান বলা হয়। ওয়েদার অ্যাপের উদাহরণে, আমরা মডেলটিকে বর্তমান আবহাওয়ার অবস্থা যেমন তাপমাত্রা, বায়ুমণ্ডলীয় চাপ এবং আপেক্ষিক আর্দ্রতা দিব—এবং এটি বৃষ্টিপাতের পরিমাণের পূর্বাভাস দেবে।