データをモデルにフィードする前に、データを形式に変換する必要がある 理解できます。
第一に、収集したデータサンプルは特定の順序である可能性があります。Google は サンプルの順序付けに関連する情報が影響を受けないようにする テキストとラベルの関係を学習しましたたとえば、データセットが並べ替えられ、 トレーニング セットと検証セットに分割された場合でも、これらのセットは データの全体的な分布を表すものです
モデルがデータ順序の影響を受けないようにするための簡単なベスト プラクティスは、 他の処理を行う前に必ずデータをシャッフルしますデータがすでに存在する場合は トレーニング セットと検証セットに分割するため、検証データを変換し、 データを変換するのと同じ方法で データを変換できますまだない場合は トレーニング セットと検証セットを分ける場合は、サンプルを シャッフルサンプルの 80% をトレーニングに、20% をトレーニングに 検証できます。
第二に、ML アルゴリズムは数値を入力として受け取ります。つまり テキストを数値ベクトルに変換する必要があります。2 つのステップで このプロセスは
トークン化: テキストを単語または小さなサブテキストに分割します。これにより、 テキストとラベルの関係を適切に一般化できるようにします。 これにより、データセットの「語彙」( できます。
ベクトル化: 特性を示す適切な数値尺度を定義します。 あります。
N グラム ベクトルとシーケンスの両方に対して、この 2 つのステップを実行する方法を見てみましょう。 特徴量を使ってベクトル表現を最適化する方法についても 正規化の手法についても学びました。
N グラム ベクトル [オプション A]
以降の段落でトークン化方法と N グラムモデルのベクトル化です。また、Google の検索エンジン最適化(N-A) 特徴選択と正規化手法を使用したグラム表現
N グラム ベクトルでは、テキストは一意の N グラムの集合として表されます。
n 個の隣接トークン(通常は単語)のグループです。テキスト The mouse ran
up the clock について考えてみましょう。こちらをご覧ください。
- 単語のユニグラム(n = 1)は
['the', 'mouse', 'ran', 'up', 'clock']です。 - 単語のバイグラム(n = 2)は
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock']である - その他に関しても同様です。
トークン化
単語のユニグラムとバイグラムにトークン化すると、 コンピューティング時間を削減できます。
ベクトル化
テキスト サンプルを N グラムに分割したら、この N グラムを 数値ベクトルに変換します。例 以下は、2 つの画像に対して生成されたユニグラムとバイグラムに割り当てられるインデックスです。 あります。
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
N グラムにインデックスを割り当てたら、通常は次のいずれかを使用してベクトル化します。 選択します。
ワンホット エンコーディング: すべてのサンプル テキストは、 テキスト内のトークンの有無。
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
カウント エンコード: すべてのサンプル テキストは、
トークンの数を返します。対応する要素は
ユニグラム「the」「the」という単語は「the」であるため、2 と表されます。
出現箇所が 2 回出現します。
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf エンコード: 問題 上記の 2 つの方法では、よく使われる単語が (すべてのドキュメントで特に固有でない単語など)が、 テキスト サンプルなど)にペナルティは課されません。たとえば、「a」という単語が すべてのテキストで非常に頻繁に出現します。したがって、「the」のトークン数は、 あまり役に立ちません。
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(Scikit-learn TfidfTransformer をご覧ください)。
ベクトル表現は他にも多数ありますが、上の 3 つは よく使用されます。
tf-idf エンコードは、他の 2 つのモデルよりもわずかに優れていることが (平均 0.25 ~ 15% 高い)が示されているため、この方法をお勧めします。 ベクトル化されています。ただし、メモリを占有する( 浮動小数点表現を使用するため)計算に時間がかかります。 特に大規模なデータセットの場合はなおさらです(場合によっては 2 倍の時間がかかることもあります)。
特徴選択
データセット内のすべてのテキストを単語の uni+bigram トークンに変換すると、 トークンが数万個にのぼることもあります。これらのトークン/機能の一部ではない 大きく影響します。特定のトークンを削除できます データセット全体で極めてまれに発生するイベントです。また 特徴量の重要度(各トークンがラベル予測に及ぼす影響の度合い) 最も有用なトークンのみを含めます。
特徴量とそれに対応する特徴量を取得する統計関数は 特徴の重要度スコアを出力しますよく使用される 2 つの関数は、 f_classif と chi2。Google テストによると、両方の関数が同等の性能を発揮します。
さらに重要なことに、多くの組織で精度のピークは約 20,000 特徴でした。 (図 6 を参照)。このしきい値を超えてさらに特徴を追加すると、 ごくわずかであり、場合によっては 過学習 パフォーマンスの低下につながります
<ph type="x-smartling-placeholder">
図 6: トップ K 機能と精度の比較。データセット全体で、上位 20, 000 個の特徴量で精度が頭打ちになっている。
正規化
正規化は、すべての特徴/サンプル値を小さな同様の値に変換します。 これにより、学習アルゴリズムにおける勾配降下法の収束が簡素化されます。ソース データ前処理時の正規化は、それほど テキスト分類問題における値この手順はスキップすることをおすすめします
次のコードは、上記のすべてのステップをまとめたものです。
- テキストのサンプルを単語のユニグラムとバイグラムにトークン化する
- tf-idf エンコードを使用してベクトル化する。
- トークンを破棄して、上位 20,000 件の特徴のみをトークンのベクトルから選択する 出現回数が 2 回未満のトークンと、f_classif を使用して特徴量を計算する 重要です
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
N グラムのベクトル表現では、単語に関する多くの情報が 順序と文法(せいぜい、部分的な順序情報は保持できます。 n > の場合1)これは「一言で言わざるを得ない手法」と呼ばれます。この表現は、 順序を考慮しないモデル( ロジスティック回帰、多層パーセプトロン、勾配ブースティングマシン ベクトルマシンをサポートします。
シーケンス ベクトル [オプション B]
以降の段落でトークン化方法と ベクトル化についても学びました。また、キャンペーンを最適化して 特徴選択と正規化の手法を使用します。
一部のテキスト サンプルでは、単語の順序がテキストの意味に重要となります。対象 「以前は通勤が嫌いだったから。新しいバイクで変わりました 理解できるのは、順番に読んだ場合のみです。CNN/RNN などのモデル 標本内の単語の順番から意味を推測できます。これらのモデルでは、 テキストを一連のトークンとして表現し、順序を維持します。
トークン化
テキストは、文字のシーケンスまたは あります。単語レベルの表現を使用すると、より効率的で パフォーマンスが向上します。これもまた 次が業種です。文字トークンの使用は、テキストに 簡単に検出できます。
ベクトル化
テキスト サンプルを単語のシーケンスに変換したら、 数値ベクトルに変換します。以下の例は、指標スコープで示されている 2 つのテキストに対して生成された 1 つのユニグラムに 最初のテキストが変換されるインデックス。
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
すべてのトークンに割り当てられるインデックス:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
注: 「the」という単語は、最も頻繁に出現するため、インデックス値 1 は 割り当てられています。一部のライブラリでは、不明なトークンのインデックス 0 がそのまま予約されています。 見ていきましょう
トークン インデックスのシーケンス:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
トークン シーケンスをベクトル化するには、次の 2 つの方法があります。
ワンホット エンコーディング: シーケンスは、 次元空間(n は語彙のサイズ)この表現は効果的です 文字としてトークン化する場合、語彙は小さくなります。 単語としてトークン化する場合、語彙は通常数十から ワンホット ベクトルが非常にスパースで非効率的になります。 例:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
単語のエンベディング: 単語には意味が関連付けられています。その結果 密なベクトル空間(約数百の実数)で単語トークンを表現できます。 単語間の位置と距離から単語の類似度がわかります 意味的に解析します(図 7 を参照)。この表現を 単語エンベディング。
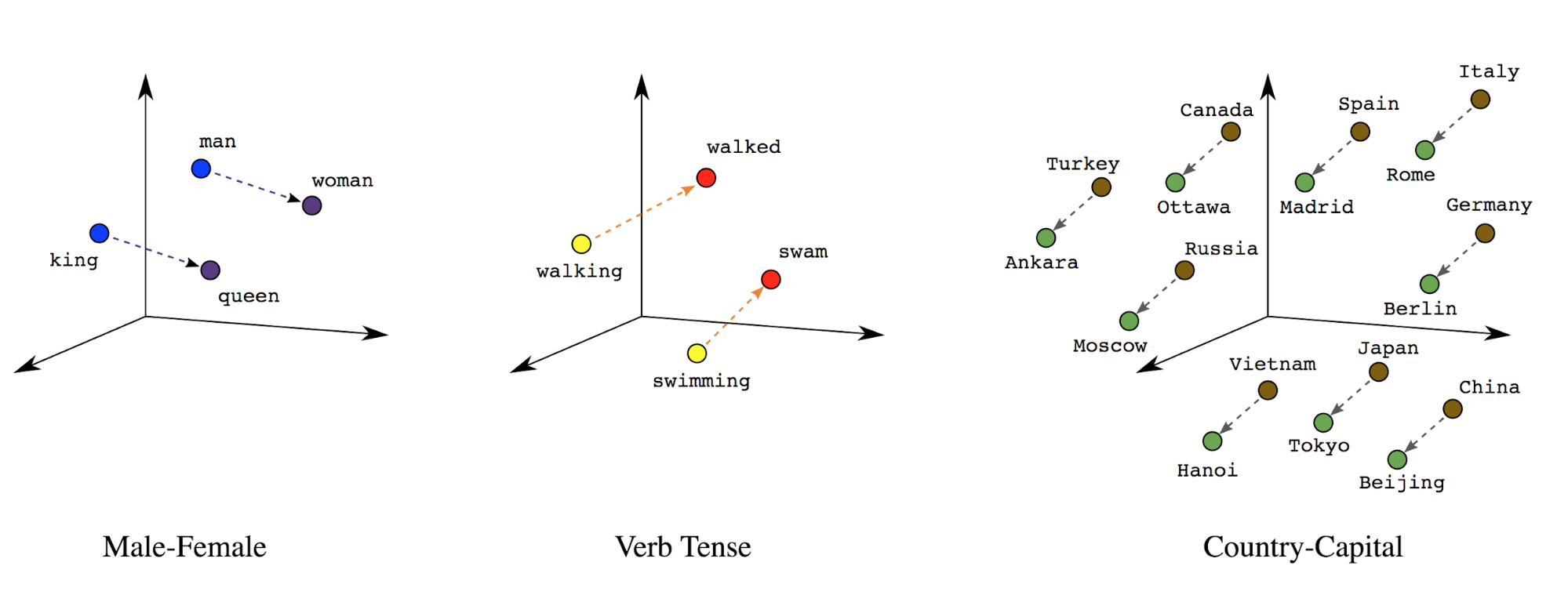
図 7: 単語のエンベディング
シーケンス モデルには多くの場合、最初のレイヤとしてこのようなエンベディング レイヤがあります。この レイヤが、単語インデックス シーケンスを単語のエンベディング ベクトルに変換することを学習します。 各単語インデックスが 2 つの単語の密なベクトルに セマンティック空間におけるその単語の位置を表す実数(図 8 を参照)。
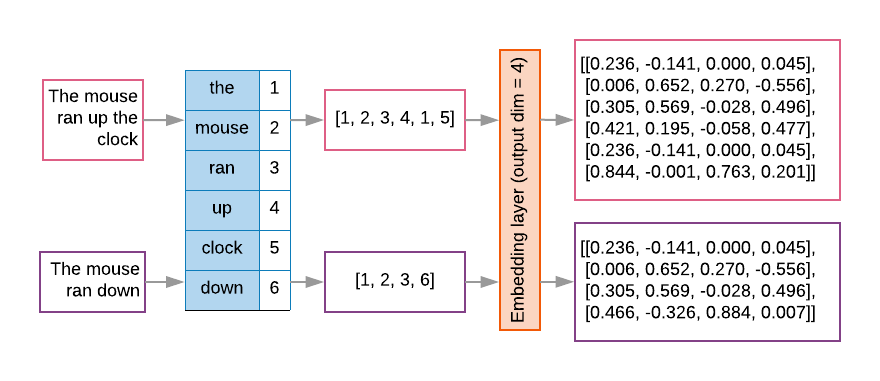
図 8: エンベディング レイヤ
特徴選択
データ内のすべての単語がラベル予測に貢献するわけではありません。自社データを 確率の低い単語や無関係な単語を語彙から捨て、イン 最も頻繁な 20,000 個の特徴量を使用することは、 十分ですこれは、N グラムモデルにも当てはまります(図 6 を参照)。
シーケンス ベクトル化に上記のすべてのステップをまとめましょう。「 これらのタスクを実行するコードは次のようになります。
- テキストを単語にトークン化します
- 上位 20,000 個のトークンを使用して語彙を作成する
- トークンをシーケンス ベクトルに変換する
- シーケンスを固定シーケンス長までパディングする
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
ラベルのベクトル化
サンプル テキストデータを数値ベクトルに変換する方法を学びました。同様のプロセス
必要があります。ラベルを範囲内の値に変換するだけで済みます。
[0, num_classes - 1]。たとえば、3 つのクラスがある場合は、
0、1、2 で表現します内部的には、ネットワークはワンホット
ベクトルを使用してこれらの値を表現します(誤った関係を推測し
です。この表現は損失関数と
レイヤ活性化関数です。この専門講座で、
これらについて説明します。