資料必須先轉換為格式,才能提供給模型 讓模型能理解
首先,我們所收集的資料樣本可能按照特定順序排列。我們自己 不希望任何與樣本順序相關的資訊 說明文字和標籤之間的關係例如,如果資料集已排序 並分為訓練/驗證集 代表資料的整體分佈情形
如要確保模型不受資料順序影響,最簡單的最佳做法就是 在執行其他作業前 一律必須重組資料如果您的資料已經 分為訓練集和驗證集,請務必轉換驗證 方法與轉換訓練資料的方式相同如果還沒有 您可以將樣本分割為兩個獨立的訓練集 隨機播放;通常使用 80% 的樣本進行訓練,20% 用於訓練 驗證。
第二,機器學習演算法將數字做為輸入內容。這表示我們 必須將文字轉換成數值向量您需要完成兩個步驟 這項程序:
符記化:將文字分成文字或較小的副文字, 幫助文字和標籤之間建立良好的一般化關係。 這會決定資料集的「字彙」( 資料)。
向量:定義良好的數值度量,使其具有特徵 文字。
接下來說明如何針對 n 元語法向量和序列執行這兩個步驟 以及如何使用特徵碼將向量表示法最佳化 選擇與正規化技術
N 公克向量 [Option A]
在後續段落中,我們會說明如何權杖化與 n-gram 模型的向量化功能此外,我們也會探討如何最佳化 n- 透過特徵選擇和正規化技術呈現的文法表示法。
在 n 元語法向量中,文字會以一組不重複的 n 元語法表示。
一組相鄰符記 (通常是字詞) 的群組。假設文字為 The mouse ran
up the clock。這裡:
- 一字不差 (n = 1) 為
['the', 'mouse', 'ran', 'up', 'clock']。 - 「大字」字樣 (n = 2) 是
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - 而其他人員也會有資料管理的需求。
代碼化
我們發現,若將文字權杖化為一元語法 + 大字機,就能帶來正面影響 同時減少運算時間的精確度
向量化
將文字樣本分割為 n-grams 後,就需要將這些文字樣本 轉換為機器學習模型可以處理的數值向量範例 下方顯示指派給一元語法和二元數的索引 文字。
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
將索引指派給 n 元語法後,我們通常會使用 下列選項。
One-hot 編碼:每個範例文字都會以表示 是否存在文字中的符記
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
計數編碼:每個範例文字都會以向量表示
文字中的符記數量。請注意,與
一元畫的「the」現在已表示 2,因為 "the"
出現了兩次
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf 編碼:問題 主要是用在類似的方式中 所有文件中的頻率 (例如,不重複的字詞 資料集內的文字樣本) 則不受影響。例如「a」 出現頻率非常高因此,「the」的符記數量比 都不是很有意義的字詞
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(請參閱 Scikit-learn TfidfTransformer)。
還有許多其他向量表示法
我們發現 tf-idf 編碼比 準確度 (平均提高 0.25-15%),建議使用這個方法 用於向量化 n 元語法但請注意,這類記憶體會佔用較多記憶體 (例如 使用浮點表示法) 且需要較多時間運算 以大型資料集來說 (在某些情況下可能需要兩倍時間)。
選取特徵
當我們將資料集中的所有文字轉換為一字 + 方格符記時, 可能會產生數萬個符記部分權杖/功能並非 對標籤預測結果的貢獻我們可以捨棄特定符記 資料集內極少發生的情況你也可以測量 特徵重要性 (每個符記對標籤預測結果的影響程度) 僅包含資訊最豐富的符記
許多統計函式採用特徵, 並輸出特徵重要性分數有兩種常用的函式 f_classif 和 chi2。我們的 實驗顯示,這兩種函式的成效都一樣好。
更重要的是,許多特徵的準確率達到約 20,000 個 資料集 (請參閱圖 6)。達到這個門檻後新增更多地圖項目,有助於 有時甚至會導致 過度配適 且會降低效能

圖 6:主要 K 功能與準確率。如為多個資料集,準確度約為 2 萬個特徵。
正規化
正規化會將所有特徵/範例值轉換為小型和類似的值。 這可簡化學習演算法中的梯度下降法收斂。根據內容 如先前所述,資料預先處理期間的正規化似乎不會增加 無法解決文字分類問題建議您略過這個步驟
以下程式碼集結了以上所有步驟:
- 將文字樣本代碼化為單字 + Bigrams,
- 使用 tf-idf 編碼進行向量化
- 捨棄符記向量中前 20,000 個地圖項目 符記顯示次數不到 2 次,且使用 f_classif 計算特徵 重要性。
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
我們採用 n 元語法向量表示法,因此捨棄了許多字詞相關資訊 排序及文法 (最好能我們保留部分排序資訊 當 n >1)。也就是所謂的簡明扼要。這種表示法 搭配較不考量排序的模型,例如 邏輯迴歸、多層感知、梯度增強機器 支援向量機。
序列向量 [選項 B]
在後續段落中,我們會說明如何權杖化與 以及序列模型的向量化功能我們也會介紹如何最佳化 透過特徵選擇和正規化技術進行序列表示法。
在某些文字樣本中,字詞順序對文字的含意至關重要。適用對象 像是「我以前討厭通勤時,我的新腳踏車改變了 必須用到順序閱讀。CNN/RNN 等型號 能夠根據樣本的字詞順序推論出含意。對於這類模型 會以保留順序的符記序列來表示文字。
代碼化
文字能以一串字元或一系列的字元表示 還能分析語法及擷取語言資訊 例如字詞之間的關係我們發現,使用字詞層級表示法可帶來更好的效果 整體效能比字元符記這是 產業只在文字包含大量文字的情況下,才適合使用字元符記 但其實並非這個情況
向量化
將文字樣本轉換為字詞序列後, 將這些序列轉換為數值向量以下範例顯示索引 一組生成至兩段文字產生的一元公克 將第一個文字轉換成的索引。
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
每個符記指派的索引:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
注意:「the」一詞所以索引值 1 是 。有些程式庫會為未知符記保留索引 0, 或這裡顯示案例
權杖索引的順序:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
有兩種選項可用於向量符記序列:
One-hot 編碼:序列會以 n- 這個詞向量表示 n = 詞彙量大小。這種呈現方式的效果很好 而符記化為字元又太小了 當我們將詞彙符記化時,詞彙通常 導致一次性向量非常稀疏且效率低落 範例:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
嵌入字詞:字詞含意與字詞相關聯。因此 可以表示文字符記在稠密向量空間 (約幾百個實數) 中 其中字詞之間的位置和距離代表字詞的相似程度 語意上下文 (請參閱圖 7)。這種表示法稱為 字詞嵌入。
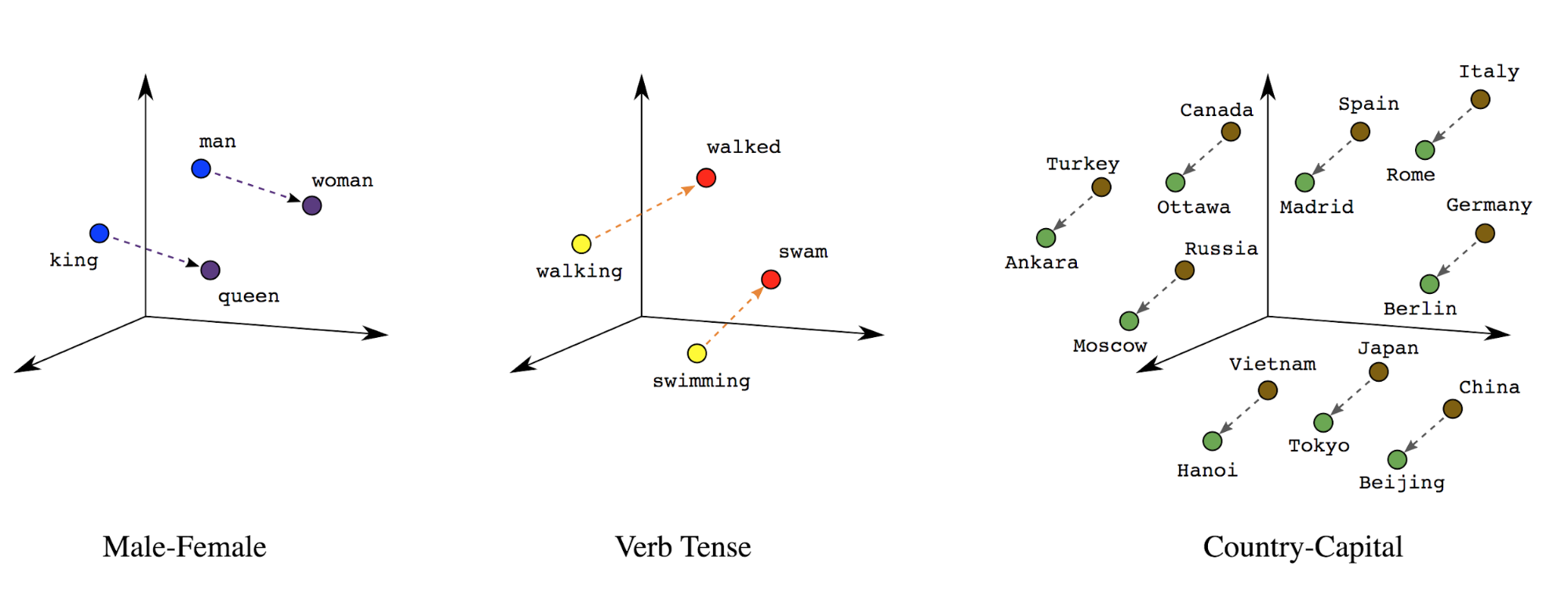
圖 7:字詞嵌入
序列模型的第一層通常會有這樣的嵌入層。這個 模型會學習如何將字詞索引序列 轉換成字詞嵌入向量 確保每個字詞索引都會對應至 表示該字詞在語意空間中的實際值 (請見圖 8)。
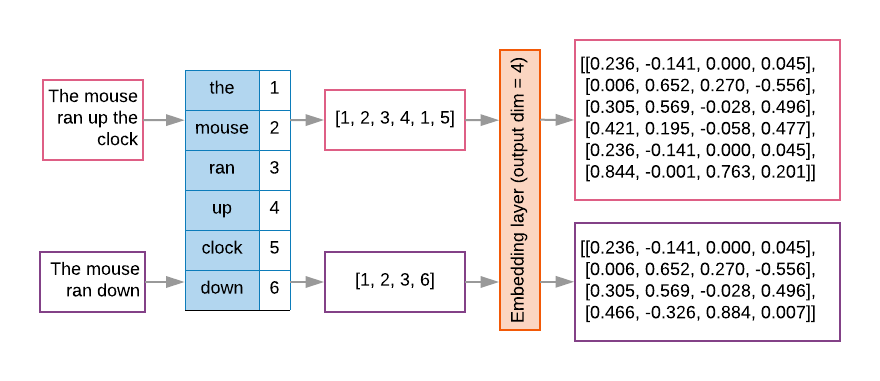
圖 8:嵌入層
選取特徵
並非所有資料都會用於標籤預測。我們可以最佳化 從詞彙中捨棄罕見或不相關的字詞,提升學習體驗。於 事實上,我們發現最常使用 20,000 個功能, 而負責任的 AI 技術做法 有助於達成這項目標這也適用於 n 元語法模型 (請見圖 6)。
讓我們將上述所有步驟以序列向量化。 以下程式碼會執行這些工作:
- 將文字權杖化
- 使用前 20,000 個符記建立詞彙
- 將符記轉換為序列向量
- 將序列固定至固定序列長度
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
標籤向量
我們已經瞭解如何將範例文字資料轉換成數值向量。類似的程序
都必須套用至標籤只要把標籤轉換成
[0, num_classes - 1]。例如,有 3 個類別
值 0、1 和 2 來表示。內部網路則會使用一次性圖片
用來代表這些值的向量 (以避免推斷出錯誤關係)
標籤)。此表示法取決於損失函式和
我們用於類神經網路的資料層啟用函式稍後我們將深入探討
相關內容