Gli algoritmi di classificazione del testo sono il nucleo di vari sistemi software che elaborano i dati di testo su larga scala. Il software email utilizza la classificazione del testo per determinare se la posta in arrivo viene inviata alla Posta in arrivo o filtrata nella cartella Spam. I forum di discussione utilizzano la classificazione del testo per determinare se i commenti devono essere contrassegnati come inappropriati.
Questi sono due esempi di classificazione degli argomenti, che classificano un documento di testo in uno di un insieme predefinito di argomenti. In molti problemi di classificazione degli argomenti, questa classificazione è basata principalmente sulle parole chiave nel testo.
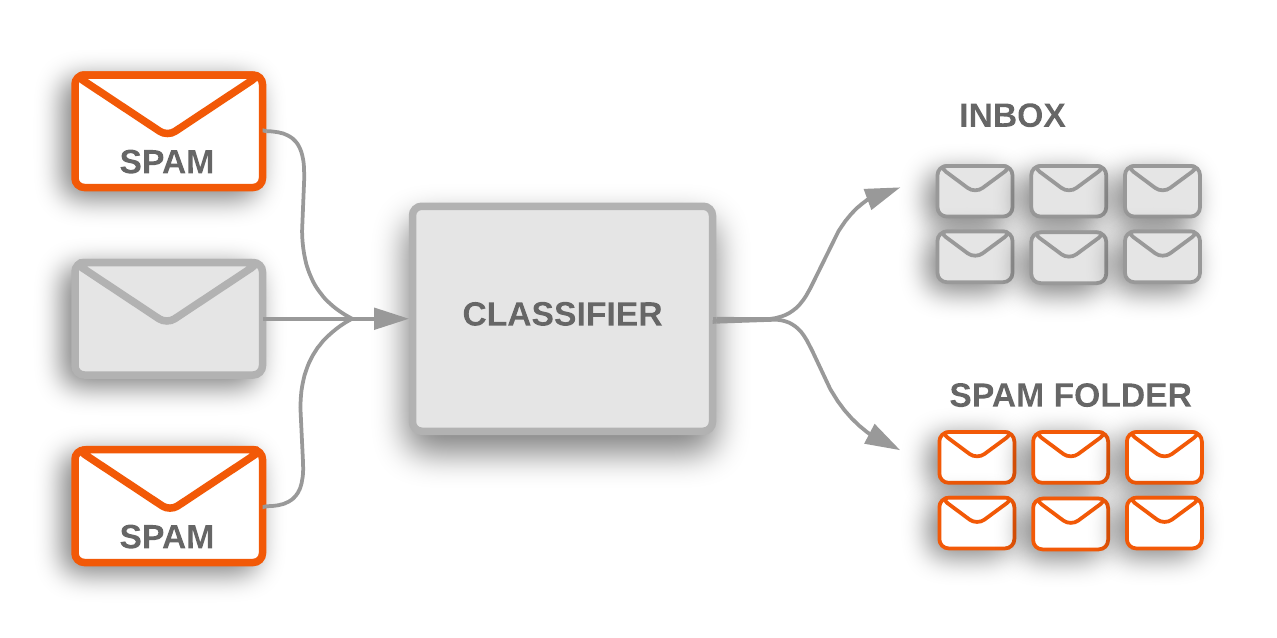
Figura 1: la classificazione degli argomenti viene utilizzata per segnalare le email di spam in arrivo, che vengono filtrate in una cartella Spam.
Un altro tipo comune di classificazione del testo è l'analisi del sentiment, il cui obiettivo è identificare la polarità dei contenuti testuali: il tipo di opinione espresso. Questo può assumere una forma binaria di Mi piace/Non mi piace o un maggior numero di opzioni, come una valutazione a stelle da 1 a 5. Alcuni esempi di analisi del sentiment sono l'analisi dei post di Twitter per determinare se le persone hanno apprezzato il film Black Panther o l'estrapolazione dell'opinione del grande pubblico sulle nuove scarpe di Nike provenienti dalle recensioni di Walmart.
Questa guida illustra alcune importanti best practice per il machine learning per risolvere problemi di classificazione del testo. Ecco cosa imparerai:
- Il flusso di lavoro end-to-end ad alto livello per risolvere i problemi di classificazione del testo utilizzando il machine learning
- Come scegliere il modello giusto per il tuo problema di classificazione del testo
- Come implementare il modello preferito con TensorFlow
Flusso di lavoro di classificazione del testo
Ecco una panoramica generale del flusso di lavoro utilizzato per risolvere i problemi di machine learning:
- Passaggio 1: raccogli i dati
- Passaggio 2: esplora i dati
- Passaggio 2.5: scegli un modello*
- Passaggio 3: prepara i dati
- Passaggio 4: crea, addestra e valuta il modello
- Passaggio 5: ottimizza gli iperparametri
- Passaggio 6: esegui il deployment del modello

Figura 2: flusso di lavoro per risolvere i problemi di machine learning
Le sezioni seguenti spiegano in dettaglio ogni passaggio e come implementarli per i dati di testo.