На этой странице содержатся термины глоссария языковой оценки. Чтобы просмотреть все термины глоссария, нажмите здесь .
А
внимание
Механизм, используемый в нейронной сети , который указывает важность определенного слова или части слова. Внимание сжимает объем информации, необходимой модели для прогнозирования следующего токена/слова. Типичный механизм внимания может состоять из взвешенной суммы по набору входных данных, где вес каждого входного сигнала вычисляется другой частью нейронной сети.
Обратитесь также к самовниманию и многоголовому самовниманию , которые являются строительными блоками Трансформеров .
См . LLM: Что такое большая языковая модель? в ускоренном курсе машинного обучения для получения дополнительной информации о самообслуживании.
автоэнкодер
Система, которая учится извлекать наиболее важную информацию из входных данных. Автоэнкодеры представляют собой комбинацию кодера и декодера . Автоэнкодеры полагаются на следующий двухэтапный процесс:
- Кодер преобразует входные данные в (обычно) низкоразмерный (промежуточный) формат с потерями.
- Декодер создает версию исходного ввода с потерями, сопоставляя формат меньшей размерности с исходным входным форматом более высокой размерности.
Автокодировщики обучаются сквозно, заставляя декодер пытаться как можно точнее восстановить исходный входной сигнал из промежуточного формата кодера. Поскольку промежуточный формат меньше (меньшая размерность), чем исходный формат, автокодировщику приходится узнавать, какая информация на входе важна, и выходные данные не будут полностью идентичны входным.
Например:
- Если входные данные представляют собой графику, неточная копия будет похожа на исходную графику, но несколько изменена. Возможно, неточная копия удаляет шум из исходной графики или заполняет некоторые недостающие пиксели.
- Если входные данные представляют собой текст, автокодировщик сгенерирует новый текст, который имитирует (но не идентичен) исходному тексту.
См. также вариационные автоэнкодеры .
автоматическая оценка
Использование программного обеспечения для оценки качества вывода модели.
Если выходные данные модели относительно просты, сценарий или программа могут сравнить выходные данные модели с золотым ответом . Этот тип автоматической оценки иногда называют программной оценкой . Такие показатели, как ROUGE или BLEU , часто полезны для программной оценки.
Если выходные данные модели сложны или не имеют единственного правильного ответа , отдельная программа машинного обучения, называемая авторейтером, иногда выполняет автоматическую оценку.
Сравните с человеческой оценкой .
авторейтерская оценка
Гибридный механизм оценки качества результатов генеративной модели ИИ , сочетающий человеческую оценку с автоматической оценкой . Авторрейтер — это модель машинного обучения, обученная на данных, полученных в результате оценки человеком . В идеале авторрейтер учится подражать оценщику-человеку.Доступны готовые авторейтинги, но лучшие авторейтинги точно настроены специально для задачи, которую вы оцениваете.
авторегрессионная модель
Модель , которая делает прогноз на основе собственных предыдущих прогнозов. Например, авторегрессионные языковые модели прогнозируют следующий токен на основе ранее предсказанных токенов. Все модели большого языка на основе Transformer являются авторегрессионными.
Напротив, модели изображений на основе GAN обычно не являются авторегрессионными, поскольку они генерируют изображение за один проход вперед, а не поэтапно итеративно. Однако некоторые модели генерации изображений являются авторегрессионными, поскольку они генерируют изображение поэтапно.
средняя точность при k
Метрика для подведения итогов эффективности модели в одном запросе, который генерирует ранжированные результаты, например нумерованный список рекомендаций книг. Средняя точность при k — это среднее значение точности при значениях k для каждого соответствующего результата. Таким образом, формула средней точности при k выглядит следующим образом:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
где:
- \(n\) — количество соответствующих элементов в списке.
Сравните с отзывом в k .
Б
мешок слов
Представление слов во фразе или отрывке независимо от порядка. Например, мешок слов одинаково представляет следующие три фразы:
- собака прыгает
- прыгает на собаку
- собака прыгает
Каждое слово сопоставляется с индексом в разреженном векторе , где вектор имеет индекс для каждого слова в словаре. Например, фраза «собака прыгает» отображается в вектор признаков с ненулевыми значениями по трем индексам, соответствующим словам « собака» и «прыжки» . Ненулевое значение может быть любым из следующих:
- 1 указывает на наличие слова.
- Подсчет количества раз, когда слово появляется в сумке. Например, если фраза «бордовая собака» — это собака с бордовой шерстью , то и «бордовый» , и «собака» будут представлены как 2, а другие слова будут представлены как 1.
- Некоторое другое значение, например логарифм количества раз, которое слово появляется в сумке.
BERT (представления двунаправленного кодировщика от трансформаторов)
Архитектура модели для представления текста. Обученная модель BERT может действовать как часть более крупной модели для классификации текста или других задач машинного обучения.
BERT имеет следующие характеристики:
- Использует архитектуру Transformer и поэтому полагается на самообслуживание .
- Использует кодирующую часть Transformer. Задача кодировщика — создавать хорошие текстовые представления, а не выполнять конкретную задачу, например классификацию.
- Является двунаправленным .
- Использует маскировку для обучения без присмотра .
Варианты BERT включают:
двунаправленный
Термин, используемый для описания системы, которая оценивает текст, который предшествует и следует за целевым разделом текста. Напротив, однонаправленная система оценивает только текст, который предшествует целевому разделу текста.
Например, рассмотрим модель языка в масках , которая должна определять вероятности для слова или слов, представляющих подчеркивание в следующем вопросе:
Что с тобой _____?
Однонаправленная языковая модель должна была бы основывать свои вероятности только на контексте, обеспечиваемом словами «Что», «есть» и «the». Напротив, двунаправленная языковая модель также может получить контекст от слов «с» и «вы», что может помочь модели генерировать более точные прогнозы.
двунаправленная языковая модель
Языковая модель , определяющая вероятность присутствия данного токена в заданном месте во фрагменте текста на основе предыдущего и последующего текста.
биграмма
N-грамма, в которой N=2.
BLEU (дублёр двуязычной оценки)
Метрика от 0,0 до 1,0 для оценки машинного перевода , например, с испанского на японский.
Для расчета оценки BLEU обычно сравнивает перевод модели ML ( сгенерированный текст ) с переводом эксперта ( справочный текст ). Степень соответствия N-грамм в сгенерированном тексте и тексте ссылки определяет оценку BLEU.
Оригинальная статья по этой метрике — BLEU: метод автоматической оценки машинного перевода .
См. также БЛЕРТ .
БЛЕУРТ (дублёр двуязычной оценки из «Трансформеров»)
Метрика для оценки машинного перевода с одного языка на другой, особенно на английский и с английского.
Для переводов на английский и с английского язык BLEURT более точно соответствует человеческим рейтингам, чем BLEU . В отличие от BLEU, BLEURT подчеркивает семантическое (значительное) сходство и допускает перефразирование.
BLEURT опирается на предварительно обученную модель большого языка (точнее, BERT ), которая затем настраивается на текст, полученный от переводчиков-людей.
Оригинальная статья по этой метрике — BLEURT: Learning Robust Metrics for Text Generation .
С
причинно-языковая модель
Синоним однонаправленной языковой модели .
См. двунаправленную языковую модель , чтобы сравнить различные направленные подходы к языковому моделированию.
подсказка по цепочке мыслей
Метод быстрого проектирования , который побуждает большую языковую модель (LLM) шаг за шагом объяснять свои рассуждения. Например, рассмотрите следующую подсказку, уделив особое внимание второму предложению:
Какую силу перегрузки испытает водитель автомобиля, разгоняющегося от 0 до 60 миль в час за 7 секунд? В ответе покажите все соответствующие расчеты.
Ответ LLM, скорее всего, будет следующим:
- Покажите последовательность физических формул, вставляя значения 0, 60 и 7 в соответствующие места.
- Объясните, почему он выбрал именно эти формулы и что означают различные переменные.
Подсказки по цепочке мыслей заставляют LLM выполнять все вычисления, которые могут привести к более правильному ответу. Кроме того, подсказки по цепочке мыслей позволяют пользователю изучить шаги LLM, чтобы определить, имеет ли ответ смысл.
чат
Содержимое двустороннего диалога с системой машинного обучения, обычно это большая языковая модель . Предыдущее взаимодействие в чате (то, что вы набрали и как ответила большая языковая модель) становится контекстом для последующих частей чата.
Чат-бот — это приложение большой языковой модели.
болтовня
Синоним галлюцинации .
Конфабуляция, вероятно, более технически точный термин, чем галлюцинация. Однако первой популярностью стали пользоваться галлюцинации.
разбор избирательного округа
Деление предложения на более мелкие грамматические конструкции («составные»). Более поздняя часть системы машинного обучения, такая как модель понимания естественного языка , может анализировать составляющие легче, чем исходное предложение. Например, рассмотрим следующее предложение:
Мой друг взял двух кошек.
Анализатор избирательного округа может разделить это предложение на следующие две составляющие:
- Мой друг — существительное.
- усыновил двух кошек — это глагольная фраза.
Эти составляющие можно разделить на более мелкие составляющие. Например, глагольная группа
взял двух кошек
можно дополнительно разделить на:
- принято – это глагол.
- две кошки — еще одна существительная группа.
контекстуализированное языковое встраивание
Встраивание , близкое к «пониманию» слов и фраз так, как это могут делать бегло говорящие люди. Контекстуализированные языковые внедрения могут понимать сложный синтаксис, семантику и контекст.
Например, рассмотрим встраивание английского слова «cow» . Старые внедрения, такие как word2vec, могут представлять английские слова таким образом, что расстояние в пространстве встраивания от коровы до быка аналогично расстоянию от овцы (овцы-самки) до барана (овцы-самцы) или от самки до самца . Контекстуализированные языковые встраивания могут пойти еще дальше, признав, что носители английского языка иногда случайно используют слово «корова» для обозначения либо коровы, либо быка.
контекстное окно
Количество токенов , которые модель может обработать в заданном приглашении . Чем больше контекстное окно, тем больше информации модель может использовать для предоставления последовательных и последовательных ответов на запрос.
крах цветения
Предложение или фраза с неоднозначным смыслом. Цветение сбоев представляет собой серьезную проблему в понимании естественного языка . Например, заголовок «Красная лента держит небоскреб» — это настоящий крах, потому что модель NLU может интерпретировать заголовок буквально или фигурально.
Д
декодер
В общем, любая система машинного обучения, которая преобразуется из обработанного, плотного или внутреннего представления в более необработанное, разреженное или внешнее представление.
Декодеры часто являются компонентами более крупных моделей, где они часто работают в паре с кодером .
В задачах преобразования последовательности в последовательность декодер начинает с внутреннего состояния, сгенерированного кодером, для прогнозирования следующей последовательности.
Обратитесь к Transformer для определения декодера в архитектуре Transformer.
Дополнительные сведения см. в разделе «Большие языковые модели» в ускоренном курсе машинного обучения.
шумоподавление
Общий подход к самостоятельному обучению, при котором:
Шумоподавление позволяет учиться на немаркированных примерах . Исходный набор данных служит целью или меткой , а зашумленные данные — входными данными.
Некоторые модели языка в масках используют шумоподавление следующим образом:
- Шум искусственно добавляется к непомеченному предложению путем маскировки некоторых токенов.
- Модель пытается предсказать исходные токены.
прямое побуждение
Синоним подсказки с нулевым выстрелом .
Э
изменить расстояние
Измерение того, насколько похожи две текстовые строки друг на друга. В машинном обучении расстояние редактирования полезно по следующим причинам:
- Расстояние редактирования легко вычислить.
- Расстояние редактирования позволяет сравнивать две строки, которые, как известно, похожи друг на друга.
- Расстояние редактирования может определять степень сходства различных строк с данной строкой.
Существует несколько определений расстояния редактирования, каждое из которых использует разные строковые операции. См. пример расстояния Левенштейна .
слой внедрения
Специальный скрытый слой , который обучается на многомерном категориальном признаке для постепенного изучения вектора внедрения более низкого измерения. Слой внедрения позволяет нейронной сети обучаться гораздо эффективнее, чем обучение только на многомерном категориальном признаке.
Например, на Земле в настоящее время произрастает около 73 000 видов деревьев. Предположим, что виды деревьев являются признаком вашей модели, поэтому входной слой вашей модели включает в себя вектор длиной 73 000 элементов. Например, возможно, baobab можно было бы представить примерно так:

Массив из 73 000 элементов очень длинный. Если вы не добавите в модель слой внедрения, обучение займет очень много времени из-за умножения 72 999 нулей. Возможно, вы выберете слой внедрения, состоящий из 12 измерений. Следовательно, слой внедрения постепенно изучает новый вектор внедрения для каждой породы деревьев.
В определенных ситуациях хеширование является разумной альтернативой слою внедрения.
Дополнительную информацию см. в разделе « Внедрения в ускоренный курс машинного обучения».
пространство для встраивания
Сопоставляется d-мерное векторное пространство, являющееся частью векторного пространства более высокой размерности. Пространство внедрения обучено захвату структуры, значимой для предполагаемого приложения.
Скалярное произведение двух вложений является мерой их сходства.
вектор внедрения
Грубо говоря, массив чисел с плавающей запятой, взятый из любого скрытого слоя и описывающий входные данные этого скрытого слоя. Часто вектор внедрения представляет собой массив чисел с плавающей запятой, обученный на слое внедрения. Например, предположим, что слой внедрения должен изучить вектор внедрения для каждого из 73 000 видов деревьев на Земле. Возможно, следующий массив является вектором внедрения дерева баобаба:

Вектор внедрения — это не набор случайных чисел. Слой внедрения определяет эти значения посредством обучения, аналогично тому, как нейронная сеть изучает другие веса во время обучения. Каждый элемент массива представляет собой рейтинг по некоторой характеристике породы дерева. Какой элемент представляет характеристику какой породы деревьев? Людям это очень трудно определить.
Математически примечательная часть вектора внедрения заключается в том, что аналогичные элементы имеют одинаковые наборы чисел с плавающей запятой. Например, похожие породы деревьев имеют более похожий набор чисел с плавающей запятой, чем разные породы деревьев. Секвойи и секвойи являются родственными породами деревьев, поэтому у них будет более похожий набор чисел с плавающей запятой, чем у секвой и кокосовых пальм. Числа в векторе внедрения будут меняться каждый раз, когда вы переобучаете модель, даже если вы переобучаете модель с идентичными входными данными.
кодер
В общем, любая система машинного обучения, которая преобразует необработанное, разреженное или внешнее представление в более обработанное, более плотное или более внутреннее представление.
Кодеры часто являются компонентом более крупной модели, где они часто работают в паре с декодером . Некоторые Трансформеры объединяют кодеры с декодерами, хотя другие Трансформеры используют только кодер или только декодер.
Некоторые системы используют выходные данные кодировщика в качестве входных данных для сети классификации или регрессии.
В задачах «последовательность-последовательность» кодер принимает входную последовательность и возвращает внутреннее состояние (вектор). Затем декодер использует это внутреннее состояние для прогнозирования следующей последовательности.
Обратитесь к Transformer для определения кодера в архитектуре Transformer.
Дополнительную информацию см. в разделе LLM: Что такое большая языковая модель в ускоренном курсе машинного обучения.
оценивает
В основном используется как аббревиатура для оценок LLM . В более широком смысле, evals — это аббревиатура, обозначающая любую форму оценки .
оценка
Процесс измерения качества модели или сравнения различных моделей друг с другом.
Чтобы оценить модель контролируемого машинного обучения , вы обычно сравниваете ее с набором проверки и набором тестов . Оценка LLM обычно включает в себя более широкую оценку качества и безопасности.
Ф
подсказка из нескольких кадров
Приглашение , содержащее более одного («несколько») примеров, демонстрирующих, как должна реагировать большая языковая модель . Например, следующая длинная подсказка содержит два примера, показывающие большую языковую модель, как отвечать на запрос.
| Части одной подсказки | Примечания |
|---|---|
| Какая официальная валюта указанной страны? | Вопрос, на который вы хотите получить ответ от LLM. |
| Франция: евро | Один пример. |
| Великобритания: фунт стерлингов. | Другой пример. |
| Индия: | Фактический запрос. |
Подсказки с небольшим количеством шагов обычно дают более желательные результаты, чем подсказки с нулевым шагом и одноразовые подсказки . Однако подсказка с несколькими выстрелами требует более длинной подсказки.
Подсказки в несколько этапов — это форма обучения в несколько этапов, применяемая к обучению на основе подсказок .
Дополнительную информацию см. в разделе «Быстрое проектирование» в ускоренном курсе машинного обучения.
скрипка
Библиотека конфигурации, ориентированная на Python, которая устанавливает значения функций и классов без инвазивного кода или инфраструктуры. В случае Pax и других баз кода ML эти функции и классы представляют модели и гиперпараметры обучения .
Фиддл предполагает, что базы кода машинного обучения обычно делятся на:
- Код библиотеки, определяющий слои и оптимизаторы.
- «Склеивающий» код набора данных, который вызывает библиотеки и связывает все воедино.
Fiddle фиксирует структуру вызовов связующего кода в неоцененной и изменяемой форме.
тонкая настройка
Второй проход обучения для конкретной задачи, выполняемый на предварительно обученной модели для уточнения ее параметров для конкретного варианта использования. Например, полная последовательность обучения для некоторых больших языковых моделей выглядит следующим образом:
- Предварительное обучение: обучите большую языковую модель на обширном общем наборе данных, например на всех англоязычных страницах Википедии.
- Точная настройка: обучение предварительно обученной модели выполнению конкретной задачи, например ответа на медицинские запросы. Точная настройка обычно включает сотни или тысячи примеров, ориентированных на конкретную задачу.
В качестве другого примера полная последовательность обучения для модели большого изображения выглядит следующим образом:
- Предварительное обучение: обучите большую модель изображения на обширном общем наборе данных изображений, например на всех изображениях в Wikimedia Commons.
- Точная настройка: обучение предварительно обученной модели выполнению конкретной задачи, например генерации изображений косаток.
Точная настройка может включать любую комбинацию следующих стратегий:
- Изменение всех существующих параметров предварительно обученной модели. Иногда это называют полной тонкой настройкой .
- Изменение только некоторых существующих параметров предварительно обученной модели (обычно слоев, ближайших к выходному слою ), сохраняя при этом другие существующие параметры неизменными (обычно слои, ближайшие к входному слою ). См. настройку с эффективным использованием параметров .
- Добавление дополнительных слоев, обычно поверх существующих слоев, ближайших к выходному слою.
Точная настройка — это форма трансферного обучения . Таким образом, при точной настройке может использоваться другая функция потерь или другой тип модели, чем те, которые используются для обучения предварительно обученной модели. Например, вы можете точно настроить предварительно обученную модель большого изображения для создания регрессионной модели, которая возвращает количество птиц во входном изображении.
Сравните и сопоставьте тонкую настройку со следующими терминами:
Дополнительные сведения см. в разделе «Точная настройка ускоренного курса машинного обучения».
Лен
Высокопроизводительная библиотека с открытым исходным кодом для глубокого обучения, построенная на основе JAX . Flax предоставляет функции для обучения нейронных сетей , а также методы оценки их производительности.
льноформер
Библиотека Transformer с открытым исходным кодом, построенная на Flax и предназначенная в первую очередь для обработки естественного языка и мультимодальных исследований.
Г
Близнецы
Экосистема, включающая самый передовой искусственный интеллект Google. К элементам этой экосистемы относятся:
- Различные модели Gemini .
- Интерактивный диалоговый интерфейс модели Gemini . Пользователи вводят запросы, и Gemini отвечает на эти запросы.
- Различные API Gemini.
- Различные бизнес-продукты на основе моделей Gemini; например, Gemini для Google Cloud .
Модели Близнецов
Новейшие мультимодальные модели Google на основе Transformer . Модели Gemini специально разработаны для интеграции с агентами .
Пользователи могут взаимодействовать с моделями Gemini различными способами, в том числе через интерактивный диалоговый интерфейс и через SDK.
сгенерированный текст
В общем, текст, который выводит модель машинного обучения. При оценке больших языковых моделей некоторые метрики сравнивают сгенерированный текст с ссылочным текстом . Например, предположим, что вы пытаетесь определить, насколько эффективно модель машинного обучения переводится с французского на голландский. В этом случае:
- Сгенерированный текст представляет собой голландский перевод, который выводит модель машинного обучения.
- Справочный текст — это голландский перевод, созданный переводчиком-человеком (или программным обеспечением).
Обратите внимание, что некоторые стратегии оценки не включают справочный текст.
генеративный ИИ
Возникающее преобразующее поле без формального определения. Тем не менее, большинство экспертов сходятся во мнении, что генеративные модели ИИ могут создавать («генерировать») контент, который имеет все следующие характеристики:
- сложный
- последовательный
- оригинальный
Например, генеративная модель ИИ может создавать сложные эссе или изображения.
Некоторые более ранние технологии, включая LSTM и RNN , также могут генерировать оригинальный и связный контент. Некоторые эксперты рассматривают эти более ранние технологии как генеративный ИИ, в то время как другие считают, что настоящий генеративный ИИ требует более сложных результатов, чем те, которые могут произвести более ранние технологии.
Сравните с прогнозным ML .
золотой ответ
Заведомо хороший ответ. Например, учитывая следующую подсказку :
2 + 2
Надеемся, что золотой ответ будет следующим:
4
GPT (Генераторный предварительно обученный трансформатор)
Семейство больших языковых моделей на основе Transformer , разработанное OpenAI .
Варианты GPT могут применяться к нескольким модальностям , в том числе:
- генерация изображений (например, ImageGPT)
- генерация текста в изображение (например, DALL-E ).
ЧАС
галлюцинация
Производство кажущихся правдоподобными, но на самом деле неверных результатов с помощью генеративной модели ИИ , которая якобы делает утверждение о реальном мире. Например, генеративная модель искусственного интеллекта, утверждающая, что Барак Обама умер в 1865 году, является галлюцинацией .
человеческая оценка
Процесс, в котором люди оценивают качество результатов модели ML; например, двуязычные люди оценивают качество модели перевода ML. Человеческая оценка особенно полезна для оценки моделей, которые не имеют единственного правильного ответа .
Сравните с автоматической оценкой и оценкой авторами .
я
обучение в контексте
Синоним «подсказки с несколькими выстрелами» .
л
LaMDA (Языковая модель для диалоговых приложений)
Модель большого языка на основе Transformer , разработанная Google, обученная на большом наборе диалоговых данных, которая может генерировать реалистичные разговорные ответы.
LaMDA: наша революционная технология общения дает обзор.
языковая модель
Модель , которая оценивает вероятность появления токена или последовательности токенов в более длинной последовательности токенов.
См. раздел Что такое языковая модель? в ускоренном курсе машинного обучения для получения дополнительной информации.
большая языковая модель
Как минимум, языковая модель , имеющая очень большое количество параметров . Говоря более неформально, любая языковая модель на основе Transformer , например Gemini или GPT .
Дополнительные сведения см. в разделе «Большие языковые модели (LLM)» в ускоренном курсе машинного обучения.
скрытое пространство
Синоним встраивания пространства .
Расстояние Левенштейн
Метрика расстояния редактирования , которая рассчитывает наименьшее количество операций удаления, вставки и замены, необходимых для замены одного слова на другое. Например, расстояние Левенштейна между словами «сердце» и «дротики» равно трем, потому что следующие три редактирования — это наименьшее количество изменений, позволяющих превратить одно слово в другое:
- сердце → дорогая (замените «h» на «d»)
- дорогой → дротик (удалить «е»)
- дротик → дартс (вставить «s»)
Обратите внимание, что предыдущая последовательность — не единственный путь из трех изменений.
Магистр права
Аббревиатура для большой языковой модели .
LLM оценки (оценки)
Набор метрик и тестов для оценки производительности больших языковых моделей (LLM). На высоком уровне оценки LLM:
- Помогите исследователям определить области, где LLM нуждается в улучшении.
- Полезны для сравнения различных LLM и определения лучшего LLM для конкретной задачи.
- Помогите гарантировать, что использование LLM безопасно и этически.
Дополнительные сведения см. в разделе «Большие языковые модели (LLM)» в ускоренном курсе машинного обучения.
ЛоРА
Аббревиатура для адаптивности низкого ранга .
Адаптивность низкого ранга (LoRA)
Эффективный по параметрам метод точной настройки , который «замораживает» предварительно обученные веса модели (таким образом, что их больше нельзя изменить), а затем вставляет в модель небольшой набор обучаемых весов. Этот набор обучаемых весов (также известный как «матрицы обновления») значительно меньше базовой модели и поэтому обучается гораздо быстрее.
LoRA предоставляет следующие преимущества:
- Улучшает качество прогнозов модели для области, к которой применяется точная настройка.
- Точная настройка выполняется быстрее, чем методы, требующие точной настройки всех параметров модели.
- Снижает вычислительные затраты на вывод , позволяя одновременно обслуживать несколько специализированных моделей, использующих одну и ту же базовую модель.
М
модель языка в масках
Языковая модель , которая прогнозирует вероятность того, что токены-кандидаты заполнят пробелы в последовательности. Например, модель замаскированного языка может вычислить вероятность того, что слова-кандидаты заменят подчеркивание в следующем предложении:
____ в шляпе вернулся.
В литературе обычно вместо подчеркивания используется строка «МАСКА». Например:
"МАСКА" в шапке вернулась.
Большинство современных моделей замаскированного языка являются двунаправленными .
средняя средняя точность при k (mAP@k)
Статистическое среднее всей средней точности при k баллах в наборе проверочных данных. Одним из использования средней средней точности в K является оценка качества рекомендаций, генерируемых системой рекомендаций .
Хотя фраза «средний средний» звучит избыточно, имя метрики подходит. В конце концов, этот показатель находит среднее значение множественной средней точности при значениях K.
Мета-обучение
Подмножество машинного обучения, которое обнаруживает или улучшает алгоритм обучения. Система мета-обучения также может стремиться к обучению модели для быстрого изучения новой задачи из небольшого количества данных или из-за опыта, полученного в предыдущих задачах. Алгоритмы мета-обучения обычно пытаются достичь следующего:
- Улучшить или изучить ручные функции (такие как инициализатор или оптимизатор).
- Будьте более эффективными и вычислимыми.
- Улучшить обобщение.
Мета-обучение связано с несколькими выстрелами .
смесь экспертов
Схема повышения эффективности нейронной сети, используя только подмножество параметров (известных как эксперт ) для обработки данного входного токена или примера . Сетевая сеть маршрутирует каждый входной токен или пример для соответствующего эксперта.
Для получения подробной информации см. Любую из следующих документов:
- Возмутительно крупные нейронные сети: редко управляемая смесь-эксперт слоя
- Смеси экспертов с экспертным выбором маршрутизации
Мит
Сокращение для мультимодальной инструкции .
модальность
Категория данных высокого уровня. Например, цифры, текст, изображения, видео и аудио - это пять различных модальностей.
модель параллелизма
Способ масштабирования обучения или вывода, который ставит разные части одной модели на разные устройства . Параллелизм модели позволяет слишком большим моделям, чтобы соответствовать одному устройству.
Чтобы реализовать параллелизм модели, система обычно выполняет следующее:
- Шарсы (делят) модель на более мелкие части.
- Распределяет обучение этих небольших деталей по нескольким процессорам. Каждый процессор обучает свою часть модели.
- Сочетает результаты, чтобы создать одну модель.
Модель параллелизма замедляет тренировки.
См. Также параллелизм данных .
Мо
Сокращение для смеси экспертов .
мульти-головное самопринятие
Расширение самоубийства , которое применяет механизм самостоятельного прихода несколько раз для каждой позиции в входной последовательности.
Трансформеры ввели мульти-головное самоуничтожение.
Мультимодальная инструкция
Модель , настроенная на инструкции , которая может обрабатывать ввод за пределами текста, такой как изображения, видео и аудио.
Мультимодальная модель
Модель, входные данные, выходы или оба включают в себя более одного модальности . Например, рассмотрим модель, которая принимает как изображение, так и текстовую подпись (два модальности) в качестве функций , и выводит оценку, указывающую, насколько уместна текстовая подпись для изображения. Таким образом, входные данные этой модели являются мультимодальными, а выход - унимодальный.
Н
обработка естественного языка
Область обучения компьютеров для обработки того, что сказал пользователь или напечатал, используя лингвистические правила. Почти вся современная обработка естественного языка зависит от машинного обучения.Понимание естественного языка
Подмножество обработки естественного языка , которая определяет намерения чего -то сказанного или напечатанного. Понимание естественного языка может выходить за рамки обработки естественного языка, чтобы рассмотреть сложные аспекты языка, такие как контекст, сарказм и настроения.
N-грамм
Упорядоченная последовательность n слов. Например, по-настоящему безумно 2 грамм. Поскольку порядок актуально, безумно отличается от 2 грамма, чем по-настоящему безумно .
| Н | Имя (ы) для такого рода n-грамма | Примеры |
|---|---|---|
| 2 | Биграм или 2 грамм | пойти, ходить, пообедать, поужинать |
| 3 | Триграмма или 3 грамма | ел слишком много, счастливо, когда |
| 4 | 4-грамм | Прогулка в парке, пыль на ветру, мальчик съел чечевицу |
Многие модели понимания естественного языка полагаются на n-граммы, чтобы предсказать следующее слово, которое пользователь напечатает или скажет. Например, предположим, что пользователь счастливо напечатал. Модель NLU, основанная на триграммах, скорее всего, предскажет, что пользователь будет в следующем введите слово после .
Контрастные n-граммы с пакетом слов , которые являются неупорядоченными наборами слов.
См. Большие языковые модели в курсе по сбою машинного обучения для получения дополнительной информации.
НЛП
Аббревиатура для обработки естественного языка .
НЛУ
Сокращение для понимания естественного языка .
никто не правильный ответ (Нора)
Подсказка имеет несколько подходящих ответов. Например, в следующей подсказке нет единого правильного ответа:
Расскажи мне шутку о слонах.
Оценка подсказок с одним правом ответом может быть сложной задачей.
НОРА
Аббревиатура ни за один правильный ответ .
О
Один выстрел побуждение
Подсказка , которая содержит один пример, демонстрирующий, как должна отвечать большая языковая модель . Например, следующая подсказка содержит один пример, показывающий большую языковую модель, как она должна ответить на запрос.
| Части одного подсказки | Примечания |
|---|---|
| Какова официальная валюта указанной страны? | Вопрос, на который вы хотите ответить LLM. |
| Франция: евро | Один пример. |
| Индия: | Фактический запрос. |
Сравните и сопоставьте один выстрел с следующими терминами:
П
Параметр-эффективная настройка
Набор методов для тонкой настройки большой предварительно обученной языковой модели (PLM) более эффективно, чем полная тонкая настройка . Параметр-эффективная настройка обычно тонко настратывает гораздо меньше параметров , чем полная точная настройка, но обычно производит большую языковую модель , которая также работает (или почти также) как большая языковая модель, построенная из полной точной настройки.
Сравните и сопоставьте настройку параметров с:
Параметр-эффективная настройка также известна как эффективная настройка параметров .
трубопровод
Форма параллелизма модели , в которой обработка модели разделена на последовательные этапы, и каждый этап выполняется на другом устройстве. В то время как этап обрабатывает одну партию, предыдущая стадия может работать на следующей партии.
Смотрите также поэтапное обучение .
ПЛМ
Аббревиатура для предварительно обученной языковой модели .
позиционное кодирование
Метод добавления информации о положении токена в последовательности в встраивание токена. Модели трансформаторов используют позиционное кодирование, чтобы лучше понять взаимосвязь между различными частями последовательности.
В общей реализации позиционного кодирования используется синусоидальная функция. (В частности, частота и амплитуда синусоидальной функции определяются положением токена в последовательности.) Этот метод позволяет модели трансформатора научиться заниматься различными частями последовательности на основе их позиции.
Пост обученная модель
Свободно определенный термин, который обычно относится к предварительно обученной модели , которая прошла через некоторую постобработку, такую как одно или несколько из следующих:
Точность в K (Precision@K)
Метрика для оценки рангового (упорядоченного) списка элементов. Точность в K идентифицирует долю первых k элементов в этом списке, которые являются «актуальными». То есть:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Значение k должно быть меньше или равно длине возвращаемого списка. Обратите внимание, что длина возвращаемого списка не является частью расчета.
Актуальность часто субъективна; Даже опытные оценщики человека часто не согласны с тем, какие предметы актуальны.
Сравните с:
Предварительно обученная модель
Как правило, модель, которая уже была обучена . Этот термин также может означать ранее обученный вектор встраивания .
Термин предварительно обученный языковой модель обычно относится к уже обученной большой языковой модели .
предварительное обучение
Первоначальная подготовка модели на большом наборе данных. Некоторые предварительно обученные модели являются неуклюжими гигантами и обычно должны быть уточнены посредством дополнительного обучения. Например, эксперты ML могут предварительно обучить большую языковую модель в обширном текстовом наборе данных, например, все английские страницы в Википедии. После предварительного обучения полученная модель может быть дополнительно уточнена с помощью любого из следующих методов:
быстрый
Любой текст, введенный в качестве ввода в большую языковую модель , чтобы поддерживать модель, чтобы вести себя определенным образом. Подсказки могут быть такими же короткими, как фраза или произвольно длинные (например, весь текст романа). Подсказки делятся на несколько категорий, в том числе показанные в следующей таблице:
| Быстрое категория | Пример | Примечания |
|---|---|---|
| Вопрос | Как быстро может летать голубь? | |
| Инструкция | Напишите забавное стихотворение об арбитраже. | Подсказка, которая просит большую языковую модель что -то сделать . |
| Пример | Перевести код разметки в HTML. Например: Markdown: * Список элемента Html: <ul> <li> Список элемента </li> </ul> | Первым предложением в этом примере подсказка является инструкция. Остальная часть подсказки является примером. |
| Роль | Объясните, почему градиент спуск используется в обучении машинного обучения для доктора философии. | Первая часть предложения - это инструкция; Фраза «до доктора философии» - это роль. |
| Частичный вход для модели для завершения | Премьер -министр Соединенного Королевства живет в | Частичная подсказка ввода может либо резко заканчиваться (как это делает этот пример), либо заканчиваться подчеркиванием. |
Генеративная модель искусственного интеллекта может ответить на подсказку с текстом, кодом, изображениями, встраиванием , видео ... почти чем угодно.
быстрое обучение
Возможность определенных моделей , которые позволяют им адаптировать свое поведение в ответ на произвольный ввод текста ( подсказка ). В типичной парадигме обучения на основе быстрого обучения крупная языковая модель реагирует на подсказку, генерируя текст. Например, предположим, что пользователь входит в следующую подсказку:
Суммируйте третий закон Ньютона.
Модель, способная к быстрому обучению на основе быстрого обучения, не обучена ответить на предыдущую подсказку. Скорее, модель «знает» много фактов о физике, о многом общих языковых правилах и многое о том, что в целом представляет собой полезные ответы. Этого знания достаточно, чтобы дать (надеюсь) полезный ответ. Дополнительные отзывы человека («Этот ответ был слишком сложным». Или «Что такое реакция?») Позволяет некоторым быстрым системам обучения постепенно повышать полезность своих ответов.
быстрый дизайн
Синоним для быстрого инженера .
оперативная инженерия
Искусство создания подсказок , которые вызывают желаемые ответы из большой языковой модели . Люди выполняют быструю инженерию. Написание хорошо структурированных подсказок является неотъемлемой частью обеспечения полезных ответов из крупной языковой модели. Обратная техническая инженерия зависит от многих факторов, в том числе:
- Набор данных, используемый для предварительного обучения и, возможно, настраивать модель большого языка.
- Температура и другие параметры декодирования, которые модель использует для генерации ответов.
Щелкий дизайн является синонимом быстрого проектирования.
См. Введение в inmport Design для получения более подробной информации о написании полезных подсказок.
быстрое настройка
Параметр эффективный механизм настройки , который изучает «префикс», который система приносит к фактической подсказке .
Один вариант быстрого настройки - иногда называемый настройкой префикса - состоит в том, чтобы подготовить префикс на каждом слое . Напротив, большинство быстрого настройки только добавляет префикс к входному слою .
Р
Напомним в K (Remeply@K)
Метрика для оценки систем, которые выводят рантин (упорядоченный) список элементов. Напомним, что в K определяет долю соответствующих элементов в первых k пунктах в этом списке из общего числа возвращаемых соответствующих элементов.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Контраст с точностью в k .
Справочный текст
Ответ эксперта на подсказку . Например, учитывая следующую подсказку:
Переведите вопрос "как вас зовут?" от английского до французского.
Ответ эксперта может быть:
Комментарий Vous Appelez-Vous?
Различные метрики (такие как Rouge ) измеряют степень, в которой эталонный текст соответствует генерируемому тексту ML -модели.
Роль подсказка
Необязательная часть подсказки , которая идентифицирует целевую аудиторию для реакции генеративной модели ИИ . Без ролевой подсказки крупная языковая модель предоставляет ответ, который может быть или не быть полезным для человека, задающего вопросы. Благодаря ролевой подсказке, большая языковая модель может ответить более уместным и более полезным для конкретной целевой аудитории. Например, ролевая часть следующих подсказок находится в жирном шрифте:
- Суммируйте этот документ для доктора наук в области экономики .
- Опишите, как приливы работают для десятилетнего .
- Объясните финансовый кризис 2008 года. Говорите, как вы могли бы маленького ребенка или золотистого ретривера.
Rouge (отзыв, ориентированная на отзыв, для расстояния оценки)
Семейство показателей, которые оценивают автоматическую суммирование и модели машинного перевода . Метрики Rouge определяют степень, в которой эталонный текст перекрывает текст сгенерированного модели ML. Каждый член семейных мер Rouge перекрывается по -разному. Более высокие оценки Rouge указывают на большее сходство между эталонным текстом и сгенерированным текстом, чем более низкие оценки Rouge.
Каждый член семьи Rouge обычно генерирует следующие показатели:
- Точность
- Отзывать
- F 1
Для получения подробной информации и примеров см.
Rouge-L
Член семьи Руж сосредоточился на продолжительности самой длинной общей последующей последовательности в эталонном тексте и сгенерированном тексту . Следующие формулы рассчитывают отзыв и точность для Rouge-L:
Затем вы можете использовать F 1 , чтобы свернуть отзыв Rouge-L и точность Rouge-L в одну метрику:
Rouge-L игнорирует любые новеньши в эталонном тексте и сгенерированный текст, поэтому самая длинная общая последовательность может пересекать несколько предложений. Когда ссылочный текст и сгенерированный текст включают несколько предложений, изменение Rouge-L, называемое Rouge-LSUM, как правило, является лучшей метрикой. Rouge-LSUM определяет самую длинную общую последующую последовательность для каждого предложения в отрывке, а затем вычисляет среднее значение для самых длинных общих подпоследований.
Rouge-n
Набор метрик в семействе Rouge , который сравнивает общие N-граммы определенного размера в эталонном тексте и сгенерированном тексту . Например:
- Rouge-1 измеряет количество общих токенов в эталонном тексте и сгенерированном тексту.
- Rouge-2 измеряет количество общих биграм (2 грамма) в эталонном тексте и сгенерированном тексту.
- Rouge-3 измеряет количество общих триграмм (3 грамма) в эталонном тексте и сгенерированном тексту.
Вы можете использовать следующие формулы для расчета Rouge-N Recall и Rouge-N. Точность для любого члена семьи Rouge-N:
Затем вы можете использовать F 1 , чтобы свернуть Rouge-n Remoad и Rouge-N. Точность в одну метрику:
Rouge-S.
Прощающая форма Rouge-n , которая позволяет сопоставлять скип-грамм . То есть Rouge-N считает только N-граммы , которые точно соответствуют, но Rouge-S также считает N-граммы, разделенные одним или несколькими словами. Например, рассмотрим следующее:
- Справочный текст : белые облака
- сгенерированный текст : белые вздымающиеся облака
При расчете Rouge-N 2-граммовые белые облака не соответствуют белым вздымающимся облакам . Однако при расчете Rouge-S белые облака соответствуют белым вздымающимся облакам .
С
Самоализация (также называется слоем самоуправления)
Слой нейронной сети, который превращает последовательность встраиваний (например, встроения токенов ) в другую последовательность встраиваний. Каждое встраивание в выходную последовательность построена путем интеграции информации из элементов входной последовательности с помощью механизма внимания .
Самостоятельная часть самопринимания относится к последовательности, присутствующей на себе, а не к какому-либо другому контексту. Самоализация является одним из основных строительных блоков для трансформаторов и использует терминологию поиска словаря, такую как «запрос», «ключ» и «ценность».
Слои с самопринятым начинается с последовательности входных представлений, по одному для каждого слова. Входное представление для слова может быть простым внедрением. Для каждого слова в входной последовательности сеть оценивает актуальность слова для каждого элемента во всей последовательности слов. Оценки актуальности определяют, насколько окончательное представление слова включает представления других слов.
Например, рассмотрим следующее предложение:
Животное не пересекало улицу, потому что оно было слишком уставшим.
Следующая иллюстрация (от Transformer: новая архитектура нейронной сети для понимания языка ) показывает шаблон внимания слоя самостоятельного приспособления для местоимения , с темнотой каждой строки, указывающей, насколько каждое слово способствует представлению:
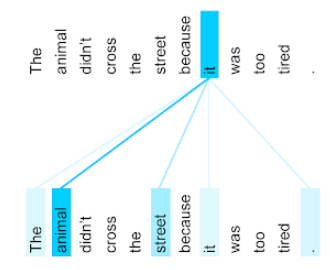
Слои с самопринятым подчеркивает слова, которые имеют отношение к «это». В этом случае слой внимания научился выделять слова, на которые он может ссылаться, присвоив самый высокий вес животному .
Для последовательности n токенов самоуверенность преобразует последовательность встроенных n отдельных времен, один раз в каждой позиции в последовательности.
Обратитесь к вниманию и многообещающемуся самоуничтожению .
Анализ настроений
Использование статистических или алгоритмов машинного обучения для определения общего отношения группы - позитивного или негативного, - поместить услугу, продукт, организацию или тему. Например, используя понимание естественного языка , алгоритм может провести анализ настроений на текстовую обратную связь от университетского курса, чтобы определить степень, в которой студенты обычно нравились или не нравились курс.
См. Руководство по классификации текста для получения дополнительной информации.
Задача последовательности к последовательности
Задача, которая преобразует входную последовательность токенов в выходную последовательность токенов. Например, два популярных вида задач последовательности к последовательности:
- Переводчики:
- Пример входной последовательности: «Я люблю тебя».
- Образец вывода последовательности: «Je t'aime».
- Ответ на вопрос:
- Пример входной последовательности: «Нужна ли мне моя машина в Нью -Йорке?»
- Образец вывода: «Нет. Держите свой автомобиль дома».
пропустить грамм
N-грамм , который может опустить (или «пропустить») слова из исходного контекста, что означает, что n слов, возможно, не были изначально смежными. Точнее, «K-Skip-N-Gram»-это N-грамм, для которого можно было пропустить до k слов.
Например, «Quick Brown Fox» имеет следующие возможные 2 грамма:
- "Быстро"
- "Быстрый коричневый"
- "Brown Fox"
«1-SKIP-2-грамм»-это пара слов, которые имеют не более 1 слова между ними. Поэтому «быстрый коричневый лис» имеет следующие 1-граммы: 2-граммы:
- "Браун"
- "Quick Fox"
Кроме того, все 2 грамма также составляют 1-шкип-2-граммы, так как может быть пропущено менее одного слова.
Скип-граммы полезны для понимания большего количества окружающего контекста слова. В примере «Fox» был непосредственно связан с «быстрым» в наборе 1-грамм 1-шкаф, но не в наборе 2 граммов.
Скип-граммы помогают обучать модели встраивания слов .
Мягкая приглашенная настройка
Техника для настройки большой языковой модели для конкретной задачи, без интенсивной настройки ресурсов. Вместо переподготовки всех весов в модели, мягкая настройка приглашения автоматически регулирует подсказку для достижения одной и той же цели.
Учитывая текстовую подсказку, настройка мягкой подсказки обычно добавляет дополнительные встроенные токеновые вставки в подсказку и использует BackPropagation для оптимизации ввода.
«Жесткое» подсказка содержит фактические токены вместо встроенных токенов.
редкая функция
Функция , значения которых преимущественно нулевые или пустые. Например, функция, содержащая одно 1 значение и значения миллиона 0, является редкой. Напротив, плотная функция имеет значения, которые преимущественно не являются нулевыми или пустыми.
В машинном обучении неожиданное количество функций - редкие функции. Категориальные особенности обычно являются редкими функциями. Например, из 300 возможных видов деревьев в лесу один пример может идентифицировать только кленовое дерево . Или из миллионов возможных видео в видео библиотеке, один пример может идентифицировать только «Касабланку».
В модели вы, как правило, представляете редкие функции с однократным кодированием . Если однокачественное кодирование большое, вы можете поместить встраивающий слой поверх однокачественного кодирования для большей эффективности.
редкое представление
Хранение только позиции (ы) ненулевых элементов в редкой функции.
Например, предположим, что категориальная особенность, названная species идентифицирует 36 видов деревьев в конкретном лесу. Далее предположим, что каждый пример идентифицирует только один вид.
Вы можете использовать одножелачный вектор для представления видов деревьев в каждом примере. Одножележный вектор будет содержать один 1 (для представления конкретных видов деревьев в этом примере) и 35 0 с (для представления 35 видов деревьев не в этом примере). Таким образом, одножелательное представление о maple может выглядеть как-то вроде следующего:

В качестве альтернативы, разреженное представление просто идентифицирует положение конкретного вида. Если maple находится в позиции 24, то разреженное представление о maple было бы просто:
24
Обратите внимание, что редкое представление гораздо более компактно, чем одножелательное представление.
Нажмите на значок, чтобы получить немного более сложный пример.
Предположим, что каждый пример в вашей модели должен представлять слова, но не порядок этих слов - в английском предложении. Английский состоит из примерно 170 000 слов, поэтому английский является категориальной особенностью с около 170 000 элементов. Большинство английских предложений используют чрезвычайно крошечную часть этих 170 000 слов, поэтому набор слов в одном примере почти наверняка будет редкими данными.
Рассмотрим следующее предложение:
My dog is a great dog
Вы можете использовать вариант однопольтного вектора, чтобы представлять слова в этом предложении. В этом варианте несколько ячеек в векторе могут содержать ненулевое значение. Кроме того, в этом варианте ячейка может содержать целое число, отличное от одного. Хотя слова «my», »,« есть »,« а »и« великий », появляются только один раз в предложении, слово« собака »появляется дважды. Использование этого варианта однопользовых векторов для представления слов в этом предложении дает следующий вектор из 170 000 элементов:

Редвое представление того же предложения было бы просто:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
См. Работа с категориальными данными в курсе сбоя машинного обучения для получения дополнительной информации.
поэтапное обучение
Тактика обучения модели в последовательности дискретных этапов. Цель может быть либо ускорить тренировочный процесс, либо достичь лучшего качества модели.
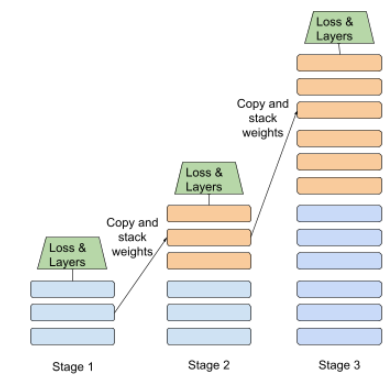
Ниже показана иллюстрация подхода прогрессивной укладки:
- Стадия 1 содержит 3 скрытых слоя, этап 2 содержит 6 скрытых слоев, а этапа 3 содержит 12 скрытых слоев.
- Стадия 2 начинает тренировки с весами, изученными в 3 скрытых слоях стадии 1. Стадия 3 начинает тренировки с весами, изученными в 6 скрытых слоях этапа 2.
Смотрите также трубопровод .
токен подвестия
В языковых моделях , токен , который представляет собой подстроение слова, которое может быть всем словом.
Например, слово, подобное «electize», может быть разбито на части «элемент» (корневое слово) и «ize» (суффикс), каждый из которых представлен своим собственным токеном. Разделение необычных слов на такие произведения, называемые подчиками, позволяет языковым моделям работать на более распространенных частях слова, таких как префиксы и суффиксы.
И наоборот, общие слова, такие как «Going», не могут быть разбиты и могут быть представлены одним токеном.
Т
T5
Модель обучения передачи текста в текст, представленная Google AI в 2020 году . T5 - это модель Encoder - декодер , основанная на архитектуре трансформатора , обученная чрезвычайно большим набором данных. Он эффективен в различных задачах по обработке естественного языка, таких как создание текста, перевод языков и ответы на вопросы в разговорной форме.
T5 получает свое название от Five T в «Трансформатор Text-Text Transfer».
T5X
Основная структура машинного обучения с открытым исходным кодом, предназначенная для создания и обучения крупномасштабных моделей обработки естественного языка (NLP). T5 реализован на кодовой базе T5X (которая построена на JAX и лене ).
температура
Гиперпараметр , который контролирует степень случайности вывода модели. Более высокие температуры приводят к более случайной мощности, в то время как более низкие температуры приводят к менее случайной мощности.
Выбор наилучшей температуры зависит от конкретного применения и предпочтительных свойств выхода модели. Например, вы, вероятно, повысите температуру при создании приложения, которое генерирует творческий выход. И наоборот, вы, вероятно, снизили бы температуру при создании модели, которая классифицирует изображения или текст, чтобы повысить точность и согласованность модели.
Температура часто используется с Softmax .
текстовый промежуток
Индекс массива, связанный с определенным подразделением текстовой строки. Например, слово good в строке Python s="Be good now" занимает текстовый промежуток от 3 до 6.
жетон
В языковой модели атомная единица, на которой тренируется модель и делая прогнозы. Токен обычно является одним из следующих:
- Слово - например, фраза «собаки, такие как кошки», состоит из трех токенов слова: «собаки», «как» и «кошки».
- Персонаж, например, фраза «велосипедная рыба» состоит из девяти токенов персонажа. (Обратите внимание, что пустое пространство считается одним из токенов.)
- подвесы, в которых одно слово может быть единственным токеном или множественными токенами. Подвесность состоит из корневого слова, префикса или суффикса. For example, a language model that uses subwords as tokens might view the word "dogs" as two tokens (the root word "dog" and the plural suffix "s"). That same language model might view the single word "taller" as two subwords (the root word "tall" and the suffix "er").
In domains outside of language models, tokens can represent other kinds of atomic units. For example, in computer vision, a token might be a subset of an image.
See Large language models in Machine Learning Crash Course for more information.
top-k accuracy
The percentage of times that a "target label" appears within the first k positions of generated lists. The lists could be personalized recommendations or a list of items ordered by softmax .
Top-k accuracy is also known as accuracy at k .
токсичность
The degree to which content is abusive, threatening, or offensive. Many machine learning models can identify and measure toxicity. Most of these models identify toxicity along multiple parameters, such as the level of abusive language and the level of threatening language.
Трансформатор
A neural network architecture developed at Google that relies on self-attention mechanisms to transform a sequence of input embeddings into a sequence of output embeddings without relying on convolutions or recurrent neural networks . A Transformer can be viewed as a stack of self-attention layers.
A Transformer can include any of the following:
An encoder transforms a sequence of embeddings into a new sequence of the same length. An encoder includes N identical layers, each of which contains two sub-layers. These two sub-layers are applied at each position of the input embedding sequence, transforming each element of the sequence into a new embedding. The first encoder sub-layer aggregates information from across the input sequence. The second encoder sub-layer transforms the aggregated information into an output embedding.
A decoder transforms a sequence of input embeddings into a sequence of output embeddings, possibly with a different length. A decoder also includes N identical layers with three sub-layers, two of which are similar to the encoder sub-layers. The third decoder sub-layer takes the output of the encoder and applies the self-attention mechanism to gather information from it.
The blog post Transformer: A Novel Neural Network Architecture for Language Understanding provides a good introduction to Transformers.
See LLMs: What's a large language model? in Machine Learning Crash Course for more information.
trigram
An N-gram in which N=3.
ты
однонаправленный
A system that only evaluates the text that precedes a target section of text. In contrast, a bidirectional system evaluates both the text that precedes and follows a target section of text. See bidirectional for more details.
unidirectional language model
A language model that bases its probabilities only on the tokens appearing before , not after , the target token(s). Contrast with bidirectional language model .
В
variational autoencoder (VAE)
A type of autoencoder that leverages the discrepancy between inputs and outputs to generate modified versions of the inputs. Variational autoencoders are useful for generative AI .
VAEs are based on variational inference: a technique for estimating the parameters of a probability model.
Вт
word embedding
Representing each word in a word set within an embedding vector ; that is, representing each word as a vector of floating-point values between 0.0 and 1.0. Words with similar meanings have more-similar representations than words with different meanings. For example, carrots , celery , and cucumbers would all have relatively similar representations, which would be very different from the representations of airplane , sunglasses , and toothpaste .
З
zero-shot prompting
A prompt that does not provide an example of how you want the large language model to respond. Например:
| Parts of one prompt | Примечания |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| Индия: | The actual query. |
The large language model might respond with any of the following:
- Рупия
- Инфекция
- ₹
- Indian rupee
- The rupee
- The Indian rupee
All of the answers are correct, though you might prefer a particular format.
Compare and contrast zero-shot prompting with the following terms: