এই পৃষ্ঠায় ভাষা মূল্যায়ন শব্দকোষ রয়েছে। সকল শব্দকোষের জন্য এখানে ক্লিক করুন ।
ক
মনোযোগ
একটি নিউরাল নেটওয়ার্কে ব্যবহৃত একটি প্রক্রিয়া যা একটি নির্দিষ্ট শব্দ বা শব্দের অংশের গুরুত্ব নির্দেশ করে। মনোযোগ একটি মডেলের পরবর্তী টোকেন/শব্দের পূর্বাভাস দিতে প্রয়োজনীয় তথ্যের পরিমাণ সংকুচিত করে। একটি সাধারণ মনোযোগ প্রক্রিয়া ইনপুটগুলির একটি সেটের উপর একটি ওজনযুক্ত যোগফল নিয়ে গঠিত হতে পারে, যেখানে প্রতিটি ইনপুটের ওজন নিউরাল নেটওয়ার্কের অন্য অংশ দ্বারা গণনা করা হয়।
স্ব-মনোযোগ এবং বহু-হেড স্ব-মনোযোগকেও উল্লেখ করুন, যা ট্রান্সফরমারের বিল্ডিং ব্লক।
LLMs দেখুন: একটি বড় ভাষা মডেল কি? স্ব-মনোযোগ সম্পর্কে আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে।
অটোএনকোডার
একটি সিস্টেম যা ইনপুট থেকে সবচেয়ে গুরুত্বপূর্ণ তথ্য বের করতে শেখে। অটোএনকোডার হল একটি এনকোডার এবং ডিকোডারের সংমিশ্রণ। অটোএনকোডারগুলি নিম্নলিখিত দ্বি-পদক্ষেপ প্রক্রিয়ার উপর নির্ভর করে:
- এনকোডার ইনপুটকে একটি (সাধারণত) ক্ষতিকর নিম্ন-মাত্রিক (মধ্যবর্তী) বিন্যাসে ম্যাপ করে।
- ডিকোডার নিম্ন-মাত্রিক বিন্যাসটিকে মূল উচ্চ-মাত্রিক ইনপুট বিন্যাসে ম্যাপ করে মূল ইনপুটের একটি ক্ষতিকারক সংস্করণ তৈরি করে।
এনকোডারের মধ্যবর্তী বিন্যাস থেকে যতটা সম্ভব ঘনিষ্ঠভাবে মূল ইনপুট পুনর্গঠন করার জন্য ডিকোডার প্রচেষ্টার মাধ্যমে অটোএনকোডারদের এন্ড-টু-এন্ড প্রশিক্ষিত করা হয়। মধ্যবর্তী বিন্যাসটি মূল বিন্যাসের চেয়ে ছোট (নিম্ন-মাত্রিক) হওয়ায়, অটোএনকোডারকে ইনপুটে কোন তথ্য অপরিহার্য তা শিখতে বাধ্য করা হয় এবং আউটপুটটি ইনপুটের সাথে পুরোপুরি অভিন্ন হবে না।
যেমন:
- যদি ইনপুট ডেটা একটি গ্রাফিক হয়, অ-নির্ভুল অনুলিপিটি মূল গ্রাফিকের অনুরূপ হবে, তবে কিছুটা পরিবর্তিত হবে। সম্ভবত অ-নির্ভুল অনুলিপি মূল গ্রাফিক থেকে শব্দ সরিয়ে দেয় বা কিছু অনুপস্থিত পিক্সেল পূরণ করে।
- যদি ইনপুট ডেটা পাঠ্য হয় তবে একটি অটোএনকোডার নতুন পাঠ্য তৈরি করবে যা মূল পাঠ্যের অনুকরণ করে (কিন্তু অনুরূপ নয়)।
পরিবর্তনশীল অটোএনকোডারগুলিও দেখুন।
স্বয়ংক্রিয় মূল্যায়ন
একটি মডেলের আউটপুট গুণমান বিচার করতে সফ্টওয়্যার ব্যবহার করে.
যখন মডেল আউটপুট তুলনামূলকভাবে সহজবোধ্য হয়, তখন একটি স্ক্রিপ্ট বা প্রোগ্রাম মডেলের আউটপুটকে সোনালী প্রতিক্রিয়ার সাথে তুলনা করতে পারে। এই ধরনের স্বয়ংক্রিয় মূল্যায়নকে কখনও কখনও প্রোগ্রামেটিক মূল্যায়ন বলা হয়। মেট্রিক্স যেমন ROUGE বা BLEU প্রায়ই প্রোগ্রামেটিক মূল্যায়নের জন্য উপযোগী।
যখন মডেল আউটপুট জটিল হয় বা এর কোনো সঠিক উত্তর থাকে না , তখন একটি স্বয়ংক্রিয় এমএল প্রোগ্রাম নামে পরিচিত একটি স্বয়ংক্রিয় মূল্যায়ন করে।
মানুষের মূল্যায়নের সাথে বৈসাদৃশ্য।
অটোরাটার মূল্যায়ন
একটি জেনারেটিভ এআই মডেলের আউটপুটের গুণমান বিচার করার জন্য একটি হাইব্রিড প্রক্রিয়া যা মানুষের মূল্যায়নকে স্বয়ংক্রিয় মূল্যায়নের সাথে একত্রিত করে। একটি অটোরেটর হল একটি এমএল মডেল যা মানুষের মূল্যায়ন দ্বারা তৈরি ডেটার উপর প্রশিক্ষিত। আদর্শভাবে, একজন অটোরাটার একজন মানুষের মূল্যায়নকারীকে অনুকরণ করতে শেখে।প্রি-বিল্ট অটোরেটর উপলব্ধ, তবে সেরা অটোরেটরগুলি বিশেষভাবে আপনি যে কাজটি মূল্যায়ন করছেন তার জন্য সূক্ষ্ম সুর করা হয়।
অটো রিগ্রেসিভ মডেল
একটি মডেল যা তার নিজের পূর্বের ভবিষ্যদ্বাণীগুলির উপর ভিত্তি করে একটি ভবিষ্যদ্বাণী অনুমান করে৷ উদাহরণস্বরূপ, অটো-রিগ্রেসিভ ল্যাঙ্গুয়েজ মডেলগুলি পূর্বে ভবিষ্যদ্বাণী করা টোকেনের উপর ভিত্তি করে পরবর্তী টোকেনের পূর্বাভাস দেয়। সমস্ত ট্রান্সফরমার -ভিত্তিক বৃহৎ ভাষার মডেলগুলি স্বয়ংক্রিয়-রিগ্রেসিভ।
বিপরীতে, GAN- ভিত্তিক ইমেজ মডেলগুলি সাধারণত অটো-রিগ্রেসিভ হয় না কারণ তারা একটি একক ফরোয়ার্ড-পাসে একটি ছবি তৈরি করে এবং ধাপে ধাপে নয়। যাইহোক, কিছু ইমেজ জেনারেশন মডেল অটো-রিগ্রেসিভ কারণ তারা ধাপে ধাপে একটি ইমেজ তৈরি করে।
k এ গড় নির্ভুলতা
একটি একক প্রম্পটে মডেলের কর্মক্ষমতা সংক্ষিপ্ত করার জন্য একটি মেট্রিক যা র্যাঙ্ক করা ফলাফল তৈরি করে, যেমন বইয়ের সুপারিশের একটি সংখ্যাযুক্ত তালিকা। k- এ গড় নির্ভুলতা হল, ভাল, প্রতিটি প্রাসঙ্গিক ফলাফলের জন্য k মানের নির্ভুলতার গড়। k এ গড় নির্ভুলতার সূত্রটি তাই:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
কোথায়:
- \(n\) তালিকায় প্রাসঙ্গিক আইটেমের সংখ্যা।
k এ প্রত্যাহার সঙ্গে বৈসাদৃশ্য।
খ
শব্দের ব্যাগ
ক্রম নির্বিশেষে একটি বাক্যাংশ বা প্যাসেজে শব্দের উপস্থাপনা। উদাহরণস্বরূপ, শব্দের ব্যাগ নিম্নলিখিত তিনটি বাক্যাংশকে অভিন্নভাবে উপস্থাপন করে:
- কুকুর লাফ দেয়
- কুকুর লাফিয়ে
- কুকুর লাফ দেয়
প্রতিটি শব্দ একটি স্পার্স ভেক্টরের একটি সূচকে ম্যাপ করা হয়, যেখানে ভেক্টরের শব্দভান্ডারের প্রতিটি শব্দের জন্য একটি সূচক থাকে। উদাহরণস্বরূপ, কুকুরের লাফানো শব্দগুচ্ছটি একটি বৈশিষ্ট্য ভেক্টরে ম্যাপ করা হয়েছে যা , কুকুর এবং লাফ শব্দের সাথে সম্পর্কিত তিনটি সূচকে শূন্য নয়। অ-শূন্য মান নিম্নলিখিত যে কোনো হতে পারে:
- একটি শব্দের উপস্থিতি বোঝাতে একটি 1।
- ব্যাগে একটি শব্দ কতবার উপস্থিত হয় তার একটি গণনা। উদাহরণস্বরূপ, যদি বাক্যাংশটি মেরুন কুকুর মেরুন পশমযুক্ত একটি কুকুর হয় , তাহলে মেরুন এবং কুকুর উভয়কেই 2 হিসাবে উপস্থাপন করা হবে, অন্য শব্দগুলিকে 1 হিসাবে উপস্থাপন করা হবে।
- আরও কিছু মান, যেমন ব্যাগে একটি শব্দ কতবার উপস্থিত হয় তার সংখ্যার লগারিদম।
BERT (ট্রান্সফরমার থেকে দ্বিমুখী এনকোডার প্রতিনিধিত্ব)
পাঠ্য উপস্থাপনার জন্য একটি মডেল আর্কিটেকচার। একটি প্রশিক্ষিত BERT মডেল পাঠ্য শ্রেণিবিন্যাস বা অন্যান্য ML কাজের জন্য একটি বড় মডেলের অংশ হিসাবে কাজ করতে পারে।
BERT এর নিম্নলিখিত বৈশিষ্ট্য রয়েছে:
- ট্রান্সফরমার আর্কিটেকচার ব্যবহার করে, এবং তাই স্ব-মনোযোগের উপর নির্ভর করে।
- ট্রান্সফরমারের এনকোডার অংশ ব্যবহার করে। এনকোডারের কাজ হল শ্রেণীবিভাগের মতো একটি নির্দিষ্ট কাজ সম্পাদন করার পরিবর্তে ভাল পাঠ্য উপস্থাপনা তৈরি করা।
- দ্বিমুখী ।
- তত্ত্বাবধানহীন প্রশিক্ষণের জন্য মাস্কিং ব্যবহার করে।
BERT এর ভেরিয়েন্টগুলির মধ্যে রয়েছে:
দ্বিমুখী
এমন একটি শব্দ যা একটি সিস্টেমকে বর্ণনা করতে ব্যবহৃত হয় যা পাঠ্যের একটি লক্ষ্য বিভাগের পূর্ববর্তী এবং অনুসরণ করে এমন পাঠ্যকে মূল্যায়ন করে। বিপরীতে, একটি ইউনিডাইরেকশনাল সিস্টেম শুধুমাত্র পাঠ্যের একটি লক্ষ্য বিভাগের আগে থাকা পাঠ্যকে মূল্যায়ন করে।
উদাহরণস্বরূপ, একটি মুখোশযুক্ত ভাষা মডেল বিবেচনা করুন যা অবশ্যই নিম্নলিখিত প্রশ্নে আন্ডারলাইন প্রতিনিধিত্বকারী শব্দ বা শব্দগুলির সম্ভাব্যতা নির্ধারণ করবে:
আপনার সাথে _____ কি?
একটি একমুখী ভাষা মডেলকে শুধুমাত্র "কী", "is", এবং "the" শব্দ দ্বারা প্রদত্ত প্রেক্ষাপটের উপর ভিত্তি করে তার সম্ভাবনার ভিত্তি করতে হবে। বিপরীতে, একটি দ্বিমুখী ভাষা মডেল "সহ" এবং "আপনি" থেকে প্রসঙ্গ লাভ করতে পারে, যা মডেলটিকে আরও ভাল ভবিষ্যদ্বাণী তৈরি করতে সহায়তা করতে পারে।
দ্বিমুখী ভাষার মডেল
একটি ভাষা মডেল যা পূর্ববর্তী এবং পরবর্তী পাঠ্যের উপর ভিত্তি করে পাঠ্যের একটি উদ্ধৃতিতে একটি প্রদত্ত টোকেন একটি নির্দিষ্ট স্থানে উপস্থিত থাকার সম্ভাবনা নির্ধারণ করে।
বিগগ্রাম
একটি N-গ্রাম যার মধ্যে N=2।
BLEU (দ্বিভাষিক মূল্যায়ন আন্ডারস্টাডি)
মেশিন অনুবাদের মূল্যায়নের জন্য 0.0 এবং 1.0 এর মধ্যে একটি মেট্রিক, উদাহরণস্বরূপ, স্প্যানিশ থেকে জাপানি পর্যন্ত।
একটি স্কোর গণনা করার জন্য, BLEU সাধারণত একটি ML মডেলের অনুবাদ ( জেনারেটেড টেক্সট ) একজন মানব বিশেষজ্ঞের অনুবাদের ( রেফারেন্স টেক্সট ) সাথে তুলনা করে। যে ডিগ্রীতে N-গ্রাম জেনারেট করা টেক্সট এবং রেফারেন্স টেক্সট মেলে তা BLEU স্কোর নির্ধারণ করে।
এই মেট্রিকের মূল কাগজটি হল BLEU: মেশিন অনুবাদের স্বয়ংক্রিয় মূল্যায়নের একটি পদ্ধতি ।
এছাড়াও BLEURT দেখুন।
BLEURT (ট্রান্সফরমার থেকে দ্বিভাষিক মূল্যায়ন আন্ডারস্টাডি)
এক ভাষা থেকে অন্য ভাষায়, বিশেষ করে ইংরেজিতে এবং থেকে মেশিন অনুবাদের মূল্যায়নের জন্য একটি মেট্রিক।
ইংরেজিতে এবং থেকে অনুবাদের জন্য, BLEURT BLEU এর চেয়ে মানব রেটিংগুলির সাথে আরও ঘনিষ্ঠভাবে সারিবদ্ধ করে। BLEU এর বিপরীতে, BLEURT শব্দার্থগত (অর্থ) মিলের উপর জোর দেয় এবং প্যারাফ্রেজিংকে মিটমাট করতে পারে।
BLEURT একটি প্রাক-প্রশিক্ষিত বৃহৎ ভাষার মডেলের উপর নির্ভর করে ( BERT সঠিক হতে) যেটি মানব অনুবাদকদের পাঠ্যের উপর সূক্ষ্ম সুর করা হয়।
এই মেট্রিকের মূল কাগজটি হল BLEURT: টেক্সট জেনারেশনের জন্য রোবাস্ট মেট্রিক্স শেখা ।
গ
কার্যকারণ ভাষা মডেল
একমুখী ভাষা মডেলের প্রতিশব্দ।
ভাষা মডেলিংয়ে বিভিন্ন দিকনির্দেশক পদ্ধতির বিপরীতে দ্বিমুখী ভাষার মডেল দেখুন।
চেইন-অফ-থট প্রম্পটিং
একটি প্রম্পট ইঞ্জিনিয়ারিং কৌশল যা একটি বৃহৎ ভাষা মডেল (LLM) কে ধাপে ধাপে তার যুক্তি ব্যাখ্যা করতে উৎসাহিত করে। উদাহরণস্বরূপ, দ্বিতীয় বাক্যে বিশেষ মনোযোগ দিয়ে নিম্নলিখিত প্রম্পটটি বিবেচনা করুন:
7 সেকেন্ডে প্রতি ঘন্টায় 0 থেকে 60 মাইল বেগে যাওয়া গাড়িতে একজন চালক কতটি জি ফোর্স অনুভব করবে? উত্তরে, সমস্ত প্রাসঙ্গিক গণনা দেখান।
এলএলএম এর প্রতিক্রিয়া সম্ভবত:
- উপযুক্ত স্থানে 0, 60, এবং 7 মান প্লাগ করে পদার্থবিজ্ঞানের সূত্রের একটি ক্রম দেখান।
- ব্যাখ্যা করুন কেন এটি সেই সূত্রগুলি বেছে নিয়েছে এবং বিভিন্ন ভেরিয়েবলের অর্থ কী।
চেইন-অফ-থট প্রম্পটিং এলএলএমকে সমস্ত গণনা সম্পাদন করতে বাধ্য করে, যা আরও সঠিক উত্তরের দিকে নিয়ে যেতে পারে। উপরন্তু, চেইন-অফ-থট প্রম্পটিং ব্যবহারকারীকে LLM-এর পদক্ষেপগুলি পরীক্ষা করতে সক্ষম করে উত্তরটি অর্থপূর্ণ কিনা তা নির্ধারণ করতে।
চ্যাট
একটি ML সিস্টেমের সাথে একটি পিছনে এবং সামনে কথোপকথনের বিষয়বস্তু, সাধারণত একটি বড় ভাষা মডেল । একটি চ্যাটে পূর্ববর্তী মিথস্ক্রিয়া (আপনি কী টাইপ করেছেন এবং কীভাবে বৃহৎ ভাষার মডেল প্রতিক্রিয়া জানিয়েছেন) চ্যাটের পরবর্তী অংশগুলির প্রসঙ্গ হয়ে ওঠে।
একটি চ্যাটবট একটি বড় ভাষা মডেলের একটি অ্যাপ্লিকেশন।
বিভ্রান্তি
হ্যালুসিনেশনের প্রতিশব্দ।
কনফ্যাবুলেশন সম্ভবত হ্যালুসিনেশনের চেয়ে প্রযুক্তিগতভাবে আরও সঠিক শব্দ। যাইহোক, হ্যালুসিনেশন প্রথম জনপ্রিয় হয়ে ওঠে।
নির্বাচনী এলাকা পার্সিং
একটি বাক্যকে ছোট ব্যাকরণগত কাঠামোতে বিভক্ত করা ("নির্ধারক")। ML সিস্টেমের একটি পরবর্তী অংশ, যেমন একটি প্রাকৃতিক ভাষা বোঝার মডেল, মূল বাক্যের চেয়ে উপাদানগুলিকে আরও সহজে পার্স করতে পারে। উদাহরণস্বরূপ, নিম্নলিখিত বাক্যটি বিবেচনা করুন:
আমার বন্ধু দুটি বিড়াল দত্তক.
একজন নির্বাচনী পার্সার এই বাক্যটিকে নিম্নলিখিত দুটি উপাদানে ভাগ করতে পারেন:
- আমার বন্ধু একটি বিশেষ্য বাক্যাংশ।
- গৃহীত দুই বিড়াল একটি ক্রিয়া বাক্যাংশ।
এই উপাদানগুলিকে আরও ছোট উপাদানগুলিতে বিভক্ত করা যেতে পারে। উদাহরণস্বরূপ, ক্রিয়াপদ বাক্যাংশ
দুটি বিড়াল দত্তক
আরও উপবিভক্ত করা যেতে পারে:
- গৃহীত একটি ক্রিয়া।
- দুটি বিড়াল আরেকটি বিশেষ্য বাক্যাংশ।
প্রাসঙ্গিক ভাষা এম্বেডিং
একটি এমবেডিং যা শব্দ এবং বাক্যাংশগুলিকে "বোঝার" কাছাকাছি আসে যেভাবে সাবলীল মানুষের বক্তারা করতে পারেন। প্রাসঙ্গিক ভাষা এম্বেডিং জটিল বাক্য গঠন, শব্দার্থবিদ্যা এবং প্রসঙ্গ বুঝতে পারে।
উদাহরণস্বরূপ, ইংরেজি শব্দ cow এর এমবেডিং বিবেচনা করুন। পুরানো এম্বেডিং যেমন word2vec ইংরেজি শব্দগুলিকে উপস্থাপন করতে পারে যেমন গাভী থেকে ষাঁড় পর্যন্ত এম্বেড করার স্থানের দূরত্ব ewe (স্ত্রী ভেড়া) থেকে রাম (পুরুষ ভেড়া) বা মহিলা থেকে পুরুষের দূরত্বের সমান। প্রাসঙ্গিক ভাষা এম্বেডিংগুলি স্বীকার করে আরও এক ধাপ এগিয়ে যেতে পারে যে ইংরেজি ভাষাভাষীরা কখনও কখনও গরু বা ষাঁড়ের অর্থ বোঝাতে গরু শব্দটি ব্যবহার করে।
প্রসঙ্গ উইন্ডো
প্রদত্ত প্রম্পটে একটি মডেল প্রক্রিয়া করতে পারে এমন টোকেনের সংখ্যা। প্রসঙ্গ উইন্ডো যত বড় হবে, মডেলটি প্রম্পটে সুসংগত এবং সামঞ্জস্যপূর্ণ প্রতিক্রিয়া প্রদান করতে তত বেশি তথ্য ব্যবহার করতে পারে।
ক্র্যাশ ব্লসম
একটি অস্পষ্ট অর্থ সহ একটি বাক্য বা বাক্যাংশ। ক্র্যাশ ফুল প্রাকৃতিক ভাষা বোঝার ক্ষেত্রে একটি উল্লেখযোগ্য সমস্যা উপস্থাপন করে। উদাহরণস্বরূপ, শিরোনাম রেড টেপ হোল্ডস আপ স্কাইস্ক্র্যাপার একটি ক্র্যাশ ব্লসম কারণ একটি NLU মডেল শিরোনামটিকে আক্ষরিক বা রূপকভাবে ব্যাখ্যা করতে পারে।
ডি
ডিকোডার
সাধারণভাবে, যে কোনো ML সিস্টেম যা একটি প্রক্রিয়াকৃত, ঘন বা অভ্যন্তরীণ উপস্থাপনা থেকে আরও কাঁচা, বিক্ষিপ্ত বা বাহ্যিক উপস্থাপনায় রূপান্তরিত হয়।
ডিকোডারগুলি প্রায়শই একটি বড় মডেলের একটি উপাদান, যেখানে তারা প্রায়শই একটি এনকোডারের সাথে যুক্ত হয়।
সিকোয়েন্স-টু-সিকোয়েন্স কাজগুলিতে , একটি ডিকোডার পরবর্তী ক্রম অনুমান করার জন্য এনকোডার দ্বারা তৈরি অভ্যন্তরীণ অবস্থা দিয়ে শুরু হয়।
ট্রান্সফরমার আর্কিটেকচারের মধ্যে একটি ডিকোডারের সংজ্ঞার জন্য ট্রান্সফরমার পড়ুন।
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে বড় ভাষার মডেলগুলি দেখুন।
denoising
স্ব-তত্ত্বাবধানে শিক্ষার একটি সাধারণ পদ্ধতি যার মধ্যে:
Denoising লেবেলবিহীন উদাহরণ থেকে শেখার সক্ষম করে। মূল ডেটাসেট লক্ষ্য বা লেবেল হিসাবে কাজ করে এবং কোলাহলপূর্ণ ডেটা ইনপুট হিসাবে কাজ করে।
কিছু মুখোশযুক্ত ভাষা মডেল নিম্নরূপ denoising ব্যবহার করে:
- কিছু টোকেন মাস্ক করে লেবেলবিহীন বাক্যে কৃত্রিমভাবে নয়েজ যোগ করা হয়।
- মডেল মূল টোকেন ভবিষ্যদ্বাণী করার চেষ্টা করে।
সরাসরি প্রম্পটিং
জিরো-শট প্রম্পটিং- এর প্রতিশব্দ।
ই
দূরত্ব সম্পাদনা করুন
দুটি টেক্সট স্ট্রিং একে অপরের সাথে কতটা অনুরূপ তার একটি পরিমাপ। মেশিন লার্নিং-এ, দূরত্ব সম্পাদনা নিম্নলিখিত কারণগুলির জন্য দরকারী:
- সম্পাদনা দূরত্ব গণনা করা সহজ।
- দূরত্ব সম্পাদনা দুটি স্ট্রিং একে অপরের অনুরূপ বলে পরিচিত তুলনা করতে পারে।
- দূরত্ব সম্পাদনা করুন বিভিন্ন স্ট্রিং একটি প্রদত্ত স্ট্রিং অনুরূপ ডিগ্রী নির্ধারণ করতে পারে.
সম্পাদনা দূরত্বের বেশ কয়েকটি সংজ্ঞা রয়েছে, প্রতিটি ভিন্ন স্ট্রিং অপারেশন ব্যবহার করে। একটি উদাহরণের জন্য Levenshtein দূরত্ব দেখুন।
এম্বেডিং স্তর
একটি বিশেষ লুকানো স্তর যা একটি উচ্চ-মাত্রিক শ্রেণীগত বৈশিষ্ট্যের উপর প্রশিক্ষণ দেয় যা ধীরে ধীরে একটি নিম্ন মাত্রার এম্বেডিং ভেক্টর শিখতে পারে। একটি এম্বেডিং স্তর একটি নিউরাল নেটওয়ার্ককে শুধুমাত্র উচ্চ-মাত্রিক শ্রেণীগত বৈশিষ্ট্যের উপর প্রশিক্ষণের চেয়ে অনেক বেশি দক্ষতার সাথে প্রশিক্ষণ দিতে সক্ষম করে।
উদাহরণস্বরূপ, পৃথিবী বর্তমানে প্রায় 73,000 গাছের প্রজাতিকে সমর্থন করে। ধরুন গাছের প্রজাতি আপনার মডেলের একটি বৈশিষ্ট্য , তাই আপনার মডেলের ইনপুট স্তরে একটি এক-হট ভেক্টর 73,000 উপাদান রয়েছে। উদাহরণস্বরূপ, সম্ভবত baobab এই মত কিছু প্রতিনিধিত্ব করা হবে:

একটি 73,000-এলিমেন্ট অ্যারে খুব দীর্ঘ। আপনি যদি মডেলটিতে একটি এম্বেডিং স্তর যোগ না করেন, তাহলে 72,999 শূন্য গুণ করার কারণে প্রশিক্ষণটি খুব সময়সাপেক্ষ হতে চলেছে। সম্ভবত আপনি 12টি মাত্রা সমন্বিত করার জন্য এম্বেডিং স্তরটি বেছে নিন। ফলস্বরূপ, এম্বেডিং স্তরটি ধীরে ধীরে প্রতিটি গাছের প্রজাতির জন্য একটি নতুন এমবেডিং ভেক্টর শিখবে।
কিছু পরিস্থিতিতে, হ্যাশিং একটি এম্বেডিং স্তরের একটি যুক্তিসঙ্গত বিকল্প।
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে এমবেডিং দেখুন।
এম্বেডিং স্থান
উচ্চ-মাত্রিক ভেক্টর স্থান থেকে বৈশিষ্ট্যযুক্ত ডি-ডাইমেনশনাল ভেক্টর স্পেস ম্যাপ করা হয়। এমবেডিং স্পেসকে স্ট্রাকচার ক্যাপচার করার জন্য প্রশিক্ষিত করা হয় যা উদ্দেশ্যপ্রণোদিত অ্যাপ্লিকেশনের জন্য অর্থপূর্ণ।
দুটি এমবেডিংয়ের ডট পণ্য তাদের সাদৃশ্যের একটি পরিমাপ।
এমবেডিং ভেক্টর
বিস্তৃতভাবে বলতে গেলে, কোনো লুকানো স্তর থেকে নেওয়া ফ্লোটিং-পয়েন্ট সংখ্যার একটি অ্যারে যা সেই লুকানো স্তরের ইনপুটগুলিকে বর্ণনা করে। প্রায়শই, একটি এমবেডিং ভেক্টর হল একটি এমবেডিং স্তরে প্রশিক্ষিত ফ্লোটিং-পয়েন্ট সংখ্যার অ্যারে। উদাহরণস্বরূপ, ধরুন একটি এম্বেডিং স্তরকে অবশ্যই পৃথিবীতে 73,000টি গাছের প্রজাতির জন্য একটি এমবেডিং ভেক্টর শিখতে হবে। সম্ভবত নিম্নলিখিত অ্যারেটি একটি বাওবাব গাছের জন্য এমবেডিং ভেক্টর:

একটি এম্বেডিং ভেক্টর এলোমেলো সংখ্যার একটি গুচ্ছ নয়। একটি এমবেডিং স্তর প্রশিক্ষণের মাধ্যমে এই মানগুলি নির্ধারণ করে, যেভাবে একটি নিউরাল নেটওয়ার্ক প্রশিক্ষণের সময় অন্যান্য ওজন শেখে। অ্যারের প্রতিটি উপাদান একটি গাছের প্রজাতির কিছু বৈশিষ্ট্য বরাবর একটি রেটিং। কোন উপাদান কোন গাছের প্রজাতির বৈশিষ্ট্য উপস্থাপন করে? এটা মানুষের জন্য নির্ধারণ করা খুব কঠিন।
একটি এমবেডিং ভেক্টরের গাণিতিকভাবে উল্লেখযোগ্য অংশ হল যে অনুরূপ আইটেমগুলিতে ভাসমান-বিন্দু সংখ্যার অনুরূপ সেট রয়েছে। উদাহরণ স্বরূপ, অনুরূপ গাছের প্রজাতির ভিন্ন ভিন্ন বৃক্ষের প্রজাতির তুলনায় ভাসমান-বিন্দু সংখ্যার আরও অনুরূপ সেট রয়েছে। রেডউডস এবং সিকোইয়াস গাছের প্রজাতি সম্পর্কিত, তাই তাদের রেডউডস এবং নারকেল পামের তুলনায় ভাসমান-পয়েন্টিং সংখ্যার আরও অনুরূপ সেট থাকবে। এমবেডিং ভেক্টরের সংখ্যাগুলি আপনি প্রতিবার মডেলটিকে পুনরায় প্রশিক্ষণ দেওয়ার সময় পরিবর্তিত হবে, এমনকি যদি আপনি অভিন্ন ইনপুট দিয়ে মডেলটিকে পুনরায় প্রশিক্ষণ দেন।
এনকোডার
সাধারণভাবে, যে কোনো ML সিস্টেম যা একটি কাঁচা, বিক্ষিপ্ত, বা বাহ্যিক উপস্থাপনা থেকে আরও প্রক্রিয়াকৃত, ঘন বা আরও অভ্যন্তরীণ উপস্থাপনায় রূপান্তরিত হয়।
এনকোডারগুলি প্রায়শই একটি বড় মডেলের একটি উপাদান, যেখানে তারা প্রায়শই একটি ডিকোডারের সাথে যুক্ত হয়। কিছু ট্রান্সফরমার ডিকোডারের সাথে এনকোডার যুক্ত করে, যদিও অন্যান্য ট্রান্সফরমার শুধুমাত্র এনকোডার বা শুধুমাত্র ডিকোডার ব্যবহার করে।
কিছু সিস্টেম শ্রেণীবিভাগ বা রিগ্রেশন নেটওয়ার্কে ইনপুট হিসাবে এনকোডারের আউটপুট ব্যবহার করে।
সিকোয়েন্স-টু-সিকোয়েন্স কাজগুলিতে , একটি এনকোডার একটি ইনপুট সিকোয়েন্স নেয় এবং একটি অভ্যন্তরীণ অবস্থা (একটি ভেক্টর) প্রদান করে। তারপর, ডিকোডার পরবর্তী ক্রম অনুমান করতে সেই অভ্যন্তরীণ অবস্থা ব্যবহার করে।
ট্রান্সফরমার আর্কিটেকচারে একটি এনকোডারের সংজ্ঞার জন্য ট্রান্সফরমার পড়ুন।
আরও তথ্যের জন্য LLMs দেখুন: মেশিন লার্নিং ক্র্যাশ কোর্সে একটি বড় ভাষা মডেল কী ।
evas
প্রাথমিকভাবে এলএলএম মূল্যায়নের সংক্ষিপ্ত রূপ হিসাবে ব্যবহৃত হয়। আরও বিস্তৃতভাবে, ইভাল হল যেকোনো ধরনের মূল্যায়নের সংক্ষিপ্ত রূপ।
মূল্যায়ন
একটি মডেলের গুণমান পরিমাপ করার বা একে অপরের সাথে বিভিন্ন মডেলের তুলনা করার প্রক্রিয়া।
একটি তত্ত্বাবধানে থাকা মেশিন লার্নিং মডেলের মূল্যায়ন করতে, আপনি সাধারণত এটিকে একটি বৈধতা সেট এবং একটি পরীক্ষা সেটের বিপরীতে বিচার করেন। একটি LLM মূল্যায়ন সাধারণত বিস্তৃত গুণমান এবং নিরাপত্তা মূল্যায়ন জড়িত।
চ
কয়েক শট প্রম্পটিং
একটি প্রম্পট যাতে একাধিক (একটি "কয়েক") উদাহরণ রয়েছে যা প্রদর্শন করে যে কীভাবে বড় ভাষা মডেলের প্রতিক্রিয়া জানানো উচিত। উদাহরণস্বরূপ, নিম্নলিখিত দীর্ঘ প্রম্পটে দুটি উদাহরণ রয়েছে যা একটি বৃহৎ ভাষার মডেল দেখাচ্ছে কিভাবে একটি প্রশ্নের উত্তর দিতে হয়।
| এক প্রম্পটের অংশ | নোট |
|---|---|
| নির্দিষ্ট দেশের সরকারী মুদ্রা কি? | যে প্রশ্নটির উত্তর আপনি LLM করতে চান। |
| ফ্রান্স: EUR | একটি উদাহরণ. |
| যুক্তরাজ্য: GBP | আরেকটি উদাহরণ। |
| ভারত: | প্রকৃত প্রশ্ন. |
কিছু-শট প্রম্পটিং সাধারণত জিরো-শট প্রম্পটিং এবং ওয়ান-শট প্রম্পটিংয়ের চেয়ে বেশি পছন্দসই ফলাফল দেয়। যাইহোক, অল্প-শট প্রম্পটিংয়ের জন্য একটি দীর্ঘ প্রম্পট প্রয়োজন।
ফিউ-শট প্রম্পটিং হল প্রম্পট-ভিত্তিক শিক্ষার জন্য প্রয়োগ করা কয়েক-শট লার্নিংয়ের একটি রূপ।
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে প্রম্পট ইঞ্জিনিয়ারিং দেখুন।
বেহালা
একটি পাইথন-প্রথম কনফিগারেশন লাইব্রেরি যা আক্রমণাত্মক কোড বা অবকাঠামো ছাড়াই ফাংশন এবং ক্লাসের মান সেট করে। প্যাক্স —এবং অন্যান্য ML কোডবেসের ক্ষেত্রে — এই ফাংশন এবং ক্লাসগুলি মডেল এবং প্রশিক্ষণ হাইপারপ্যারামিটারগুলিকে উপস্থাপন করে।
ফিডল অনুমান করে যে মেশিন লার্নিং কোডবেসগুলি সাধারণত বিভক্ত হয়:
- লাইব্রেরি কোড, যা স্তর এবং অপ্টিমাইজার সংজ্ঞায়িত করে।
- ডেটাসেট "আঠালো" কোড, যা লাইব্রেরিগুলিকে কল করে এবং সবকিছুকে একত্রিত করে।
ফিডল একটি অমূল্যায়িত এবং পরিবর্তনযোগ্য আকারে আঠালো কোডের কল কাঠামো ক্যাপচার করে।
ফাইন-টিউনিং
একটি নির্দিষ্ট ব্যবহারের ক্ষেত্রে এর পরামিতিগুলিকে পরিমার্জিত করার জন্য একটি প্রাক-প্রশিক্ষিত মডেলে একটি দ্বিতীয়, টাস্ক-নির্দিষ্ট প্রশিক্ষণ পাস। উদাহরণস্বরূপ, কিছু বড় ভাষা মডেলের জন্য সম্পূর্ণ প্রশিক্ষণের ক্রম নিম্নরূপ:
- প্রাক-প্রশিক্ষণ: একটি বিশাল সাধারণ ডেটাসেটে একটি বৃহৎ ভাষার মডেলকে প্রশিক্ষণ দিন, যেমন সমস্ত ইংরেজি ভাষার উইকিপিডিয়া পৃষ্ঠা।
- ফাইন-টিউনিং: একটি নির্দিষ্ট কাজ করার জন্য প্রাক-প্রশিক্ষিত মডেলকে প্রশিক্ষণ দিন, যেমন মেডিকেল প্রশ্নের উত্তর দেওয়া। ফাইন-টিউনিংয়ে সাধারণত নির্দিষ্ট কাজের উপর দৃষ্টি নিবদ্ধ করে শত শত বা হাজার হাজার উদাহরণ জড়িত থাকে।
আরেকটি উদাহরণ হিসাবে, একটি বড় ইমেজ মডেলের জন্য সম্পূর্ণ প্রশিক্ষণের ক্রম নিম্নরূপ:
- প্রাক-প্রশিক্ষণ: একটি বিশাল সাধারণ ইমেজ ডেটাসেটে একটি বড় ইমেজ মডেলকে প্রশিক্ষণ দিন, যেমন উইকিমিডিয়া কমন্সের সমস্ত ছবি।
- ফাইন-টিউনিং: একটি নির্দিষ্ট কাজ সম্পাদন করার জন্য পূর্ব-প্রশিক্ষিত মডেলকে প্রশিক্ষণ দিন, যেমন অর্কাসের ছবি তৈরি করা।
ফাইন-টিউনিং নিম্নলিখিত কৌশলগুলির যেকোন সংমিশ্রণকে অন্তর্ভুক্ত করতে পারে:
- প্রাক-প্রশিক্ষিত মডেলের বিদ্যমান পরামিতিগুলির সমস্ত পরিবর্তন করা। একে কখনও কখনও ফুল ফাইন-টিউনিং বলা হয়।
- অন্যান্য বিদ্যমান পরামিতিগুলি অপরিবর্তিত রেখে (সাধারণত, ইনপুট স্তরের সবচেয়ে কাছের স্তরগুলি) রেখে শুধুমাত্র প্রাক-প্রশিক্ষিত মডেলের বিদ্যমান প্যারামিটারগুলির কিছু পরিবর্তন করা (সাধারণত, আউটপুট স্তরের নিকটতম স্তরগুলি)। প্যারামিটার-দক্ষ টিউনিং দেখুন।
- আরও স্তর যুক্ত করা হচ্ছে, সাধারণত আউটপুট স্তরের নিকটতম বিদ্যমান স্তরগুলির উপরে।
ফাইন-টিউনিং হল ট্রান্সফার লার্নিং এর একটি ফর্ম। যেমন, ফাইন-টিউনিং একটি ভিন্ন লস ফাংশন ব্যবহার করতে পারে বা প্রাক-প্রশিক্ষিত মডেলকে প্রশিক্ষিত করতে ব্যবহৃত মডেলের তুলনায় ভিন্ন মডেলের ধরন ব্যবহার করতে পারে। উদাহরণস্বরূপ, আপনি একটি রিগ্রেশন মডেল তৈরি করতে একটি প্রাক-প্রশিক্ষিত বড় ইমেজ মডেলকে সূক্ষ্ম-টিউন করতে পারেন যা একটি ইনপুট চিত্রে পাখির সংখ্যা ফেরত দেয়।
নিম্নলিখিত পদগুলির সাথে ফাইন-টিউনিং তুলনা করুন এবং বৈসাদৃশ্য করুন:
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে ফাইন-টিউনিং দেখুন।
শণ
JAX- এর উপরে তৈরি গভীর শিক্ষার জন্য একটি উচ্চ-কর্মক্ষমতাসম্পন্ন ওপেন-সোর্স লাইব্রেরি । ফ্ল্যাক্স নিউরাল নেটওয়ার্কের প্রশিক্ষণের জন্য ফাংশন প্রদান করে, সেইসাথে তাদের কার্যকারিতা মূল্যায়নের পদ্ধতি।
ফ্ল্যাক্সফর্মার
একটি ওপেন সোর্স ট্রান্সফরমার লাইব্রেরি , ফ্ল্যাক্সের উপর নির্মিত, যা প্রাথমিকভাবে প্রাকৃতিক ভাষা প্রক্রিয়াকরণ এবং মাল্টিমোডাল গবেষণার জন্য ডিজাইন করা হয়েছে।
জি
মিথুন
Google-এর সবচেয়ে উন্নত AI সমন্বিত ইকোসিস্টেম। এই ইকোসিস্টেমের উপাদানগুলির মধ্যে রয়েছে:
- বিভিন্ন মিথুন মডেল ।
- মিথুন মডেলের ইন্টারেক্টিভ কথোপকথন ইন্টারফেস। ব্যবহারকারীরা প্রম্পট টাইপ করে এবং মিথুন সেই প্রম্পটে সাড়া দেয়।
- বিভিন্ন জেমিনি API
- মিথুন মডেলের উপর ভিত্তি করে বিভিন্ন ব্যবসায়িক পণ্য; উদাহরণস্বরূপ, গুগল ক্লাউডের জন্য মিথুন ।
মিথুন মডেল
গুগলের অত্যাধুনিক ট্রান্সফরমার -ভিত্তিক মাল্টিমডাল মডেল । মিথুন মডেলগুলি বিশেষভাবে এজেন্টদের সাথে সংহত করার জন্য ডিজাইন করা হয়েছে৷
ব্যবহারকারীরা মিথুন মডেলের সাথে ইন্টারেক্টিভ ডায়ালগ ইন্টারফেস এবং SDK-এর মাধ্যমে বিভিন্ন উপায়ে যোগাযোগ করতে পারে।
তৈরি করা পাঠ্য
সাধারণভাবে, একটি ML মডেল আউটপুট যে পাঠ্য. বৃহৎ ভাষার মডেলের মূল্যায়ন করার সময়, কিছু মেট্রিক্স উত্পন্ন পাঠ্যকে রেফারেন্স পাঠ্যের সাথে তুলনা করে। উদাহরণস্বরূপ, ধরুন আপনি একটি এমএল মডেল ফরাসি থেকে ডাচ ভাষায় কতটা কার্যকরভাবে অনুবাদ করে তা নির্ধারণ করার চেষ্টা করছেন। এই ক্ষেত্রে:
- জেনারেট করা পাঠ্য হল ডাচ অনুবাদ যা ML মডেল আউটপুট করে।
- রেফারেন্স টেক্সট হল ডাচ অনুবাদ যা একজন মানব অনুবাদক (বা সফ্টওয়্যার) তৈরি করে।
মনে রাখবেন কিছু মূল্যায়ন কৌশল রেফারেন্স টেক্সট জড়িত না.
জেনারেটিভ এআই
কোনো আনুষ্ঠানিক সংজ্ঞা ছাড়াই একটি উদীয়মান রূপান্তরমূলক ক্ষেত্র। এটি বলেছে, বেশিরভাগ বিশেষজ্ঞরা সম্মত হন যে জেনারেটিভ এআই মডেলগুলি নিম্নলিখিত সমস্ত সামগ্রী তৈরি করতে পারে ("উত্পন্ন"):
- জটিল
- সুসঙ্গত
- মূল
উদাহরণস্বরূপ, একটি জেনারেটিভ এআই মডেল পরিশীলিত প্রবন্ধ বা চিত্র তৈরি করতে পারে।
LSTMs এবং RNN সহ কিছু আগের প্রযুক্তিও আসল এবং সুসংগত বিষয়বস্তু তৈরি করতে পারে। কিছু বিশেষজ্ঞ এই আগের প্রযুক্তিগুলিকে জেনারেটিভ AI হিসাবে দেখেন, অন্যরা মনে করেন যে সত্যিকারের জেনারেটিভ AI-এর জন্য আগের প্রযুক্তিগুলি তৈরি করতে পারে তার চেয়ে আরও জটিল আউটপুট প্রয়োজন।
ভবিষ্যদ্বাণীমূলক ML এর সাথে বৈসাদৃশ্য।
সুবর্ণ প্রতিক্রিয়া
একটি উত্তর ভাল হতে পরিচিত. উদাহরণস্বরূপ, নিম্নলিখিত প্রম্পট দেওয়া হয়েছে:
2 + 2
সুবর্ণ প্রতিক্রিয়া আশা করা যায়:
4
জিপিটি (জেনারেটিভ প্রাক-প্রশিক্ষিত ট্রান্সফরমার)
OpenAI দ্বারা বিকশিত ট্রান্সফরমার -ভিত্তিক বড় ভাষা মডেলের একটি পরিবার।
GPT ভেরিয়েন্টগুলি একাধিক পদ্ধতিতে প্রয়োগ করতে পারে, যার মধ্যে রয়েছে:
- ইমেজ জেনারেশন (উদাহরণস্বরূপ, ImageGPT)
- টেক্সট-টু-ইমেজ জেনারেশন (উদাহরণস্বরূপ, DALL-E )।
এইচ
হ্যালুসিনেশন
একটি জেনারেটিভ এআই মডেল দ্বারা প্রশংসনীয়-আপাত কিন্তু বাস্তবে ভুল আউটপুট উৎপাদন যা বাস্তব জগৎ সম্পর্কে একটি দাবী করে। উদাহরণস্বরূপ, একটি জেনারেটিভ এআই মডেল যা দাবি করে যে বারাক ওবামা 1865 সালে মারা গিয়েছিলেন তা হ্যালুসিনেটিং ।
মানুষের মূল্যায়ন
একটি প্রক্রিয়া যেখানে লোকেরা একটি এমএল মডেলের আউটপুটের গুণমান বিচার করে; উদাহরণস্বরূপ, দ্বিভাষিক লোকেদের একটি ML অনুবাদ মডেলের গুণমান বিচার করা। মানুষের মূল্যায়ন বিশেষ করে এমন মডেল বিচার করার জন্য উপযোগী যেগুলোর কোনো সঠিক উত্তর নেই।
স্বয়ংক্রিয় মূল্যায়ন এবং অটোরাটার মূল্যায়নের সাথে বৈসাদৃশ্য।
আমি
প্রেক্ষাপটে শিক্ষা
কয়েক শট প্রম্পটিং এর সমার্থক।
এল
LaMDA (সংলাপ অ্যাপ্লিকেশনের জন্য ভাষা মডেল)
একটি ট্রান্সফরমার -ভিত্তিক বৃহৎ ভাষা মডেল যা Google দ্বারা তৈরি করা হয়েছে একটি বৃহৎ ডায়ালগ ডেটাসেটে প্রশিক্ষণ দেওয়া হয়েছে যা বাস্তবসম্মত কথোপকথনমূলক প্রতিক্রিয়া তৈরি করতে পারে।
LaMDA: আমাদের যুগান্তকারী কথোপকথন প্রযুক্তি একটি ওভারভিউ প্রদান করে।
ভাষার মডেল
একটি মডেল যা একটি টোকেন বা টোকেনের ক্রম টোকেনগুলির একটি দীর্ঘ ক্রমানুসারে ঘটানোর সম্ভাবনা অনুমান করে৷
দেখুন একটি ভাষা মডেল কি? আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে।
বড় ভাষা মডেল
ন্যূনতম, একটি ভাষার মডেলে অনেক বেশি সংখ্যক পরামিতি রয়েছে। আরও অনানুষ্ঠানিকভাবে, যেকোনো ট্রান্সফরমার -ভিত্তিক ভাষা মডেল, যেমন জেমিনি বা GPT ।
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে বড় ভাষা মডেল (এলএলএম) দেখুন।
সুপ্ত স্থান
স্থান এমবেডিং জন্য সমার্থক.
Levenshtein দূরত্ব
একটি সম্পাদনা দূরত্ব মেট্রিক যা একটি শব্দ থেকে অন্য শব্দে পরিবর্তন করার জন্য প্রয়োজনীয় কম মুছে ফেলা, সন্নিবেশ করা এবং বিকল্প ক্রিয়াকলাপ গণনা করে৷ উদাহরণস্বরূপ, "হার্ট" এবং "ডার্টস" শব্দের মধ্যে লেভেনশটাইনের দূরত্ব তিনটি কারণ নিম্নলিখিত তিনটি সম্পাদনা একটি শব্দকে অন্য শব্দে পরিণত করার জন্য সবচেয়ে কম পরিবর্তন:
- হৃদয় → deart ("d" এর সাথে "h" বিকল্প)
- deart → ডার্ট ("e" মুছুন)
- ডার্ট → ডার্টস ("s" ঢোকান)
উল্লেখ্য যে পূর্ববর্তী ক্রম তিনটি সম্পাদনার একমাত্র পথ নয়।
এলএলএম
বড় ভাষার মডেলের সংক্ষিপ্ত রূপ।
এলএলএম মূল্যায়ন (ইভাল)
বড় ভাষা মডেল (LLMs) এর কর্মক্ষমতা মূল্যায়ন করার জন্য মেট্রিক্স এবং বেঞ্চমার্কের একটি সেট। উচ্চ স্তরে, এলএলএম মূল্যায়ন:
- এলএলএম-এর উন্নতি প্রয়োজন এমন ক্ষেত্রগুলি চিহ্নিত করতে গবেষকদের সাহায্য করুন।
- বিভিন্ন এলএলএম তুলনা করতে এবং একটি নির্দিষ্ট কাজের জন্য সেরা এলএলএম সনাক্ত করতে কার্যকর।
- LLM গুলি নিরাপদ এবং ব্যবহারের জন্য নৈতিক তা নিশ্চিত করতে সাহায্য করুন৷
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে বড় ভাষা মডেল (এলএলএম) দেখুন।
LoRA
নিম্ন-র্যাঙ্ক অভিযোজনযোগ্যতার সংক্ষিপ্ত রূপ।
নিম্ন-র্যাঙ্ক অভিযোজনযোগ্যতা (LoRA)
সূক্ষ্ম টিউনিংয়ের জন্য একটি প্যারামিটার-দক্ষ কৌশল যা মডেলের প্রাক-প্রশিক্ষিত ওজনগুলিকে "হিমায়িত" করে (যেমন সেগুলি আর পরিবর্তন করা যায় না) এবং তারপরে মডেলের মধ্যে প্রশিক্ষণযোগ্য ওজনের একটি ছোট সেট সন্নিবেশ করায়। প্রশিক্ষণযোগ্য ওজনের এই সেটটি ("আপডেট ম্যাট্রিক্স" নামেও পরিচিত) বেস মডেলের তুলনায় যথেষ্ট ছোট এবং তাই প্রশিক্ষন করা অনেক দ্রুত।
LoRA নিম্নলিখিত সুবিধা প্রদান করে:
- ডোমেনের জন্য একটি মডেলের ভবিষ্যদ্বাণীর গুণমান উন্নত করে যেখানে সূক্ষ্ম টিউনিং প্রয়োগ করা হয়।
- একটি মডেলের সমস্ত প্যারামিটার সূক্ষ্ম-টিউন করার প্রয়োজন হয় এমন কৌশলগুলির চেয়ে দ্রুত ফাইন-টিউন।
- একই বেস মডেল ভাগ করে নেওয়া একাধিক বিশেষ মডেলের একযোগে পরিবেশন সক্ষম করে অনুমানের গণনামূলক খরচ হ্রাস করে।
এম
মুখোশযুক্ত ভাষা মডেল
একটি ভাষা মডেল যা প্রার্থীর টোকেনগুলির একটি ক্রমানুসারে শূন্যস্থান পূরণ করার সম্ভাবনার পূর্বাভাস দেয়৷ উদাহরণস্বরূপ, একটি মুখোশযুক্ত ভাষা মডেল নিম্নলিখিত বাক্যে আন্ডারলাইন প্রতিস্থাপন করতে প্রার্থীর শব্দ(গুলি) জন্য সম্ভাব্যতা গণনা করতে পারে:
টুপির ____ ফিরে এল।
সাহিত্য সাধারণত আন্ডারলাইনের পরিবর্তে স্ট্রিং "MASK" ব্যবহার করে। যেমন:
টুপিতে "মাস্ক" ফিরে এসেছে।
বেশিরভাগ আধুনিক মুখোশযুক্ত ভাষার মডেলগুলি দ্বিমুখী ।
গড় নির্ভুলতা k এ গড় (mAP@k)
একটি বৈধতা ডেটাসেট জুড়ে k স্কোরে সমস্ত গড় নির্ভুলতার পরিসংখ্যানগত গড়। k-এ গড় গড় নির্ভুলতার একটি ব্যবহার হল একটি সুপারিশ সিস্টেম দ্বারা উত্পন্ন সুপারিশের গুণমান বিচার করা।
যদিও "গড় গড়" শব্দগুচ্ছ অপ্রয়োজনীয় শোনায়, মেট্রিকের নামটি উপযুক্ত। সর্বোপরি, এই মেট্রিকটি k মানগুলিতে একাধিক গড় নির্ভুলতার গড় খুঁজে পায়।
মেটা-লার্নিং
মেশিন লার্নিংয়ের একটি উপসেট যা একটি শেখার অ্যালগরিদম আবিষ্কার করে বা উন্নত করে। একটি মেটা-লার্নিং সিস্টেমের লক্ষ্য হতে পারে একটি মডেলকে দ্রুত একটি নতুন কাজ শিখতে শেখার জন্য অল্প পরিমাণ ডেটা বা পূর্ববর্তী কাজগুলিতে অর্জিত অভিজ্ঞতা থেকে। মেটা-লার্নিং অ্যালগরিদমগুলি সাধারণত নিম্নলিখিতগুলি অর্জন করার চেষ্টা করে:
- হ্যান্ড-ইঞ্জিনিয়ার করা বৈশিষ্ট্যগুলি উন্নত বা শিখুন (যেমন একটি ইনিশিয়ালাইজার বা একটি অপ্টিমাইজার)।
- আরও ডেটা-দক্ষ এবং গণনা-দক্ষ হন।
- সাধারণীকরণ উন্নত করুন।
মেটা-লার্নিং অল্প-শট শেখার সাথে সম্পর্কিত।
বিশেষজ্ঞদের মিশ্রণ
একটি প্রদত্ত ইনপুট টোকেন বা উদাহরণ প্রক্রিয়া করার জন্য শুধুমাত্র এর পরামিতিগুলির একটি উপসেট (একজন বিশেষজ্ঞ হিসাবে পরিচিত) ব্যবহার করে নিউরাল নেটওয়ার্ক দক্ষতা বাড়ানোর একটি স্কিম। একটি গেটিং নেটওয়ার্ক প্রতিটি ইনপুট টোকেন বা উদাহরণ সঠিক বিশেষজ্ঞের কাছে পাঠায়।
বিস্তারিত জানার জন্য, নিচের যে কোনো একটি পেপার দেখুন:
- আক্রোশজনকভাবে বৃহৎ নিউরাল নেটওয়ার্ক: বিক্ষিপ্তভাবে গেটেড মিশ্রণ-অফ-বিশেষজ্ঞ স্তর
- এক্সপার্ট চয়েস রাউটিং সহ বিশেষজ্ঞদের মিশ্রণ
এমএমআইটি
মাল্টিমোডাল নির্দেশের সংক্ষিপ্ত রূপ।
পদ্ধতি
একটি উচ্চ-স্তরের ডেটা বিভাগ। উদাহরণস্বরূপ, সংখ্যা, পাঠ্য, চিত্র, ভিডিও এবং অডিও পাঁচটি ভিন্ন পদ্ধতি।
মডেল সমান্তরালতা
প্রশিক্ষণ বা অনুমান স্কেলিং করার একটি উপায় যা একটি মডেলের বিভিন্ন অংশকে বিভিন্ন ডিভাইসে রাখে। মডেল সমান্তরালতা এমন মডেলগুলিকে সক্ষম করে যা একক ডিভাইসে ফিট করার জন্য খুব বড়।
মডেল সমান্তরালতা বাস্তবায়নের জন্য, একটি সিস্টেম সাধারণত নিম্নলিখিতগুলি করে:
- শার্ডস (বিভক্ত) মডেলটিকে ছোট অংশগুলিতে।
- একাধিক প্রসেসর জুড়ে সেই ছোট অংশগুলির প্রশিক্ষণ বিতরণ করে। প্রতিটি প্রসেসর মডেলের নিজস্ব অংশকে প্রশিক্ষণ দেয়।
- একটি একক মডেল তৈরি করতে ফলাফলগুলি একত্রিত করে।
মডেল সমান্তরালতা প্রশিক্ষণ ধীর করে দেয়।
ডেটা সমান্তরালতাও দেখুন।
MOE
বিশেষজ্ঞদের মিশ্রণের জন্য সংক্ষেপণ।
মাল্টি-হেড স্ব-মনোভাব
স্ব-মনোভাবের একটি এক্সটেনশন যা ইনপুট সিকোয়েন্সে প্রতিটি অবস্থানের জন্য একাধিকবার স্ব-অনুমোদন প্রক্রিয়া প্রয়োগ করে।
ট্রান্সফর্মারগুলি মাল্টি-হেড স্ব-মনোভাব প্রবর্তন করে।
মাল্টিমোডাল নির্দেশনা-সুরযুক্ত
একটি নির্দেশ-সুরযুক্ত মডেল যা চিত্র, ভিডিও এবং অডিওর মতো পাঠ্য ছাড়িয়ে ইনপুট প্রক্রিয়া করতে পারে।
মাল্টিমোডাল মডেল
এমন একটি মডেল যার ইনপুট, আউটপুট বা উভয়ই একাধিক মোডালিটি অন্তর্ভুক্ত করে। উদাহরণস্বরূপ, এমন একটি মডেল বিবেচনা করুন যা একটি চিত্র এবং একটি পাঠ্য ক্যাপশন (দুটি পদ্ধতি) বৈশিষ্ট্য হিসাবে গ্রহণ করে এবং চিত্রটির জন্য পাঠ্য ক্যাপশনটি কতটা উপযুক্ত তা নির্দেশ করে এমন একটি স্কোর আউটপুট দেয়। সুতরাং, এই মডেলের ইনপুটগুলি মাল্টিমোডাল এবং আউটপুটটি অবিচ্ছিন্ন।
এন
প্রাকৃতিক ভাষা প্রক্রিয়াকরণ
কোনও ব্যবহারকারী ভাষাগত বিধি ব্যবহার করে কী বলেছিলেন বা টাইপ করেছেন তা প্রক্রিয়া করার জন্য কম্পিউটার শেখানোর ক্ষেত্র। প্রায় সমস্ত আধুনিক প্রাকৃতিক ভাষা প্রক্রিয়াকরণ মেশিন লার্নিংয়ের উপর নির্ভর করে।প্রাকৃতিক ভাষা বোঝা
প্রাকৃতিক ভাষা প্রক্রিয়াজাতকরণের একটি উপসেট যা বলা বা টাইপ করা কোনও কিছুর উদ্দেশ্য নির্ধারণ করে। প্রাকৃতিক ভাষা বোঝাপড়া প্রাকৃতিক ভাষা প্রক্রিয়াজাতকরণের বাইরে যেতে পারে প্রসঙ্গ, কটাক্ষ এবং অনুভূতির মতো ভাষার জটিল দিকগুলি বিবেচনা করতে।
এন-গ্রাম
এন শব্দের একটি আদেশযুক্ত ক্রম। উদাহরণস্বরূপ, সত্যই পাগল একটি 2-গ্রাম। কারণ অর্ডার প্রাসঙ্গিক, ম্যাডলি সত্যই সত্যই উন্মাদতার চেয়ে আলাদা 2-গ্রাম।
| এন | এই ধরণের এন-গ্রামের নাম (গুলি) | উদাহরণ |
|---|---|---|
| 2 | বিগরাম বা 2-গ্রাম | যেতে, যেতে, দুপুরের খাবার খেতে, রাতের খাবার খেতে |
| 3 | ট্রাইগ্রাম বা 3-গ্রাম | খুব বেশি খেয়েছে, সুখের পরে, বেল টোলস |
| 4 | 4-গ্রাম | পার্কে হাঁটুন, বাতাসে ধুলো, ছেলেটি মসুর খেয়েছে |
অনেক প্রাকৃতিক ভাষা বোঝার মডেলগুলি পরবর্তী শব্দটির পূর্বাভাস দেওয়ার জন্য এন-গ্রামগুলির উপর নির্ভর করে যা ব্যবহারকারী টাইপ করবেন বা বলবেন। উদাহরণস্বরূপ, ধরুন কোনও ব্যবহারকারী সুখে কখনও টাইপ করেছেন। ট্রাইগ্রামগুলির উপর ভিত্তি করে একটি এনএলইউ মডেল সম্ভবত পূর্বাভাস দেবে যে ব্যবহারকারী পরবর্তী শব্দটি পরে টাইপ করবে।
শব্দের ব্যাগের সাথে এন-গ্রামগুলি বিপরীতে, যা শব্দের আনঅর্ডারড সেট।
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে বড় ভাষার মডেলগুলি দেখুন।
এনএলপি
প্রাকৃতিক ভাষা প্রক্রিয়াজাতকরণের জন্য সংক্ষেপণ।
এনএলইউ
প্রাকৃতিক ভাষা বোঝার জন্য সংক্ষেপণ।
কারও সঠিক উত্তর নেই (নোরা)
একটি প্রম্পট একাধিক উপযুক্ত প্রতিক্রিয়া আছে। উদাহরণস্বরূপ, নিম্নলিখিত প্রম্পটের কোনও সঠিক উত্তর নেই:
হাতি সম্পর্কে একটি রসিকতা বলুন।
কোনও-ডান-উত্তর প্রম্পটগুলি মূল্যায়ন করা চ্যালেঞ্জিং হতে পারে।
নোরা
কারওর জন্য সংক্ষিপ্তসার সঠিক উত্তর নেই ।
ও
এক শট অনুরোধ
একটি প্রম্পট যাতে বৃহত্তর ভাষার মডেলটির প্রতিক্রিয়া জানানো উচিত তা প্রদর্শন করে এমন একটি উদাহরণ রয়েছে। উদাহরণস্বরূপ, নিম্নলিখিত প্রম্পটে একটি বৃহত ভাষার মডেল দেখানো একটি উদাহরণ রয়েছে যা এটি কোনও প্রশ্নের উত্তর কীভাবে দেওয়া উচিত।
| একটি প্রম্পটের অংশ | নোট |
|---|---|
| নির্দিষ্ট দেশের সরকারী মুদ্রা কী? | আপনি যে প্রশ্নের উত্তর চান তা প্রশ্নের উত্তর দিন। |
| ফ্রান্স: ইউরো | একটি উদাহরণ. |
| ভারত: | আসল ক্যোয়ারী। |
নিম্নলিখিত শর্তগুলির সাথে এক-শট অনুরোধের তুলনা করুন এবং বিপরীতে:
পৃ
প্যারামিটার-দক্ষ টিউনিং
পুরো সূক্ষ্ম-টিউনিংয়ের চেয়ে আরও দক্ষতার সাথে একটি বৃহত প্রাক-প্রশিক্ষিত ভাষার মডেল (পিএলএম) সূক্ষ্ম সুর করার কৌশলগুলির একটি সেট। প্যারামিটার-দক্ষ টিউনিং সাধারণত সূক্ষ্ম-সুরের তুলনায় খুব কম প্যারামিটারগুলি সূক্ষ্ম-টিউন করে, তবুও সাধারণত একটি বৃহত ভাষার মডেল তৈরি করে যা পুরো ফাইন-টিউনিং থেকে নির্মিত একটি বৃহত ভাষার মডেল হিসাবে (বা প্রায় পাশাপাশি) সম্পাদন করে।
এর সাথে তুলনা করুন এবং বিপরীতে প্যারামিটার-দক্ষ টিউনিং:
প্যারামিটার-দক্ষ টিউনিং প্যারামিটার-দক্ষ সূক্ষ্ম-টিউনিং হিসাবেও পরিচিত।
পাইপলাইন
মডেল সমান্তরালতার একটি ফর্ম যেখানে কোনও মডেলের প্রক্রিয়াকরণটি ধারাবাহিক পর্যায়ে বিভক্ত হয় এবং প্রতিটি পর্যায়টি অন্য কোনও ডিভাইসে কার্যকর করা হয়। যখন একটি পর্যায়টি একটি ব্যাচ প্রক্রিয়াজাত করছে, পূর্ববর্তী পর্যায়ে পরবর্তী ব্যাচে কাজ করতে পারে।
মঞ্চস্থ প্রশিক্ষণও দেখুন।
পিএলএম
প্রাক-প্রশিক্ষিত ভাষার মডেলের সংক্ষেপণ।
অবস্থানগত এনকোডিং
টোকেনের এম্বেডিংয়ের ক্রমটিতে একটি টোকেনের অবস্থান সম্পর্কে তথ্য যুক্ত করার একটি কৌশল। ট্রান্সফর্মার মডেলগুলি ক্রমের বিভিন্ন অংশের মধ্যে সম্পর্ক আরও ভালভাবে বুঝতে পজিশনাল এনকোডিং ব্যবহার করে।
পজিশনাল এনকোডিংয়ের একটি সাধারণ প্রয়োগ একটি সাইনোসয়েডাল ফাংশন ব্যবহার করে। (বিশেষত, সাইনোসয়েডাল ফাংশনের ফ্রিকোয়েন্সি এবং প্রশস্ততা সিকোয়েন্সে টোকেনের অবস্থান দ্বারা নির্ধারিত হয়)) এই কৌশলটি একটি ট্রান্সফর্মার মডেলকে তাদের অবস্থানের উপর ভিত্তি করে ক্রমের বিভিন্ন অংশে অংশ নিতে শিখতে সক্ষম করে।
প্রশিক্ষিত পোস্ট মডেল
আলগাভাবে সংজ্ঞায়িত শব্দ যা সাধারণত একটি প্রাক-প্রশিক্ষিত মডেলকে বোঝায় যা কিছু পোস্ট-প্রসেসিংয়ের মধ্য দিয়ে গেছে, যেমন নিম্নলিখিতগুলির এক বা একাধিক:
কে এ যথার্থতা (যথার্থ@কে)
আইটেমগুলির একটি র্যাঙ্কড (অর্ডার করা) তালিকা মূল্যায়নের জন্য একটি মেট্রিক। কে এ নির্ভুলতা সেই তালিকার প্রথম কে আইটেমগুলির ভগ্নাংশ সনাক্ত করে যা "প্রাসঙ্গিক"। অর্থাৎ:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
কে এর মান অবশ্যই প্রত্যাবর্তিত তালিকার দৈর্ঘ্যের চেয়ে কম বা সমান হতে হবে। নোট করুন যে ফিরে আসা তালিকার দৈর্ঘ্য গণনার অংশ নয়।
প্রাসঙ্গিকতা প্রায়শই বিষয়গত হয়; এমনকি বিশেষজ্ঞ মানব মূল্যায়নকারীরা প্রায়শই কোন আইটেম প্রাসঙ্গিক তা নিয়ে একমত নন।
এর সাথে তুলনা করুন:
প্রাক-প্রশিক্ষিত মডেল
সাধারণত, একটি মডেল যা ইতিমধ্যে প্রশিক্ষিত হয়েছে। এই শব্দটির অর্থ পূর্বে প্রশিক্ষিত এম্বেডিং ভেক্টরও হতে পারে।
প্রাক-প্রশিক্ষিত ভাষার মডেল শব্দটি সাধারণত ইতিমধ্যে প্রশিক্ষিত বৃহত ভাষার মডেলকে বোঝায়।
প্রাক-প্রশিক্ষণ
একটি বড় ডেটাসেটে একটি মডেলের প্রাথমিক প্রশিক্ষণ। কিছু প্রাক-প্রশিক্ষিত মডেল হ'ল আনাড়ি জায়ান্ট এবং সাধারণত অতিরিক্ত প্রশিক্ষণের মাধ্যমে অবশ্যই পরিমার্জন করা উচিত। উদাহরণস্বরূপ, এমএল বিশেষজ্ঞরা উইকিপিডিয়ায় সমস্ত ইংরেজি পৃষ্ঠাগুলির মতো একটি বিশাল পাঠ্য ডেটাসেটে একটি বৃহত ভাষার মডেল প্রাক-প্রশিক্ষণ দিতে পারেন। প্রাক-প্রশিক্ষণ অনুসরণ করে, ফলাফলের মডেলটি নিম্নলিখিত যে কোনও কৌশলগুলির মাধ্যমে আরও পরিমার্জন করা যেতে পারে:
প্রম্পট
যে কোনও পাঠ্য নির্দিষ্ট উপায়ে আচরণ করার জন্য মডেলটিকে শর্ত করতে একটি বৃহত ভাষার মডেলটিতে ইনপুট হিসাবে প্রবেশ করেছে। প্রম্পটগুলি একটি বাক্যাংশ বা নির্বিচারে দীর্ঘ হিসাবে সংক্ষিপ্ত হতে পারে (উদাহরণস্বরূপ, একটি উপন্যাসের পুরো পাঠ্য)। প্রম্পটগুলি নিম্নলিখিত সারণীতে প্রদর্শিতগুলি সহ একাধিক বিভাগে পড়ে:
| প্রম্পট বিভাগ | উদাহরণ | নোট |
|---|---|---|
| প্রশ্ন | একটি কবুতর কত দ্রুত উড়তে পারে? | |
| নির্দেশ | সালিশ সম্পর্কে একটি মজার কবিতা লিখুন। | একটি প্রম্পট যা বড় ভাষার মডেলটিকে কিছু করতে বলে। |
| উদাহরণ | HTML এ মার্কডাউন কোডটি অনুবাদ করুন। যেমন: মার্কডাউন: * তালিকা আইটেম এইচটিএমএল: <ul> <li> তালিকা আইটেম </li> </ul> | এই উদাহরণ প্রম্পটে প্রথম বাক্যটি একটি নির্দেশনা। প্রম্পটের বাকী অংশগুলি উদাহরণ। |
| ভূমিকা | পদার্থবিজ্ঞানের পিএইচডি -তে মেশিন লার্নিং প্রশিক্ষণে কেন গ্রেডিয়েন্ট বংশোদ্ভূত ব্যবহৃত হয় তা ব্যাখ্যা করুন। | বাক্যটির প্রথম অংশটি একটি নির্দেশনা; "পদার্থবিজ্ঞানের পিএইচডি" বাক্যাংশটি ভূমিকা অংশ। |
| মডেলটি সম্পূর্ণ করার জন্য আংশিক ইনপুট | যুক্তরাজ্যের প্রধানমন্ত্রী থাকেন | একটি আংশিক ইনপুট প্রম্পট হয় হঠাৎ করে শেষ হতে পারে (যেমন এই উদাহরণটি হয়) বা একটি আন্ডারস্কোর দিয়ে শেষ হতে পারে। |
একটি জেনারেটর এআই মডেল পাঠ্য, কোড, চিত্র, এম্বেডিংস , ভিডিও… প্রায় কোনও কিছুর সাথে একটি প্রম্পটে সাড়া দিতে পারে।
প্রম্পট-ভিত্তিক শেখা
নির্দিষ্ট মডেলের একটি ক্ষমতা যা তাদের স্বেচ্ছাসেবী পাঠ্য ইনপুট ( প্রম্পটস ) এর প্রতিক্রিয়াতে তাদের আচরণকে মানিয়ে নিতে সক্ষম করে। একটি সাধারণ প্রম্পট-ভিত্তিক শেখার দৃষ্টান্তে, একটি বৃহত ভাষার মডেল পাঠ্য তৈরি করে একটি প্রম্পটে সাড়া দেয়। উদাহরণস্বরূপ, ধরুন কোনও ব্যবহারকারী নিম্নলিখিত প্রম্পটে প্রবেশ করেছেন:
নিউটনের গতির তৃতীয় আইন সংক্ষিপ্ত করুন।
প্রম্পট-ভিত্তিক শিক্ষার জন্য সক্ষম একটি মডেল পূর্ববর্তী প্রম্পটের উত্তর দেওয়ার জন্য বিশেষভাবে প্রশিক্ষিত নয়। বরং, মডেলটি পদার্থবিজ্ঞান সম্পর্কে প্রচুর তথ্য "জানে", সাধারণ ভাষার নিয়ম সম্পর্কে অনেক কিছু এবং সাধারণত কার্যকর উত্তরগুলি কী তা নিয়ে আসে সে সম্পর্কে অনেক কিছু। এই জ্ঞানটি একটি (আশাবাদী) দরকারী উত্তর সরবরাহ করার জন্য যথেষ্ট। অতিরিক্ত মানব প্রতিক্রিয়া ("সেই উত্তরটি খুব জটিল ছিল" "বা" একটি প্রতিক্রিয়া কী? ") কিছু প্রম্পট-ভিত্তিক শেখার সিস্টেমগুলিকে ধীরে ধীরে তাদের উত্তরের কার্যকারিতা উন্নত করতে সক্ষম করে।
প্রম্পট ডিজাইন
প্রম্পট ইঞ্জিনিয়ারিংয়ের প্রতিশব্দ।
প্রম্পট ইঞ্জিনিয়ারিং
তৈরির শিল্পটি একটি বৃহত ভাষার মডেল থেকে কাঙ্ক্ষিত প্রতিক্রিয়াগুলি প্রকাশ করে। মানুষ প্রম্পট ইঞ্জিনিয়ারিং সম্পাদন করে। একটি বৃহত ভাষার মডেল থেকে দরকারী প্রতিক্রিয়াগুলি নিশ্চিত করার জন্য সু-কাঠামোগত প্রম্পটগুলি লেখা একটি অপরিহার্য অঙ্গ। প্রম্পট ইঞ্জিনিয়ারিং অনেকগুলি কারণের উপর নির্ভর করে:
- ডেটাসেটটি প্রাক-প্রশিক্ষণের জন্য ব্যবহৃত হত এবং সম্ভবত বড় ভাষার মডেলটিকে সূক্ষ্ম-সুর করতে ব্যবহৃত হত।
- তাপমাত্রা এবং অন্যান্য ডিকোডিং প্যারামিটারগুলি যা মডেল প্রতিক্রিয়া তৈরি করতে ব্যবহার করে।
প্রম্পট ডিজাইন প্রম্পট ইঞ্জিনিয়ারিংয়ের প্রতিশব্দ।
সহায়ক প্রম্পটগুলি লেখার বিষয়ে আরও তথ্যের জন্য প্রম্পট ডিজাইনের পরিচিতি দেখুন।
প্রম্পট টিউনিং
একটি প্যারামিটার দক্ষ টিউনিং প্রক্রিয়া যা একটি "উপসর্গ" শিখেছে যা সিস্টেমটি প্রকৃত প্রম্পটে প্রস্তুত করে।
প্রম্পট টিউনিংয়ের একটি প্রকরণ - কখনও কখনও উপসর্গ টিউনিং নামে পরিচিত - প্রতিটি স্তরে উপসর্গটি প্রস্তুত করার জন্য। বিপরীতে, বেশিরভাগ প্রম্পট টিউনিং কেবল ইনপুট স্তরটিতে একটি উপসর্গ যুক্ত করে।
আর
কে এ স্মরণ করুন (@কে পুনরুদ্ধার করুন)
সিস্টেমগুলির মূল্যায়ন করার জন্য একটি মেট্রিক যা আইটেমগুলির একটি র্যাঙ্কড (অর্ডার করা) তালিকা আউটপুট দেয়। কে -এ পুনরুদ্ধার করা প্রাসঙ্গিক আইটেমগুলির প্রথম কে আইটেমগুলির ভগ্নাংশটি চিহ্নিত করে যে প্রাসঙ্গিক আইটেমগুলির মোট সংখ্যার মধ্যে ফিরে আসে।
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
কে এ নির্ভুলতার সাথে বৈপরীত্য।
রেফারেন্স পাঠ্য
একটি প্রম্পটে বিশেষজ্ঞের প্রতিক্রিয়া। উদাহরণস্বরূপ, নিম্নলিখিত প্রম্পট দেওয়া:
"আপনার নাম কি?" প্রশ্নটি অনুবাদ করুন ইংরেজি থেকে ফরাসি পর্যন্ত।
একজন বিশেষজ্ঞের প্রতিক্রিয়া হতে পারে:
মন্তব্য vous applez-vous?
বিভিন্ন মেট্রিক (যেমন রাউজ ) রেফারেন্স পাঠ্যটি এমএল মডেলের উত্পন্ন পাঠ্যের সাথে মেলে এমন ডিগ্রি পরিমাপ করে।
ভূমিকা অনুরোধ
প্রম্পটের একটি al চ্ছিক অংশ যা একটি জেনারেটর এআই মডেলের প্রতিক্রিয়ার জন্য একটি লক্ষ্য শ্রোতাদের চিহ্নিত করে। কোনও ভূমিকা প্রম্পট ছাড়াই , একটি বৃহত ভাষার মডেল এমন একটি উত্তর সরবরাহ করে যা প্রশ্ন জিজ্ঞাসা করা ব্যক্তির পক্ষে কার্যকর বা নাও হতে পারে। একটি ভূমিকা প্রম্পটের সাথে , একটি বৃহত ভাষার মডেল এমনভাবে উত্তর দিতে পারে যা নির্দিষ্ট লক্ষ্য দর্শকদের জন্য আরও উপযুক্ত এবং আরও সহায়ক। উদাহরণস্বরূপ, নিম্নলিখিত অনুরোধগুলির ভূমিকা প্রম্পট অংশটি বোল্ডফেসে রয়েছে:
- অর্থনীতিতে পিএইচডি করার জন্য এই দস্তাবেজটি সংক্ষিপ্ত করুন।
- দশ বছরের পুরানো জন্য জোয়ারগুলি কীভাবে কাজ করে তা বর্ণনা করুন।
- ২০০৮ আর্থিক সংকট ব্যাখ্যা করুন। আপনি একটি ছোট বাচ্চা, বা একটি সোনার পুনরুদ্ধারকারী হিসাবে কথা বলুন।
ROUGE (প্রত্যাহার-অরিয়েন্টেড আন্ডারস্টাডি ফর জিস্টিং ইভালুয়েশন)
মেট্রিকের একটি পরিবার যা স্বয়ংক্রিয় সংক্ষিপ্তকরণ এবং মেশিন অনুবাদ মডেলগুলি মূল্যায়ন করে। রাউজ মেট্রিকগুলি এমন একটি ডিগ্রি নির্ধারণ করে যা কোনও রেফারেন্স পাঠ্য এমএল মডেলের উত্পন্ন পাঠ্যকে ওভারল্যাপ করে। রাউজ পরিবারের প্রতিটি সদস্য ভিন্ন উপায়ে ওভারল্যাপ করে। উচ্চতর রাউজ স্কোরগুলি রেফারেন্স পাঠ্য এবং উত্পন্ন পাঠ্যের মধ্যে আরও সাদৃশ্য নির্দেশ করে নিম্ন রুজ স্কোরগুলির চেয়ে।
প্রতিটি রাউজ পরিবারের সদস্য সাধারণত নিম্নলিখিত মেট্রিকগুলি তৈরি করে:
- যথার্থতা
- স্মরণ করুন
- চ ঘ
বিশদ এবং উদাহরণগুলির জন্য, দেখুন:
রুজ-এল
রাউজ পরিবারের একজন সদস্য রেফারেন্স পাঠ্য এবং উত্পন্ন পাঠ্যের মধ্যে দীর্ঘতম সাধারণ পরবর্তীকালের দৈর্ঘ্যের দিকে মনোনিবেশ করেছিলেন। নিম্নলিখিত সূত্রগুলি রুজ-এল এর জন্য পুনরুদ্ধার এবং নির্ভুলতা গণনা করে:
তারপরে আপনি রাউজ-এল রিকল এবং রাউজ-এল প্রিসিশনকে একক মেট্রিকের মধ্যে রোল আপ করতে এফ 1 ব্যবহার করতে পারেন:
রাউজ-এল রেফারেন্স পাঠ্য এবং উত্পন্ন পাঠ্যের যে কোনও নতুন লাইন উপেক্ষা করে, তাই দীর্ঘতম সাধারণ অনুপাত একাধিক বাক্য অতিক্রম করতে পারে। যখন রেফারেন্স পাঠ্য এবং উত্পন্ন পাঠ্য একাধিক বাক্য জড়িত থাকে, তখন রাউজ- লাম নামক রাউজ- এল এর একটি প্রকরণটি সাধারণত একটি ভাল মেট্রিক হয়। রাউজ-লসাম একটি উত্তরণে প্রতিটি বাক্যটির জন্য দীর্ঘতম সাধারণ উপসর্গ নির্ধারণ করে এবং তারপরে সেই দীর্ঘতম সাধারণ পরবর্তীকালের গড় গণনা করে।
রুজ-এন
রাউজ পরিবারের মধ্যে মেট্রিকগুলির একটি সেট যা রেফারেন্স পাঠ্য এবং উত্পন্ন পাঠ্যের একটি নির্দিষ্ট আকারের ভাগ করা এন-গ্রামগুলির সাথে তুলনা করে। যেমন:
- রাউজ -১ রেফারেন্স পাঠ্য এবং উত্পন্ন পাঠ্যে ভাগ করা টোকেনের সংখ্যা পরিমাপ করে।
- রাউজ -২ রেফারেন্স পাঠ্য এবং উত্পন্ন পাঠ্যে ভাগ করা বিগরাম (2-গ্রাম) এর সংখ্যা পরিমাপ করে।
- রাউজ -3 রেফারেন্স পাঠ্য এবং উত্পন্ন পাঠ্যে ভাগ করা ট্রাইগ্রাম (3-গ্রাম) এর সংখ্যা পরিমাপ করে।
রাউজ-এন পরিবারের যে কোনও সদস্যের জন্য রুজ-এন রিকল এবং রুজ-এন নির্ভুলতা গণনা করতে আপনি নিম্নলিখিত সূত্রগুলি ব্যবহার করতে পারেন:
তারপরে আপনি রাউজ-এন রিকল এবং রুজ-এন নির্ভুলতাটিকে একক মেট্রিকের মধ্যে রোল আপ করতে এফ 1 ব্যবহার করতে পারেন:
রাউজ-এস
রাউজ-এন এর একটি ক্ষমাশীল ফর্ম যা স্কিপ-গ্রাম ম্যাচিংকে সক্ষম করে। এটি হ'ল, রাউজ-এন কেবলমাত্র এন-গ্রামগুলি গণনা করে যা ঠিক মেলে, তবে রাউজ-এসও এক বা একাধিক শব্দ দ্বারা পৃথক এন-গ্রাম গণনা করে। উদাহরণস্বরূপ, নিম্নলিখিত বিবেচনা করুন:
- রেফারেন্স পাঠ্য : সাদা মেঘ
- উত্পন্ন পাঠ্য : সাদা বিলিং মেঘ
রাউজ-এন গণনা করার সময়, 2-গ্রাম, সাদা মেঘগুলি সাদা বিলিং মেঘের সাথে মেলে না। যাইহোক, রাউজ-এস গণনা করার সময়, সাদা মেঘগুলি সাদা বিলিং মেঘের সাথে মেলে।
এস
স্ব-অ্যাটেনশন (যাকে স্ব-অ্যাটেনশন স্তরও বলা হয়)
একটি নিউরাল নেটওয়ার্ক স্তর যা এম্বেডিংগুলির ক্রমকে (উদাহরণস্বরূপ, টোকেন এম্বেডিংস) এম্বেডিংগুলির অন্য ক্রমে রূপান্তর করে। আউটপুট সিকোয়েন্সে প্রতিটি এম্বেডিং একটি মনোযোগ ব্যবস্থার মাধ্যমে ইনপুট ক্রমের উপাদানগুলি থেকে তথ্য সংহত করে নির্মিত হয়।
স্ব-অনুমোদনের স্ব- অংশটি অন্য কোনও প্রসঙ্গের চেয়ে নিজের কাছে উপস্থিত ক্রমকে বোঝায়। স্ব-অ্যাটেনশন ট্রান্সফর্মারগুলির জন্য অন্যতম প্রধান বিল্ডিং ব্লক এবং "ক্যোয়ারী", "কী" এবং "মান" এর মতো অভিধান লুকআপ পরিভাষা ব্যবহার করে।
একটি স্ব-মনোভাব স্তরটি ইনপুট উপস্থাপনার ক্রম দিয়ে শুরু হয়, প্রতিটি শব্দের জন্য একটি করে। একটি শব্দের জন্য ইনপুট উপস্থাপনা একটি সাধারণ এম্বেডিং হতে পারে। একটি ইনপুট ক্রমের প্রতিটি শব্দের জন্য, নেটওয়ার্ক শব্দের পুরো অনুক্রমের প্রতিটি উপাদানের সাথে শব্দের প্রাসঙ্গিকতা স্কোর করে। প্রাসঙ্গিক স্কোরগুলি নির্ধারণ করে যে শব্দের চূড়ান্ত উপস্থাপনা অন্য শব্দের উপস্থাপনাগুলিকে কতটা অন্তর্ভুক্ত করে।
উদাহরণস্বরূপ, নিম্নলিখিত বাক্যটি বিবেচনা করুন:
প্রাণীটি রাস্তায় পার হয়নি কারণ এটি খুব ক্লান্ত ছিল।
নিম্নলিখিত চিত্রটি ( ট্রান্সফর্মার থেকে: ভাষা বোঝার জন্য একটি উপন্যাস নিউরাল নেটওয়ার্ক আর্কিটেকচার ) সর্বনামটির জন্য একটি স্ব-মনোযোগ স্তরটির মনোযোগ প্যাটার্ন দেখায়, প্রতিটি লাইনের অন্ধকারের সাথে প্রতিটি শব্দ প্রতিনিধিত্বকে কতটা অবদান রাখে তা নির্দেশ করে:
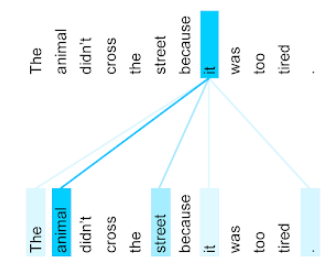
স্ব-অধিকার স্তরটি "এটি" এর সাথে প্রাসঙ্গিক শব্দগুলিকে হাইলাইট করে। এই ক্ষেত্রে, মনোযোগ স্তরটি এমন শব্দগুলি হাইলাইট করতে শিখেছে যা এটি উল্লেখ করতে পারে, প্রাণীকে সর্বোচ্চ ওজন নির্ধারণ করে।
এন টোকেনগুলির ক্রমের জন্য, স্ব-মনোভাবটি এম্বেডিংস এন পৃথক সময়ের ক্রমকে রূপান্তর করে, একবারে প্রতিটি অবস্থানে একবারে।
মনোযোগ এবং মাল্টি-হেড স্ব-অধিকারকেও উল্লেখ করুন।
অনুভূতি বিশ্লেষণ
কোনও গোষ্ঠীর সামগ্রিক মনোভাব - ইতিবাচক বা নেতিবাচক - কোনও পরিষেবা, পণ্য, সংস্থা বা বিষয়কে ধরে রাখার জন্য পরিসংখ্যান বা মেশিন লার্নিং অ্যালগরিদম ব্যবহার করে। উদাহরণস্বরূপ, প্রাকৃতিক ভাষা বোঝাপড়া ব্যবহার করে, একটি অ্যালগরিদম একটি বিশ্ববিদ্যালয় কোর্স থেকে পাঠ্য প্রতিক্রিয়া সম্পর্কে সংবেদন বিশ্লেষণ করতে পারে যে শিক্ষার্থীরা সাধারণত কোর্সটি পছন্দ করে বা অপছন্দ করে তা নির্ধারণ করতে।
আরও তথ্যের জন্য পাঠ্য শ্রেণিবদ্ধকরণ গাইড দেখুন।
সিকোয়েন্স-টু-সিকোয়েন্স টাস্ক
এমন একটি কাজ যা টোকেনগুলির একটি ইনপুট ক্রমকে টোকেনের আউটপুট সিকোয়েন্সে রূপান্তর করে। উদাহরণস্বরূপ, দুটি জনপ্রিয় ধরণের সিকোয়েন্স-টু-সিকোয়েন্স কাজগুলি হ'ল:
- অনুবাদক:
- নমুনা ইনপুট ক্রম: "আমি আপনাকে ভালবাসি।"
- নমুনা আউটপুট ক্রম: "জে টি'মাইম।"
- প্রশ্নের উত্তর:
- নমুনা ইনপুট ক্রম: "নিউ ইয়র্ক সিটিতে আমার কি আমার গাড়ি দরকার?"
- নমুনা আউটপুট ক্রম: "না। আপনার গাড়িটি বাড়িতে রাখুন।"
স্কিপ-গ্রাম
একটি এন-গ্রাম যা মূল প্রসঙ্গ থেকে শব্দ বাদ দিতে পারে (বা "এড়িয়ে যান"), যার অর্থ এন শব্দগুলি মূলত সংলগ্ন নাও হতে পারে। আরও স্পষ্টভাবে, একটি "কে-স্কিপ-এন-গ্রাম" একটি এন-গ্রাম যার জন্য কে শব্দ পর্যন্ত এড়িয়ে যেতে পারে।
উদাহরণস্বরূপ, "দ্য কুইক ব্রাউন ফক্স" এর নিম্নলিখিত সম্ভাব্য 2-গ্রাম রয়েছে:
- "দ্রুত"
- "কুইক ব্রাউন"
- "বাদামী শিয়াল"
একটি "1-স্কিপ-2-গ্রাম" হ'ল শব্দের একটি জুড়ি যা তাদের মধ্যে সর্বাধিক 1 টি শব্দ রয়েছে। অতএব, "দ্য কুইক ব্রাউন ফক্স" এর নিম্নলিখিত 1-স্কিপ 2-গ্রাম রয়েছে:
- "দ্য ব্রাউন"
- "কুইক ফক্স"
এছাড়াও , সমস্ত 2-গ্রামগুলিও 1-স্কিপ-2-গ্রাম, যেহেতু একেরও কম শব্দ এড়িয়ে যেতে পারে।
স্কিপ-গ্রামগুলি কোনও শব্দের আশেপাশের প্রসঙ্গে আরও বোঝার জন্য দরকারী। উদাহরণস্বরূপ, "ফক্স" সরাসরি 1-স্কিপ-2-গ্রামগুলির সেটে "কুইক" এর সাথে সরাসরি যুক্ত ছিল, তবে 2-গ্রামের সেটে নয়।
স্কিপ-গ্রামগুলি ওয়ার্ড এম্বেডিং মডেলগুলি প্রশিক্ষণে সহায়তা করে।
নরম প্রম্পট টিউনিং
একটি নির্দিষ্ট কাজের জন্য একটি বৃহত ভাষার মডেল টিউন করার জন্য একটি কৌশল, রিসোর্স নিবিড় সূক্ষ্ম-সুরকরণ ছাড়াই। মডেলের সমস্ত ওজনকে পুনরায় প্রশিক্ষণ দেওয়ার পরিবর্তে, সফট প্রম্পট টিউনিং স্বয়ংক্রিয়ভাবে একই লক্ষ্য অর্জনের জন্য একটি প্রম্পট সামঞ্জস্য করে।
একটি পাঠ্য প্রম্পট দেওয়া, নরম প্রম্পট টিউনিং সাধারণত অতিরিক্ত টোকেন এম্বেডিংগুলিকে প্রম্পটে সংযুক্ত করে এবং ইনপুটটি অনুকূল করতে ব্যাকপ্রোপেশন ব্যবহার করে।
একটি "হার্ড" প্রম্পটে টোকেন এম্বেডিংয়ের পরিবর্তে প্রকৃত টোকেন রয়েছে।
বিরল বৈশিষ্ট্য
এমন একটি বৈশিষ্ট্য যার মানগুলি মূলত শূন্য বা খালি। উদাহরণস্বরূপ, একটি একক 1 মান এবং এক মিলিয়ন 0 মান সমন্বিত একটি বৈশিষ্ট্য বিরল। বিপরীতে, একটি ঘন বৈশিষ্ট্যের মান রয়েছে যা মূলত শূন্য বা খালি নয়।
মেশিন লার্নিংয়ে, আশ্চর্যজনক সংখ্যক বৈশিষ্ট্য হ'ল স্পারস বৈশিষ্ট্য। শ্রেণীবদ্ধ বৈশিষ্ট্যগুলি সাধারণত বিরল বৈশিষ্ট্য হয়। উদাহরণস্বরূপ, একটি বনে 300 টি সম্ভাব্য গাছের প্রজাতির মধ্যে একটি একক উদাহরণ কেবল একটি ম্যাপেল গাছ সনাক্ত করতে পারে। বা, একটি ভিডিও লাইব্রেরিতে কয়েক মিলিয়ন সম্ভাব্য ভিডিওর মধ্যে একটি একক উদাহরণ কেবল "ক্যাসাব্ল্যাঙ্কা" সনাক্ত করতে পারে।
একটি মডেলটিতে, আপনি সাধারণত এক-হট এনকোডিং সহ স্পারস বৈশিষ্ট্যগুলি উপস্থাপন করেন। যদি এক-হট এনকোডিং বড় হয় তবে আপনি আরও বেশি দক্ষতার জন্য এক-হট এনকোডিংয়ের উপরে একটি এম্বেডিং স্তর রাখতে পারেন।
বিক্ষিপ্ত প্রতিনিধিত্ব
একটি বিরল বৈশিষ্ট্যে ননজারো উপাদানগুলির কেবলমাত্র অবস্থান (গুলি) সংরক্ষণ করা।
উদাহরণস্বরূপ, ধরুন species নামের একটি শ্রেণিবদ্ধ বৈশিষ্ট্য একটি নির্দিষ্ট বনে 36 টি গাছের প্রজাতি সনাক্ত করে। আরও ধরে নিন যে প্রতিটি উদাহরণ কেবল একটি একক প্রজাতি চিহ্নিত করে।
আপনি প্রতিটি উদাহরণে গাছের প্রজাতির প্রতিনিধিত্ব করতে এক-হট ভেক্টর ব্যবহার করতে পারেন। এক-হট ভেক্টরটিতে একটি একক 1 (সেই উদাহরণে নির্দিষ্ট গাছের প্রজাতির প্রতিনিধিত্ব করতে) এবং 35 0 এস (35 টি গাছের প্রজাতির প্রতিনিধিত্ব করতে সেই উদাহরণে ) থাকবে। সুতরাং, maple এক-হট উপস্থাপনা নিম্নলিখিতগুলির মতো কিছু দেখতে পারে:

বিকল্পভাবে, বিরল প্রতিনিধিত্ব কেবল নির্দিষ্ট প্রজাতির অবস্থান সনাক্ত করতে পারে। যদি maple 24 অবস্থানে থাকে তবে maple বিরল উপস্থাপনা কেবল হবে:
24
লক্ষ্য করুন যে বিরল উপস্থাপনা এক-হট উপস্থাপনের চেয়ে অনেক বেশি কমপ্যাক্ট।
কিছুটা জটিল উদাহরণের জন্য আইকনটি ক্লিক করুন।
ধরুন আপনার মডেলের প্রতিটি উদাহরণ অবশ্যই একটি ইংরেজী বাক্যে শব্দগুলি উপস্থাপন করতে হবে - তবে এই শব্দগুলির ক্রম নয়। ইংরাজী প্রায় 170,000 শব্দ নিয়ে গঠিত, তাই ইংরেজি প্রায় 170,000 উপাদান সহ একটি শ্রেণিবদ্ধ বৈশিষ্ট্য। বেশিরভাগ ইংরেজি বাক্যগুলি সেই 170,000 শব্দের একটি অত্যন্ত ক্ষুদ্র ভগ্নাংশ ব্যবহার করে, সুতরাং একক উদাহরণে শব্দের সেটটি প্রায় অবশ্যই বিরল ডেটা হতে চলেছে।
নিম্নলিখিত বাক্য বিবেচনা করুন:
My dog is a great dog
এই বাক্যটির শব্দগুলি উপস্থাপন করতে আপনি ওয়ান-হট ভেক্টরের একটি বৈকল্পিক ব্যবহার করতে পারেন। এই বৈকল্পিকটিতে, ভেক্টরের একাধিক কোষে একটি ননজারো মান থাকতে পারে। তদ্ব্যতীত, এই বৈকল্পিকগুলিতে, একটি কোষে একটি ছাড়া অন্য একটি পূর্ণসংখ্যা থাকতে পারে। যদিও "আমার", "শব্দটি হ'ল", "এ", এবং "দুর্দান্ত" বাক্যটিতে একবারই উপস্থিত হয়, "কুকুর" শব্দটি দু'বার উপস্থিত হয়। এই বাক্যে শব্দগুলি উপস্থাপন করতে এক-হট ভেক্টরগুলির এই বৈকল্পিক ব্যবহার করে নিম্নলিখিত 170,000-উপাদান ভেক্টর ফলন করে:

একই বাক্যটির একটি বিরল উপস্থাপনা সহজভাবে হবে:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে শ্রেণিবদ্ধ ডেটা নিয়ে কাজ করা দেখুন।
মঞ্চস্থ প্রশিক্ষণ
বিচ্ছিন্ন পর্যায়ে একটি অনুক্রমে একটি মডেল প্রশিক্ষণের কৌশল। লক্ষ্যটি হয় প্রশিক্ষণ প্রক্রিয়াটি গতি বাড়ানো বা আরও ভাল মডেলের গুণমান অর্জন করা।
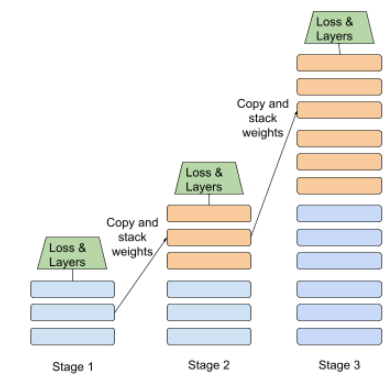
প্রগতিশীল স্ট্যাকিং পদ্ধতির একটি চিত্র নীচে দেখানো হয়েছে:
- পর্যায় 1 এ 3 টি লুকানো স্তর রয়েছে, মঞ্চ 2 এ 6 টি লুকানো স্তর রয়েছে এবং 3 ম পর্যায়টি 12 টি লুকানো স্তর রয়েছে।
- পর্যায় 2 পর্যায় 1 এর 3 টি গোপন স্তরগুলিতে শিখে নেওয়া ওজনের সাথে প্রশিক্ষণ শুরু করে। পর্যায় 3 পর্যায় 2 এর 6 টি লুকানো স্তরগুলিতে শিখে নেওয়া ওজনের সাথে প্রশিক্ষণ শুরু করে।
পাইপলাইনিংও দেখুন।
সাবওয়ার্ড টোকেন
ভাষার মডেলগুলিতে , একটি টোকেন যা একটি শব্দের একটি সাবস্ট্রিং, যা পুরো শব্দ হতে পারে।
উদাহরণস্বরূপ, "আইটেমাইজ" এর মতো একটি শব্দ "আইটেম" (একটি মূল শব্দ) এবং "আইজ" (একটি প্রত্যয়) টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো সাবওয়ার্ড নামে পরিচিত এই জাতীয় টুকরোগুলিতে অস্বাভাবিক শব্দগুলিকে বিভক্ত করা, ভাষার মডেলগুলিকে শব্দের আরও সাধারণ উপাদানগুলির অংশগুলিতে যেমন উপসর্গ এবং প্রত্যয়গুলি পরিচালনা করতে দেয়।
বিপরীতে, "যাওয়া" এর মতো সাধারণ শব্দগুলি ভেঙে যেতে পারে না এবং এটি একটি একক টোকেন দ্বারা প্রতিনিধিত্ব করা যেতে পারে।
টি
T5
2020 সালে গুগল এআই দ্বারা প্রবর্তিত একটি পাঠ্য-থেকে-পাঠ্য স্থানান্তর শেখার মডেল । টি 5 হ'ল একটি এনকোডার - ডিকোডার মডেল, ট্রান্সফর্মার আর্কিটেকচারের উপর ভিত্তি করে একটি অত্যন্ত বড় ডেটাসেটে প্রশিক্ষিত। এটি বিভিন্ন প্রাকৃতিক ভাষা প্রক্রিয়াজাতকরণ কার্যগুলিতে কার্যকর যেমন পাঠ্য উত্পন্ন করা, ভাষা অনুবাদ করা এবং কথোপকথনের পদ্ধতিতে প্রশ্নের উত্তর দেওয়া।
"পাঠ্য-থেকে-পাঠ্য ট্রান্সফার ট্রান্সফর্মার" তে পাঁচটি টি থেকে টি 5 এর নাম পেয়েছে।
T5x
একটি ওপেন সোর্স, মেশিন লার্নিং ফ্রেমওয়ার্ক বড় আকারের প্রাকৃতিক ভাষা প্রসেসিং (এনএলপি) মডেলগুলি তৈরি এবং প্রশিক্ষণের জন্য ডিজাইন করা হয়েছে। টি 5 টি 5 এক্স কোডবেসে প্রয়োগ করা হয়েছে (যা জ্যাক্স এবং ফ্ল্যাক্সে নির্মিত)।
তাপমাত্রা
একটি হাইপারপ্যারামিটার যা কোনও মডেলের আউটপুটটির এলোমেলো ডিগ্রি নিয়ন্ত্রণ করে। উচ্চতর তাপমাত্রার ফলে আরও এলোমেলো আউটপুট হয়, যখন কম তাপমাত্রার ফলে কম এলোমেলো আউটপুট হয়।
সর্বোত্তম তাপমাত্রা নির্বাচন করা নির্দিষ্ট অ্যাপ্লিকেশন এবং মডেলের আউটপুটটির পছন্দসই বৈশিষ্ট্যের উপর নির্ভর করে। উদাহরণস্বরূপ, সৃজনশীল আউটপুট উত্পন্ন করে এমন একটি অ্যাপ্লিকেশন তৈরি করার সময় আপনি সম্ভবত তাপমাত্রা বাড়িয়ে তুলবেন। বিপরীতে, মডেলটির যথার্থতা এবং ধারাবাহিকতা উন্নত করার জন্য চিত্র বা পাঠ্যকে শ্রেণিবদ্ধ করে এমন কোনও মডেল তৈরি করার সময় আপনি সম্ভবত তাপমাত্রা কমিয়ে দেবেন।
তাপমাত্রা প্রায়শই সফটম্যাক্সের সাথে ব্যবহৃত হয়।
পাঠ্য স্প্যান
একটি পাঠ্য স্ট্রিংয়ের একটি নির্দিষ্ট উপধারার সাথে যুক্ত অ্যারে সূচক স্প্যান। উদাহরণস্বরূপ, পাইথন স্ট্রিং s="Be good now" good 3 থেকে 6 পর্যন্ত পাঠ্য স্প্যানটি দখল করে।
টোকেন
একটি ভাষার মডেলটিতে , মডেলটি প্রশিক্ষণ নিচ্ছে এবং ভবিষ্যদ্বাণী করছে এমন পারমাণবিক ইউনিট। একটি টোকেন সাধারণত নিম্নলিখিতগুলির মধ্যে একটি:
- একটি শব্দ - উদাহরণস্বরূপ, "কুকুরের মতো কুকুর" শব্দটি তিনটি শব্দের টোকেন নিয়ে গঠিত: "কুকুর", "লাইক" এবং "বিড়াল"।
- একটি চরিত্র - উদাহরণস্বরূপ, "বাইক ফিশ" শব্দটি নয়টি চরিত্রের টোকেন নিয়ে গঠিত। (নোট করুন যে ফাঁকা স্থানটি টোকেনগুলির মধ্যে একটি হিসাবে গণনা করে))
- সাবওয়ার্ডস - যার মধ্যে একটি শব্দ একক টোকেন বা একাধিক টোকেন হতে পারে। একটি সাবওয়ার্ড একটি মূল শব্দ, একটি উপসর্গ বা একটি প্রত্যয় নিয়ে গঠিত। উদাহরণস্বরূপ, একটি ভাষার মডেল যা টোকেন হিসাবে সাবওয়ার্ড ব্যবহার করে "কুকুর" শব্দটিকে দুটি টোকেন হিসাবে দেখতে পারে (মূল শব্দ "কুকুর" এবং বহুবচন প্রত্যয় "গুলি")। একই ভাষার মডেলটি একক শব্দটিকে "লম্বা" দুটি সাবওয়ার্ড হিসাবে দেখতে পারে (মূল শব্দ "লম্বা" এবং প্রত্যয় "এর")।
ভাষার মডেলের বাইরের ডোমেনগুলিতে, টোকেনগুলি অন্যান্য ধরণের পারমাণবিক ইউনিটকে উপস্থাপন করতে পারে। উদাহরণস্বরূপ, কম্পিউটার ভিশনে, একটি টোকেন কোনও চিত্রের একটি উপসেট হতে পারে।
আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে বড় ভাষার মডেলগুলি দেখুন।
শীর্ষ-কে নির্ভুলতা
উত্পন্ন তালিকার প্রথম কে পজিশনের মধ্যে একটি "টার্গেট লেবেল" প্রদর্শিত হওয়ার পরিমাণ। তালিকাগুলি ব্যক্তিগতকৃত সুপারিশ বা সফটম্যাক্স দ্বারা অর্ডার করা আইটেমগুলির একটি তালিকা হতে পারে।
শীর্ষ-কে যথার্থতা কে এ নির্ভুলতা হিসাবেও পরিচিত।
বিষাক্ততা
যে ডিগ্রীতে সামগ্রীটি আপত্তিজনক, হুমকিস্বরূপ বা আপত্তিকর। অনেক মেশিন লার্নিং মডেল বিষাক্ততা সনাক্ত এবং পরিমাপ করতে পারে। এই মডেলগুলির বেশিরভাগই একাধিক পরামিতিগুলির সাথে বিষাক্ততা চিহ্নিত করে যেমন আপত্তিজনক ভাষার স্তর এবং হুমকী ভাষার স্তর।
ট্রান্সফরমার
গুগলে বিকশিত একটি নিউরাল নেটওয়ার্ক আর্কিটেকচার যা ইনপুট এম্বেডিংগুলির ক্রমকে কনভোলিউশন বা পুনরাবৃত্ত নিউরাল নেটওয়ার্কগুলির উপর নির্ভর না করে আউটপুট এম্বেডিংগুলির ক্রম হিসাবে রূপান্তর করতে স্ব-অনুমোদন প্রক্রিয়াগুলির উপর নির্ভর করে। একটি ট্রান্সফর্মার স্ব-মনোযোগ স্তরগুলির স্ট্যাক হিসাবে দেখা যেতে পারে।
একটি ট্রান্সফর্মার নিম্নলিখিত যে কোনও একটি অন্তর্ভুক্ত করতে পারে:
একটি এনকোডার এম্বেডিংগুলির একটি ক্রমকে একই দৈর্ঘ্যের একটি নতুন অনুক্রমে রূপান্তর করে। একটি এনকোডারটিতে এন অভিন্ন স্তরগুলি অন্তর্ভুক্ত রয়েছে, যার প্রত্যেকটিতে দুটি উপ-স্তর রয়েছে। এই দুটি সাব-স্তরগুলি ইনপুট এম্বেডিং সিকোয়েন্সের প্রতিটি অবস্থানে প্রয়োগ করা হয়, ক্রমের প্রতিটি উপাদানকে একটি নতুন এম্বেডিংয়ে রূপান্তরিত করে। প্রথম এনকোডার সাব-লেয়ার ইনপুট ক্রম জুড়ে তথ্যকে একত্রিত করে। দ্বিতীয় এনকোডার সাব-স্তর একত্রিত তথ্যকে একটি আউটপুট এম্বেডিংয়ে রূপান্তর করে।
একটি ডিকোডার ইনপুট এম্বেডিংগুলির একটি ক্রমকে আউটপুট এম্বেডিংগুলির ক্রম হিসাবে রূপান্তর করে, সম্ভবত একটি আলাদা দৈর্ঘ্যের সাথে। একটি ডিকোডারটিতে তিনটি উপ-স্তরযুক্ত এন অভিন্ন স্তরগুলিও অন্তর্ভুক্ত রয়েছে, যার মধ্যে দুটি এনকোডার সাব-স্তরগুলির সাথে সমান। তৃতীয় ডিকোডার সাব-লেয়ার এনকোডারের আউটপুট নেয় এবং এটি থেকে তথ্য সংগ্রহের জন্য স্ব-মনোযোগ প্রক্রিয়া প্রয়োগ করে।
ব্লগ পোস্ট ট্রান্সফর্মার: ভাষা বোঝার জন্য একটি উপন্যাস নিউরাল নেটওয়ার্ক আর্কিটেকচার ট্রান্সফর্মারগুলির একটি ভাল ভূমিকা সরবরাহ করে।
এলএলএমএস দেখুন: একটি বৃহত ভাষার মডেল কী? আরও তথ্যের জন্য মেশিন লার্নিং ক্র্যাশ কোর্সে।
trigram
একটি এন-গ্রাম যা এন = 3।
উ
একমুখী
এমন একটি সিস্টেম যা কেবল পাঠ্যের লক্ষ্য বিভাগের পূর্ববর্তী পাঠ্যকে মূল্যায়ন করে। In contrast, a bidirectional system evaluates both the text that precedes and follows a target section of text. See bidirectional for more details.
unidirectional language model
A language model that bases its probabilities only on the tokens appearing before , not after , the target token(s). Contrast with bidirectional language model .
ভি
variational autoencoder (VAE)
A type of autoencoder that leverages the discrepancy between inputs and outputs to generate modified versions of the inputs. Variational autoencoders are useful for generative AI .
VAEs are based on variational inference: a technique for estimating the parameters of a probability model.
ডব্লিউ
word embedding
Representing each word in a word set within an embedding vector ; that is, representing each word as a vector of floating-point values between 0.0 and 1.0. Words with similar meanings have more-similar representations than words with different meanings. For example, carrots , celery , and cucumbers would all have relatively similar representations, which would be very different from the representations of airplane , sunglasses , and toothpaste .
জেড
zero-shot prompting
A prompt that does not provide an example of how you want the large language model to respond. যেমন:
| Parts of one prompt | নোট |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| ভারত: | The actual query. |
The large language model might respond with any of the following:
- রুপি
- INR
- ₹
- ভারতীয় রুপি
- The rupee
- ভারতীয় রুপি
All of the answers are correct, though you might prefer a particular format.
Compare and contrast zero-shot prompting with the following terms: