หน้านี้มีคำศัพท์ในอภิธานศัพท์ของการประเมินภาษา ดูคำศัพท์ทั้งหมดในอภิธานศัพท์ได้โดยการคลิกที่นี่
A
โปรดทราบ
กลไกที่ใช้ในเครือข่ายประสาทเทียมซึ่งระบุความสำคัญของคําหนึ่งๆ หรือส่วนหนึ่งของคํา การใส่ใจจะบีบอัดปริมาณข้อมูลที่จำเป็นต่อโมเดลในการคาดการณ์โทเค็น/คำถัดไป กลไกการให้ความสำคัญทั่วไปอาจประกอบด้วยผลรวมถ่วงน้ำหนักของชุดอินพุต โดยที่น้ำหนักของอินพุตแต่ละรายการจะคํานวณโดยส่วนอื่นของเครือข่ายประสาท
โปรดดูการใส่ใจตนเองและการใส่ใจตนเองแบบหลายส่วน ซึ่งเป็นองค์ประกอบพื้นฐานของ Transformer
ดูข้อมูลเพิ่มเติมเกี่ยวกับการให้ความสนใจตนเองได้ที่หัวข้อ LLM: โมเดลภาษาขนาดใหญ่คืออะไรในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
ตัวเข้ารหัสอัตโนมัติ
ระบบที่เรียนรู้วิธีดึงข้อมูลที่สำคัญที่สุดจากอินพุต โปรแกรมเปลี่ยนไฟล์อัตโนมัติเป็นชุดค่าผสมของโปรแกรมเปลี่ยนไฟล์และโปรแกรมถอดรหัส โปรแกรมเข้ารหัสอัตโนมัติใช้กระบวนการ 2 ขั้นตอนต่อไปนี้
- ตัวเข้ารหัสจะแมปอินพุตเป็นรูปแบบ (โดยปกติ) ที่มีการสูญเสียและมิติข้อมูลต่ำลง (ระดับกลาง)
- ตัวถอดรหัสจะสร้างอินพุตต้นฉบับเวอร์ชันที่สูญเสียคุณภาพโดยการแมปรูปแบบมิติข้อมูลต่ำกับรูปแบบอินพุตมิติข้อมูลสูงเดิม
ระบบจะฝึก Autoencoder ตั้งแต่ต้นจนจบโดยให้ตัวถอดรหัสพยายามสร้างอินพุตเดิมขึ้นมาใหม่จากรูปแบบกลางของตัวเข้ารหัสให้ใกล้เคียงกับต้นฉบับมากที่สุด เนื่องจากรูปแบบกลางมีขนาดเล็กกว่า (มิติข้อมูลต่ำกว่า) รูปแบบเดิม ระบบจึงบังคับให้ตัวเข้ารหัสอัตโนมัติต้องเรียนรู้ว่าข้อมูลใดในอินพุตมีความสําคัญ และเอาต์พุตจะไม่เหมือนกับอินพุตอย่างสมบูรณ์
เช่น
- หากข้อมูลอินพุตเป็นกราฟิก สำเนาที่ไม่ใช่สำเนาที่ตรงกันทั้งหมดจะคล้ายกับกราฟิกต้นฉบับ แต่มีการแก้ไขเล็กน้อย อาจเป็นเพราะสำเนาที่ไม่ใช่สำเนาที่ตรงกันทั้งหมดได้นำสัญญาณรบกวนออกจากกราฟิกต้นฉบับหรือเติมพิกเซลที่ขาดหายไป
- หากข้อมูลอินพุตเป็นข้อความ ตัวแปลงรหัสอัตโนมัติจะสร้างข้อความใหม่ที่เลียนแบบ (แต่ไม่เหมือนกับ) ข้อความต้นฉบับ
ดูข้อมูลเพิ่มเติมได้ที่ตัวแปร Autoencoder
การประเมินอัตโนมัติ
ใช้ซอฟต์แวร์เพื่อตัดสินคุณภาพของเอาต์พุตของโมเดล
เมื่อเอาต์พุตของโมเดลค่อนข้างตรงไปตรงมา สคริปต์หรือโปรแกรมจะเปรียบเทียบเอาต์พุตของโมเดลกับคำตอบมาตรฐานได้ บางครั้งเราเรียกการประเมินอัตโนมัติประเภทนี้ว่าการประเมินแบบเป็นโปรแกรม เมตริกต่างๆ เช่น ROUGE หรือBLEU มักมีประโยชน์สําหรับการประเมินแบบเป็นโปรแกรม
เมื่อเอาต์พุตของโมเดลมีความซับซ้อนหรือมีคำตอบที่ถูกต้องเพียงคำตอบเดียว บางครั้งโปรแกรม ML แยกต่างหากที่เรียกว่าโปรแกรมประเมินอัตโนมัติจะดำเนินการประเมินโดยอัตโนมัติ
ตรงข้ามกับการประเมินโดยเจ้าหน้าที่
การประเมินโดยโปรแกรมอัตโนมัติ
กลไกแบบผสมผสานสำหรับตัดสินคุณภาพของเอาต์พุตจากโมเดลGenerative AI ซึ่งรวมการประเมินโดยเจ้าหน้าที่เข้ากับการประเมินอัตโนมัติ โปรแกรมให้คะแนนอัตโนมัติคือโมเดล ML ที่ฝึกด้วยข้อมูลที่สร้างขึ้นจากการประเมินโดยมนุษย์ ในทางทฤษฎีแล้ว โปรแกรมประเมินอัตโนมัติจะเรียนรู้ที่จะเลียนแบบผู้ประเมินที่เป็นมนุษย์เครื่องมือประเมินอัตโนมัติที่สร้างไว้ล่วงหน้ามีให้ใช้งาน แต่เครื่องมือประเมินอัตโนมัติที่ดีที่สุดคือเครื่องมือที่ปรับแต่งมาเพื่องานที่คุณประเมินโดยเฉพาะ
โมเดลการถดถอยอัตโนมัติ
โมเดลที่อนุมานการคาดการณ์ตามการคาดการณ์ก่อนหน้าของตนเอง ตัวอย่างเช่น โมเดลภาษาแบบย้อนกลับอัตโนมัติจะคาดการณ์โทเค็นถัดไปโดยอิงตามโทเค็นที่คาดการณ์ไว้ก่อนหน้านี้ โมเดลภาษาขนาดใหญ่ทั้งหมดที่อิงตาม Transformer จะเป็นแบบย้อนกลับอัตโนมัติ
ในทางตรงกันข้าม โมเดลรูปภาพที่อิงตาม GAN มักจะไม่แสดงการถดถอยอัตโนมัติ เนื่องจากสร้างรูปภาพในขั้นตอนเดียวแบบไปข้างหน้า ไม่ใช่แบบซ้ำๆ ในขั้นตอน อย่างไรก็ตาม โมเดลการสร้างรูปภาพบางรุ่นเป็นแบบถดถอยอัตโนมัติเนื่องจากสร้างรูปภาพเป็นขั้นตอน
ความแม่นยำเฉลี่ยที่ k
เมตริกสำหรับสรุปประสิทธิภาพของโมเดลในพรอมต์เดียวซึ่งจะสร้างผลลัพธ์ที่จัดอันดับ เช่น รายการคำแนะนำหนังสือที่มีหมายเลข ความแม่นยำเฉลี่ยที่ k คือค่าเฉลี่ยของค่าความแม่นยำที่ k สำหรับผลการค้นหาที่เกี่ยวข้องแต่ละรายการ ดังนั้น สูตรความแม่นยำเฉลี่ยที่ k จึงจะเป็นดังนี้
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
where:
- \(n\) คือจํานวนรายการที่เกี่ยวข้องในรายการ
เปรียบเทียบกับ recall at k
B
ถุงคำ
การนําเสนอคําในวลีหรือข้อความ โดยไม่ได้คำนึงถึงลําดับ เช่น ถุงคำจะแสดงวลี 3 วลีต่อไปนี้ในลักษณะเดียวกัน
- สุนัขกระโดด
- กระโดดใส่สุนัข
- สุนัขกระโดด
ระบบจะจับคู่แต่ละคำกับดัชนีในเวกเตอร์แบบเบาบาง โดยเวกเตอร์จะมีดัชนีสําหรับคําทุกคำในคําศัพท์ ตัวอย่างเช่น วลี the dog jumps จะแมปกับเวกเตอร์ลักษณะที่มีค่าที่ไม่ใช่ 0 ที่ดัชนี 3 รายการซึ่งสอดคล้องกับคําว่า the, dog และ jumps ค่าที่ไม่ใช่ 0 อาจเป็นค่าใดค่าหนึ่งต่อไปนี้
- 1 เพื่อระบุการมีอยู่ของคำ
- จำนวนครั้งที่คำหนึ่งๆ ปรากฏในถุง เช่น หากวลีคือ สุนัขสีน้ำตาลแดงเป็นสุนัขที่มีขนสีน้ำตาลแดง ทั้ง สีน้ำตาลแดงและสุนัขจะแสดงเป็น 2 ส่วนคําอื่นๆ จะแสดงเป็น 1
- ค่าอื่นๆ เช่น ลอการิทึมของจํานวนครั้งที่คําปรากฏในถุง
BERT (Bidirectional Encoder Representations from Transformers)
สถาปัตยกรรมโมเดลสําหรับการนําเสนอข้อความ โมเดล BERT ที่ผ่านการฝึกสามารถทํางานเป็นส่วนหนึ่งของโมเดลขนาดใหญ่สําหรับการจัดประเภทข้อความหรืองาน ML อื่นๆ
BERT มีลักษณะต่อไปนี้
- ใช้สถาปัตยกรรม Transformer จึงอาศัยการใส่ใจตนเอง
- ใช้ส่วน encoder ของ Transformer งานของโปรแกรมเข้ารหัสคือการสร้างการนําเสนอข้อความที่ดี ไม่ใช่เพื่อทํางานเฉพาะเจาะจง เช่น การแยกประเภท
- เป็นแบบ 2 ทิศทาง
- ใช้การมาสก์สําหรับการฝึกที่ไม่มีการควบคุมดูแล
รูปแบบของ BERT มีดังนี้
ดูภาพรวมของ BERT ได้ที่การเผยแพร่ BERT แบบโอเพนซอร์ส: การฝึกล่วงหน้าที่ล้ำสมัยสำหรับการประมวลผลภาษาธรรมชาติ
แบบ 2 ทิศทาง
คําที่ใช้อธิบายระบบที่ประเมินข้อความทั้งในส่วนที่อยู่ก่อนและอยู่หลังส่วนข้อความเป้าหมาย ในทางตรงกันข้าม ระบบแบบทิศทางเดียวจะประเมินเฉพาะข้อความที่อยู่ก่อนส่วนข้อความเป้าหมาย
ตัวอย่างเช่น ลองพิจารณาโมเดลภาษาที่มีการปกปิดซึ่งต้องระบุความน่าจะเป็นของคำที่แสดงขีดล่างในคำถามต่อไปนี้
_____ กับคุณเป็นอย่างไรบ้าง
โมเดลภาษาแบบทิศทางเดียวจะต้องอิงความน่าจะเป็นตามบริบทที่ได้จากคําว่า "อะไร" "คือ" และ "ที่" เท่านั้น ในทางตรงกันข้าม โมเดลภาษาแบบ 2 ทิศทางอาจได้รับบริบทจาก "กับ" และ "คุณ" ด้วย ซึ่งอาจช่วยให้โมเดลคาดการณ์ได้ดีขึ้น
โมเดลภาษาแบบ 2 ทาง
โมเดลภาษาที่กําหนดความน่าจะเป็นที่โทเค็นหนึ่งๆ จะปรากฏในตําแหน่งหนึ่งๆ ของข้อความที่ตัดตอนมาโดยอิงตามข้อความก่อนหน้าและถัดจาก
Bigram
N-gram โดยที่ N=2
BLEU (Bilingual Evaluation Understudy)
เมตริกระหว่าง 0.0 ถึง 1.0 สําหรับประเมินการแปลด้วยคอมพิวเตอร์ เช่น จากภาษาสเปนเป็นภาษาญี่ปุ่น
โดยปกติแล้ว BLEU จะคำนวณคะแนนโดยการเปรียบเทียบคำแปลของโมเดล ML (ข้อความที่สร้างขึ้น) กับคำแปลของผู้เชี่ยวชาญที่เป็นมนุษย์ (ข้อความอ้างอิง) ระดับที่ N-grams ในข้อความที่สร้างขึ้นและข้อความอ้างอิงตรงกันเป็นตัวกำหนดคะแนน BLEU
เอกสารต้นฉบับเกี่ยวกับเมตริกนี้คือ BLEU: a Method for Automatic Evaluation of Machine Translation
โปรดดูBLEURT ด้วย
BLEURT (Bilingual Evaluation Understudy from Transformers)
เมตริกสำหรับประเมินการแปลด้วยคอมพิวเตอร์จากภาษาหนึ่งเป็นภาษาอื่น โดยเฉพาะจากและไปยังภาษาอังกฤษ
สำหรับคำแปลจากและไปยังภาษาอังกฤษ BLEURT จะสอดคล้องกับคะแนนของมนุษย์มากกว่า BLEU BLEURT เน้นความคล้ายคลึงทางความหมาย (ความหมาย) และรองรับการถอดความ ซึ่งแตกต่างจาก BLEU
BLEURT ใช้โมเดลภาษาขนาดใหญ่ที่ผ่านการฝึกล่วงหน้า (หรือก็คือ BERT) ซึ่งได้รับการปรับแต่งอย่างละเอียดจากข้อความที่นักแปลมนุษย์แปล
เอกสารต้นฉบับเกี่ยวกับเมตริกนี้คือ BLEURT: Learning Robust Metrics for Text Generation
C
โมเดลภาษาเชิงสาเหตุ
คำพ้องความหมายของโมเดลภาษาแบบทิศทางเดียว
ดูโมเดลภาษาแบบ 2 ทิศทางเพื่อเปรียบเทียบแนวทางแบบต่างๆ ในการประมาณภาษา
การช่วยสร้างคำพูดตามลำดับความคิด
เทคนิคการสร้างพรอมต์ที่กระตุ้นโมเดลภาษาขนาดใหญ่ (LLM) ให้อธิบายเหตุผลทีละขั้นตอน ตัวอย่างเช่น ลองดูพรอมต์ต่อไปนี้ โดยให้ความสนใจเป็นพิเศษกับประโยคที่ 2
ผู้ขับขี่จะรู้สึกถึงแรง g เท่าใดในรถที่เร่งจาก 0 เป็น 60 ไมล์ต่อชั่วโมงใน 7 วินาที แสดงการคํานวณที่เกี่ยวข้องทั้งหมดในคําตอบ
คำตอบของ LLM มีแนวโน้มที่จะมีลักษณะดังนี้
- แสดงลำดับสูตรฟิสิกส์ โดยใส่ค่า 0, 60 และ 7 ในตำแหน่งที่เหมาะสม
- อธิบายเหตุผลที่เลือกสูตรเหล่านั้น และความหมายของตัวแปรต่างๆ
การแจ้งเตือนแบบเชื่อมโยงความคิดจะบังคับให้ LLM ทำการคํานวณทั้งหมด ซึ่งอาจทําให้ได้คําตอบที่ถูกต้องมากขึ้น นอกจากนี้ ข้อความแจ้งแบบเป็นลำดับความคิดยังช่วยให้ผู้ใช้ตรวจสอบขั้นตอนของ LLM เพื่อดูว่าคำตอบนั้นสมเหตุสมผลหรือไม่
แชท
เนื้อหาของบทสนทนาแบบโต้ตอบกับระบบ ML ซึ่งโดยทั่วไปแล้วจะเป็นโมเดลภาษาขนาดใหญ่ การโต้ตอบก่อนหน้านี้ในแชท (สิ่งที่คุณพิมพ์และวิธีที่โมเดลภาษาขนาดใหญ่ตอบกลับ) จะกลายเป็นบริบทสําหรับส่วนถัดไปของแชท
แชทบ็อตคือแอปพลิเคชันของโมเดลภาษาขนาดใหญ่
การสมมติ
คำพ้องความหมายของอาการหลอน
การสมมติอาจใช้แทนคำว่าภาพหลอนได้อย่างถูกต้องกว่าในแง่เทคนิค แต่ภาพหลอนได้รับความนิยมก่อน
การแยกวิเคราะห์เขตเลือกตั้ง
การแบ่งประโยคออกเป็นโครงสร้างทางไวยากรณ์ที่เล็กลง ("องค์ประกอบ") ส่วนต่อมาของระบบ ML เช่น โมเดลความเข้าใจภาษาธรรมชาติ จะแยกวิเคราะห์องค์ประกอบต่างๆ ได้ง่ายกว่าประโยคต้นฉบับ ตัวอย่างเช่น ลองพิจารณาประโยคต่อไปนี้
เพื่อนของฉันรับแมวมาเลี้ยง 2 ตัว
โปรแกรมแยกองค์ประกอบสามารถแบ่งประโยคนี้ออกเป็นองค์ประกอบ 2 รายการต่อไปนี้
- เพื่อนของฉันคือวลีนาม
- รับเลี้ยงแมว 2 ตัวเป็นวลีที่มีคํากริยา
องค์ประกอบเหล่านี้สามารถแบ่งย่อยออกเป็นองค์ประกอบขนาดเล็กๆ เพิ่มเติมได้ เช่น วลีที่มีคํากริยา
อุปการะแมว 2 ตัว
อาจแบ่งย่อยออกเป็น
- adopted เป็นกริยา
- two cats เป็นวลีนามอีกวลีหนึ่ง
การฝังภาษาตามบริบท
การฝังที่ใกล้เคียงกับ "การทำความเข้าใจ" คำและวลีในลักษณะที่มนุษย์พูดได้อย่างคล่องแคล่ว ภาษาตามบริบทที่ฝังไว้จะเข้าใจไวยากรณ์ ความหมาย และบริบทที่ซับซ้อน
เช่น ลองพิจารณาการฝังคําภาษาอังกฤษว่า cow รูปแบบการฝังข้อมูลรุ่นเก่า เช่น word2vec สามารถแสดงคำภาษาอังกฤษได้ เช่น ระยะทางในพื้นที่การฝังข้อมูลจากวัวถึงวัวกระทิงจะคล้ายกับระยะทางจากแม่แพะ (แพะตัวเมีย) ถึงแพะตัวผู้ หรือจากหญิงถึงชาย การป้อนข้อมูลภาษาตามบริบทสามารถดำเนินการต่อได้โดยตระหนักว่าบางครั้งผู้พูดภาษาอังกฤษใช้คำว่า cow ในความหมายว่าวัวหรือวัวตัวผู้ก็ได้
หน้าต่างบริบท
จำนวนโทเค็นที่โมเดลประมวลผลได้ในพรอมต์หนึ่งๆ ยิ่งหน้าต่างบริบทมีขนาดใหญ่เท่าใด โมเดลก็ยิ่งมีข้อมูลมากขึ้นที่จะใช้ตอบกลับพรอมต์ได้อย่างสอดคล้องกัน
ดอกซากุระ
ประโยคหรือวลีที่มีความหมายคลุมเครือ ข้อความที่แสดงผลไม่ถูกต้องเป็นปัญหาที่สำคัญในความเข้าใจภาษาธรรมชาติ ตัวอย่างเช่น บรรทัดแรก Red Tape Holds Up Skyscraper เป็นตัวอย่างของ Crash Blossom เนื่องจากโมเดล NLU อาจตีความบรรทัดแรกตามตัวอักษรหรือตามความหมาย
D
เครื่องมือถอดรหัส
โดยทั่วไปแล้ว ระบบ ML ที่แปลงจากการแสดงผลที่ประมวลผลแล้ว หนาแน่น หรือภายในเป็นการแสดงผลที่ดิบ เบาบาง หรือภายนอกมากขึ้น
ตัวถอดรหัสมักเป็นคอมโพเนนต์ของโมเดลขนาดใหญ่ ซึ่งมักจะจับคู่กับโปรแกรมและอุปกรณ์เปลี่ยนไฟล์
ในงานแบบอนุกรมต่ออนุกรม ตัวถอดรหัสจะเริ่มต้นด้วยสถานะภายในที่เอนโค้ดเดอร์สร้างขึ้นเพื่อคาดการณ์ลำดับถัดไป
ดูคำจำกัดความของตัวถอดรหัสภายในสถาปัตยกรรม Transformer ได้ที่ Transformer
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาขนาดใหญ่ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
การกรองสัญญาณรบกวน
แนวทางทั่วไปของการเรียนรู้แบบควบคุมตนเอง ซึ่งมีลักษณะดังนี้
- มีการจงใจเพิ่มสัญญาณรบกวนลงในชุดข้อมูล
- โมเดลจะพยายามนำเสียงรบกวนออก
การกรองสัญญาณรบกวนช่วยให้สามารถเรียนรู้จากตัวอย่างที่ไม่มีป้ายกำกับ ชุดข้อมูลเดิมทำหน้าที่เป็นเป้าหมายหรือป้ายกำกับ และข้อมูลที่มีสัญญาณรบกวนเป็นอินพุต
โมเดลภาษาที่มีการปกปิดบางรุ่นใช้การกรองสัญญาณรบกวน ดังนี้
- ระบบจะเพิ่มสัญญาณรบกวนลงในประโยคที่ไม่มีป้ายกำกับโดยการปกปิดโทเค็นบางส่วน
- โมเดลจะพยายามคาดคะเนโทเค็นต้นฉบับ
การแจ้งเตือนโดยตรง
คำพ้องความหมายของพรอมต์แบบไม่ใช้ตัวอย่าง
E
แก้ไขระยะทาง
การวัดความคล้ายคลึงของสตริงข้อความ 2 รายการ ระยะการแก้ไขมีประโยชน์ในแมชชีนเลิร์นนิงเนื่องจากเหตุผลต่อไปนี้
- ระยะห่างการแก้ไขคํานวณได้ง่าย
- ระยะห่างการแก้ไขจะเปรียบเทียบสตริง 2 รายการที่ทราบว่าคล้ายกัน
- ระยะห่างการแก้ไขสามารถระบุระดับที่สตริงต่างๆ คล้ายกับสตริงหนึ่งๆ
ระยะห่างการแก้ไขมีหลายคำจำกัดความ โดยแต่ละคำจำกัดความจะใช้การดำเนินการสตริงที่แตกต่างกัน ดูตัวอย่างได้ที่ระยะ Levenshtein
เลเยอร์การฝัง
เลเยอร์ที่ซ่อนอยู่แบบพิเศษที่ฝึกด้วยฟีเจอร์เชิงหมวดหมู่มิติสูงเพื่อค่อยๆ เรียนรู้เวกเตอร์การฝังมิติข้อมูลต่ำ เลเยอร์การฝังช่วยให้เครือข่ายประสาทสามารถฝึกได้อย่างมีประสิทธิภาพมากกว่าการฝึกเฉพาะกับฟีเจอร์เชิงหมวดหมู่มิติสูง
ตัวอย่างเช่น ปัจจุบัน Earth รองรับพันธุ์ไม้ประมาณ 73,000 ชนิด สมมติว่าพันธุ์ไม้เป็นฟีเจอร์ในโมเดลของคุณ เลเยอร์อินพุตของโมเดลจึงมีเวกเตอร์แบบฮอตเวิร์กที่มีองค์ประกอบยาว 73,000 รายการ
เช่น baobab อาจแสดงเป็นดังนี้

อาร์เรย์ที่มีองค์ประกอบ 73,000 รายการนั้นยาวมาก หากไม่เพิ่มเลเยอร์การฝังลงในโมเดล การฝึกจะใช้เวลานานมากเนื่องจากการคูณ 0 72,999 ครั้ง สมมติว่าคุณเลือกเลเยอร์การฝังให้มีมิติข้อมูล 12 รายการ เลเยอร์การฝังจึงค่อยๆ เรียนรู้เวกเตอร์การฝังใหม่สําหรับต้นไม้แต่ละสายพันธุ์
ในบางสถานการณ์ การแฮชเป็นทางเลือกที่สมเหตุสมผลสำหรับเลเยอร์การฝัง
ดูข้อมูลเพิ่มเติมเกี่ยวกับการฝังในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
พื้นที่ฝัง
ปริภูมิเวกเตอร์ 3 มิติที่แมปกับองค์ประกอบจากปริภูมิเวกเตอร์มิติที่สูงกว่า พื้นที่โฆษณาแบบฝังได้รับการฝึกให้จับโครงสร้างที่มีความหมายสําหรับแอปพลิเคชันที่ต้องการ
ผลคูณจุดของข้อมูลเชิงลึก 2 รายการคือตัววัดความคล้ายคลึงกัน
เวกเตอร์การฝัง
กล่าวโดยคร่าวๆ ก็คืออาร์เรย์ของตัวเลขทศนิยมที่มาจากเลเยอร์ใดก็ได้ ที่ซ่อนอยู่ซึ่งอธิบายอินพุตของเลเยอร์ที่ซ่อนอยู่นั้น โดยปกติแล้ว เวกเตอร์การฝังจะเป็นอาร์เรย์ของตัวเลขทศนิยมที่ผ่านการฝึกในเลเยอร์การฝัง ตัวอย่างเช่น สมมติว่าเลเยอร์การฝังต้องเรียนรู้เวกเตอร์การฝังสําหรับต้นไม้แต่ละสายพันธุ์บนโลกซึ่งมีอยู่ 73,000 สายพันธุ์ อาร์เรย์ต่อไปนี้อาจเป็นเวกเตอร์การฝังสำหรับต้นบาวบับ

เวกเตอร์การฝังไม่ใช่ตัวเลขสุ่ม เลเยอร์การฝังจะกําหนดค่าเหล่านี้ผ่านการฝึก คล้ายกับวิธีที่เครือข่ายประสาทเรียนรู้น้ำหนักอื่นๆ ระหว่างการฝึก องค์ประกอบแต่ละรายการของอาร์เรย์คือคะแนนตามลักษณะบางอย่างของสายพันธุ์ต้นไม้ องค์ประกอบใดแสดงถึงลักษณะของสายพันธุ์ต้นไม้ ซึ่งเป็นสิ่งที่มนุษย์ตัดสินได้ยากมาก
สิ่งที่น่าสนใจทางคณิตศาสตร์ของเวกเตอร์การฝังคือรายการที่คล้ายกันจะมีชุดตัวเลขทศนิยมที่คล้ายกัน เช่น สายพันธุ์ต้นไม้ที่คล้ายกันจะมีชุดตัวเลขทศนิยมที่คล้ายกันมากกว่าสายพันธุ์ต้นไม้ที่ไม่คล้ายกัน ต้นสนซีดาร์และต้นสนสควอยเอียเป็นต้นไม้สายพันธุ์ที่เกี่ยวข้องกัน ดังนั้นชุดตัวเลขทศนิยมของต้นสนซีดาร์และต้นสนสควอยเอียจึงมีความคล้ายคลึงกันมากกว่าต้นสนซีดาร์และต้นมะพร้าว ตัวเลขในเวกเตอร์การฝังจะเปลี่ยนแปลงทุกครั้งที่คุณฝึกโมเดลใหม่ แม้ว่าคุณจะฝึกโมเดลใหม่ด้วยอินพุตที่เหมือนกันก็ตาม
โปรแกรมเปลี่ยนไฟล์
โดยทั่วไปแล้ว ระบบ ML ใดก็ตามที่แปลงจากการแสดงผลแบบดิบ เบาบาง หรือภายนอกเป็นการแสดงผลที่ประมวลผลแล้ว หนาแน่นขึ้น หรือภายในมากขึ้น
โดยปกติแล้ว โปรแกรมเข้ารหัสจะเป็นส่วนหนึ่งของโมเดลขนาดใหญ่ ซึ่งมักจะจับคู่กับโปรแกรมถอดรหัส Transformer บางตัวจะจับคู่โปรแกรมเปลี่ยนไฟล์กับโปรแกรมถอดรหัส แต่ Transformer อื่นๆ ใช้เฉพาะโปรแกรมเปลี่ยนไฟล์หรือเฉพาะโปรแกรมถอดรหัส
ระบบบางระบบใช้เอาต์พุตของโปรแกรมเข้ารหัสเป็นอินพุตของเครือข่ายการจัดประเภทหรือการถดถอย
ในงานแบบอนุกรมต่ออนุกรม ตัวเข้ารหัสจะรับลำดับอินพุตและแสดงผลสถานะภายใน (เวกเตอร์) จากนั้น ตัวถอดรหัสจะใช้สถานะภายในนั้นเพื่อคาดการณ์ลำดับถัดไป
ดูคำจำกัดความของตัวเข้ารหัสในสถาปัตยกรรม Transformer ได้ที่ Transformer
ดูข้อมูลเพิ่มเติมได้ที่LLM: โมเดลภาษาขนาดใหญ่ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
evals
ใช้เป็นหลักเป็นตัวย่อของการประเมิน LLM evals ย่อมาจากการประเมินในรูปแบบต่างๆ
การประเมิน
กระบวนการวัดคุณภาพของรูปแบบหรือการเปรียบเทียบรูปแบบต่างๆ กัน
หากต้องการประเมินโมเดลแมชชีนเลิร์นนิงที่มีการควบคุมดูแล คุณมักจะประเมินโมเดลนั้นเทียบกับชุดการตรวจสอบและชุดทดสอบ การประเมิน LLMมักเกี่ยวข้องกับการประเมินคุณภาพและความปลอดภัยในวงกว้าง
F
Few-Shot Prompting
พรอมต์ที่มีตัวอย่างมากกว่า 1 รายการ ("2-3" รายการ) ซึ่งแสดงวิธีที่โมเดลภาษาขนาดใหญ่ควรตอบ ตัวอย่างเช่น พรอมต์ที่ยาวต่อไปนี้มีตัวอย่าง 2 รายการที่แสดงวิธีตอบคำถามของโมเดลภาษาขนาดใหญ่
| ส่วนต่างๆ ของพรอมต์ 1 รายการ | หมายเหตุ |
|---|---|
| สกุลเงินทางการของประเทศที่ระบุคืออะไร | คำถามที่คุณต้องการให้ LLM ตอบ |
| ฝรั่งเศส: EUR | ตัวอย่างหนึ่ง |
| สหราชอาณาจักร: GBP | อีกตัวอย่างหนึ่ง |
| อินเดีย: | คําค้นหาจริง |
โดยทั่วไปแล้วพรอมต์แบบไม่กี่ช็อตจะให้ผลลัพธ์ที่ต้องการมากกว่าพรอมต์แบบไม่มีช็อตและพรอมต์แบบช็อตเดียว แต่การพรอมต์แบบไม่กี่คำต้องใช้พรอมต์ที่ยาวกว่า
พรอมต์แบบไม่กี่คำเป็นรูปแบบการเรียนรู้แบบไม่กี่คำที่ใช้กับการเรียนรู้ตามพรอมต์
ดูข้อมูลเพิ่มเติมได้ที่การวิศวกรรมพรอมต์ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
ฟิดเดิล
ไลบรารีการกําหนดค่าที่ใช้ Python เป็นภาษาหลัก ซึ่งจะกําหนดค่าของฟังก์ชันและคลาสโดยไม่ต้องใช้โค้ดหรือโครงสร้างพื้นฐานที่แทรกแซง ในกรณีของ Pax และโค้ดเบส ML อื่นๆ ฟังก์ชันและคลาสเหล่านี้แสดงถึงโมเดลและการฝึก ไฮเปอร์พารามิเตอร์
Fiddle จะถือว่าโค้ดเบสแมชชีนเลิร์นนิงมักจะแบ่งออกเป็น 3 ส่วนดังนี้
- โค้ดไลบรารีซึ่งกําหนดเลเยอร์และเครื่องมือเพิ่มประสิทธิภาพ
- โค้ด "กาว" ของชุดข้อมูล ซึ่งเรียกใช้ไลบรารีและเชื่อมต่อทุกอย่างเข้าด้วยกัน
Fiddle จะบันทึกโครงสร้างการเรียกของโค้ดกาวในรูปแบบที่ยังไม่ได้ประเมินและเปลี่ยนแปลงได้
การปรับแต่ง
การฝึกครั้งที่ 2 สำหรับงานเฉพาะที่ดำเนินการกับโมเดลที่ฝึกล่วงหน้าเพื่อปรับแต่งพารามิเตอร์สำหรับกรณีการใช้งานที่เฉพาะเจาะจง ตัวอย่างเช่น ลำดับการฝึกแบบเต็มสำหรับโมเดลภาษาขนาดใหญ่บางรายการมีดังนี้
- การฝึกล่วงหน้า: ฝึกโมเดลภาษาขนาดใหญ่ด้วยชุดข้อมูลทั่วไปขนาดใหญ่ เช่น หน้า Wikipedia ภาษาอังกฤษทั้งหมด
- การปรับแต่ง: ฝึกโมเดลที่ฝึกไว้ล่วงหน้าให้ทํางานที่เฉพาะเจาะจง เช่น การตอบคําค้นหาทางการแพทย์ โดยปกติการปรับแต่งแบบละเอียดจะเกี่ยวข้องกับตัวอย่างหลายร้อยหรือหลายพันรายการที่มุ่งเน้นงานหนึ่งๆ
อีกตัวอย่างหนึ่งคือลําดับการฝึกแบบเต็มสําหรับโมเดลรูปภาพขนาดใหญ่มีดังนี้
- การฝึกล่วงหน้า: ฝึกโมเดลรูปภาพขนาดใหญ่ในชุดข้อมูลรูปภาพทั่วไปขนาดใหญ่ เช่น รูปภาพทั้งหมดใน Wikimedia Commons
- การปรับแต่ง: ฝึกโมเดลที่ฝึกไว้ล่วงหน้าให้ทํางานเฉพาะ เช่น สร้างรูปภาพโลมาน้ำจืด
การปรับแต่งอาจใช้กลยุทธ์ต่อไปนี้ร่วมกัน
- การแก้ไขพารามิเตอร์ที่มีอยู่ทั้งหมดของโมเดลที่ผ่านการฝึกอบรมไว้ล่วงหน้า บางครั้งเรียกว่าการปรับแต่งอย่างละเอียด
- การแก้ไขพารามิเตอร์ที่มีอยู่บางส่วนของโมเดลที่ผ่านการฝึกอบรมล่วงหน้า (โดยปกติแล้วคือชั้นที่อยู่ใกล้กับชั้นเอาต์พุตมากที่สุด) โดยไม่เปลี่ยนแปลงพารามิเตอร์อื่นๆ ที่มีอยู่ (โดยปกติแล้วคือชั้นที่อยู่ใกล้กับชั้นอินพุตมากที่สุด) ดูการปรับแต่งที่มีประสิทธิภาพในแง่พารามิเตอร์
- การเพิ่มเลเยอร์ โดยปกติจะวางไว้บนเลเยอร์ที่มีอยู่ซึ่งอยู่ใกล้กับเลเยอร์เอาต์พุตมากที่สุด
การปรับแต่งเป็นรูปแบบหนึ่งของการเรียนรู้แบบโอน ดังนั้นการปรับแต่งอาจใช้ Loss Function หรือโมเดลประเภทอื่นที่แตกต่างจากที่ใช้ฝึกโมเดลที่ผ่านการฝึกอบรมไว้ล่วงหน้า เช่น คุณอาจปรับแต่งโมเดลรูปภาพขนาดใหญ่ที่ฝึกไว้ล่วงหน้าเพื่อสร้างโมเดลการถดถอยซึ่งจะแสดงจํานวนนกในรูปภาพอินพุต
เปรียบเทียบการปรับแต่งกับคําต่อไปนี้
ดูข้อมูลเพิ่มเติมได้ที่การปรับแต่งในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
เหลืองแฟลกซ์
ไลบรารีโอเพนซอร์สที่มีประสิทธิภาพสูงสําหรับการเรียนรู้เชิงลึกซึ่งสร้างขึ้นจาก JAX Flax มีฟังก์ชันสำหรับการฝึก เครือข่ายประสาทเทียม รวมถึงวิธีการประเมินประสิทธิภาพของเครือข่าย
Flaxformer
ไลบรารี Transformer แบบโอเพนซอร์สที่สร้างขึ้นจาก Flax ซึ่งออกแบบมาเพื่อประมวลผลภาษาธรรมชาติและการวิจัยแบบหลายมิติเป็นหลัก
G
Gemini
ระบบนิเวศที่ประกอบด้วย AI ที่ล้ำหน้าที่สุดของ Google องค์ประกอบของระบบนิเวศนี้ได้แก่
- โมเดล Gemini ต่างๆ
- อินเทอร์เฟซการสนทนาแบบอินเทอร์แอกทีฟกับโมเดล Gemini ผู้ใช้พิมพ์พรอมต์และ Gemini จะตอบกลับพรอมต์เหล่านั้น
- Gemini API ต่างๆ
- ผลิตภัณฑ์ทางธุรกิจต่างๆ ที่อิงตามโมเดล Gemini เช่น Gemini สำหรับ Google Cloud
โมเดล Gemini
โมเดลมัลติโมดที่อิงตาม Transformer ที่ทันสมัยของ Google โมเดล Gemini ได้รับการออกแบบมาโดยเฉพาะเพื่อผสานรวมกับตัวแทน
ผู้ใช้โต้ตอบกับโมเดล Gemini ได้หลายวิธี เช่น ผ่านอินเทอร์เฟซการสนทนาแบบอินเทอร์แอกทีฟและผ่าน SDK
ข้อความที่สร้างขึ้น
โดยทั่วไปคือข้อความที่โมเดล ML แสดงผล เมื่อประเมินโมเดลภาษาขนาดใหญ่ เมตริกบางรายการจะเปรียบเทียบข้อความที่สร้างขึ้นกับข้อความอ้างอิง ตัวอย่างเช่น สมมติว่าคุณพยายามประเมินประสิทธิภาพของโมเดล ML ในการแปลจากภาษาฝรั่งเศสเป็นภาษาดัตช์ ในกรณีนี้
- ข้อความที่สร้างขึ้นคือคำแปลภาษาดัตช์ที่โมเดล ML แสดงผล
- ข้อความอ้างอิงคือคำแปลภาษาดัตช์ที่นักแปล (หรือซอฟต์แวร์) สร้างขึ้น
โปรดทราบว่ากลยุทธ์การประเมินบางกลยุทธ์ไม่มีข้อความอ้างอิง
Generative AI
ช่องการเปลี่ยนแปลงที่กําลังเกิดขึ้นซึ่งไม่มีคําจํากัดความอย่างเป็นทางการ อย่างไรก็ตาม ผู้เชี่ยวชาญส่วนใหญ่ยอมรับว่าโมเดล Generative AI สามารถสร้าง ("สร้าง") เนื้อหาที่มีลักษณะต่อไปนี้ได้ทั้งหมด
- ซับซ้อน
- สอดคล้องกัน
- เดิม
เช่น โมเดล Generative AI สามารถสร้างเรียงความหรือรูปภาพที่ซับซ้อน
เทคโนโลยีรุ่นก่อนหน้าบางรายการ เช่น LSTM และ RNN สามารถสร้างเนื้อหาต้นฉบับที่สอดคล้องกันได้ด้วย ผู้เชี่ยวชาญบางรายมองว่าเทคโนโลยียุคแรกๆ เหล่านี้เป็น Generative AI ขณะที่ผู้เชี่ยวชาญอีกกลุ่มหนึ่งเชื่อว่า Generative AI ที่แท้จริงต้องสร้างเอาต์พุตที่ซับซ้อนกว่าเทคโนโลยียุคแรกๆ เหล่านั้นจะทำได้
ตรงข้ามกับ ML เชิงคาดการณ์
คำตอบที่ยอดเยี่ยม
คำตอบที่ทราบว่าดี ตัวอย่างเช่น เมื่อมีพรอมต์ต่อไปนี้
2 + 2
คำตอบที่เหมาะที่สุดคือ
4
GPT (Generative Pre-trained Transformer)
ตระกูลโมเดลภาษาขนาดใหญ่ที่อิงตาม Transformer ซึ่งพัฒนาโดย OpenAI
รูปแบบ GPT สามารถใช้กับรูปแบบต่างๆ ได้ ซึ่งรวมถึง
- การสร้างรูปภาพ (เช่น ImageGPT)
- การสร้างรูปภาพจากข้อความ (เช่น DALL-E)
H
อาการหลอน
การสร้างเอาต์พุตที่ดูน่าเชื่อถือแต่ข้อเท็จจริงไม่ถูกต้องโดยโมเดล Generative AI ที่อ้างว่ากำลังกล่าวอ้างเกี่ยวกับโลกแห่งความเป็นจริง ตัวอย่างเช่น โมเดล Generative AI ที่อ้างว่า Barack Obama เสียชีวิตในปี 1865 เป็นการเพ้อเจ้อ
การประเมินโดยเจ้าหน้าที่
กระบวนการที่ผู้คนตัดสินคุณภาพของเอาต์พุตของโมเดล ML เช่น การให้ผู้ที่พูดได้ 2 ภาษาตัดสินคุณภาพของโมเดลการแปลด้วย ML การประเมินโดยเจ้าหน้าที่มีประโยชน์อย่างยิ่งในการพิจารณาโมเดลที่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว
ตรงข้ามกับการประเมินอัตโนมัติ และการประเมินโดยเครื่องมือประเมินอัตโนมัติ
I
การเรียนรู้ในบริบท
คำพ้องความหมายของ Few-Shot Prompting
L
LaMDA (โมเดลภาษาสำหรับแอปพลิเคชันด้านการโต้ตอบ หรือ Language Model for Dialog Applications)
โมเดลภาษาขนาดใหญ่ที่อิงตาม Transformer ซึ่งพัฒนาโดย Google และได้รับการฝึกจากชุดข้อมูลการสนทนาขนาดใหญ่ที่สามารถสร้างคำตอบแบบการสนทนาที่สมจริง
LaMDA: เทคโนโลยีการสนทนาที่ก้าวล้ำให้ภาพรวม
โมเดลภาษา
โมเดลที่ประมาณความน่าจะเป็นของโทเค็นหรือลำดับโทเค็นที่ปรากฏในลำดับโทเค็นที่ยาวขึ้น
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาคืออะไรในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
โมเดลภาษาขนาดใหญ่
เป็นโมเดลภาษาที่มีพารามิเตอร์จํานวนมากเป็นอย่างน้อย หรือเรียกง่ายๆ ว่าโมเดลภาษาที่อิงตาม Transformer เช่น Gemini หรือ GPT
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาขนาดใหญ่ (LLM) ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
พื้นที่เชิงซ้อน
คำพ้องความหมายของพื้นที่การฝัง
ระยะ Levenshtein
เมตริกระยะแก้ไขที่คำนวณการดำเนินการลบ แทรก และแทนที่น้อยที่สุดที่จำเป็นต่อการเปลี่ยนคำหนึ่งเป็นคำอื่น ตัวอย่างเช่น ระยะ Levenshtein ระหว่างคําว่า "heart" กับ "darts" มีค่าเป็น 3 เนื่องจากการแก้ไข 3 รายการต่อไปนี้เป็นการเปลี่ยนแปลงที่น้อยที่สุดในการเปลี่ยนคําหนึ่งเป็นคําอื่น
- heart → deart (แทนที่ "h" ด้วย "d")
- deart → dart (ลบ "e")
- dart → darts (แทรก "s")
โปรดทราบว่าลำดับก่อนหน้าไม่ใช่เส้นทางเดียวสำหรับการแก้ไข 3 ครั้ง
LLM
ตัวย่อของโมเดลภาษาขนาดใหญ่
การประเมิน LLM (evals)
ชุดเมตริกและการเปรียบเทียบเพื่อประเมินประสิทธิภาพของโมเดลภาษาขนาดใหญ่ (LLM) การประเมิน LLM ในระดับสูงมีดังนี้
- ช่วยให้นักวิจัยระบุด้านที่ LLM จำเป็นต้องปรับปรุง
- มีประโยชน์ในการเปรียบเทียบ LLM ต่างๆ และระบุ LLM ที่ดีที่สุดสําหรับงานหนึ่งๆ
- ช่วยให้มั่นใจว่า LLM นั้นปลอดภัยและใช้งานได้อย่างมีจริยธรรม
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาขนาดใหญ่ (LLM) ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
LoRA
ตัวย่อของ Low-Rank Adaptability
Low-Rank Adaptability (LoRA)
เทคนิคการใช้พารามิเตอร์อย่างมีประสิทธิภาพสําหรับการปรับแต่งแบบละเอียดที่จะ "หยุด" น้ำหนักที่ผ่านการฝึกล่วงหน้าของโมเดลไว้ (เพื่อไม่ให้แก้ไขได้อีก) จากนั้นแทรกชุดน้ำหนักขนาดเล็กที่ฝึกได้ลงในโมเดล ชุดน้ำหนักที่ฝึกได้นี้ (หรือที่เรียกว่า "เมทริกซ์การอัปเดต") มีขนาดน้อยกว่าโมเดลฐานมาก จึงฝึกได้เร็วกว่ามาก
LoRA มีข้อดีดังต่อไปนี้
- ปรับปรุงคุณภาพการคาดการณ์ของโมเดลสําหรับโดเมนที่ใช้การปรับแต่ง
- ปรับแต่งได้เร็วกว่าเทคนิคที่ต้องปรับแต่งพารามิเตอร์ทั้งหมดของโมเดล
- ลดต้นทุนการประมวลผลของการอนุมานด้วยการเปิดใช้การเรียกใช้โมเดลเฉพาะหลายรายการพร้อมกันซึ่งใช้โมเดลพื้นฐานเดียวกัน
M
โมเดลภาษาที่มีการปกปิด
โมเดลภาษาที่คาดการณ์ความน่าจะเป็นของโทเค็นที่เป็นไปได้ที่จะเติมช่องว่างในลำดับ ตัวอย่างเช่น รูปแบบภาษาที่มีการปกปิดสามารถคํานวณความน่าจะเป็นสําหรับคําที่เป็นไปได้เพื่อแทนที่ขีดล่างในประโยคต่อไปนี้
____ ในหมวกกลับมาแล้ว
โดยปกติแล้ว เอกสารประกอบจะใช้สตริง "MASK" แทนขีดล่าง เช่น
"MASK" ในหมวกกลับมาแล้ว
โมเดลภาษาที่มีการปกปิดสมัยใหม่ส่วนใหญ่เป็นแบบแบบ 2 ทิศทาง
ความแม่นยำเฉลี่ยของค่าเฉลี่ยที่ k (mAP@k)
ค่าเฉลี่ยทางสถิติของคะแนนความแม่นยำเฉลี่ยที่ k ทั้งหมดในชุดข้อมูลที่ใช้ตรวจสอบ การใช้ความแม่นยำเฉลี่ยที่ k อย่างหนึ่งคือเพื่อตัดสินคุณภาพของคําแนะนําที่ระบบคําแนะนําสร้างขึ้น
แม้ว่าวลี "ค่าเฉลี่ยถ่วงน้ำหนัก" จะฟังดูซ้ำซ้อน แต่ชื่อเมตริกก็เหมาะสม ท้ายที่สุดแล้ว เมตริกนี้จะหาค่ามัธยฐานของความแม่นยําเฉลี่ยที่ k หลายค่า
การเรียนรู้เชิงเมตา
แมชชีนเลิร์นนิงย่อยที่ค้นพบหรือปรับปรุงอัลกอริทึมการเรียนรู้ นอกจากนี้ ระบบการเรียนรู้เชิงเมตายังมุ่งฝึกโมเดลให้เรียนรู้งานใหม่ได้อย่างรวดเร็วจากข้อมูลเพียงเล็กน้อยหรือจากประสบการณ์ที่ได้รับจากงานก่อนหน้า โดยทั่วไปแล้ว อัลกอริทึมการเรียนรู้เชิงเมตาจะพยายามบรรลุเป้าหมายต่อไปนี้
- ปรับปรุงหรือเรียนรู้ฟีเจอร์ที่วิศวกรเขียนขึ้นเอง (เช่น ตัวเริ่มต้นหรือเครื่องมือเพิ่มประสิทธิภาพ)
- ประหยัดพื้นที่เก็บข้อมูลและมีประสิทธิภาพในการประมวลผลมากขึ้น
- ปรับปรุงการทั่วไป
การเรียนรู้เชิงเมตาเกี่ยวข้องกับการเรียนรู้แบบดูตัวอย่างน้อย
ผู้เชี่ยวชาญหลากหลายสาขา
รูปแบบที่เพิ่มประสิทธิภาพของเครือข่ายประสาทเทียมโดยใช้เฉพาะชุดย่อยของพารามิเตอร์ (เรียกว่าผู้เชี่ยวชาญ) เพื่อประมวลผลโทเค็นอินพุตหรือตัวอย่างที่ระบุ เครือข่ายการกำหนดสิทธิ์จะกำหนดเส้นทางโทเค็นอินพุตหรือตัวอย่างแต่ละรายการไปยังผู้เชี่ยวชาญที่เหมาะสม
โปรดดูรายละเอียดในเอกสารต่อไปนี้
- โครงข่ายระบบประสาทเทียมขนาดใหญ่อย่างไม่น่าเชื่อ: เลเยอร์การผสมผสานผู้เชี่ยวชาญแบบมีเกตแบบเบาบาง
- การผสมผสานผู้เชี่ยวชาญกับ Expert Choice Routing
MMIT
ตัวย่อของ Multimodal Instruction-Tuned
รูปแบบ
หมวดหมู่ข้อมูลระดับสูง ตัวอย่างเช่น ตัวเลข ข้อความ รูปภาพ วิดีโอ และเสียงเป็นรูปแบบที่แตกต่างกัน 5 รูปแบบ
การทํางานแบบขนานของโมเดล
วิธีปรับขนาดการฝึกหรือการทำนายที่วางส่วนต่างๆ ของโมเดลหนึ่งไว้ในอุปกรณ์ที่แตกต่างกัน การทำงานแบบขนานของโมเดลทำให้ใช้โมเดลที่มีขนาดใหญ่เกินกว่าที่จะใส่ลงในอุปกรณ์เครื่องเดียวได้
โดยทั่วไปแล้ว ระบบจะใช้การทำงานแบบขนานของโมเดลดังนี้
- แยก (แบ่ง) โมเดลออกเป็นส่วนเล็กๆ
- กระจายการฝึกของชิ้นส่วนขนาดเล็กเหล่านั้นไปยังหลายโปรเซสเซอร์ โปรเซสเซอร์แต่ละตัวจะฝึกโมเดลส่วนของตัวเอง
- รวมผลลัพธ์เพื่อสร้างโมเดลเดียว
การทำงานแบบขนานของโมเดลจะทำให้การฝึกช้าลง
โปรดดูการขนานกันของข้อมูลด้วย
MOE
ตัวย่อของ mixture of experts
การใส่ใจตนเองแบบหลายหัว
ส่วนขยายของ Self-Attention ที่ใช้กลไก Self-Attention หลายครั้งสำหรับแต่ละตำแหน่งในลำดับอินพุต
Transformer เปิดตัวการใส่ใจตนเองแบบ Multi-Head
ปรับแต่งตามคำสั่งแบบหลายรูปแบบ
โมเดลที่ปรับตามคำสั่งซึ่งสามารถประมวลผลอินพุตได้นอกเหนือจากข้อความ เช่น รูปภาพ วิดีโอ และเสียง
โมเดลหลายรูปแบบ
โมเดลที่มีอินพุต เอาต์พุต หรือทั้ง 2 อย่างมีรูปแบบมากกว่า 1 รูปแบบ ตัวอย่างเช่น พิจารณาโมเดลที่ใช้ทั้งรูปภาพและคำบรรยายแทนเสียง (โมดาลิตี 2 รูปแบบ) เป็นฟีเจอร์ และแสดงผลคะแนนที่บ่งบอกความเหมาะสมของคำบรรยายแทนเสียงสำหรับรูปภาพ ดังนั้น อินพุตของโมเดลนี้จึงเป็นแบบหลายโมดัลและเอาต์พุตเป็นแบบโมดัลเดียว
N
การประมวลผลภาษาธรรมชาติ
ศาสตร์ด้านการสอนคอมพิวเตอร์ให้ประมวลผลสิ่งที่ผู้ใช้พูดหรือพิมพ์โดยใช้กฎทางภาษา การประมวลผลภาษาธรรมชาติสมัยใหม่เกือบทั้งหมดอาศัยการเรียนรู้ของเครื่องความเข้าใจภาษาธรรมชาติ
กลุ่มย่อยของการประมวลผลภาษาธรรมชาติซึ่งระบุความตั้งใจของสิ่งที่พูดหรือพิมพ์ การทำความเข้าใจภาษาธรรมชาติทำได้มากกว่าการประมวลผลภาษาธรรมชาติ โดยพิจารณาแง่มุมที่ซับซ้อนของภาษา เช่น บริบท การสนทนาเชิงประชด และความรู้สึก
N-gram
ลําดับคํา N รายการ เช่น truly madly เป็น 2-gram เนื่องจากลำดับคำมีความเกี่ยวข้อง madly truly จึงถือเป็น 2-gram ที่แตกต่างจาก truly madly
| N | ชื่อของ N-gram ประเภทนี้ | ตัวอย่าง |
|---|---|---|
| 2 | Bigram หรือ 2-gram | to go, go to, eat lunch, eat dinner |
| 3 | 3-gram | กินมากเกินไป อยู่กันอย่างมีความสุขตลอดไป เสียงระฆังดังก้อง |
| 4 | 4-gram | เดินเล่นในสวนสาธารณะ ฝุ่นในสายลม เด็กชายกินถั่วเลนทิล |
โมเดลการทำความเข้าใจภาษาธรรมชาติจํานวนมากใช้ N-gram เพื่อคาดเดาคําถัดไปที่ผู้ใช้จะพิมพ์หรือพูด ตัวอย่างเช่น สมมติว่าผู้ใช้พิมพ์ happily ever โมเดล NLU ที่อิงตามไตรแกรมมีแนวโน้มที่จะคาดเดาว่าผู้ใช้จะพิมพ์คำว่า after เป็นคำถัดไป
เปรียบเทียบ N-gram กับถุงคำ ซึ่งเป็นชุดคำที่ไม่มีลําดับ
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาขนาดใหญ่ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
NLP
ตัวย่อของการประมวลผลภาษาธรรมชาติ
NLU
ตัวย่อของความเข้าใจภาษาธรรมชาติ
ไม่มีคำตอบที่ถูกต้อง (NORA)
พรอมต์ที่มีคำตอบที่เหมาะสมหลายรายการ ตัวอย่างเช่น พรอมต์ต่อไปนี้ไม่มีคำตอบที่ถูกต้องเพียงคำตอบเดียว
เล่าเรื่องตลกเกี่ยวกับช้างให้ฟังหน่อย
การประเมินพรอมต์ที่ไม่มีคำตอบที่ถูกต้องอาจเป็นเรื่องยาก
NORA
ตัวย่อของคำตอบที่ถูกต้องไม่ได้มีเพียงคำตอบเดียว
O
One-Shot Prompting
พรอมต์ที่มีตัวอย่างรายการเดียวซึ่งแสดงวิธีที่โมเดลภาษาขนาดใหญ่ควรตอบกลับ ตัวอย่างเช่น พรอมต์ต่อไปนี้มีตัวอย่าง 1 รายการที่แสดงวิธีที่โมเดลภาษาขนาดใหญ่ควรตอบคำถาม
| ส่วนต่างๆ ของพรอมต์ 1 รายการ | หมายเหตุ |
|---|---|
| สกุลเงินทางการของประเทศที่ระบุคืออะไร | คำถามที่คุณต้องการให้ LLM ตอบ |
| ฝรั่งเศส: EUR | ตัวอย่างหนึ่ง |
| อินเดีย: | คําค้นหาจริง |
เปรียบเทียบพรอมต์แบบยิงครั้งเดียวกับเงื่อนไขต่อไปนี้
P
การปรับแต่งพารามิเตอร์ที่มีประสิทธิภาพ
ชุดเทคนิคในการปรับแต่งโมเดลภาษาที่ผ่านการฝึกอบรมล่วงหน้า (PLM) ขนาดใหญ่อย่างมีประสิทธิภาพมากกว่าการปรับแต่งแบบเต็ม การปรับแต่งแบบประหยัดพารามิเตอร์มักจะปรับแต่งพารามิเตอร์น้อยกว่าการปรับแต่งแบบเต็ม แต่โดยทั่วไปจะสร้างโมเดลภาษาขนาดใหญ่ที่มีประสิทธิภาพดี (หรือเกือบเท่า) กับโมเดลภาษาขนาดใหญ่ที่สร้างจากการปรับแต่งแบบเต็ม
เปรียบเทียบการปรับแต่งแบบมีประสิทธิภาพของพารามิเตอร์กับสิ่งต่อไปนี้
การปรับแต่งที่มีประสิทธิภาพของพารามิเตอร์เรียกอีกอย่างว่าการปรับแต่งอย่างละเอียดที่มีประสิทธิภาพของพารามิเตอร์
การจัดลําดับ
รูปแบบการทํางานแบบขนานของโมเดล ซึ่งการประมวลผลของโมเดลจะแบ่งออกเป็นระยะๆ ต่อเนื่องกันและแต่ละระยะจะทํางานในอุปกรณ์เครื่องอื่น ขณะที่ระยะหนึ่งกำลังประมวลผลกลุ่มหนึ่ง ระยะก่อนหน้าจะประมวลผลกลุ่มถัดไปได้
โปรดดูการฝึกอบรมแบบเป็นขั้นด้วย
PLM
ตัวย่อของโมเดลภาษาที่ฝึกล่วงหน้า
การเข้ารหัสตำแหน่ง
เทคนิคในการเพิ่มข้อมูลเกี่ยวกับตําแหน่งของโทเค็นในลําดับไปยังการฝังของโทเค็น โมเดล Transformer ใช้การเข้ารหัสตำแหน่งเพื่อทำความเข้าใจความสัมพันธ์ระหว่างส่วนต่างๆ ของลำดับได้ดียิ่งขึ้น
การใช้งานการเข้ารหัสตำแหน่งทั่วไปจะใช้ฟังก์ชันไซน์ (กล่าวอย่างเจาะจงคือ ความถี่และแอมพลิจูดของฟังก์ชันไซน์กำหนดโดยตําแหน่งของโทเค็นในลําดับ) เทคนิคนี้ช่วยให้โมเดล Transformer เรียนรู้ที่จะให้ความสำคัญกับส่วนต่างๆ ของลำดับตามตำแหน่งของส่วนนั้นๆ
โมเดลหลังการฝึก
คําที่กําหนดไว้อย่างหลวมๆ ซึ่งโดยทั่วไปหมายถึงโมเดลที่ผ่านการฝึกล่วงหน้าซึ่งผ่านกระบวนการประมวลผลขั้นสุดท้ายแล้ว เช่น การดำเนินการต่อไปนี้อย่างน้อย 1 อย่าง
ความแม่นยำที่ k (precision@k)
เมตริกสําหรับประเมินรายการที่จัดอันดับ (เรียงลําดับ) ความแม่นยำที่ k จะระบุส่วนของรายการ k รายการแรกในรายการนั้นซึ่ง "เกี่ยวข้อง" โดยการ
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
ค่าของ k ต้องน้อยกว่าหรือเท่ากับความยาวของลิสต์ที่แสดงผล โปรดทราบว่าความยาวของรายการที่แสดงผลจะไม่รวมอยู่ในการคำนวณ
ความเกี่ยวข้องมักเป็นเรื่องส่วนตัว แม้แต่ผู้ประเมินที่เป็นมนุษย์ที่เชี่ยวชาญก็มักไม่เห็นด้วยว่ารายการใดมีความเกี่ยวข้อง
เปรียบเทียบกับ:
โมเดลที่ฝึกล่วงหน้า
โดยปกติแล้วคือโมเดลที่ผ่านการฝึกแล้ว หรืออาจหมายถึงเวกเตอร์การฝังที่ผ่านการฝึกก่อนหน้านี้
คําว่าโมเดลภาษาที่ฝึกล่วงหน้ามักจะหมายถึงโมเดลภาษาขนาดใหญ่ที่ได้รับการฝึกมาแล้ว
การฝึกขั้นต้น
การฝึกโมเดลครั้งแรกในชุดข้อมูลขนาดใหญ่ โมเดลที่ผ่านการฝึกล่วงหน้าบางรุ่นเป็นโมเดลที่ทำงานได้ไม่ดีนัก และมักจะต้องได้รับการปรับแต่งผ่านการฝึกเพิ่มเติม ตัวอย่างเช่น ผู้เชี่ยวชาญด้าน ML อาจฝึกโมเดลภาษาขนาดใหญ่ล่วงหน้าด้วยชุดข้อมูลข้อความขนาดใหญ่ เช่น หน้าภาษาอังกฤษทั้งหมดใน Wikipedia หลังจากการฝึกล่วงหน้าแล้ว โมเดลที่ได้อาจได้รับการปรับแต่งเพิ่มเติมผ่านเทคนิคต่อไปนี้
- distillation
- การปรับแต่ง
- การปรับแต่งคำสั่ง
- การปรับแต่งที่มีประสิทธิภาพในแง่พารามิเตอร์
- prompt-tuning
พรอมต์
ข้อความที่ป้อนเป็นอินพุตให้กับโมเดลภาษาขนาดใหญ่เพื่อปรับสภาพโมเดลให้ทำงานในลักษณะหนึ่งๆ พรอมต์อาจเป็นวลีสั้นๆ หรือยาวเท่าใดก็ได้ (เช่น ข้อความทั้งหมดของนวนิยาย) พรอมต์จะแบ่งออกเป็นหลายหมวดหมู่ ซึ่งรวมถึงหมวดหมู่ที่แสดงในตารางต่อไปนี้
| หมวดหมู่พรอมต์ | ตัวอย่าง | หมายเหตุ |
|---|---|---|
| คำถาม | นกพิราบบินได้เร็วแค่ไหน | |
| โรงเรียนฝึกอบรม | แต่งบทกวีตลกๆ เกี่ยวกับอาร์บิทราจ | พรอมต์ที่ขอให้โมเดลภาษาขนาดใหญ่ทําบางอย่าง |
| ตัวอย่าง | แปลโค้ด Markdown เป็น HTML ตัวอย่างเช่น
Markdown: * รายการย่อย HTML: <ul> <li>รายการย่อย</li> </ul> |
ประโยคแรกในพรอมต์ตัวอย่างนี้คือคำสั่ง ส่วนที่เหลือของพรอมต์คือตัวอย่าง |
| บทบาท | อธิบายเหตุผลที่ต้องใช้การลดเชิงลาดในการสอนแมชชีนเลิร์นนิงเพื่อรับปริญญาเอกสาขาฟิสิกส์ | ส่วนแรกของประโยคคือคำสั่ง ส่วนวลี "จบปริญญาเอกสาขาฟิสิกส์" คือส่วนบทบาท |
| อินพุตบางส่วนเพื่อให้โมเดลทำงานได้ | นายกรัฐมนตรีของสหราชอาณาจักรอาศัยอยู่ที่ | พรอมต์การป้อนข้อมูลบางส่วนอาจสิ้นสุดอย่างกะทันหัน (เช่น ตัวอย่างนี้) หรือลงท้ายด้วยขีดล่างก็ได้ |
โมเดล Generative AI สามารถตอบสนองต่อพรอมต์ด้วยข้อความ โค้ด รูปภาพ การฝัง วิดีโอ และแทบทุกสิ่ง
การเรียนรู้ตามพรอมต์
ความสามารถของโมเดลบางรายการที่ช่วยให้สามารถปรับเปลี่ยนลักษณะการทํางานเพื่อตอบสนองต่ออินพุตข้อความแบบไม่เจาะจง (พรอมต์) ในกระบวนทัศน์การเรียนรู้แบบพรอมต์ทั่วไป โมเดลภาษาขนาดใหญ่จะตอบสนองต่อพรอมต์ด้วยการสร้างข้อความ ตัวอย่างเช่น สมมติว่าผู้ใช้ป้อนพรอมต์ต่อไปนี้
สรุปกฎการเคลื่อนที่ข้อที่ 3 ของนิวตัน
โมเดลที่เรียนรู้ตามพรอมต์ไม่ได้ผ่านการฝึกมาเพื่อตอบพรอมต์ก่อนหน้าโดยเฉพาะ แต่โมเดลจะ "รู้" ข้อเท็จจริงมากมายเกี่ยวกับฟิสิกส์ กฎทั่วไปของภาษา และองค์ประกอบต่างๆ ของคำตอบที่เป็นประโยชน์โดยทั่วไป ความรู้ดังกล่าวเพียงพอที่จะให้คำตอบที่เป็นประโยชน์ (หวังว่าจะเป็นเช่นนั้น) ความคิดเห็นเพิ่มเติมจากผู้ใช้ ("คำตอบนั้นซับซ้อนเกินไป" หรือ "Reaction คืออะไร") จะช่วยให้ระบบการเรียนรู้แบบพรอมต์บางระบบปรับปรุงความมีประโยชน์ของคำตอบได้ทีละน้อย
การออกแบบพรอมต์
คำพ้องความหมายของวิศวกรรมพรอมต์
วิศวกรรมพรอมต์
ศิลปะในการสร้างพรอมต์ที่ดึงดูดคำตอบที่ต้องการจากโมเดลภาษาขนาดใหญ่ มนุษย์ทำการดัดแปลงพรอมต์ การเขียนพรอมต์ที่มีโครงสร้างดีเป็นส่วนสําคัญในการช่วยให้ได้รับคําตอบที่เป็นประโยชน์จากโมเดลภาษาขนาดใหญ่ การปรับแต่งข้อความแจ้งขึ้นอยู่กับหลายปัจจัย ได้แก่
- ชุดข้อมูลที่ใช้ฝึกล่วงหน้าและอาจปรับแต่งโมเดลภาษาขนาดใหญ่
- temperature และพารามิเตอร์การถอดรหัสอื่นๆ ที่โมเดลใช้ในการสร้างคำตอบ
การออกแบบพรอมต์เป็นคําพ้องความหมายของวิศวกรรมพรอมต์
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการเขียนพรอมต์ที่เป็นประโยชน์ได้ในส่วนข้อมูลเบื้องต้นเกี่ยวกับการออกแบบพรอมต์
การปรับแต่งพรอมต์
กลไกการปรับพารามิเตอร์อย่างมีประสิทธิภาพซึ่งจะเรียนรู้ "คำนำหน้า" ที่ระบบจะใส่ไว้ก่อนพรอมต์จริง
การปรับพรอมต์รูปแบบหนึ่ง ซึ่งบางครั้งเรียกว่าการปรับคำนำหน้าคือการใส่คำนำหน้าไว้ที่ทุกเลเยอร์ ในทางตรงกันข้าม การปรับแต่งพรอมต์ส่วนใหญ่จะเพิ่มเฉพาะคำนำหน้าในเลเยอร์อินพุต
R
การจําที่ k (recall@k)
เมตริกสําหรับประเมินระบบที่แสดงรายการที่จัดอันดับ (เรียงลําดับ) การเรียกคืนที่ k จะระบุเศษส่วนของรายการที่เกี่ยวข้องในรายการ k รายการแรกในรายการนั้นจากจํานวนรายการที่เกี่ยวข้องทั้งหมดที่แสดง
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
เปรียบเทียบกับความแม่นยำที่ k
ข้อความอ้างอิง
คำตอบของผู้เชี่ยวชาญต่อพรอมต์ ตัวอย่างเช่น จากพรอมต์ต่อไปนี้
แปลคำถาม "คุณชื่ออะไร" จากภาษาอังกฤษเป็นภาษาฝรั่งเศส
คำตอบของผู้เชี่ยวชาญอาจเป็นดังนี้
Comment vous appelez-vous?
เมตริกต่างๆ (เช่น ROUGE) จะวัดระดับที่ข้อความอ้างอิงตรงกับข้อความที่สร้างขึ้นของโมเดล ML
การแจ้งเตือนบทบาท
ส่วนที่ไม่บังคับของพรอมต์ที่ระบุกลุ่มเป้าหมายสำหรับการตอบกลับของโมเดล Generative AI หากไม่มีพรอมต์บทบาท โมเดลภาษาขนาดใหญ่จะให้คำตอบที่อาจหรือไม่เป็นประโยชน์สำหรับบุคคลที่ถามคำถาม เมื่อใช้พรอมต์บทบาท โมเดลภาษาขนาดใหญ่จะตอบคำถามในลักษณะที่เหมาะสมและเป็นประโยชน์มากขึ้นสําหรับกลุ่มเป้าหมายที่เฉพาะเจาะจง ตัวอย่างเช่น ส่วนพรอมต์บทบาทของพรอมต์ต่อไปนี้จะเป็นตัวหนา
- สรุปเอกสารนี้สำหรับปริญญาเอกสาขาเศรษฐศาสตร์
- อธิบายวิธีการทำงานของน้ำขึ้นน้ำลงสำหรับเด็กอายุ 10 ปี
- อธิบายวิกฤตการเงินปี 2008 พูดเหมือนพูดกับเด็กเล็กหรือสุนัขพันธุ์โกลเด้นรีทรีฟเวอร์
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
กลุ่มเมตริกที่ประเมินการสรุปอัตโนมัติและรูปแบบการแปลด้วยคอมพิวเตอร์ เมตริก ROUGE จะระบุระดับที่ข้อความอ้างอิงซ้อนทับกับข้อความที่สร้างขึ้นของโมเดล ML แต่ละสมาชิกของครอบครัว ROUGE จะวัดผลการซ้อนทับกันด้วยวิธีที่แตกต่างกัน คะแนน ROUGE ที่สูงกว่าบ่งชี้ว่าข้อความอ้างอิงกับข้อความที่สร้างขึ้นมีความคล้ายคลึงกันมากกว่าคะแนน ROUGE ที่ต่ำกว่า
โดยปกติแล้วสมาชิกในครอบครัว ROUGE แต่ละคนจะสร้างเมตริกต่อไปนี้
- ความแม่นยำ
- การจดจำ
- F1
ดูรายละเอียดและตัวอย่างได้ที่
ROUGE-L
สมาชิกของตระกูล ROUGE ที่มุ่งเน้นที่ความยาวของอนุกรมย่อยที่พบร่วมกันยาวที่สุดในข้อความอ้างอิงและข้อความที่สร้างขึ้น สูตรต่อไปนี้จะคํานวณการเรียกคืนและความแม่นยําสําหรับ ROUGE-L
จากนั้นคุณสามารถใช้ F1 เพื่อรวมการเรียกคืน ROUGE-L และแม่นยำของ ROUGE-L ไว้ในเมตริกเดียว ดังนี้
ROUGE-L ไม่สนใจการขึ้นบรรทัดใหม่ในข้อความอ้างอิงและข้อความที่สร้างขึ้น ดังนั้นอนุกรมย่อยที่พบร่วมกันยาวที่สุดอาจข้ามหลายประโยค เมื่อข้อความอ้างอิงและข้อความที่สร้างขึ้นมีประโยคหลายประโยค โดยทั่วไปแล้ว รูปแบบของ ROUGE-L ที่ชื่อ ROUGE-Lsum จะถือเป็นเมตริกที่ดีกว่า ROUGE-Lsum จะระบุอนุกรมย่อยที่พบร่วมกันยาวที่สุดสำหรับประโยคแต่ละประโยคในย่อหน้า จากนั้นจะคํานวณค่าเฉลี่ยของอนุกรมย่อยที่พบร่วมกันยาวที่สุดเหล่านั้น
ROUGE-N
ชุดเมตริกภายในตระกูล ROUGE ที่เปรียบเทียบ N-gram ที่ใช้ร่วมกันซึ่งมีขนาดที่แน่นอนในข้อความอ้างอิงและข้อความที่สร้างขึ้น เช่น
- ROUGE-1 จะวัดจํานวนโทเค็นที่แชร์ในข้อความอ้างอิงและข้อความที่สร้างขึ้น
- ROUGE-2 จะวัดจํานวน Bigram (2-gram) ที่แชร์ในข้อความอ้างอิงและข้อความที่สร้างขึ้น
- ROUGE-3 จะวัดจํานวน Trigram (3-gram) ที่แชร์ในข้อความอ้างอิงและข้อความที่สร้างขึ้น
คุณสามารถใช้สูตรต่อไปนี้เพื่อคํานวณการเรียกคืนและแม่นยําของ ROUGE-N สําหรับสมาชิกของครอบครัว ROUGE-N
จากนั้นคุณสามารถใช้ F1 เพื่อรวมการเรียกคืน ROUGE-N และแม่นยำของ ROUGE-N ไว้ในเมตริกเดียว ดังนี้
ROUGE-S
รูปแบบ ROUGE-N ที่ยืดหยุ่นซึ่งเปิดใช้การจับคู่ Skip-Gram กล่าวคือ ROUGE-N จะนับเฉพาะ N-gram ที่ตรงกันทุกประการ แต่ ROUGE-S จะนับ N-gram ที่แยกกันด้วยคำอย่างน้อย 1 คำด้วย เช่น โปรดคำนึงถึงสิ่งต่อไปนี้
- reference text: White clouds
- ข้อความที่สร้างขึ้น: เมฆสีขาวที่ลอยอยู่
เมื่อคํานวณ ROUGE-N 2-gram White clouds ไม่ตรงกับ White billowing clouds อย่างไรก็ตาม เมื่อคำนวณ ROUGE-S คำว่าเมฆสีขาวจะตรงกับเมฆสีขาวที่ลอยอยู่
S
การใส่ใจตนเอง (หรือที่เรียกว่าเลเยอร์การใส่ใจตนเอง)
เลเยอร์เครือข่ายประสาทที่เปลี่ยนรูปแบบของลําดับการฝัง (เช่น การฝังโทเค็น) เป็นลําดับการฝังอีกรูปแบบหนึ่ง แต่ละการฝังในลำดับเอาต์พุตสร้างขึ้นโดยการรวมข้อมูลจากองค์ประกอบของลำดับอินพุตผ่านกลไกการใส่ใจ
ส่วน self ของ self-attention หมายถึงลำดับที่สนใจตัวมันเอง ไม่ใช่บริบทอื่น การใส่ใจตนเองเป็นหนึ่งในองค์ประกอบหลักของ Transformer และใช้คำศัพท์การค้นหาพจนานุกรม เช่น "การค้นหา" "คีย์" และ "ค่า"
เลเยอร์ Self-Attention เริ่มต้นด้วยลําดับของการแสดงข้อมูลอินพุต 1 รายการสําหรับแต่ละคํา การนําเสนออินพุตสําหรับคําอาจเป็นการฝังข้อมูลแบบง่าย สําหรับคําแต่ละคําในลําดับอินพุต เครือข่ายจะประเมินความเกี่ยวข้องของคํานั้นกับองค์ประกอบทุกรายการในลําดับคําทั้งหมด คะแนนความเกี่ยวข้องจะกําหนดว่าการแสดงผลสุดท้ายของคํารวมเอาการแสดงผลของคําอื่นๆ มากน้อยเพียงใด
ตัวอย่างเช่น ลองพิจารณาประโยคต่อไปนี้
สัตว์ไม่ข้ามถนนเพราะเหนื่อยเกินไป
ภาพประกอบต่อไปนี้ (จาก Transformer: A Novel Neural Network Architecture for Language Understanding) แสดงรูปแบบการให้ความสำคัญกับเลเยอร์การให้ความสำคัญกับตนเองสำหรับคำสรรพนาม it โดยความเข้มของเส้นแต่ละเส้นจะบ่งบอกถึงระดับที่แต่ละคำมีส่วนร่วมในการแสดงแทน
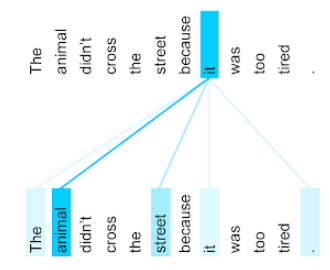
เลเยอร์การใส่ใจตนเองจะไฮไลต์คำที่เกี่ยวข้องกับ "มัน" ในกรณีนี้ เลเยอร์ความสนใจได้เรียนรู้ที่จะไฮไลต์คำที่มันอาจอ้างอิงถึง โดยกำหนดน้ำหนักสูงสุดให้กับสัตว์
สําหรับลําดับ โทเค็น n รายการ การใส่ใจตนเองจะเปลี่ยนลําดับของ n รายการ embeddings แยกกันทีละรายการในลําดับ
โปรดดูการใส่ใจและการใส่ใจตนเองแบบ Multi-Head ด้วย
การวิเคราะห์ความเห็น
การใช้อัลกอริทึมสถิติหรือแมชชีนเลิร์นนิงเพื่อพิจารณาทัศนคติโดยรวมของกลุ่ม (เชิงบวกหรือเชิงลบ) ต่อบริการ ผลิตภัณฑ์ องค์กร หรือหัวข้อ ตัวอย่างเช่น เมื่อใช้ความเข้าใจภาษาธรรมชาติ อัลกอริทึมอาจทำการวิเคราะห์ความรู้สึกในความคิดเห็นที่เป็นข้อความจากหลักสูตรของมหาวิทยาลัยเพื่อพิจารณาระดับที่นักเรียนชอบหรือไม่ชอบหลักสูตรโดยทั่วไป
ดูข้อมูลเพิ่มเติมได้ที่คู่มือการจัดประเภทข้อความ
งานแบบอนุกรมต่ออนุกรม
งานที่จะแปลงลำดับอินพุตของโทเค็นเป็นลำดับเอาต์พุตของโทเค็น ตัวอย่างเช่น งานประเภทอนุกรมต่ออนุกรมที่ได้รับความนิยม 2 ประเภท ได้แก่
- ผู้แปล
- ตัวอย่างลำดับอินพุต: "ฉันรักคุณ"
- ตัวอย่างลำดับเอาต์พุต: "Je t'aime."
- การตอบคําถาม
- ตัวอย่างลำดับอินพุต: "Do I need my car in New York City?" (ฉันต้องใช้รถในนิวยอร์กซิตี้ไหม)
- ตัวอย่างลำดับเอาต์พุต: "ไม่ โปรดจอดรถไว้ที่บ้าน"
Skip-gram
N-gram ซึ่งอาจละเว้น (หรือ "ข้าม") คำจากบริบทเดิม ซึ่งหมายความว่าคำ N คำอาจไม่ได้อยู่ติดกันตั้งแต่แรก กล่าวอย่างละเอียดคือ "k-skip-n-gram" คือ n-gram ที่อาจมีการข้ามคำได้สูงสุด k คำ
เช่น "the quick brown fox" มี 2-gram ที่เป็นไปได้ดังต่อไปนี้
- "the quick"
- "quick brown"
- "หมาป่าสีน้ำตาล"
"1-skip-2-gram" คือคู่คำที่มีคำคั่นระหว่างกันไม่เกิน 1 คำ ดังนั้น "the quick brown fox" จึงมี 2-gram แบบข้าม 1 รายการดังต่อไปนี้
- "the brown"
- "quick fox"
นอกจากนี้ 2-gram ทั้งหมดยังเป็น 1-skip-2-gram ด้วย เนื่องจากอาจข้ามได้น้อยกว่า 1 คำ
Skip-gram มีประโยชน์ในการทําความเข้าใจบริบทรอบๆ คํามากขึ้น ในตัวอย่างนี้ "fox" เชื่อมโยงโดยตรงกับ "quick" ในชุด 1-skip-2-grams แต่ไม่ได้อยู่ในชุด 2-grams
Skip-gram ช่วยฝึกโมเดลการฝังคำ
การปรับแต่งพรอมต์แบบนุ่มนวล
เทคนิคการปรับโมเดลภาษาขนาดใหญ่สำหรับงานหนึ่งๆ โดยไม่ต้องปรับแต่งอย่างละเอียดซึ่งต้องใช้ทรัพยากรมาก การปรับพรอมต์แบบนุ่มจะปรับพรอมต์โดยอัตโนมัติเพื่อให้บรรลุเป้าหมายเดียวกันแทนที่จะฝึกน้ำหนักทั้งหมดในโมเดลใหม่
เมื่อได้รับพรอมต์ที่เป็นข้อความ การปรับพรอมต์แบบ Soft มักจะเพิ่มการฝังโทเค็นเพิ่มเติมลงในพรอมต์ และใช้ Backpropagation เพื่อเพิ่มประสิทธิภาพอินพุต
พรอมต์ "แบบแข็ง" จะมีโทเค็นจริงแทนการฝังโทเค็น
องค์ประกอบที่กระจัดกระจาย
ฟีเจอร์ที่มีค่าเป็น 0 หรือว่างเปล่าเป็นส่วนใหญ่ เช่น ฟีเจอร์ที่มีค่า 1 รายการเดียวและค่า 0 1 ล้านรายการจะมีความกระจัดกระจาย ในทางตรงกันข้าม ฟีเจอร์แบบหนาแน่นมีค่าที่ส่วนใหญ่ไม่ใช่ 0 หรือว่าง
ในแมชชีนเลิร์นนิง ฟีเจอร์จำนวนมากเป็นฟีเจอร์ที่กระจัดกระจาย ฟีเจอร์เชิงหมวดหมู่มักจะเป็นฟีเจอร์ที่กระจัดกระจาย เช่น จากต้นไม้ 300 สายพันธุ์ที่เป็นไปได้ในป่า ตัวอย่างเดียวอาจระบุได้เพียงต้นเมเปิล หรือจากวิดีโอที่เป็นไปได้หลายล้านรายการในคลังวิดีโอ ตัวอย่างเพียงรายการเดียวอาจระบุแค่ "Casablanca"
ในโมเดล โดยทั่วไปคุณแสดงฟีเจอร์แบบเบาบางด้วยการเข้ารหัสแบบฮอตเวิร์ก หากการเข้ารหัสแบบฮอตเวิร์กมีขนาดใหญ่ คุณอาจใส่เลเยอร์การฝังไว้ด้านบนการเข้ารหัสแบบฮอตเวิร์กเพื่อให้มีประสิทธิภาพมากขึ้น
การนําเสนอแบบเบาบาง
การจัดเก็บเฉพาะตําแหน่งขององค์ประกอบที่ไม่ใช่ 0 ในฟีเจอร์แบบเบาบาง
ตัวอย่างเช่น สมมติว่าองค์ประกอบเชิงหมวดหมู่ชื่อ species ระบุสายพันธุ์ต้นไม้ 36 ชนิดในป่าแห่งหนึ่ง และสมมติเพิ่มเติมว่า ตัวอย่างแต่ละรายการระบุเพียงสปีชีส์เดียว
คุณสามารถใช้เวกเตอร์แบบฮอตเวิร์ก 1 รายการเพื่อแสดงสายพันธุ์ต้นไม้ในแต่ละตัวอย่าง
เวกเตอร์แบบฮอตเวิร์กเดียวจะมี 1 รายการเดียว (เพื่อแสดงถึงพันธุ์ไม้บางชนิดในตัวอย่างนั้น) และ 0 35 รายการ (เพื่อแสดงถึงพันธุ์ไม้ 35 ชนิดที่ไม่อยู่ในตัวอย่างนั้น) ดังนั้นการนําเสนอแบบฮอตเวิร์ดของ maple จึงอาจมีลักษณะดังนี้

หรือการแสดงแบบเบาบางจะระบุตำแหน่งของพันธุ์นั้นๆ เท่านั้น หาก maple อยู่ที่ตําแหน่ง 24 การแสดงแบบเบาบางของ maple จะเป็นดังนี้
24
โปรดสังเกตว่าการนําเสนอแบบเบาบางมีความกะทัดรัดกว่าการนําเสนอแบบฮอตเวิร์ก
คลิกไอคอนเพื่อดูตัวอย่างที่ซับซ้อนขึ้นเล็กน้อย
สมมติว่าตัวอย่างแต่ละรายการในโมเดลต้องแสดงคำ (แต่ไม่แสดงลําดับของคําเหล่านั้น) ในประโยคภาษาอังกฤษ ภาษาอังกฤษประกอบด้วยคำประมาณ 170,000 คำ ดังนั้นภาษาอังกฤษจึงเป็นฟีเจอร์เชิงหมวดหมู่ที่มีองค์ประกอบประมาณ 170,000 รายการ ประโยคภาษาอังกฤษส่วนใหญ่ใช้คำเพียงส่วนน้อยมากจาก 170,000 คำดังกล่าว ชุดคำในตัวอย่างเดียวจึงมีแนวโน้มสูงที่จะกลายเป็นข้อมูลเบาบาง
ลองพิจารณาประโยคต่อไปนี้
My dog is a great dog
คุณอาจใช้ตัวแปรของเวกเตอร์แบบฮอตเวิร์กเพื่อแสดงคําในประโยคนี้ได้ ในตัวแปรนี้ เซลล์หลายเซลล์ในเวกเตอร์อาจมีค่าที่ไม่ใช่ 0 นอกจากนี้ ในตัวแปรนี้ เซลล์อาจมีจำนวนเต็มอื่นที่ไม่ใช่ 1 แม้ว่าคำว่า "my", "is", "a" และ "great" จะปรากฏเพียงครั้งเดียวในประโยค แต่คำว่า "dog" ปรากฏ 2 ครั้ง การใช้เวกเตอร์ One-Hot รูปแบบนี้เพื่อแสดงคําในประโยคนี้จะให้เวกเตอร์องค์ประกอบ 170,000 รายการดังต่อไปนี้

การแสดงประโยคเดียวกันแบบเบาบางจะเป็นดังนี้
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
ดูข้อมูลเพิ่มเติมที่หัวข้อการทํางานกับข้อมูลเชิงหมวดหมู่ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
การฝึกแบบเป็นขั้น
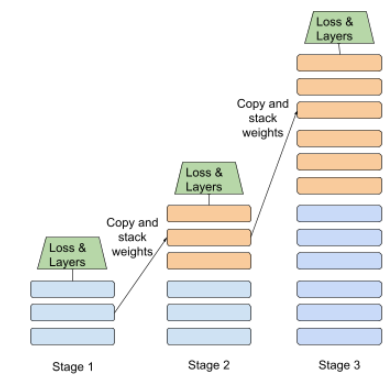
กลยุทธ์การฝึกโมเดลตามลำดับขั้นตอนที่แยกกัน เป้าหมายอาจเป็นการเร่งกระบวนการฝึกอบรมหรือเพื่อให้ได้โมเดลที่มีคุณภาพดีขึ้น
ภาพประกอบของแนวทางการซ้อนแบบเป็นขั้นๆ แสดงอยู่ด้านล่าง
- ระยะที่ 1 มีเลเยอร์ที่ซ่อนอยู่ 3 เลเยอร์ ระยะที่ 2 มีเลเยอร์ที่ซ่อนอยู่ 6 เลเยอร์ และระยะที่ 3 มีเลเยอร์ที่ซ่อนอยู่ 12 เลเยอร์
- ระยะที่ 2 จะเริ่มการฝึกด้วยน้ำหนักที่เรียนรู้ในเลเยอร์ที่ซ่อนอยู่ 3 เลเยอร์ของระยะที่ 1 ระยะที่ 3 จะเริ่มการฝึกด้วยน้ำหนักที่เรียนรู้ในเลเยอร์ที่ซ่อนอยู่ 6 เลเยอร์ของระยะที่ 2
โปรดดูการไปป์ไลน์ด้วย
โทเค็นคำย่อย
ในโมเดลภาษา โทเค็นคือสตริงย่อยของคำ ซึ่งอาจเป็นทั้งคำ
เช่น คําอย่าง "แจกแจง" อาจแบ่งออกเป็น "รายการ" (รากคํา) และ "แจกแจง" (ส่วนต่อท้าย) ซึ่งแต่ละรายการจะแสดงด้วยโทเค็นของตัวเอง การแยกคำที่ไม่พบบ่อยออกเป็นส่วนๆ ที่เรียกว่าคำย่อยจะช่วยให้โมเดลภาษาทำงานกับองค์ประกอบที่พบบ่อยกว่าของคำได้ เช่น คำนำหน้าและคำต่อท้าย
ในทางกลับกัน คําทั่วไปอย่าง "going" อาจไม่แบ่งออกเป็นหลายส่วนและอาจแสดงด้วยโทเค็นเดียว
T
T5
โมเดลการเรียนรู้แบบโอนจากข้อความหนึ่งไปยังอีกข้อความหนึ่งซึ่ง AI ของ Google เปิดตัวในปี 2020 T5 เป็นโมเดลโปรแกรมเปลี่ยนไฟล์-โปรแกรมถอดรหัสที่อิงตามสถาปัตยกรรม Transformer ซึ่งได้รับการฝึกด้วยชุดข้อมูลขนาดใหญ่มาก โมเดลนี้มีประสิทธิภาพในงานการประมวลผลภาษาธรรมชาติที่หลากหลาย เช่น การสร้างข้อความ แปลภาษา และการตอบคำถามในลักษณะการสนทนา
T5 มาจาก T 5 ตัวใน "Text-to-Text Transfer Transformer"
T5X
เฟรมเวิร์กแมชชีนเลิร์นนิงแบบโอเพนซอร์สที่ออกแบบมาเพื่อสร้างและฝึกโมเดลการประมวลผลภาษาธรรมชาติ (NLP) ขนาดใหญ่ T5 ติดตั้งใช้งานบนโค้ดเบส T5X (ซึ่งสร้างขึ้นจาก JAX และ Flax)
อุณหภูมิ
ไฮเปอร์พารามิเตอร์ที่ควบคุมระดับความสุ่มของเอาต์พุตของโมเดล อุณหภูมิที่สูงขึ้นจะทำให้เอาต์พุตเป็นแบบสุ่มมากขึ้น ส่วนอุณหภูมิที่ต่ำลงจะทำให้เอาต์พุตเป็นแบบสุ่มน้อยลง
การเลือกอุณหภูมิที่ดีที่สุดขึ้นอยู่กับแอปพลิเคชันเฉพาะและพร็อพเพอร์ตี้ที่ต้องการของเอาต์พุตของโมเดล เช่น คุณอาจเพิ่มอุณหภูมิเมื่อสร้างแอปพลิเคชันที่สร้างเอาต์พุตครีเอทีฟโฆษณา ในทางกลับกัน คุณอาจลดอุณหภูมิเมื่อสร้างโมเดลที่จัดประเภทรูปภาพหรือข้อความเพื่อปรับปรุงความแม่นยำและความสอดคล้องของโมเดล
อุณหภูมิมักใช้ร่วมกับ softmax
ช่วงข้อความ
ช่วงที่ระบุอาร์เรย์ที่เชื่อมโยงกับส่วนย่อยที่เฉพาะเจาะจงของสตริงข้อความ
เช่น คำว่า good ในสตริง Python s="Be good now" ครอบครองช่วงข้อความที่ 3 ถึง 6
โทเค็น
ในโมเดลภาษา หน่วยพื้นฐานที่โมเดลใช้ฝึกและทำการคาดการณ์ โดยปกติแล้วโทเค็นจะเป็นอย่างใดอย่างหนึ่งต่อไปนี้
- คํา เช่น วลี "สุนัขชอบแมว" ประกอบด้วยโทเค็นคํา 3 รายการ ได้แก่ "สุนัข" "ชอบ" และ "แมว"
- อักขระ เช่น วลี "ปลาปั่นจักรยาน" ประกอบด้วยโทเค็นอักขระ 9 ตัว (โปรดทราบว่าช่องว่างจะนับเป็นหนึ่งในโทเค็น)
- วลีย่อย ซึ่งคำเดียวอาจเป็นโทเค็นเดียวหรือหลายโทเค็นก็ได้ คำย่อยประกอบด้วยคำหลัก คำนำหน้า หรือคำต่อท้าย ตัวอย่างเช่น โมเดลภาษาที่ใช้คำย่อยเป็นโทเค็นอาจมองว่าคำว่า "dogs" เป็นโทเค็น 2 รายการ (คำราก "dog" และส่วนต่อท้าย "s" ที่แสดงพหูพจน์) โมเดลภาษาเดียวกันนี้อาจมองว่าคําเดียวอย่าง "สูงกว่า" เป็นคําย่อย 2 คํา (คําหลัก "สูง" และส่วนต่อท้าย "กว่า")
ในโดเมนนอกโมเดลภาษา โทเค็นอาจแสดงหน่วยพื้นฐานประเภทอื่นๆ เช่น ในคอมพิวเตอร์วิทัศน์ โทเค็นอาจเป็นชุดย่อยของรูปภาพ
ดูข้อมูลเพิ่มเติมได้ที่โมเดลภาษาขนาดใหญ่ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
ความแม่นยำของ Top-K
เปอร์เซ็นต์ของเวลาที่ "ป้ายกํากับเป้าหมาย" ปรากฏในตําแหน่ง k แรกๆ ของรายการที่สร้างขึ้น รายการอาจเป็นคําแนะนําที่ปรับเปลี่ยนในแบบของคุณ หรือรายการสินค้าที่จัดเรียงตาม softmax
ความแม่นยำของ Top-k เรียกอีกอย่างว่าความแม่นยำที่ k
ความเชื่อผิดๆ
ระดับที่เนื้อหาเป็นการละเมิด ข่มขู่ หรือทำให้เกิดความไม่พอใจ โมเดลแมชชีนเลิร์นนิงจำนวนมากสามารถระบุและวัดระดับความเป็นพิษได้ โมเดลส่วนใหญ่เหล่านี้จะระบุความเป็นพิษตามพารามิเตอร์หลายรายการ เช่น ระดับภาษาที่ไม่เหมาะสมและระดับภาษาที่เป็นภัย
Transformer
สถาปัตยกรรมโครงข่ายประสาทที่พัฒนาขึ้นโดย Google ซึ่งอาศัยกลไกการใส่ใจตนเองเพื่อเปลี่ยนลำดับของข้อมูลเชิงลึกอินพุตให้เป็นลำดับของข้อมูลเชิงลึกเอาต์พุตโดยไม่ต้องใช้การกรองข้อมูลหรือโครงข่ายประสาทแบบซ้ำ Transformer เปรียบเสมือนกองเลเยอร์ Self-Attention
Transformer อาจมีสิ่งต่อไปนี้
- โปรแกรมเปลี่ยนไฟล์
- โปรแกรมถอดรหัส
- ทั้งโปรแกรมเปลี่ยนไฟล์และโปรแกรมถอดรหัส
โปรแกรมเปลี่ยนไฟล์จะเปลี่ยนลําดับขององค์ประกอบเป็นลําดับใหม่ที่มีความยาวเท่ากัน ตัวเข้ารหัสประกอบด้วยเลเยอร์ N เลเยอร์ซึ่งเหมือนกัน โดยแต่ละเลเยอร์จะมีเลเยอร์ย่อย 2 เลเยอร์ ระบบจะใช้เลเยอร์ย่อย 2 เลเยอร์นี้ในแต่ละตําแหน่งของลําดับการฝังอินพุต ซึ่งจะเปลี่ยนองค์ประกอบแต่ละรายการของลําดับเป็นการฝังใหม่ เลเยอร์ย่อยของตัวเข้ารหัสแรกจะรวบรวมข้อมูลจากลำดับอินพุตต่างๆ เลเยอร์ย่อยของโปรแกรมเปลี่ยนไฟล์ที่ 2 จะเปลี่ยนข้อมูลที่รวบรวมไว้เป็นการฝังเอาต์พุต
ตัวถอดรหัสจะเปลี่ยนรูปแบบของลําดับการฝังข้อมูลอินพุตเป็นลําดับการฝังข้อมูลเอาต์พุต ซึ่งอาจมีความยาวต่างกัน ตัวถอดรหัสยังมีเลเยอร์ที่เหมือนกัน N ชั้นที่มีเลเยอร์ย่อย 3 ชั้น โดย 2 ชั้นนั้นคล้ายกับเลเยอร์ย่อยของตัวเข้ารหัส เลเยอร์ย่อยตัวถอดรหัสที่ 3 จะนำเอาเอาต์พุตของตัวเข้ารหัสไปใช้กับกลไกการใส่ใจตนเองเพื่อรวบรวมข้อมูลจากเอาต์พุตดังกล่าว
บล็อกโพสต์เรื่อง Transformer: สถาปัตยกรรมโครงข่ายระบบประสาทเทียมรูปแบบใหม่สำหรับการทําความเข้าใจภาษาเป็นข้อมูลเบื้องต้นที่ดีมากเกี่ยวกับ Transformer
ดูข้อมูลเพิ่มเติมได้ที่LLM: โมเดลภาษาขนาดใหญ่คืออะไรในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
3-gram
N-gram โดยที่ N=3
U
ทิศทางเดียว
ระบบที่ประเมินเฉพาะข้อความที่อยู่ก่อนส่วนข้อความเป้าหมาย ในทางตรงกันข้าม ระบบแบบ 2 ทิศทางจะประเมินทั้งข้อความที่อยู่ก่อนและอยู่หลังส่วนของข้อความเป้าหมาย ดูรายละเอียดเพิ่มเติมที่แบบ 2 ทิศทาง
โมเดลภาษาแบบทิศทางเดียว
โมเดลภาษาที่อิงความน่าจะเป็นตามโทเค็นที่ปรากฏก่อนโทเค็นเป้าหมายเท่านั้น ไม่ใช่หลัง ตรงข้ามกับโมเดลภาษาแบบ 2 ทิศทาง
V
ตัวแปรอัตโนมัติ (VAE)
Autoencoder ประเภทหนึ่งที่ใช้ประโยชน์จากความคลาดเคลื่อนระหว่างอินพุตและเอาต์พุตเพื่อสร้างอินพุตเวอร์ชันที่แก้ไขแล้ว ตัวแปร Autoencoder มีประโยชน์สําหรับ Generative AI
VAEs อิงตามการอนุมานแบบผันแปร ซึ่งเป็นเทคนิคในการประมาณพารามิเตอร์ของโมเดลความน่าจะเป็น
W
Word Embedding
การนำเสนอคําแต่ละคำในชุดคําภายในเวกเตอร์การฝัง กล่าวคือ การนำเสนอคําแต่ละคําเป็นเวกเตอร์ของค่าทศนิยมระหว่าง 0.0 ถึง 1.0 คําที่มีความหมายคล้ายกันจะมีการแสดงผลที่คล้ายกันมากกว่าคําที่มีความหมายต่างกัน ตัวอย่างเช่น แครอท ขึ้นฉ่าย และแตงกวาล้วนมีการแสดงผลที่คล้ายกัน ซึ่งจะแตกต่างจากการแสดงผลของเครื่องบิน แว่นกันแดด และยาสีฟัน
Z
การแจ้งเตือนแบบไม่แสดงตัวอย่าง
พรอมต์ที่ไม่ได้แสดงตัวอย่างวิธีที่คุณต้องการให้โมเดลภาษาขนาดใหญ่ตอบกลับ เช่น
| ส่วนต่างๆ ของพรอมต์ 1 รายการ | หมายเหตุ |
|---|---|
| สกุลเงินทางการของประเทศที่ระบุคืออะไร | คำถามที่คุณต้องการให้ LLM ตอบ |
| อินเดีย: | คําค้นหาจริง |
โมเดลภาษาขนาดใหญ่อาจตอบกลับด้วยสิ่งต่อไปนี้
- รูปี
- INR
- ₹
- รูปีอินเดีย
- รูปี
- รูปีอินเดีย
คำตอบทั้งหมดถูกต้อง แต่คุณอาจต้องการรูปแบบที่เฉพาะเจาะจง
เปรียบเทียบพรอมต์แบบไม่ใช้ตัวอย่างกับคำศัพท์ต่อไปนี้