Ce glossaire définit les termes liés à l'intelligence artificielle.
A
ablation
Technique permettant d'évaluer l'importance d'une caractéristique ou d'un composant en le supprimant temporairement d'un modèle. Vous réentraînez ensuite le modèle sans cette caractéristique ni ce composant. Si le modèle réentraîné est nettement moins performant, cela signifie que la caractéristique ou le composant supprimé était probablement important.
Par exemple, supposons que vous entraîniez un modèle de classification sur 10 caractéristiques et que vous obteniez une précision de 88 % sur l'ensemble de test. Pour vérifier l'importance de la première caractéristique, vous pouvez réentraîner le modèle en utilisant uniquement les neuf autres caractéristiques. Si le modèle réentraîné est beaucoup moins performant (par exemple, avec une précision de 55 %), cela signifie que la caractéristique supprimée était probablement importante. À l'inverse, si le modèle réentraîné est tout aussi performant, cela signifie que cette caractéristique n'était probablement pas si importante.
L'ablation peut également aider à déterminer l'importance des éléments suivants :
- Composants plus volumineux, tels qu'un sous-système entier d'un système de ML plus vaste
- Processus ou techniques, comme une étape de prétraitement des données
Dans les deux cas, vous observerez comment les performances du système évoluent (ou non) après la suppression du composant.
Tests A/B
Il s'agit d'une méthode statistique permettant de comparer deux techniques (ou plus), A et B. En règle générale, A est une technique existante et B est une nouvelle technique. Les tests A/B permettent non seulement de déterminer quelle technique est la plus performante, mais aussi de savoir si la différence est statistiquement significative.
Les tests A/B comparent généralement une seule métrique sur deux techniques. Par exemple, comment se compare l'exactitude du modèle pour deux techniques ? Toutefois, les tests A/B peuvent également comparer un nombre fini de métriques.
chip d'accélération
Catégorie de composants matériels spécialisés conçus pour effectuer les calculs clés nécessaires aux algorithmes de deep learning.
Les puces d'accélération (ou simplement accélérateurs) peuvent augmenter considérablement la vitesse et l'efficacité des tâches d'entraînement et d'inférence par rapport à un CPU à usage général. Elles sont idéales pour l'entraînement des réseaux neuronaux et les tâches similaires nécessitant beaucoup de calculs.
Voici quelques exemples de puces d'accélération :
- Les Tensor Processing Units (TPU) de Google avec matériel dédié au deep learning.
- Les GPU de NVIDIA, bien qu'initialement conçus pour le traitement graphique, sont conçus pour permettre le traitement parallèle, ce qui peut augmenter considérablement la vitesse de traitement.
accuracy
Nombre de prédictions de classification correctes divisé par le nombre total de prédictions. Par exemple :
Par exemple, un modèle qui a fait 40 prédictions correctes et 10 prédictions incorrectes aurait une précision de :
La classification binaire fournit des noms spécifiques pour les différentes catégories de prédictions correctes et de prédictions incorrectes. La formule de précision pour la classification binaire est la suivante :
où :
- VP correspond au nombre de vrais positifs (prédictions correctes).
- TN correspond au nombre de vrais négatifs (prédictions correctes).
- FP correspond au nombre de faux positifs (prédictions incorrectes).
- FN correspond au nombre de faux négatifs (prédictions incorrectes).
Comparer et opposer la justesse à la précision et au rappel.
Pour en savoir plus, consultez Classification : précision, rappel, exactitude et métriques associées dans le Cours d'initiation au Machine Learning.
agir
Étape de la boucle agentique au cours de laquelle l'agent exécute l'action choisie lors de l'étape Raison. Par exemple, l'étape "Act" (Agir) peut envoyer une requête API.
action
Dans l'apprentissage par renforcement, le mécanisme par lequel l'agent passe d'un état de l'environnement à un autre. L'agent choisit l'action à l'aide d'une stratégie.
espace d'action
Ensemble de ressources qu'un agent peut utiliser pour effectuer une tâche. L'espace d'action peut inclure les outils et les API que l'agent peut appeler, ainsi que les autorisations dont il dispose. En général, l'espace d'action doit être juste assez grand pour que l'agent puisse effectuer la tâche. Si l'espace d'action est trop petit, l'agent peut manquer de ressources pour effectuer la tâche. Si l'espace d'action est trop grand, l'agent a tendance à commettre plus d'erreurs.
fonction d'activation
Fonction qui permet aux réseaux de neurones d'apprendre les relations non linéaires (complexes) entre les caractéristiques et le libellé.
Voici quelques fonctions d'activation courantes :
Les graphiques des fonctions d'activation ne sont jamais des lignes droites. Par exemple, le graphique de la fonction d'activation ReLU se compose de deux lignes droites :

Voici à quoi ressemble un graphique de la fonction d'activation sigmoïde :

Cliquez sur l'icône pour voir un exemple.
Dans un réseau de neurones, les fonctions d'activation manipulent la somme pondérée de toutes les entrées d'un neurone. Pour calculer une somme pondérée, le neurone additionne les produits des valeurs et des pondérations concernées. Par exemple, supposons que l'entrée pertinente d'un neurone se compose des éléments suivants :
| valeur d'entrée | poids d'entrée |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
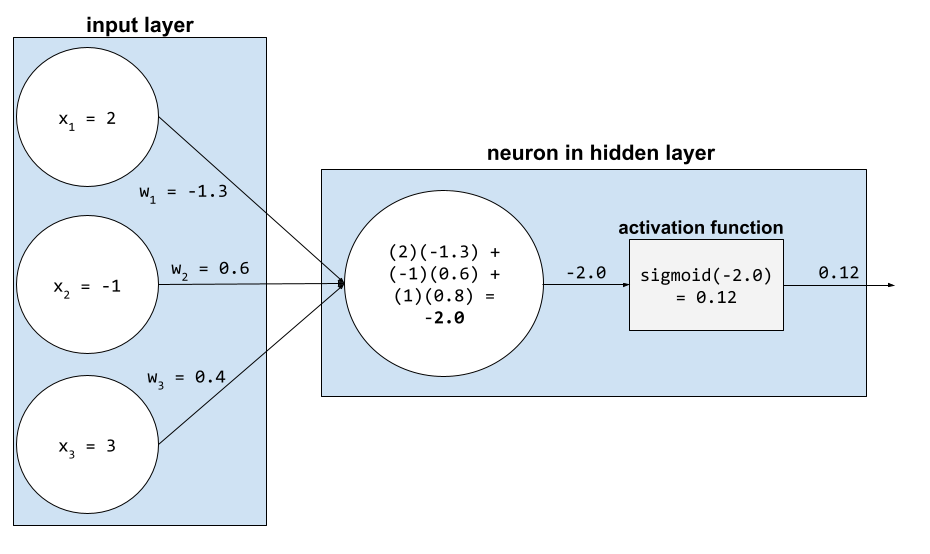
Pour en savoir plus, consultez Réseaux de neurones : fonctions d'activation dans le Cours d'initiation au Machine Learning.
apprentissage actif
Méthode d'entraînement dans laquelle l'algorithme sélectionne une partie des données qui servent à son apprentissage. L'apprentissage actif est particulièrement utile lorsque les exemples étiquetés sont peu nombreux ou coûteux. Au lieu de rechercher sans distinction une gamme variée d'exemples étiquetés, un algorithme d'apprentissage actif recherche sélectivement la gamme spécifique des exemples qui serviront à son apprentissage.
AdaGrad
Algorithme complexe de descente de gradient qui redimensionne les gradients de chaque paramètre en attribuant à chacun des paramètres un taux d'apprentissage indépendant. Pour une explication complète, consultez Adaptive Subgradient Methods for Online Learning and Stochastic Optimization.
adaptation
Synonyme d'optimisation ou d'affinage.
agent
Logiciel capable de raisonner sur les entrées utilisateur afin de planifier et d'exécuter des actions pour le compte de l'utilisateur.
Dans l'apprentissage par renforcement, un agent est l'entité qui utilise une stratégie pour maximiser le rendement attendu obtenu en passant d'un état à un autre de l'environnement.
mouton
Forme adjective de agent. Le terme "agentif" fait référence aux qualités que possèdent les agents (comme l'autonomie).
boucle agentique
Cycle qu'un agent parcourt jusqu'à ce qu'une condition de fin soit remplie. Le cycle se compose généralement des quatre étapes suivantes :
workflow agentif
Processus dynamique dans lequel un agent planifie et exécute de manière autonome des actions pour atteindre un objectif. Ce processus peut impliquer un raisonnement, l'appel d'outils externes et l'autocorrection de son plan.
orchestration des agents
La gestion et le routage centralisés des tâches sur plusieurs sous-agents ou appels LLM. L'orchestration d'agents décompose les tâches complexes en sous-tâches plus petites et les attribue aux sous-agents les plus compétents.
clustering agglomératif
Voir clustering hiérarchique.
Slop IA
Résultat d'un système d'IA générative qui privilégie la quantité à la qualité. Par exemple, une page Web contenant de la bouillie d'IA est remplie de contenus de mauvaise qualité, générés par IA et produits à bas prix.
détection d'anomalies
Processus d'identification des valeurs aberrantes. Par exemple, si la moyenne d'une caractéristique donnée est de 100 avec un écart-type de 10, la détection des anomalies doit signaler une valeur de 200 comme suspecte.
AR
Abréviation de réalité augmentée.
aire sous la courbe de précision/rappel
Consultez AUC PR (aire sous la courbe de précision/rappel).
aire sous la courbe ROC
Consultez AUC (aire sous la courbe ROC).
intelligence artificielle générale
Mécanisme non humain qui fait preuve d'un large éventail de capacités de résolution de problèmes, de créativité et d'adaptabilité. Par exemple, un programme démontrant une intelligence générale artificielle pourrait traduire du texte, composer des symphonies et exceller à des jeux qui n'ont pas encore été inventés.
intelligence artificielle
Un programme ou un modèle non humain capable de résoudre des tâches complexes. Par exemple, un programme ou un modèle qui traduit du texte ou un programme ou un modèle qui identifie des maladies à partir d'images radiologiques font tous deux preuve d'intelligence artificielle.
Formellement, le machine learning est un sous-domaine de l'intelligence artificielle. Toutefois, ces dernières années, certaines organisations ont commencé à utiliser les termes intelligence artificielle et machine learning de manière interchangeable.
"Attention",
Mécanisme utilisé dans un réseau de neurones qui indique l'importance d'un mot ou d'une partie de mot spécifique. L'attention compresse la quantité d'informations dont un modèle a besoin pour prédire le jeton/mot suivant. Un mécanisme d'attention typique peut se composer d'une somme pondérée sur un ensemble d'entrées, où le poids de chaque entrée est calculé par une autre partie du réseau de neurones.
Consultez également Auto-attention et Auto-attention multi-têtes, qui sont les blocs de construction des Transformers.
Pour en savoir plus sur l'auto-attention, consultez LLM : qu'est-ce qu'un grand modèle de langage ? dans le cours d'initiation au Machine Learning.
attribut
Synonyme de caractéristique.
Dans le domaine de l'équité en machine learning, les attributs font souvent référence à des caractéristiques propres aux individus.
échantillonnage d'attributs
Tactique d'entraînement d'une forêt de décision dans laquelle chaque arbre de décision ne tient compte que d'un sous-ensemble aléatoire de caractéristiques lors de l'apprentissage de la condition. En général, un sous-ensemble différent de caractéristiques est échantillonné pour chaque nœud. En revanche, lorsque vous entraînez un arbre de décision sans échantillonnage d'attributs, toutes les caractéristiques possibles sont prises en compte pour chaque nœud.
AUC (aire sous la courbe ROC)
Nombre compris entre 0,0 et 1,0 représentant la capacité d'un modèle de classification binaire à séparer les classes positives des classes négatives. Plus l'AUC est proche de 1,0, plus le modèle est performant pour séparer les classes les unes des autres.
Par exemple, l'illustration suivante montre un modèle de classification qui sépare parfaitement les classes positives (ovales verts) des classes négatives (rectangles violets). Ce modèle parfait et irréaliste a une AUC de 1,0 :

À l'inverse, l'illustration suivante montre les résultats d'un modèle de classification qui a généré des résultats aléatoires. Ce modèle a une AUC de 0,5 :

Oui, le modèle précédent a une AUC de 0,5, et non de 0.
La plupart des modèles se situent entre ces deux extrêmes. Par exemple, le modèle suivant sépare plus ou moins les positifs des négatifs et présente donc une AUC comprise entre 0,5 et 1,0 :

L'AUC ignore toute valeur que vous définissez pour le seuil de classification. En revanche, l'AUC prend en compte tous les seuils de classification possibles.
Cliquez sur l'icône pour en savoir plus sur la relation entre les courbes AUC et ROC.
L'AUC représente l'aire sous une courbe ROC. Par exemple, la courbe ROC d'un modèle qui sépare parfaitement les positifs des négatifs se présente comme suit :
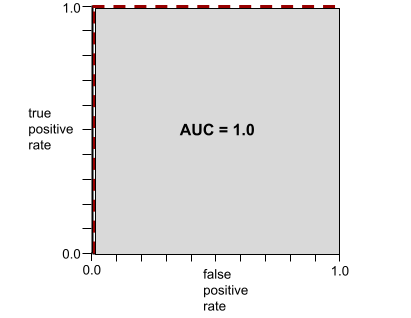
L'AUC correspond à la zone grise de l'illustration précédente. Dans ce cas inhabituel, la zone correspond simplement à la longueur de la région grise (1,0) multipliée par sa largeur (1,0). Ainsi, le produit de 1,0 et 1,0 donne une AUC de exactement 1,0, qui est le score AUC le plus élevé possible.
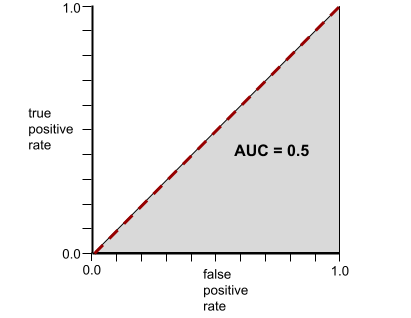
À l'inverse, la courbe ROC d'un modèle de classification qui ne peut pas du tout séparer les classes est la suivante. L'aire de cette région grise est de 0,5.
Une courbe ROC plus typique ressemble approximativement à ce qui suit :
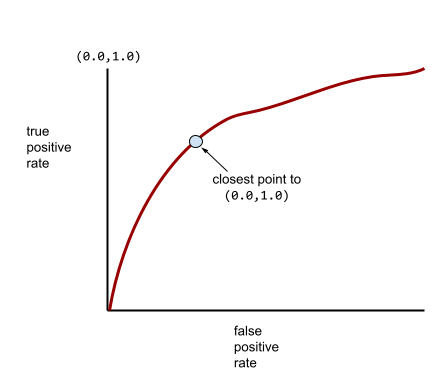
Il serait fastidieux de calculer manuellement l'aire sous cette courbe. C'est pourquoi un programme calcule généralement la plupart des valeurs AUC.
Pour en savoir plus, consultez Classification : ROC et AUC dans le Cours d'initiation au machine learning.
réalité augmentée
Technologie qui superpose une image générée par ordinateur à la vue de l'utilisateur sur le monde réel, fournissant ainsi une vue composite.
auto-encodeur
Système qui apprend à extraire les informations les plus importantes de l'entrée. Les auto-encodeurs sont une combinaison d'un encodeur et d'un décodeur. Les auto-encodeurs reposent sur le processus en deux étapes suivant :
- L'encodeur mappe l'entrée dans un format (intermédiaire) de dimension inférieure (généralement avec perte).
- Le décodeur crée une version avec perte de l'entrée d'origine en mappant le format de dimension inférieure au format d'entrée de dimension supérieure d'origine.
Les auto-encodeurs sont entraînés de bout en bout en demandant au décodeur de reconstruire le plus fidèlement possible l'entrée d'origine à partir du format intermédiaire de l'encodeur. Comme le format intermédiaire est plus petit (de dimension inférieure) que le format d'origine, l'auto-encodeur est obligé d'apprendre quelles informations de l'entrée sont essentielles. La sortie ne sera donc pas parfaitement identique à l'entrée.
Exemple :
- Si les données d'entrée sont un graphique, la copie non exacte sera semblable au graphique d'origine, mais légèrement modifiée. Il se peut que la copie non exacte supprime le bruit de l'image d'origine ou remplisse certains pixels manquants.
- Si les données d'entrée sont du texte, un auto-encodeur génère un nouveau texte qui imite (mais n'est pas identique à) le texte d'origine.
Voir aussi Auto-encodeurs variationnels.
évaluation automatique
Utilisation d'un logiciel pour évaluer la qualité de la sortie d'un modèle.
Lorsque la sortie du modèle est relativement simple, un script ou un programme peut comparer la sortie du modèle à une réponse de référence. Ce type d'évaluation automatique est parfois appelé évaluation programmatique. Les métriques telles que ROUGE ou BLEU sont souvent utiles pour l'évaluation programmatique.
Lorsque la sortie du modèle est complexe ou qu'il n'y a pas de bonne réponse, un programme de ML distinct appelé évaluateur automatique effectue parfois l'évaluation automatique.
À comparer à l'évaluation humaine.
biais d'automatisation
Lorsqu'un décisionnaire humain donne priorité aux recommandations d'un système automatisé de prise de décision par rapport aux informations ne provenant pas d'un processus d'automatisation, même en cas d'erreur du système automatisé.
Pour en savoir plus, consultez Équité : types de biais dans le cours d'initiation au machine learning.
AutoML
Tout processus automatisé permettant de créer des modèles de machine learning. AutoML peut effectuer automatiquement des tâches telles que les suivantes :
- Recherchez le modèle le plus approprié.
- Réglez les hyperparamètres.
- Préparer les données (y compris l'ingénierie des caractéristiques).
- Déployez le modèle obtenu.
AutoML est utile aux data scientists, car il leur permet de gagner du temps et de l'énergie lors du développement de pipelines de machine learning, et d'améliorer la précision des prédictions. Il est également utile aux non-experts, car il leur permet d'accéder plus facilement à des tâches complexes de machine learning.
Pour en savoir plus, consultez Automated Machine Learning (AutoML) dans le Cours d'initiation au Machine Learning.
agent autonome
Un agent qui s'efforce d'atteindre un objectif complexe en planifiant, en agissant et en s'adaptant sans intervention humaine continue.
Évaluation de l'outil d'évaluation automatique
Mécanisme hybride permettant de juger de la qualité de la sortie d'un modèle d'IA générative, qui combine l'évaluation humaine et l'évaluation automatique. Un évaluateur automatique est un modèle de ML entraîné sur des données créées par l'évaluation humaine. Idéalement, un évaluateur automatique apprend à imiter un évaluateur humain.Des évaluateurs automatiques prédéfinis sont disponibles, mais les meilleurs sont affinés spécifiquement pour la tâche que vous évaluez.
modèle autorégressif
Un modèle qui déduit une prédiction à partir de ses propres prédictions précédentes. Par exemple, les modèles de langage autorégressifs prédisent le prochain jeton en fonction des jetons prédits précédemment. Tous les grands modèles de langage basés sur Transformer sont autorégressifs.
En revanche, les modèles d'images basés sur les GAN ne sont généralement pas autorégressifs, car ils génèrent une image en une seule passe avant, et non de manière itérative par étapes. Cependant, certains modèles de génération d'images sont autorégressifs, car ils génèrent une image par étapes.
perte auxiliaire
Une fonction de perte (utilisée conjointement avec la fonction de perte principale d'un modèle de réseau de neurones) qui permet d'accélérer l'entraînement lors des premières itérations lorsque les pondérations sont initialisées de manière aléatoire.
Les fonctions de perte auxiliaires transmettent des gradients efficaces aux couches précédentes. Cela facilite la convergence pendant l'entraînement en luttant contre le problème de disparition du gradient.
précision moyenne à k
Métrique permettant de résumer les performances d'un modèle sur une seule invite qui génère des résultats classés, comme une liste numérotée de recommandations de livres. La précision moyenne à k correspond à la moyenne des valeurs de précision à k pour chaque résultat pertinent. La formule de la précision moyenne à k est donc la suivante :
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
où :
- \(n\) correspond au nombre d'éléments pertinents dans la liste.
À comparer au rappel à k.
condition alignée sur un axe
Dans un arbre de décision, une condition
qui n'implique qu'une seule caractéristique. Par exemple, si area est une caractéristique, la condition suivante est alignée sur un axe :
area > 200
À comparer à la condition oblique.
B
rétropropagation
Algorithme qui implémente la descente de gradient dans les réseaux de neurones.
L'entraînement d'un réseau de neurones implique de nombreuses itérations du cycle à deux passes suivant :
- Lors de la propagation directe, le système traite un lot d'exemples pour générer une ou plusieurs prédictions. Le système compare chaque prédiction à chaque valeur de libellé. La différence entre la prédiction et la valeur de l'étiquette correspond à la perte pour cet exemple. Le système agrège les pertes de tous les exemples pour calculer la perte totale du lot actuel.
- Lors de la propagation à rebours (rétropropagation), le système réduit la perte en ajustant les pondérations de tous les neurones dans toutes les couches cachées.
Les réseaux de neurones contiennent souvent de nombreux neurones répartis sur plusieurs couches cachées. Chacun de ces neurones contribue à la perte globale de différentes manières. La rétropropagation détermine s'il faut augmenter ou diminuer les pondérations appliquées à certains neurones.
Le taux d'apprentissage est un multiplicateur qui contrôle le degré d'augmentation ou de diminution de chaque poids à chaque passe arrière. Un taux d'apprentissage élevé augmentera ou diminuera chaque poids plus qu'un taux d'apprentissage faible.
En termes de calcul, la rétropropagation implémente la règle de la chaîne du calcul. Autrement dit, la rétropropagation calcule la dérivée partielle de l'erreur par rapport à chaque paramètre.
Il y a quelques années, les praticiens du ML devaient écrire du code pour implémenter la rétropropagation. Les API de ML modernes comme Keras implémentent désormais la rétropropagation pour vous. Ouf !
Pour en savoir plus, consultez la section Réseaux de neurones du cours d'initiation au machine learning.
bagging
Méthode d'entraînement d'un ensemble où chaque modèle constitutif s'entraîne sur un sous-ensemble aléatoire d'exemples d'entraînement échantillonnés avec remplacement. Par exemple, une forêt aléatoire est une collection d'arbres de décision entraînés avec le bagging.
Le terme bagging est l'abréviation de bootstrap aggregating.
Pour en savoir plus, consultez Forêts aléatoires dans le cours "Forêts de décision".
sac de mots
Représentation des mots d'une expression ou d'un extrait, quel que soit leur ordre. Par exemple, un sac de mots représente les trois phrases suivantes à l'identique :
- the dog jumps
- jumps the dog
- dog jumps the
Chaque mot est mappé à l'index correspondant d'un vecteur creux, où le vecteur a un index pour chaque mot du vocabulaire. Par exemple, la phrase the dog jumps est mappée dans un vecteur de caractéristiques dont les trois indices correspondant aux mots the, dog et jumps auront des valeurs non nulles. La valeur non nulle peut être l'une des suivantes :
- 1 pour indiquer la présence d'un mot.
- Le nombre d'apparition d'un mot dans le sac. Par exemple, si l'expression est the maroon dog is a dog with maroon fur, les mots maroon et dog seront représentés par la valeur 2, tandis que les autres mots seront représentés par la valeur 1.
- Une autre valeur, telle que le logarithme du nombre d'apparition d'un mot dans le sac.
Valeur de référence
Modèle utilisé comme point de référence pour comparer les performances d'un autre modèle (généralement plus complexe). Par exemple, un modèle de régression logistique peut servir de bonne référence pour un modèle profond.
Pour un problème donné, la référence aide les développeurs de modèles à quantifier les performances minimales attendues qu'un nouveau modèle doit atteindre pour être utile.
modèle de base
Un modèle pré-entraîné qui peut servir de point de départ pour l'affinage afin de répondre à des tâches ou applications spécifiques.
Voir aussi modèle pré-entraîné et modèle de fondation.
lot
Ensemble d'exemples utilisés dans une itération d'entraînement. La taille de lot détermine le nombre d'exemples dans un lot.
Pour comprendre le lien entre un lot et une époque, consultez époque.
Pour en savoir plus, consultez Régression linéaire : hyperparamètres dans le Cours d'initiation au Machine Learning.
inférence par lot
Processus d'inférence des prédictions sur plusieurs exemples non libellés divisés en sous-ensembles plus petits ("lots").
L'inférence par lot peut tirer parti des fonctionnalités de parallélisation des puces d'accélération. Autrement dit, plusieurs accélérateurs peuvent simultanément inférer des prédictions sur différents lots d'exemples non libellés, ce qui augmente considérablement le nombre d'inférences par seconde.
Pour en savoir plus, consultez Systèmes de ML de production : inférence statique ou dynamique dans le Cours d'initiation au machine learning.
normalisation par lots
Normaliser l'entrée ou la sortie des fonctions d'activation dans une couche cachée. La normalisation des lots peut offrir les avantages suivants :
- Renforcer la stabilité des réseaux de neurones en les protégeant contre les pondérations aberrantes.
- Améliorer les taux d'apprentissage, ce qui peut accélérer l'entraînement.
- Réduisez le surapprentissage.
taille du lot
Nombre d'exemples dans un lot. Par exemple, si la taille de lot est de 100, le modèle traite 100 exemples par itération.
Voici quelques stratégies de taille de lot populaires :
- Descente de gradient stochastique (SGD), dans laquelle la taille du lot est de 1.
- Lot complet : la taille du lot correspond au nombre d'exemples dans l'ensemble d'entraînement. Par exemple, si l'ensemble d'entraînement contient un million d'exemples, la taille du lot sera d'un million d'exemples. Le traitement par lot complet est généralement une stratégie inefficace.
- Mini-lot, dont la taille est généralement comprise entre 10 et 1 000. Le mini-lot est généralement la stratégie la plus efficace.
Pour en savoir plus, lisez les informations ci-après.
- Systèmes de production de ML : inférence statique ou dynamique dans le cours intensif sur le machine learning.
- Playbook sur l'optimisation du deep learning.
Réseau de neurones bayésien
Réseau de neurones probabiliste qui prend en compte les incertitudes liées aux pondérations et aux résultats. Un modèle de régression de réseau neuronal standard prédit généralement une valeur scalaire. Par exemple, un modèle standard prédit le prix d'une maison à 853 000. En revanche, un réseau de neurones bayésien prédit une distribution de valeurs. Par exemple, un modèle bayésien prédit le prix d'une maison à 853 000 avec un écart type de 67 200.
Un réseau de neurones bayésien s'appuie sur le théorème de Bayes pour calculer les incertitudes liées aux pondérations et aux prédictions. Un réseau de neurones bayésien peut être utile lorsqu'il est important de quantifier l'incertitude, comme dans les modèles liés aux produits pharmaceutiques. Les réseaux de neurones bayésiens peuvent également empêcher le surapprentissage.
Optimisation bayésienne
Une technique de modélisation de régression probabiliste pour optimiser les fonctions objectives coûteuses en termes de calcul en optimisant plutôt un substitut qui quantifie l'incertitude à l'aide d'une technique d'apprentissage bayésienne. Étant donné que l'optimisation bayésienne est elle-même très coûteuse, elle est généralement utilisée pour optimiser les tâches coûteuses à évaluer qui comportent un petit nombre de paramètres, comme la sélection des hyperparamètres.
Équation de Bellman
Dans l'apprentissage par renforcement, l'identité suivante est satisfaite par la fonction Q optimale :
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
Les algorithmes d'apprentissage par renforcement appliquent cette identité pour créer un apprentissage par renforcement à l'aide de la règle de mise à jour suivante :
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
Au-delà de l'apprentissage par renforcement, l'équation de Bellman s'applique à la programmation dynamique. Consultez l' article Wikipédia sur l'équation de Bellman.
BERT (Bidirectional Encoder Representations from Transformers)
Architecture de modèle pour la représentation de texte. Un modèle BERT entraîné peut faire partie d'un modèle plus vaste pour la classification de texte ou d'autres tâches de ML.
BERT présente les caractéristiques suivantes :
- Utilise l'architecture Transformer et repose donc sur l'auto-attention.
- Utilise la partie encodeur du Transformer. L'encodeur a pour tâche de produire de bonnes représentations textuelles, plutôt que d'effectuer une tâche spécifique comme la classification.
- Bidirectionnel
- Utilise le masquage pour l'entraînement non supervisé.
Voici quelques variantes de BERT :
Pour obtenir une présentation de BERT, consultez Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing.
biais (éthique/équité) (bias (ethics/fairness))
1. Stéréotypes, préjudice ou favoritisme envers certains groupes, choses ou personnes par rapport à d'autres. Ces biais peuvent avoir une incidence sur la collecte et l'interprétation des données, ainsi que sur la conception d'un système et la manière dont les utilisateurs interagissent avec celui-ci. Les formes de ce type de biais comprennent les éléments suivants :
- biais d'automatisation
- biais de confirmation
- effet expérimentateur
- biais de représentativité
- biais implicite
- biais d'appartenance
- biais d'homogénéité de l'exogroupe
2. Erreur systématique introduite par une procédure d'échantillonnage ou de rapport. Les formes de ce type de biais comprennent les éléments suivants :
- Biais de couverture
- biais de non-réponse
- biais de participation
- biais de fréquence
- biais d'échantillonnage
- biais de sélection
À ne pas confondre avec le biais des modèles de machine learning ou le biais de prédiction.
Pour en savoir plus, consultez Équité : types de biais dans le cours d'initiation au machine learning.
biais (mathématiques) ou terme de biais
Ordonnée à l'origine ou décalage par rapport à une origine. Le biais est un paramètre des modèles de machine learning, symbolisé par l'un des éléments suivants :
- b
- w0
Par exemple, b représente le biais dans la formule suivante :
Dans une ligne bidimensionnelle simple, le biais signifie simplement "ordonnée à l'origine". Par exemple, le biais de la ligne dans l'illustration suivante est de 2.
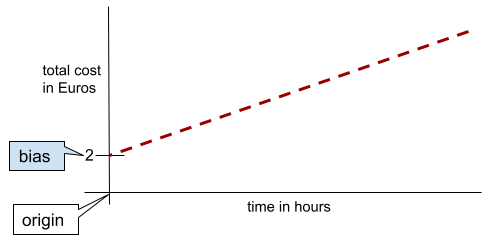
Le biais existe, car tous les modèles ne partent pas de l'origine (0,0). Par exemple, supposons qu'un parc d'attractions coûte 2 euros à l'entrée et 0,5 euro supplémentaire par heure passée par un client. Par conséquent, un modèle mappant le coût total présente un biais de 2, car le coût le plus bas est de 2 euros.
Le biais ne doit pas être confondu avec le biais en matière d'éthique et d'équité ni avec le biais de prédiction.
Pour en savoir plus, consultez Régression linéaire dans le cours d'initiation au machine learning.
bidirectionnel
Terme utilisé pour décrire un système qui évalue le texte qui précède et suit une section de texte cible. En revanche, un système unidirectionnel n'évalue que le texte qui précède une section de texte cible.
Par exemple, prenons l'exemple d'un modèle de langage masqué qui doit déterminer les probabilités du ou des mots représentant le soulignement dans la question suivante :
Qu'est-ce qui ne va pas chez toi ?
Un modèle de langage unidirectionnel devrait baser ses probabilités uniquement sur le contexte fourni par les mots "What", "is" et "the". En revanche, un modèle de langage bidirectionnel pourrait également obtenir du contexte à partir de "avec" et "vous", ce qui pourrait aider le modèle à générer de meilleures prédictions.
modèle de langage bidirectionnel
Un modèle de langage qui détermine la probabilité qu'un jeton donné soit présent à un emplacement donné dans un extrait de texte en fonction du texte précédent et suivant.
bigramme
Un N-gramme dans lequel N=2.
classification binaire
Type de tâche de classification qui prédit l'une des deux classes mutuellement exclusives :
Par exemple, les deux modèles de machine learning suivants effectuent chacun une classification binaire :
- Modèle qui détermine si les e-mails sont du spam (classe positive) ou non-spam (classe négative).
- Un modèle qui évalue les symptômes médicaux pour déterminer si une personne est atteinte d'une maladie spécifique (classe positive) ou non (classe négative).
À comparer à la classification à classes multiples.
Consultez également Régression logistique et Seuil de classification.
Pour en savoir plus, consultez la section Classification du cours d'initiation au machine learning.
condition binaire
Dans un arbre de décision, une condition qui n'a que deux résultats possibles, généralement oui ou non. Par exemple, la condition suivante est une condition binaire :
temperature >= 100
À comparer à la condition non binaire.
Pour en savoir plus, consultez Types de conditions dans le cours "Forêts de décision".
binning
Synonyme de binning.
modèle de boîte noire
Un modèle dont le "raisonnement" est impossible ou difficile à comprendre pour les humains. En d'autres termes, même si les humains peuvent voir comment les requêtes affectent les réponses, ils ne peuvent pas déterminer exactement comment un modèle de boîte noire détermine la réponse. En d'autres termes, un modèle en boîte noire manque d'interprétabilité.
La plupart des modèles profonds et des grands modèles de langage sont des boîtes noires.
BLEU (Bilingual Evaluation Understudy)
Métrique comprise entre 0 et 1 permettant d'évaluer les traductions automatiques, par exemple de l'espagnol vers le japonais.
Pour calculer un score, BLEU compare généralement la traduction d'un modèle de ML (texte généré) à la traduction d'un expert humain (texte de référence). Le score BLEU est déterminé par le degré de correspondance des n-grammes dans le texte généré et le texte de référence.
L'article d'origine sur cette métrique est BLEU: a Method for Automatic Evaluation of Machine Translation.
Voir aussi BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Métrique permettant d'évaluer les traductions automatiques d'une langue à une autre, en particulier vers et depuis l'anglais.
Pour les traductions vers et depuis l'anglais, BLEURT est plus proche des évaluations humaines que BLEU. Contrairement à BLEU, BLEURT met l'accent sur les similitudes sémantiques (de sens) et peut s'adapter à la reformulation.
BLEURT s'appuie sur un grand modèle de langage pré-entraîné (BERT, pour être précis), qui est ensuite affiné sur du texte provenant de traducteurs humains.
L'article d'origine sur cette métrique est BLEURT: Learning Robust Metrics for Text Generation.
Questions booléennes (BoolQ)
Ensemble de données permettant d'évaluer la capacité d'un LLM à répondre à des questions par "oui" ou "non". Chacun des défis de l'ensemble de données comporte trois éléments :
- Une requête
- Passage impliquant la réponse à la requête.
- La bonne réponse, qui est oui ou non.
Exemple :
- Requête : Y a-t-il des centrales nucléaires dans le Michigan ?
- Extrait : …trois centrales nucléaires fournissent environ 30 % de l'électricité du Michigan.
- Bonne réponse : Oui
Les chercheurs ont recueilli les questions à partir de requêtes de recherche Google anonymisées et agrégées, puis ont utilisé les pages Wikipédia pour ancrer les informations.
Pour en savoir plus, consultez BoolQ : Exploring the Surprising Difficulty of Natural Yes/No Questions.
BoolQ est un composant de l'ensemble SuperGLUE.
BoolQ
Abréviation de Boolean Questions (questions booléennes).
booster
Technique de machine learning qui combine de manière itérative un ensemble de modèles de classification simples et peu précis (appelés "classificateurs faibles") en un modèle de classification très précis (un "classificateur fort") en surpondérant les exemples que le modèle classifie actuellement de manière erronée.
Pour en savoir plus, consultez Arbres de décision avec boosting de gradient dans le cours "Forêts de décision".
cadre de délimitation
Dans une image, les coordonnées (x, y) d'un rectangle autour d'une zone d'intérêt, comme le chien dans l'image ci-dessous.

diffusion
Développer la forme d'un opérande d'une opération mathématique matricielle à des dimensions compatibles pour cette opération. Par exemple, en algèbre linéaire, il est nécessaire que les deux opérandes d'une opération d'addition matricielle aient les mêmes dimensions. Par conséquent, vous ne pouvez pas ajouter une matrice de forme (m, n) à un vecteur de longueur n. Le broadcasting permet d'effectuer cette opération en développant virtuellement le vecteur de longueur n en une matrice de forme (m, n) en répliquant les mêmes valeurs dans chaque colonne.
Voir la description suivante de broadcasting dans NumPy pour en savoir plus.
le binning
Conversion d'une seule caractéristique en plusieurs caractéristiques binaires appelées ensembles ou classes, généralement en fonction d'une plage de valeurs. La caractéristique tronquée est généralement une caractéristique continue.
Par exemple, au lieu de représenter la température comme une seule caractéristique à virgule flottante continue, vous pouvez découper les plages de températures en buckets distincts, tels que :
- La catégorie "froid" correspond à une température inférieure ou égale à 10 degrés Celsius.
- La tranche "tempérée" correspondrait à une température comprise entre 11 et 24 degrés Celsius.
- La tranche "chaud" correspond à une température supérieure ou égale à 25 degrés Celsius.
Le modèle traitera chaque valeur du même bucket de manière identique. Par exemple, les valeurs 13 et 22 se trouvent toutes les deux dans le bucket "tempéré". Le modèle les traite donc de manière identique.
Pour en savoir plus, consultez Données numériques : binning dans le cours d'initiation au machine learning.
C
couche de calibration
Ajustement réalisé après la prédiction, généralement pour prendre en compte le biais de prédiction. Les prédictions et les probabilités ajustées doivent correspondre à la distribution d'un ensemble observé d'étiquettes.
génération de candidats
Ensemble initial de recommandations sélectionné par un système de recommandation. Prenons l'exemple d'une librairie proposant 100 000 livres. La phase de génération de candidats crée une liste beaucoup plus restreinte de livres pertinents pour un utilisateur particulier, par exemple 500. Mais recommander 500 livres à un utilisateur reste beaucoup trop. Les phases ultérieures et plus coûteuses d'un système de recommandation (comme le scoring et le reclassement) réduisent cet ensemble de 500 recommandations afin de le rendre plus utile.
Pour en savoir plus, consultez la présentation de la génération de candidats dans le cours sur les systèmes de recommandation.
échantillonnage de candidats
Optimisation réalisée lors de l'entraînement, dans laquelle une probabilité est calculée pour toutes les étiquettes positives, en utilisant par exemple softmax, mais seulement pour un échantillon aléatoire d'étiquettes négatives. Par exemple, si un exemple est étiqueté beagle et chien, l'échantillonnage de candidats calcule les probabilités prédites et les termes de pertes correspondants pour :
- beagle
- chien
- un sous-ensemble aléatoire des classes négatives restantes (par exemple, chat, sucette, clôture).
L'idée est que les classes négatives peuvent apprendre à partir d'un renforcement négatif moins fréquent tant que les classes positives sont correctement renforcées positivement, ce qui est effectivement observé empiriquement.
L'échantillonnage de candidats est plus efficace en termes de calcul que les algorithmes d'entraînement qui calculent les prédictions pour toutes les classes négatives, en particulier lorsque le nombre de classes négatives est très élevé.
données catégorielles
Caractéristiques avec un ensemble spécifique de valeurs possibles. Par exemple, prenons une caractéristique catégorielle nommée traffic-light-state, qui ne peut avoir que l'une des trois valeurs possibles suivantes :
redyellowgreen
En représentant traffic-light-state comme une caractéristique catégorielle, un modèle peut apprendre les différents impacts de red, green et yellow sur le comportement du conducteur.
Les caractéristiques catégorielles sont parfois appelées caractéristiques discrètes.
À comparer aux données numériques.
Pour en savoir plus, consultez Utiliser des données catégorielles dans le Cours d'initiation au Machine Learning.
modèle de langage causal
Synonyme de modèle de langage unidirectionnel.
Consultez modèle de langage bidirectionnel pour comparer différentes approches directionnelles dans la modélisation du langage.
CB
Abréviation de CommitmentBank.
centroid
Centre d'un cluster déterminé par un algorithme k-moyennes ou k-médiane. Par exemple, si k est égal à 3, alors l'algorithme k-moyennes ou k-médiane trouve 3 centroïdes.
Pour en savoir plus, consultez Algorithmes de clustering dans le cours sur le clustering.
clustering basé sur centroïde
Catégorie d'algorithmes de clustering qui organisent les données en clusters non hiérarchiques. k-moyennes est l'algorithme de clustering basé sur centroïde le plus utilisé.
À comparer aux algorithmes de clustering hiérarchique.
Pour en savoir plus, consultez Algorithmes de clustering dans le cours sur le clustering.
prompting par chaîne de pensée
Technique de prompt engineering qui encourage un grand modèle de langage (LLM) à expliquer son raisonnement, étape par étape. Par exemple, examinez l'invite suivante, en prêtant une attention particulière à la deuxième phrase :
Combien de forces G un conducteur ressentirait-il dans une voiture qui passe de 0 à 100 km/h en 7 secondes ? Dans la réponse, indique tous les calculs pertinents.
La réponse du LLM serait probablement :
- Affiche une séquence de formules de physique, en insérant les valeurs 0, 60 et 7 aux endroits appropriés.
- Explique pourquoi il a choisi ces formules et ce que signifient les différentes variables.
Les requêtes en chaîne de pensée forcent le LLM à effectuer tous les calculs, ce qui peut conduire à une réponse plus correcte. De plus, l'incitation à la réflexion en chaîne permet à l'utilisateur d'examiner les étapes du LLM pour déterminer si la réponse est logique ou non.
Score F de N-grammes de caractères (ChrF)
Métrique permettant d'évaluer les modèles de traduction automatique. Le score F des n-grammes de caractères détermine le degré de chevauchement des n-grammes dans le texte de référence avec les n-grammes dans le texte généré d'un modèle de ML.
Le score F de n-grammes de caractères est semblable aux métriques des familles ROUGE et BLEU, sauf que :
- Le score F des n-grammes de caractères fonctionne sur les n-grammes de caractères.
- ROUGE et BLEU fonctionnent sur des N-grammes de mots ou des jetons.
chat
Contenu d'un dialogue avec un système de ML, généralement un grand modèle de langage. L'interaction précédente dans une discussion (ce que vous avez écrit et la réponse du grand modèle de langage) devient le contexte pour les parties suivantes de la discussion.
Un chatbot est une application d'un grand modèle de langage.
point de contrôle
Données qui capturent l'état des paramètres d'un modèle pendant l'entraînement ou une fois celui-ci terminé. Par exemple, pendant l'entraînement, vous pouvez :
- Arrêter l'entraînement, peut-être intentionnellement ou en raison de certaines erreurs.
- Capturez le point de contrôle.
- Rechargez ensuite le point de contrôle, éventuellement sur un autre matériel.
- Redémarrez l'entraînement.
Choix d'alternatives plausibles (COPA)
Ensemble de données permettant d'évaluer la capacité d'un LLM à identifier la meilleure réponse parmi deux alternatives à une prémisse. Chacun des défis de l'ensemble de données se compose de trois éléments :
- Une hypothèse, qui est généralement une affirmation suivie d'une question
- Deux réponses possibles à la question posée dans le postulat, dont l'une est correcte et l'autre incorrecte
- La bonne réponse
Exemple :
- Hypothèse : l'homme s'est cassé un orteil. Quelle est la CAUSE de ce problème ?
- Réponses possibles :
- Il a un trou dans sa chaussette.
- Il s'est fait tomber un marteau sur le pied.
- Bonne réponse : 2
COPA est un composant de l'ensemble SuperGLUE.
précision des citations
Métrique répondant à la question suivante :
Quel pourcentage des citations dans la réponse d'un LLM étaient réellement correctes et pertinentes ?
Autrement dit, quel pourcentage de citations contiennent les faits exacts ou les informations pertinentes nécessaires pour vérifier l'affirmation faite dans la réponse d'un LLM.
Par exemple, si une réponse de LLM cite 10 documents, mais que seulement 7 de ces citations sont correctes et pertinentes, la précision des citations sera de 0,7.
Rappel des citations
Métrique répondant à la question suivante :
Quel pourcentage des documents sources utilisés par le LLM pour composer sa réponse sont réellement cités dans la réponse ?
Par exemple, si un LLM s'est appuyé sur 20 documents pour composer sa réponse, mais que la réponse n'en cite que 11, le rappel de citation sera de 0,55.
classe
Catégorie à laquelle une étiquette peut appartenir. Exemple :
- Dans un modèle de classification binaire qui détecte le spam, les deux classes peuvent être spam et non-spam.
- Dans un modèle de classification à classes multiples qui identifie les races de chiens, les classes peuvent être caniche, beagle, carlin, etc.
Un modèle de classification prédit une classe. En revanche, un modèle de régression prédit un nombre plutôt qu'une classe.
Pour en savoir plus, consultez la section Classification du cours d'initiation au machine learning.
ensemble de données équilibré
Un ensemble de données contenant des étiquettes catégorielles dans lesquelles le nombre d'instances de chaque catégorie est approximativement égal. Prenons l'exemple d'un ensemble de données botaniques dont le libellé binaire peut être plante indigène ou plante non indigène :
- Un ensemble de données contenant 515 plantes indigènes et 485 plantes non indigènes est un ensemble de données équilibré.
- Un ensemble de données comportant 875 plantes indigènes et 125 plantes non indigènes est un ensemble de données avec déséquilibre des classes.
Il n'existe pas de limite formelle entre les ensembles de données équilibrés et les ensembles de données avec déséquilibre des classes. La distinction n'est importante que lorsqu'un modèle entraîné sur un ensemble de données très déséquilibré en termes de classes ne peut pas converger. Pour en savoir plus, consultez Ensembles de données : ensembles de données déséquilibrés dans le cours d'initiation au machine learning.
modèle de classification
Un modèle dont la prédiction est une classe. Par exemple, les éléments suivants sont tous des modèles de classification :
- Modèle qui prédit la langue d'une phrase saisie (français ? Espagnol ? Italien ?)
- Un modèle qui prédit les espèces d'arbres (érable ? Chêne ? Baobab ?).
- Modèle qui prédit la classe positive ou négative pour une affection médicale spécifique.
En revanche, les modèles de régression prédisent des nombres plutôt que des classes.
Voici deux types courants de modèles de classification :
seuil de classification
Dans une classification binaire, il s'agit d'un nombre compris entre 0 et 1 qui convertit la sortie brute d'un modèle de régression logistique en prédiction de la classe positive ou de la classe négative. Notez que le seuil de classification est une valeur choisie par un humain, et non par l'entraînement du modèle.
Un modèle de régression logistique génère une valeur brute comprise entre 0 et 1. Ensuite :
- Si cette valeur brute est supérieure au seuil de classification, la classe positive est prédite.
- Si cette valeur brute est inférieure au seuil de classification, la classe négative est prédite.
Par exemple, supposons que le seuil de classification soit de 0,8. Si la valeur brute est de 0,9, le modèle prédit la classe positive. Si la valeur brute est de 0,7, le modèle prédit la classe négative.
Le choix du seuil de classification a une forte incidence sur le nombre de faux positifs et de faux négatifs.
Pour en savoir plus, consultez Seuils et matrice de confusion dans le Cours d'initiation au machine learning.
classificateur
Terme informel désignant un modèle de classification.
ensemble de données avec déséquilibre des classes
Un ensemble de données pour une classification dans lequel le nombre total d'étiquettes de chaque classe diffère de manière significative. Prenons l'exemple d'un ensemble de données de classification binaire dont les deux libellés sont répartis comme suit :
- 1 000 000 de libellés à exclure
- 10 libellés positifs
Le ratio d'étiquettes négatives par rapport aux étiquettes positives est de 100 000 pour 1. Il s'agit donc d'un ensemble de données avec déséquilibre des classes.
En revanche, l'ensemble de données suivant est équilibré par classe, car le ratio de libellés négatifs par rapport aux libellés positifs est relativement proche de 1 :
- 517 libellés négatifs
- 483 libellés positifs
Les ensembles de données multiclasses peuvent également présenter un déséquilibre des classes. Par exemple, l'ensemble de données de classification multiclasse suivant est également déséquilibré, car un libellé comporte beaucoup plus d'exemples que les deux autres :
- 1 000 000 d'étiquettes avec la classe "vert"
- 200 étiquettes avec la classe "violet"
- 350 libellés avec la classe "orange"
L'entraînement d'ensembles de données avec déséquilibre des classes peut présenter des difficultés particulières. Pour en savoir plus, consultez Ensembles de données déséquilibrés dans le Cours d'initiation au Machine Learning.
Voir aussi entropie, classe majoritaire et classe minoritaire.
écrêtage
Technique de gestion des valeurs aberrantes en effectuant l'une des opérations suivantes ou les deux :
- Abaisser les valeurs de caractéristiques qui sont au-dessus d'un seuil maximal à ce seuil maximal.
- Augmenter les valeurs de caractéristiques qui sont en-dessous d'un certain seuil minimal à ce seuil minimal.
Supposons, par exemple, que moins de 0,5 % des valeurs d'une caractéristique donnée ne sont pas comprises entre 40 et 60. Dans ce cas, vous pouvez procéder comme suit :
- Borner toutes les valeurs supérieures à 60 (le seuil maximal) pour obtenir exactement 60.
- Borner toutes les valeurs inférieures à 40 (le seuil minimal) pour obtenir exactement 40.
Les valeurs aberrantes peuvent endommager les modèles et parfois entraîner un dépassement de capacité des pondérations pendant l'entraînement. Certaines valeurs aberrantes peuvent également nuire considérablement aux métriques telles que l'exactitude. Le clipping est une technique courante pour limiter les dégâts.
Le bornement du gradient force les valeurs de gradient dans une plage désignée pendant l'entraînement.
Pour en savoir plus, consultez Données numériques : normalisation dans le Cours d'initiation au machine learning.
Cloud TPU
Accélérateur matériel spécialisé conçu pour accélérer les charges de travail de machine learning sur Google Cloud.
clustering
Regrouper des exemples associés, en particulier lors de l'apprentissage non supervisé. Une fois tous les exemples groupés, une personne peut éventuellement attribuer un sens à chaque cluster.
Il existe de nombreux algorithmes de clustering. Par exemple, l'algorithme k-moyennes regroupe les exemples en clusters en fonction de leur proximité avec un centroïde, comme dans le diagramme suivant :

Un chercheur pourrait alors examiner les clusters et, par exemple, étiqueter le cluster 1 en tant qu'"arbres nains" et le cluster 2 en tant qu'"arbres de taille normale".
Autre exemple, celui d'un algorithme de clustering basé sur la distance entre un exemple et un point central, illustré comme suit :

Pour en savoir plus, consultez le cours sur le clustering.
coadaptation
Comportement indésirable dans lequel les neurones prédisent des schémas dans les données d'entraînement en s'appuyant presque exclusivement sur les sorties d'autres neurones spécifiques, au lieu de s'appuyer sur le comportement du réseau dans son ensemble. Lorsque les schémas à l'origine de la coadaptation ne sont pas présents dans les données de validation, la coadaptation entraîne alors un surapprentissage. La régularisation par abandon réduit l'occurrence de la coadaptation, car l'abandon empêche les neurones de ne s'appuyer que sur d'autres neurones spécifiques.
filtrage collaboratif
Prédictions sur les centres d'intérêt d'un utilisateur en fonction de ceux de nombreux autres utilisateurs. Le filtrage collaboratif est souvent utilisé dans les systèmes de recommandation.
Pour en savoir plus, consultez la section Filtrage collaboratif du cours sur les systèmes de recommandation.
CommitmentBank (CB)
Ensemble de données permettant d'évaluer la capacité d'un LLM à déterminer si l'auteur d'un passage croit en une clause cible dans ce passage. Chaque entrée de l'ensemble de données contient les éléments suivants :
- Un extrait
- Une clause cible dans ce passage
- Valeur booléenne indiquant si l'auteur du passage croit en la clause cible.
Exemple :
- Extrait : Quel plaisir d'entendre Artemis rire. Elle est tellement sérieuse. Je ne savais pas qu'elle avait de l'humour.
- Clause cible : elle avait le sens de l'humour
- Booléen : "True", ce qui signifie que l'auteur croit en la clause cible
CommitmentBank est un composant de l'ensemble SuperGLUE.
modèle compact
Tout petit modèle conçu pour s'exécuter sur de petits appareils disposant de ressources de calcul limitées. Par exemple, les modèles compacts peuvent s'exécuter sur des téléphones mobiles, des tablettes ou des systèmes embarqués.
calcul
(Nom) Ressources de calcul utilisées par un modèle ou un système, telles que la puissance de traitement, la mémoire et le stockage.
Consultez Puces d'accélération.
dérive conceptuelle
Un changement dans la relation entre les caractéristiques et l'étiquette. Au fil du temps, la dérive des concepts réduit la qualité d'un modèle.
Pendant l'entraînement, le modèle apprend la relation entre les caractéristiques et leurs étiquettes dans l'ensemble d'entraînement. Si les libellés de l'ensemble d'entraînement sont de bons substituts pour le monde réel, le modèle devrait faire de bonnes prédictions dans le monde réel. Toutefois, en raison de la dérive conceptuelle, les prédictions du modèle ont tendance à se dégrader au fil du temps.
Par exemple, prenons un modèle de classification binaire qui prédit si un certain modèle de voiture est "économe en carburant". Autrement dit, les caractéristiques peuvent être les suivantes :
- poids de la voiture
- compression du moteur
- type de transmission
lorsque le libellé est :
- économe en carburant
- ne pas être économe en carburant
Toutefois, le concept de "voiture économe en carburant" ne cesse d'évoluer. Un modèle de voiture étiqueté économe en carburant en 1994 serait presque certainement étiqueté non économe en carburant en 2024. Un modèle souffrant de dérive du concept a tendance à faire des prédictions de moins en moins utiles au fil du temps.
Comparer et différencier avec la non-stationnarité.
état
Dans un arbre de décision, tout nœud effectue un test. Par exemple, l'arbre de décision suivant contient deux conditions :
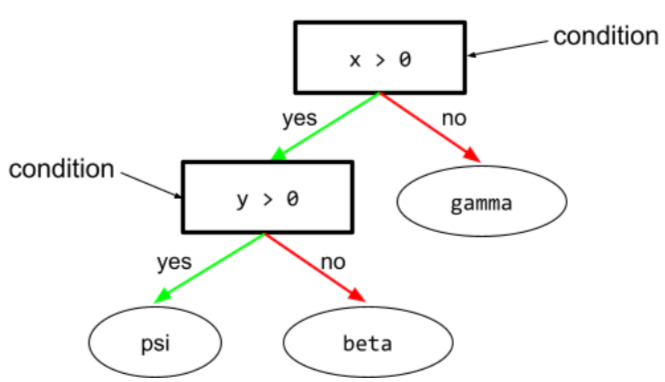
Une condition est également appelée "répartition" ou "test".
Condition de contraste avec leaf.
Voir également :
Pour en savoir plus, consultez Types de conditions dans le cours "Forêts de décision".
confabulation
Synonyme de hallucination.
La confabulation est probablement un terme plus précis techniquement que l'hallucination. Cependant, l'hallucination est devenue populaire en premier.
configuration
Processus d'attribution des valeurs de propriété initiales utilisées pour entraîner un modèle, y compris :
- les couches de composition du modèle.
- l'emplacement des données ;
- Hyperparamètres, tels que :
Dans les projets de machine learning, la configuration peut être effectuée à l'aide d'un fichier de configuration spécial ou de bibliothèques de configuration telles que les suivantes :
biais de confirmation
Tendance à rechercher, interpréter, favoriser et rappeler des informations d'une manière qui confirme ses propres croyances ou hypothèses préexistantes. Les développeurs en machine learning peuvent collecter ou étiqueter par inadvertance des données d'une telle manière que cela influence la production d'un résultat confortant leurs croyances existantes. Le biais de confirmation est une forme de biais implicite.
L'effet expérimentateur est une forme de biais de confirmation dans lequel un expérimentateur continue d'entraîner des modèles jusqu'à confirmation d'une hypothèse préexistante.
matrice de confusion
Table NxN qui résume le nombre de prédictions correctes et incorrectes effectuées par un modèle de classification. Prenons l'exemple de la matrice de confusion suivante pour un modèle de classification binaire :
| Tumeur (prédite) | Non tumoral (prédit) | |
|---|---|---|
| Tumeur (vérité terrain) | 18 (VP) | 1 (FN) |
| Non-Tumor (vérité terrain) | 6 (FP) | 452 (VN) |
La matrice de confusion précédente montre les éléments suivants :
- Sur les 19 prédictions où la vérité terrain était "Tumeur", le modèle en a classé 18 correctement et 1 incorrectement.
- Sur les 458 prédictions pour lesquelles la vérité terrain était "Non-Tumor", le modèle en a classé 452 correctement et 6 incorrectement.
La matrice de confusion pour un problème de classification multiclasse peut vous aider à identifier les schémas d'erreurs. Prenons l'exemple de la matrice de confusion suivante pour un modèle de classification multiclasse à trois classes qui catégorise trois types d'iris différents (Virginica, Versicolor et Setosa). Lorsque la vérité terrain était "Virginica", la matrice de confusion montre que le modèle était beaucoup plus susceptible de prédire à tort "Versicolor" que "Setosa" :
| Setosa (prédit) | Versicolor (prédit) | Virginica (prédit) | |
|---|---|---|---|
| Setosa (vérité terrain) | 88 | 12 | 0 |
| Versicolor (vérité terrain) | 6 | 141 | 7 |
| Virginica (vérité terrain) | 2 | 27 | 109 |
Par exemple, une matrice de confusion peut révéler qu'un modèle entraîné à reconnaître les chiffres écrits à la main tend à prédire de façon erronée 9 à la place de 4, ou 1 au lieu de 7.
Les matrices de confusion contiennent suffisamment d'informations pour calculer diverses métriques de performances, y compris la précision et le rappel.
analyse syntaxique par constituants
Diviser une phrase en structures grammaticales plus petites ("constituants"). Une partie ultérieure du système de ML, telle qu'un modèle de compréhension du langage naturel, peut analyser les constituants plus facilement que la phrase d'origine. Par exemple, prenons la phrase suivante :
Mon ami a adopté deux chats.
Un analyseur syntaxique peut diviser cette phrase en deux constituants :
- Mon ami est un groupe nominal.
- a adopté deux chats est un groupe verbal.
Ces composants peuvent être subdivisés en composants plus petits. Par exemple, le groupe verbal
a adopté deux chats
peut être subdivisée en :
- Adopté est un verbe.
- deux chats est un autre syntagme nominal.
embedding de langage contextualisé
Un embedding qui s'approche de la "compréhension" des mots et des expressions comme le font les locuteurs humains. Les embeddings de langage contextualisés peuvent comprendre la syntaxe, la sémantique et le contexte complexes.
Prenons l'exemple des embeddings du mot anglais cow (vache). Les anciens embeddings, tels que word2vec, peuvent représenter des mots anglais de sorte que la distance dans l'espace d'embedding entre cow (vache) et bull (taureau) soit semblable à la distance entre ewe (brebis) et ram (bélier), ou entre female (femme) et male (homme). Les embeddings de langage contextualisés peuvent aller plus loin en reconnaissant que les anglophones utilisent parfois le mot cow (vache) pour désigner une vache ou un taureau.
fenêtre de contexte
Nombre de jetons qu'un modèle peut traiter dans une requête donnée. Plus la fenêtre de contexte est grande, plus le modèle peut utiliser d'informations pour fournir des réponses cohérentes à la requête.
caractéristique continue
Caractéristique à virgule flottante avec une plage infinie de valeurs possibles, comme la température ou le poids.
À comparer à la caractéristique discrète.
échantillonnage de commodité
Utiliser un ensemble de données collecté de manière non scientifique pour réaliser des tests rapides. Par la suite, il est essentiel de passer à un ensemble de données collecté de manière scientifique.
convergence
État atteint lorsque les valeurs de perte varient très peu ou pas du tout à chaque itération. Par exemple, la courbe de perte suivante suggère une convergence à environ 700 itérations :
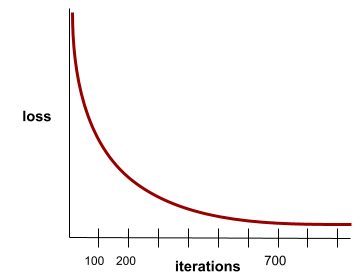
Un modèle converge lorsque la poursuite de l'entraînement ne l'améliore pas.
Dans le deep learning, les valeurs de perte restent parfois constantes ou presque pendant de nombreuses itérations avant de finalement diminuer. Pendant une longue période de valeurs de perte constantes, vous pouvez temporairement avoir une fausse impression de convergence.
Voir aussi arrêt prématuré.
Pour en savoir plus, consultez Convergence du modèle et courbes de perte dans le cours d'initiation au Machine Learning.
codage conversationnel
Dialogue itératif entre vous et un modèle d'IA générative dans le but de créer un logiciel. Vous émettez une requête décrivant un logiciel. Le modèle utilise ensuite cette description pour générer du code. Ensuite, vous émettez une nouvelle requête pour corriger les défauts de la requête précédente ou du code généré, et le modèle génère un code mis à jour. Vous deux continuez à échanger jusqu'à ce que le logiciel généré soit suffisamment bon.
Le codage des conversations est essentiellement la signification d'origine du vibe coding.
À comparer au codage spécificationnel.
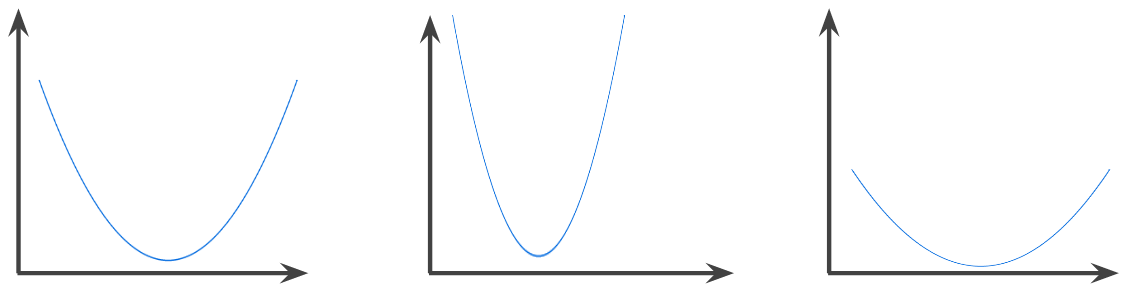
fonction convexe
Fonction dans laquelle la région au-dessus du graphique est un ensemble convexe. La fonction convexe prototypique ressemble à la lettre U. Par exemple, les fonctions suivantes sont toutes des fonctions convexes :
En revanche, la fonction suivante n'est pas convexe. Notez comment la région au-dessus du graphique diffère d'un ensemble convexe :

Une fonction strictement convexe ne possède qu'un seul point de minimum local, qui est également le point de minimum global. Les fonctions classiques en forme de U sont des fonctions strictement convexes. Ce n'est pas le cas de certaines fonctions convexes, comme les droites.
Pour en savoir plus, consultez Convergence et fonctions convexes dans le Cours d'initiation au Machine Learning.
optimisation convexe
Processus d'utilisation de techniques mathématiques telles que la descente de gradient pour trouver le minimum d'une fonction convexe. Dans le domaine du machine learning, de nombreuses études ont cherché à exprimer divers problèmes sous la forme de problèmes d'optimisation convexe pour les résoudre plus efficacement.
Pour en savoir plus, consultez Convex Optimization de Boyd et Vandenberghe.
ensemble convexe
Sous-ensemble de l'espace euclidien tel qu'une ligne tracée entre deux points quelconques du sous-ensemble reste entièrement dans le sous-ensemble. Par exemple, les deux formes suivantes sont des ensembles convexes :

À titre de comparaison, les deux formes suivantes ne sont pas des ensembles convexes :

convolution
En mathématiques, il s'agit d'un mélange de deux fonctions. Dans le machine learning, une convolution mélange le filtre convolutif et la matrice d'entrée pour entraîner les pondérations.
Dans le machine learning, le terme "convolution" est souvent une abréviation pour désigner une opération de convolution ou une couche de convolution.
Sans convolution, un algorithme de machine learning devrait apprendre une pondération différente pour chaque cellule d'un grand Tensor. Par exemple, un algorithme de machine learning dont l'entraînement s'effectue sur des images de 2K x 2K serait forcé de trouver 4 millions de pondérations. Grâce aux convolutions, un algorithme de machine learning ne doit trouver des pondérations que pour chaque cellule du filtre convolutif, ce qui réduit considérablement la mémoire nécessaire à l'entraînement du modèle. Lorsque le filtre de convolution est appliqué, il est simplement répliqué dans les cellules de sorte que chacune soit multipliée par le filtre.
filtre de convolution
L'un des deux acteurs d'une opération convolutive. (L'autre acteur est une tranche d'une matrice d'entrée.) Un filtre convolutif est une matrice de même rang que la matrice d'entrée, mais de forme plus petite. Par exemple, pour une matrice d'entrée 28x28, le filtre peut être n'importe quelle matrice 2D plus petite que 28x28.
Dans la manipulation photographique, toutes les cellules d'un filtre de convolution sont généralement définies sur un modèle constant de uns et de zéros. Dans le machine learning, les filtres convolutifs sont généralement initialisés avec des nombres aléatoires, puis le réseau entraîne les valeurs idéales.
couche de convolution
Couche d'un réseau de neurones profond dans laquelle un filtre convolutif transfère une matrice d'entrée. Soit, par exemple, le filtre convolutif 3 x 3 suivant :
![Matrice 3x3 avec les valeurs suivantes : [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?hl=fr)
L'animation suivante montre une couche convolutive composée de neuf opérations convolutives impliquant la matrice d'entrée 5x5. Notez que chaque opération de convolution fonctionne sur une tranche 3x3 différente de la matrice d'entrée. La matrice 3 x 3 résultante (à droite) est constituée des résultats des 9 opérations convolutives :
![Animation montrant deux matrices. La première matrice est la matrice 5x5 : [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
La deuxième matrice est la matrice 3x3 :
[[181,303,618], [115,338,605], [169,351,560]].
La deuxième matrice est calculée en appliquant le filtre de convolution [[0, 1, 0], [1, 0, 1], [0, 1, 0]] à différents sous-ensembles 3x3 de la matrice 5x5.](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?hl=fr)
réseau de neurones convolutif
Un réseau de neurones dans lequel au moins une couche est une couche convolutive. Un réseau de neurones convolutif typique consiste en une combinaison des couches suivantes :
Les réseaux de neurones convolutifs ont eu beaucoup de succès pour certains types de problèmes, notamment la reconnaissance d'images.
opération de convolution
L'opération mathématique en deux étapes suivante :
- Multiplication élément par élément du filtre convolutif et d'une tranche d'une matrice d'entrée. (La tranche de la matrice d'entrée est de même rang et de même taille que le filtre convolutif.)
- Somme de toutes les valeurs de la matrice de produits résultante.
Soit, par exemple, la matrice d'entrée 5 x 5 suivante :
![Matrice 5x5 : [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?hl=fr)
Soit, à présent, le filtre convolutif 2 x 2 suivant :
![Matrice 2x2 : [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?hl=fr)
Chaque opération de convolution implique une seule tranche 2x2 de la matrice d'entrée. Par exemple, supposons que nous utilisions la tranche 2x2 en haut à gauche de la matrice d'entrée. L'opération de convolution sur cette tranche est alors :
![Appliquer le filtre de convolution [[1, 0], [0, 1]] à la section 2x2 en haut à gauche de la matrice d'entrée, qui est [[128,97], [35,22]].
Le filtre convolutif laisse les valeurs 128 et 22 intactes, mais met à zéro les valeurs 97 et 35. Par conséquent, l'opération de convolution génère la valeur 150 (128+22).](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?hl=fr)
Une couche convolutive consiste en une série d'opérations convolutives, chacune agissant sur une tranche différente de la matrice d'entrée.
COPA
Abréviation de Choice of Plausible Alternatives (Choix d'alternatives plausibles).
coût
Synonyme de perte.
cotraining
Une approche d'apprentissage semi-supervisé est particulièrement utile lorsque toutes les conditions suivantes sont remplies :
- Le ratio exemples sans étiquette/exemples avec étiquette est élevé dans l'ensemble de données.
- Il s'agit d'un problème de classification (binaire ou à classes multiples).
- L'ensemble de données contient deux ensembles différents de caractéristiques prédictives indépendantes les unes des autres et complémentaires.
Le co-apprentissage amplifie essentiellement les signaux indépendants pour en faire un signal plus fort. Par exemple, prenons un modèle de classification qui classe les voitures d'occasion individuelles dans les catégories Bon état ou Mauvais état. Un ensemble de caractéristiques prédictives peut se concentrer sur les caractéristiques globales telles que l'année, la marque et le modèle de la voiture. Un autre ensemble de caractéristiques prédictives peut se concentrer sur l'historique de conduite du propriétaire précédent et l'historique d'entretien de la voiture.
L'article de référence sur le co-apprentissage est Combining Labeled and Unlabeled Data with Co-Training de Blum et Mitchell.
équité contrefactuelle
Une métrique d'équité qui vérifie si un modèle de classification produit le même résultat pour une personne que pour une autre qui est identique à la première, sauf en ce qui concerne un ou plusieurs attributs sensibles. L'évaluation d'un modèle de classification pour l'équité contrefactuelle est une méthode permettant d'identifier les sources potentielles de biais dans un modèle.
Pour en savoir plus, consultez les ressources suivantes :
- Équité : équité contrefactuelle dans le cours d'initiation au machine learning
- Quand les mondes se rencontrent : intégrer différentes hypothèses contrefactuelles dans l'équité
biais de couverture
Voir biais de sélection.
phrase équivoque
Phrase ou expression au sens ambigu. Les phrases équivoques posent un problème majeur pour la compréhension du langage naturel. Par exemple, l'expression au pied de la lettre est une phrase équivoque, car un modèle NLU peut l'interpréter littéralement ou figurativement.
critique
Synonyme de réseau Deep Q.
entropie croisée
Généralisation de la perte logistique aux problèmes de classification à classes multiples. L'entropie croisée quantifie la différence entre deux distributions de probabilité. Voir aussi perplexité.
validation croisée
Mécanisme permettant d'estimer la capacité d'un modèle à être généralisé à de nouvelles données en le testant par rapport à un ou plusieurs sous-ensembles de données qui ne se chevauchent pas et sont retenus de l'ensemble d'entraînement.
fonction de distribution cumulative (CDF)
Fonction qui définit la fréquence des échantillons inférieurs ou égaux à une valeur cible. Par exemple, considérons une distribution normale de valeurs continues. Une CDF vous indique qu'environ 50 % des échantillons doivent être inférieurs ou égaux à la moyenne et qu'environ 84 % des échantillons doivent être inférieurs ou égaux à un écart-type au-dessus de la moyenne.
D
analyse des données
Procédure visant à comprendre des données en en étudiant les échantillons, les mesures et les visualisations. L'analyse de données peut s'avérer particulièrement utile à la réception d'un ensemble de données, avant la création du premier modèle. Elle est également cruciale pour interpréter les expériences et déboguer les problèmes affectant le système.
augmentation des données
Augmenter artificiellement l'éventail et le nombre d'exemples d'entraînement en transformant les exemples existants afin d'en créer de nouveaux. Supposons que votre ensemble de données contienne des exemples d'images, mais pas suffisamment pour que le modèle apprenne des associations utiles. Dans l'idéal, vous allez ajouter suffisamment d'images avec libellé à votre ensemble de données pour que votre modèle puisse s'entraîner correctement. Si ce n'est pas possible, l'augmentation des données peut faire pivoter, étirer et faire un reflet de chaque image afin de créer de nombreuses variantes de l'image originale, ce qui produira éventuellement suffisamment de données avec libellé pour un entraînement d'excellente qualité.
DataFrame
Type de données pandas populaire pour représenter les ensembles de données en mémoire.
Un DataFrame est analogue à un tableau ou à une feuille de calcul. Chaque colonne d'un DataFrame porte un nom (un en-tête) et chaque ligne est identifiée par un numéro unique.
Chaque colonne d'un DataFrame est structurée comme un tableau à deux dimensions, sauf que chaque colonne peut se voir attribuer son propre type de données.
Consultez également la page de référence officielle pandas.DataFrame.
parallélisme des données
Méthode de mise à l'échelle de l'entraînement ou de l'inférence qui réplique un modèle entier sur plusieurs appareils, puis transmet un sous-ensemble des données d'entrée à chaque appareil. Le parallélisme des données peut permettre l'entraînement et l'inférence sur des tailles de lot très importantes. Toutefois, il nécessite que le modèle soit suffisamment petit pour tenir sur tous les appareils.
Le parallélisme des données accélère généralement l'entraînement et l'inférence.
Voir aussi parallélisme des modèles.
API Dataset (tf.data)
API TensorFlow de haut niveau pour la lecture des données et leur transformation en une forme requise par un algorithme de machine learning.
Un objet tf.data.Dataset représente une séquence d'éléments dans laquelle chaque élément contient un ou plusieurs Tensors. Un objet tf.data.Iterator permet d'accéder aux éléments d'un Dataset.
ensemble de données (data set ou dataset)
Ensemble de données brutes, généralement (mais pas exclusivement) organisé dans l'un des formats suivants :
- une feuille de calcul
- un fichier au format CSV (valeurs séparées par une virgule)
frontière de décision
Séparateur entre les classes apprises par un modèle dans les problèmes de classification binaire ou à classes multiples. Par exemple, dans l'image suivante représentant un problème de classification binaire, la frontière de décision est la limite entre la classe orange et la classe bleue :

forêt de décision
Modèle créé à partir de plusieurs arbres de décision. Une forêt de décision effectue une prédiction en agrégeant les prédictions de ses arbres de décision. Les types de forêts de décision les plus courants sont les forêts aléatoires et les arbres à boosting de gradient.
Pour en savoir plus, consultez la section Forêts de décision du cours sur les forêts de décision.
seuil de décision
Synonyme de seuil de classification.
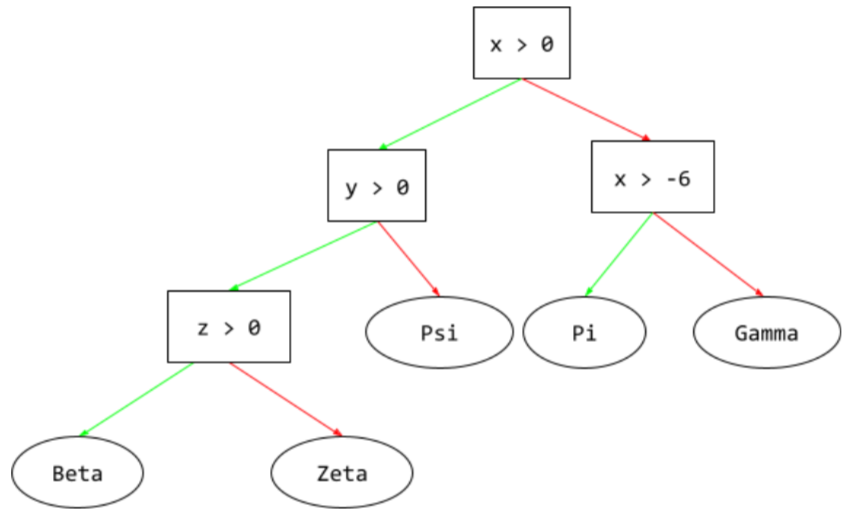
arbre de décision
Modèle d'apprentissage supervisé composé d'un ensemble de conditions et de feuilles organisées de manière hiérarchique. Par exemple, voici un arbre de décision :
décodeur
En général, tout système de ML qui convertit une représentation traitée, dense ou interne en une représentation plus brute, parcimonieuse ou externe.
Les décodeurs sont souvent un composant d'un modèle plus grand, où ils sont fréquemment associés à un encodeur.
Dans les tâches de séquence à séquence, un décodeur commence par l'état interne généré par l'encodeur pour prédire la séquence suivante.
Pour en savoir plus sur la définition d'un décodeur dans l'architecture Transformer, consultez Transformer.
Pour en savoir plus, consultez Grands modèles de langage dans le cours d'initiation au machine learning.
modèle deep learning
Un réseau de neurones contenant plus d'une couche cachée.
Un modèle profond est également appelé réseau de neurones profond.
À comparer au modèle large.
de réseau de neurones profond
Synonyme de modèle profond.
Deep Q-Network (DQN)
Dans Q-learning, un réseau de neurones profond qui prédit les fonctions Q.
Critic est un synonyme de Deep Q-Network.
parité démographique
Une métrique d'équité qui est satisfaite si les résultats de la classification d'un modèle ne dépendent pas d'un attribut sensible donné.
Par exemple, si les Lilliputiens et les Brobdingnags postulent à l'université de Glubbdubdrib, la parité démographique est atteinte si le pourcentage de Lilliputiens admis est le même que celui des Brobdingnags, que l'un des groupes soit en moyenne plus qualifié que l'autre ou non.
À l'inverse de l'égalité des chances et de l'égalité des opportunités, qui autorisent les résultats de classification agrégés à dépendre des attributs sensibles, mais pas les résultats de classification pour certains libellés de vérité terrain spécifiés. Consultez "Attacking discrimination with smarter machine learning" pour une visualisation explorant les compromis lors de l'optimisation pour la parité démographique.
Pour en savoir plus, consultez Équité : parité démographique dans le Cours d'initiation au Machine Learning.
Débruitage
Une approche courante de l'apprentissage autosupervisé dans laquelle :
- Du bruit est ajouté artificiellement à l'ensemble de données.
- Le modèle tente de supprimer le bruit.
La suppression du bruit permet d'apprendre à partir d'exemples sans étiquette. L'ensemble de données d'origine sert de cible ou d'étiquette, et les données bruitées servent d'entrée.
Certains modèles de langage masqués utilisent la suppression du bruit comme suit :
- Du bruit est ajouté artificiellement à une phrase non libellée en masquant certains jetons.
- Le modèle tente de prédire les jetons d'origine.
caractéristique dense
Une feature dans laquelle la plupart ou la totalité des valeurs sont non nulles, généralement un Tensor de valeurs à virgule flottante. Par exemple, le Tensor à 10 éléments ci-dessous est dense, car 9 de ses valeurs sont non nulles :
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
À comparer à la caractéristique creuse.
couche dense
Synonyme de couche entièrement connectée.
profondeur
La somme des éléments suivants dans un réseau de neurones :
- le nombre de couches cachées
- le nombre de couches de sortie, qui est généralement de 1.
- le nombre de couches d'embedding
Par exemple, un réseau de neurones avec cinq couches cachées et une couche de sortie a une profondeur de 6.
Notez que la couche d'entrée n'a pas d'incidence sur la profondeur.
Réseau de neurones convolutifs séparables en profondeur (sepCNN)
Architecture de réseau de neurones convolutifs basée sur Inception, mais où les modules Inception sont remplacés par des convolutions séparables en profondeur. Également appelé Xception.
Une convolution séparable en profondeur (également appelée convolution séparable) factorise une convolution 3D standard en deux opérations de convolution distinctes qui sont plus efficaces en termes de calcul : d'abord, une convolution en profondeur, avec une profondeur de 1 (n × n × 1), puis une convolution ponctuelle, avec une longueur et une largeur de 1 (1 × 1 × n).
Pour en savoir plus, consultez Xception: Deep Learning with Depthwise Separable Convolutions.
libellé dérivé
Synonyme d'étiquette de substitution.
déterministe
Système qui renvoie toujours la même sortie pour une entrée donnée. Par exemple, la fonction ReLU est déterministe, car :
- Lorsque l'entrée est négative, la sortie est toujours égale à 0.
- Lorsque l'entrée est non négative, la sortie est toujours égale à l'entrée.
En revanche, une fonction qui renvoie un nombre aléatoire à chaque fois qu'elle est appelée est non déterministe.
Les systèmes déterministes sont généralement beaucoup plus faciles à tester que les systèmes non déterministes.
Les LLM sont généralement non déterministes, c'est-à-dire que la réponse du LLM à la même requête est souvent différente.
appareil
Terme complexe ayant deux définitions possibles :
- Catégorie de matériel pouvant exécuter une session TensorFlow, y compris les CPU, les GPU et les TPU.
- Lors de l'entraînement d'un modèle de ML sur des puces d'accélérateur (GPU ou TPU), il s'agit de la partie du système qui manipule réellement les Tensors et les embeddings. L'appareil fonctionne avec des puces d'accélération. En revanche, l'hôte s'exécute généralement sur un processeur.
confidentialité différentielle
Dans le machine learning, approche d'anonymisation visant à protéger les données sensibles (par exemple, les informations personnelles d'un individu) incluses dans l'ensemble d'entraînement d'un modèle contre toute exposition. Cette approche garantit que le modèle n'apprend ni ne mémorise beaucoup d'informations sur une personne spécifique. Pour ce faire, nous échantillonnons et ajoutons du bruit lors de l'entraînement du modèle afin d'obscurcir les points de données individuels, ce qui réduit le risque d'exposer des données d'entraînement sensibles.
La confidentialité différentielle est également utilisée en dehors du machine learning. Par exemple, les data scientists utilisent parfois la confidentialité différentielle pour protéger la confidentialité individuelle lorsqu'ils calculent des statistiques d'utilisation des produits pour différentes données démographiques.
réduction de la dimensionnalité
Diminution du nombre de dimensions utilisées pour représenter une caractéristique particulière dans un vecteur de caractéristiques, généralement par conversion en un vecteur d'embedding.
Dimensions
Terme complexe qui a une des définitions suivantes :
Nombre de niveaux de coordonnées dans un Tensor. Exemple :
- Un scalaire a zéro dimension; par exemple,
["Hello"]. - Un vecteur a une dimension (par exemple,
[3, 5, 7, 11]). - Une matrice a deux dimensions; par exemple,
[[2, 4, 18], [5, 7, 14]]. Vous pouvez spécifier de manière unique une cellule particulière dans un vecteur à une dimension avec une coordonnée; vous avez besoin de deux coordonnées pour spécifier de manière unique une cellule particulière dans une matrice à deux dimensions.
- Un scalaire a zéro dimension; par exemple,
Nombre d'entrées dans un vecteur de caractéristiques.
Nombre d'éléments dans une couche d'intégration.
le prompting direct ;
Synonyme de requête zero-shot.
caractéristique discrète
Caractéristique avec un ensemble fini de valeurs possibles. Par exemple, une caractéristique dont les valeurs ne peuvent être que animal, végétal ou minéral est une caractéristique discrète (ou catégorielle).
À comparer à la caractéristique continue.
modèle discriminatif
Un modèle qui prédit des libellés à partir d'un ensemble d'une ou plusieurs caractéristiques. Plus formellement, les modèles discriminatifs définissent la probabilité conditionnelle d'un résultat compte tenu des caractéristiques et des pondérations, soit :
p(output | features, weights)
Par exemple, un modèle qui prédit si un e-mail est du spam à partir de caractéristiques et de pondérations est un modèle discriminatif.
La grande majorité des modèles d'apprentissage supervisé, y compris les modèles de classification et de régression, sont des modèles discriminatifs.
À comparer au modèle génératif.
discriminateur
Système qui détermine si les exemples sont réels ou factices.
Il s'agit également du sous-système d'un réseau antagoniste génératif qui détermine si les exemples créés par le générateur sont réels ou factices.
Pour en savoir plus, consultez Le discriminateur dans le cours sur les GAN.
Impact disparate
Prendre des décisions concernant des personnes qui ont un impact disproportionné sur différents sous-groupes de population. Il s'agit généralement de situations dans lesquelles un processus de prise de décision algorithmique nuit à certains sous-groupes ou leur profite plus qu'à d'autres.
Par exemple, supposons qu'un algorithme qui détermine l'éligibilité d'un Lilliputien à un prêt immobilier miniature est plus susceptible de le classer comme "non éligible" si son adresse postale contient un certain code postal. Si les Lilliputiens Big-Endian sont plus susceptibles d'avoir des adresses postales avec ce code postal que les Lilliputiens Little-Endian, cet algorithme peut entraîner un impact disparate.
À ne pas confondre avec le traitement différentiel, qui se concentre sur les disparités résultant de caractéristiques de sous-groupes qui sont des entrées explicites dans un processus de prise de décision algorithmique.
traitement inégalitaire
Intégration des attributs sensibles des sujets dans un processus de prise de décision algorithmique de sorte que différents sous-groupes de personnes soient traités différemment.
Par exemple, prenons l'exemple d'un algorithme qui détermine l'éligibilité des Lilliputiens à un prêt pour une maison miniature en fonction des données qu'ils fournissent dans leur demande de prêt. Si l'algorithme utilise l'affiliation d'un Lilliputien en tant que Big-Endian ou Little-Endian comme entrée, il applique un traitement différentiel selon cette dimension.
À l'inverse, l'impact disparate se concentre sur les disparités dans les impacts sociétaux des décisions algorithmiques sur les sous-groupes, que ces sous-groupes soient des entrées du modèle ou non.
distillation
Processus de réduction de la taille d'un modèle (appelé modèle enseignant) en un modèle plus petit (appelé modèle élève) qui imite les prédictions du modèle d'origine aussi fidèlement que possible. La distillation est utile, car le modèle plus petit présente deux avantages clés par rapport au modèle plus grand (l'enseignant) :
- Temps d'inférence plus rapide
- Réduction de l'utilisation de la mémoire et de l'énergie
Toutefois, les prédictions de l'élève ne sont généralement pas aussi bonnes que celles de l'enseignant.
La distillation entraîne le modèle élève à minimiser une fonction de perte basée sur la différence entre les sorties des prédictions des modèles élève et enseignant.
Comparez et opposez la distillation aux termes suivants :
Pour en savoir plus, consultez LLM : affinage, distillation et ingénierie des prompts dans le cours d'initiation au machine learning.
distribution
La fréquence et la plage des différentes valeurs pour une caractéristique ou un libellé donné. Une distribution indique la probabilité d'une valeur donnée.
L'image suivante montre les histogrammes de deux distributions différentes :
- À gauche, une distribution de la loi de puissance de la richesse par rapport au nombre de personnes possédant cette richesse.
- À droite, une distribution normale de la taille par rapport au nombre de personnes ayant cette taille.

Comprendre la distribution de chaque caractéristique et de chaque libellé peut vous aider à déterminer comment normaliser les valeurs et détecter les valeurs aberrantes.
L'expression hors distribution fait référence à une valeur qui n'apparaît pas dans l'ensemble de données ou qui est très rare. Par exemple, une image de la planète Saturne serait considérée comme hors distribution pour un ensemble de données composé d'images de chats.
clustering divisif
Voir clustering hiérarchique.
sous-échantillonnage
Terme complexe qui désigne l'un des deux concepts suivants, selon les cas :
- Réduction de la quantité d'informations dans une caractéristique afin d'entraîner un modèle plus efficacement. Par exemple, avant d'entraîner un modèle de reconnaissance d'images, procéder au sous-échantillonnage d'images haute résolution dans un format de résolution inférieure.
- Entraînement du modèle sur un pourcentage excessivement faible d'exemples de classes surreprésentés afin d'améliorer l'entraînement sur les classes sous-représentées. Par exemple, dans un ensemble de données déséquilibré, les modèles ont tendance à en apprendre beaucoup sur la classe majoritaire et pas assez sur la classe minoritaire. Le sous-échantillonnage permet d'équilibrer la durée d'entraînement sur les classes majoritaires et minoritaires.
Pour en savoir plus, consultez Ensembles de données : ensembles de données déséquilibrés dans le Cours d'initiation au Machine Learning.
DQN
Abréviation de Deep Q-Network.
régularisation par abandon
Forme de régularisation utile pour entraîner les réseaux de neurones. La régularisation par abandon supprime de manière aléatoire un nombre fixe d'unités dans une couche du réseau pour un pas de gradient unique. Plus il y a d'abandons, plus la régularisation est poussée. Cette méthode est analogue à l'entraînement du modèle pour émuler un ensemble exponentiellement large de réseaux plus petits. Pour plus d'informations, consultez l'article Dropout: A Simple Way to Prevent Neural Networks from Overfitting (en anglais).
dynamic
Quelque chose qui est fait fréquemment ou en continu. Les termes dynamique et en ligne sont synonymes dans le machine learning. Voici des utilisations courantes des termes dynamique et en ligne dans le machine learning :
- Un modèle dynamique (ou modèle en ligne) est un modèle réentraîné fréquemment ou en continu.
- L'entraînement dynamique (ou entraînement en ligne) est le processus d'entraînement fréquent ou continu.
- L'inférence dynamique (ou inférence en ligne) est le processus de génération de prédictions à la demande.
modèle dynamique
Un modèle fréquemment (voire en continu) réentraîné. Un modèle dynamique est un "apprenant permanent" qui s'adapte constamment à l'évolution des données. Un modèle dynamique est également appelé modèle en ligne.
À comparer au modèle statique.
E
exécution eager
Environnement de programmation TensorFlow dans lequel les opérations s'exécutent immédiatement. En revanche, les opérations appelées dans l'exécution de graphe ne sont exécutées que lorsqu'elles sont explicitement évaluées. L'exécution eager est une interface impérative, à l'instar du code de la plupart des langages de programmation. Les programmes d'exécution eager sont généralement bien plus faciles à déboguer que les programmes d'exécution de graphe.
arrêt prématuré
Méthode de régularisation qui consiste à mettre fin à l'entraînement avant que la perte d'entraînement ait fini de baisser. Dans l'arrêt prématuré, vous arrêtez intentionnellement l'entraînement du modèle lorsque la perte sur un ensemble de données de validation commence à augmenter, c'est-à-dire lorsque les performances de généralisation se détériorent.
À comparer à la sortie anticipée.
Distance Earth Mover (EMD)
Mesure de la similarité relative de deux distributions. Plus la distance EMD est faible, plus les distributions sont similaires.
distance d'édition
Mesure de la similarité entre deux chaînes de texte. Dans le machine learning, la distance d'édition est utile pour les raisons suivantes :
- La distance d'édition est facile à calculer.
- La distance d'édition peut comparer deux chaînes connues pour être similaires.
- La distance d'édition peut déterminer le degré de similarité entre différentes chaînes et une chaîne donnée.
Il existe plusieurs définitions de la distance d'édition, chacune utilisant des opérations de chaîne différentes. Pour obtenir un exemple, consultez Distance de Levenshtein.
Notation Einsum
Notation efficace pour décrire la façon dont deux tenseurs doivent être combinés. Les Tensors sont combinés en multipliant les éléments d'un Tensor par les éléments de l'autre Tensor, puis en additionnant les produits. La notation Einsum utilise des symboles pour identifier les axes de chaque Tensor. Ces mêmes symboles sont réorganisés pour spécifier la forme du nouveau Tensor résultant.
NumPy fournit une implémentation Einsum courante.
couche d'embedding
Une couche cachée spéciale qui s'entraîne sur une caractéristique catégorielle de grande dimension pour apprendre progressivement un vecteur d'intégration de dimension inférieure. Une couche d'intégration permet à un réseau de neurones de s'entraîner beaucoup plus efficacement que s'il s'entraînait uniquement sur la caractéristique catégorielle de grande dimension.
Par exemple, la Terre abrite actuellement environ 73 000 espèces d'arbres. Supposons que l'espèce d'arbre soit une caractéristique de votre modèle. La couche d'entrée de votre modèle inclut donc un vecteur one-hot de 73 000 éléments.
Par exemple, baobab pourrait se présenter comme suit :

Un tableau de 73 000 éléments est très long. Si vous n'ajoutez pas de couche d'intégration au modèle, l'entraînement prendra beaucoup de temps en raison de la multiplication de 72 999 zéros. Vous pouvez choisir que la couche d'intégration comporte 12 dimensions. Par conséquent, la couche d'intégration apprendra progressivement un nouveau vecteur d'intégration pour chaque espèce d'arbre.
Dans certaines situations, le hachage est une alternative raisonnable à une couche d'embedding.
Pour en savoir plus, consultez Embeddings dans le Cours d'initiation au Machine Learning.
espace d'embedding
Les espaces vectoriels à d dimensions auxquelles les caractéristiques d'un espace vectoriel de plus grande dimension sont mappées. L'espace d'intégration est entraîné pour capturer une structure significative pour l'application prévue.
Le produit scalaire de deux embeddings est une mesure de leur similarité.
vecteur d'embedding
En termes généraux, il s'agit d'un tableau de nombres à virgule flottante provenant de n'importe quelle couche cachée qui décrit les entrées de cette couche cachée. Un vecteur d'embedding est souvent le tableau de nombres à virgule flottante entraîné dans une couche d'embedding. Par exemple, supposons qu'une couche d'embedding doit apprendre un vecteur d'embedding pour chacune des 73 000 espèces d'arbres sur Terre. Le tableau suivant est peut-être le vecteur d'embedding d'un baobab :

Un vecteur d'embedding n'est pas un ensemble de nombres aléatoires. Une couche d'embedding détermine ces valeurs par le biais de l'entraînement, de la même manière qu'un réseau de neurones apprend d'autres pondérations pendant l'entraînement. Chaque élément du tableau est une note attribuée à une caractéristique d'une espèce d'arbre. Quel élément représente quelle caractéristique d'espèce d'arbre ? Il est très difficile pour les humains de le déterminer.
La partie mathématiquement remarquable d'un vecteur d'embedding est que les éléments similaires ont des ensembles de nombres à virgule flottante similaires. Par exemple, les espèces d'arbres similaires ont un ensemble de nombres à virgule flottante plus semblable que les espèces d'arbres différentes. Les séquoias et les séquoias géants sont des espèces d'arbres apparentées. Ils auront donc un ensemble de nombres à virgule flottante plus similaire que les séquoias et les cocotiers. Les nombres du vecteur d'embedding changeront chaque fois que vous réentraînerez le modèle, même si vous le faites avec des entrées identiques.
comportement émergent
Capacité d'un LLM à générer des réponses à des requêtes pour lesquelles il n'a pas été explicitement entraîné.
fonction de distribution empirique (FDR ou FDE)
Fonction de distribution cumulative basée sur des mesures empiriques issues d'un ensemble de données réel. La valeur de la fonction à n'importe quel point de l'axe x correspond à la fraction des observations de l'ensemble de données qui sont inférieures ou égales à la valeur spécifiée.
minimisation du risque empirique (ERM)
Sélection de la fonction qui minimise la perte pour l'ensemble d'entraînement. À comparer à la minimisation du risque structurel.
encodeur
En général, tout système de ML qui convertit une représentation brute, éparse ou externe en une représentation plus traitée, plus dense ou plus interne.
Les encodeurs sont souvent un composant d'un modèle plus vaste, où ils sont fréquemment associés à un décodeur. Certains Transformers associent des encodeurs à des décodeurs, tandis que d'autres Transformers n'utilisent que l'encodeur ou que le décodeur.
Certains systèmes utilisent la sortie de l'encodeur comme entrée d'un réseau de classification ou de régression.
Dans les tâches de séquence à séquence, un encodeur prend une séquence d'entrée et renvoie un état interne (un vecteur). L'encodeur utilise ensuite cet état interne pour prédire la séquence suivante.
Pour la définition d'un encodeur dans l'architecture Transformer, consultez Transformer.
Pour en savoir plus, consultez LLM : qu'est-ce qu'un grand modèle de langage ? dans le Cours d'initiation au Machine Learning.
points de terminaison
Emplacement accessible sur le réseau (généralement une URL) où un service peut être contacté.
automatisé
Collection de modèles entraînés indépendamment dont les prédictions sont moyennées ou agrégées. Dans de nombreux cas, un ensemble produit de meilleures prédictions qu'un modèle unique. Par exemple, une forêt aléatoire est un ensemble construit à partir de plusieurs arbres de décision. Notez que tous les forêts de décision ne sont pas des ensembles.
Pour en savoir plus, consultez Forêt aléatoire dans le cours d'initiation au machine learning.
entropie
Dans la théorie de l'information, l'entropie est une description du degré d'imprévisibilité d'une distribution de probabilité. Elle est également définie comme la quantité d'informations contenues dans chaque exemple. Une distribution présente l'entropie la plus élevée possible lorsque toutes les valeurs d'une variable aléatoire sont équiprobables.
L'entropie d'un ensemble avec deux valeurs possibles "0" et "1" (par exemple, les libellés dans un problème de classification binaire) a la formule suivante :
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
où :
- H est l'entropie.
- p correspond à la fraction d'exemples "1".
- q correspond à la fraction d'exemples "0". Notez que q = (1 - p).
- Le log est généralement log2. Dans ce cas, l'unité d'entropie est un bit.
Par exemple, supposons les éléments suivants :
- 100 exemples contiennent la valeur "1"
- 300 exemples contiennent la valeur "0"
La valeur d'entropie est donc la suivante :
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = 0,81 bit par exemple
Un ensemble parfaitement équilibré (par exemple, 200 "0" et 200 "1") aurait une entropie de 1,0 bit par exemple. À mesure qu'un ensemble devient plus déséquilibré, son entropie tend vers 0.
Dans les arbres de décision, l'entropie permet de formuler le gain d'information pour aider le splitter à sélectionner les conditions lors de la croissance d'un arbre de décision de classification.
Comparer l'entropie avec :
- Impureté Gini
- Fonction de perte d'entropie croisée
L'entropie est souvent appelée entropie de Shannon.
Pour en savoir plus, consultez Splitter exact pour la classification binaire avec des caractéristiques numériques dans le cours sur les forêts de décision.
de test
Dans l'apprentissage par renforcement, le monde qui contient l'agent et lui permet d'observer l'état de ce monde. Par exemple, le monde représenté peut être un jeu comme les échecs ou un monde physique comme un labyrinthe. Lorsque l'agent applique une action à l'environnement, celui-ci passe d'un état à un autre.
ancrage de l'environnement
Données brutes renvoyées à l'agent lors de l'étape feedback de la boucle agentique. Par exemple, l'ancrage de l'environnement pour un agent peut inclure des journaux d'erreurs ou le code HTML d'une page Web nouvellement créée.
épisode
Dans l'apprentissage par renforcement, chacune des tentatives répétées de l'agent pour apprendre un environnement.
mémoire épisodique
Dans les LLM, les informations sont apprises après l'entraînement. En revanche, la mémoire sémantique correspond aux informations apprises pendant l'entraînement. La mémoire épisodique peut être temporaire (par exemple, ne durer que pendant la session de chatbot en cours) ou plus permanente (par exemple, persister pour chaque session que l'utilisateur invoque).
Voir aussi mémoire procédurale.
epoch
Cycle d'entraînement complet sur l'intégralité de l'ensemble d'entraînement de manière à ce que chaque exemple ait été traité une fois.
Une époque représente N/taille du lot itérations d'entraînement, où N correspond au nombre total d'exemples.
Par exemple, supposons les éléments suivants :
- L'ensemble de données se compose de 1 000 exemples.
- La taille du lot est de 50 exemples.
Par conséquent, une seule époque nécessite 20 itérations :
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Pour en savoir plus, consultez Régression linéaire : hyperparamètres dans le Cours d'initiation au Machine Learning.
stratégie epsilon-greedy
Dans l'apprentissage par renforcement, une stratégie qui suit une stratégie aléatoire avec une probabilité epsilon ou une stratégie gourmande dans le cas contraire. Par exemple, si epsilon est de 0,9, la règle suit une règle aléatoire 90 % du temps et une règle gourmande 10 % du temps.
Au fil des épisodes, l'algorithme réduit la valeur d'epsilon afin de passer d'une stratégie aléatoire à une stratégie gourmande. En modifiant la stratégie, l'agent explore d'abord l'environnement de manière aléatoire, puis exploite de manière gourmande les résultats de l'exploration aléatoire.
l'égalité des chances.
Une métrique d'équité permettant d'évaluer si un modèle prédit le résultat souhaitable aussi bien pour toutes les valeurs d'une caractéristique sensible. En d'autres termes, si le résultat souhaitable pour un modèle est la classe positive, l'objectif serait d'avoir le même taux de vrais positifs pour tous les groupes.
L'égalité des chances est liée à la parité des chances, qui exige que les taux de vrais positifs et les taux de faux positifs soient les mêmes pour tous les groupes.
Supposons que l'université Glubbdubdrib accepte les Lilliputiens et les Brobdingnagiens dans un programme de mathématiques rigoureux. Les établissements secondaires lilliputiens proposent un programme solide de cours de mathématiques, et la grande majorité des élèves sont qualifiés pour le programme universitaire. Les établissements secondaires de Brobdingnag ne proposent pas de cours de mathématiques. Par conséquent, beaucoup moins d'élèves sont qualifiés. L'égalité des chances est respectée pour le libellé préféré "admis" par rapport à la nationalité (Lilliputien ou Brobdingnagien) si les élèves qualifiés ont la même probabilité d'être admis, qu'ils soient Lilliputiens ou Brobdingnagiens.
Par exemple, supposons que 100 Lilliputiens et 100 Brobdingnagiens postulent à l'université de Glubbdubdrib, et que les décisions d'admission sont prises comme suit :
Tableau 1. Candidats lilliputiens (90 % sont qualifiés)
| Qualifié | Non défini | |
|---|---|---|
| Admis | 45 | 3 |
| Refusé | 45 | 7 |
| Total | 90 | 10 |
|
Pourcentage d'étudiants qualifiés admis : 45/90 = 50 % Pourcentage d'étudiants non qualifiés refusés : 7/10 = 70 % Pourcentage total d'étudiants lilliputiens admis : (45+3)/100 = 48 % |
||
Tableau 2. Candidats brobdingnagiens (10 % sont qualifiés) :
| Qualifié | Non défini | |
|---|---|---|
| Admis | 5 | 9 |
| Refusé | 5 | 81 |
| Total | 10 | 90 |
|
Pourcentage d'étudiants qualifiés admis : 5/10 = 50 % Pourcentage d'étudiants non qualifiés refusés : 81/90 = 90 % Pourcentage total d'étudiants brobdingnagiens admis : (5+9)/100 = 14 % |
||
Les exemples précédents satisfont l'égalité des chances pour l'acceptation des élèves qualifiés, car les Lilliputiens et les Brobdingnagiens qualifiés ont tous deux 50 % de chances d'être admis.
Bien que l'égalité des opportunités soit respectée, les deux métriques d'équité suivantes ne le sont pas :
- Parité démographique : les Lilliputiens et les Brobdingnagiens sont admis à l'université à des taux différents (48 % des Lilliputiens sont admis, contre seulement 14 % des Brobdingnagiens).
- Parité des chances : bien que les élèves lilliputiens et brobdingnagiens qualifiés aient la même chance d'être admis, la contrainte supplémentaire selon laquelle les lilliputiens et les brobdingnagiens non qualifiés ont la même chance d'être refusés n'est pas respectée. Le taux de refus est de 70 % pour les Lilliputiens non qualifiés et de 90 % pour les Brobdingnagiens non qualifiés.
Pour en savoir plus, consultez Équité : égalité des chances dans le cours d'initiation au machine learning.
Chances égales
Métrique d'équité permettant d'évaluer si un modèle prédit les résultats aussi bien pour toutes les valeurs d'un attribut sensible par rapport à la classe positive et à la classe négative, et non pas uniquement à l'une ou l'autre. En d'autres termes, le taux de vrais positifs et le taux de faux négatifs doivent être identiques pour tous les groupes.
L'égalité des chances est liée à l'égalité des opportunités, qui ne se concentre que sur les taux d'erreur pour une seule classe (positive ou négative).
Par exemple, supposons que l'université Glubbdubdrib accepte les Lilliputiens et les Brobdingnagiens dans un programme de mathématiques rigoureux. Les établissements secondaires lilliputiens proposent un programme solide de cours de mathématiques, et la grande majorité des élèves sont qualifiés pour le programme universitaire. Les établissements secondaires de Brobdingnag ne proposent pas de cours de mathématiques. Par conséquent, beaucoup moins de leurs élèves sont qualifiés. Les chances égales sont respectées si, qu'un candidat soit lilliputien ou brobdingnagien, il a les mêmes chances d'être admis au programme s'il est qualifié et les mêmes chances d'être refusé s'il ne l'est pas.
Supposons que 100 Lilliputiens et 100 Brobdingnagiens postulent à l'université de Glubbdubdrib, et que les décisions d'admission sont prises comme suit :
Tableau 3 : Candidats lilliputiens (90 % sont qualifiés)
| Qualifié | Non défini | |
|---|---|---|
| Admis | 45 | 2 |
| Refusé | 45 | 8 |
| Total | 90 | 10 |
|
Pourcentage d'étudiants qualifiés admis : 45/90 = 50 % Pourcentage d'étudiants non qualifiés refusés : 8/10 = 80 % Pourcentage total d'étudiants lilliputiens admis : (45+2)/100 = 47 % |
||
Tableau 4. Candidats brobdingnagiens (10 % sont qualifiés) :
| Qualifié | Non défini | |
|---|---|---|
| Admis | 5 | 18 |
| Refusé | 5 | 72 |
| Total | 10 | 90 |
|
Pourcentage d'étudiants qualifiés admis : 5/10 = 50 % Pourcentage d'étudiants non qualifiés refusés : 72/90 = 80 % Pourcentage total d'étudiants brobdingnagiens admis : (5+18)/100 = 23 % |
||
Les chances égales sont respectées, car les étudiants lilliputiens et brobdingnagiens qualifiés ont tous deux 50 % de chances d'être admis, et les étudiants lilliputiens et brobdingnagiens non qualifiés ont 80 % de chances d'être refusés.
La parité des chances est formellement définie dans "Equality of Opportunity in Supervised Learning" comme suit : "Le prédicteur Ŷ satisfait à la parité des chances par rapport à l'attribut protégé A et au résultat Y si Ŷ et A sont indépendants, conditionnellement à Y."
Estimator
API TensorFlow obsolète. Utilisez plutôt tf.keras que les Estimators.
evals
Principalement utilisé comme abréviation pour évaluations LLM. Plus généralement, evals est l'abréviation de toute forme d'évaluation.
hors connexion
Processus de mesure de la qualité d'un modèle ou de comparaison de différents modèles.
Pour évaluer un modèle de machine learning supervisé, vous le comparez généralement à un ensemble de validation et à un ensemble de test. L'évaluation d'un LLM implique généralement des évaluations plus larges de la qualité et de la sécurité.
agent évaluateur
Agent qui évalue les résultats d'un autre agent avant qu'ils ne soient finalisés. Imaginez qu'un agent fabrique un produit et qu'un autre agent (l'agent évaluateur) teste ce produit avant sa sortie.
Critic est un synonyme d'agent évaluateur.
mots clés exacts
Il s'agit d'une métrique tout ou rien dans laquelle la sortie du modèle correspond exactement à la vérité terrain ou au texte de référence, ou pas du tout. Par exemple, si la vérité terrain est orange, la seule sortie de modèle qui correspond exactement est orange.
La correspondance exacte peut également évaluer les modèles dont la sortie est une séquence (une liste d'éléments classés). En général, la correspondance exacte exige que la liste classée générée corresponde exactement à la vérité terrain, c'est-à-dire que chaque élément des deux listes doit être dans le même ordre. Cela dit, si la vérité terrain se compose de plusieurs séquences correctes, la correspondance exacte ne nécessite que la sortie du modèle corresponde à l'une des séquences correctes.
exemple
Les valeurs d'une ligne de caractéristiques et éventuellement un libellé. Les exemples d'apprentissage supervisé se répartissent en deux catégories générales :
- Un exemple étiqueté se compose d'une ou de plusieurs caractéristiques et d'une étiquette. Des exemples étiquetés sont utilisés pendant l'entraînement.
- Un exemple non étiqueté se compose d'une ou plusieurs caractéristiques, mais pas d'étiquette. Les exemples sans étiquette sont utilisés lors de l'inférence.
Par exemple, supposons que vous entraîniez un modèle pour déterminer l'influence des conditions météorologiques sur les résultats des élèves aux tests. Voici trois exemples annotés :
| Fonctionnalités | Libellé | ||
|---|---|---|---|
| Température | Humidité | Pression | Note du test |
| 15 | 47 | 998 | Bonne |
| 19 | 34 | 1020 | Excellente |
| 18 | 92 | 1012 | Médiocre |
Voici trois exemples non étiquetés :
| Température | Humidité | Pression | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
La ligne d'un ensemble de données est généralement la source brute d'un exemple. Autrement dit, un exemple se compose généralement d'un sous-ensemble des colonnes de l'ensemble de données. De plus, les caractéristiques d'un exemple peuvent également inclure des caractéristiques synthétiques, telles que des caractéristiques croisées.
Pour en savoir plus, consultez Apprentissage supervisé dans le cours "Introduction au machine learning".
replay d'expérience
Dans l'apprentissage par renforcement, une technique DQN est utilisée pour réduire les corrélations temporelles dans les données d'entraînement. L'agent stocke les transitions d'état dans un tampon de relecture, puis échantillonne les transitions du tampon de relecture pour créer des données d'entraînement.
effet expérimentateur
Voir biais de confirmation.
problème d'explosion du gradient
Tendance des gradients dans les réseaux de neurones profonds (en particulier les réseaux de neurones récurrents) à devenir étonnamment abrupts (élevés). Les gradients abrupts entraînent souvent des mises à jour très importantes des pondérations de chaque nœud d'un réseau neuronal profond.
Les modèles souffrant du problème d'explosion du gradient deviennent difficiles, voire impossibles à entraîner. L'écrêtement du gradient peut atténuer ce problème.
À comparer au problème de la disparition du gradient.
Synthèse extrême (xsum)
Ensemble de données permettant d'évaluer la capacité d'un LLM à résumer un seul document. Chaque entrée de l'ensemble de données se compose des éléments suivants :
- Document rédigé par la British Broadcasting Corporation (BBC).
- Un résumé d'une phrase de ce document.
Pour en savoir plus, consultez Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization.
F
F1
Métrique de classification binaire "cumulée" qui repose à la fois sur la précision et le rappel. Voici la formule :
factualité
Dans le monde du ML, il s'agit d'une propriété décrivant un modèle dont la sortie est basée sur la réalité. La factualité est un concept plutôt qu'une métrique. Par exemple, supposons que vous envoyez la requête suivante à un grand modèle de langage :
Quelle est la formule chimique du sel de table ?
Un modèle qui optimise la factualité répondrait :
NaCl
Il est tentant de supposer que tous les modèles doivent être basés sur la factualité. Toutefois, certains prompts, tels que ceux ci-dessous, devraient inciter un modèle d'IA générative à optimiser la créativité plutôt que la factualité.
Raconte-moi un limerick sur un astronaute et une chenille.
Il est peu probable que le limerick obtenu soit basé sur la réalité.
À comparer à l'ancrage.
contrainte d'équité
Appliquer une contrainte à un algorithme pour s'assurer qu'une ou plusieurs définitions de l'équité sont respectées. Voici quelques exemples de contraintes d'équité :- Post-traitez la sortie de votre modèle.
- Modifier la fonction de perte pour intégrer une pénalité en cas de non-respect d'une métrique d'équité.
- Ajouter directement une contrainte mathématique à un problème d'optimisation.
métrique d'équité
Définition mathématique de l'équité qui est mesurable. Voici quelques métriques d'équité couramment utilisées :
De nombreuses métriques d'équité s'excluent mutuellement. Pour en savoir plus, consultez Incompatibilité des métriques d'équité.
Faux négatif (FN)
Exemple dans lequel le modèle a prédit à tort la classe négative. Par exemple, le modèle prédit qu'un e-mail particulier n'est pas du spam (classe négative), alors qu'en réalité, il l'est.
taux de faux négatifs
Proportion d'exemples positifs réels pour lesquels le modèle a prédit à tort la classe négative. La formule suivante permet de calculer le taux de faux négatifs :
Pour en savoir plus, consultez Seuils et matrice de confusion dans le Cours d'initiation au machine learning.
Faux positif (FP)
Exemple dans lequel le modèle prédit à tort la classe positive. Par exemple, le modèle prédit qu'un e-mail particulier est du spam (classe positive), alors qu'en réalité ce n'est pas un courrier indésirable.
Pour en savoir plus, consultez Seuils et matrice de confusion dans le Cours d'initiation au machine learning.
taux de faux positifs (TFP) (false positive rate (FPR))
Proportion d'exemples négatifs réels pour lesquels le modèle a prédit à tort la classe positive. La formule suivante permet de calculer le taux de faux positifs :
Le taux de faux positifs correspond à l'abscisse d'une courbe ROC.
Pour en savoir plus, consultez Classification : ROC et AUC dans le Cours d'initiation au machine learning.
régression rapide
Technique d'entraînement permettant d'améliorer les performances des LLM. La décroissance rapide consiste à diminuer rapidement le taux d'apprentissage pendant l'entraînement. Cette stratégie permet d'éviter le surapprentissage du modèle par rapport aux données d'entraînement et d'améliorer la généralisation.
fonctionnalité
Variable d'entrée d'un modèle de machine learning. Un exemple se compose d'une ou de plusieurs caractéristiques. Par exemple, supposons que vous entraîniez un modèle pour déterminer l'influence des conditions météorologiques sur les résultats des élèves aux tests. Le tableau suivant présente trois exemples, chacun contenant trois caractéristiques et un libellé :
| Fonctionnalités | Libellé | ||
|---|---|---|---|
| Température | Humidité | Pression | Note du test |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
À comparer à label.
Pour en savoir plus, consultez Apprentissage supervisé dans le cours "Introduction au Machine Learning".
croisement de caractéristiques
Une caractéristique synthétique formée en "croisant" des caractéristiques catégorielles ou regroupées dans des bins.
Par exemple, prenons un modèle de "prévision de l'humeur" qui représente la température dans l'un des quatre buckets suivants :
freezingchillytemperatewarm
et représente la vitesse du vent dans l'un des trois buckets suivants :
stilllightwindy
Sans croisements de caractéristiques, le modèle linéaire s'entraîne indépendamment sur chacun des sept buckets précédents. Ainsi, le modèle s'entraîne sur freezing indépendamment de l'entraînement sur windy.
Vous pouvez également créer un croisement de caractéristiques entre la température et la vitesse du vent. Cette caractéristique synthétique aurait les 12 valeurs possibles suivantes :
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Grâce aux croisements de caractéristiques, le modèle peut apprendre les différences d'humeur entre un jour freezing-windy et un jour freezing-still.
Si vous créez une caractéristique synthétique à partir de deux caractéristiques comportant chacune de nombreux buckets différents, le croisement de caractéristiques obtenu aura un nombre énorme de combinaisons possibles. Par exemple, si une caractéristique comporte 1 000 buckets et l'autre 2 000, la caractéristique croisée résultante comporte 2 000 000 de buckets.
Formellement, un croisement est un produit cartésien.
Les croisements de caractéristiques sont principalement utilisés avec les modèles linéaires et rarement avec les réseaux de neurones.
Pour en savoir plus, consultez Données catégorielles : croisements de caractéristiques dans le Cours d'initiation au machine learning.
l'ingénierie des caractéristiques.
Processus comprenant les étapes suivantes :
- Déterminer les caractéristiques susceptibles d'être utiles pour entraîner un modèle.
- Convertir les données brutes de l'ensemble de données en versions efficaces de ces caractéristiques.
Par exemple, vous pouvez déterminer que temperature peut être une fonctionnalité utile. Vous pouvez ensuite tester le bucketing pour optimiser ce que le modèle peut apprendre à partir de différentes plages de temperature.
L'ingénierie des caractéristiques est parfois appelée extraction de caractéristiques ou featurisation.
Pour en savoir plus, consultez Données numériques : comment un modèle ingère des données à l'aide de vecteurs de caractéristiques dans le cours intensif sur le machine learning.
extraction de caractéristiques
Terme complexe qui a une des définitions suivantes :
- Récupérer les représentations de caractéristiques intermédiaires calculées par un modèle non supervisé ou pré-entraîné (par exemple, les valeurs de la couche cachée dans un réseau de neurones) pour les utiliser en entrée dans un autre modèle.
- Synonyme d'ingénierie des caractéristiques.
importance des caractéristiques.
Synonyme de importance des variables.
ensemble de fonctionnalités
Groupe des caractéristiques utilisées pour l'entraînement de votre modèle de machine learning. Par exemple, un ensemble de caractéristiques simple pour un modèle qui prédit les prix des logements peut se composer du code postal, de la taille du bien et de son état.
spécification des caractéristiques
Décrit les informations requises pour extraire les données des features du tampon de protocole tf.Example. Étant donné que le tampon de protocole tf.Example n'est qu'un conteneur de données, vous devez spécifier les éléments suivants :
- Données à extraire (c'est-à-dire les clés des caractéristiques)
- Type de données (par exemple, float ou int)
- Longueur (fixe ou variable)
vecteur de caractéristiques
Tableau des valeurs de caractéristiques constituant un exemple. Le vecteur de caractéristiques est saisi lors de l'entraînement et de l'inférence. Par exemple, le vecteur de caractéristiques d'un modèle comportant deux caractéristiques discrètes peut être le suivant :
[0.92, 0.56]
Chaque exemple fournit des valeurs différentes pour le vecteur de caractéristiques. Le vecteur de caractéristiques pour l'exemple suivant pourrait donc ressembler à ceci :
[0.73, 0.49]
L'ingénierie des caractéristiques détermine comment représenter les caractéristiques dans le vecteur de caractéristiques. Par exemple, une caractéristique catégorielle binaire avec cinq valeurs possibles peut être représentée avec un encodage one-hot. Dans ce cas, la partie du vecteur de caractéristiques pour un exemple particulier se composerait de quatre zéros et d'un seul 1.0 à la troisième position, comme suit :
[0.0, 0.0, 1.0, 0.0, 0.0]
Prenons un autre exemple. Supposons que votre modèle comporte trois caractéristiques :
- une caractéristique catégorielle binaire avec cinq valeurs possibles représentées avec l'encodage one-hot (par exemple,
[0.0, 1.0, 0.0, 0.0, 0.0]) ; - une autre caractéristique catégorielle binaire avec trois valeurs possibles représentées avec l'encodage one-hot (par exemple,
[0.0, 0.0, 1.0]) ; - une caractéristique à virgule flottante, par exemple :
8.3.
Dans ce cas, le vecteur de caractéristiques de chaque exemple serait représenté par neuf valeurs. Compte tenu des exemples de valeurs de la liste précédente, le vecteur de caractéristiques serait le suivant :
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Pour en savoir plus, consultez Données numériques : comment un modèle ingère des données à l'aide de vecteurs de caractéristiques dans le cours intensif sur le machine learning.
featurization
Processus d'extraction de caractéristiques à partir d'une source d'entrée, telle qu'un document ou une vidéo, et de mappage de ces caractéristiques dans un vecteur de caractéristiques.
Certains experts en ML utilisent le terme "featurisation" comme synonyme d'ingénierie des caractéristiques ou d'extraction de caractéristiques.
apprentissage fédéré
Une approche de machine learning distribué qui entraîne les modèles de machine learning à l'aide d'exemples décentralisés stockés sur des appareils, par exemple des smartphones. Dans l'apprentissage fédéré, un sous-ensemble d'appareils télécharge le modèle actuel à partir d'un serveur de coordination central. Les appareils utilisent les exemples stockés sur eux pour améliorer le modèle. Les appareils importent ensuite les améliorations du modèle (mais pas les exemples d'entraînement) sur le serveur de coordination, où elles sont agrégées avec d'autres mises à jour pour obtenir un modèle global amélioré. Une fois l'agrégation effectuée, les mises à jour du modèle calculées par les appareils ne sont plus nécessaires et peuvent être supprimées.
Comme les exemples d'entraînement ne sont jamais importés, l'apprentissage fédéré respecte les principes de confidentialité de la collecte de données ciblée et de la minimisation des données.
Pour en savoir plus, consultez la bande dessinée sur l'apprentissage fédéré.
commentaires
Étape d'une boucle agentique dans laquelle l'agent évalue l'action entreprise lors de l'étape agir. Par exemple, si l'agent a envoyé une requête d'API lors de la phase d'action, la phase de commentaires peut déterminer si la réponse de l'API a abouti.
boucle de rétroaction
En machine learning, situation dans laquelle les prédictions d'un modèle influencent les données d'entraînement du même modèle ou d'un autre modèle. Par exemple, un modèle qui recommande des films influencera les films que les utilisateurs verront, ce qui influencera ensuite les modèles de recommandation de films ultérieurs.
Pour en savoir plus, consultez Systèmes de ML de production : questions à poser dans le cours d'initiation au machine learning.
réseau de neurones feedforward (FFN)
Réseau de neurones sans connexions cycliques ni récursives. Par exemple, les réseaux de neurones profonds traditionnels sont des réseaux de neurones feedforward. À comparer aux réseaux de neurones récurrents, qui sont cycliques.
apprentissage few-shot
Approche du machine learning, souvent utilisée pour la classification d'objets, conçue pour entraîner des modèles de classification efficaces à partir d'un petit nombre d'exemples d'entraînement.
Voir aussi apprentissage one-shot et apprentissage zero-shot.
prompting few-shot
Une requête contenant plusieurs exemples ("few-shot") montrant comment le grand modèle de langage doit répondre. Par exemple, l'invite longue suivante contient deux exemples montrant à un grand modèle de langage comment répondre à une requête.
| Composantes d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | La question à laquelle vous souhaitez que le LLM réponde. |
| France : EUR | Voici un exemple. |
| Royaume-Uni : GBP | Autre exemple. |
| Inde : | Requête réelle. |
Le prompting few-shot produit généralement des résultats plus intéressants que le prompting zero-shot et le prompting one-shot. Toutefois, le prompting few-shot nécessite un prompt plus long.
Le prompting few-shot est une forme d'apprentissage few-shot appliquée à l'apprentissage basé sur les requêtes.
Pour en savoir plus, consultez Ingénierie des requêtes dans le Cours d'initiation au machine learning.
Violon
Bibliothèque de configuration Python-first qui définit les valeurs des fonctions et des classes sans code ni infrastructure invasifs. Dans le cas de Pax et d'autres bases de code de ML, ces fonctions et classes représentent les modèles et les hyperparamètres d'entraînement.
Fiddle suppose que les bases de code de machine learning sont généralement divisées en :
- Code de la bibliothèque, qui définit les couches et les optimiseurs.
- Code "glue" de l'ensemble de données, qui appelle les bibliothèques et relie tous les éléments.
Fiddle capture la structure d'appel du code de colle sous une forme non évaluée et mutable.
affinage
Deuxième passe d'entraînement spécifique à une tâche effectuée sur un modèle pré-entraîné pour affiner ses paramètres pour un cas d'utilisation spécifique. Par exemple, la séquence d'entraînement complète de certains grands modèles de langage est la suivante :
- Pré-entraînement : entraînez un grand modèle de langage sur un vaste ensemble de données générales, comme toutes les pages Wikipédia en anglais.
- Affinage : entraînez le modèle pré-entraîné à effectuer une tâche spécifique, comme répondre à des questions médicales. L'affinage implique généralement des centaines ou des milliers d'exemples axés sur la tâche spécifique.
Autre exemple : la séquence d'entraînement complète pour un grand modèle d'image est la suivante :
- Pré-entraînement : entraînez un grand modèle d'image sur un vaste ensemble de données d'images générales, comme toutes les images de Wikimedia Commons.
- Affinage : entraînez le modèle pré-entraîné pour qu'il effectue une tâche spécifique, comme générer des images d'épaulards.
L'affinage peut impliquer n'importe quelle combinaison des stratégies suivantes :
- Modification de tous les paramètres existants du modèle pré-entraîné. On parle parfois d'affinage complet.
- Modification de certains paramètres existants du modèle pré-entraîné (généralement, les couches les plus proches de la couche de sortie), tout en conservant les autres paramètres existants (généralement, les couches les plus proches de la couche d'entrée). Consultez la section Affinage d'un sous-ensemble de paramètres.
- Ajouter des calques, généralement au-dessus des calques existants les plus proches du calque de sortie.
L'optimisation est une forme d'apprentissage par transfert. Par conséquent, l'affinage peut utiliser une fonction de perte ou un type de modèle différents de ceux utilisés pour entraîner le modèle pré-entraîné. Par exemple, vous pouvez affiner un grand modèle d'image pré-entraîné pour produire un modèle de régression qui renvoie le nombre d'oiseaux dans une image d'entrée.
Comparez et opposez le fine-tuning aux termes suivants :
Pour en savoir plus, consultez Finetuning dans le cours d'initiation au machine learning.
Modèle Flash
Une famille de modèles Gemini relativement petits, optimisés pour la vitesse et la faible latence. Les modèles Flash sont conçus pour un large éventail d'applications où des réponses rapides et un débit élevé sont essentiels.
Flax
Bibliothèque Open Source hautes performances pour le deep learning, basée sur JAX. Flax fournit des fonctions pour entraîner des réseaux de neurones, ainsi que des méthodes pour évaluer leurs performances.
Flaxformer
Transformer est une bibliothèque Open Source basée sur Flax, conçue principalement pour le traitement du langage naturel et la recherche multimodale.
Portail d'oubli
Partie d'une cellule LSTM qui régule le flux d'informations dans la cellule. Les portes d'oubli maintiennent le contexte en décidant quelles informations supprimer de l'état de la cellule.
modèle de fondation
Un modèle pré-entraîné très volumineux, entraîné sur un ensemble d'entraînement énorme et diversifié. Un modèle de fondation peut effectuer les deux opérations suivantes :
- répondre correctement à un large éventail de requêtes ;
- Servir de modèle de base pour un affinage supplémentaire ou d'autres personnalisations.
En d'autres termes, un modèle de fondation est déjà très performant de manière générale, mais il peut être personnalisé davantage pour devenir encore plus utile pour une tâche spécifique.
fraction de succès
Métrique permettant d'évaluer le texte généré par un modèle de ML. La fraction de succès correspond au nombre de résultats textuels générés "réussis" divisé par le nombre total de résultats textuels générés. Par exemple, si un grand modèle de langage a généré 10 blocs de code, dont cinq ont réussi, la fraction de succès serait de 50 %.
Bien que la fraction de succès soit largement utile dans les statistiques, dans le ML, cette métrique est principalement utile pour mesurer les tâches vérifiables telles que la génération de code ou les problèmes mathématiques.
softmax complet
Synonyme de softmax.
À comparer à l'échantillonnage de candidats.
Pour en savoir plus, consultez Réseaux de neurones : classification multiclasse dans le Cours d'initiation au Machine Learning.
couche entièrement connectée
Une couche cachée dans laquelle chaque nœud est connecté à chaque nœud de la couche cachée suivante.
Les couches entièrement connectées sont également appelées couches denses.
Transformation de fonction
Fonction qui prend une fonction en entrée et renvoie une fonction transformée en sortie. JAX utilise des transformations de fonctions.
G
GAN
Abréviation de réseaux antagonistes génératifs.
Gemini
Écosystème comprenant l'IA la plus avancée de Google. Voici quelques éléments de cet écosystème :
- Différents modèles Gemini.
- Interface de conversation interactive avec un modèle Gemini. Les utilisateurs saisissent des requêtes et Gemini y répond.
- Diverses API Gemini.
- Divers produits professionnels basés sur les modèles Gemini, par exemple Gemini pour Google Cloud.
Modèles Gemini
Modèles multimodaux de pointe de Google basés sur Transformer. Les modèles Gemini sont spécifiquement conçus pour s'intégrer aux agents.
Les utilisateurs peuvent interagir avec les modèles Gemini de différentes manières, y compris via une interface de dialogue interactive et des SDK.
Gemma
Une famille de modèles ouverts et légers basés sur les mêmes recherches et technologies que celles utilisées pour créer les modèles Gemini. Plusieurs modèles Gemma sont disponibles, chacun offrant des fonctionnalités différentes, telles que la vision, le code et le suivi d'instructions. Pour en savoir plus, consultez Gemma.
IA générative
Abréviation de IA générative.
généralisation
Capacité d'un modèle à effectuer des prédictions correctes pour des données nouvelles, qui n'ont encore jamais été vues. Un modèle capable de généraliser est l'opposé d'un modèle en surapprentissage.
Pour en savoir plus, consultez Généralisation dans le Cours d'initiation au Machine Learning.
courbe de généralisation
Graphique de la perte d'entraînement et de la perte de validation en fonction du nombre d'itérations.
Une courbe de généralisation peut vous aider à détecter un éventuel surapprentissage. Par exemple, la courbe de généralisation suivante suggère un surapprentissage, car la perte de validation devient finalement beaucoup plus élevée que la perte d'entraînement.
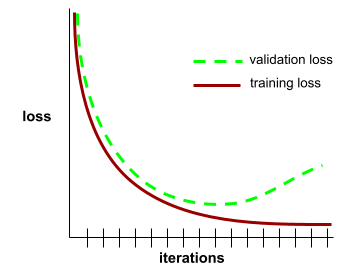
Pour en savoir plus, consultez Généralisation dans le Cours d'initiation au Machine Learning.
modèle linéaire généralisé
Généralisation des modèles de régression des moindres carrés, qui sont basés sur le bruit gaussien, à d'autres types de modèles basés sur d'autres types de bruit, tels que le bruit de Poisson ou le bruit catégoriel. Exemples de modèles linéaires généralisés :
- Régression logistique
- régression multiclasses
- régression des moindres carrés
Les paramètres d'un modèle linéaire généralisé peuvent être déterminés via une optimisation convexe.
Les modèles linéaires généralisés présentent les propriétés suivantes :
- La prédiction moyenne du modèle de régression des moindres carrés optimal est égale à l'étiquette moyenne des données d'entraînement.
- La probabilité moyenne prédite par le modèle de régression logistique optimal est égale au libellé moyen des données d'entraînement.
La puissance d'un modèle linéaire généralisé est limitée par ses caractéristiques. Contrairement à un modèle profond, un modèle linéaire généralisé ne peut pas "apprendre de nouvelles caractéristiques".
texte généré
Texte généré par un modèle de ML. Lors de l'évaluation de grands modèles de langage, certaines métriques comparent le texte généré au texte de référence. Par exemple, supposons que vous essayiez de déterminer l'efficacité d'un modèle de ML pour traduire du français vers le néerlandais. Dans ce cas :
- Le texte généré est la traduction en néerlandais fournie par le modèle de ML.
- Le texte de référence est la traduction en néerlandais créée par un traducteur humain (ou un logiciel).
Notez que certaines stratégies d'évaluation n'impliquent pas de texte de référence.
réseau antagoniste génératif (GAN)
Système permettant de créer des données dans lequel un générateur crée des données et un discriminateur détermine la validité de ces données.
Pour en savoir plus, consultez le cours sur les réseaux antagonistes génératifs.
agents génératifs (simulacres)
Agents dotés de personnalités, de souvenirs et de routines uniques qui simulent un comportement humain réaliste.
Pour en savoir plus, consultez Generative Agents: Interactive Simulacra of Human Behavior.
IA générative
Il s'agit d'un domaine de transformation émergent sans définition formelle. Cela dit, la plupart des experts s'accordent à dire que les modèles d'IA générative peuvent créer ("générer") des contenus qui sont à la fois :
- complexe
- cohérent
- originale
Voici quelques exemples d'IA générative :
- Les grands modèles de langage, qui peuvent générer du texte original sophistiqué et répondre à des questions.
- Modèle de génération d'images, qui peut produire des images uniques.
- Modèles de génération audio et musicale, qui peuvent composer de la musique originale ou générer des voix réalistes.
- Les modèles de génération de vidéos, qui peuvent générer des vidéos originales.
Certaines technologies plus anciennes, y compris les LSTM et les RNN, peuvent également générer des contenus originaux et cohérents. Certains experts considèrent ces technologies antérieures comme de l'IA générative, tandis que d'autres estiment que la véritable IA générative nécessite des résultats plus complexes que ceux que ces technologies antérieures peuvent produire.
À comparer au ML prédictif.
modèle génératif
Concrètement, un modèle qui effectue l'une des opérations suivantes :
- Crée (génère) de nouveaux exemples à partir de l'ensemble de données d'entraînement. Par exemple, un modèle génératif pourrait créer de la poésie à l'issue d'un entraînement sur un ensemble de données de poèmes. La partie générateur d'un réseau antagoniste génératif entre dans cette catégorie.
- Détermine la probabilité qu'un nouvel exemple provienne de l'ensemble d'entraînement, ou ait été créé à partir du même mécanisme à l'origine de l'ensemble d'entraînement. Par exemple, après un entraînement sur un ensemble de données de phrases en anglais, un modèle génératif pourrait déterminer la probabilité qu'une nouvelle entrée est une phrase anglaise valide.
Un modèle génératif peut théoriquement discerner la distribution des exemples ou des caractéristiques particulières dans un ensemble de données. Par exemple :
p(examples)
Les modèles d'apprentissage non supervisé sont génératifs.
À comparer aux modèles discriminatifs.
générateur
Sous-système d'un réseau antagoniste génératif qui crée de nouveaux exemples.
À comparer au modèle discriminatif.
Impureté de Gini
Métrique semblable à l'entropie. Les splitters utilisent des valeurs dérivées de l'impureté de Gini ou de l'entropie pour composer des conditions pour les arbres de décision de classification. Le gain d'information est dérivé de l'entropie. Il n'existe pas de terme équivalent universellement accepté pour la métrique dérivée de l'impureté de Gini. Toutefois, cette métrique sans nom est tout aussi importante que le gain d'information.
L'impureté de Gini est également appelée indice de Gini ou simplement Gini.
ensemble de données de référence
Ensemble de données sélectionnées manuellement qui capturent la vérité terrain. Les équipes peuvent utiliser un ou plusieurs ensembles de données de référence pour évaluer la qualité d'un modèle.
Certains ensembles de données de référence capturent différents sous-domaines de vérité terrain. Par exemple, un ensemble de données de référence pour la classification d'images peut capturer les conditions d'éclairage et la résolution des images.
réponse optimale
Une réponse reconnue comme étant de bonne qualité. Par exemple, prenons le prompt suivant :
2 + 2
La réponse idéale est la suivante :
4
Google AI Studio
Outil Google qui fournit une interface conviviale pour tester et créer des applications à l'aide des grands modèles de langage de Google. Pour en savoir plus, consultez la page d'accueil de Google AI Studio.
GPT (Generative Pre-trained Transformer)
Une famille de grands modèles de langage basés sur Transformer développés par OpenAI.
Les variantes GPT peuvent s'appliquer à plusieurs modalités, y compris :
- la génération d'images (par exemple, ImageGPT) ;
- génération d'images à partir de texte (par exemple, DALL-E).
gradient
Vecteur des dérivées partielles calculées pour l'ensemble des variables indépendantes. Dans le machine learning, le gradient correspond au vecteur des dérivées partielles de la fonction du modèle. Le gradient indique toujours la direction de la croissance maximale.
accumulation de gradients
Technique de rétropropagation qui met à jour les paramètres une seule fois par époque, et non une fois par itération. Après le traitement de chaque mini-lot, l'accumulation de gradient met simplement à jour un total cumulé de gradients. Ensuite, après avoir traité le dernier mini-batch de l'époque, le système met enfin à jour les paramètres en fonction du total de toutes les modifications de gradient.
L'accumulation de gradients est utile lorsque la taille du lot est très grande par rapport à la quantité de mémoire disponible pour l'entraînement. Lorsque la mémoire est un problème, la tendance naturelle est de réduire la taille du lot. Toutefois, la réduction de la taille du lot dans la rétropropagation normale augmente le nombre de mises à jour des paramètres. L'accumulation de gradients permet au modèle d'éviter les problèmes de mémoire tout en s'entraînant efficacement.
arbres de décision à boosting de gradient (GBT)
Type de forêt de décision dans lequel :
- L'entraînement repose sur le gradient boosting.
- Le modèle faible est un arbre de décision.
Pour en savoir plus, consultez Arbres de décision à boosting de gradient dans le cours sur les forêts de décision.
gradient boosting
Algorithme d'entraînement dans lequel des modèles faibles sont entraînés pour améliorer de manière itérative la qualité (réduire la perte) d'un modèle fort. Par exemple, un modèle faible peut être un modèle linéaire ou un petit modèle d'arbre de décision. Le modèle fort devient la somme de tous les modèles faibles précédemment entraînés.
Dans la forme la plus simple du boosting de gradient, à chaque itération, un modèle faible est entraîné pour prédire le gradient de perte du modèle fort. Ensuite, la sortie du modèle fort est mise à jour en soustrayant le gradient prédit, de la même manière que la descente de gradient.
où :
- $F_{0}$ est le modèle de départ.
- $F_{i+1}$ est le prochain modèle fort.
- $F_{i}$ est le modèle fort actuel.
- $\xi$ est une valeur comprise entre 0,0 et 1,0 appelée rétrécissement, qui est analogue au taux d'apprentissage dans la descente de gradient.
- $f_{i}$ est le modèle faible entraîné pour prédire le gradient de perte de $F_{i}$.
Les variantes modernes du boosting de gradient incluent également la dérivée seconde (hessien) de la perte dans leur calcul.
Les arbres de décision sont souvent utilisés comme modèles faibles dans le boosting de gradient. Consultez Arbres de décision à boosting de gradient.
bornage du gradient
Mécanisme couramment utilisé pour atténuer le problème d'explosion du gradient en limitant artificiellement (clipping) la valeur maximale des gradients lors de l'utilisation de la descente de gradient pour entraîner un modèle.
descente de gradient
Technique mathématique permettant de minimiser la perte. La descente de gradient ajuste de manière itérative les pondérations et les biais afin de trouver progressivement la meilleure combinaison pour minimiser la perte.
La descente de gradient est beaucoup plus ancienne que le machine learning.
Pour en savoir plus, consultez la section Régression linéaire : descente de gradient du cours d'initiation au machine learning.
graphique
Dans TensorFlow, les spécifications du calcul. Les nœuds du graphe représentent des opérations. Les bords sont orientés et représentent le passage du résultat d'une opération (un Tensor) en tant qu'opérande vers une autre opération. Pour visualiser un graphique, utilisez TensorBoard.
exécution de graphe
Environnement de programmation TensorFlow dans lequel le programme commence par construire un graphe, puis exécute tout ou partie de ce graphe. L'exécution de graphe est le mode d'exécution par défaut dans TensorFlow 1.x.
À comparer à l'exécution eager.
stratégie gourmande
Dans l'apprentissage par renforcement, une stratégie qui choisit toujours l'action avec le retour attendu le plus élevé.
ancrage
Propriété d'un modèle dont la sortie est basée (ancrée) sur un matériel source spécifique. Par exemple, supposons que vous fournissiez un manuel de physique complet en entrée ("contexte") à un grand modèle de langage. Ensuite, vous posez une question de physique à ce grand modèle de langage. Si la réponse du modèle reflète des informations contenues dans ce manuel, alors ce modèle est ancré sur ce manuel.
Notez qu'un modèle ancré n'est pas toujours un modèle factuel. Par exemple, le manuel de physique saisi peut contenir des erreurs.
grounding
Processus consistant à baser tout ou partie de la réponse d'un LLM sur des informations extraites d'une ou plusieurs sources fiables. Par exemple, supposons qu'un utilisateur demande à un LLM les prévisions météo pour aujourd'hui à Berlin. Le LLM peut ancrer la réponse sur les informations qu'il recueille auprès du Centre européen de prévisions météorologiques à moyen terme.
La génération augmentée par récupération (RAG) est une technique d'ancrage courante.
vérité terrain
La réalité.
Ce qui s'est réellement passé.
Prenons l'exemple d'un modèle de classification binaire qui prédit si un étudiant de première année d'université obtiendra son diplôme dans les six ans. La vérité terrain pour ce modèle est de savoir si l'élève a obtenu son diplôme dans les six ans.
biais de représentativité
Fait de supposer que ce qui s'applique à un individu s'applique également à tous les membres du groupe auquel cet individu appartient. Les effets du biais de représentativité peuvent être exacerbés si un échantillonnage de commodité est utilisé pour la collecte de données. Dans un échantillon non représentatif, il est possible de faire des attributions qui ne reflètent pas la réalité.
Voir aussi biais d'homogénéité de l'exogroupe et biais d'appartenance. Pour en savoir plus, consultez également Équité : types de biais dans le cours d'initiation au machine learning.
garde-fous
Tout logiciel ou processus qui empêche de nuire aux humains ou aux systèmes. Les préjudices peuvent se présenter sous de nombreuses formes, y compris la prévention des fuites de données ou des accès non autorisés, ou la garantie que les réponses d'un LLM ne contiennent pas de contenu choquant.
H
hallucination
Production de résultats qui semblent plausibles, mais qui sont factuellement incorrects, par un modèle d'IA générative qui prétend faire une affirmation sur le monde réel. Par exemple, un modèle d'IA générative qui affirme que Barack Obama est décédé en 1865 hallucine.
hachage
Dans le machine learning, un mécanisme qui permet de faire un binning des données catégorielles par classe, en particulier lorsque le nombre de catégories est grand, mais que le nombre de catégories figurant réellement dans l'ensemble de données est comparativement faible.
Par exemple, la Terre abrite environ 73 000 espèces d'arbres. Vous pouvez représenter chacune des 73 000 espèces d'arbres dans 73 000 ensembles de catégories distinctes. Ou bien, si seulement 200 de ces espèces d'arbres figurent réellement dans un ensemble de données, vous pouvez utiliser le hachage pour diviser les espèces d'arbres en 500 ensembles, par exemple.
Un même bucket peut contenir plusieurs espèces d'arbres. Par exemple, le hachage pourrait placer le baobab et l'érable rouge dans le même ensemble, même si ces deux espèces sont génétiquement dissemblables. Quoi qu'il en soit, le hachage reste un bon moyen de mapper de grands ensembles catégoriels au nombre sélectionné de ensembles. Le hachage transforme une caractéristique catégorique comportant un grand nombre de valeurs possibles en un nombre de valeurs bien plus réduit en regroupant les valeurs de manière déterministe.
Pour en savoir plus, consultez Données catégorielles : vocabulaire et encodage one-hot dans le Cours d'initiation au Machine Learning.
heuristique
Solution simple et rapide à un problème. Par exemple, "Avec une heuristique, nous avons atteint une précision de 86 %. Lorsque nous avons opté pour un réseau de neurones profond, la précision a atteint 98 %."
couche cachée
Couche d'un réseau de neurones entre la couche d'entrée (les caractéristiques) et la couche de sortie (la prédiction). Chaque couche cachée est constituée d'un ou de plusieurs neurones. Par exemple, le réseau de neurones suivant contient deux couches cachées, la première avec trois neurones et la seconde avec deux neurones :
Un réseau de neurones profond contient plus d'une couche cachée. Par exemple, l'illustration précédente est un réseau de neurones profond, car le modèle contient deux couches cachées.
Pour en savoir plus, consultez Réseaux de neurones : nœuds et couches cachées dans le Cours d'initiation au Machine Learning.
clustering hiérarchique
Catégorie d'algorithmes de clustering qui créent un arbre de clusters. Le clustering hiérarchique est parfaitement adapté aux données hiérarchiques, telles que les catégories botaniques. Il existe deux types d'algorithmes de clustering hiérarchique :
- Le clustering agglomératif assigne d'abord chaque exemple à son propre cluster, puis fusionne de manière itérative les clusters les plus proches pour créer un arbre hiérarchique.
- Le clustering divisif regroupe d'abord tous les exemples en un cluster, puis divise le cluster de manière itérative en un arbre hiérarchique.
À comparer au clustering basé sur centroïde.
Pour en savoir plus, consultez la section Algorithmes de clustering du cours sur le clustering.
escalade de colline
Algorithme permettant d'améliorer de manière itérative ("monter une côte") un modèle de ML jusqu'à ce qu'il cesse de s'améliorer ("atteigne le sommet d'une côte"). La forme générale de l'algorithme est la suivante :
- Créez un modèle de départ.
- Créez des modèles candidats en apportant de petites modifications à la façon dont vous entraînez ou affinez vos modèles. Cela peut impliquer de travailler avec un ensemble d'entraînement légèrement différent ou avec des hyperparamètres différents.
- Évaluez les nouveaux modèles candidats et effectuez l'une des actions suivantes :
- Si un modèle candidat surpasse le modèle de départ, il devient le nouveau modèle de départ. Dans ce cas, répétez les étapes 1, 2 et 3.
- Si aucun modèle ne surpasse le modèle de départ, vous avez atteint le sommet de la colline et devez arrêter d'itérer.
Consultez le Playbook sur le réglage du deep learning pour obtenir des conseils sur le réglage des hyperparamètres. Consultez les modules de données du Cours d'initiation au Machine Learning pour obtenir des conseils sur l'ingénierie des caractéristiques.
perte de marge maximale
Famille de fonctions de perte pour la classification conçue pour trouver la frontière de décision la plus éloignée possible de chaque exemple d'entraînement, afin de maximiser la marge entre les exemples et la frontière. Les KSVMs utilisent la marge maximale (ou une fonction associée, par exemple le carré de la marge maximale). Dans le cas de la classification binaire, la fonction de perte de marge maximale est définie ainsi :
où y est l'étiquette réelle (-1 ou +1) et y' est la sortie brute du modèle de classification :
Par conséquent, le graphique de la marge maximale en fonction de (y * y') est de la forme suivante :

biais historique
Type de biais qui existe déjà dans le monde et qui s'est retrouvé dans un ensemble de données. Ces biais ont tendance à refléter les stéréotypes culturels, les inégalités démographiques et les préjugés existants à l'encontre de certains groupes sociaux.
Par exemple, prenons un modèle de classification qui prédit si un demandeur de prêt manquera ou non à ses obligations de remboursement. Ce modèle a été entraîné sur des données historiques de défaut de paiement de prêts datant des années 1980, provenant de banques locales de deux communautés différentes. Si les anciens demandeurs de la communauté A étaient six fois plus susceptibles de ne pas rembourser leurs prêts que ceux de la communauté B, le modèle pourrait apprendre un biais historique, ce qui le rendrait moins susceptible d'approuver les prêts dans la communauté A, même si les conditions historiques qui ont entraîné des taux de défaut plus élevés dans cette communauté n'étaient plus pertinentes.
Pour en savoir plus, consultez Équité : types de biais dans le cours d'initiation au machine learning.
données de validation
Exemples intentionnellement non utilisés ("exclus") pendant l'entraînement. L'ensemble de données de validation et l'ensemble de données de test sont des exemples de données exclues. Les données de validation permettent d'évaluer la capacité de votre modèle à être généralisé à des données autres que celles utilisées pour l'apprentissage. La perte de l'ensemble de données exclues permet de mieux estimer la perte d'un ensemble de données non vues jusqu'à présent que la perte de l'ensemble d'entraînement.
hôte
Lors de l'entraînement d'un modèle de ML sur des puces d'accélérateur (GPU ou TPU), la partie du système qui contrôle les deux éléments suivants :
- Le flux global du code.
- Extraction et transformation du pipeline d'entrée.
L'hôte s'exécute généralement sur un processeur, et non sur une puce d'accélération. Le périphérique manipule les Tensors sur les puces d'accélération.
évaluation humaine
Processus dans lequel des personnes évaluent la qualité de la sortie d'un modèle de ML. Par exemple, des personnes bilingues peuvent évaluer la qualité d'un modèle de traduction de ML. L'évaluation humaine est particulièrement utile pour juger les modèles qui n'ont pas de réponse unique.
À comparer à l'évaluation automatique et à l'évaluation par un évaluateur automatique.
human-in-the-loop (avec intervention humaine)
Expression idiomatique mal définie qui peut signifier l'une des deux choses suivantes :
- Une règle qui consiste à examiner de manière critique ou sceptique les résultats de l'IA générative.
- Stratégie ou système permettant de s'assurer que les utilisateurs contribuent à façonner, évaluer et affiner le comportement d'un modèle. Le fait de garder un humain dans la boucle permet à une IA de bénéficier à la fois de l'intelligence artificielle et de l'intelligence humaine. Par exemple, un système dans lequel une IA génère du code que des ingénieurs logiciels examinent ensuite est un système avec supervision humaine.
hyperparamètre
Variables que vous ou un service de réglage des hyperparamètres ajustez lors des exécutions successives de l'entraînement d'un modèle. Le taux d'apprentissage, par exemple, est un hyperparamètre. Vous pouvez définir le taux d'apprentissage sur 0,01 avant une session d'entraînement. Si vous déterminez que 0,01 est trop élevé, vous pouvez peut-être définir le taux d'apprentissage sur 0,003 pour la prochaine session d'entraînement.
En revanche, les paramètres sont les différents poids et biais que le modèle apprend pendant l'entraînement.
Pour en savoir plus, consultez Régression linéaire : hyperparamètres dans le Cours d'initiation au Machine Learning.
hyperplan
Limite qui sépare un espace en deux sous-espaces. Par exemple, une ligne est un hyperplan en deux dimensions et un plan est un hyperplan en trois dimensions. Plus généralement, en machine learning, un hyperplan est la limite qui sépare un espace de grande dimension. Les machines à vecteurs de support à noyau utilisent les hyperplans pour séparer les classes positives et négatives, souvent dans un espace de très grande dimension.
I
i.i.d.
Abréviation de variables indépendantes et identiquement distribuées.
reconnaissance d'image
Processus de classification des objets, des formes ou des concepts dans une image. La reconnaissance d'image est également appelée classification d'images.
ensemble de données déséquilibré
Synonyme d'ensemble de données avec déséquilibre des classes.
biais implicite
Fait de faire automatiquement une association ou une hypothèse sur la base de ses propres modèles mentaux et souvenirs. Le biais implicite peut avoir une incidence sur les points suivants :
- Manière dont les données sont collectées et classées.
- Manière dont les systèmes de machine learning sont conçus et développés.
Par exemple, lors de la création d'un modèle de classification pour identifier des photos de mariage, un ingénieur peut utiliser comme caractéristique une robe blanche trouvée sur une photo. Cependant, les robes blanches ne sont d'usage que dans certaines cultures et, de surcroît, seulement à certaines époques.
Voir aussi biais de confirmation.
imputation
Forme abrégée de imputation de valeurs.
incompatibilité des métriques d'équité
L'idée que certaines notions d'équité sont mutuellement incompatibles et ne peuvent pas être satisfaites simultanément. Par conséquent, il n'existe pas de métrique universelle unique pour quantifier l'équité qui puisse être appliquée à tous les problèmes de ML.
Bien que cela puisse sembler décourageant, l'incompatibilité des métriques d'équité n'implique pas que les efforts d'équité sont vains. Au lieu de cela, il suggère que l'équité doit être définie de manière contextuelle pour un problème de ML donné, dans le but de prévenir les préjudices spécifiques à ses cas d'utilisation.
Pour en savoir plus sur l'incompatibilité des métriques d'équité, consultez On the (im)possibility of fairness.
apprentissage en contexte
Synonyme de requête few-shot.
variables indépendantes et identiquement distribuées (i.i.d)
Données issues d'une distribution qui ne change pas et où chaque valeur tirée ne dépend pas des valeurs tirées précédemment. Un i.i.d. est le gaz parfait du machine learning : c'est une construction mathématique utile qui ne se rencontre quasiment jamais à l'identique dans le monde réel. Par exemple, la distribution des visiteurs d'une page Web peut être une variable idd sur une courte période, c'est-à-dire que la distribution ne change pas pendant cette période et que la visite d'un internaute est généralement indépendante de la visite d'un autre. Toutefois, si vous élargissez cette période, des différences saisonnières peuvent apparaître dans les visiteurs de la page Web.
Voir aussi non-stationnarité.
équité individuelle
Métrique d'équité qui vérifie si des individus semblables sont classés de manière similaire. Par exemple, l'Académie Brobdingnagian peut souhaiter satisfaire l'équité individuelle en s'assurant que deux élèves ayant obtenu des notes et des résultats de tests standardisés identiques ont la même probabilité d'être admis.
Notez que l'équité individuelle repose entièrement sur la façon dont vous définissez la "similarité" (dans ce cas, les notes et les résultats des tests). Vous risquez d'introduire de nouveaux problèmes d'équité si votre métrique de similarité ne tient pas compte d'informations importantes (comme la rigueur du programme d'études d'un élève).
Pour en savoir plus sur l'équité individuelle, consultez Fairness Through Awareness.
inférence
Dans le machine learning traditionnel, processus consistant à effectuer des prédictions en appliquant un modèle entraîné à des exemples sans étiquette. Pour en savoir plus, consultez Apprentissage supervisé dans le cours d'introduction au ML.
Dans les grands modèles de langage, l'inférence est le processus d'utilisation d'un modèle entraîné pour générer une réponse à une requête d'entrée.
L'inférence a une signification quelque peu différente en statistiques. Pour en savoir plus, consultez l' article Wikipédia sur l'inférence statistique.
chemin d'inférence
Dans un arbre de décision, lors de l'inférence, l'itinéraire qu'emprunte un exemple spécifique depuis la racine vers d'autres conditions, se terminant par une feuille. Par exemple, dans l'arbre de décision suivant, les flèches plus épaisses indiquent le chemin d'inférence pour un exemple avec les valeurs de caractéristiques suivantes :
- x = 7
- y = 12
- z = -3
Le chemin d'inférence de l'illustration suivante passe par trois conditions avant d'atteindre la feuille (Zeta).
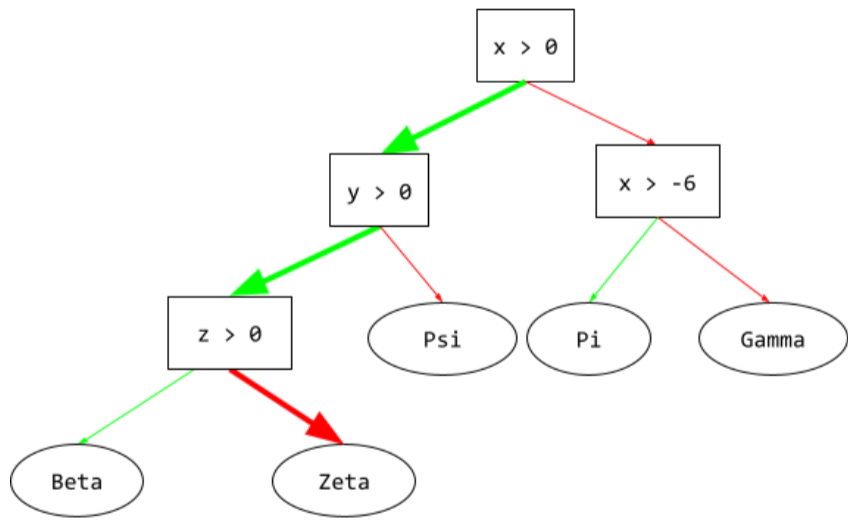
Les trois flèches épaisses indiquent le chemin d'inférence.
Pour en savoir plus, consultez Arbres de décision dans le cours "Forêts de décision".
gain d'information
Dans les forêts de décision, il s'agit de la différence entre l'entropie d'un nœud et la somme pondérée (par nombre d'exemples) de l'entropie de ses nœuds enfants. L'entropie d'un nœud correspond à l'entropie des exemples de ce nœud.
Prenons par exemple les valeurs d'entropie suivantes :
- Entropie du nœud parent = 0,6
- L'entropie d'un nœud enfant avec 16 exemples pertinents est égale à 0,2.
- Entropie d'un autre nœud enfant avec 24 exemples pertinents = 0,1
Ainsi, 40 % des exemples se trouvent dans un nœud enfant et 60 % dans l'autre. Par conséquent :
- Somme pondérée de l'entropie des nœuds enfants = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Le gain d'information est donc le suivant :
- Gain d'information = entropie du nœud parent - somme pondérée de l'entropie des nœuds enfants
- gain d'information = 0,6 – 0,14 = 0,46
La plupart des splitters cherchent à créer des conditions qui maximisent le gain d'informations.
biais d'appartenance
Faire preuve de partialité envers son propre groupe ou ses propres traits caractéristiques. Si les testeurs ou les évaluateurs sont composés d'amis, de membres de la famille ou de collègues du développeur en machine learning, alors le biais d'appartenance peut invalider le test du produit ou l'ensemble de données.
Le biais d'appartenance est une forme de biais de représentativité. Voir aussi biais d'homogénéité de l'exogroupe.
Pour en savoir plus, consultez Équité : types de biais dans le cours d'initiation au machine learning.
générateur d'entrées
Mécanisme permettant de charger des données dans un réseau de neurones.
Un générateur d'entrée peut être considéré comme un composant chargé de traiter les données brutes en Tensors, qui sont itérés pour générer des lots pour l'entraînement, l'évaluation et l'inférence.
couche d'entrée
La couche d'un réseau de neurones qui contient le vecteur de caractéristiques. Autrement dit, la couche d'entrée fournit des exemples pour l'entraînement ou l'inférence. Par exemple, la couche d'entrée du réseau de neurones suivant se compose de deux caractéristiques :
condition dans l'ensemble
Dans un arbre de décision, une condition qui teste la présence d'un élément dans un ensemble d'éléments. Par exemple, la condition suivante est une condition dans l'ensemble :
house-style in [tudor, colonial, cape]
Lors de l'inférence, si la valeur de la caractéristique de style de maison est tudor, colonial ou cape, cette condition est évaluée sur "Oui". Si la valeur de la caractéristique "style de maison" est différente (par exemple, ranch), cette condition renvoie "Non".
Les conditions d'ensemble conduisent généralement à des arbres de décision plus efficaces que les conditions qui testent les caractéristiques encodées one-hot.
instance
Synonyme d'exemple.
réglage des instructions
Forme d'affinage qui améliore la capacité d'un modèle d'IA générative à suivre des instructions. L'affinage des instructions consiste à entraîner un modèle sur une série de requêtes d'instructions, couvrant généralement un large éventail de tâches. Le modèle affiné par instruction qui en résulte a ensuite tendance à générer des réponses utiles aux requêtes zero-shot pour diverses tâches.
Comparer et différencier :
interprétabilité
Capacité à expliquer ou à présenter le raisonnement d'un modèle de ML en termes compréhensibles pour un humain.
La plupart des modèles de régression linéaire, par exemple, sont très interprétables. (Il suffit d'examiner les pondérations entraînées pour chaque fonctionnalité.) Les forêts de décision sont également très interprétables. Cependant, certains modèles nécessitent des visualisations complexes pour pouvoir être interprétés.
Vous pouvez utiliser le Learning Interpretability Tool (LIT) pour interpréter les modèles de ML.
accord inter-évaluateurs
Mesure de la fréquence à laquelle les évaluateurs humains sont d'accord lorsqu'ils effectuent une tâche. Si les évaluateurs ne sont pas d'accord, il faudra peut-être améliorer les instructions de la tâche. Parfois également appelé accord inter-annotateurs ou fiabilité inter-évaluateurs. Voir aussi le kappa de Cohen, l'une des mesures de l'accord inter-évaluateurs les plus populaires.
Pour en savoir plus, consultez Données catégorielles : problèmes courants dans le Cours d'initiation au Machine Learning.
Intersection over Union (IoU)
Intersection de deux ensembles divisée par leur union. Dans les tâches de détection d'images par machine learning, l'IoU est utilisé pour mesurer la précision du cadre de délimitation prédit par le modèle par rapport au cadre de délimitation de la vérité terrain. Dans ce cas, l'IoU des deux cadres correspond au rapport entre la zone de chevauchement et la zone totale. Sa valeur varie de 0 (aucun chevauchement entre le cadre de délimitation prédit et le cadre de délimitation de vérité terrain) à 1 (le cadre de délimitation prédit et le cadre de délimitation de vérité terrain ont exactement les mêmes coordonnées).
Par exemple, dans l'image ci-dessous :
- Le cadre de délimitation prédit (les coordonnées délimitant l'emplacement de la table de nuit dans le tableau selon le modèle) est indiqué en violet.
- Le cadre de délimitation de vérité terrain (les coordonnées délimitant l'emplacement réel de la table de nuit dans le tableau) est indiqué en vert.
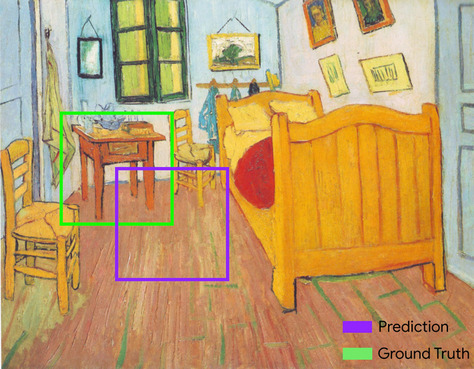
Ici, l'intersection des cadres de délimitation pour la prédiction et la vérité terrain (en bas à gauche) est de 1, et l'union des cadres de délimitation pour la prédiction et la vérité terrain (en bas à droite) est de 7. L'IoU est donc de \(\frac{1}{7}\).
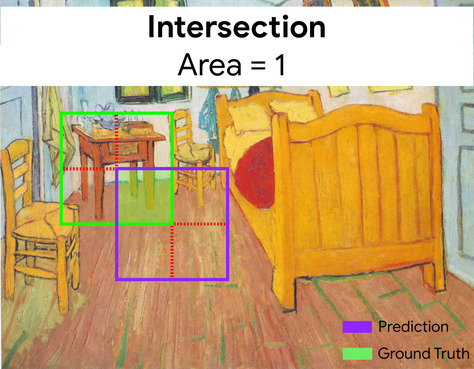
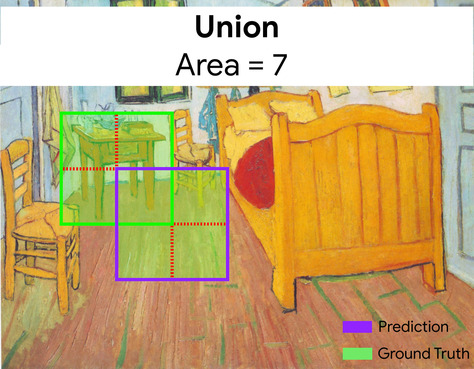
IoU
Abréviation de intersection sur union.
matrice éléments
Dans les systèmes de recommandation, une matrice de vecteurs d'embedding générée par la factorisation matricielle contient des signaux latents sur chaque élément. Chaque ligne de la matrice éléments contient la valeur d'une seule caractéristique latente pour tous les éléments. Prenons l'exemple d'un système de recommandation de films. Chaque colonne de la matrice éléments représente un seul film. Les signaux latents peuvent représenter des genres ou être des signaux plus difficiles à interpréter impliquant des interactions complexes entre des facteurs comme le genre, la note ou l'ancienneté du film.
La matrice éléments a le même nombre de colonnes que la matrice cible qui est factorisée. Par exemple, dans le cas d'un système de recommandation de films évaluant 10 000 titres de films, la matrice éléments comportera 10 000 colonnes.
éléments
Dans un système de recommandation, les entités recommandées par un système. Par exemple, les vidéos sont les éléments recommandés par un vidéo club, alors que les livres sont les éléments recommandés par une librairie.
itération
Mise à jour unique des paramètres d'un modèle (ses pondérations et ses biais) pendant l'entraînement. La taille du lot détermine le nombre d'exemples que le modèle traite en une seule itération. Par exemple, si la taille de lot est de 20, le modèle traite 20 exemples avant d'ajuster les paramètres.
Lors de l'entraînement d'un réseau de neurones, une seule itération implique les deux passes suivantes :
- Transmission directe pour évaluer la perte sur un seul lot.
- Un passage à rebours (rétropropagation) pour ajuster les paramètres du modèle en fonction de la perte et du taux d'apprentissage.
Pour en savoir plus, consultez la section Descente de gradient du cours d'initiation au machine learning.
J
JAX
Bibliothèque de calcul matriciel qui regroupe XLA (Accelerated Linear Algebra) et la différenciation automatique pour le calcul numérique hautes performances. JAX fournit une API simple et puissante pour écrire du code numérique accéléré avec des transformations composables. JAX propose des fonctionnalités telles que :
grad(différenciation automatique)jit(compilation juste-à-temps)vmap(vectorisation ou regroupement automatiques)pmap(parallélisation)
JAX est un langage permettant d'exprimer et de composer des transformations de code numérique, analogue à la bibliothèque NumPy de Python, mais dont la portée est beaucoup plus large. (En fait, la bibliothèque .numpy sous JAX est une version fonctionnellement équivalente, mais entièrement réécrite de la bibliothèque Python NumPy.)
JAX est particulièrement adapté pour accélérer de nombreuses tâches de machine learning en transformant les modèles et les données sous une forme adaptée au parallélisme sur les GPU et les puces d'accélérateur TPU.
Flax, Optax, Pax et de nombreuses autres bibliothèques sont basées sur l'infrastructure JAX.
K
Keras
API de machine learning Python populaire. Keras s'exécute sur plusieurs frameworks de deep learning, y compris TensorFlow, où il est disponible via tf.keras.
Machines à vecteurs de support à noyau (KSVM)
Algorithme de classification qui cherche à maximiser la marge entre les classes positives et négatives en associant à chaque vecteur d'entrée un vecteur dans un espace de plus grande dimension. Supposons un problème de classification dans lequel l'ensemble de données d'entrée se compose de cent caractéristiques. Afin de maximiser la marge entre les classes positives et négatives, un KVSM pourrait associer, en interne, chaque vecteur de caractéristiques à un vecteur dans un espace à un million de dimensions. Les KSVMs utilisent une fonction de perte appelée marge maximale.
points clés
Coordonnées de caractéristiques spécifiques dans une image. Par exemple, pour un modèle de reconnaissance d'images qui distingue les espèces de fleurs, les points clés peuvent être le centre de chaque pétale, la tige, l'étamine, etc.
Validation croisée à k blocs
Algorithme permettant de prédire la capacité d'un modèle à généraliser de nouvelles données. Le k dans la validation croisée à k plis fait référence au nombre de groupes égaux dans lesquels vous divisez les exemples d'un ensemble de données. Autrement dit, vous entraînez et testez votre modèle k fois. Pour chaque série d'entraînement et de tests, un groupe différent constitue l'ensemble de test, et tous les groupes restants deviennent l'ensemble d'entraînement. Après k cycles d'entraînement et de test, vous calculez la moyenne et l'écart-type des métriques de test choisies.
Par exemple, supposons que votre ensemble de données comporte 120 exemples. Supposons que vous décidiez de définir k sur 4. Par conséquent, après avoir mélangé les exemples, vous divisez l'ensemble de données en quatre groupes égaux de 30 exemples et effectuez quatre cycles d'entraînement et de test :
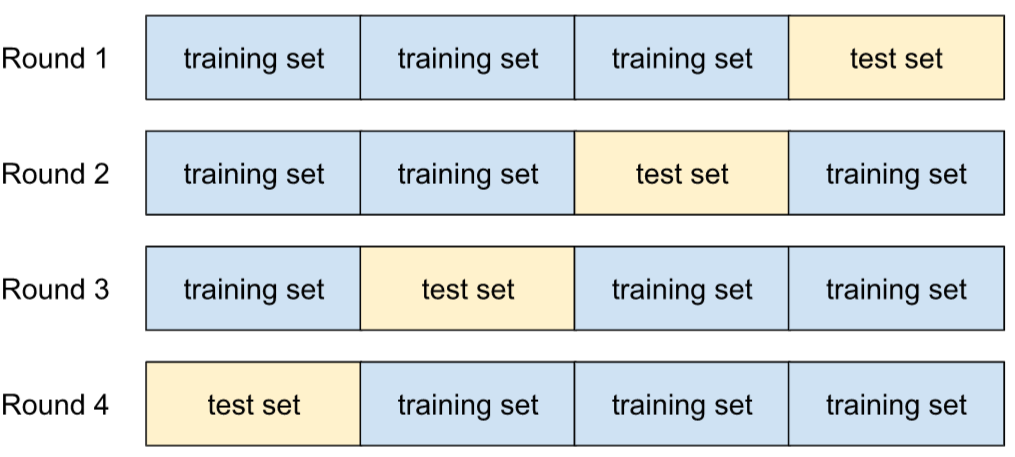
Par exemple, l'erreur quadratique moyenne (MSE) peut être la métrique la plus pertinente pour un modèle de régression linéaire. Vous devez donc trouver la moyenne et l'écart-type de l'erreur quadratique moyenne pour les quatre tours.
k-moyennes
Algorithme de clustering populaire qui regroupe des exemples dans l'apprentissage non supervisé. L'algorithme k-moyennes effectue les opérations suivantes :
- Détermination de manière itérative des meilleurs k points centraux (appelés centroïdes).
- Assignation de chaque exemple au centroïde le plus proche. Les exemples les plus proches du même centroïde font partie du même groupe.
L'algorithme k-moyennes choisit l'emplacement des centroïdes de manière à minimiser le carré cumulatif des distances entre chaque exemple et son centroïde le plus proche.
Supposons le graphe suivant représentant la taille de chiens en fonction de leur largeur :

Si k=3, l'algorithme k-moyennes déterminera trois centroïdes. Chaque exemple est assigné à son centroïde le plus proche, ce qui donne trois groupes :

Imaginons qu'un fabricant souhaite déterminer les tailles idéales pour les pulls pour chiens de petite, moyenne et grande tailles. Les trois centroïdes identifient la hauteur et la largeur moyennes de chaque chien de ce cluster. Le fabricant devrait donc probablement baser les tailles de pulls sur ces trois centroïdes. Notez que le centroïde d'un cluster n'est généralement pas un exemple dans le cluster.
Les illustrations précédentes montrent le k-means pour des exemples avec seulement deux caractéristiques (hauteur et largeur). Notez que k-means peut regrouper des exemples sur de nombreuses caractéristiques.
Pour en savoir plus, consultez Qu'est-ce que le clustering des k-moyennes ? dans le cours sur le clustering.
k-médiane
Algorithme de clustering étroitement lié à k-moyennes. La différence pratique entre les deux est la suivante :
- Dans l'algorithme k-moyennes, les centroïdes sont déterminés en minimisant la somme des carrés de la distance entre un centroïde potentiel et chacun de ses exemples.
- Dans l'algorithme k-médiane, les centroïdes sont déterminés en minimisant la somme de la distance entre un centroïde potentiel et chacun de ses exemples.
Notez que la définition du terme "distance" est également différente :
- Dans l'algorithme k-moyennes, la notion de distance utilisée est la distance euclidienne entre un centroïde et un exemple. Dans un espace à deux dimensions, la distance euclidienne revient à utiliser le théorème de Pythagore pour calculer l'hypoténuse. Par exemple, la distance k-moyennes entre (2,2) et (5,-2) est :
- Dans l'algorithme k-médiane, la notion de distance utilisée est la distance de Manhattan entre le centroïde et un exemple. Cette distance est la somme des deltas absolus dans chaque dimension. Par exemple, la distance k-médiane entre (2,2) et (5,-2) est :
L
Régularisation L0
Type de régularisation qui pénalise le nombre total de pondérations non nulles dans un modèle. Par exemple, un modèle comportant 11 pondérations non nulles sera plus pénalisé qu'un modèle similaire comportant 10 pondérations non nulles.
La régularisation L0 est parfois appelée régularisation de la norme L0.
Perte L1
Fonction de perte qui calcule la valeur absolue de la différence entre les valeurs d'étiquette réelles et les valeurs prédites par un modèle. Par exemple, voici le calcul de la perte L1 pour un batch de cinq exemples :
| Valeur réelle de l'exemple | Valeur prédite du modèle | Valeur absolue du delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = perte L1 | ||
La perte L1 est moins sensible aux valeurs aberrantes que la perte L2.
L'erreur absolue moyenne correspond à la perte L1 moyenne par exemple.
Pour en savoir plus, consultez Régression linéaire : perte dans le cours d'initiation au machine learning.
Régularisation L1
Type de régularisation qui pénalise les pondérations proportionnellement à la somme de leurs valeurs absolues. La régularisation L1 aide à mettre à zéro les pondérations des caractéristiques peu ou pas pertinentes. Une caractéristique avec un poids de 0 est effectivement supprimée du modèle.
À comparer à la régularisation L2.
Perte L2
Une fonction de perte qui calcule le carré de la différence entre les valeurs d'étiquette réelles et les valeurs prédites par un modèle. Par exemple, voici le calcul de la perte L2 pour un batch de cinq exemples :
| Valeur réelle de l'exemple | Valeur prédite du modèle | Carré du delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = perte L2 | ||
En raison de la mise au carré, la perte L2 amplifie l'influence des valeurs aberrantes. En d'autres termes, la perte L2 réagit plus fortement aux mauvaises prédictions que la perte L1. Par exemple, la perte L1 pour le lot précédent serait de 8 au lieu de 16. Notez qu'une seule valeur aberrante représente 9 des 16 valeurs.
Les modèles de régression utilisent généralement la perte L2 comme fonction de perte.
L'erreur quadratique moyenne correspond à la perte L2 moyenne par exemple. La perte quadratique est un autre nom pour la perte L2.
Pour en savoir plus, consultez Régression logistique : perte et régularisation dans le Cours d'initiation au machine learning.
Régularisation L2
Type de régularisation qui pénalise les pondérations proportionnellement à la somme des carrés des pondérations. La régularisation L2 aide à rapprocher de zéro la pondération des valeurs aberrantes (celles dont la valeur est très positive ou très négative), sans pour autant atteindre zéro. Les caractéristiques dont les valeurs sont très proches de 0 restent dans le modèle, mais n'ont pas beaucoup d'influence sur la prédiction du modèle.
La régularisation L2 améliore toujours la généralisation dans les modèles linéaires.
À comparer à la régularisation L1.
Pour en savoir plus, consultez Surapprentissage : régularisation L2 dans le cours d'initiation au machine learning.
étiquette
Dans l'apprentissage supervisé du machine learning, "réponse" ou "résultat" d'un exemple.
Chaque exemple étiqueté se compose d'une ou plusieurs caractéristiques et d'une étiquette. Par exemple, dans un ensemble de données de détection de spam, l'étiquette serait probablement "spam" ou "non spam". Dans un ensemble de données sur les précipitations, le libellé peut correspondre à la quantité de pluie tombée au cours d'une période donnée.
Pour en savoir plus, consultez Apprentissage supervisé dans "Introduction au machine learning".
exemple étiqueté
Exemple contenant une ou plusieurs caractéristiques et un libellé. Par exemple, le tableau suivant présente trois exemples étiquetés d'un modèle d'évaluation de maisons, chacun avec trois caractéristiques et une étiquette :
| Nombre de chambres | Nombre de salles de bain | Ancienneté de la maison | Prix de la maison (libellé) |
|---|---|---|---|
| 3 | 2 | 15 | $345,000 |
| 2 | 1 | 72 | 179 000 $ |
| 4 | 2 | 34 | 392 000 $ |
Dans le machine learning supervisé, les modèles sont entraînés sur des exemples étiquetés et effectuent des prédictions sur des exemples sans étiquette.
Contrastez un exemple étiqueté avec des exemples non étiquetés.
Pour en savoir plus, consultez Apprentissage supervisé dans "Introduction au machine learning".
Fuite d'étiquettes
Défaut de conception d'un modèle dans lequel une caractéristique est un substitut du libellé. Par exemple, prenons un modèle de classification binaire qui prédit si un client potentiel achètera ou non un produit spécifique.
Supposons que l'une des caractéristiques du modèle soit un booléen nommé SpokeToCustomerAgent. Supposons également qu'un agent du service client n'est attribué qu'après l'achat effectif du produit par le client potentiel. Lors de l'entraînement, le modèle apprendra rapidement l'association entre SpokeToCustomerAgent et l'étiquette.
Pour en savoir plus, consultez Surveiller les pipelines dans le Cours d'initiation au machine learning.
lambda
Synonyme de taux de régularisation.
Lambda est un terme surchargé. Ici, nous nous référons à sa définition dans le cadre de la régularisation.
LaMDA (Language Model for Dialogue Applications)
Un grand modèle de langage basé sur Transformer développé par Google et entraîné sur un grand ensemble de données de dialogue, capable de générer des réponses conversationnelles réalistes.
LaMDA : notre technologie conversationnelle révolutionnaire fournit une vue d'ensemble.
landmarks
Synonyme de points clés.
modèle de langage
Un modèle qui estime la probabilité qu'un jeton ou une séquence de jetons se produisent dans une séquence de jetons plus longue.
Pour en savoir plus, consultez Qu'est-ce qu'un modèle de langage ? dans le Cours d'initiation au Machine Learning.
grand modèle de langage
Au minimum, un modèle de langage comportant un très grand nombre de paramètres. Plus précisément, tout modèle de langage basé sur Transformer, comme Gemini ou GPT.
Pour en savoir plus, consultez Grands modèles de langage (LLM) dans le Cours d'initiation au Machine Learning.
latence
Temps nécessaire à un modèle pour traiter une entrée et générer une réponse. Une réponse à latence élevée prend plus de temps à générer qu'une réponse à latence faible.
Voici quelques facteurs qui influencent la latence des grands modèles de langage :
- Longueurs des jetons d'entrée et de sortie
- Complexité des modèles
- Infrastructure sur laquelle le modèle s'exécute
L'optimisation de la latence est essentielle pour créer des applications réactives et conviviales.
espace latent
Synonyme d'espace d'embedding.
cachée)
Ensemble de neurones dans un réseau de neurones. Voici trois types de calques courants :
- La couche d'entrée, qui fournit des valeurs pour toutes les caractéristiques.
- Une ou plusieurs couches cachées, qui trouvent des relations non linéaires entre les caractéristiques et l'étiquette.
- La couche de sortie, qui fournit la prédiction.
Par exemple, l'illustration suivante montre un réseau de neurones avec une couche d'entrée, deux couches cachées et une couche de sortie :
Dans TensorFlow, les couches sont également des fonctions Python qui prennent des Tensors et des options de configuration en entrée pour générer d'autres Tensors en sortie.
API Layers (tf.layers)
API TensorFlow pour la construction d'un réseau de neurones profond à partir de plusieurs couches. L'API Layers permet de créer différents types de couches, comme les suivants :
tf.layers.Densepour une couche entièrement connectée.tf.layers.Conv2Dpour une couche convolutive.
L'API Layers respecte les conventions de l'API Keras concernant les couches. Autrement dit, à l'exception d'un préfixe différent, toutes les fonctions de l'API Layers ont les mêmes noms et signatures que leurs homologues dans l'API Keras Layers.
feuille
Tout point de terminaison dans un arbre de décision. Contrairement à une condition, une feuille n'effectue pas de test. Une feuille est une prédiction possible. Une feuille est également le nœud terminal d'un chemin d'inférence.
Par exemple, l'arbre de décision suivant contient trois feuilles :
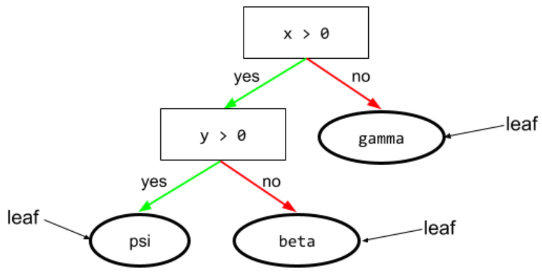
Pour en savoir plus, consultez Arbres de décision dans le cours "Forêts de décision".
Learning Interpretability Tool (LIT)
Un outil visuel et interactif de compréhension des modèles et de visualisation des données.
Vous pouvez utiliser LIT open source pour interpréter des modèles ou visualiser des données textuelles, d'images et tabulaires.
taux d'apprentissage
Nombre à virgule flottante qui indique à l'algorithme de descente de gradient le niveau d'ajustement des pondérations et des biais à chaque itération. Par exemple, un taux d'apprentissage de 0,3 ajusterait les pondérations et les biais trois fois plus fortement qu'un taux d'apprentissage de 0,1.
Le taux d'apprentissage est un hyperparamètre clé. Si vous définissez un taux d'apprentissage trop faible, l'entraînement prendra trop de temps. Si vous définissez un taux d'apprentissage trop élevé, la descente de gradient a souvent du mal à atteindre la convergence.
Pour en savoir plus, consultez Régression linéaire : hyperparamètres dans le Cours d'initiation au Machine Learning.
régression des moindres carrés
Modèle de régression linéaire entraîné en minimisant la perte L2.
prompting de la réponse la plus simple à la plus complexe
Forme de chaîne de requêtes qui divise les problèmes complexes en un ensemble ordonné de problèmes plus simples. Voici un exemple de stratégie de prompting du moins au plus pour un problème donné :
- Divisez un problème complexe en une liste ordonnée de sous-problèmes plus simples. Pour cet exemple, supposons qu'il s'agisse de trois sous-problèmes.
- Requête 1 : Demandez au LLM de résoudre le premier sous-problème. Le LLM renvoie la réponse 1.
- Requête 2 : Intégrez tout ou partie de la réponse 1 dans la requête pour résoudre le deuxième sous-problème. Le LLM renvoie la réponse 2.
- Requête 3 : Intégrez tout ou partie de la réponse 2 dans la requête pour résoudre le troisième sous-problème. La réponse du LLM à la requête 3 est la réponse "finale" au problème complexe initial.
Notez que chaque étape dépend de la solution de l'étape précédente.
À comparer au prompting "arbre de pensée".
Distance de Levenshtein
Une métrique de distance d'édition qui calcule le nombre minimal d'opérations de suppression, d'insertion et de substitution nécessaires pour transformer un mot en un autre. Par exemple, la distance de Levenshtein entre les mots "cœur" et "fléchettes" est de trois, car les trois modifications suivantes sont les moins nombreuses pour transformer un mot en l'autre :
- heart → deart (remplacer "h" par "d")
- deart → dart (supprimer le "e")
- dart → darts (ajouter un "s")
Notez que la séquence précédente n'est pas le seul chemin possible pour effectuer trois modifications.
linear
Relation entre deux variables ou plus qui peut être représentée uniquement par l'addition et la multiplication.
Le graphique d'une relation linéaire est une ligne.
À comparer à non linéaire.
modèle linéaire
Un modèle qui attribue une pondération par caractéristique pour effectuer des prédictions. (Les modèles linéaires intègrent également un biais.) En revanche, la relation entre les caractéristiques et les prédictions dans les modèles profonds est généralement non linéaire.
Les modèles linéaires sont généralement plus faciles à entraîner et plus interprétables que les modèles profonds. Toutefois, les modèles profonds peuvent apprendre des relations complexes entre les caractéristiques.
La régression linéaire et la régression logistique sont deux types de modèles linéaires.
régression linéaire
Type de modèle de machine learning dans lequel les deux conditions suivantes sont remplies :
- Le modèle est un modèle linéaire.
- La prédiction est une valeur à virgule flottante. (Il s'agit de la partie régression de la régression linéaire.)
Comparer la régression linéaire à la régression logistique. Comparez également la régression à la classification.
Pour en savoir plus, consultez Régression linéaire dans le Cours d'initiation au Machine Learning.
LIT
Abréviation de Learning Interpretability Tool (LIT), qui était auparavant connu sous le nom de Language Interpretability Tool.
LLM
Abréviation de grand modèle de langage.
Évaluations de LLM
Ensemble de métriques et de benchmarks permettant d'évaluer les performances des grands modèles de langage (LLM). De manière générale, les évaluations de LLM :
- Aider les chercheurs à identifier les domaines dans lesquels les LLM doivent être améliorés
- Elles sont utiles pour comparer différents LLM et identifier le meilleur LLM pour une tâche spécifique.
- Contribuer à garantir que les LLM sont sûrs et éthiques à utiliser.
Pour en savoir plus, consultez Grands modèles de langage (LLM) dans le cours d'initiation au Machine Learning.
régression logistique
Type de modèle de régression qui prédit une probabilité. Les modèles de régression logistique présentent les caractéristiques suivantes :
- Le libellé est catégoriel. Le terme "régression logistique" fait généralement référence à la régression logistique binaire, c'est-à-dire à un modèle qui calcule les probabilités pour les libellés avec deux valeurs possibles. Une variante moins courante, la régression logistique multinomiale, calcule les probabilités pour les libellés comportant plus de deux valeurs possibles.
- La fonction de perte pendant l'entraînement est la perte logistique. (Plusieurs unités de perte logistique multiple peuvent être placées en parallèle pour les libellés comportant plus de deux valeurs possibles.)
- Le modèle possède une architecture linéaire, et non un réseau de neurones profond. Toutefois, le reste de cette définition s'applique également aux modèles profonds qui prédisent les probabilités pour les libellés de catégories.
Prenons l'exemple d'un modèle de régression logistique qui calcule la probabilité qu'un e-mail entrant soit du spam ou non. Pendant l'inférence, supposons que le modèle prédise 0,72. Le modèle estime donc :
- L'e-mail a 72 % de chances d'être un spam.
- Il y a 28 % de chances que l'e-mail ne soit pas du spam.
Un modèle de régression logistique utilise l'architecture en deux étapes suivante :
- Le modèle génère une prédiction brute (y') en appliquant une fonction linéaire des caractéristiques d'entrée.
- Le modèle utilise cette prédiction brute comme entrée pour une fonction sigmoïde, qui convertit la prédiction brute en une valeur comprise entre 0 et 1 (exclusivement).
Comme tout modèle de régression, un modèle de régression logistique prédit un nombre. Toutefois, ce nombre fait généralement partie d'un modèle de classification binaire comme suit :
- Si le nombre prédit est supérieur au seuil de classification, le modèle de classification binaire prédit la classe positive.
- Si le nombre prédit est inférieur au seuil de classification, le modèle de classification binaire prédit la classe négative.
Pour en savoir plus, consultez Régression logistique dans le Cours d'initiation au machine learning.
logits
Vecteur de prédictions brutes (non normalisées) généré par un modèle de classification, qui est généralement transmis à une fonction de normalisation. Si le modèle résout un problème de classification multiclasse, les logits deviennent généralement une entrée de la fonction softmax. La fonction softmax génère ensuite un vecteur de probabilités (normalisées) avec une valeur pour chaque classe possible.
Perte logistique
La fonction de perte utilisée dans la régression logistique binaire.
Pour en savoir plus, consultez Régression logistique : perte et régularisation dans le Cours d'initiation au Machine Learning.
logarithme de cote
Logarithme des chances d'un événement.
LSTM (Long Short-Term Memory)
Type de cellule dans un réseau de neurones récurrents utilisé pour traiter des séquences de données dans des applications telles que la reconnaissance de l'écriture manuscrite, la traduction automatique et le sous-titrage d'images. Les LSTM résolvent le problème de disparition du gradient qui se produit lors de l'entraînement des RNN en raison de longues séquences de données. Pour ce faire, ils conservent l'historique dans un état de mémoire interne basé sur les nouvelles entrées et le contexte des cellules précédentes du RNN.
LoRA
Abréviation de Low-Rank Adaptability (adaptabilité de rang faible).
perte
Pendant l'entraînement d'un modèle supervisé, une mesure de la distance entre la prédiction d'un modèle et son libellé.
Une fonction de perte calcule la perte.
Pour en savoir plus, consultez Régression linéaire : perte dans le cours d'initiation au machine learning.
agrégateur de pertes
Type d'algorithme de machine learning qui améliore les performances d'un modèle en combinant les prédictions de plusieurs modèles et en utilisant ces prédictions pour en faire une seule. Par conséquent, un agrégateur de pertes peut réduire la variance des prédictions et améliorer la précision des prédictions.
courbe de perte
Graphique de la perte en fonction du nombre d'itérations d'entraînement. Le graphique suivant montre une courbe de perte typique :
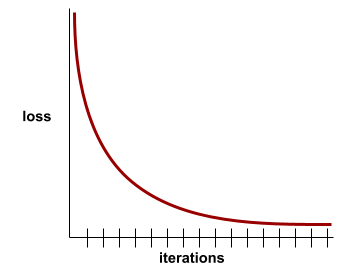
Les courbes de perte peuvent vous aider à déterminer quand votre modèle converge ou surapprend.
Les courbes de perte peuvent représenter tous les types de perte suivants :
Voir aussi courbe de généralisation.
Pour en savoir plus, consultez Surapprentissage : interpréter les courbes de perte dans le Cours d'initiation au machine learning.
fonction de perte
Pendant l'entraînement ou le test, une fonction mathématique qui calcule la perte sur un batch d'exemples. Une fonction de perte renvoie une perte plus faible pour les modèles qui font de bonnes prédictions que pour ceux qui font de mauvaises prédictions.
L'objectif de l'entraînement est généralement de minimiser la perte renvoyée par une fonction de perte.
Il existe de nombreux types de fonctions de perte. Choisissez la fonction de perte appropriée pour le type de modèle que vous créez. Exemple :
- La perte L2 (ou erreur quadratique moyenne) est la fonction de perte pour la régression linéaire.
- La perte logistique est la fonction de perte pour la régression logistique.
graphe de fonction de perte
Un graphique de pondération(s) par rapport à la perte. La descente de gradient vise à trouver les pondérations pour lesquelles le graphe de fonction de perte atteint un minimum local.
effet lost-in-the-middle
Tendance d'un LLM à utiliser plus efficacement les informations du début et de la fin d'une longue fenêtre de contexte que celles du milieu. Autrement dit, étant donné un contexte long, l'effet de perte au milieu entraîne une précision :
- Relativement élevé lorsque les informations pertinentes pour former une réponse se trouvent au début ou à la fin du contexte.
- Relativement faible lorsque les informations pertinentes pour former une réponse se trouvent au milieu du contexte.
Le terme provient de l'article Lost in the Middle: How Language Models Use Long Contexts.
Adaptabilité à faible rang (LoRA)
Il s'agit d'une technique efficace en termes de paramètres pour l'affinage qui "fige" les pondérations pré-entraînées du modèle (de sorte qu'elles ne peuvent plus être modifiées), puis insère un petit ensemble de pondérations entraînables dans le modèle. Cet ensemble de pondérations entraînables (également appelées "matrices de mise à jour") est considérablement plus petit que le modèle de base et est donc beaucoup plus rapide à entraîner.
LoRA offre les avantages suivants :
- Améliore la qualité des prédictions d'un modèle pour le domaine dans lequel l'affinage est appliqué.
- Il s'affine plus rapidement que les techniques qui nécessitent d'affiner tous les paramètres d'un modèle.
- Réduit les coûts de calcul de l'inférence en permettant la diffusion simultanée de plusieurs modèles spécialisés partageant le même modèle de base.
LSTM
Abréviation de Long Short-Term Memory.
M
machine learning
Programme ou système qui entraîne un modèle à partir de données d'entrée. Le modèle entraîné peut faire des prédictions utiles à partir de données inédites issues de la même distribution que celle utilisée pour entraîner le modèle.
Le machine learning (ou apprentissage automatique) désigne également la discipline qui traite de ces programmes ou systèmes.
Pour en savoir plus, consultez le cours Introduction au machine learning.
traduction automatique
Utilisation d'un logiciel (généralement un modèle de machine learning) pour convertir du texte d'une langue humaine à une autre, par exemple de l'anglais vers le japonais.
classe majoritaire
Étiquette la plus commune dans un ensemble de données avec déséquilibre des classes. Par exemple, pour un ensemble de données contenant 99 % d'étiquettes négatives et 1 % d'étiquettes positives, les étiquettes négatives constituent la classe majoritaire.
À comparer à la classe minoritaire.
Pour en savoir plus, consultez Ensembles de données : ensembles de données déséquilibrés dans le Cours d'initiation au Machine Learning.
agent de gestion
Agent qui contrôle un ou plusieurs sous-agents.
Processus de décision markovien (MDP)
Graphique représentant le modèle de prise de décision dans lequel des décisions (ou actions) sont prises pour parcourir une séquence d'états en supposant que la propriété de Markov est respectée. Dans l'apprentissage par renforcement, ces transitions entre les états renvoient une récompense numérique.
Propriété de Markov
Propriété de certains environnements, où les transitions d'état sont entièrement déterminées par les informations implicites dans l'état actuel et l'action de l'agent.
modèle de langage masqué
Un modèle de langage qui prédit la probabilité des jetons candidats pour remplir les blancs d'une séquence. Par exemple, un modèle de langage masqué peut calculer les probabilités pour un ou plusieurs mots candidats afin de remplacer le mot souligné dans la phrase suivante :
Le ____ dans le chapeau est revenu.
La littérature utilise généralement la chaîne "MASK" au lieu d'un trait de soulignement. Exemple :
Le "MASQUE" du chapeau est revenu.
La plupart des modèles de langage masqués modernes sont bidirectionnels.
math-pass@k
Métrique permettant de déterminer la précision d'un LLM pour résoudre un problème de mathématiques en K tentatives. Par exemple, math-pass@2 mesure la capacité d'un LLM à résoudre des problèmes mathématiques en deux tentatives. Une précision de 0,85 sur math-pass@2 indique qu'un LLM a été capable de résoudre des problèmes de mathématiques 85 % du temps en deux tentatives.
math-pass@k est identique à la métrique pass@k, sauf que le terme math-pass@k est spécifiquement utilisé pour l'évaluation mathématique.
matplotlib
Bibliothèque de traçage 2D open source écrite en Python. matplotlib vous aide à visualiser différents aspects du machine learning.
factorisation matricielle
En mathématiques, mécanisme pour trouver les matrices dont le produit scalaire se rapproche d'une matrice cible.
Dans les systèmes de recommandation, la matrice cible contient souvent les notes des utilisateurs sur les éléments. Par exemple, la matrice cible d'un système de recommandation de films peut ressembler au tableau ci-dessous, où les entiers positifs sont les notes des utilisateurs et où zéro signifie que l'utilisateur n'a pas évalué le film :
| Casablanca | Indiscrétions | Black Panther | Wonder Woman | Pulp Fiction | |
|---|---|---|---|---|---|
| Utilisateur 1 | 5.0 | 3,0 | 0,0 | 2.0 | 0,0 |
| Utilisateur 2 | 4.0 | 0,0 | 0,0 | 1.0 | 5.0 |
| Utilisateur 3 | 3,0 | 1.0 | 4.0 | 5,0 | 0,0 |
Le système de recommandation de films vise à prédire les notes des utilisateurs pour les films non évalués. Par exemple, l'utilisateur 1 va-t-il aimer Black Panther ?
Une approche pour les systèmes de recommandation consiste à utiliser la factorisation matricielle afin de générer les deux matrices suivantes :
- Une matrice utilisateur, définie sous la forme nombre d'utilisateurs X nombre de dimensions de la représentation vectorielle.
- Une matrice éléments, définie sous la forme nombre de dimensions de la représentation vectorielle X nombre d'éléments.
Par exemple, utiliser la factorisation matricielle sur nos trois utilisateurs et cinq éléments pourrait générer les matrices utilisateurs et les matrices éléments suivantes :
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
Le produit scalaire de la matrice utilisateur et de la matrice élément génère une matrice de recommandations qui contient non seulement les notes originales des utilisateurs, mais également des prédictions pour les films que chaque utilisateur n'a pas vu. Prenons par exemple la note de l'utilisateur 1 pour Casablanca, qui était de 5, 0. Le produit scalaire correspondant à cette cellule dans la matrice de recommandations devrait normalement se situer autour de 5,0, et c'est bien le cas :
(1.1 * 0.9) + (2.3 * 1.7) = 4.9Plus important encore, l'utilisateur 1 va-t-il aimer Black Panther ? En prenant le produit scalaire correspondant à la première ligne et à la troisième colonne, on obtient une note de 4,3 :
(1.1 * 1.4) + (2.3 * 1.2) = 4.3La factorisation matricielle produit généralement une matrice utilisateur et une matrice élément qui, ensemble, sont nettement plus compactes que la matrice cible.
MBPP
Abréviation de Mostly Basic Python Problems.
Erreur absolue moyenne (EAM)
Perte moyenne par exemple lorsque la perte L1 est utilisée. Pour calculer l'erreur absolue moyenne :
- Calcule la perte L1 pour un lot.
- Divisez la perte L1 par le nombre d'exemples du lot.
Prenons l'exemple du calcul de la perte L1 sur le lot de cinq exemples suivant :
| Valeur réelle de l'exemple | Valeur prédite du modèle | Perte (différence entre la valeur réelle et la valeur prédite) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = perte L1 | ||
La perte L1 est donc de 8 et le nombre d'exemples est de 5. L'erreur absolue moyenne est donc la suivante :
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Comparez l'erreur absolue moyenne à l'erreur quadratique moyenne et à la racine carrée de l'erreur quadratique moyenne.
Précision moyenne à k (mAP@k)
Moyenne statistique de tous les scores précision moyenne à k dans un ensemble de données de validation. La précision moyenne à k permet d'évaluer la qualité des recommandations générées par un système de recommandation.
Bien que l'expression "moyenne moyenne" semble redondante, le nom de la métrique est approprié. En effet, cette métrique trouve la moyenne de plusieurs valeurs précision moyenne à k.
Erreur quadratique moyenne (MSE)
Perte moyenne par exemple lorsque la perte L2 est utilisée. Calculez l'erreur quadratique moyenne comme suit :
- Calcule la perte L2 pour un lot.
- Divisez la perte L2 par le nombre d'exemples du lot.
Par exemple, considérons la perte sur le lot suivant de cinq exemples :
| Valeur réelle | Prédiction du modèle | Perte | Perte quadratique |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = perte L2 | |||
L'erreur quadratique moyenne est donc la suivante :
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
L'erreur quadratique moyenne est un optimiseur d'entraînement populaire, en particulier pour la régression linéaire.
Comparez l'erreur quadratique moyenne avec l'erreur absolue moyenne et la racine carrée de l'erreur quadratique moyenne.
TensorFlow Playground utilise l'erreur quadratique moyenne pour calculer les valeurs de perte.
Grille
En programmation parallèle ML, terme associé à l'attribution des données et du modèle aux puces TPU, et à la définition de la manière dont ces valeurs seront fragmentées ou répliquées.
Le terme "mesh" est complexe et peut désigner l'un des deux concepts suivants :
- Disposition physique des puces TPU.
- Construction logique abstraite permettant de mapper les données et le modèle aux puces TPU.
Dans les deux cas, un maillage est spécifié en tant que forme.
méta-apprentissage
Sous-ensemble du machine learning qui découvre ou améliore un algorithme d'apprentissage. Un système de méta-apprentissage peut également viser à entraîner un modèle pour qu'il apprenne rapidement une nouvelle tâche à partir d'une petite quantité de données ou de l'expérience acquise lors de tâches précédentes. Les algorithmes de méta-apprentissage tentent généralement d'atteindre les objectifs suivants :
- Améliorer ou apprendre des caractéristiques conçues à la main (comme un initialiseur ou un optimiseur).
- Être plus efficace en termes de données et de calculs.
- Améliorer la généralisation.
Le méta-apprentissage est lié à l'apprentissage few-shot.
metric
Statistique qui vous intéresse.
Un objectif est une métrique qu'un système de machine learning tente d'optimiser.
API Metrics (tf.metrics)
API TensorFlow permettant d'évaluer des modèles. Par exemple, tf.metrics.accuracy détermine la fréquence à laquelle les prédictions d'un modèle correspondent aux libellés.
mini-lot
Petit sous-ensemble, sélectionné aléatoirement, d'un lot traité en une seule itération. La taille de lot d'un mini-lot est généralement comprise entre 10 et 1 000 exemples.
Par exemple, supposons que l'ensemble d'entraînement complet (le lot complet) se compose de 1 000 exemples. Supposons également que vous définissez la taille de lot de chaque mini-lot sur 20. Par conséquent, chaque itération détermine la perte sur 20 exemples aléatoires sur les 1 000,puis ajuste les poids et les biais en conséquence.
Il est bien plus efficace de calculer la perte pour un mini-lot que pour l'ensemble des exemples du lot complet.
Pour en savoir plus, consultez Régression linéaire : hyperparamètres dans le Cours d'initiation au Machine Learning.
descente de gradient stochastique par mini-lots
Algorithme de descente de gradient qui utilise des mini-lots. En d'autres termes, la descente de gradient stochastique par mini-lots estime le gradient à partir d'un petit sous-ensemble des données d'entraînement. La descente de gradient stochastique standard utilise un mini-lot de taille 1.
perte minimax
Fonction de perte pour les réseaux antagonistes génératifs, basée sur l'entropie croisée entre la distribution des données générées et des données réelles.
La perte minimax est utilisée dans le premier article pour décrire les réseaux antagonistes génératifs.
Pour en savoir plus, consultez Fonctions de perte dans le cours sur les réseaux antagonistes génératifs.
classe minoritaire
Étiquette la moins commune dans un ensemble de données avec déséquilibre des classes. Par exemple, pour un ensemble de données contenant 99 % d'étiquettes négatives et 1 % d'étiquettes positives, les étiquettes positives constituent la classe minoritaire.
À comparer à la classe majoritaire.
Pour en savoir plus, consultez Ensembles de données : ensembles de données déséquilibrés dans le Cours d'initiation au Machine Learning.
mixture of experts
Schéma permettant d'accroître l'efficacité d'un réseau de neurones en n'utilisant qu'un sous-ensemble de ses paramètres (appelé expert) pour traiter un jeton ou un exemple d'entrée donné. Un réseau de gating achemine chaque jeton ou exemple d'entrée vers le ou les experts appropriés.
Pour en savoir plus, consultez l'un des articles suivants :
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts avec routage Expert Choice
ML
Abréviation de machine learning (apprentissage automatique).
MMIT
Abréviation de multimodal instruction-tuned (multimodal adapté aux instructions).
MNIST
Ensemble de données du domaine public compilé par LeCun, Cortes et Burges qui contient 60 000 images montrant chacune un chiffre manuscrit compris entre 0 et 9. Chaque image est stockée sous forme de tableau d'entiers 28x28, chaque entier représentant une valeur d'échelle de gris comprise entre 0 et 255 inclus.
MNIST est un ensemble de données canonique pour le machine learning, souvent utilisé pour tester de nouvelles approches de machine learning. Pour en savoir plus, consultez la base de données MNIST de chiffres écrits à la main.
modality
Catégorie de données de haut niveau. Par exemple, les nombres, le texte, les images, les vidéos et l'audio sont cinq modalités différentes.
modèle
En général, il s'agit de toute construction mathématique qui traite des données d'entrée et renvoie des données de sortie. En d'autres termes, un modèle est l'ensemble des paramètres et de la structure nécessaires à un système pour effectuer des prédictions. Dans le machine learning supervisé, un modèle prend un exemple comme entrée et infère une prédiction comme sortie. Dans l'apprentissage automatique supervisé, les modèles diffèrent quelque peu. Exemple :
- Un modèle de régression linéaire se compose d'un ensemble de pondérations et d'un biais.
- Un modèle de réseau de neurones se compose des éléments suivants :
- Un ensemble de couches cachées, chacune contenant un ou plusieurs neurones.
- Les pondérations et le biais associés à chaque neurone.
- Un modèle en arbre de décision se compose des éléments suivants :
- Forme de l'arbre, c'est-à-dire le schéma selon lequel les conditions et les feuilles sont connectées.
- Conditions et feuilles
Vous pouvez enregistrer, restaurer ou copier un modèle.
L'apprentissage automatique non supervisé génère également des modèles, généralement une fonction qui peut mapper un exemple d'entrée au cluster le plus approprié.
capacité du modèle
Complexité des problèmes à travers lesquels un modèle est capable d'apprendre. Plus un modèle est capable d'apprendre à travers des problèmes complexes, plus sa capacité est grande. La capacité d'un modèle augmente généralement avec le nombre de ses paramètres. Pour une définition formelle de la capacité d'un modèle de classification, consultez Dimension VC.
mise en cascade de modèles
Système qui sélectionne le modèle idéal pour une requête d'inférence spécifique.
Imaginez un groupe de modèles, allant de très grands (avec de nombreux paramètres) à beaucoup plus petits (avec beaucoup moins de paramètres). Les très grands modèles consomment plus de ressources de calcul au moment de l'inférence que les modèles plus petits. Toutefois, les très grands modèles peuvent généralement inférer des requêtes plus complexes que les modèles plus petits. La mise en cascade des modèles détermine la complexité de la requête d'inférence, puis sélectionne le modèle approprié pour effectuer l'inférence. La principale motivation de la mise en cascade des modèles est de réduire les coûts d'inférence en sélectionnant généralement des modèles plus petits et en ne sélectionnant un modèle plus grand que pour les requêtes plus complexes.
Imaginez qu'un petit modèle s'exécute sur un téléphone et qu'une version plus grande de ce modèle s'exécute sur un serveur distant. Une bonne mise en cascade des modèles réduit les coûts et la latence en permettant au modèle plus petit de traiter les requêtes simples et en n'appelant le modèle distant que pour les requêtes complexes.
Voir aussi routeur de modèle.
parallélisme du modèle
Méthode de mise à l'échelle de l'entraînement ou de l'inférence qui place différentes parties d'un même modèle sur différents appareils. Le parallélisme des modèles permet d'entraîner des modèles trop volumineux pour tenir sur un seul appareil.
Pour implémenter le parallélisme de modèle, un système effectue généralement les opérations suivantes :
- Partitionne (divise) le modèle en parties plus petites.
- répartit l'entraînement de ces petites parties sur plusieurs processeurs. Chaque processeur entraîne sa propre partie du modèle.
- combine les résultats pour créer un seul modèle.
Le parallélisme des modèles ralentit l'entraînement.
Voir aussi parallélisme des données.
routeur de modèle
Algorithme qui détermine le modèle idéal pour l'inférence dans la mise en cascade de modèles. Un routeur de modèle est lui-même généralement un modèle de machine learning qui apprend progressivement à choisir le meilleur modèle pour une entrée donnée. Toutefois, un routeur de modèle peut parfois être un algorithme plus simple, non basé sur le machine learning.
entraînement du modèle
Processus visant à déterminer le meilleur modèle.
ME
Abréviation de mixture of experts (mélange d'experts).
Momentum
Algorithme de descente de gradient sophistiqué dans lequel une étape d'apprentissage dépend non seulement de la dérivée de l'étape actuelle, mais aussi des dérivées de la ou des étapes qui la précèdent immédiatement. L'élan consiste à calculer une moyenne mobile pondérée de manière exponentielle des gradients au fil du temps, de manière analogue à l'élan en physique. L'élan empêche parfois l'apprentissage de rester bloqué dans des minimums locaux.
Mostly Basic Python Problems (MBPP)
Ensemble de données permettant d'évaluer la capacité d'un LLM à générer du code Python. Mostly Basic Python Problems propose environ 1 000 problèmes de programmation issus du crowdsourcing. Chaque problème de l'ensemble de données contient les éléments suivants :
- Description de la tâche
- Code de solution
- Trois scénarios de test automatisés
MT
Abréviation de traduction automatique.
collaboration multi-agents
Framework dans lequel plusieurs agents IA spécialisés interagissent, débattent ou se transmettent des tâches pour résoudre un problème complexe.
classification à classes multiples
Dans l'apprentissage supervisé, un problème de classification dans lequel l'ensemble de données contient plus de deux classes d'étiquettes. Par exemple, les libellés de l'ensemble de données Iris doivent appartenir à l'une des trois classes suivantes :
- Iris setosa
- Iris virginica
- Iris versicolor
Un modèle entraîné sur l'ensemble de données Iris qui prédit le type d'iris sur de nouveaux exemples effectue une classification à classes multiples.
En revanche, les problèmes de classification qui font la distinction entre exactement deux classes sont des modèles de classification binaire. Par exemple, un modèle d'e-mail qui prédit spam ou non-spam est un modèle de classification binaire.
Dans les problèmes de clustering, la classification multiclasse fait référence à plus de deux clusters.
Pour en savoir plus, consultez Réseaux de neurones : classification multiclasse dans le cours d'initiation au machine learning.
Régression logistique multiclasses
Utilisation de la régression logistique dans les problèmes de classification multiclasses.
auto-attention multi-têtes
Extension de l'auto-attention qui applique le mécanisme d'auto-attention plusieurs fois pour chaque position de la séquence d'entrée.
Les Transformers ont introduit l'auto-attention multi-têtes.
multimodal instruction-tuned
Modèle ajusté aux instructions capable de traiter des entrées autres que du texte, comme des images, des vidéos et des contenus audio.
modèle multimodal
Modèle dont les entrées, les sorties ou les deux incluent plusieurs modalités. Prenons l'exemple d'un modèle qui prend à la fois une image et une légende (deux modalités) comme caractéristiques et génère un score indiquant l'adéquation de la légende avec l'image. Les entrées de ce modèle sont donc multimodales et la sortie est unimodale.
classification multinomiale
Synonyme de classification à classes multiples.
régression multinomiale
Synonyme de régression logistique multiclasses.
Compréhension écrite multisentence (MultiRC)
Ensemble de données permettant d'évaluer la capacité d'un LLM à répondre à des exercices à choix multiples. Chaque exemple de l'ensemble de données contient les éléments suivants :
- Paragraphe de contexte
- Une question sur ce paragraphe
- Plusieurs réponses à la question. Chaque réponse est associée à la mention "Vrai" ou "Faux". Plusieurs réponses peuvent être vraies.
Exemple :
Paragraphe de contexte :
Susan voulait organiser une fête d'anniversaire. Elle a appelé tous ses amis. Elle a cinq amis. Sa mère a dit que Susan pouvait inviter tout le monde à la fête. Sa première amie n'a pas pu venir à la fête, car elle était malade. Sa deuxième amie partait en voyage. Sa troisième amie n'était pas sûre que ses parents l'y autoriseraient. Le quatrième ami a répondu "peut-être". Le cinquième ami pourra certainement venir à la fête. Susan était un peu triste. Le jour de la fête, les cinq amis sont venus. Chaque ami avait un cadeau pour Susan. Susan était heureuse et a envoyé une carte de remerciement à chacun de ses amis la semaine suivante.
Question : L'ami malade de Susan s'est-il rétabli ?
Plusieurs réponses :
- Oui, elle s'en est remise. (True)
- Non (Faux)
- Oui. (True)
- Non, elle ne s'est pas rétablie. (Faux)
- Oui, elle était à la fête de Susan. (True)
MultiRC est un composant de l'ensemble SuperGLUE.
Pour en savoir plus, consultez Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences.
multitâche
Technique de machine learning dans laquelle un seul modèle est entraîné pour effectuer plusieurs tâches.
Les modèles multitâches sont créés en les entraînant sur des données adaptées à chacune des différentes tâches. Cela permet au modèle d'apprendre à partager des informations entre les tâches, ce qui l'aide à apprendre plus efficacement.
Un modèle entraîné pour plusieurs tâches présente souvent des capacités de généralisation améliorées et peut être plus robuste pour gérer différents types de données.
N
Nano
Un modèle Gemini relativement petit, conçu pour une utilisation sur l'appareil. Pour en savoir plus, consultez Gemini Nano.
Piège NaN
Lorsqu'un nombre du modèle devient un NaN pendant l'entraînement et que, à la suite de ce changement, de nombreux autres nombres du modèle, voire tous, finissent par devenir également des NaN.
NaN est l'abréviation de Not a Number (Ce n'est pas un nombre).
traitement du langage naturel
Domaine de l'enseignement aux ordinateurs pour traiter ce qu'un utilisateur a dit ou saisi à l'aide de règles linguistiques. Presque tous les systèmes modernes de traitement du langage naturel reposent sur le machine learning.compréhension du langage naturel
Sous-ensemble du traitement du langage naturel qui détermine les intentions de ce qui est dit ou saisi. La compréhension du langage naturel peut aller au-delà du traitement du langage naturel pour prendre en compte des aspects complexes du langage tels que le contexte, le sarcasme et les sentiments.
classe négative
Dans la classification binaire, une classe est dite positive et l'autre négative. La classe positive est l'élément ou l'événement que le modèle teste, et la classe négative est l'autre possibilité. Exemple :
- La classe négative d'un test médical pourrait être "pas une tumeur".
- La classe négative d'un modèle de classification d'e-mails peut être "non-spam".
À comparer à la classe positive.
échantillonnage négatif
Synonyme d'échantillonnage de candidats.
Recherche d'architecture neuronale (NAS)
Technique permettant de concevoir automatiquement l'architecture d'un réseau de neurones. Les algorithmes NAS peuvent réduire le temps et les ressources nécessaires à l'entraînement d'un réseau de neurones.
Le NAS utilise généralement :
- Un espace de recherche, qui est un ensemble d'architectures possibles.
- Une fonction de fitness, qui mesure les performances d'une architecture spécifique pour une tâche donnée.
Les algorithmes NAS commencent souvent par un petit ensemble d'architectures possibles et élargissent progressivement l'espace de recherche à mesure que l'algorithme en apprend davantage sur les architectures efficaces. La fonction de fitness est généralement basée sur les performances de l'architecture sur un ensemble d'entraînement, et l'algorithme est généralement entraîné à l'aide d'une technique d'apprentissage par renforcement.
Les algorithmes NAS se sont avérés efficaces pour trouver des architectures très performantes pour diverses tâches, y compris la classification d'images, la classification de texte et la traduction automatique.
neurones feedforward
Un modèle contenant au moins une couche cachée. Un réseau de neurones profond est un type de réseau de neurones contenant plus d'une couche cachée. Par exemple, le diagramme suivant montre un réseau de neurones profonds contenant deux couches cachées.
Chaque neurone d'un réseau de neurones se connecte à tous les nœuds de la couche suivante. Par exemple, dans le diagramme précédent, notez que chacun des trois neurones de la première couche cachée se connecte séparément aux deux neurones de la deuxième couche cachée.
Les réseaux de neurones implémentés sur des ordinateurs sont parfois appelés réseaux de neurones artificiels pour les différencier des réseaux de neurones présents dans le cerveau et d'autres systèmes nerveux.
Certains réseaux de neurones peuvent imiter des relations non linéaires extrêmement complexes entre différentes caractéristiques et le libellé.
Consultez également Réseau de neurones convolutif et Réseau de neurones récurrent.
Pour en savoir plus, consultez la section Réseaux de neurones du cours d'initiation au machine learning.
neurone
En machine learning, une unité distincte au sein d'une couche cachée d'un réseau de neurones. Chaque neurone effectue les deux actions suivantes :
- Calcule la somme pondérée des valeurs d'entrée multipliées par leurs pondérations correspondantes.
- Transmet la somme pondérée en entrée à une fonction d'activation.
Un neurone de la première couche cachée accepte les entrées des valeurs de caractéristiques dans la couche d'entrée. Un neurone de n'importe quelle couche cachée au-delà de la première accepte les entrées des neurones de la couche cachée précédente. Par exemple, un neurone de la deuxième couche cachée accepte les entrées des neurones de la première couche cachée.
L'illustration suivante met en évidence deux neurones et leurs entrées.
Un neurone dans un réseau de neurones imite le comportement des neurones dans le cerveau et d'autres parties du système nerveux.
N-gramme
Séquence ordonnée de N mots. Par exemple, vraiment follement est un 2-grammes. L'ordre a une importance : follement vraiment est un 2-grammes différent de vraiment follement.
| N | Nom(s) pour ce genre de N-gramme | Exemples |
|---|---|---|
| 2 | bigramme ou 2-gramme | to go, go to, eat lunch, eat dinner |
| 3 | trigramme ou 3-gramme | ate too much, happily ever after, the bell tolls |
| 4 | 4-gramme | walk in the park, dust in the wind, the boy ate lentils |
De nombreux modèles de compréhension du langage naturel reposent sur les N-grammes pour prédire le prochain mot que l'utilisateur saisira ou énoncera. Supposons qu'un utilisateur saisisse les mots happily ever. Un modèle NLU basé sur des trigrammes prédira probablement que le prochain mot saisi sera after.
Faire la distinction entre les N-grammes et les sacs de mots, qui sont des listes de mots non ordonnées.
Pour en savoir plus, consultez Grands modèles de langage dans le cours d'initiation au machine learning.
NLP
Abréviation de traitement du langage naturel.
NLU (Natural Language Understanding, compréhension du langage naturel) - 1st occurrence only, then use "NLU".
Abréviation de compréhension du langage naturel.
nœud (arbre de décision)
Dans un arbre de décision, toute condition ou feuille.
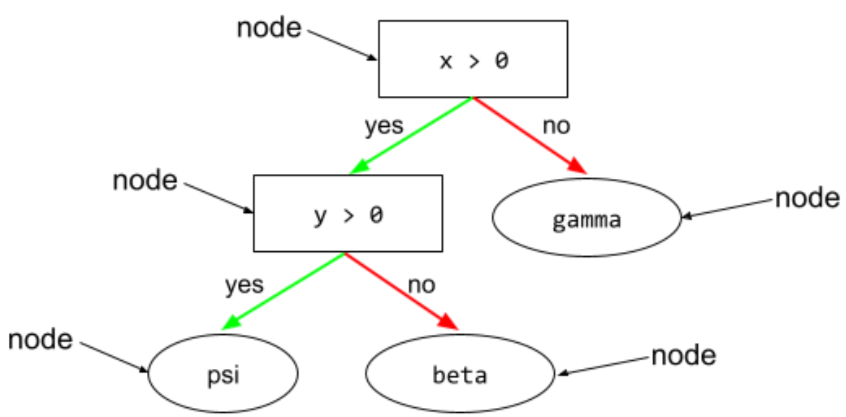
Pour en savoir plus, consultez Arbres de décision dans le cours "Forêts de décision".
nœud (réseau de neurones)
Un neurone dans une couche cachée.
Pour en savoir plus, consultez Réseaux de neurones dans le Cours d'initiation au Machine Learning.
nœud (graphe TensorFlow)
Opération dans un graphe TensorFlow.
bruit
Pour faire simple, tout ce qui masque le signal dans un ensemble de données. Du bruit peut être introduit dans les données de différentes manières. Exemple :
- Des évaluateurs humains font des erreurs concernant l'ajout d'étiquettes.
- Des instruments sont mal enregistrés ou des humains omettent des valeurs de caractéristiques.
condition non binaire
Une condition contenant plus de deux résultats possibles. Par exemple, la condition non binaire suivante contient trois résultats possibles :
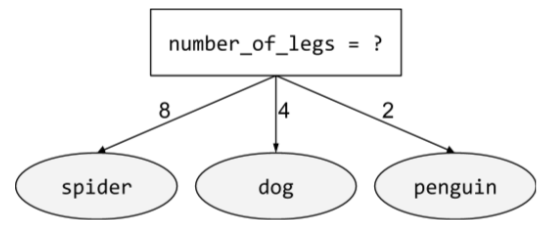
Pour en savoir plus, consultez Types de conditions dans le cours "Forêts de décision".
non déterministe
Système qui n'est pas garanti de renvoyer la même sortie pour une entrée donnée. Les LLM sont généralement non déterministes, c'est-à-dire qu'ils génèrent généralement des réponses différentes au même prompt.
Les systèmes non déterministes sont généralement beaucoup plus difficiles à tester que les systèmes déterministes.
Voir aussi probabiliste.
non linéaire
Relation entre deux variables ou plus qui ne peut pas être représentée uniquement par l'addition et la multiplication. Une relation linéaire peut être représentée sous la forme d'une ligne, contrairement à une relation non linéaire. Prenons l'exemple de deux modèles qui associent chacun une seule caractéristique à un seul libellé. Le modèle de gauche est linéaire et celui de droite est non linéaire :

Consultez Réseaux de neurones : nœuds et couches cachées dans le cours intensif sur le machine learning pour tester différents types de fonctions non linéaires.
biais de non-réponse
Voir biais de sélection.
non-stationnarité
Caractéristique dont les valeurs changent selon une ou plusieurs dimensions, généralement le temps. Par exemple, voici quelques exemples de non-stationnarité :
- Le nombre de maillots de bain vendus dans un magasin donné varie selon la saison.
- La quantité d'un fruit particulier récolté dans une région donnée est nulle pendant la majeure partie de l'année, mais importante pendant une brève période.
- En raison du changement climatique, les températures moyennes annuelles évoluent.
À comparer à la stationnarité.
aucune réponse unique (NORA, no one right answer)
Une requête ayant plusieurs réponses correctes. Par exemple, la requête suivante n'a pas qu'une seule bonne réponse :
Raconte-moi une blague amusante sur les éléphants.
Évaluer les réponses aux requêtes sans réponse unique est généralement beaucoup plus subjectif que d'évaluer les requêtes avec une réponse unique. Par exemple, pour évaluer une blague sur un éléphant, il faut une méthode systématique pour déterminer son degré d'humour.
NORA
Abréviation de no one right answer (pas de bonne réponse).
normalisation
De manière générale, le processus de conversion de la plage de valeurs réelle d'une variable en une plage de valeurs standard, par exemple :
- -1 à +1
- De 0 à 1
- Scores Z (environ de -3 à +3)
Par exemple, supposons que la plage de valeurs réelle d'une caractéristique donnée soit comprise entre 800 et 2 400. Dans le cadre de l'ingénierie des caractéristiques, vous pouvez normaliser les valeurs réelles dans une plage standard, par exemple de -1 à +1.
La normalisation est une tâche courante dans l'ingénierie des caractéristiques. Les modèles s'entraînent généralement plus rapidement (et produisent de meilleures prédictions) lorsque chaque caractéristique numérique du vecteur de caractéristiques a à peu près la même plage.
Voir aussi Normalisation du score Z.
Pour en savoir plus, consultez Données numériques : normalisation dans le Cours d'initiation au machine learning.
NotebookLM
Outil basé sur Gemini qui permet aux utilisateurs d'importer des documents, puis d'utiliser des requêtes pour poser des questions sur ces documents, les résumer ou les organiser. Par exemple, un auteur peut importer plusieurs nouvelles et demander à NotebookLM de trouver leurs thèmes communs ou d'identifier celle qui ferait le meilleur film.
détection de nouveautés
Processus permettant de déterminer si un nouvel exemple provient de la même distribution que l'ensemble d'entraînement. En d'autres termes, après l'entraînement sur l'ensemble d'entraînement, la détection de nouveautés détermine si un nouvel exemple (pendant l'inférence ou pendant l'entraînement supplémentaire) est une valeur aberrante.
À comparer à la détection des valeurs aberrantes.
données numériques
Caractéristiques représentées par des nombres entiers ou réels. Par exemple, un modèle d'évaluation de maison représenterait probablement la taille d'une maison (en pieds carrés ou en mètres carrés) sous forme de données numériques. Représenter une caractéristique sous forme de données numériques indique que les valeurs de la caractéristique ont une relation mathématique avec le libellé. Autrement dit, le nombre de mètres carrés d'une maison est probablement lié mathématiquement à sa valeur.
Toutes les données entières ne doivent pas être représentées sous forme de données numériques. Par exemple, les codes postaux de certaines régions du monde sont des nombres entiers. Toutefois, les codes postaux entiers ne doivent pas être représentés comme des données numériques dans les modèles. En effet, un code postal 20000 n'est pas deux fois (ou moitié) plus puissant qu'un code postal 10000. De plus, bien que différents codes postaux correspondent à différentes valeurs immobilières, nous ne pouvons pas supposer que les valeurs immobilières du code postal 20000 sont deux fois plus élevées que celles du code postal 10000.
Les codes postaux doivent être représentés par des données catégorielles.
Les caractéristiques numériques sont parfois appelées caractéristiques continues.
Pour en savoir plus, consultez Utiliser des données numériques dans le Cours d'initiation au Machine Learning.
NumPy
Bibliothèque mathématique Open Source qui fournit différentes opérations de tableau efficaces pour Python. pandas est basé sur NumPy.
O
objectif
Une métrique que votre algorithme tente d'optimiser.
fonction objectif
Formule mathématique ou métrique qu'un modèle vise à optimiser. Par exemple, la fonction objectif de la régression linéaire est généralement la perte quadratique moyenne. Par conséquent, lors de l'entraînement d'un modèle de régression linéaire, l'objectif est de minimiser la perte quadratique moyenne.
Dans certains cas, l'objectif est de maximiser la fonction objectif. Par exemple, si la fonction objectif est la précision, l'objectif est de maximiser la précision.
Voir aussi perte.
condition oblique
Dans un arbre de décision, une condition qui implique plusieurs caractéristiques. Par exemple, si la hauteur et la largeur sont toutes deux des caractéristiques, la condition suivante est oblique :
height > width
À comparer à la condition alignée sur les axes.
Pour en savoir plus, consultez Types de conditions dans le cours "Forêts de décision".
observer
Étape de la boucle agentique dans laquelle l'agent examine ou évalue un aspect de sa progression. Par exemple, supposons que l'étape act génère du code. Par conséquent, l'étape observe peut exécuter des tests sur le code généré.
Hors connexion
Synonyme de statique.
inférence hors connexion
Processus par lequel un modèle génère un lot de prédictions, puis met ces prédictions en cache (les enregistre). Les applications peuvent ensuite accéder à la prédiction inférée à partir du cache au lieu de réexécuter le modèle.
Prenons l'exemple d'un modèle qui génère des prévisions météo locales (prédictions) toutes les quatre heures. Après chaque exécution du modèle, le système met en cache toutes les prévisions météo locales. Les applications météo récupèrent les prévisions à partir du cache.
L'inférence hors connexion est également appelée inférence statique.
À comparer à l'inférence en ligne. Pour en savoir plus, consultez Systèmes de ML de production : inférence statique ou dynamique dans le Cours d'initiation au machine learning.
Encodage one-hot
Représentation des données catégorielles sous forme de vecteur :
- Un élément est défini sur 1.
- Tous les autres éléments sont définis sur 0.
L'encodage one-hot est couramment utilisé pour représenter des chaînes ou des identifiants qui ont un ensemble fini de valeurs possibles.
Par exemple, supposons qu'une certaine caractéristique catégorielle nommée Scandinavia comporte cinq valeurs possibles :
- "Danemark"
- "Suède"
- "Norvège"
- "Finlande"
- "Islande"
L'encodage one-hot pourrait représenter chacune des cinq valeurs comme suit :
| Pays | Vecteur | ||||
|---|---|---|---|---|---|
| "Danemark" | 1 | 0 | 0 | 0 | 0 |
| "Suède" | 0 | 1 | 0 | 0 | 0 |
| "Norvège" | 0 | 0 | 1 | 0 | 0 |
| "Finlande" | 0 | 0 | 0 | 1 | 0 |
| "Islande" | 0 | 0 | 0 | 0 | 1 |
Grâce à l'encodage one-hot, un modèle peut apprendre différentes connexions en fonction de chacun des cinq pays.
Représenter une caractéristique sous forme de données numériques est une alternative à l'encodage one-hot. Malheureusement, représenter les pays scandinaves numériquement n'est pas un bon choix. Par exemple, prenons la représentation numérique suivante :
- "Denmark" (Danemark) est défini sur 0.
- "Suède" est 1
- "Norvège" est 2
- "Finlande" est 3
- "Islande" est 4
Avec l'encodage numérique, un modèle interpréterait les nombres bruts de manière mathématique et tenterait de s'entraîner sur ces nombres. Cependant, l'Islande n'est pas deux fois plus (ou deux fois moins) que la Norvège. Le modèle tirerait donc des conclusions étranges.
Pour en savoir plus, consultez Données catégorielles : vocabulaire et encodage one-hot dans le Cours d'initiation au Machine Learning.
une seule bonne réponse (ORA, one right answer)
Une requête ayant une seule réponse correcte. Par exemple, prenons la requête suivante :
Vrai ou faux : Saturne est plus grande que Mars.
La seule réponse correcte est vrai.
À comparer à il n'y a pas qu'une seule bonne réponse.
apprentissage one-shot
Approche du machine learning, souvent utilisée pour la classification d'objets, conçue pour apprendre des modèles de classification efficaces à partir d'un seul exemple d'entraînement.
Voir aussi apprentissage few-shot et apprentissage zero-shot.
prompting one-shot
Une requête contenant un exemple montrant comment le grand modèle de langage doit répondre. Par exemple, l'invite suivante contient un exemple montrant à un grand modèle de langage comment répondre à une requête.
| Composantes d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | La question à laquelle vous souhaitez que le LLM réponde. |
| France : EUR | Voici un exemple. |
| Inde : | Requête réelle. |
Indiquer les points communs et les différences entre l'incitation one-shot et les termes suivants :
un contre tous
Face à un problème de classification avec N classes, une solution consiste en N modèles de classification binaire distincts : un modèle de classification binaire pour chaque résultat possible. Soit, par exemple, un modèle qui classe les exemples en animal, végétal ou minéral. Une solution un contre tous fournirait les trois modèles de classification binaire distincts suivants :
- animal ou non
- légume ou non
- minéral ou non minéral
online
Synonyme de dynamique.
inférence en ligne
Génération de prédictions à la demande. Par exemple, supposons qu'une application transmette une entrée à un modèle et émette une demande de prédiction. Un système utilisant l'inférence en ligne répond à la requête en exécutant le modèle (et en renvoyant la prédiction à l'application).
À comparer à l'inférence hors connexion.
Pour en savoir plus, consultez Systèmes de ML de production : inférence statique ou dynamique dans le Cours d'initiation au Machine Learning.
opération (op)
Dans TensorFlow, toute procédure qui crée, manipule ou détruit un Tensor. Par exemple, une multiplication matricielle est une opération qui prend deux Tensors en entrée et génère un Tensor en sortie.
Optax
Bibliothèque de traitement et d'optimisation des gradients pour JAX. Optax facilite la recherche en fournissant des blocs de construction qui peuvent être recombinés de manière personnalisée pour optimiser les modèles paramétriques tels que les réseaux de neurones profonds. Voici d'autres objectifs :
- Fournir des implémentations lisibles, bien testées et efficaces des composants principaux.
- Améliorer la productivité en permettant de combiner des ingrédients de bas niveau dans des optimiseurs personnalisés (ou d'autres composants de traitement des gradients).
- Accélérer l'adoption de nouvelles idées en permettant à chacun de contribuer facilement.
optimizer
Implémentation particulière de l'algorithme de descente de gradient. Voici quelques optimiseurs populaires :
- AdaGrad, qui signifie ADAptive GRADient descent (descente de gradient adaptative).
- Adam, qui signifie ADAptive with Momentum.
ORA
Abréviation de une seule bonne réponse.
biais d'homogénéité de l'exogroupe
Tendance à percevoir les membres d'un exogroupe comme plus semblables que les membres de son groupe d'appartenance lorsque l'on compare les attitudes, les valeurs, les traits de personnalité et d'autres caractéristiques. Le groupe d'appartenance désigne les personnes avec lesquelles vous interagissez régulièrement, tandis que l'exogroupe désigne les personnes avec lesquelles vous n'interagissez pas régulièrement. Si vous créez un ensemble de données en demandant à des personnes de fournir des attributs relatifs à des exogroupes, ces attributs seront probablement moins nuancés et plus stéréotypés que les attributs mis en avant quant au groupe d'appartenance des participants.
Par exemple, des Lilliputiens pourraient décrire de manière très détaillée les maisons d'autres Lilliputiens, en mentionnant de légères différences dans les styles architecturaux, les fenêtres, les portes et les dimensions. Cependant, les mêmes Lilliputiens pourraient simplement affirmer que les Brobdingnagiens habitent tous dans des maisons identiques.
Le biais d'homogénéité de l'exogroupe est une forme de biais de représentativité.
Voir aussi biais d'appartenance.
détection des valeurs aberrantes
Processus d'identification des valeurs aberrantes dans un ensemble d'entraînement.
À comparer à la détection de nouveauté.
des anomalies
Valeurs éloignées de la plupart des autres valeurs. Dans le machine learning, toutes les valeurs suivantes sont des anomalies :
- Données d'entrée dont les valeurs sont éloignées de plus de trois écarts types environ de la moyenne
- Pondérations dont la valeur absolue est élevée
- Valeurs prédites relativement éloignées des valeurs réelles
Par exemple, supposons que widget-price soit une caractéristique d'un certain modèle.
Supposons que la moyenne widget-price soit de 7 euros avec un écart-type de 1 euro. Les exemples contenant un widget-price de 12 euros ou de 2 euros seraient donc considérés comme des valeurs aberrantes, car chacun de ces prix se situe à cinq écarts-types de la moyenne.
Les valeurs aberrantes sont souvent dues à des fautes de frappe ou à d'autres erreurs de saisie. Dans d'autres cas, les valeurs aberrantes ne sont pas des erreurs. Après tout, les valeurs qui s'écartent de cinq écarts-types de la moyenne sont rares, mais pas impossibles.
Les valeurs aberrantes entraînent souvent des problèmes lors de l'entraînement du modèle. Le bornement est un moyen de gérer les anomalies.
Pour en savoir plus, consultez Utiliser des données numériques dans le Cours d'initiation au Machine Learning.
Évaluation hors sac (OOB)
Mécanisme permettant d'évaluer la qualité d'une forêt de décision en testant chaque arbre de décision par rapport aux exemples non utilisés lors de l'entraînement de cet arbre de décision. Par exemple, dans le schéma suivant, notez que le système entraîne chaque arbre de décision sur environ deux tiers des exemples, puis l'évalue par rapport au tiers restant.
L'évaluation hors sac est une approximation efficace et conservatrice du mécanisme de validation croisée. Dans la validation croisée, un modèle est entraîné pour chaque tour de validation croisée (par exemple, 10 modèles sont entraînés dans une validation croisée à 10 volets). Avec l'évaluation OOB, un seul modèle est entraîné. Étant donné que la bagging retient certaines données de chaque arbre pendant l'entraînement, l'évaluation OOB peut utiliser ces données pour approximer la validation croisée.
Pour en savoir plus, consultez Évaluation hors sac dans le cours sur les forêts de décision.
couche de sortie
Couche "finale" d'un réseau de neurones. La couche de sortie contient la prédiction.
L'illustration suivante montre un petit réseau de neurones profond avec une couche d'entrée, deux couches cachées et une couche de sortie :
surapprentissage
Création d'un modèle correspondant si étroitement aux données d'entraînement qu'il ne parvient pas à effectuer des prédictions correctes avec de nouvelles données.
La régularisation peut réduire le surapprentissage. L'entraînement sur un ensemble d'entraînement volumineux et diversifié peut également réduire le surapprentissage.
Pour en savoir plus, consultez Surapprentissage dans le Cours d'initiation au Machine Learning.
suréchantillonnage
Réutilisation des exemples d'une classe minoritaire dans un ensemble de données avec déséquilibre des classes afin de créer un ensemble d'entraînement plus équilibré.
Prenons l'exemple d'un problème de classification binaire dans lequel le ratio entre la classe majoritaire et la classe minoritaire est de 5 000:1. Si l'ensemble de données contient un million d'exemples, il ne contient qu'environ 200 exemples de la classe minoritaire, ce qui peut être trop peu pour un entraînement efficace. Pour pallier cette insuffisance, vous pouvez suréchantillonner (réutiliser) ces 200 exemples plusieurs fois, ce qui peut vous permettre d'obtenir suffisamment d'exemples pour un entraînement utile.
Vous devez faire attention au surapprentissage lorsque vous suréchantillonnez.
À comparer au sous-échantillonnage.
P
données compressées
Approche permettant de stocker les données plus efficacement.
Les données compressées sont stockées dans un format compressé ou d'une autre manière qui permet d'y accéder plus efficacement. Les données compressées minimisent la quantité de mémoire et de calcul nécessaire pour y accéder, ce qui permet un entraînement plus rapide et une inférence de modèle plus efficace.
Les données compressées sont souvent utilisées avec d'autres techniques, telles que l'augmentation des données et la régularisation, ce qui améliore encore les performances des modèles.
PaLM
Abréviation de Pathways Language Model.
pandas
API d'analyse de données orientée colonnes, basée sur numpy. De nombreux frameworks de machine learning, y compris TensorFlow, acceptent les structures de données pandas comme entrées. Pour en savoir plus, consultez la documentation de pandas.
paramètre
Les pondérations et les biais qu'un modèle apprend lors de l'entraînement. Par exemple, dans un modèle de régression linéaire, les paramètres se composent du biais (b) et de tous les poids (w1, w2, etc.) dans la formule suivante :
En revanche, les hyperparamètres sont les valeurs que vous (ou un service de réglage d'hyperparamètres) fournissez au modèle. Le taux d'apprentissage, par exemple, est un hyperparamètre.
optimisation du réglage des paramètres
Ensemble de techniques permettant d'affiner un grand modèle de langage préentraîné (PLM) plus efficacement que l'affinage complet. Le réglage des paramètres avec optimisation affine généralement beaucoup moins de paramètres que l'affinage complet, mais produit généralement un grand modèle de langage aussi performant (ou presque) qu'un grand modèle de langage créé à partir d'un affinage complet.
Comparez et opposez l'optimisation du réglage des paramètres avec :
Le réglage des paramètres avec optimisation est également appelé affinage d'un sous-ensemble de paramètres.
Serveur de paramètres (PS)
Tâche qui effectue le suivi des paramètres d'un modèle dans une configuration distribuée.
mise à jour des paramètres
Opération d'ajustement des paramètres d'un modèle pendant l'entraînement, généralement au cours d'une seule itération de descente de gradient.
dérivée partielle
Dérivée dans laquelle toutes les variables, sauf une, sont considérées comme des constantes. Par exemple, la dérivée partielle de f(x, y) par rapport à x est la dérivée de f considérée comme une fonction de x uniquement (c'est-à-dire en gardant y constant). La dérivée partielle de f par rapport à x se concentre uniquement sur l'évolution de x et ignore toutes les autres variables de l'équation.
biais de participation
Synonyme de biais de non-réponse. Voir biais de sélection.
stratégie de partitionnement
Algorithme qui répartit les variables entre les serveurs de paramètres.
pass at k (pass@k)
Métrique permettant de déterminer la qualité du code (par exemple, Python) généré par un grand modèle de langage. Plus précisément, "pass at k" indique la probabilité qu'au moins un bloc de code généré sur k blocs de code générés réussisse tous ses tests unitaires.
Les grands modèles de langage ont souvent du mal à générer du code de qualité pour les problèmes de programmation complexes. Pour résoudre ce problème, les ingénieurs logiciels demandent au grand modèle de langage de générer plusieurs (k) solutions pour le même problème. Les ingénieurs logiciels testent ensuite chacune des solutions à l'aide de tests unitaires. Le calcul de la réussite à k dépend du résultat des tests unitaires :
- Si une ou plusieurs de ces solutions réussissent le test unitaire, le LLM réussit ce défi de génération de code.
- Si aucune des solutions ne réussit le test unitaire, le LLM échoue à ce défi de génération de code.
La formule pour le taux de réussite à k est la suivante :
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
En général, des valeurs de k plus élevées produisent des scores "pass at k" plus élevés. Toutefois, des valeurs de k plus élevées nécessitent davantage de ressources de grands modèles de langage et de tests unitaires.
PaLM (Pathways Language Model)
Modèle plus ancien et prédécesseur des modèles Gemini.
Pax
Framework de programmation conçu pour entraîner des modèles de réseaux de neurones à grande échelle, si grands qu'ils s'étendent sur plusieurs tranches ou pods de puces d'accélérateur TPU.
Pax est basé sur Flax, qui est basé sur JAX.
perceptron
Système (matériel ou logiciel) qui prend une ou plusieurs valeurs d'entrée, exécute une fonction sur la somme pondérée des entrées et calcule une seule valeur de sortie. Dans le machine learning, la fonction est généralement non linéaire, comme ReLU, sigmoïde ou tanh. Par exemple, le perceptron suivant repose sur la fonction sigmoïde pour traiter trois valeurs d'entrée :
Dans l'illustration suivante, le perceptron prend trois entrées, chacune modifiée par une pondération avant d'entrer dans le perceptron :

Les perceptrons sont les neurones des réseaux de neurones.
performance
Terme complexe ayant plusieurs significations :
- Sens standard dans le génie logiciel, à savoir : à quelle vitesse, ou avec quelle efficacité, ce logiciel s'exécute-t-il ?
- Sens dans le machine learning, Ici, les performances répondent à la question suivante : quel est le degré d'exactitude de ce modèle ? Autrement dit, les prédictions du modèle sont-elles bonnes ?
Importance des variables de permutation
Type d'importance des variables qui évalue l'augmentation de l'erreur de prédiction d'un modèle après permutation des valeurs de la caractéristique. L'importance des variables de permutation est une métrique indépendante du modèle.
perplexité
Mesure de l'efficacité d'un modèle à exécuter une tâche. Par exemple, supposons que votre tâche consiste à lire les premières lettres d'un mot qu'un utilisateur saisit sur un clavier de téléphone et à proposer une liste de mots possibles pour compléter la saisie. La perplexité P pour cette tâche correspond approximativement au nombre de suggestions que vous devez proposer pour que votre liste contienne le mot que l'utilisateur essaie de saisir.
La perplexité est liée à l'entropie croisée par la formule suivante :
pipeline
Infrastructure sur laquelle repose l'algorithme de machine learning. Le pipeline inclut la collecte des données, l'intégration de celles-ci dans des fichiers de données d'entraînement, l'entraînement d'un ou plusieurs modèles, et l'exportation des modèles en production.
Pour en savoir plus, consultez Pipelines de ML dans le cours "Gérer des projets de ML".
pipelining
Forme de parallélisme de modèle dans laquelle le traitement d'un modèle est divisé en étapes consécutives, chacune étant exécutée sur un appareil différent. Pendant qu'une étape traite un lot, l'étape précédente peut travailler sur le lot suivant.
Voir aussi entraînement par étapes.
pjit
Fonction JAX qui divise le code pour l'exécuter sur plusieurs puces d'accélérateur. L'utilisateur transmet une fonction à pjit, qui renvoie une fonction ayant la même sémantique, mais compilée dans un calcul XLA qui s'exécute sur plusieurs appareils (tels que des GPU ou des cœurs TPU).
pjit permet aux utilisateurs de partitionner des calculs sans les réécrire en utilisant le partitionneur SPMD.
Depuis mars 2023, pjit a été fusionné avec jit. Pour en savoir plus, consultez Tableaux distribués et parallélisation automatique.
plan-and-solve
Stratégie agentique dans laquelle le modèle rédige d'abord un plan explicite en plusieurs étapes avant de tenter d'exécuter des actions.
PLM
Abréviation de modèle de langage pré-entraîné.
plug-in
Outil modulaire standardisé qui peut être facilement associé à un agent pour étendre ses capacités. Par exemple, un plug-in GitHub permet aux agents d'effectuer des actions telles que la lecture des problèmes GitHub et la création de demandes d'extraction.
pmap
Fonction JAX qui exécute des copies d'une fonction d'entrée sur plusieurs appareils matériels sous-jacents (processeurs, GPU ou TPU), avec différentes valeurs d'entrée. pmap s'appuie sur SPMD.
règlement
Dans l'apprentissage par renforcement, le mappage probabiliste d'un agent, des états aux actions.
pooling
Réduction d'une matrice (ou de matrices) créée par une couche convolutive antérieure à une matrice plus petite. Le pooling consiste généralement à prendre la valeur maximale ou moyenne de la zone regroupée. Soit, par exemple, la matrice 3 x 3 suivante :
![Matrice 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?hl=fr)
Une opération de pooling, tout comme une opération convolutive, divise cette matrice en tranches, puis déplace cette opération convolutive selon un certain pas. Par exemple, supposons que l'opération de pooling divise la matrice de convolution en tranches de 2x2 avec un pas de 1x1. Comme l'illustre le schéma suivant, quatre opérations de mise en commun ont lieu. Imaginons que chaque opération de pooling sélectionne la valeur maximale des quatre valeurs de cette tranche :
![La matrice d'entrée est de 3x3 avec les valeurs : [[5,3,1], [8,2,5], [9,4,3]].
La sous-matrice 2x2 en haut à gauche de la matrice d'entrée est [[5,3], [8,2]]. L'opération de pooling en haut à gauche génère donc la valeur 8 (qui est le maximum de 5, 3, 8 et 2). La sous-matrice 2x2 en haut à droite de la matrice d'entrée est [[3,1], [2,5]], donc l'opération de pooling en haut à droite donne la valeur 5. La sous-matrice 2x2 en bas à gauche de la matrice d'entrée est [[8,2], [9,4]]. L'opération de pooling en bas à gauche génère donc la valeur 9. La sous-matrice 2x2 en bas à droite de la matrice d'entrée est [[2,5], [4,3]], de sorte que l'opération de pooling en bas à droite donne la valeur 5. En résumé, l'opération de pooling génère la matrice 2x2 [[8,5], [9,5]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?hl=fr)
Le pooling permet d'appliquer l'invariance par translation dans la matrice d'entrée.
Le pooling pour les applications de vision est plus formellement connu sous le nom de pooling spatial. Les applications de séries temporelles font généralement référence au pooling en tant que pooling temporel. De manière moins formelle, le pooling est souvent appelé sous-échantillonnage ou sous-échantillonnage.
encodage positionnel
Technique permettant d'ajouter des informations sur la position d'un jeton dans une séquence à l'embedding du jeton. Les modèles Transformer utilisent l'encodage positionnel pour mieux comprendre la relation entre les différentes parties de la séquence.
Une implémentation courante de l'encodage positionnel utilise une fonction sinusoïdale. (Plus précisément, la fréquence et l'amplitude de la fonction sinusoïdale sont déterminées par la position du jeton dans la séquence.) Cette technique permet à un modèle Transformer d'apprendre à prêter attention à différentes parties de la séquence en fonction de leur position.
classe positive
Classe pour laquelle vous effectuez le test.
Par exemple, la classe positive d'un modèle de détection du cancer pourrait être "tumeur". La classe positive d'un modèle de classification d'e-mails pourrait être "spam".
À comparer à la classe négative.
post-traitement
Ajuster la sortie d'un modèle après son exécution. Le post-traitement peut être utilisé pour appliquer des contraintes d'équité sans modifier les modèles eux-mêmes.
Par exemple, il est possible d'appliquer un post-traitement à un modèle de classification binaire en définissant un seuil de classification de sorte que l'égalité des chances soit maintenue pour un attribut donné en vérifiant que le taux de vrais positifs est le même pour toutes les valeurs de cet attribut.
modèle post-entraîné
Terme mal défini qui fait généralement référence à un modèle pré-entraîné qui a subi un post-traitement, par exemple un ou plusieurs des éléments suivants :
AUC PR (aire sous la courbe de précision/rappel)
Aire sous la courbe de précision/rappel interpolée, obtenue en traçant les points (rappel, précision) pour différentes valeurs du seuil de classification.
Praxis
Bibliothèque ML de base et hautes performances de Pax. Praxis est souvent appelé "bibliothèque de calques".
Praxis contient non seulement les définitions de la classe Layer, mais aussi la plupart de ses composants associés, y compris :
- données saisies
- Bibliothèques de configuration (HParam et Fiddle)
- optimizers
Praxis fournit les définitions de la classe Model.
precision
Statistique des modèles de classification qui répond à la question suivante :
Lorsque le modèle a prédit la classe positive, quel pourcentage de prédictions étaient correctes ?
Voici la formule :
où :
- Un vrai positif signifie que le modèle a prédit correctement la classe positive.
- Un faux positif signifie que le modèle a prédit à tort la classe positive.
Par exemple, supposons qu'un modèle a effectué 200 prédictions positives. Parmi ces 200 prédictions positives :
- 150 étaient des vrais positifs.
- 50 d'entre eux étaient des faux positifs.
Dans ce cas :
À comparer à la justesse et au rappel.
Pour en savoir plus, consultez Classification : précision, rappel, exactitude et métriques associées dans le Cours d'initiation au Machine Learning.
précision à k (precision@k)
Métrique permettant d'évaluer une liste d'éléments classés (ordonnés). La précision à k identifie la fraction des k premiers éléments de cette liste qui sont "pertinents". Par exemple :
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
La valeur de k doit être inférieure ou égale à la longueur de la liste renvoyée. Notez que la longueur de la liste renvoyée ne fait pas partie du calcul.
La pertinence est souvent subjective. Même les évaluateurs humains experts ne sont pas toujours d'accord sur les éléments pertinents.
Comparer avec :
la courbe de précision/rappel
Courbe de précision par rapport au rappel à différents seuils de classification.
prédiction
Résultat d'un modèle. Exemple :
- La prédiction d'un modèle de classification binaire correspond à la classe positive ou à la classe négative.
- La prédiction d'un modèle de classification à classes multiples est une classe.
- La prédiction d'un modèle de régression linéaire est un nombre.
biais de prédiction
Valeur indiquant l'écart entre la moyenne des prédictions et la moyenne des libellés dans l'ensemble de données.
À ne pas confondre avec le biais des modèles de machine learning ni avec le biais en matière d'éthique et d'équité.
ML prédictif
Tout système de machine learning standard ("classique").
Le terme ML prédictif n'a pas de définition formelle. Il s'agit plutôt d'une catégorie de systèmes de ML non basés sur l'IA générative.
parité prédictive
Une métrique d'équité qui vérifie si, pour un modèle de classification donné, les taux de précision sont équivalents pour les sous-groupes considérés.
Par exemple, un modèle qui prédit l'acceptation dans une université respecterait la parité prédictive pour la nationalité si son taux de précision était le même pour les Lilliputiens et les Brobdingnags.
La parité prédictive est parfois appelée parité du taux de prédiction.
Pour en savoir plus sur la parité prédictive, consultez la section 3.2.1 de l'article Explication des définitions d'équité.
parité des taux prédictive
Autre nom pour la parité prédictive.
prétraitement
Traitement des données avant leur utilisation pour entraîner un modèle. Le prétraitement peut être aussi simple que la suppression des mots d'un corpus de texte anglais qui ne figurent pas dans le dictionnaire anglais, ou aussi complexe que la réexpression des points de données de manière à éliminer autant d'attributs corrélés aux attributs sensibles que possible. Le prétraitement peut aider à respecter les contraintes d'équité.modèle pré-entraîné
Bien que ce terme puisse faire référence à n'importe quel modèle ou vecteur d'embedding entraîné, le terme "modèle pré-entraîné" fait désormais généralement référence à un grand modèle de langage entraîné ou à une autre forme de modèle d'IA générative entraîné.
Voir aussi modèle de base et modèle de fondation.
auto-supervisé
Entraînement initial d'un modèle sur un grand ensemble de données. Certains modèles pré-entraînés sont des géants maladroits et doivent généralement être affinés par un entraînement supplémentaire. Par exemple, les experts en ML peuvent pré-entraîner un grand modèle de langage sur un vaste ensemble de données textuelles, comme toutes les pages en anglais de Wikipédia. Après le pré-entraînement, le modèle obtenu peut être affiné à l'aide de l'une des techniques suivantes :
- distillation
- fine-tuning
- Réglage des instructions
- Optimisation efficace en termes de paramètres
- prompt-tuning
croyance a priori
Ce que vous croyez à propos des données avant de commencer l'entraînement avec celles-ci. Par exemple, la régularisation L2 repose sur une croyance a priori selon laquelle les pondérations doivent être faibles et normalement distribuées autour de zéro.
Pro
Un modèle Gemini avec moins de paramètres que Ultra, mais plus que Nano. Pour en savoir plus, consultez Gemini Pro.
probabiliste
En général, toute situation dans laquelle des décisions sont prises en fonction de probabilités ou de chances. Les LLM sont des systèmes probabilistes qui génèrent le mot ou la phrase suivants dans une réponse en fonction des probabilités.
Si la température est relativement basse, un LLM choisira des mots ou des phrases ayant une probabilité élevée. Si la température est relativement élevée, un LLM sera plus "créatif" et choisira parfois des mots ou des phrases ayant une probabilité plus faible.
modèle de régression probabiliste
Un modèle de régression qui utilise non seulement les pondérations pour chaque caractéristique, mais aussi l'incertitude de ces pondérations. Un modèle de régression probabiliste génère une prédiction et l'incertitude de cette prédiction. Par exemple, un modèle de régression probabiliste peut générer une prédiction de 325 avec un écart-type de 12. Pour en savoir plus sur les modèles de régression probabiliste, consultez ce Colab sur tensorflow.org.
fonction de densité de probabilité
Fonction qui identifie la fréquence des échantillons de données ayant exactement une valeur spécifique. Lorsque les valeurs d'un ensemble de données sont des nombres à virgule flottante continus, les correspondances exactes sont rares. Toutefois, l'intégration d'une fonction de densité de probabilité de la valeur x à la valeur y donne la fréquence attendue des échantillons de données entre x et y.
Prenons l'exemple d'une distribution normale dont la moyenne est de 200 et l'écart-type de 30. Pour déterminer la fréquence attendue des échantillons de données compris entre 211,4 et 218,7, vous pouvez intégrer la fonction de densité de probabilité pour une distribution normale de 211,4 à 218,7.
mémoire procédurale
Dans les agents, il s'agit de la connaissance de la façon de faire quelque chose. Par exemple, un agent peut développer une mémoire procédurale sur comment effectuer une recherche sur le Web, puis afficher les trois premiers sites.
prompt
Tout texte saisi en entrée dans un grand modèle de langage pour conditionner le modèle à se comporter d'une certaine manière. Les requêtes peuvent être aussi courtes qu'une phrase ou arbitrairement longues (par exemple, le texte complet d'un roman). Les requêtes sont classées dans plusieurs catégories, y compris celles indiquées dans le tableau suivant :
| Catégorie de requête | Exemple | Remarques |
|---|---|---|
| Question | À quelle vitesse un pigeon peut-il voler ? | |
| Instruction | Écris un poème amusant sur l'arbitrage. | Requête qui demande au grand modèle de langage de faire quelque chose. |
| Exemple | Traduisez le code Markdown en HTML. Par exemple :
Markdown : * list item HTML : <ul> <li>list item</li> </ul> |
La première phrase de cet exemple de requête est une instruction. Le reste de la requête est l'exemple. |
| Rôle | Explique à un docteur en physique pourquoi la descente de gradient est utilisée dans l'entraînement du machine learning. | La première partie de la phrase est une instruction, tandis que l'expression "à un doctorat en physique" correspond à la partie du rôle. |
| Entrée partielle à compléter par le modèle | Le Premier ministre du Royaume-Uni vit au | Une invite d'entrée partielle peut se terminer brusquement (comme dans cet exemple) ou par un trait de soulignement. |
Un modèle d'IA générative peut répondre à une requête avec du texte, du code, des images, des représentations vectorielles continues, des vidéos… presque tout.
apprentissage basé sur les requêtes
Capacité de certains modèles qui leur permet d'adapter leur comportement en réponse à une entrée de texte arbitraire (requêtes). Dans un paradigme d'apprentissage basé sur les requêtes, un grand modèle de langage répond à une requête en générant du texte. Par exemple, supposons qu'un utilisateur saisisse la requête suivante :
Résume la troisième loi du mouvement de Newton.
Un modèle capable d'apprendre à partir de requêtes n'est pas spécifiquement entraîné pour répondre à la requête précédente. Le modèle "connaît" de nombreux faits sur la physique, de nombreuses règles générales de langage et de nombreuses informations sur ce qui constitue des réponses généralement utiles. Ces connaissances suffisent à fournir une réponse (espérons-le) utile. Le feedback humain supplémentaire ("Cette réponse était trop compliquée" ou "Qu'est-ce qu'une réaction ?") permet à certains systèmes d'apprentissage basés sur les requêtes d'améliorer progressivement l'utilité de leurs réponses.
chaînage de prompts
Utiliser la sortie d'un prompt comme entrée d'un autre prompt. L'incitation du moins au plus est une forme courante de chaînage d'incitations.
conception de prompts
Synonyme de prompt engineering.
prompt engineering
L'art de créer des requêtes qui déclenchent les réponses souhaitées d'un grand modèle de langage. Les humains effectuent l'ingénierie des requêtes. Pour obtenir des réponses utiles d'un grand modèle de langage, il est essentiel de rédiger des requêtes bien structurées. L'ingénierie des requêtes dépend de nombreux facteurs, y compris :
- Ensemble de données utilisé pour le pré-entraînement et éventuellement l'affinage du grand modèle de langage.
- Le paramètre temperature et d'autres paramètres de décodage que le modèle utilise pour générer des réponses.
La conception de requêtes est un synonyme de l'ingénierie des requêtes.
Pour en savoir plus sur la rédaction de requêtes utiles, consultez Présentation de la conception de requêtes.
ensemble de requêtes
Un groupe de requêtes pour évaluer un grand modèle de langage. Par exemple, l'illustration suivante montre un ensemble de requêtes composé de trois requêtes :
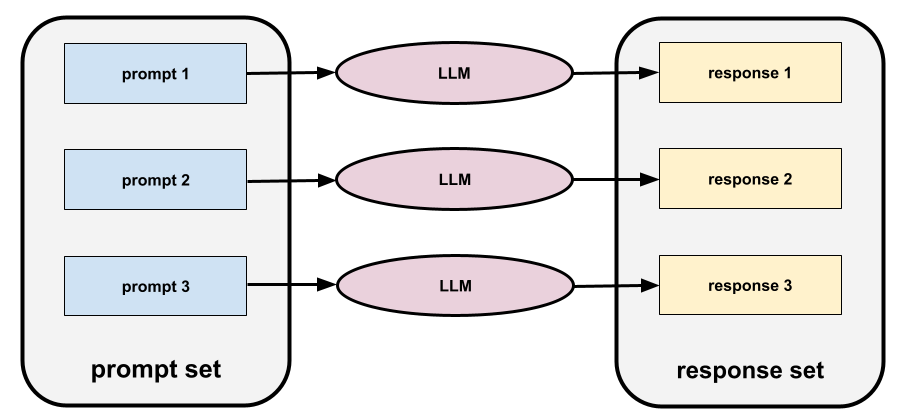
Les bons ensembles de requêtes se composent d'une collection de requêtes suffisamment "large" pour évaluer en profondeur la sécurité et l'utilité d'un grand modèle de langage.
Voir aussi ensemble de réponses.
réglage des prompts
Mécanisme d'optimisation du réglage des paramètres qui apprend un "préfixe" que le système ajoute au prompt.
Une variante du réglage des requêtes, parfois appelée réglage des préfixes, consiste à ajouter le préfixe à chaque couche. En revanche, la plupart des ajustements d'invite n'ajoutent qu'un préfixe à la couche d'entrée.
provenance
Données détaillant la façon dont un contenu multimédia numérique a été créé ou modifié.
proxy (attributs sensibles)
Attribut utilisé comme substitut d'un attribut sensible. Par exemple, le code postal d'une personne peut être utilisé comme indicateur de son revenu, de son origine ou de son appartenance ethnique.étiquettes de substitution
Données utilisées pour réaliser une approximation des libellés qui ne sont pas directement disponibles dans un ensemble de données.
Par exemple, supposons que vous deviez entraîner un modèle pour prédire le niveau de stress des employés. Votre ensemble de données contient de nombreuses caractéristiques prédictives, mais pas d'étiquette nommée niveau de stress. Sans vous décourager, vous choisissez "accidents du travail" comme libellé proxy pour le niveau de stress. En effet, les employés stressés sont plus susceptibles d'avoir des accidents que les employés calmes. Ou pas ? Il est possible que les accidents du travail augmentent et diminuent pour plusieurs raisons.
Prenons un deuxième exemple. Supposons que vous souhaitiez que pleut-il ? soit une étiquette booléenne pour votre ensemble de données, mais que celui-ci ne contienne pas de données sur la pluie. Si des photos sont disponibles, vous pouvez créer des photos de personnes portant des parapluies comme étiquette de substitution pour la phrase is it raining? Est-ce une bonne étiquette de substitution ? C'est possible, mais dans certaines cultures, les gens sont plus susceptibles de porter un parapluie pour se protéger du soleil que de la pluie.
Les libellés de substitution sont souvent imparfaits. Dans la mesure du possible, choisissez des libellés réels plutôt que des libellés de substitution. Cela dit, en l'absence d'étiquette réelle, choisissez l'étiquette de substitution avec beaucoup de soin, en sélectionnant le candidat le moins horrible.
Pour en savoir plus, consultez Ensembles de données : libellés dans le Cours d'initiation au Machine Learning.
fonction pure
Fonction dont les sorties sont basées uniquement sur ses entrées et qui n'a aucun effet secondaire. Plus précisément, une fonction pure n'utilise ni ne modifie aucun état global, tel que le contenu d'un fichier ou la valeur d'une variable en dehors de la fonction.
Les fonctions pures peuvent être utilisées pour créer du code thread-safe, ce qui est utile lors du partitionnement du code modèle sur plusieurs puces d'accélérateur.
Les méthodes de transformation de fonction de JAX exigent que les fonctions d'entrée soient des fonctions pures.
Q
Fonction Q
Dans l'apprentissage par renforcement, fonction qui prédit le rendement attendu en effectuant une action dans un état, puis en suivant une stratégie donnée.
La fonction Q est également appelée fonction de valeur état-action.
Q-learning
Dans l'apprentissage par renforcement, un algorithme permet à un agent d'apprendre la fonction Q optimale d'un processus de décision markovien en appliquant l'équation de Bellman. Le processus de décision markovien modélise un environnement.
quantile
Chaque ensemble dans le binning en quantiles.
binning en quantiles
Distribuer les valeurs d'une caractéristique dans des ensembles afin que chaque ensemble contienne le même nombre (ou presque) d'exemples. Par exemple, la figure suivante divise 44 points en 4 ensembles, chacun contenant 11 points. Pour que chaque ensemble de la figure contienne le même nombre de points, certains ensembles couvrent une largeur différente de valeurs x.

Pour en savoir plus, consultez Données numériques : binning dans le cours d'initiation au machine learning.
quantification
Terme complexe qui peut être utilisé de l'une des manières suivantes :
- Implémentation du binning en quantiles sur une caractéristique spécifique.
- Transformer les données en zéros et en uns pour un stockage, un entraînement et une inférence plus rapides. Étant donné que les données booléennes sont plus robustes au bruit et aux erreurs que les autres formats, la quantification peut améliorer l'exactitude du modèle. Les techniques de quantification incluent l'arrondi, la troncature et le binning.
Réduction du nombre de bits utilisés pour stocker les paramètres d'un modèle. Par exemple, supposons que les paramètres d'un modèle soient stockés sous forme de nombres à virgule flottante sur 32 bits. La quantification convertit ces paramètres de 32 bits à 4, 8 ou 16 bits. La quantification réduit les éléments suivants :
- Utilisation du calcul, de la mémoire, du disque et du réseau
- Temps nécessaire pour inférer une prédiction
- Consommation d'énergie
Toutefois, la quantification diminue parfois la justesse des prédictions d'un modèle.
q
Opération TensorFlow qui implémente une structure de données de file d'attente. Généralement utilisé dans les E/S.
R
RAG
Abréviation de génération augmentée par récupération.
forêt aléatoire
Un ensemble d'arbres de décision dans lequel chaque arbre de décision est entraîné avec un bruit aléatoire spécifique, tel que l'agrégation bootstrap.
Les forêts d'arbres décisionnels sont un type de forêt de décision.
Pour en savoir plus, consultez Forêt aléatoire dans le cours "Forêts de décision".
stratégie aléatoire
Dans l'apprentissage par renforcement, une stratégie qui choisit une action au hasard.
rang (ordinalité)
Position ordinale d'une classe dans un problème de machine learning qui hiérarchise des classes par ordre décroissant. Par exemple, un système de classement de comportement pourrait classer les récompenses pour un chien de la récompense la plus élevée (un steak) à la récompense la plus faible (du chou frisé flétri).
rang (Tensor) (rank (Tensor))
Nombre de dimensions d'un Tensor. Par exemple, une grandeur scalaire a un rang de 0, un vecteur un rang de 1 et une matrice un rang de 2.
À ne pas confondre avec le rang (ordinalité).
classement
Type d'apprentissage supervisé dont l'objectif est d'ordonner une liste d'éléments.
évaluateur
Personne qui fournit des libellés pour des exemples. "Annotateur" est un autre nom pour évaluateur.
Pour en savoir plus, consultez Données catégorielles : problèmes courants dans le Cours d'initiation au Machine Learning.
Ensemble de données pour la compréhension écrite avec raisonnement logique (ReCoRD)
Ensemble de données permettant d'évaluer la capacité d'un LLM à effectuer un raisonnement basé sur le bon sens. Chaque exemple de l'ensemble de données contient trois composants :
- Un ou deux paragraphes d'un article d'actualité
- Requête dans laquelle l'une des entités identifiées explicitement ou implicitement dans le passage est masquée.
- La réponse (nom de l'entité à insérer dans le masque)
Pour obtenir une liste complète d'exemples, consultez ReCoRD.
ReCoRD est un composant de l'ensemble SuperGLUE.
RealToxicityPrompts
Ensemble de données contenant un ensemble de débuts de phrases susceptibles de contenir du contenu toxique. Utilisez cet ensemble de données pour évaluer la capacité d'un LLM à générer du texte non toxique pour compléter la phrase. En règle générale, vous utilisez l'API Perspective pour déterminer dans quelle mesure le LLM a réussi cette tâche.
Pour en savoir plus, consultez RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models.
reason
Étape de la boucle agentique dans laquelle l'agent détermine ce qu'il doit faire. Par exemple, l'agent peut déterminer qu'une requête d'API spécifique doit être envoyée.
recall
Statistique des modèles de classification qui répond à la question suivante :
Lorsque la vérité terrain correspondait à la classe positive, quel pourcentage de prédictions le modèle a-t-il correctement identifié comme classe positive ?
Voici la formule :
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
où :
- Un vrai positif signifie que le modèle a prédit correctement la classe positive.
- Un faux négatif signifie que le modèle a prédit à tort la classe négative.
Par exemple, supposons que votre modèle ait effectué 200 prédictions sur des exemples pour lesquels la vérité terrain était la classe positive. Sur ces 200 prédictions :
- 180 étaient des vrais positifs.
- 20 étaient des faux négatifs.
Dans ce cas :
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Pour en savoir plus, consultez Classification : précision, rappel et métriques associées.
Rappel à k (recall@k)
Métrique permettant d'évaluer les systèmes qui génèrent une liste d'éléments classés (ordonnés). Le rappel à k identifie la fraction d'éléments pertinents dans les k premiers éléments de cette liste sur le nombre total d'éléments pertinents renvoyés.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
À comparer à la précision à k.
Reconnaissance de l'implication textuelle (RTE, Recognizing Textual Entailment)
Ensemble de données permettant d'évaluer la capacité d'un LLM à déterminer si une hypothèse peut être déduite (logiquement tirée) d'un passage de texte. Chaque exemple d'évaluation RTE se compose de trois parties :
- Un extrait, généralement tiré d'articles d'actualités ou Wikipédia
- Une hypothèse
- La bonne réponse, qui est l'une des suivantes :
- Vrai, ce qui signifie que l'hypothèse peut être déduite du passage
- Faux, ce qui signifie que l'hypothèse ne peut pas être déduite du passage
Exemple :
- Extrait : L'euro est la monnaie de l'Union européenne.
- Hypothèse : la France utilise l'euro comme devise.
- Entailment : Vrai, car la France fait partie de l'Union européenne.
RTE est un composant de l'ensemble SuperGLUE.
système de recommandation
Système qui sélectionne pour chaque utilisateur un ensemble relativement petit d'éléments souhaitables dans un corpus volumineux. Par exemple, un système de recommandation de vidéos peut recommander deux vidéos d'un corpus de 100 000 vidéos, en sélectionnant Casablanca et Indiscrétions pour un utilisateur et Wonder Woman et Black Panther pour un autre. Un système de recommandation de vidéos pourrait baser ses recommandations sur la base de facteurs tels que :
- Des films notés ou vus par des utilisateurs similaires ;
- Le genre, les réalisateurs, les acteurs, la cible démographique, etc.
Pour en savoir plus, consultez le cours sur les systèmes de recommandation.
ReCoRD
Abréviation de Reading Comprehension with Commonsense Reasoning Dataset (ensemble de données pour la compréhension de la lecture avec raisonnement logique).
Unité de rectification linéaire (ReLU)
Fonction d'activation dont le comportement est le suivant :
- Si l'entrée est négative ou nulle, la sortie est 0.
- Si l'entrée est positive, la sortie est égale à l'entrée.
Exemple :
- Si l'entrée est -3, la sortie est 0.
- Si l'entrée est +3, la sortie est 3.0.
Voici un graphique de ReLU :
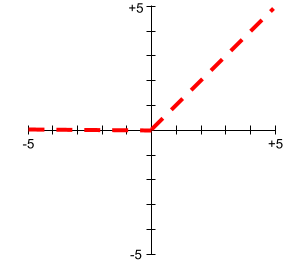
ReLU est une fonction d'activation très populaire. Malgré son comportement simple, ReLU permet toujours à un réseau de neurones d'apprendre les relations non linéaires entre les caractéristiques et le libellé.
réseau de neurones récurrent
Réseau de neurones exécuté intentionnellement à plusieurs reprises, où des parties de chaque exécution alimentent la prochaine exécution. Plus précisément, les couches cachées de l'exécution précédente fournissent une partie de l'entrée dans la même couche cachée lors de l'exécution suivante. Les réseaux de neurones récurrents sont particulièrement utiles pour évaluer les séquences, afin que les couches cachées puissent apprendre des exécutions précédentes du réseau de neurones sur les parties précédentes de la séquence.
Par exemple, la figure suivante illustre un réseau de neurones récurrent exécuté quatre fois. Notez que les valeurs apprises dans les couches cachées lors de la première exécution font partie de l'entrée des mêmes couches cachées lors de la deuxième exécution. De même, les valeurs apprises dans la couche cachée lors de la deuxième exécution font partie de l'entrée de la même couche cachée lors de la troisième exécution. De cette manière, le réseau de neurones récurrent s'entraîne progressivement et prédit la signification de la séquence complète plutôt que simplement la signification des mots individuels.

texte de référence
Réponse d'un expert à une requête. Par exemple, prenons la requête suivante :
Traduis la question "What is your name?" de l'anglais vers le français.
Voici un exemple de réponse d'un expert :
Comment vous appelez-vous ?
Diverses métriques (telles que ROUGE) mesurent le degré de correspondance entre le texte de référence et le texte généré par un modèle de ML.
réflexion
Stratégie permettant d'améliorer la qualité d'un workflow agentique en examinant (en réfléchissant à) le résultat d'une étape avant de le transmettre à l'étape suivante.
L'examinateur est souvent le même LLM que celui qui a généré la réponse (mais il peut s'agir d'un autre LLM). Comment le même LLM qui a généré une réponse peut-il être un juge impartial de sa propre réponse ? L'astuce consiste à mettre le LLM dans un état d'esprit critique (réflexif). Ce processus est analogue à celui d'un écrivain qui utilise un état d'esprit créatif pour rédiger un premier brouillon, puis passe à un état d'esprit critique pour le modifier.
Par exemple, imaginez un workflow agentique dont la première étape consiste à créer du texte pour des tasses à café. Le prompt pour cette étape pourrait être :
Vous êtes un créateur. Génère un texte humoristique et original de moins de 50 caractères pour une tasse à café.
Imaginons maintenant le prompt de réflexion suivant :
Vous buvez du café. Trouvez-vous la réponse précédente amusante ?
Le workflow ne transmettra ensuite à l'étape suivante que le texte ayant obtenu un score de réflexion élevé.
modèle de régression
Informellement, un modèle qui génère une prédiction numérique. (À l'inverse, un modèle de classification génère une prédiction de classe.) Par exemple, les modèles suivants sont tous des modèles de régression :
- Un modèle qui prédit la valeur d'une maison en euros, par exemple 423 000.
- Modèle qui prédit l'espérance de vie d'un arbre en années, par exemple 23,2.
- Modèle qui prédit la quantité de pluie (en pouces) qui tombera dans une ville donnée au cours des six prochaines heures, par exemple 0,18.
Voici deux types courants de modèles de régression :
- La régression linéaire, qui trouve la ligne qui correspond le mieux aux valeurs de libellé par rapport aux caractéristiques.
- La régression logistique, qui génère une probabilité comprise entre 0,0 et 1,0 qu'un système mappe généralement à une prédiction de classe.
Tous les modèles qui génèrent des prédictions numériques ne sont pas des modèles de régression. Dans certains cas, une prédiction numérique n'est en réalité qu'un modèle de classification dont les noms de classes sont numériques. Par exemple, un modèle qui prédit un code postal numérique est un modèle de classification, et non un modèle de régression.
régularisation
Tout mécanisme qui réduit le surapprentissage. Voici quelques types de régularisation courants :
- Régularisation L1
- Régularisation L2
- Régularisation par abandon
- Arrêt prématuré (Il ne s'agit pas vraiment d'une méthode de régularisation, mais l'arrêt prématuré peut limiter efficacement le surapprentissage.)
La régularisation peut également être définie comme la pénalité appliquée à la complexité d'un modèle.
Pour en savoir plus, consultez Surapprentissage : complexité du modèle dans le Cours d'initiation au Machine Learning.
taux de régularisation
Nombre qui spécifie l'importance relative de la régularisation pendant l'entraînement. L'augmentation du taux de régularisation réduit le surapprentissage, mais peut diminuer le pouvoir prédictif du modèle. À l'inverse, réduire ou omettre le taux de régularisation augmente le surapprentissage.
Pour en savoir plus, consultez Surapprentissage : régularisation L2 dans le cours d'initiation au machine learning.
apprentissage par renforcement
Famille d'algorithmes qui apprennent une stratégie optimale, dont l'objectif est de maximiser le retour lors de l'interaction avec un environnement. Par exemple, la récompense ultime dans la plupart des jeux est la victoire. Les systèmes d'apprentissage par renforcement peuvent devenir experts dans les jeux complexes en évaluant les séquences d'actions de parties antérieures qui ont finalement conduit à des victoires et les séquences qui ont finalement conduit à des échecs.
Apprentissage automatique par renforcement qui utilise le feedback humain (RLHF)
Utilisation des commentaires d'évaluateurs humains pour améliorer la qualité des réponses d'un modèle. Par exemple, un mécanisme RLHF peut demander aux utilisateurs d'évaluer la qualité de la réponse d'un modèle à l'aide d'un emoji 👍 ou 👎. Le système peut ensuite ajuster ses futures réponses en fonction de ces commentaires.
ReLU
Abréviation de Rectified Linear Unit.
mémoire de rejeu
Dans les algorithmes de type DQN, la mémoire utilisée par l'agent pour stocker les transitions d'état à utiliser dans la relecture de l'expérience.
Cloud SQL
Copie (ou partie) d'un ensemble d'entraînement ou d'un modèle, généralement stockée sur une autre machine. Par exemple, un système peut utiliser la stratégie suivante pour implémenter le parallélisme des données :
- Placez des répliques d'un modèle existant sur plusieurs machines.
- Envoyez différents sous-ensembles de l'ensemble d'entraînement à chaque réplica.
- Agrégez les mises à jour du paramètre.
Une réplique peut également faire référence à une autre copie d'un serveur d'inférence. Augmenter le nombre de répliques augmente le nombre de requêtes que le système peut traiter simultanément, mais augmente également les coûts de diffusion.
biais de fréquence
Fait que le rythme auquel les personnes écrivent à propos d'actions, de résultats ou de propriétés ne reflète pas leur rythme dans le monde réel ou le degré selon lequel une propriété est caractéristique d'une classe d'individus. Le biais de fréquence peut influer sur la composition des données à partir desquelles les systèmes de machine learning apprennent.
Par exemple, dans les livres, le mot ri est plus répandu que respiré. Un modèle de ML conçu pour estimer à partir d'un corpus de livres la fréquence relative du fait de rire et du fait de respirer déterminerait probablement que le premier est plus courant que le second.
Pour en savoir plus, consultez Équité : types de biais dans le cours d'initiation au machine learning.
vectorielle
Processus de mise en correspondance des données et des caractéristiques utiles.
reclassement
Étape finale d'un système de recommandation au cours duquel les éléments notés peuvent être réévalués selon un autre algorithme (généralement non issu du machine learning). Le reclassement évalue la liste des éléments générés par la phase d'attribution de scores, en prenant des mesures telles que :
- Éliminer les éléments que l'utilisateur a déjà achetés.
- Booster le score des éléments plus récents.
Pour en savoir plus, consultez la section Reclassement du cours sur les systèmes de recommandation.
réponse
Texte, images, éléments audio ou vidéo qu'un modèle d'IA générative déduit. En d'autres termes, un prompt est une entrée pour un modèle d'IA générative, et la réponse est la sortie.
ensemble de réponses
Ensemble de réponses qu'un grand modèle de langage renvoie à un ensemble de requêtes.
génération augmentée par récupération (RAG)
Technique permettant d'améliorer la qualité de la sortie d'un grand modèle de langage (LLM) en l'ancrant avec des sources de connaissances récupérées après l'entraînement du modèle. Le RAG améliore la précision des réponses des LLM en leur donnant accès à des informations extraites de bases de connaissances ou de documents fiables.
Voici quelques raisons courantes d'utiliser la génération augmentée par récupération :
- Améliorer la justesse factuelle des réponses générées par un modèle.
- Donner au modèle l'accès à des connaissances sur lesquelles il n'a pas été entraîné.
- Modifier les connaissances utilisées par le modèle.
- Permettre au modèle de citer des sources.
Par exemple, supposons qu'une application de chimie utilise l'API PaLM pour générer des résumés liés aux requêtes des utilisateurs. Lorsque le backend de l'application reçoit une requête, il effectue les opérations suivantes :
- Recherche ("récupère") les données pertinentes pour la requête de l'utilisateur.
- Ajoute ("augmente") les données de chimie pertinentes à la requête de l'utilisateur.
- Indique au LLM de créer un résumé basé sur les données ajoutées.
retour
Dans l'apprentissage par renforcement, étant donné une règle et un état spécifiques, le retour correspond à la somme de toutes les récompenses que l'agent s'attend à recevoir en suivant la règle de l'état jusqu'à la fin de l'épisode. L'agent tient compte de la nature différée des récompenses attendues en les actualisant en fonction des transitions d'état nécessaires pour les obtenir.
Par conséquent, si le facteur de remise est \(\gamma\), et que \(r_0, \ldots, r_{N}\)désigne les récompenses jusqu'à la fin de l'épisode, le calcul du rendement est le suivant :
récompense
Dans l'apprentissage par renforcement, le résultat numérique d'une action dans un état, tel que défini par l'environnement.
régularisation ridge
Synonyme de régularisation L2. Le terme régularisation d'arête est utilisé plus souvent dans les contextes de statistiques pures, tandis que le terme régularisation L2 est utilisé plus souvent dans le machine learning.
RNN
Abréviation de réseaux de neurones récurrents.
Courbe ROC (receiver operating characteristic)
Graphique du taux de vrais positifs par rapport au taux de faux positifs pour différents seuils de classification dans la classification binaire.
La forme d'une courbe ROC suggère la capacité d'un modèle de classification binaire à séparer les classes positives des classes négatives. Supposons, par exemple, qu'un modèle de classification binaire sépare parfaitement toutes les classes négatives de toutes les classes positives :
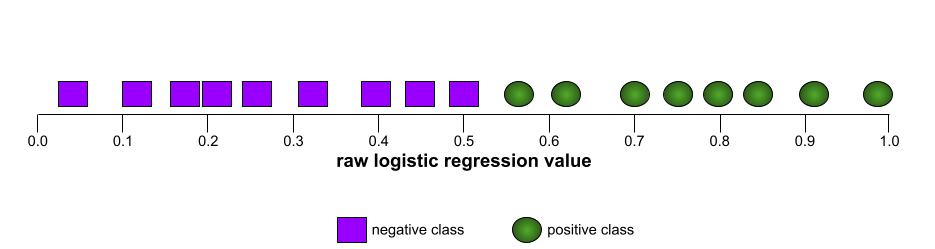
La courbe ROC du modèle précédent se présente comme suit :
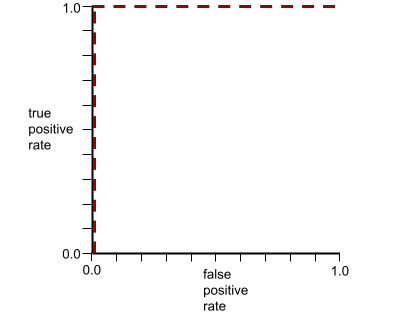
En revanche, l'illustration suivante représente les valeurs brutes de régression logistique pour un modèle médiocre qui ne peut pas du tout séparer les classes négatives des classes positives :
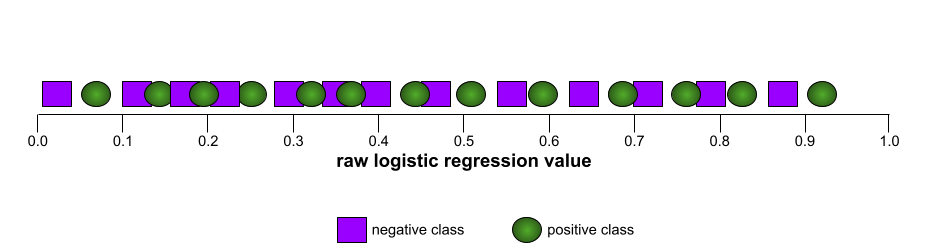
La courbe ROC de ce modèle se présente comme suit :
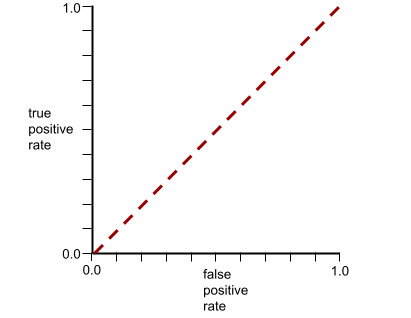
Dans le monde réel, la plupart des modèles de classification binaire séparent les classes positives et négatives dans une certaine mesure, mais généralement pas parfaitement. Par conséquent, une courbe ROC typique se situe quelque part entre les deux extrêmes :
Le point d'une courbe ROC le plus proche de (0.0,1.0) identifie théoriquement le seuil de classification idéal. Toutefois, plusieurs autres problèmes concrets influencent la sélection du seuil de classification idéal. Par exemple, les faux négatifs peuvent être beaucoup plus problématiques que les faux positifs.
Une métrique numérique appelée AUC résume la courbe ROC en une seule valeur à virgule flottante.
prompts de rôle
Un prompt, commençant généralement par le pronom vous, qui indique à un modèle d'IA générative de se faire passer pour une certaine personne ou un certain rôle lorsqu'il génère la réponse. L'incitation par rôle peut aider un modèle d'IA générative à adopter le bon "état d'esprit" pour générer une réponse plus utile. Par exemple, l'une des invites de rôle suivantes peut être appropriée en fonction du type de réponse que vous recherchez :
Vous êtes titulaire d'un doctorat en informatique.
Vous êtes un ingénieur logiciel qui aime expliquer patiemment Python aux nouveaux étudiants en programmation.
Vous êtes un héros de l'action doté de compétences en programmation très spécifiques. Assure-moi que tu trouveras un élément spécifique dans une liste Python.
racine
Nœud de départ (première condition) d'un arbre de décision. Par convention, les diagrammes placent la racine en haut de l'arbre de décision. Exemple :
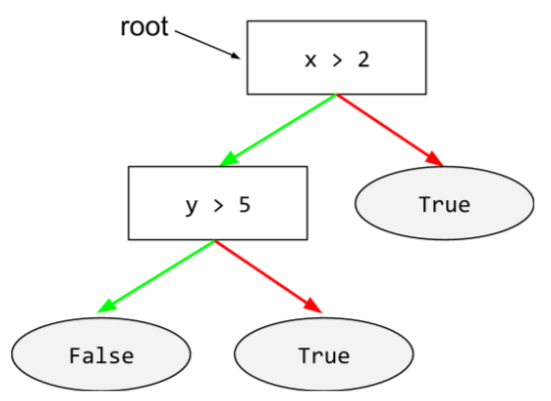
répertoire racine
Répertoire que vous spécifiez pour l'enregistrement des sous-répertoires du point de contrôle TensorFlow et des fichiers d'événements de plusieurs modèles.
la racine carrée de l'erreur quadratique moyenne (RMSE, Root Mean Squared Error)
Racine carrée de l'erreur quadratique moyenne.
invariance rotationnelle
Dans un problème de classification d'images, il s'agit de la capacité d'un algorithme à classer correctement les images même lorsque leur orientation change. Par exemple, l'algorithme peut identifier une raquette de tennis, qu'elle soit orientée vers le haut, sur le côté ou vers le bas. Notez que l'invariance rotationnelle n'est pas toujours souhaitable. Par exemple, un 9 à l'envers ne devrait pas être classé comme étant un 9.
Voir aussi invariance par translation et invariance par redimensionnement.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Famille de métriques qui évaluent les modèles de traduction automatique et de synthèse automatique. Les métriques ROUGE déterminent le degré de chevauchement entre un texte de référence et le texte généré par un modèle de ML. Chaque membre de la famille ROUGE mesure le chevauchement d'une manière différente. Plus les scores ROUGE sont élevés, plus le texte de référence et le texte généré sont semblables.
Chaque membre de la famille ROUGE génère généralement les métriques suivantes :
- Précision
- Rappel
- F1
Pour en savoir plus et obtenir des exemples, consultez :
ROUGE-L
Membre de la famille ROUGE axé sur la longueur de la plus longue sous-séquence commune dans le texte de référence et le texte généré. Les formules suivantes permettent de calculer le rappel et la précision pour ROUGE-L :
Vous pouvez ensuite utiliser F1 pour regrouper le rappel ROUGE-L et la précision ROUGE-L dans une seule métrique :
ROUGE-L ignore les sauts de ligne dans le texte de référence et le texte généré. La plus longue sous-séquence commune peut donc s'étendre sur plusieurs phrases. Lorsque le texte de référence et le texte généré comportent plusieurs phrases, une variante de ROUGE-L appelée ROUGE-Lsum est généralement une meilleure métrique. ROUGE-Lsum détermine la plus longue sous-séquence commune pour chaque phrase d'un passage, puis calcule la moyenne de ces plus longues sous-séquences communes.
ROUGE-N
Ensemble de métriques de la famille ROUGE qui compare les N-grammes partagés d'une certaine taille dans le texte de référence et le texte généré. Exemple :
- ROUGE-1 mesure le nombre de jetons partagés dans le texte de référence et le texte généré.
- ROUGE-2 mesure le nombre de bigrammes (2-grammes) partagés dans le texte de référence et le texte généré.
- ROUGE-3 mesure le nombre de trigrammes (3-grammes) partagés dans le texte de référence et le texte généré.
Vous pouvez utiliser les formules suivantes pour calculer le rappel ROUGE-N et la précision ROUGE-N pour n'importe quel membre de la famille ROUGE-N :
Vous pouvez ensuite utiliser F1 pour regrouper le rappel ROUGE-N et la précision ROUGE-N dans une seule métrique :
ROUGE-S
Forme tolérante de ROUGE-N qui permet la mise en correspondance des skip-grammes. Autrement dit, ROUGE-N ne compte que les n-grammes qui correspondent exactement, tandis que ROUGE-S compte également les n-grammes séparés par un ou plusieurs mots. Nous vous conseillons, par exemple, de suivre les recommandations suivantes :
- texte de référence : Nuages blancs
- generated text : White billowing clouds
Lors du calcul de ROUGE-N, le 2-gramme White clouds ne correspond pas à White billowing clouds. Toutefois, lors du calcul de ROUGE-S, White clouds correspond à White billowing clouds.
agent de routeur
Agent qui classe une requête utilisateur, puis appelle l'agent le plus approprié pour la traiter.
Coefficient de détermination
Il s'agit d'une métrique de régression indiquant dans quelle mesure la variance d'une étiquette est due à une caractéristique individuelle ou à un ensemble de caractéristiques. Il s'agit d'une valeur comprise entre 0 et 1, que vous pouvez interpréter comme suit :
- Un coefficient de détermination de 0 signifie que la variance d'une étiquette n'est en rien due à l'ensemble de caractéristiques.
- Un coefficient de détermination de 1 signifie que la variance d'une étiquette est totalement due à l'ensemble de caractéristiques.
- Un coefficient de détermination compris entre 0 et 1 indique dans quelle mesure la variance de l'étiquette peut être prédite à partir d'une caractéristique particulière ou de l'ensemble de caractéristiques. Par exemple, un coefficient de détermination de 0,10 signifie que 10 % de la variance de l'étiquette est due à l'ensemble de caractéristiques, un coefficient de détermination de 0,20 signifie que 20 % est dû à l'ensemble de caractéristiques, et ainsi de suite.
Le R-carré correspond au carré du coefficient de corrélation de Pearson entre les valeurs prédites par un modèle et la vérité terrain.
RTE
Abréviation de Recognizing Textual Entailment.
S
biais d'échantillonnage
Voir biais de sélection.
échantillonnage avec remplacement
Méthode de sélection d'éléments à partir d'un ensemble d'éléments candidats dans laquelle le même élément peut être sélectionné plusieurs fois. L'expression "avec remplacement" signifie qu'après chaque sélection, l'élément sélectionné est renvoyé dans le pool d'éléments candidats. La méthode inverse, l'échantillonnage sans remplacement, signifie qu'un élément candidat ne peut être sélectionné qu'une seule fois.
Prenons l'exemple de l'ensemble de fruits suivant :
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}Supposons que le système sélectionne aléatoirement fig comme premier élément.
Si vous utilisez l'échantillonnage avec remplacement, le système sélectionne le deuxième élément de l'ensemble suivant :
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}Oui, il s'agit du même ensemble qu'avant. Le système pourrait donc potentiellement choisir à nouveau fig.
Si vous utilisez l'échantillonnage sans remplacement, une fois qu'un échantillon a été sélectionné, il ne peut plus l'être. Par exemple, si le système sélectionne aléatoirement fig comme premier échantillon, fig ne peut plus être sélectionné. Le système sélectionne donc le deuxième échantillon de l'ensemble (réduit) suivant :
fruit = {kiwi, apple, pear, cherry, lime, mango}SavedModel
Format recommandé pour enregistrer et récupérer des modèles TensorFlow. SavedModel est un format de sérialisation récupérable, de langage neutre, qui permet aux systèmes et aux outils de plus haut niveau de produire, consommer et transformer des modèles TensorFlow.
Pour en savoir plus, consultez la section Enregistrer et récupérer du guide du programmeur TensorFlow.
Économique
Objet TensorFlow responsable de l'enregistrement des points de contrôle du modèle.
scalaire
Un nombre ou une chaîne unique pouvant être représentés sous la forme d'un tenseur de rang 0. Par exemple, les lignes de code suivantes créent chacune un scalaire dans TensorFlow :
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)scaling
Toute transformation ou technique mathématique qui modifie la plage d'un libellé, d'une valeur de caractéristique ou des deux. Certaines formes de scaling sont très utiles pour les transformations telles que la normalisation.
Voici quelques formes de scaling courantes et utiles dans le machine learning :
- La mise à l'échelle linéaire, qui utilise généralement une combinaison de soustraction et de division pour remplacer la valeur d'origine par un nombre compris entre -1 et +1 ou entre 0 et 1.
- la mise à l'échelle logarithmique, qui remplace la valeur d'origine par son logarithme.
- La normalisation du score Z, qui remplace la valeur d'origine par une valeur à virgule flottante représentant le nombre d'écarts-types par rapport à la moyenne de cette caractéristique.
scikit-learn
Plate-forme de machine learning Open Source populaire. Pour en savoir plus, consultez scikit-learn.org.
notation
Partie d'un système de recommandation qui fournit une valeur ou un classement pour chaque élément produit par la phase de génération de candidats.
biais de sélection
Erreurs dans les conclusions tirées des échantillons de données en raison d'un processus de sélection générant des différences systématiques entre les échantillons observés dans les données et ceux non observés. Le biais de sélection existe sous les formes suivantes :
- Biais de couverture : la population représentée dans l'ensemble de données ne correspond pas à celle sur laquelle le modèle de machine learning fait des prédictions.
- biais d'échantillonnage : les données ne sont pas collectées aléatoirement auprès du groupe cible.
- Biais de non-réponse (également appelé biais de participation) : les utilisateurs de certains groupes refusent de participer à certaines enquêtes à des taux différents des utilisateurs d'autres groupes.
Supposons que vous créez un modèle de machine learning qui prédit le succès d'un film. Pour collecter les données d'entraînement, vous distribuez une enquête à toutes les personnes situées au premier rang d'une salle de cinéma projetant le film. Même si de prime abord cette approche peut sembler être un bon moyen de recueillir un ensemble de données, elle peut introduire les formes de biais de sélection suivantes :
- Biais de couverture : en échantillonnant à partir d'une population qui a choisi de voir le film, les prédictions de votre modèle peuvent mal se généraliser à des personnes qui n'ont pas manifesté un tel intérêt pour le film.
- Biais d'échantillonnage : plutôt que d'échantillonner aléatoirement la population visée (toutes les personnes dans la salle), vous n'avez échantillonné que les personnes du premier rang. Il est possible que les personnes du premier rang soient plus intéressées par le film que celles des autres rangs.
- Biais de non-réponse : en général, les personnes qui ont des opinions fortes ont tendance à répondre plus souvent aux enquêtes facultatives que les personnes qui ont des opinions modérées. Comme l'enquête sur le film est facultative, il est plus probable que les réponses forment une distribution bimodale plutôt qu'une distribution normale (en cloche).
Auto-attention (également appelée couche d'auto-attention)
Couche de réseau de neurones qui transforme une séquence d'embeddings (par exemple, des embeddings de jetons) en une autre séquence d'embeddings. Chaque embedding de la séquence de sortie est construit en intégrant des informations provenant des éléments de la séquence d'entrée via un mécanisme d'attention.
La partie auto de l'auto-attention fait référence à la séquence qui s'intéresse à elle-même plutôt qu'à un autre contexte. L'auto-attention est l'un des principaux éléments de base des Transformers et utilise la terminologie de la recherche dans un dictionnaire, comme "requête", "clé" et "valeur".
Une couche d'auto-attention commence par une séquence de représentations d'entrée, une pour chaque mot. La représentation d'un mot en entrée peut être un simple embedding. Pour chaque mot d'une séquence d'entrée, le réseau évalue la pertinence du mot par rapport à chaque élément de l'ensemble de la séquence de mots. Les scores de pertinence déterminent dans quelle mesure la représentation finale du mot intègre les représentations d'autres mots.
Prenons l'exemple de la phrase suivante :
L'animal n'a pas traversé la rue, car il était trop fatigué.
L'illustration suivante (tirée de Transformer: A Novel Neural Network Architecture for Language Understanding) montre le modèle d'attention d'une couche d'auto-attention pour le pronom it. L'épaisseur de chaque ligne indique la contribution de chaque mot à la représentation :
La couche d'auto-attention met en évidence les mots qui sont pertinents pour "il". Dans ce cas, la couche d'attention a appris à mettre en évidence les mots auxquels elle peut faire référence, en attribuant le poids le plus élevé à animal.
Pour une séquence de n jetons, l'auto-attention transforme une séquence d'embeddings n fois, une fois à chaque position de la séquence.
Consultez également attention et auto-attention multi-têtes.
autocorrection
Capacité d'un agent à détecter une erreur dans sa propre sortie et à essayer une autre approche.
apprentissage auto-supervisé
Famille de techniques permettant de convertir un problème d'apprentissage automatique non supervisé en problème d'apprentissage automatique supervisé en créant des étiquettes de substitution à partir d'exemples non étiquetés.
Certains modèles basés sur Transformer, comme BERT, utilisent l'apprentissage autosupervisé.
L'entraînement auto-supervisé est une approche d'apprentissage partiellement supervisé.
auto-apprentissage
Une variante de l'apprentissage autosupervisé particulièrement utile lorsque toutes les conditions suivantes sont remplies :
- Le ratio exemples sans étiquette/exemples avec étiquette est élevé dans l'ensemble de données.
- Il s'agit d'un problème de classification.
L'auto-apprentissage fonctionne en itérant sur les deux étapes suivantes jusqu'à ce que le modèle cesse de s'améliorer :
- Utilisez le machine learning supervisé pour entraîner un modèle sur les exemples étiquetés.
- Utilisez le modèle créé à l'étape 1 pour générer des prédictions (étiquettes) sur les exemples non étiquetés, en déplaçant ceux pour lesquels la confiance est élevée vers les exemples étiquetés avec l'étiquette prédite.
Notez que chaque itération de l'étape 2 ajoute des exemples étiquetés pour l'étape 1 sur lesquels s'entraîner.
mémoire sémantique
Informations dont dispose un LLM à la fin de l'entraînement. Par exemple, la mémoire sémantique inclut une excellente connaissance de la grammaire, du vocabulaire et des faits sur lesquels elle a été explicitement entraînée.
La mémoire sémantique n'inclut pas les informations recueillies à partir de la génération augmentée par récupération.
À comparer à la mémoire épisodique.
apprentissage semi-supervisé
Entraînement d'un modèle avec des données où seulement certains des exemples d'entraînement sont étiquetés. Une technique d'apprentissage partiellement supervisé consiste à inférer des étiquettes pour les exemples non étiquetés, puis à entraîner un nouveau modèle sur les étiquettes inférées. L'apprentissage partiellement supervisé peut être utile si les étiquettes sont coûteuses, mais que les exemples sans étiquette abondent.
L'auto-apprentissage est une technique d'apprentissage partiellement supervisé.
attribut sensible
Attribut humain auquel une attention particulière peut être accordée pour des motifs juridiques, éthiques, sociaux ou personnels.analyse des sentiments
Utilisation d'algorithmes statistiques ou de machine learning pour déterminer l'attitude globale d'un groupe (positive ou négative) à l'égard d'un service, d'un produit, d'une organisation ou d'un sujet. Par exemple, en utilisant la compréhension du langage naturel, un algorithme pourrait effectuer une analyse des sentiments sur les commentaires textuels d'un cours universitaire afin de déterminer le degré d'appréciation des étudiants pour ce cours.
Pour en savoir plus, consultez le guide sur la classification de texte.
modèle de séquence
Modèle dont les entrées ont une dépendance séquentielle. Par exemple, prévision de la prochaine vidéo visionnée à partir d'une séquence de vidéos précédemment regardées.
tâche de séquence à séquence
Tâche qui convertit une séquence d'entrée de jetons en une séquence de sortie de jetons. Par exemple, deux types courants de tâches de séquence à séquence sont les suivants :
- Traducteurs :
- Exemple de séquence d'entrée : "Je t'aime."
- Exemple de séquence de sortie : "Je t'aime."
- Systèmes de questions-réponses :
- Exemple de séquence d'entrée : "Ai-je besoin de ma voiture à New York ?"
- Exemple de séquence de sortie : "Non, gardez votre voiture à la maison."
du modèle
Processus permettant de rendre un modèle entraîné disponible pour fournir des prédictions par le biais de l'inférence en ligne ou de l'inférence hors connexion.
forme (Tensor) (shape (Tensor))
Nombre d'éléments dans chaque dimension d'un Tensor. La forme est représentée sous la forme d'une liste d'entiers. Par exemple, le Tensor bidimensionnel suivant a une forme [3,4]:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
TensorFlow utilise le format "row-major" (style C) pour représenter l'ordre des dimensions. C'est pourquoi la forme dans TensorFlow est [3,4] plutôt que [4,3]. En d'autres termes, dans un Tensor TensorFlow bidimensionnel, la forme est [nombre de lignes, nombre de colonnes].
Une forme statique est une forme de Tensor qui est connue au moment de la compilation.
Une forme dynamique est inconnue au moment de la compilation et dépend donc des données d'exécution. Ce Tensor peut être représenté par une dimension d'espace réservé dans TensorFlow, comme dans [3, ?].
segment
Division logique de l'ensemble d'entraînement ou du modèle. En règle générale, un processus crée des partitions en divisant les exemples ou les paramètres en blocs de taille (généralement) égale. Chaque segment est ensuite attribué à une machine différente.
Le partitionnement d'un modèle est appelé parallélisme des modèles, tandis que le partitionnement des données est appelé parallélisme des données.
rétrécissement
Un hyperparamètre dans le boosting de gradient qui contrôle le surapprentissage. La réduction dans le boosting de gradient est analogue au taux d'apprentissage dans la descente de gradient. La réduction est une valeur décimale comprise entre 0,0 et 1,0. Une valeur de réduction plus faible réduit davantage le surapprentissage qu'une valeur de réduction plus élevée.
évaluation côte à côte
Comparer la qualité de deux modèles en évaluant leurs réponses à la même requête. Par exemple, supposons que le prompt suivant soit donné à deux modèles différents :
Crée une image d'un adorable chien jonglant avec trois balles.
Lors d'une évaluation côte à côte, un évaluateur choisit l'image qui est "meilleure" (plus précise ? Plus belle ? Plus mignon ?).
fonction sigmoïde
Fonction mathématique qui "écrase" une valeur d'entrée dans une plage limitée, généralement de 0 à 1 ou de -1 à +1. Autrement dit, vous pouvez transmettre n'importe quel nombre (deux, un million, un milliard négatif, etc.) à une sigmoïde, et la sortie sera toujours dans la plage contrainte. Voici à quoi ressemble un graphique de la fonction d'activation sigmoïde :
La fonction sigmoïde a plusieurs utilisations dans le machine learning, y compris :
- Conversion de la sortie brute d'un modèle de régression logistique ou de régression multinomiale en probabilité.
- Agit comme une fonction d'activation dans certains réseaux de neurones.
mesure de similarité
Dans les algorithmes de clustering, la métrique permettant de déterminer le degré de similarité entre deux exemples.
programme unique / données multiples (SPMD)
Technique de parallélisme dans laquelle le même calcul est exécuté en parallèle sur différentes données d'entrée sur différents appareils. L'objectif de SPMD est d'obtenir des résultats plus rapidement. Il s'agit du style de programmation parallèle le plus courant.
invariance par redimensionnement
Dans un problème de classification d'images, la capacité d'un algorithme à classer correctement les images même lorsque leur taille change. Par exemple, l'algorithme peut identifier un chat, qu'il occupe 2 millions de pixels ou 200 000 pixels. Notez que même les meilleurs algorithmes de classification d'images présentent encore des limites pratiques au niveau de l'invariance par redimensionnement. Par exemple, il est peu probable qu'un algorithme (ou une personne) puisse classer correctement une image de chat de seulement 20 pixels.
Consultez également Invariance par translation et invariance rotationnelle.
Pour en savoir plus, consultez le cours sur le clustering.
croquis
Dans le machine learning non supervisé, une catégorie d'algorithmes qui effectuent une analyse de similarité préliminaire sur les exemples. Les algorithmes de similarité approximative utilisent une fonction de hachage sensible à la localité pour identifier les points potentiellement similaires, puis les regroupent dans des ensembles.
La similarité approximative diminue la quantité de calcul requise pour les calculs de similarité sur les grands ensembles de données. Au lieu de calculer la similarité pour chaque paire d'exemples dans l'ensemble de données, nous la calculons uniquement pour chaque paire de points de chaque bucket.
skip-gram
Un n-gramme qui peut omettre (ou "ignorer") des mots du contexte d'origine, ce qui signifie que les N mots n'étaient peut-être pas adjacents à l'origine. Plus précisément, un "k-skip-n-gram" est un n-gramme pour lequel jusqu'à k mots peuvent avoir été ignorés.
Par exemple, "the quick brown fox" présente les 2-grammes possibles suivants :
- "the quick"
- "quick brown"
- "renard brun"
Un "1-skip-2-gram" est une paire de mots séparés par au maximum un mot. Par conséquent, "le renard brun vif" comporte les 2-grammes à un saut suivants :
- "the brown"
- "quick fox"
De plus, tous les 2-grams sont également des 1-skip-2-grams, car moins d'un mot peut être ignoré.
Les skip-grams sont utiles pour mieux comprendre le contexte d'un mot. Dans l'exemple, "renard" était directement associé à "rapide" dans l'ensemble des 1-skip-2-grams, mais pas dans l'ensemble des 2-grams.
Les skip-grammes permettent d'entraîner des modèles d'embedding de mots.
softmax
Fonction qui détermine les probabilités pour chaque classe possible dans un modèle de classification à classes multiples. La somme des probabilités est exactement égale à 1.0. Par exemple, le tableau suivant montre comment softmax distribue différentes probabilités :
| L'image est… | Probabilité |
|---|---|
| chien | 0,85 |
| cat | .13 |
| cheval | ,02 |
Softmax est également appelé softmax complet.
À comparer à l'échantillonnage de candidats.
Pour en savoir plus, consultez Réseaux de neurones : classification multiclasse dans le cours d'initiation au machine learning.
Réglage des prompts logiciels
Technique permettant de régler un grand modèle de langage pour une tâche spécifique, sans affinage gourmand en ressources. Au lieu de réentraîner tous les poids du modèle, le réglage des soft prompts ajuste automatiquement un prompt pour atteindre le même objectif.
Étant donné un prompt textuel, le réglage des soft prompts ajoute généralement des embeddings de jetons supplémentaires au prompt et utilise la rétropropagation pour optimiser l'entrée.
Une requête "dure" contient des jetons réels au lieu d'embeddings de jetons.
caractéristique creuse
Caractéristique dont les valeurs sont pour la plupart nulles ou vides. Par exemple, une caractéristique contenant une seule valeur 1 et un million de valeurs 0 est considérée comme éparse. En revanche, une caractéristique dense comporte des valeurs qui ne sont pas majoritairement nulles ni vides.
En machine learning, un nombre surprenant de caractéristiques sont des caractéristiques éparses. Les caractéristiques catégorielles sont généralement des caractéristiques éparses. Par exemple, sur les 300 espèces d'arbres possibles dans une forêt, un seul exemple peut identifier un érable. Ou, parmi les millions de vidéos possibles dans une bibliothèque vidéo, un seul exemple peut identifier "Casablanca".
Dans un modèle, vous représentez généralement les caractéristiques creuses avec l'encodage one-hot. Si l'encodage one-hot est volumineux, vous pouvez ajouter une couche d'embedding au-dessus de l'encodage one-hot pour plus d'efficacité.
représentation creuse
Stockage uniquement des positions des éléments non nuls dans une caractéristique éparse.
Par exemple, supposons qu'une caractéristique catégorielle nommée species identifie les 36 espèces d'arbres d'une forêt donnée. Supposons également que chaque exemple n'identifie qu'une seule espèce.
Vous pouvez utiliser un vecteur one-hot pour représenter les espèces d'arbres dans chaque exemple.
Un vecteur one-hot contiendrait un seul 1 (pour représenter l'espèce d'arbre spécifique dans cet exemple) et 35 0 (pour représenter les 35 espèces d'arbres non présentes dans cet exemple). La représentation one-hot de maple peut ressembler à ceci :

Une représentation creuse identifierait simplement la position de l'espèce en question. Si maple se trouve à la position 24, la représentation creuse de maple serait simplement la suivante :
24
Notez que la représentation creuse est beaucoup plus compacte que la représentation one-hot.
Cliquez sur l'icône pour obtenir un exemple légèrement plus complexe.
Supposons que chaque exemple de votre modèle doive représenter les mots d'une phrase en anglais, mais pas leur ordre. L'anglais se compose d'environ 170 000 mots. Il s'agit donc d'une caractéristique catégorielle avec environ 170 000 éléments. La plupart des phrases en anglais utilisent une infime fraction de ces 170 000 mots. L'ensemble de mots dans un seul exemple sera donc presque certainement des données éparses.
Considérez la phrase suivante :
My dog is a great dog
Vous pouvez utiliser une variante de vecteur one-hot pour représenter les mots de cette phrase. Dans cette variante, plusieurs cellules du vecteur peuvent contenir une valeur non nulle. De plus, dans cette variante, une cellule peut contenir un nombre entier autre que un. Bien que les mots "mon", "est", "un" et "super" n'apparaissent qu'une seule fois dans la phrase, le mot "chien" apparaît deux fois. L'utilisation de cette variante de vecteurs one-hot pour représenter les mots de cette phrase donne le vecteur de 170 000 éléments suivant :

Une représentation creuse de la même phrase serait simplement :
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Pour en savoir plus, consultez Utiliser des données catégorielles dans le Cours d'initiation au Machine Learning.
vecteur creux
Vecteur dont les valeurs sont principalement nulles. Voir aussi caractéristique creuse et creux.
parcimonie
Nombre d'éléments définis sur zéro (ou null) dans un vecteur ou une matrice, divisé par le nombre total d'entrées dans ce vecteur ou cette matrice. Prenons l'exemple d'une matrice de 100 éléments dans laquelle 98 cellules contiennent la valeur zéro. La formule permettant de calculer la parcimonie est la suivante :
La rareté des caractéristiques fait référence à la rareté d'un vecteur de caractéristiques, tandis que la rareté du modèle fait référence à la rareté des pondérations du modèle.
pooling spatial
Voir pooling.
codage spécificationnel
Processus d'écriture et de maintenance d'un fichier dans une langue humaine (par exemple, l'anglais) qui décrit un logiciel. Vous pouvez ensuite demander à un modèle d'IA générative ou à un autre ingénieur logiciel de créer le logiciel qui correspond à cette description.
Le code généré automatiquement nécessite généralement des itérations. Dans le codage spécificationnel, vous itérez sur le fichier de description. En revanche, dans le codage conversationnel, vous itérez dans la zone de requête. En pratique, la génération automatique de code implique parfois une combinaison de codage par spécification et de codage conversationnel.
split
Dans un arbre de décision, autre nom pour une condition.
séparateur
Routine (et algorithme) responsable de la recherche de la meilleure condition à chaque nœud lors de l'entraînement d'un arbre de décision.
SPMD
Abréviation de single program / multiple data (programme unique/données multiples).
SQuAD
Acronyme de Stanford Question Answering Dataset, introduit dans l'article SQuAD: 100,000+ Questions for Machine Comprehension of Text. Les questions de cet ensemble de données proviennent de personnes qui posent des questions sur des articles Wikipédia. Certaines questions de SQuAD ont des réponses, mais d'autres n'en ont intentionnellement pas. Vous pouvez donc utiliser SQuAD pour évaluer la capacité d'un LLM à effectuer les deux opérations suivantes :
- Répondez aux questions auxquelles il est possible de répondre.
- Identifier les questions auxquelles il n'est pas possible de répondre
La correspondance exacte associée à F1 sont les métriques les plus courantes pour évaluer les LLM par rapport à SQuAD.
marge maximale quadratique
Carré de la marge maximale. La marge maximale quadratique pénalise les valeurs aberrantes plus sévèrement que la marge maximale standard.
perte quadratique
Synonyme de perte L2.
entraînement par étapes
Tactique d'entraînement d'un modèle en une séquence d'étapes discrètes. L'objectif peut être d'accélérer le processus d'entraînement ou d'améliorer la qualité du modèle.
Vous trouverez ci-dessous une illustration de l'approche de l'empilement progressif :
- La phase 1 contient trois couches cachées, la phase 2 en contient six et la phase 3 en contient 12.
- L'étape 2 commence l'entraînement avec les pondérations apprises dans les trois couches cachées de l'étape 1. L'étape 3 commence l'entraînement avec les pondérations apprises dans les six couches cachées de l'étape 2.
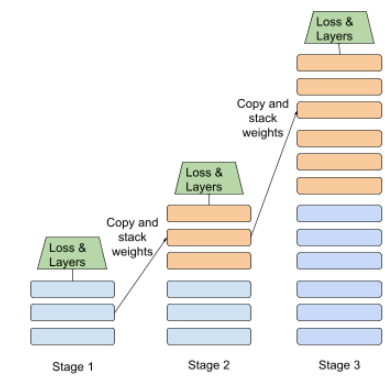
Voir aussi pipelining.
state
En apprentissage par renforcement, les valeurs de paramètre décrivent la configuration actuelle de l'environnement, que l'agent utilise pour choisir une action.
fonction de valeur état-action
Synonyme de fonction Q.
agent de machine à états
Un agent dont les workflows sont soumis à des règles strictes. Les agents à machine à états font généralement moins d'erreurs que les agents autonomes, mais ils ne peuvent pas s'adapter aux situations qui ne respectent pas leurs contraintes.
static
Action ponctuelle plutôt que continue. Les termes statique et hors connexion sont synonymes. Voici des utilisations courantes des termes statique et hors connexion dans le machine learning :
- Un modèle statique (ou modèle hors connexion) est un modèle entraîné une seule fois, puis utilisé pendant un certain temps.
- L'entraînement statique (ou entraînement hors connexion) est le processus d'entraînement d'un modèle statique.
- L'inférence statique (ou inférence hors connexion) est un processus dans lequel un modèle génère un lot de prédictions à la fois.
À comparer à dynamique.
inférence statique
Synonyme d'inférence hors connexion.
stationnarité
Caractéristique dont les valeurs ne changent pas pour une ou plusieurs dimensions, généralement le temps. Par exemple, une caractéristique dont les valeurs sont à peu près les mêmes en 2021 et en 2023 présente une stationnarité.
Dans le monde réel, très peu de caractéristiques présentent une stationnarité. Même les caractéristiques synonymes de stabilité (comme le niveau de la mer) évoluent au fil du temps.
À comparer à la non-stationnarité.
étape
Propagation avant et propagation arrière d'un lot.
Pour en savoir plus sur la passe avant et la passe arrière, consultez Rétropropagation.
taille de pas
Synonyme de taux d'apprentissage.
descente de gradient stochastique (SGD)
Algorithme de descente de gradient dans lequel la taille de lot est égale à un. Autrement dit, la descente de gradient stochastique s'entraîne sur un seul exemple prélevé uniformément, de manière aléatoire, dans un ensemble d'entraînement.
Pour en savoir plus, consultez Régression linéaire : hyperparamètres dans le Cours d'initiation au Machine Learning.
stride
Dans une opération de convolution ou de pooling, il s'agit du delta dans chaque dimension de la prochaine série de tranches d'entrée. Par exemple, l'animation suivante montre un pas (1,1) lors d'une opération de convolution. Par conséquent, la tranche d'entrée suivante commence une position à droite de la tranche d'entrée précédente. Lorsque l'opération atteint le bord droit, la tranche suivante se trouve tout à gauche, mais une position plus bas.
L'exemple précédent illustre un stride bidimensionnel. Si la matrice d'entrée est tridimensionnelle, le pas est également tridimensionnel.
minimisation du risque structurel (SRM)
Algorithme qui concilie les deux objectifs suivants :
- Créer le modèle prédictif le plus efficace (par exemple, perte la plus faible)
- Créer un modèle aussi simple que possible (par exemple, forte régularisation)
Par exemple, une fonction qui minimise la perte et effectue la régularisation sur l'ensemble d'entraînement est un algorithme de minimisation du risque structurel.
À comparer à la minimisation du risque empirique.
sous-agent
Modèle spécialisé et très ciblé invoqué par un agent gestionnaire pour traiter un sous-ensemble spécifique d'un problème plus vaste. Les sous-agents disposent généralement d'un espace d'actions plus restreint que les agents.
sous-échantillonnage
Voir pooling.
jeton de sous-mot
Dans les modèles de langage, un jeton est une sous-chaîne d'un mot, qui peut être le mot entier.
Par exemple, un mot comme "itemize" (détailler) peut être divisé en "item" (article, mot racine) et "ize" (suffixe), chacun étant représenté par son propre jeton. La division des mots rares en sous-mots permet aux modèles de langage de fonctionner sur les parties constitutives les plus courantes du mot, telles que les préfixes et les suffixes.
Inversement, les mots courants tels que "going" (aller) peuvent ne pas être segmentés et être représentés par un seul jeton.
résumé
Dans TensorFlow, valeur ou ensemble de valeurs calculées à un pas donné, généralement utilisé pour effectuer le suivi des métriques du modèle pendant l'entraînement.
SuperGLUE
Ensemble de données permettant d'évaluer la capacité globale d'un LLM à comprendre et à générer du texte. L'ensemble comprend les ensembles de données suivants :
- Questions booléennes (BoolQ)
- CommitmentBank (CB)
- Choix d'alternatives plausibles (COPA)
- Compréhension écrite multisentence (MultiRC)
- Ensemble de données pour la compréhension écrite avec raisonnement logique (ReCoRD)
- Reconnaissance de l'implication textuelle (RTE)
- Mots dans leur contexte (WiC)
- Winograd Schema Challenge (WSC)
Pour en savoir plus, consultez SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.
machine learning supervisé
Entraînement d'un modèle à partir de caractéristiques et de leurs libellés correspondants. Le machine learning supervisé est comparable à l'apprentissage d'un sujet en étudiant une série de questions et les réponses correspondantes. Après avoir maîtrisé la mise en correspondance entre les questions et les réponses, un élève peut ensuite répondre à de nouvelles questions (jamais vues auparavant) sur le même sujet.
À comparer au machine learning non supervisé.
Pour en savoir plus, consultez la section Apprentissage supervisé du cours "Introduction au ML".
caractéristique synthétique
Une caractéristique absente des caractéristiques d'entrée, mais assemblée à partir d'une ou plusieurs d'entre elles. Voici quelques méthodes pour créer des caractéristiques synthétiques :
- Binning d'une caractéristique continue dans des paquets de plage
- Création d'un croisement de caractéristiques
- Multiplication (ou division) d'une valeur de caractéristique par d'autres valeurs de caractéristiques ou par elle-même Par exemple, si
aetbsont des caractéristiques d'entrée, les exemples suivants sont des caractéristiques synthétiques :- ab
- a2
- Appliquer une fonction transcendante à une valeur de caractéristique. Par exemple, si
cest une caractéristique d'entrée, les exemples suivants sont des caractéristiques synthétiques :- sin(c)
- ln(c)
Les caractéristiques créées par normalisation ou mise à l'échelle ne sont pas considérées comme des caractéristiques synthétiques.
T
T5
Un modèle d'apprentissage par transfert de texte à texte introduit par Google AI en 2020. T5 est un modèle encodeur-décodeur basé sur l'architecture Transformer et entraîné sur un ensemble de données extrêmement volumineux. Il est efficace pour diverses tâches de traitement du langage naturel, comme la génération de texte, la traduction de langues et la réponse à des questions de manière conversationnelle.
Le nom T5 provient des cinq T de "Text-to-Text Transfer Transformer".
T5X
Framework de machine learning Open Source conçu pour créer et entraîner des modèles de traitement du langage naturel (TLN) à grande échelle. T5 est implémenté sur la codebase T5X (qui est basée sur JAX et Flax).
Q-learning tabulaire
Dans l'apprentissage par renforcement, l'apprentissage par Q-learning est implémenté à l'aide d'un tableau pour stocker les fonctions Q pour chaque combinaison d'état et d'action.
cible
Synonyme d'étiquette.
réseau cible
Dans l'apprentissage par renforcement profond avec Q-learning, un réseau de neurones est une approximation stable du réseau de neurones principal, où le réseau de neurones principal implémente une fonction Q ou une stratégie. Vous pouvez ensuite entraîner le réseau principal sur les valeurs Q prédites par le réseau cible. Vous évitez ainsi la boucle de rétroaction qui se produit lorsque le réseau principal s'entraîne sur des valeurs Q qu'il a lui-même prédites. En évitant ce retour d'information, la stabilité de l'entraînement augmente.
opération
Un problème pouvant être résolu à l'aide de techniques de machine learning, par exemple :
décomposition des tâches
Décomposer un objectif important en étapes atomiques et exécutables. Les agents gèrent certains problèmes en décomposant les tâches.
température
Un hyperparamètre qui contrôle le degré de hasard de la sortie d'un modèle. Les températures plus élevées entraînent des résultats plus aléatoires, tandis que les températures plus basses entraînent des résultats moins aléatoires.
Le choix de la température optimale dépend de l'application spécifique et/ou des valeurs de chaîne.
données temporelles
Données enregistrées à différents moments. Par exemple, les ventes de manteaux d'hiver enregistrées pour chaque jour de l'année sont des données temporelles.
Tensor
Structure de données principale des programmes TensorFlow. Les Tensors sont des structures de données à N dimensions (où N peut être très grand), le plus souvent des scalaires, des vecteurs ou des matrices. Les éléments d'un Tensor peuvent contenir des valeurs de type entier, à virgule flottante ou chaîne.
TensorBoard
Tableau de bord qui affiche les résumés enregistrés lors de l'exécution d'un ou de plusieurs programmes TensorFlow.
TensorFlow
Plate-forme de machine learning distribuée à grande échelle. Le terme fait également référence à la couche d'API de base de la pile TensorFlow, qui prend en charge le calcul général sur les graphiques de flux de données.
Bien que TensorFlow soit principalement utilisé pour le machine learning, vous pouvez également l'utiliser pour des tâches non liées au ML qui nécessitent un calcul numérique à l'aide de graphiques de flux de données.
TensorFlow Playground
Programme qui visualise l'influence de différents hyperparamètres sur l'entraînement d'un modèle (principalement un réseau de neurones). Pour découvrir TensorFlow Playground, rendez-vous sur http://playground.tensorflow.org.
TensorFlow Serving
Plate-forme permettant de déployer des modèles entraînés en production.
Tensor Processing Unit (TPU)
Circuit intégré propre à une application (ASIC) qui optimise les performances des charges de travail de machine learning. Ces ASIC sont déployés sous la forme de plusieurs puces TPU sur un appareil TPU.
Rang de Tensor
Voir rang (Tensor).
Forme du Tensor
Nombre d'éléments d'un Tensor dans différentes dimensions.
Par exemple, un Tensor [5, 10] a une forme de 5 dans une dimension et de 10 dans une autre.
Taille du Tensor
Nombre total de grandeurs scalaires d'un Tensor. Par exemple, la taille d'un Tensor [5, 10] est de 50.
TensorStore
Une bibliothèque permettant de lire et d'écrire efficacement de grands tableaux multidimensionnels.
condition de fin
Dans l'IA agentique, les critères prédéfinis qui indiquent à l'agent d'arrêter d'itérer. Voici quelques exemples de conditions de résiliation :
- L'agent a atteint l'objectif.
- L'agent ne peut plus utiliser de ressources.
- Un human-in-the-loop a détecté un problème.
Dans l'apprentissage par renforcement, les conditions qui déterminent la fin d'un épisode, par exemple lorsque l'agent atteint un certain état ou dépasse un nombre seuil de transitions d'état. Par exemple, dans tic-tac-toe (également connu sous le nom de noughts and crosses), un épisode se termine lorsqu'un joueur marque trois espaces consécutifs ou lorsque tous les espaces sont marqués.
test
Dans un arbre de décision, autre nom pour une condition.
perte de test
Une métrique représentant la perte d'un modèle par rapport à l'ensemble de test. Lorsque vous créez un modèle, vous essayez généralement de minimiser la perte de test. En effet, une faible perte de test est un signal de qualité plus fort qu'une faible perte d'entraînement ou une faible perte de validation.
Un écart important entre la perte de test et la perte d'entraînement ou de validation suggère parfois que vous devez augmenter le taux de régularisation.
ensemble de test
Sous-ensemble de l'ensemble de données réservé au test d'un modèle entraîné.
Traditionnellement, vous divisez les exemples de l'ensemble de données en trois sous-ensembles distincts :
- un ensemble d'entraînement
- un ensemble de validation.
- un ensemble de test ;
Chaque exemple d'un ensemble de données ne doit appartenir qu'à l'un des sous-ensembles précédents. Par exemple, un même exemple ne doit pas appartenir à la fois à l'ensemble d'entraînement et à l'ensemble de test.
L'ensemble d'entraînement et l'ensemble de validation sont tous deux étroitement liés à l'entraînement d'un modèle. Étant donné que l'ensemble de test n'est associé à l'entraînement qu'indirectement, la perte de test est une métrique de meilleure qualité et moins biaisée que la perte d'entraînement ou la perte de validation.
Pour en savoir plus, consultez Ensembles de données : diviser l'ensemble de données d'origine dans le cours d'initiation au machine learning.
span de texte
Plage d'index du tableau associée à une sous-section spécifique d'une chaîne de texte.
Par exemple, le mot good dans la chaîne Python s="Be good now" occupe la plage de texte de 3 à 6.
tf.Example
Protocol Buffer standard pour la description des données d'entrée, pour l'inférence ou l'entraînement d'un modèle de machine learning.
tf.keras
Implémentation de Keras intégrée à TensorFlow.
seuil (pour les arbres de décision)
Dans une condition alignée sur un axe, il s'agit de la valeur à laquelle une caractéristique est comparée. Par exemple, 75 est la valeur seuil dans la condition suivante :
grade >= 75
Pour en savoir plus, consultez Splitter exact pour la classification binaire avec des caractéristiques numériques dans le cours sur les forêts de décision.
analyse de séries temporelles
Sous-domaine du machine learning et de la statistique qui analyse les données temporelles. De nombreux types de problèmes de machine learning nécessitent une analyse de séries temporelles, y compris la classification, le clustering, la prévision et la détection d'anomalies. Vous pouvez par exemple utiliser l'analyse de séries temporelles pour prédire les ventes mensuelles de manteaux d'hiver à partir des données de vente historiques.
pas de temps
Cellule "déroulée" dans un réseau de neurones récurrent. Par exemple, la figure suivante montre trois pas de temps (identifiés par les indices t-1, t et t+1) :

jeton
Dans un modèle de langage, le jeton est l'unité atomique sur laquelle le modèle effectue l'entraînement et les prédictions. Un jeton correspond généralement à l'un des éléments suivants :
- un mot (par exemple, l'expression "les chiens aiment les chats" se compose de trois jetons de mots : "les", "chiens" et "aiment").
- un caractère : par exemple, l'expression "poisson à vélo" se compose de neuf jetons de caractères. (Notez que l'espace vide compte comme l'un des jetons.)
- sous-mots : un mot peut être un jeton unique ou plusieurs jetons. Un sous-mot se compose d'un mot racine, d'un préfixe ou d'un suffixe. Par exemple, un modèle de langage qui utilise des sous-mots comme jetons peut considérer le mot "chiens" comme deux jetons (le mot racine "chien" et le suffixe pluriel "s"). Ce même modèle de langage peut considérer le mot "plus grand" comme deux sous-mots (le mot racine "grand" et le suffixe "er").
Dans les domaines autres que les modèles de langage, les jetons peuvent représenter d'autres types d'unités atomiques. Par exemple, dans les applications de vision par ordinateur, un jeton peut être un sous-ensemble d'une image.
Pour en savoir plus, consultez Grands modèles de langage dans le cours d'initiation au machine learning.
tokenizer
Système ou algorithme qui traduit une séquence de données d'entrée en jetons.
La plupart des modèles de fondation modernes sont multimodaux. Un tokenizer pour un système multimodal doit traduire chaque type d'entrée dans le format approprié. Par exemple, étant donné des données d'entrée composées à la fois de texte et de graphiques, le tokenizer peut traduire le texte d'entrée en sous-mots et les images d'entrée en petits blocs. Le tokenizer doit ensuite convertir tous les jetons en un seul espace d'intégration unifié, ce qui permet au modèle de "comprendre" un flux d'entrée multimodal.
Précision top-k
Pourcentage de fois où un "libellé cible" apparaît dans les k premières positions des listes générées. Les listes peuvent être des recommandations personnalisées ou une liste d'éléments classés par softmax.
La précision top-k est également appelée précision à k.
tour
Composant d'un réseau de neurones profond qui est lui-même un réseau de neurones profond. Dans certains cas, chaque tour lit à partir d'une source de données indépendante, et ces tours restent indépendants jusqu'à ce que leur sortie soit combinée dans une couche finale. Dans d'autres cas (par exemple, dans la tour encodeur et la tour décodeur de nombreux Transformers), les tours sont interconnectées.
toxique
Degré de violence, de menace ou de caractère offensant du contenu. De nombreux modèles de machine learning peuvent identifier, mesurer et classer la toxicité. La plupart de ces modèles identifient la toxicité selon plusieurs paramètres, tels que le niveau de langage abusif et le niveau de langage menaçant.
TPU
Abréviation de Tensor Processing Unit.
Puce TPU
Accélérateur d'algèbre linéaire programmable avec mémoire à haute bande passante sur puce, optimisé pour les charges de travail de machine learning. Plusieurs puces TPU sont déployées sur un appareil TPU.
Appareil TPU
Carte de circuit imprimé (PCB) comportant plusieurs puces TPU, des interfaces réseau à bande passante élevée et du matériel de refroidissement du système.
Nœud TPU
Ressource TPU sur Google Cloud avec un type de TPU spécifique. Le nœud TPU se connecte à votre réseau VPC à partir d'un réseau VPC pair. Les nœuds TPU sont une ressource définie dans l'API Cloud TPU.
Pod TPU
Configuration spécifique d'appareils TPU dans un centre de données Google. Tous les appareils d'un pod TPU sont interconnectés sur un réseau haut débit dédié. Un pod TPU est la plus grande configuration d'appareils TPU disponible pour une version spécifique de TPU.
Ressource TPU
Entité TPU sur Google Cloud que vous créez, gérez ou utilisez. Par exemple, les nœuds TPU et les types de TPU sont des ressources TPU.
Tranche TPU
Une tranche de TPU est une fraction des appareils TPU d'un pod TPU. Tous les appareils d'une tranche TPU sont interconnectés sur un réseau haut débit dédié.
Type de TPU
Configuration d'un ou plusieurs appareils TPU avec une version matérielle de TPU spécifique. Vous sélectionnez un type de TPU lorsque vous créez un nœud TPU sur Google Cloud. Par exemple, un type de TPU v2-8 est un appareil TPU v2 unique avec huit cœurs. Un type de TPU v3-2048 comporte 256 appareils TPU v3 en réseau et un total de 2 048 cœurs. Les types de TPU sont des ressources définies dans l'API Cloud TPU.
Nœud de calcul TPU
Processus qui s'exécute sur une machine hôte et exécute des programmes de machine learning sur des appareils TPU.
entraînement
Processus consistant à déterminer les paramètres (pondérations et biais) idéaux d'un modèle. Lors de l'entraînement, un système lit des exemples et ajuste progressivement les paramètres. L'entraînement utilise chaque exemple de quelques fois à des milliards de fois.
Pour en savoir plus, consultez la section Apprentissage supervisé du cours "Introduction au ML".
perte d'entraînement
Métrique représentant la perte d'un modèle lors d'une itération d'entraînement spécifique. Par exemple, supposons que la fonction de perte soit Mean Squared Error. Par exemple, la perte d'entraînement (erreur quadratique moyenne) pour la 10e itération est de 2,2, et celle pour la 100e itération est de 1,9.
Une courbe de perte représente la perte d'entraînement par rapport au nombre d'itérations. Une courbe de perte fournit les indications suivantes sur l'entraînement :
- Une pente descendante signifie que le modèle s'améliore.
- Une pente ascendante signifie que le modèle se dégrade.
- Une pente plate implique que le modèle a atteint la convergence.
Par exemple, la courbe de perte suivante, quelque peu idéalisée, montre :
- Une pente descendante abrupte lors des itérations initiales, ce qui implique une amélioration rapide du modèle.
- Une pente qui s'aplatit progressivement (mais reste descendante) jusqu'à la fin de l'entraînement, ce qui implique une amélioration continue du modèle à un rythme un peu plus lent que lors des itérations initiales.
- Une pente plate vers la fin de l'entraînement, ce qui suggère une convergence.
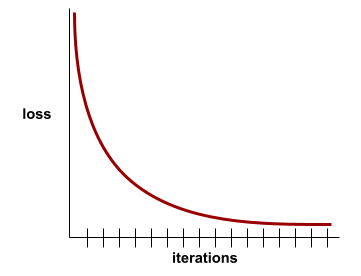
Bien que la perte d'entraînement soit importante, consultez également la généralisation.
décalage entraînement/mise en service
La différence entre les performances d'un modèle pendant l'entraînement et celles du même modèle pendant la diffusion.
ensemble d'entraînement
Sous-ensemble de l'ensemble de données utilisé pour entraîner un modèle.
Traditionnellement, les exemples de l'ensemble de données sont divisés en trois sous-ensembles distincts :
- un ensemble d'entraînement ;
- un ensemble de validation.
- un ensemble de test ;
Idéalement, chaque exemple de l'ensemble de données ne doit appartenir qu'à l'un des sous-ensembles précédents. Par exemple, un même exemple ne doit pas appartenir à la fois à l'ensemble d'entraînement et à l'ensemble de validation.
Pour en savoir plus, consultez Ensembles de données : diviser l'ensemble de données d'origine dans le cours d'initiation au machine learning.
trajectoire
Dans l'apprentissage par renforcement, une séquence de tuples représente une séquence de transitions d'état de l'agent, où chaque tuple correspond à l'état, à l'action, à la récompense et à l'état suivant pour une transition d'état donnée.
apprentissage par transfert
Transfert d'informations d'une tâche de machine learning à une autre. Par exemple, dans un apprentissage multitâche, un seul modèle résout plusieurs tâches. C'est le cas des modèles profonds, qui ont différents nœuds de sortie pour différentes tâches. L'apprentissage par transfert peut impliquer le transfert de connaissances de la solution d'une tâche plus simple vers une tâche plus complexe, ou le transfert de connaissances d'une tâche où il y a plus de données vers une tâche où il y en a moins.
La plupart des systèmes de machine learning résolvent une seule tâche. L'apprentissage par transfert est une première étape vers l'intelligence artificielle, dans laquelle un seul programme peut résoudre plusieurs tâches.
Transformer
Architecture de réseau de neurones développée chez Google, qui s'appuie sur des mécanismes d'auto-attention pour transformer une séquence d'intégrations d'entrée en une séquence d'intégrations de sortie sans s'appuyer sur des convolutions ni sur des réseaux de neurones récurrents. Un Transformer peut être considéré comme une pile de couches d'auto-attention.
Un Transformer peut inclure l'un des éléments suivants :
Un encodeur transforme une séquence d'embeddings en une nouvelle séquence de même longueur. Un encodeur comprend N couches identiques, chacune contenant deux sous-couches. Ces deux sous-couches sont appliquées à chaque position de la séquence d'intégration d'entrée, transformant chaque élément de la séquence en une nouvelle intégration. La première sous-couche de l'encodeur agrège les informations de toute la séquence d'entrée. La deuxième sous-couche de l'encodeur transforme les informations agrégées en un embedding de sortie.
Un décodeur transforme une séquence d'embeddings d'entrée en une séquence d'embeddings de sortie, éventuellement de longueur différente. Un décodeur comprend également N calques identiques avec trois sous-calques, dont deux sont semblables aux sous-calques de l'encodeur. La troisième sous-couche du décodeur prend la sortie de l'encodeur et applique le mécanisme d'auto-attention pour collecter des informations à partir de celle-ci.
L'article de blog Transformer : une nouvelle architecture de réseau de neurones pour la compréhension du langage constitue une bonne introduction aux Transformers.
Pour en savoir plus, consultez LLM : qu'est-ce qu'un grand modèle de langage ? dans le cours d'initiation au machine learning.
invariance par translation
Dans un problème de classification d'images, il s'agit de la capacité d'un algorithme à classer correctement les images même lorsque la position des objets qu'elles contiennent change. Par exemple, l'algorithme peut identifier un chien comme tel, qu'il se trouve au centre ou à gauche de l'image.
Voir aussi invariance par redimensionnement et invariance par rotation.
prompting par arbre de pensée (ToT)
Stratégie de requête sophistiquée qui encourage un LLM à poursuivre et à affiner les solutions intermédiaires les plus prometteuses, et à abandonner les autres. L'incitation à l'arbre de pensée utilise un algorithme comme celui-ci :
- Divisez un problème complexe en différentes branches (stratégies potentielles), chacune comprenant plusieurs étapes.
- Demandez au LLM de travailler sur chaque branche de manière indépendante.
- Demandez au LLM d'évaluer la qualité de la solution pour chaque branche après chaque étape.
- Continuez à affiner la ou les branches les plus prometteuses et abandonnez les autres.
- Si une branche prometteuse finit par échouer, revenez en arrière et essayez d'autres étapes prometteuses.
trigramme
Un N-gramme dans lequel N=3.
Questions-réponses sur des questions de culture générale
Ensembles de données permettant d'évaluer la capacité d'un LLM à répondre à des questions de culture générale. Chaque ensemble de données contient des paires de questions-réponses créées par des passionnés de quiz. Différents ensembles de données sont ancrés par différentes sources, y compris :
- Recherche sur le Web (TriviaQA)
- Wikipédia (TriviaQA_wiki)
Pour en savoir plus, consultez TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.
vrai négatif (VN)
Exemple dans lequel le modèle prédit correctement la classe négative. Par exemple, le modèle déduit qu'un e-mail particulier n'est pas du spam, ce qui est bien le cas.
vrai positif (VP)
Exemple dans lequel le modèle prédit correctement la classe positive. Par exemple, le modèle déduit qu'un e-mail particulier est du spam, ce qui est bien le cas.
taux de vrais positifs (TVP)
Synonyme de rappel. Par exemple :
Le taux de vrais positifs correspond à l'ordonnée d'une courbe ROC.
TTL
Abréviation de time to live (durée de vie).
Typologically Diverse Question Answering (TyDi QA)
Ensemble de données volumineux permettant d'évaluer la capacité d'un LLM à répondre à des questions. L'ensemble de données contient des paires de questions/réponses dans de nombreuses langues.
Pour en savoir plus, consultez TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages.
U
UCR
Abréviation de unsupported-claim rate (taux de revendications non acceptées).
Ultra
Le modèle Gemini avec le plus grand nombre de paramètres. Pour en savoir plus, consultez Gemini Ultra.
Inconscience (par rapport à un attribut sensible)
Situation dans laquelle des attributs sensibles sont présents, mais ne sont pas inclus dans les données d'entraînement. Étant donné que les attributs sensibles sont souvent corrélés à d'autres attributs des données, un modèle entraîné sans tenir compte d'un attribut sensible peut quand même avoir un impact disparate par rapport à cet attribut ou enfreindre d'autres contraintes d'équité.
sous-ajustement
Produire un modèle qui a une faible capacité de prédiction, car le modèle n'a pas appréhendé toute la complexité des données d'entraînement. De nombreux problèmes peuvent causer un sous-apprentissage, y compris :
- Entraînement sur un ensemble de caractéristiques inadéquat
- Entraînement sur trop peu d'époques ou avec un taux d'apprentissage trop faible.
- Entraînement avec un taux de régularisation trop élevé.
- Fournir trop peu de couches cachées dans un réseau de neurones profond.
Pour en savoir plus, consultez Surapprentissage dans le Cours d'initiation au Machine Learning.
sous-échantillonnage
Suppression d'exemples de la classe majoritaire dans un ensemble de données avec déséquilibre des classes afin de créer un ensemble d'entraînement plus équilibré.
Par exemple, considérons un ensemble de données dans lequel le ratio de la classe majoritaire par rapport à la classe minoritaire est de 20:1. Pour surmonter ce déséquilibre de classe, vous pouvez créer un ensemble d'entraînement composé de tous les exemples de la classe minoritaire, mais seulement d'un dixième des exemples de la classe majoritaire, ce qui créerait un ratio de classe d'ensemble d'entraînement de 2:1. Grâce au sous-échantillonnage, cet ensemble d'entraînement plus équilibré peut produire un meilleur modèle. En revanche, cet ensemble d'entraînement plus équilibré peut contenir un nombre insuffisant d'exemples pour entraîner un modèle efficace.
À comparer au suréchantillonnage.
unidirectionnel
Système qui n'évalue que le texte qui précède une section de texte cible. En revanche, un système bidirectionnel évalue à la fois le texte qui précède et celui qui suit une section de texte cible. Pour en savoir plus, consultez bidirectionnel.
modèle de langage unidirectionnel
Un modèle de langage qui base ses probabilités uniquement sur les jetons apparaissant avant, et non après, le ou les jetons cibles. À comparer au modèle de langage bidirectionnel.
exemple sans étiquette
Exemple contenant des caractéristiques, mais aucune étiquette. Par exemple, le tableau suivant présente trois exemples non étiquetés issus d'un modèle d'évaluation de maisons, chacun comportant trois caractéristiques, mais aucune valeur de maison :
| Nombre de chambres | Nombre de salles de bain | Ancienneté de la maison |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
Dans le machine learning supervisé, les modèles sont entraînés sur des exemples étiquetés et effectuent des prédictions sur des exemples sans étiquette.
Dans l'apprentissage semi-supervisé et non supervisé, les exemples sans étiquette sont utilisés pendant l'entraînement.
À comparer à un exemple étiqueté.
machine learning non supervisé
Entraînement d'un modèle pour détecter des schémas dans un ensemble de données, généralement sans étiquette.
Le machine learning non supervisé est surtout utilisé pour regrouper les données dans des groupes d'exemples similaires. Par exemple, un algorithme d'apprentissage automatique non supervisé peut regrouper des titres en fonction de diverses propriétés de la musique. Les clusters obtenus peuvent servir d'entrée à d'autres algorithmes de machine learning (par exemple, à un service de recommandation musicale). Le clustering peut être utile lorsque les libellés utiles sont rares ou absents. Par exemple, dans les domaines tels que la lutte contre les abus et la fraude, les clusters peuvent aider à mieux comprendre les données.
À comparer au machine learning supervisé.
Pour en savoir plus, consultez Qu'est-ce que le machine learning ? dans le cours d'introduction au ML.
Taux de réclamations non fondées
Pourcentage d'affirmations dans une réponse qui ne sont pas ancrées. Par exemple, si la réponse d'un LLM comporte 10 affirmations, mais qu'une seule est ancrée, le taux d'ancrage est de 10 %.
Un taux de couverture de l'ensemble de réponses élevé implique qu'un LLM hallucine trop souvent.
Consultez également Précision des citations et Rappel des citations.
modélisation de l'amélioration
Technique de modélisation couramment utilisée en marketing, qui modélise l'"effet causal" (également appelé "impact incrémentiel") d'un "traitement" sur un "individu". Voici deux exemples :
- Les médecins peuvent utiliser la modélisation de l'élévation pour prédire la diminution de la mortalité (effet causal) d'une procédure médicale (traitement) en fonction de l'âge et des antécédents médicaux d'un patient (individu).
- Les responsables marketing peuvent utiliser la modélisation de l'impact pour prédire l'augmentation de la probabilité d'achat (effet causal) due à une publicité (traitement) sur une personne (individu).
La modélisation de l'élévation diffère de la classification ou de la régression, car certaines étiquettes (par exemple, la moitié des étiquettes dans les traitements binaires) sont toujours manquantes dans la modélisation de l'élévation. Par exemple, un patient peut recevoir ou non un traitement. Par conséquent, nous ne pouvons observer si le patient va guérir ou non que dans l'une de ces deux situations (mais jamais les deux). Le principal avantage d'un modèle d'impact incrémental est qu'il peut générer des prédictions pour la situation non observée (le contrefactuel) et les utiliser pour calculer l'effet causal.
surpondération
Appliquer à la classe sous-échantillonnée une pondération égale au facteur de sous-échantillonnage.
matrice utilisateur
Dans les systèmes de recommandation, un vecteur d'embedding généré par la factorisation matricielle qui contient des signaux latents sur les préférences utilisateur. Chaque ligne de la matrice utilisateur contient des informations sur la force relative de divers signaux latents pour un seul utilisateur. Prenons l'exemple d'un système de recommandation de films. Dans ce système, les signaux latents de la matrice utilisateur peuvent représenter l'intérêt de chaque utilisateur pour des genres particuliers, ou bien il peut s'agir de signaux plus difficiles à interpréter impliquant des interactions complexes entre plusieurs facteurs.
La matrice utilisateur comporte une colonne pour chaque caractéristique latente et une ligne pour chaque utilisateur. Autrement dit, la matrice utilisateur a le même nombre de lignes que la matrice cible qui est factorisée. Par exemple, avec un système de recommandation de films pour 1 000 000 d'utilisateurs, la matrice utilisateur comportera 1 000 000 lignes.
V
validation
Évaluation initiale de la qualité d'un modèle. La validation vérifie la qualité des prédictions d'un modèle par rapport à l'ensemble de validation.
Étant donné que l'ensemble de validation diffère de l'ensemble d'entraînement, la validation permet de se prémunir contre le surapprentissage.
Vous pouvez considérer l'évaluation du modèle par rapport à l'ensemble de validation comme le premier cycle de test et l'évaluation du modèle par rapport à l'ensemble de test comme le deuxième cycle de test.
perte de validation
Métrique représentant la perte d'un modèle sur l'ensemble de validation au cours d'une itération d'entraînement spécifique.
Voir aussi courbe de généralisation.
ensemble de validation
Sous-ensemble de l'ensemble de données qui effectue une évaluation initiale par rapport à un modèle entraîné. En règle générale, vous évaluez le modèle entraîné par rapport à l'ensemble de validation plusieurs fois avant d'évaluer le modèle par rapport à l'ensemble de test.
Traditionnellement, vous divisez les exemples de l'ensemble de données en trois sous-ensembles distincts :
- un ensemble d'entraînement
- un ensemble de validation ;
- un ensemble de test ;
Idéalement, chaque exemple de l'ensemble de données ne doit appartenir qu'à l'un des sous-ensembles précédents. Par exemple, un même exemple ne doit pas appartenir à la fois à l'ensemble d'entraînement et à l'ensemble de validation.
Pour en savoir plus, consultez Ensembles de données : diviser l'ensemble de données d'origine dans le cours d'initiation au machine learning.
imputation de valeurs
Processus consistant à remplacer une valeur manquante par un substitut acceptable. Lorsqu'une valeur est manquante, vous pouvez soit supprimer l'intégralité de l'exemple, soit utiliser l'imputation de valeurs pour le récupérer.
Prenons l'exemple d'un ensemble de données contenant une caractéristique temperature qui doit être enregistrée toutes les heures. Toutefois, la température n'était pas disponible pour une heure spécifique. Voici une section de l'ensemble de données :
| Horodatage | Température |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | missing |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
Un système peut supprimer l'exemple manquant ou imputer la température manquante comme 12, 16, 18 ou 20, selon l'algorithme d'imputation.
problème de disparition du gradient
Tendance des gradients des premières couches cachées de certains réseaux de neurones profonds à devenir étonnamment plats (faibles). Des gradients de plus en plus faibles entraînent des modifications de plus en plus petites des pondérations sur les nœuds d'un réseau de neurones profond, ce qui conduit à un apprentissage faible ou nul. Les modèles souffrant du problème de disparition du gradient deviennent difficiles, voire impossibles à entraîner. Les cellules Long Short-Term Memory (LSTM) résolvent ce problème.
À comparer au problème d'explosion du gradient.
importance des variables
Ensemble de scores indiquant l'importance relative de chaque caractéristique pour le modèle.
Prenons l'exemple d'un arbre de décision qui estime le prix des maisons. Supposons que cet arbre de décision utilise trois caractéristiques : la taille, l'âge et le style. Si un ensemble d'importances de variables pour les trois caractéristiques est calculé comme suit : {size=5.8, age=2.5, style=4.7}, alors la taille est plus importante pour l'arbre de décision que l'âge ou le style.
Il existe différentes métriques d'importance des variables, qui peuvent informer les experts en ML sur différents aspects des modèles.
Auto-encodeur variationnel (VAE)
Type d'auto-encodeur qui exploite la différence entre les entrées et les sorties pour générer des versions modifiées des entrées. Les auto-encodeurs variationnels sont utiles pour l'IA générative.
Les VAE sont basés sur l'inférence variationnelle, une technique permettant d'estimer les paramètres d'un modèle de probabilité.
vecteur
Terme très complexe dont la signification varie selon les domaines mathématiques et scientifiques. Dans le machine learning, un vecteur possède deux propriétés :
- Type de données : les vecteurs de machine learning contiennent généralement des nombres à virgule flottante.
- Nombre d'éléments : il s'agit de la longueur du vecteur ou de sa dimension.
Prenons l'exemple d'un vecteur de caractéristiques contenant huit nombres à virgule flottante. Ce vecteur de caractéristiques a une longueur ou une dimension de huit. Notez que les vecteurs de machine learning ont souvent un grand nombre de dimensions.
Vous pouvez représenter de nombreux types d'informations sous forme de vecteur. Exemple :
- Toute position à la surface de la Terre peut être représentée sous la forme d'un vecteur bidimensionnel, où une dimension est la latitude et l'autre la longitude.
- Les cours actuels de chacune des 500 actions peuvent être représentés sous la forme d'un vecteur à 500 dimensions.
- Une distribution de probabilité sur un nombre fini de classes peut être représentée sous la forme d'un vecteur. Par exemple, un système de classification multiclasse qui prédit l'une des trois couleurs de sortie (rouge, vert ou jaune) peut générer le vecteur
(0.3, 0.2, 0.5)pour signifierP[red]=0.3, P[green]=0.2, P[yellow]=0.5.
Les vecteurs peuvent être concaténés. Par conséquent, différents types de contenus multimédias peuvent être représentés sous la forme d'un seul vecteur. Certains modèles fonctionnent directement sur la concaténation de nombreux encodages one-hot.
Les processeurs spécialisés tels que les TPU sont optimisés pour effectuer des opérations mathématiques sur les vecteurs.
Un vecteur est un Tensor de rang 1.
Vertex
Plate-forme Google Cloud pour l'IA et le machine learning. Vertex fournit des outils et une infrastructure pour créer, déployer et gérer des applications d'IA, y compris l'accès aux modèles Gemini.vibe coding
Demander à un modèle d'IA générative de créer un logiciel Autrement dit, vos requêtes décrivent l'objectif et les fonctionnalités du logiciel, qu'un modèle d'IA générative traduit en code source. Le code généré ne correspond pas toujours à vos intentions. Le vibe coding nécessite donc généralement des itérations.
Andrej Karpathy a inventé le terme "vibe coding" dans ce post sur X. Dans son post sur X, Karpathy le décrit comme "un nouveau type de programmation… où vous vous laissez complètement emporter par l'ambiance…" Le terme impliquait donc à l'origine une approche intentionnellement souple de la création de logiciels, dans laquelle vous n'examiniez peut-être même pas le code généré. Toutefois, le terme a rapidement évolué dans de nombreux cercles pour désigner désormais toute forme de codage généré par l'IA.
Pour une description plus détaillée du codage des ambiances, consultez Qu'est-ce que le vibe coding ?
Comparez également le vibe coding avec :
W
Perte Wasserstein
L'une des fonctions de perte couramment utilisées dans les réseaux antagonistes génératifs, basée sur la distance Earth Mover entre la distribution des données générées et des données réelles.
weight
Valeur par laquelle un modèle multiplie une autre valeur. L'entraînement est le processus qui consiste à déterminer les pondérations idéales d'un modèle. L'inférence est le processus qui consiste à utiliser ces pondérations apprises pour faire des prédictions.
Pour en savoir plus, consultez Régression linéaire dans le Cours d'initiation au Machine Learning.
Moindres carrés alternés pondérés (WALS)
Algorithme permettant de minimiser la fonction objectif lors de la factorisation matricielle dans les systèmes de recommandation, ce qui permet de sous-pondérer les exemples manquants. WALS minimise l'erreur quadratique pondérée entre la matrice d'origine et la reconstruction en corrigeant alternativement la factorisation des lignes et la factorisation des colonnes. Chacune de ces optimisations peut être résolue par l'optimisation convexe des moindres carrés. Pour en savoir plus, consultez le cours sur les systèmes de recommandation.
Somme pondérée
Somme de toutes les valeurs d'entrée pertinentes multipliées par leurs pondérations correspondantes. Par exemple, supposons que les entrées pertinentes sont les suivantes :
| valeur d'entrée | poids d'entrée |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
La somme pondérée est donc la suivante :
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Une somme pondérée est l'argument d'entrée d'une fonction d'activation.
WiC
Abréviation de Words in Context (Mots en contexte).
modèle wide
Modèle linéaire qui contient généralement un grand nombre de caractéristiques d'entrée creuses. Ce modèle est dit "large", car il s'agit d'un type particulier de réseau de neurones comportant un grand nombre d'entrées connectées directement au nœud de sortie. Les modèles larges sont souvent plus faciles à déboguer et à inspecter que les modèles profonds. Bien que les modèles larges ne puissent pas exprimer les non-linéarités par le biais de couches cachées, ils peuvent utiliser des transformations telles que le croisement de caractéristiques et la binning pour modéliser les non-linéarités de différentes manières.
À comparer au modèle profond.
largeur
Nombre de neurones dans une couche spécifique d'un réseau de neurones.
WikiLingua (wiki_lingua)
Ensemble de données permettant d'évaluer la capacité d'un LLM à résumer des articles courts. WikiHow, une encyclopédie d'articles expliquant comment effectuer diverses tâches, est la source rédigée par des humains pour les articles et les résumés. Chaque entrée de l'ensemble de données se compose des éléments suivants :
- Un article, créé en ajoutant chaque étape de la version en prose (paragraphe) de la liste numérotée, sans la phrase d'introduction de chaque étape.
- Résumé de cet article, composé de la première phrase de chaque étape de la liste numérotée.
Pour en savoir plus, consultez WikiLingua : un nouvel ensemble de données de référence pour la synthèse abstraite multilingue.
Winograd Schema Challenge (WSC)
Format (ou ensemble de données conforme à ce format) permettant d'évaluer la capacité d'un LLM à déterminer le groupe nominal auquel un pronom fait référence.
Chaque entrée du Winograd Schema Challenge se compose des éléments suivants :
- Un court passage contenant un pronom cible
- Un pronom cible
- Groupes nominaux candidats, suivis de la bonne réponse (booléen). Si le pronom cible fait référence à ce candidat, la réponse est "True". Si le pronom cible ne fait pas référence à ce candidat, la réponse est "False" (Faux).
Exemple :
- Extrait : Mark a raconté de nombreux mensonges à Pete sur lui-même, que Pete a inclus dans son livre. Il aurait dû être plus honnête.
- Pronom cible : il
- Groupes nominaux candidats :
- Mark : "True" (Vrai), car le pronom cible fait référence à Mark
- Pete : Faux, car le pronom cible ne fait pas référence à Peter
Le Winograd Schema Challenge est un composant de l'ensemble SuperGLUE.
sagesse de la foule
L'idée selon laquelle la moyenne des opinions ou des estimations d'un grand groupe de personnes ("la foule") produit souvent des résultats étonnamment bons. Prenons l'exemple d'un jeu dans lequel les participants doivent deviner le nombre de bonbons contenus dans un grand bocal. Bien que la plupart des estimations individuelles soient inexactes, la moyenne de toutes les estimations s'est avérée étonnamment proche du nombre réel de bonbons dans le bocal.
Les ensembles sont l'équivalent logiciel de la sagesse de la foule. Même si les modèles individuels font des prédictions très inexactes, la moyenne des prédictions de nombreux modèles génère souvent des prédictions étonnamment bonnes. Par exemple, même si un arbre de décision individuel peut générer de mauvaises prédictions, une forêt de décision en génère souvent de très bonnes.
WMT
Abréviation de Conference on Machine Translation (Conférence sur la traduction automatique). (L'abréviation WMT vient de l'anglais Workshop on Machine Translation.) La conférence se concentre sur les développements dans les systèmes de traduction automatique.
embedding de mots
Représenter chaque mot d'un ensemble de mots dans un vecteur d'intégration, c'est-à-dire représenter chaque mot sous la forme d'un vecteur de valeurs à virgule flottante comprises entre 0,0 et 1,0. Les mots ayant des significations similaires ont des représentations plus similaires que les mots ayant des significations différentes. Par exemple, carottes, céleri et concombres auraient des représentations relativement similaires, qui seraient très différentes de celles d'avion, lunettes de soleil et dentifrice.
Mots en contexte (WiC)
Ensemble de données permettant d'évaluer la capacité d'un LLM à utiliser le contexte pour comprendre les mots ayant plusieurs significations. Chaque entrée de l'ensemble de données contient les éléments suivants :
- Deux phrases contenant chacune le mot cible
- Le mot cible
- La bonne réponse (valeur booléenne), où :
- "True" signifie que le mot cible a la même signification dans les deux phrases.
- "Faux" signifie que le mot cible a une signification différente dans les deux phrases.
Exemple :
- Deux phrases :
- Il y a beaucoup de déchets dans le lit de la rivière.
- Je garde un verre d'eau à côté de mon lit quand je dors.
- Mot cible : lit
- Bonne réponse : Faux, car le mot cible a une signification différente dans les deux phrases.
Pour en savoir plus, consultez WiC : l'ensemble de données Word-in-Context pour évaluer les représentations de sens sensibles au contexte.
Words in Context est un composant de l'ensemble SuperGLUE.
WSC
Abréviation de Winograd Schema Challenge.
X
XLA (Accelerated Linear Algebra)
Compilateur de machine learning Open Source pour les GPU, les CPU et les accélérateurs de ML.
Le compilateur XLA prend les modèles des frameworks de ML populaires tels que PyTorch, TensorFlow et JAX, et les optimise pour une exécution hautes performances sur différentes plates-formes matérielles, y compris les GPU, les processeurs et les accélérateurs de ML.
XL-Sum (xlsum)
Ensemble de données permettant d'évaluer la capacité d'un LLM à résumer du texte. XL-Sum fournit des entrées dans de nombreuses langues. Chaque entrée de l'ensemble de données contient les éléments suivants :
- Article de la British Broadcasting Company (BBC).
- Résumé de l'article, rédigé par son auteur. Notez que ce résumé peut contenir des mots ou des expressions qui ne figurent pas dans l'article.
Pour en savoir plus, consultez XL-Sum : résumé abstrait multilingue à grande échelle pour 44 langues.
xsum
Abréviation de Extreme Summarization.
Z
apprentissage zero-shot
Type d'entraînement de machine learning où le modèle infère une prédiction pour une tâche sur laquelle il n'a pas été spécifiquement entraîné. En d'autres termes, le modèle ne reçoit aucun exemple d'entraînement spécifique à la tâche, mais est invité à effectuer une inférence pour cette tâche.
prompting zero-shot
Une requête qui ne fournit pas d'exemple de réponse attendue du grand modèle de langage. Exemple :
| Composantes d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | La question à laquelle vous souhaitez que le LLM réponde. |
| Inde : | Requête réelle. |
Le grand modèle de langage peut répondre de l'une des manières suivantes :
- Roupie
- INR
- ₹
- Roupie indienne
- La roupie
- Roupie indienne
Toutes les réponses sont correctes, mais vous pouvez préférer un format particulier.
Comparez et opposez l'incitation zero-shot aux termes suivants :
Normalisation du score Z
Technique de scaling qui remplace une valeur feature brute par une valeur à virgule flottante représentant le nombre d'écarts-types par rapport à la moyenne de cette feature. Prenons l'exemple d'une caractéristique dont la moyenne est de 800 et dont l'écart-type est de 100. Le tableau suivant montre comment la normalisation du score Z mapperait la valeur brute à son score Z :
| Valeur brute | Cote Z |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
Le modèle de machine learning s'entraîne ensuite sur les scores Z de cette caractéristique au lieu des valeurs brutes.
Pour en savoir plus, consultez Données numériques : normalisation dans le Cours d'initiation au machine learning.