Depois de examinar os dados usando técnicas estatísticas e de visualização, transforme-os de maneira que ajude o modelo a treinar com mais eficiência. O objetivo da normalização é transformar recursos para que estejam em uma escala semelhante. Por exemplo, considere estas duas características:
- O recurso
Xabrange o intervalo de 154 a 24.917.482. - O recurso
Yabrange o intervalo de 5 a 22.
Esses dois recursos abrangem intervalos muito diferentes. A normalização pode manipular X e Y para que eles abranjam um intervalo semelhante, talvez de 0 a 1.
A normalização oferece os seguintes benefícios:
- Ajuda os modelos a convergir mais rapidamente durante o treinamento. Quando diferentes recursos têm intervalos diferentes, a descida do gradiente pode "oscilar" e diminuir a convergência. No entanto, otimizadores mais avançados, como Adagrad e Adam, protegem contra esse problema mudando a taxa de aprendizado efetiva ao longo do tempo.
- Ajuda os modelos a inferir previsões melhores. Quando diferentes recursos têm intervalos diferentes, o modelo resultante pode fazer previsões um pouco menos úteis.
- Ajuda a evitar a "armadilha de NaN" quando os valores de recursos são muito altos.
NaN é uma abreviação de not a number (não é um número). Quando um valor em um modelo excede o limite de precisão de ponto flutuante, o sistema define o valor como
NaNem vez de um número. Quando um número no modelo se torna um NaN, outros números no modelo também acabam se tornando um NaN. - Ajuda o modelo a aprender ponderações adequadas para cada atributo. Sem o escalonamento de atributos, o modelo presta muita atenção aos atributos com intervalos amplos e não o suficiente aos atributos com intervalos estreitos.
Recomendamos normalizar recursos numéricos que abrangem intervalos distintos (por exemplo, idade e renda).
Também recomendamos normalizar um único recurso numérico que abrange uma ampla variedade, como city population..
Considere os dois recursos a seguir:
- O menor valor da característica
Aé -0,5, e o maior é +0,5. - O menor valor da característica
Bé -5,0, e o maior é +5,0.
Os recursos A e B têm intervalos relativamente estreitos. No entanto, o intervalo do recurso B é 10 vezes maior que o do recurso A. Assim:
- No início do treinamento, o modelo pressupõe que o atributo
Bé dez vezes mais "importante" do que o atributoA. - O treinamento vai levar mais tempo do que deveria.
- O modelo resultante pode ser abaixo do ideal.
O dano geral devido à não normalização será relativamente pequeno. No entanto, ainda recomendamos normalizar o recurso A e o recurso B na mesma escala, talvez de -1,0 a +1,0.
Agora considere dois atributos com uma disparidade maior de intervalos:
- O menor valor da característica
Cé -1, e o maior é +1. - O menor valor da característica
Dé +5.000, e o maior é +1.000.000.000.
Se você não normalizar os recursos C e D, seu modelo provavelmente será inadequado. Além disso, o treinamento vai levar muito mais tempo para convergir ou até mesmo não vai convergir.
Esta seção aborda três métodos de normalização conhecidos:
- dimensionamento linear
- Escalonamento de valor Z
- dimensionamento logarítmico
Esta seção também aborda o corte. Embora não seja uma técnica de normalização verdadeira, o corte limita atributos numéricos indisciplinados a intervalos que produzem modelos melhores.
Dimensionamento linear
A escalonagem linear (mais comumente abreviada para apenas escalonagem) significa converter valores de ponto flutuante do intervalo natural para um intervalo padrão, geralmente de 0 a 1 ou de -1 a +1.
O escalonamento linear é uma boa opção quando todas as condições a seguir são atendidas:
- Os limites inferior e superior dos seus dados não mudam muito com o tempo.
- O atributo tem poucos ou nenhum outlier, e eles não são extremos.
- O recurso é distribuído de maneira aproximadamente uniforme em todo o intervalo. Ou seja, um histograma mostraria barras aproximadamente iguais para a maioria dos valores.
Suponha que age humano seja um recurso. O escalonamento linear é uma boa técnica de normalização para age porque:
- Os limites aproximados são de 0 a 100.
agecontém uma porcentagem relativamente pequena de outliers. Apenas 0,3% da população tem mais de 100 anos.- Embora algumas idades sejam mais representadas do que outras, um grande conjunto de dados deve conter exemplos suficientes de todas as idades.
Exercício: teste de conhecimentos
Suponha que seu modelo tenha um recurso chamadonet_worth que contém o patrimônio líquido de diferentes pessoas. O escalonamento linear seria uma boa técnica de normalização para net_worth? Por que sim ou por que não?
Escalonamento de valor Z
Uma pontuação Z é o número de desvios padrão de um valor em relação à média. Por exemplo, um valor que é 2 desvios padrão maior que a média tem um escore Z de +2,0. Um valor que é 1,5 desvio padrão menor que a média tem uma pontuação Z de -1,5.
Representar um atributo com escalonamento de pontuação Z significa armazenar a pontuação Z desse atributo no vetor de atributos. Por exemplo, a figura a seguir mostra dois histogramas:
- À esquerda, uma distribuição normal clássica.
- À direita, a mesma distribuição normalizada pelo escalonamento de pontuação z.
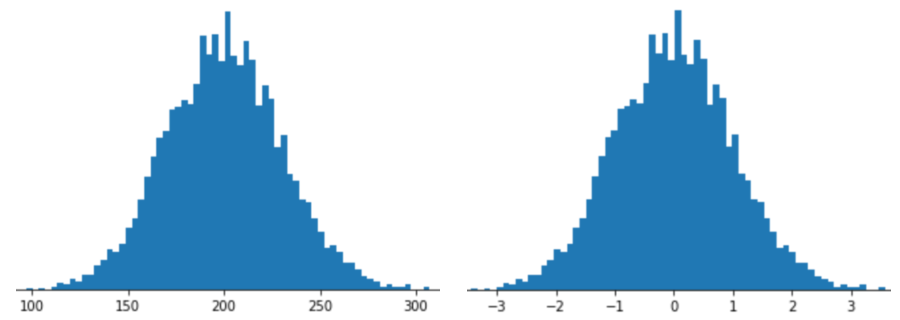
O escalonamento de pontuação Z também é uma boa opção para dados como os mostrados na figura a seguir, que tem apenas uma distribuição vagamente normal.
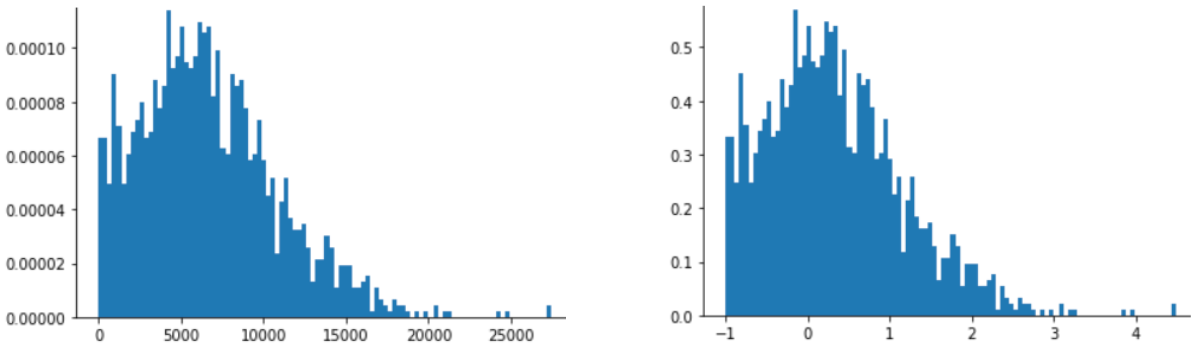
O escore Z é uma boa opção quando os dados seguem uma distribuição normal ou algo parecido.
Algumas distribuições podem ser normais na maior parte do intervalo, mas ainda conter outliers extremos. Por exemplo, quase todos os pontos em um atributo net_worth podem se encaixar perfeitamente em três desvios padrão, mas alguns exemplos desse atributo podem estar a centenas de desvios padrão da média. Nesses casos, é possível combinar o escalonamento de pontuação Z com outra forma de normalização (geralmente corte) para lidar com essa situação.
Exercício: teste de conhecimentos
Suponha que seu modelo seja treinado com um recurso chamadoheight que contém as alturas de dez milhões de mulheres adultas. O escalonamento de pontuação z seria uma boa técnica de normalização para height? Por que sim ou por que não?
Dimensionamento logarítmico
A escalonagem logarítmica calcula o logaritmo do valor bruto. Na teoria, o logaritmo pode ter qualquer base. Na prática, o escalonamento logarítmico geralmente calcula o logaritmo natural (ln).
A escalonagem logarítmica é útil quando os dados estão de acordo com uma distribuição de lei de potência. Em termos gerais, uma distribuição de lei de potência tem esta aparência:
- Valores baixos de
Xtêm valores muito altos deY. - À medida que os valores de
Xaumentam, os valores deYdiminuem rapidamente. Consequentemente, valores altos deXtêm valores muito baixos deY.
As classificações de filmes são um bom exemplo de distribuição de lei de potência. Na figura a seguir, observe:
- Alguns filmes têm muitas classificações de usuários. Valores baixos de
Xtêm valores altos deY. - A maioria dos filmes tem pouquíssimas avaliações de usuários. (Valores altos de
Xtêm valores baixos deY.)
O escalonamento logarítmico muda a distribuição, o que ajuda a treinar um modelo que fará previsões melhores.

Como segundo exemplo, as vendas de livros seguem uma distribuição de lei de potência porque:
- A maioria dos livros publicados vende um número pequeno de cópias, talvez cem ou duzentas.
- Alguns vendem um número moderado de cópias, na casa dos milhares.
- Apenas alguns best-sellers vendem mais de um milhão de cópias.
Suponha que você esteja treinando um modelo linear para encontrar a relação entre, digamos, capas de livros e vendas de livros. Um modelo linear treinado com valores brutos precisaria encontrar algo sobre as capas de livros que vendem um milhão de cópias que seja 10.000 vezes mais poderoso do que as capas de livros que vendem apenas 100 cópias. No entanto, o escalonamento logarítmico de todos os números de vendas torna a tarefa muito mais viável. Por exemplo, o logaritmo de 100 é:
~4.6 = ln(100)
enquanto o log de 1.000.000 é:
~13.8 = ln(1,000,000)
Portanto, o log de 1.000.000 é apenas cerca de três vezes maior que o log de 100. Você provavelmente pode imaginar que a capa de um livro best-seller é cerca de três vezes mais poderosa (de alguma forma) do que a capa de um livro que vende pouco.
Corte
O corte é uma técnica para minimizar a influência de outliers extremos. Em resumo, o truncamento geralmente limita (reduz) o valor dos outliers a um valor máximo específico. O corte é uma ideia estranha, mas pode ser muito eficaz.
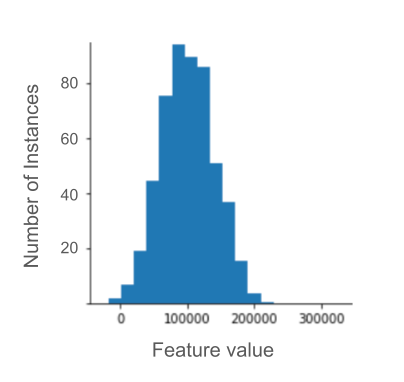
Por exemplo, imagine um conjunto de dados que contém um recurso chamado roomsPerPerson, que representa o número de cômodos (total de cômodos dividido pelo número de ocupantes) de várias casas. O gráfico a seguir mostra que mais de 99% dos valores de recursos estão em conformidade com uma distribuição normal (aproximadamente, uma média de 1,8 e um desvio padrão de 0,7). No entanto, o recurso contém alguns outliers, alguns deles extremos:
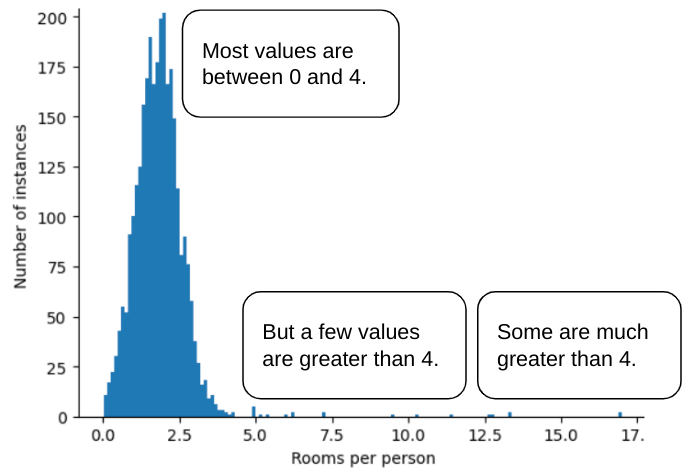
Como minimizar a influência desses outliers extremos? O histograma não é uma distribuição uniforme, normal ou de lei de potência. E se você simplesmente limitar ou cortar o valor máximo de roomsPerPerson em um valor arbitrário, digamos 4,0?
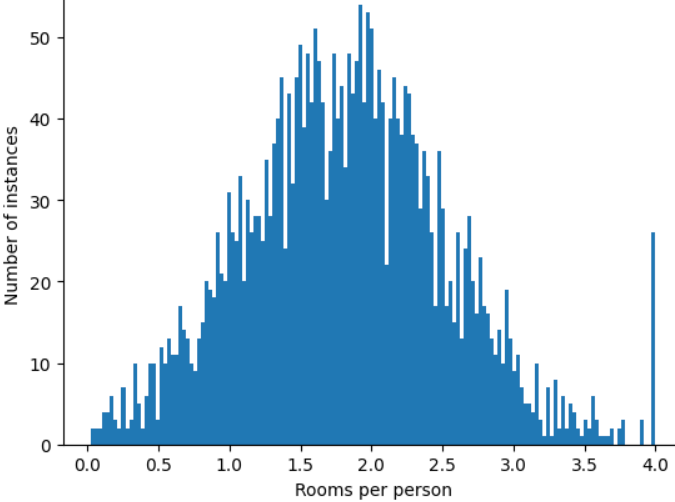
O corte do valor do recurso em 4,0 não significa que o modelo ignora todos os valores maiores que 4,0. Em vez disso, significa que todos os valores maiores que 4,0 agora se tornam 4,0. Isso explica o pico peculiar em 4,0. Apesar dessa dificuldade, o conjunto de recursos escalonado agora é mais útil do que os dados originais.
Espere um momento! É possível reduzir todos os valores discrepantes a um limite superior arbitrário? Sim, ao treinar um modelo.
Também é possível cortar valores depois de aplicar outras formas de normalização. Por exemplo, suponha que você use o escalonamento de pontuação Z, mas alguns outliers tenham valores absolutos muito maiores que 3. Nesse caso, você pode:
- Faça o corte dos escores Z maiores que 3 para que fiquem exatamente 3.
- Os valores Z de corte menores que -3 se tornam exatamente -3.
O corte impede que seu modelo indexe demais dados sem importância. No entanto, alguns outliers são importantes. Portanto, faça o corte com cuidado.
Resumo das técnicas de normalização
| Técnica de normalização | Fórmula | Quando usar |
|---|---|---|
| Dimensionamento linear | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Quando o recurso é distribuído de maneira uniforme no intervalo. Formato achatado |
| Escalonamento de valor Z | $$ x' = \frac{x - μ}{σ}$$ | Quando o recurso tem distribuição normal (pico próximo da média). Em forma de sino |
| Dimensionamento logarítmico | $$ x' = log(x)$$ | Quando a distribuição de recursos é muito assimétrica em pelo menos um dos lados da cauda. Formato de cauda pesada |
| Corte | Se $x > max$, defina $x' = max$ Se $x < min$, defina $x' = min$ |
Quando o recurso contém outliers extremos. |
Exercício: teste seu conhecimento
Imagine que você está desenvolvendo um modelo que prevê a produtividade de um data center com base na temperatura medida dentro dele.
Quase todos os valores de temperature no conjunto de dados estão entre 15 e 30 (Celsius), com as seguintes exceções:
- Uma ou duas vezes por ano, em dias extremamente quentes, alguns valores entre 31 e 45 são registrados em
temperature. - A cada milésimo ponto em
temperature,o valor é definido como 1.000,e não a temperatura real.
Qual seria uma técnica de normalização razoável para temperature?
Os valores de 1.000 são erros e precisam ser excluídos em vez de cortados.
Os valores entre 31 e 45 são pontos de dados legítimos. O corte provavelmente seria uma boa ideia para esses valores, supondo que o conjunto de dados não tenha exemplos suficientes nessa faixa de temperatura para treinar o modelo e fazer boas previsões. No entanto, durante a inferência, observe que o modelo com corte faria a mesma previsão para uma temperatura de 45 e de 35.