इस सेक्शन में, इन तीन सवालों के बारे में बताया गया है:
- क्लास-बैलेंस किए गए डेटासेट और क्लास-इंबैलेंस किए गए डेटासेट में क्या अंतर है?
- इंबैलेंस डेटासेट को ट्रेन करना मुश्किल क्यों होता है?
- डेटासेट में मौजूद डेटा के बीच अंतर होने की वजह से ट्रेनिंग में आने वाली समस्याओं को कैसे ठीक किया जा सकता है?
क्लास-बैलेंस वाले डेटासेट बनाम क्लास-इंबैलेंस वाले डेटासेट
मान लें कि आपके पास एक ऐसा डेटासेट है जिसमें कैटेगरी के हिसाब से लेबल किया गया डेटा है. इस डेटा में मौजूद वैल्यू, पॉज़िटिव क्लास या नेगेटिव क्लास में से कोई एक है. क्लास-बैलेंस वाले डेटासेट में, पॉज़िटिव क्लास और नेगेटिव क्लास की संख्या लगभग बराबर होती है. उदाहरण के लिए, 235 पॉज़िटिव क्लास और 247 नेगेटिव क्लास वाला डेटासेट, एक संतुलित डेटासेट है.
क्लास-इंबैलेंस वाले डेटासेट में, एक लेबल दूसरे लेबल की तुलना में ज़्यादा बार दिखता है. असल दुनिया में, क्लास-इंबैलेंस वाले डेटासेट, क्लास-बैलेंस वाले डेटासेट की तुलना में ज़्यादा आम हैं. उदाहरण के लिए, क्रेडिट कार्ड से किए गए लेन-देन के डेटासेट में, धोखाधड़ी वाली खरीदारी के उदाहरण 0.1% से भी कम हो सकते हैं. इसी तरह, किसी बीमारी की जांच से जुड़े डेटासेट में, किसी दुर्लभ वायरस से पीड़ित मरीज़ों की संख्या, कुल उदाहरणों के 0.01% से कम हो सकती है. क्लास के असंतुलित डेटासेट में:
- ज़्यादा सामान्य लेबल को मेजोरिटी क्लास कहा जाता है.
- कम सामान्य लेबल को माइनॉरिटी क्लास कहा जाता है.
क्लास के बीच काफ़ी अंतर वाले डेटासेट को ट्रेन करने में आने वाली समस्या
ट्रेनिंग का मकसद ऐसा मॉडल बनाना है जो पॉज़िटिव क्लास को नेगेटिव क्लास से अलग कर सके. इसके लिए, बैच में पॉज़िटिव क्लास और नेगेटिव क्लास, दोनों की ज़रूरी संख्या होनी चाहिए. क्लास के बीच थोड़ा अंतर वाले डेटासेट पर ट्रेनिंग करते समय, यह समस्या नहीं होती. ऐसा इसलिए, क्योंकि छोटे बैच में भी आम तौर पर पॉज़िटिव क्लास और नेगेटिव क्लास, दोनों के लिए ज़रूरी उदाहरण शामिल होते हैं. हालांकि, क्लास के हिसाब से बहुत ज़्यादा असंतुलित डेटासेट में, सही ट्रेनिंग के लिए माइनॉरिटी क्लास के उदाहरण काफ़ी नहीं हो सकते.
उदाहरण के लिए, फ़िगर 6 में दिखाए गए क्लास-इंबैलेंस वाले डेटासेट पर विचार करें. इसमें:
- ज़्यादातर क्लास में 200 लेबल हैं.
- दो लेबल माइनॉरिटी क्लास में हैं.
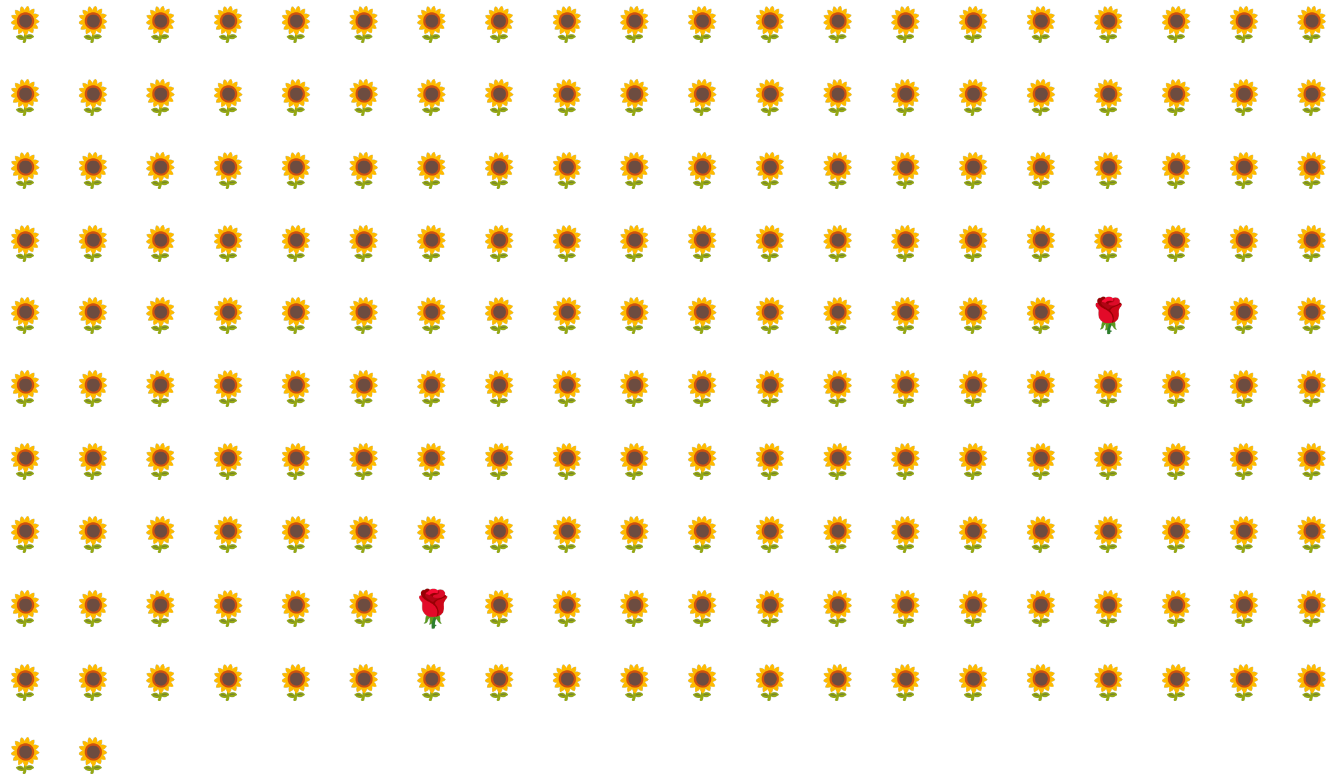
अगर बैच का साइज़ 20 है, तो ज़्यादातर बैच में माइनॉरिटी क्लास का कोई उदाहरण नहीं होगा. अगर बैच का साइज़ 100 है, तो हर बैच में औसतन सिर्फ़ एक माइनॉरिटी क्लास का उदाहरण होगा. यह सही ट्रेनिंग के लिए काफ़ी नहीं है. बैच का साइज़ बहुत बड़ा होने पर भी, डेटा का अनुपात इतना असंतुलित होगा कि मॉडल को सही तरीके से ट्रेन नहीं किया जा सकेगा.
क्लास के असंतुलित डेटासेट को ट्रेन करना
ट्रेनिंग के दौरान, मॉडल को दो चीज़ें सीखनी चाहिए:
- हर क्लास कैसी दिखती है. इसका मतलब है कि कौनसी सुविधा की वैल्यू, किस क्लास से मेल खाती है?
- हर क्लास कितनी सामान्य है. इसका मतलब है कि क्लास का डिस्ट्रिब्यूशन कितना है?
स्टैंडर्ड ट्रेनिंग में, इन दोनों लक्ष्यों को एक साथ रखा जाता है. इसके उलट, डाउनसैंपलिंग और मेजॉरिटी क्लास को अपवेट करना नाम की दो चरणों वाली इस तकनीक में, इन दोनों लक्ष्यों को अलग-अलग रखा जाता है. इससे मॉडल, दोनों लक्ष्यों को हासिल कर पाता है.
पहला चरण: मेजॉरिटी क्लास के डेटा को कम करना
डाउनसैंपलिंग का मतलब है कि ज़्यादातर क्लास के उदाहरणों के बहुत कम प्रतिशत पर ट्रेनिंग दी जाती है. इसका मतलब है कि ट्रेनिंग के दौरान, ज़्यादातर क्लास के उदाहरणों को हटाकर, क्लास के असंतुलित डेटासेट को कुछ हद तक संतुलित किया जाता है. डाउनसैंपलिंग से, इस बात की संभावना काफ़ी बढ़ जाती है कि हर बैच में माइनॉरिटी क्लास के काफ़ी उदाहरण मौजूद हों, ताकि मॉडल को सही तरीके से और असरदार तरीके से ट्रेन किया जा सके.
उदाहरण के लिए, इमेज 6 में दिखाया गया क्लास-इंबैलेंस वाला डेटासेट, 99% मेजॉरिटी क्लास और 1% माइनॉरिटी क्लास के उदाहरणों से मिलकर बना है. ज़्यादातर क्लास को 25 के फ़ैक्टर से डाउनसैंपल करने पर, ट्रेनिंग के लिए ज़्यादा संतुलित सेट (ज़्यादातर क्लास के लिए 80% और कम क्लास के लिए 20%) आर्टिफ़िशियली तौर पर तैयार होता है. इसके बारे में, इमेज 7 में बताया गया है:

दूसरा चरण: डाउनसैंपल की गई क्लास को अपवेट करना
डाउनसैंपलिंग से, पूर्वानुमान में पूर्वाग्रह पैदा होता है. ऐसा इसलिए होता है, क्योंकि मॉडल को एक ऐसा आर्टिफ़िशियल एनवायरमेंट दिखाया जाता है जहां क्लास, असल दुनिया की तुलना में ज़्यादा संतुलित होती हैं. इस पूर्वाग्रह को ठीक करने के लिए, आपको ज़्यादातर क्लास को उस फ़ैक्टर से "अपवेट" करना होगा जिससे आपने डाउनसैंपल किया था. अपवेटिंग का मतलब है कि ज़्यादातर क्लास के उदाहरण में होने वाले नुकसान को, माइनॉरिटी क्लास के उदाहरण में होने वाले नुकसान की तुलना में ज़्यादा गंभीरता से लेना.
उदाहरण के लिए, हमने मेजॉरिटी क्लास को 25 के फ़ैक्टर से डाउनसैंपल किया है. इसलिए, हमें मेजॉरिटी क्लास को 25 के फ़ैक्टर से अपवेट करना होगा. इसका मतलब है कि जब मॉडल, ज़्यादातर क्लास का अनुमान गलत तरीके से लगाता है, तो नुकसान को इस तरह से माना जाता है जैसे कि 25 गड़बड़ियां हुई हों. इसके लिए, सामान्य नुकसान को 25 से गुणा किया जाता है.

अपने डेटासेट को फिर से बैलेंस करने के लिए, आपको डाउनसैंपल और अपवेट कितना करना चाहिए? जवाब तय करने के लिए, आपको अलग-अलग डाउनसैंपलिंग और अपवेटिंग फ़ैक्टर आज़माने चाहिए. ठीक उसी तरह जैसे अन्य हाइपरपैरामीटर आज़माए जाते हैं.
इस तकनीक के फ़ायदे
मेजर क्लास को डाउनसैंपल करने और अपवेट करने से ये फ़ायदे मिलते हैं:
- बेहतर मॉडल: नतीजे के तौर पर मिले मॉडल को इन दोनों के बारे में "पता" होता है:
- सुविधाओं और लेबल के बीच कनेक्शन
- क्लास का सही डिस्ट्रिब्यूशन
- तेज़ी से कन्वर्जेंस: ट्रेनिंग के दौरान, मॉडल को माइनॉरिटी क्लास ज़्यादा बार दिखती है. इससे मॉडल को तेज़ी से कन्वर्ज होने में मदद मिलती है.