이전 연습 에서 보셨듯이, 신경망에 은닉층을 추가하는 것만으로는 비선형성을 표현하기에 충분하지 않습니다. 선형 연산에 선형 연산을 수행해도 여전히 선형 연산으로 처리됩니다.
신경망이 값들 사이의 비선형 관계를 학습하도록 구성하려면 어떻게 해야 할까요? 모델에 비선형 수학 연산을 삽입할 수 있는 방법이 필요합니다.
이 내용이 다소 익숙하게 느껴진다면, 그 이유는 우리가 수업 초반에 선형 모델의 출력에 비선형 수학 연산을 적용했기 때문입니다. 로지스틱 회귀 모듈에서 우리는 선형 회귀 모델의 출력값을 시그모이드 함수 에 통과시켜 0에서 1 사이의 연속적인 값(확률을 나타냄)을 출력하도록 모델을 수정했습니다.
우리는 동일한 원리를 신경망에도 적용할 수 있습니다. 앞서 연습문제 2 에서 사용했던 모델을 다시 살펴보되, 이번에는 각 노드의 값을 출력하기 전에 먼저 시그모이드 함수를 적용해 보겠습니다.
재생 버튼 오른쪽에 있는 >| 버튼을 클릭하여 각 노드의 계산 과정을 단계별로 살펴보세요. 그래프 아래의 계산 패널에서 각 노드 값을 계산하는 데 사용된 수학적 연산을 확인할 수 있습니다. 각 노드의 출력은 이전 레이어 노드들의 선형 조합에 대한 시그모이드 변환이며, 출력값은 모두 0과 1 사이에 집중되어 있음을 알 수 있습니다.
여기서 시그모이드 함수는 신경망의 활성화 함수 역할을 하며, 뉴런의 출력값이 다음 레이어의 계산에 입력으로 전달되기 전에 비선형 변환을 수행합니다.
활성화 함수를 추가했으므로 레이어를 추가하는 것이 더 큰 영향을 미칩니다. 비선형 함수 위에 비선형 함수를 쌓아 올리면 입력과 예측 출력 사이의 매우 복잡한 관계를 모델링할 수 있습니다. 간단히 말하면, 각 레이어는 원시 입력에 대해 더 복잡하고 고차원적인 함수를 학습하는 것입니다. 이 작동 방식에 대한 더 깊은 이해를 원하시면 Chris Olah의 훌륭한 블로그 게시물을 참조하세요.
공통 활성화 기능
활성화 함수로 흔히 사용되는 세 가지 수학 함수는 시그모이드, tanh, 그리고 ReLU입니다.
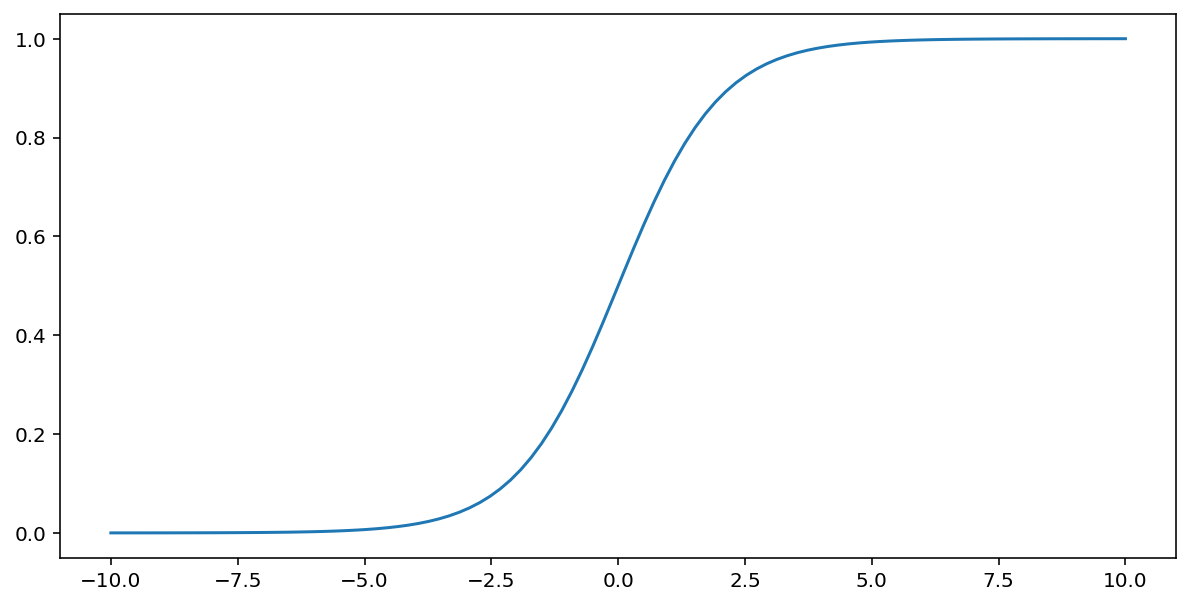
위에서 설명한 시그모이드 함수는 입력값 $x$에 다음과 같은 변환을 수행하여 0과 1 사이의 출력값을 생성합니다.
\[F(x)=\frac{1} {1+e^{-x}}\]
다음은 이 함수의 그래프입니다.
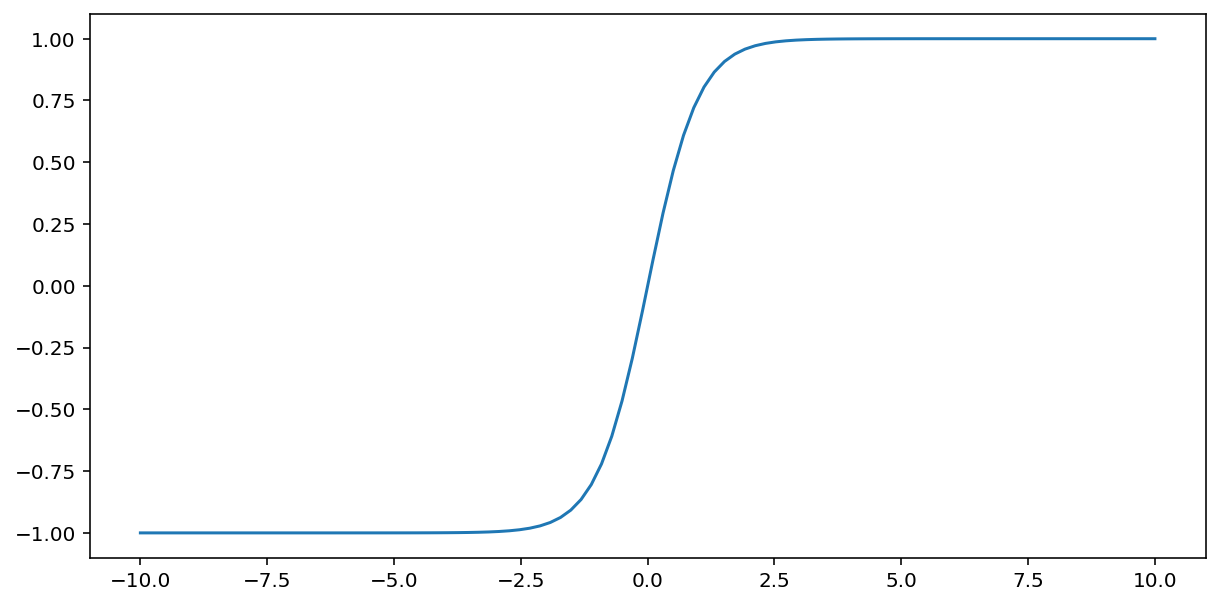
tanh("쌍곡선 탄젠트"의 줄임말) 함수는 입력값 $x$를 변환하여 -1과 1 사이의 출력값을 생성합니다.
\[F(x)=tanh(x)\]
다음은 이 함수의 그래프입니다.
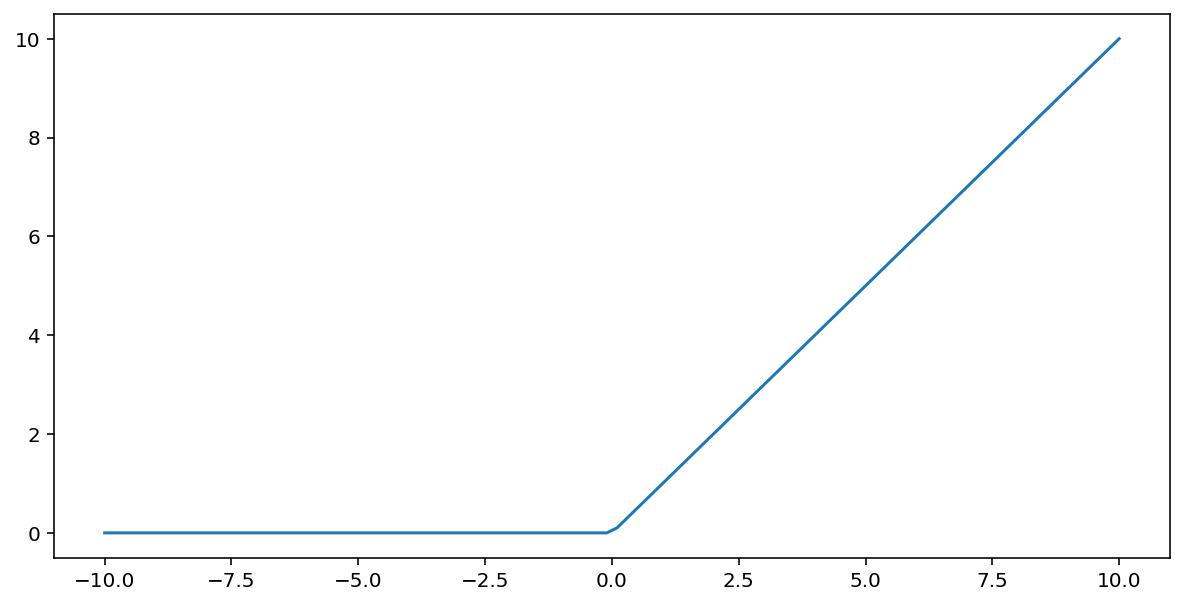
정류선형단위 ( ReLU ) 활성화 함수는 다음 알고리즘을 사용하여 출력을 변환합니다.
- 입력값 $x$가 0보다 작으면 0을 반환합니다.
- 입력값 $x$가 0보다 크거나 같으면 입력값을 반환합니다.
ReLU 활성화 함수는 max() 함수를 사용하여 수학적으로 표현할 수 있습니다.
다음은 이 함수의 그래프입니다.
ReLU는 시그모이드나 tanh 같은 평활 함수보다 활성화 함수로서 더 나은 성능을 보이는 경우가 많은데, 이는 신경망 훈련 중 기울기 소실 문제 에 덜 민감하기 때문입니다. 또한 ReLU는 이러한 함수들보다 계산량이 훨씬 적습니다.
기타 활성화 기능
실제로 어떤 수학적 함수든 활성화 함수로 사용될 수 있습니다. 예를 들어, \(\sigma\) 이는 활성화 함수를 나타냅니다. 네트워크에서 노드의 값은 다음 공식으로 주어집니다.
Keras는 다양한 활성화 함수를 기본적으로 지원합니다. 하지만 ReLU 활성화 함수부터 시작하는 것을 권장합니다.
요약
다음 영상은 신경망이 어떻게 구성되는지에 대해 지금까지 배운 모든 내용을 요약해 줍니다.
이제 우리 모델은 사람들이 일반적으로 신경망이라고 부를 때 의미하는 모든 표준 구성 요소를 갖추고 있습니다.
- 뉴런과 유사한 노드들의 집합체가 계층적으로 구성되어 있습니다.
- 학습된 가중치와 편향의 집합으로, 각 신경망 계층과 그 바로 아래 계층 간의 연결을 나타냅니다. 바로 아래 계층은 또 다른 신경망 계층일 수도 있고, 다른 종류의 계층일 수도 있습니다.
- 활성화 함수는 레이어 내 각 노드의 출력을 변환합니다. 각 레이어는 서로 다른 활성화 함수를 가질 수 있습니다.
주의할 점은 신경망이 특징 교차보다 항상 더 나은 것은 아니지만, 많은 경우에 잘 작동하는 유연한 대안을 제공한다는 것입니다.