本單元介紹線性迴歸概念。
線性迴歸是 用於找出變數之間的關係的統計技巧。在機器學習中 線性迴歸會找出 功能,以及 label。
舉例來說,假設我們想預測某輛車的燃油效率 (以英里為單位) 的加侖計算 ,而我們有以下資料集:
| 1000 年代英鎊 (地圖項目) | 每加侖英里數 (標籤) |
|---|---|
| 3.5 | 18 |
| 3.69 | 15 |
| 3.44 | 18 |
| 3.43 | 16 |
| 4.34 | 15 |
| 4.42 | 14 |
| 2.37 | 24 |
如果我們繪製這些資料點,就會得到下方圖表:

圖 1. 車輛重量 (以磅為單位) 與每加侖英里數的英里數。身為 車輛的行駛里程較大,每公升的里程數通常會下降。
我們可以從下列點畫出最合適的線條,藉此建立自己的模型:

圖 2. 根據上一張資料繪製的最佳適線。
線性迴歸方程式
代數中的模型定義為 $ y = mx + b $,其中
- $ y $ 是每加侖的英里,也就是我們想要預測的值。
- $ m $ 為線條的斜率。
- $ x $ 是磅—我們的輸入值。
- $ b $ 是 y 截距。
在機器學習中,我們寫出線性迴歸模型的方程式,如下所示:
其中:
- $ 年$ 是預測的標籤,也就是輸出內容。
- $ b $ 是偏誤 模型偏誤與代數中的 y 截距相同 方程式在機器學習中,偏誤有時稱為 $ w_0 $。偏誤 是模型的「參數」,且 是從訓練期間計算出來的
- $ w_1 $ 是 而不是每個特徵的分數權重的概念與代數中的斜率 $ m $ 相同 方程式權重為 模型的 parameter, 都是透過這個權重值
- $ x_1 $ 是功能, 。
在訓練期間,模型會計算權重和偏誤 模型

圖 3. 線性模型的數學表示法。
在本範例中,我們根據所繪製線條計算權重和偏誤。 偏誤為 30 (當線與 y 軸相交),權重為 -3.6 (亦即 線條的斜率)。模型會定義為「$ y」= 30 + (-3.6)(x_1) $,以及 我們就能用這些資料進行預測例如,使用這個模型時 車輛約 4,000 磅的燃料效率預測為每輛 15.6 英里 加侖
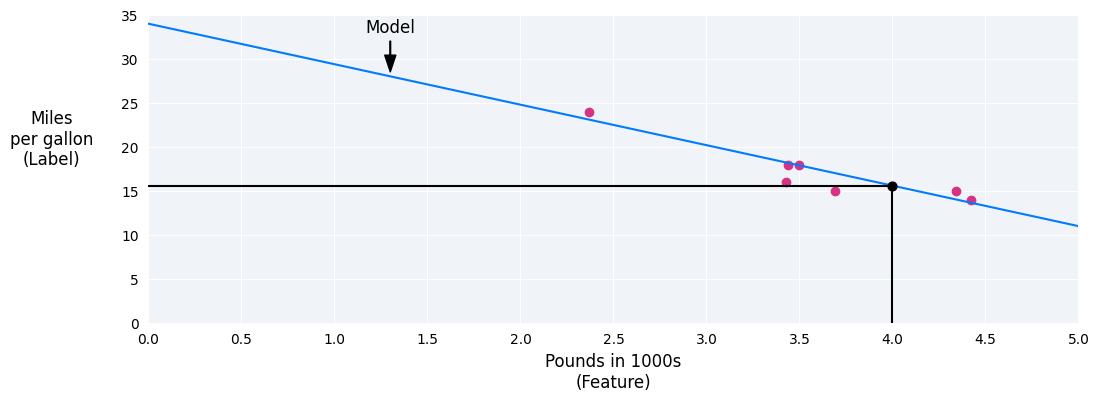
圖 4. 根據這個模型,一輛 4,000 磅的汽車 燃油效率為每加侖 15.6 英里
包含多個特徵的模型
雖然本節範例僅使用單一特徵,也就是重度 較複雜的模型可能會仰賴多種特徵 每個都有各自的權重 ($ w_1 $、$ w_2 $ 等)。例如 需要五項特徵的寫法如下:
$ 年= b + w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4 + w_5x_5 $
舉例來說,預測氣體里程數的模型可能會額外使用特徵 例如:
- 引擎位移
- 加速性能
- 圓柱數量
- 馬力
這個模型的編寫方式如下:

圖 5:包含五項特徵,可預測車輛每加侖的英里數 評分
透過繪製這些其他功能的圖表後 與標籤的線性關係 (每加侖英里數:

圖 6. 車輛的移位 (立方公尺) 和每公升的英里數 評分隨著車輛的引擎越來越大,每公升的里程數通常為英里 下降。

圖 7. 車輛的加速度以及每加侖的里程數。車輛 但會較久,每公升的里程數通常都會增加。

圖 8. 汽車的馬力以及每加侖的里程數。車輛 馬力增加,每加侖的英里數通常會下降。