רגרסיה לינארית: ירידה בגרדינט
קל לארגן דפים בעזרת אוספים
אפשר לשמור ולסווג תוכן על סמך ההעדפות שלך.
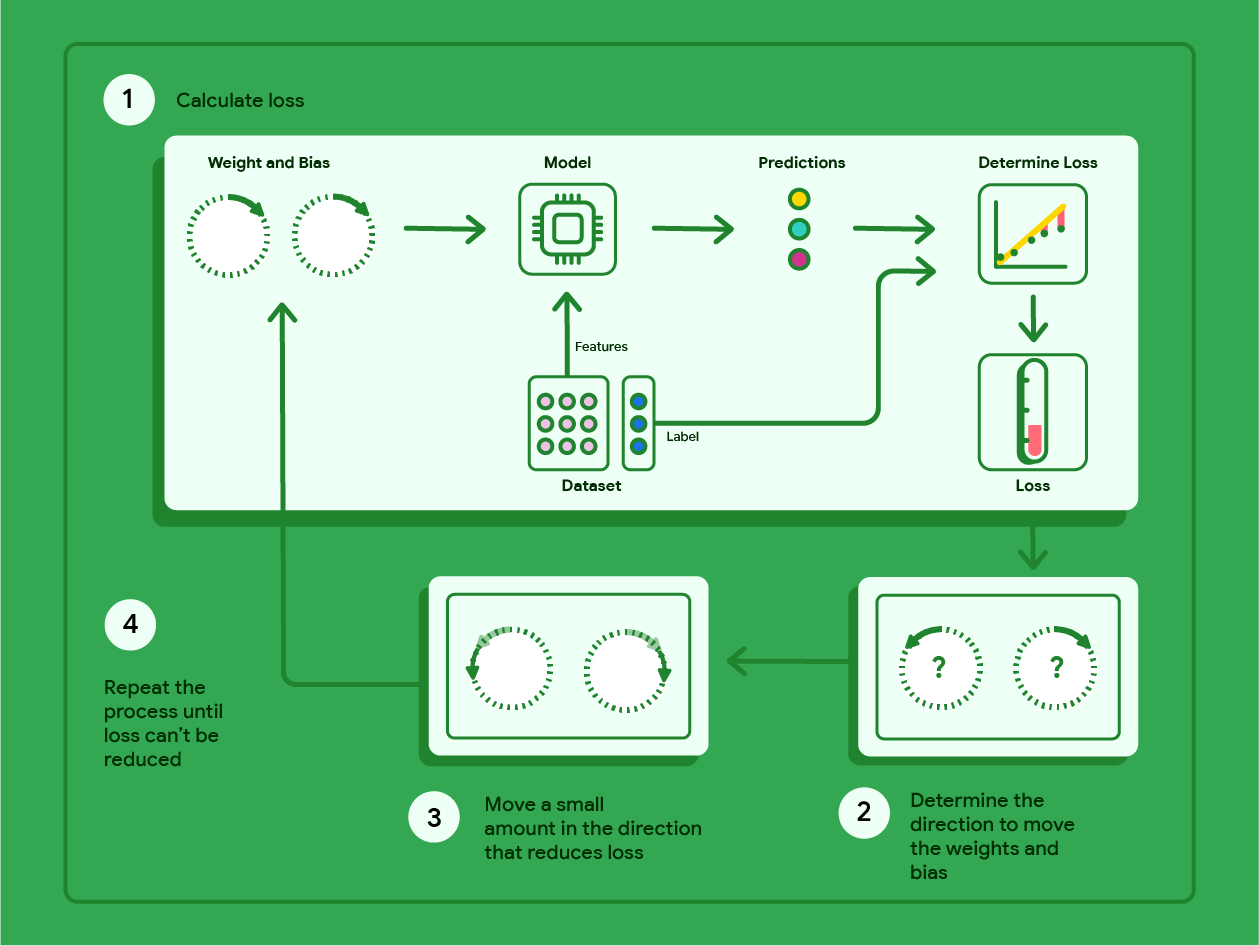
Gradient descent היא טכניקה מתמטית שמוצאת באופן איטרטיבי את המשקלים וההטיה שמפיקים את המודל עם ההפסד הנמוך ביותר. האלגוריתם Gradient descent מוצא את המשקל וההטיה הכי טובים על ידי חזרה על התהליך הבא למספר איטרציות שהמשתמש מגדיר.
המודל מתחיל להתאמן עם משקלים והטיות אקראיים שקרובים לאפס,
ואז חוזר על השלבים הבאים:
חישוב ההפסד עם המשקל וההטיה הנוכחיים.
קובעים את הכיוון להזזת המשקלים וההטיות שמפחיתים את ההפסד.
מזיזים את ערכי המשקל וההטיה במידה קטנה בכיוון שמקטין את השגיאה.
חוזרים לשלב הראשון וחוזרים על התהליך עד שהמודל לא יכול להקטין יותר את ערך הפסד.
הדיאגרמה שלמטה מתארת את השלבים האיטרטיביים של ירידת הגרדיאנט, שבעזרתם נמצאים המשקלים וההטיה שיוצרים את המודל עם ההפסד הכי נמוך.
איור 11. Gradient descent הוא תהליך איטרטיבי שמוצא את המשקלים ואת הטיה שמפיקים את המודל עם ההפסד הכי נמוך.
כדי לקבל מידע נוסף על המתמטיקה שמאחורי שיטת הגרדיאנט, לוחצים על סמל הפלוס.
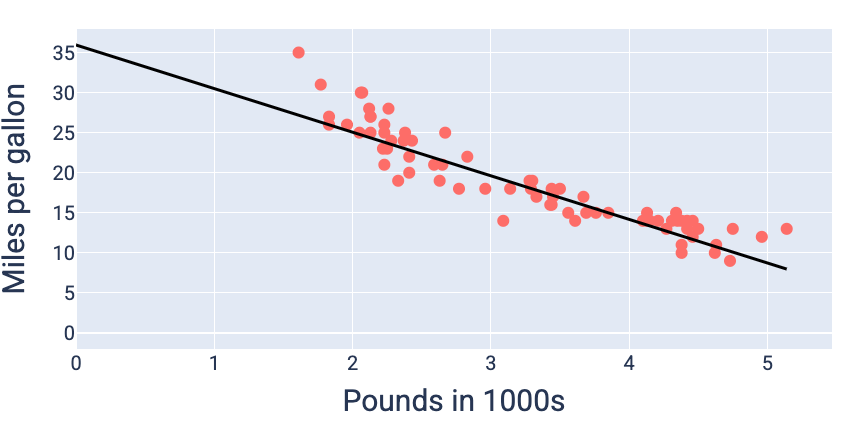
כדי להבין את התהליך, נשתמש בנתונים הבאים של יעילות צריכת הדלק, עם שבע דוגמאות, ובטעות הריבועית הממוצעת (MSE) כמדד ההפסד:
כדי לקבל מידע על חישוב השיפוע, לוחצים על סמל הפלוס.
כדי לקבל את השיפוע של הקווים המשיקים למשקל ול-bias, מחשבים את הנגזרת של פונקציית ההפסד ביחס למשקל ול-bias, ואז פותרים את המשוואות.
המשוואה ליצירת תחזית תהיה:
$ f_{w,b}(x) = (w*x)+b $.
הערך בפועל יופיע כך: $ y $.
נחשב את MSE באמצעות הנוסחה הבאה:
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
כאשר $i$ מייצג את הדוגמה ה-$ith$ לאימון ו-$M$ מייצג
את מספר הדוגמאות.
משקל נגזר
הנגזרת של פונקציית ההפסד ביחס למשקל נכתבת כך:
$ \frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
קודם כל מחשבים את הסכום של כל ערך חזוי פחות הערך בפועל
ואז מכפילים אותו בערך התכונה כפול שתיים.
לאחר מכן מחלקים את הסכום במספר הדוגמאות.
התוצאה היא השיפוע של קו המשיק לערך המשקל.
אם נפתור את המשוואה הזו עם משקל והטיה ששווים לאפס, נקבל את הערך -119.7 עבור השיפוע של הקו.
נגזרת של הטיה
הנגזרת של פונקציית ההפסד ביחס להטיה נכתבת כך:
$ \frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
קודם מחשבים את הסכום של כל ערך חזוי פחות הערך בפועל
ואז מכפילים אותו בשניים. לאחר מכן מחלקים את הסכום במספר הדוגמאות. התוצאה היא שיפוע הישר
המשיק לערך של הטיה.
אם נפתור את המשוואה הזו עם משקל והטיה ששווים לאפס, נקבל את הערך -34.3 עבור השיפוע של הקו.
כדי לקבל את המשקל וההטיה הבאים, מבצעים תזוזה קטנה בכיוון של השיפוע השלילי. לבינתיים, נגדיר באופן שרירותי את ה"סכום הקטן" כ-0.01:
משתמשים במשקל החדש ובטיה כדי לחשב את ההפסד ולחזור על הפעולה. אחרי שש חזרות של התהליך, נקבל את המשקלים, ההטיות וההפסדים הבאים:
איטרציה
משקל
הטיה
הפסד (MSE)
1
0
0
303.71
2
1.20
0.34
170.84
3
2.05
0.59
103.17
4
2.66
0.78
68.70
5
3.09
0.91
51.13
6
3.40
1.01
42.17
אפשר לראות שההפסד קטן יותר עם כל עדכון של המשקל וההטיה.
בדוגמה הזו, הפסקנו אחרי שש חזרות. בפועל, המודל עובר אימון עד שהוא מתכנס.
כשמודל מתכנס, איטרציות נוספות לא מפחיתות את השגיאה יותר כי האלגוריתם של ירידת הגרדיאנט מצא את המשקלים וההטיה שממזערים את השגיאה כמעט לחלוטין.
אם המודל ממשיך להתאמן אחרי ההתכנסות, ערך הפונקציה מתחיל לנוע בתנודות קלות כי המודל מעדכן כל הזמן את הפרמטרים סביב הערכים הנמוכים ביותר שלהם. לכן קשה לוודא שהמודל באמת התכנס. כדי לוודא שהמודל התכנס, צריך להמשיך באימון עד שההפסד יתייצב.
התכנסות המודל ועקומות ההפסד
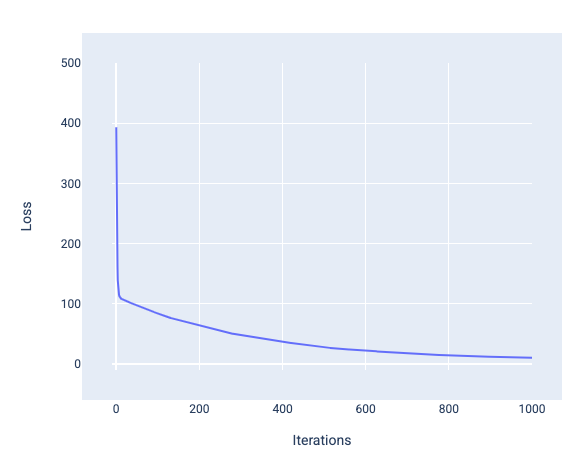
במהלך אימון מודל, בדרך כלל בודקים עקומת הפסד כדי לקבוע אם המודל התכנס. עקומת ההפסד מראה איך ההפסד משתנה במהלך אימון המודל. התרשים הבא מציג עקומת הפסד אופיינית. ההפסד מוצג בציר ה-Y והאיטרציות מוצגות בציר ה-X:
איור 12. עקומת אובדן שמראה שהמודל מתכנס סביב סימן האיטרציה ה-1,000.
אפשר לראות שההפסד יורד באופן משמעותי במהלך האיטרציות הראשונות,
ואז יורד בהדרגה עד שהוא מתייצב סביב האיטרציה ה-1,000. אחרי 1,000 איטרציות, אפשר להיות בטוחים במידה רבה שהמודל הגיע למצב של התכנסות.
באיורים הבאים אנחנו מציגים את המודל בשלוש נקודות במהלך תהליך האימון: בהתחלה, באמצע ובסוף. הדמיה של מצב המודל בתמונות מצב במהלך תהליך האימון מחזקת את הקשר בין עדכון המשקלים וההטיה, הפחתת ההפסד והתכנסות המודל.
באיורים, אנחנו משתמשים במשקלים ובערכי ההטיה שהתקבלו באיטרציה מסוימת כדי לייצג את המודל. בתרשים עם נקודות הנתונים וצילום המסך של המודל, קווי הפסד כחולים מהמודל לנקודות הנתונים מראים את כמות ההפסד. ככל שהשורות ארוכות יותר, כך האובדן גדול יותר.
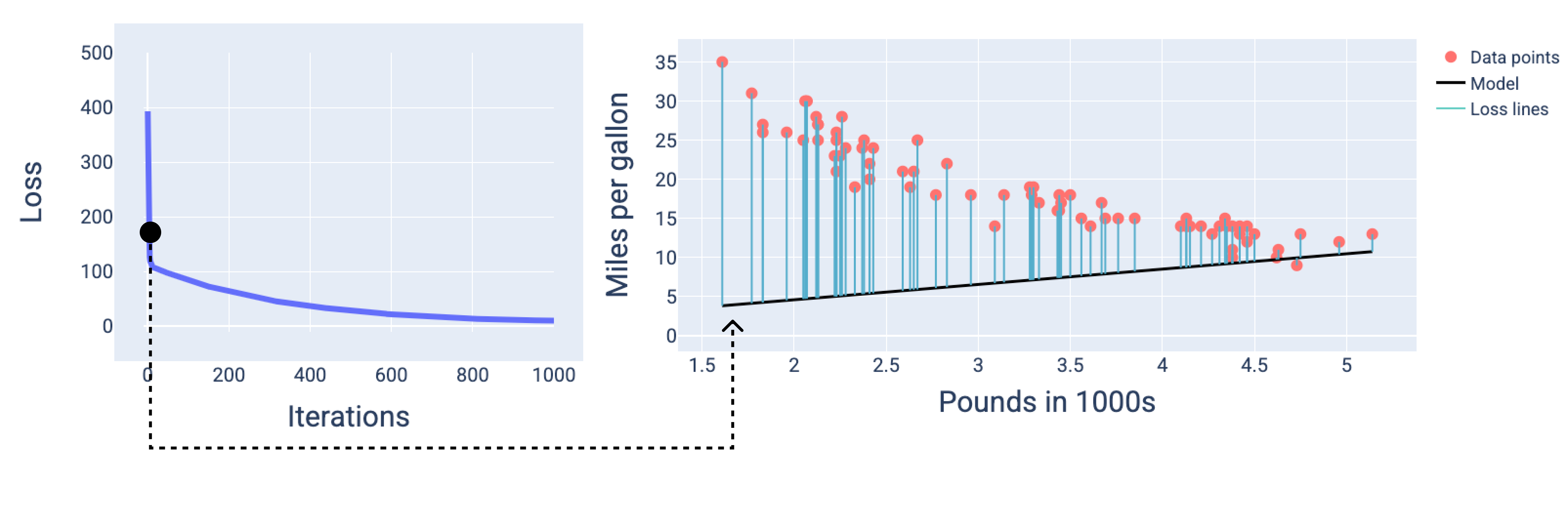
באיור הבא אפשר לראות שסביב האיטרציה השנייה, המודל לא יהיה טוב בחיזויים בגלל כמות ההפסד הגבוהה.
איור 13. עקומת ההפסד ותמונת מצב של המודל בתחילת תהליך האימון.
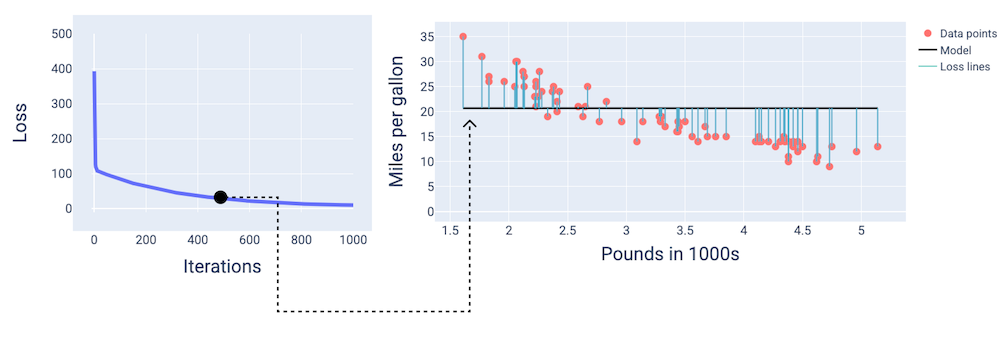
באיטרציה ה-400 בערך, אפשר לראות שהאלגוריתם של ירידת הגרדיאנט מצא את המשקל וההטיה שיוצרים מודל טוב יותר.
איור 14. עקומת הפסד ותמונת מצב של המודל באמצע האימון.
ובערך באיטרציה ה-1,000, אפשר לראות שהמודל הגיע למצב של התכנסות,
והוא מפיק מודל עם הפסד נמוך ככל האפשר.
איור 15. עקומת ההפסד ותמונת מצב של המודל לקראת סוף תהליך האימון.
תרגיל: בדיקת ההבנה
מה התפקיד של שיטת גרדיאנט הירידה ברגרסיה לינארית?
ירידת גרדיאנט היא תהליך איטרטיבי שמוצא את המשקלים וההטיות הטובים ביותר שממזערים את ההפסד.
השיטה 'ירידת גרדיאנט' עוזרת לקבוע באיזה סוג של הפסד להשתמש כשמאמנים מודל, למשל L1 או L2.
האלגוריתם Gradient descent לא מעורב בבחירה של פונקציית הפסד לאימון המודל.
האלגוריתם Gradient descent מסיר ערכים חריגים ממערך הנתונים כדי לעזור למודל ליצור תחזיות טובות יותר.
האלגוריתם Gradient descent לא משנה את מערך הנתונים.
התכנסות ופונקציות קמורות
פונקציות ההפסד של מודלים לינאריים תמיד יוצרות משטח קמור. כתוצאה מהמאפיין הזה, כשמודל רגרסיה לינארית מתכנס, אנחנו יודעים שהמודל מצא את המשקלים וההטיה שמניבים את ההפסד הנמוך ביותר.
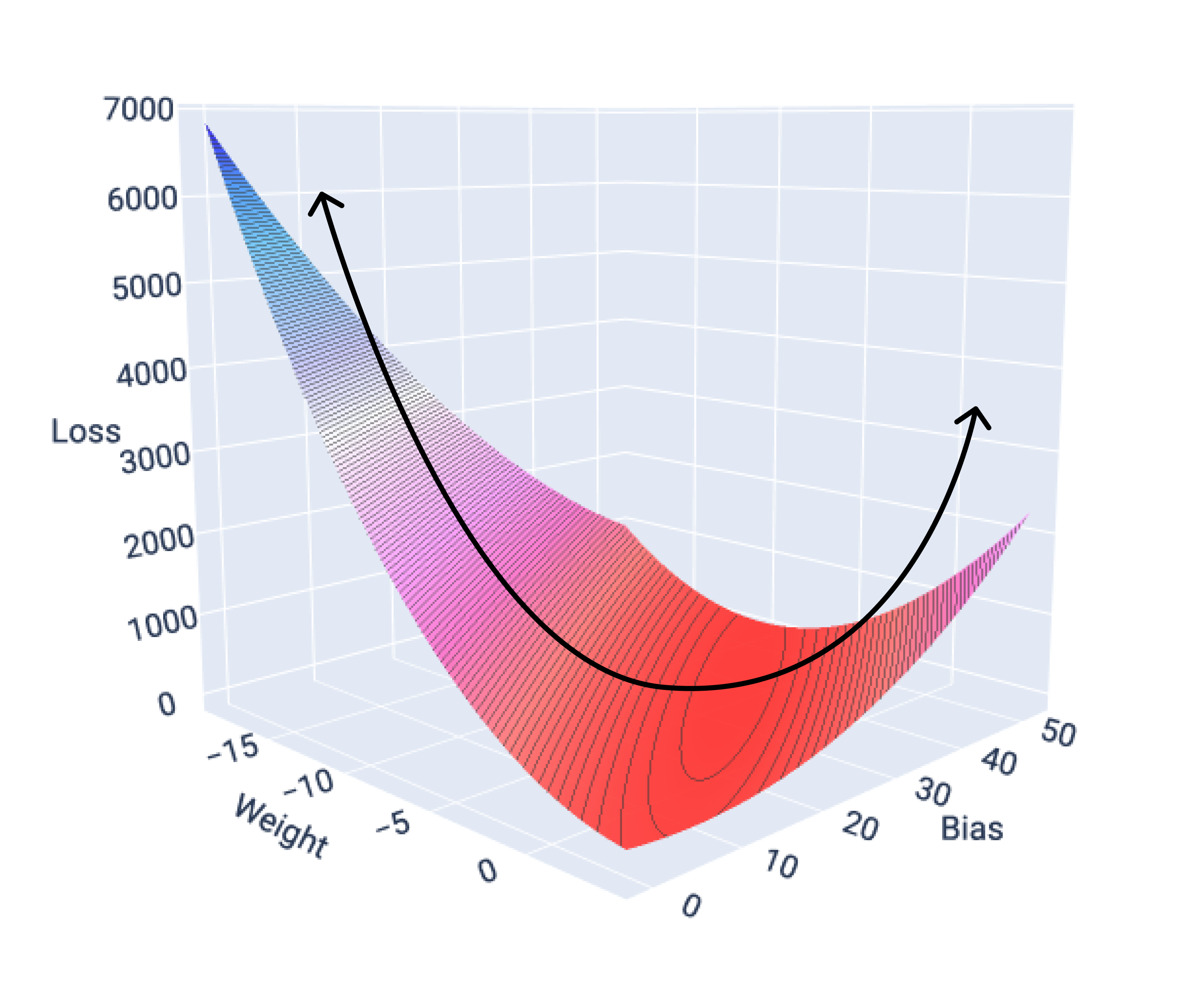
אם נשרטט את משטח ההפסד של מודל עם תכונה אחת, נוכל לראות את הצורה הקמורה שלו. התרשים הבא מציג את משטח ההפסד של מערך נתונים היפותטי של מיילים לגלון. המשקל מוצג בציר ה-x, ההטיה בציר ה-y וההפסד בציר ה-z:
איור 16. משטח הפסד שמציג את הצורה הקמורה שלו.
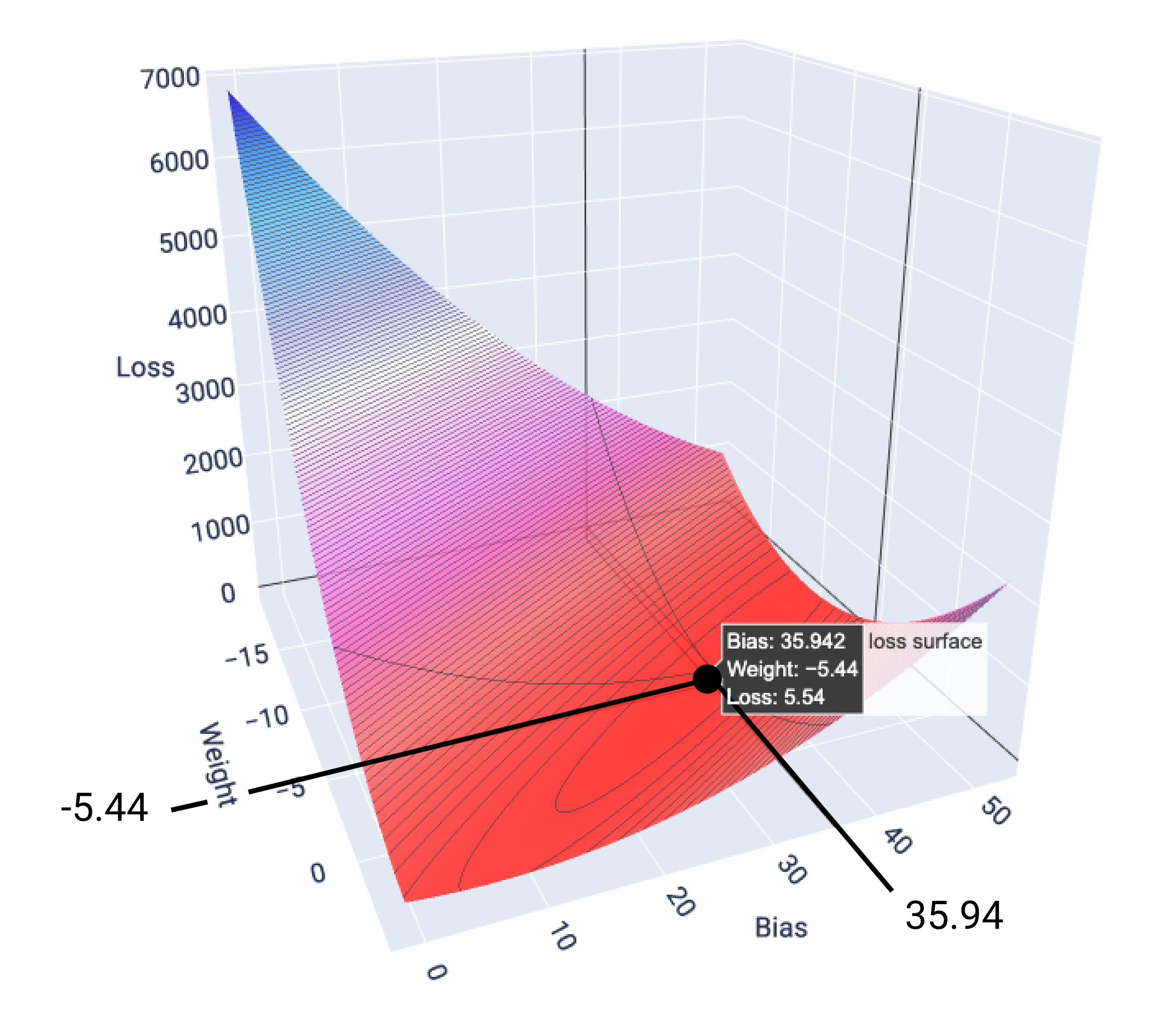
בדוגמה הזו, משקל של -5.44 והטיה של 35.94 מניבים את ההפסד הנמוך ביותר, 5.54:
איור 17. משטח הפסד שמציג את ערכי המשקל וההטיה שמניבים את ההפסד הנמוך ביותר.
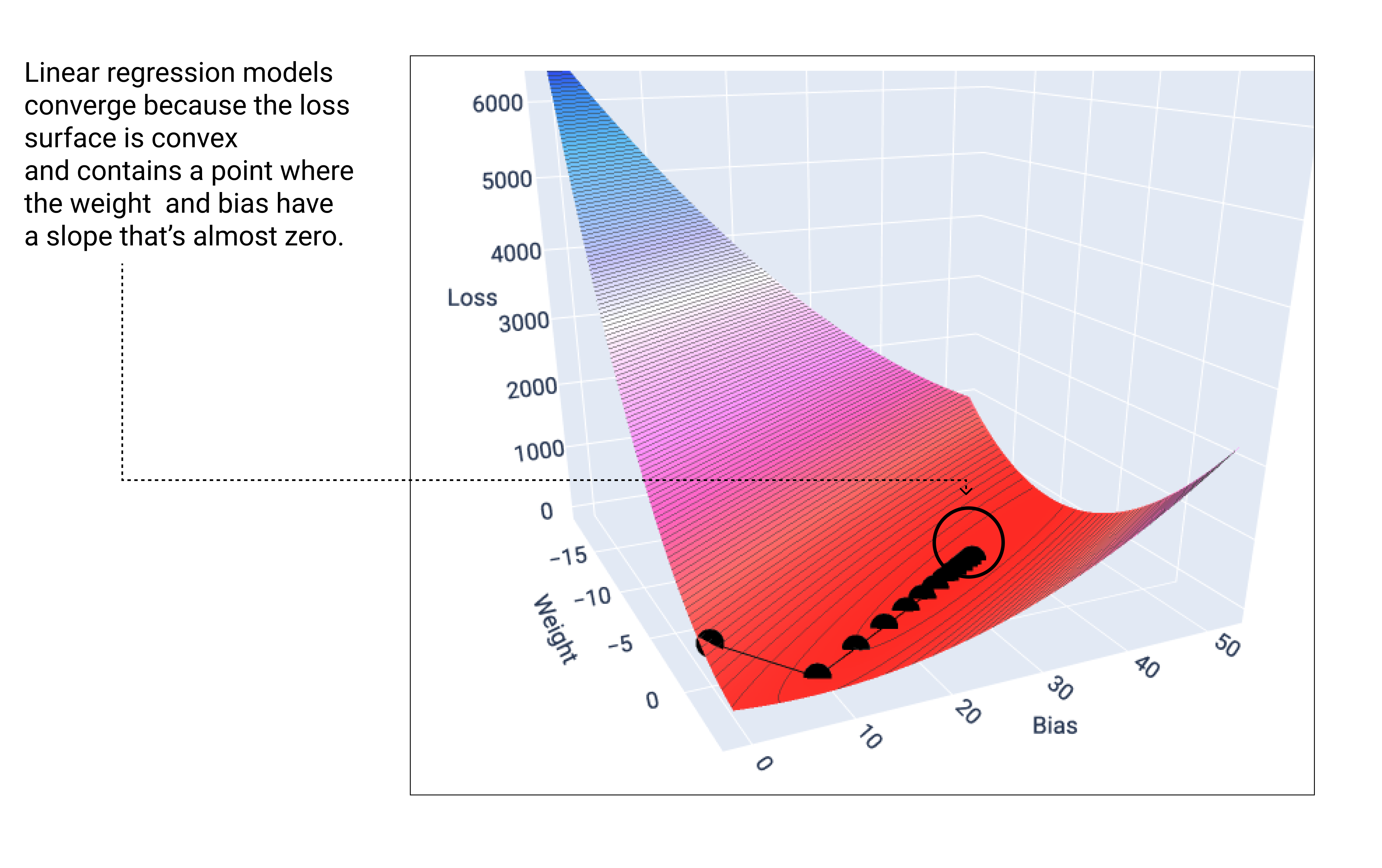
מודל ליניארי מגיע למצב של התכנסות כשהוא מוצא את ההפסד המינימלי. אם היינו משרטטים גרף של המשקלים ונקודות ההטיה במהלך ירידת הגרדיאנט, הנקודות היו נראות כמו כדור שמתגלגל במורד גבעה, ובסופו של דבר נעצר בנקודה שבה אין יותר שיפוע כלפי מטה.
איור 18. גרף הפסדים שמציג נקודות של ירידה הדרגתית שעוצרות בנקודה הנמוכה ביותר בגרף.
שימו לב שנקודות האובדן השחורות יוצרות את הצורה המדויקת של עקומת האובדן: ירידה חדה לפני שהיא מתמתנת בהדרגה עד שהיא מגיעה לנקודה הנמוכה ביותר במשטח האובדן.
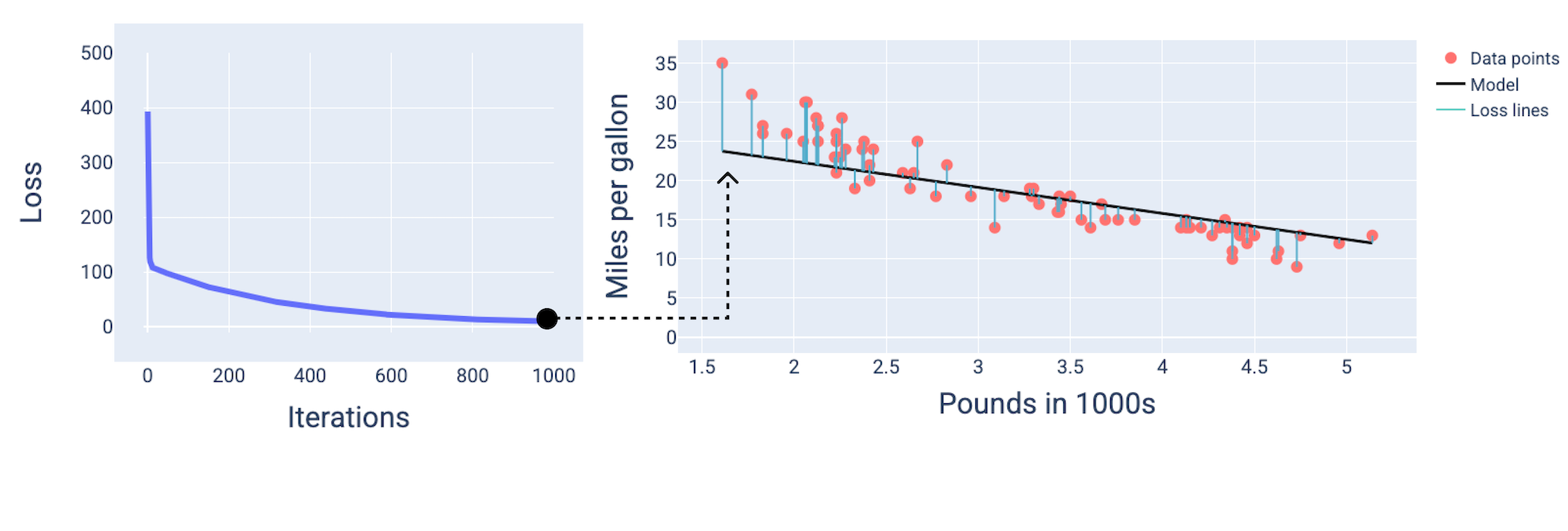
בעזרת ערכי המשקל וההטיה שמניבים את ההפסד הנמוך ביותר – במקרה הזה משקל של -5.44 והטיה של 35.94 – אפשר לשרטט את המודל כדי לראות עד כמה הוא מתאים לנתונים:
איור 19. מודל שמוצג בתרשים באמצעות ערכי המשקל וההטיה שמניבים את ההפסד הנמוך ביותר.
זה יהיה המודל הכי טוב למערך הנתונים הזה, כי אין ערכים אחרים של משקל והטיה שמניבים מודל עם הפסד נמוך יותר.
[[["התוכן קל להבנה","easyToUnderstand","thumb-up"],["התוכן עזר לי לפתור בעיה","solvedMyProblem","thumb-up"],["סיבה אחרת","otherUp","thumb-up"]],[["חסרים לי מידע או פרטים","missingTheInformationINeed","thumb-down"],["התוכן מורכב מדי או עם יותר מדי שלבים","tooComplicatedTooManySteps","thumb-down"],["התוכן לא עדכני","outOfDate","thumb-down"],["בעיה בתרגום","translationIssue","thumb-down"],["בעיה בדוגמאות/בקוד","samplesCodeIssue","thumb-down"],["סיבה אחרת","otherDown","thumb-down"]],["עדכון אחרון: 2026-02-03 (שעון UTC)."],[],[]]