Regressione lineare: discesa del gradiente
Mantieni tutto organizzato con le raccolte
Salva e classifica i contenuti in base alle tue preferenze.
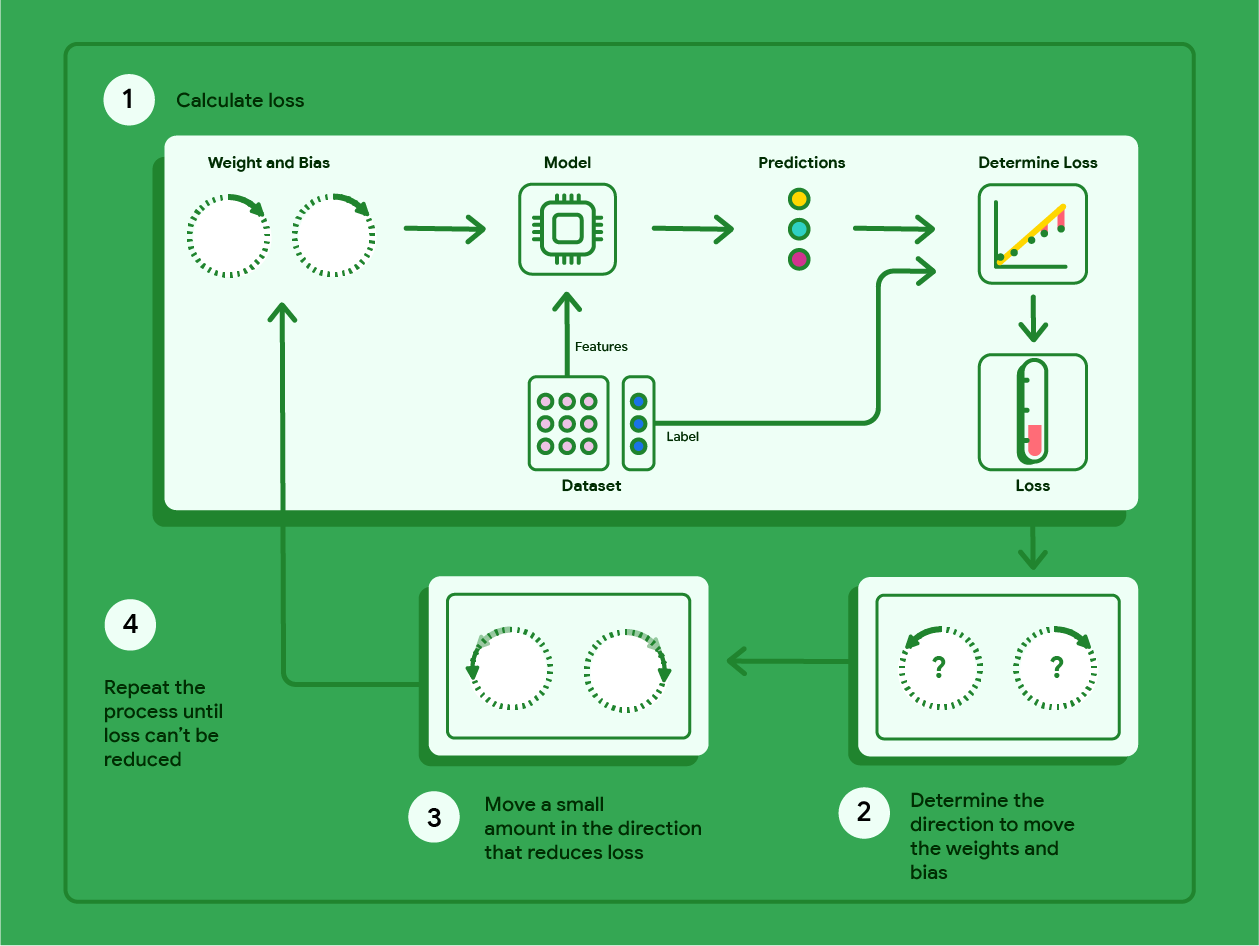
La discesa del gradiente è una tecnica matematica che trova in modo iterativo i pesi e il bias che producono il modello con la perdita più bassa. La discesa del gradiente trova il peso e il bias migliori
ripetendo la seguente procedura per un numero di iterazioni definite dall'utente.
Il modello inizia l'addestramento con pesi e bias casuali vicini allo zero
e poi ripete i seguenti passaggi:
Calcola la perdita con il peso e il bias attuali.
Determina la direzione in cui spostare i pesi e il bias che riducono la perdita.
Sposta i valori di peso e bias di una piccola quantità nella direzione che riduce
la perdita.
Torna al passaggio 1 e ripeti la procedura finché il modello non riesce a ridurre ulteriormente
la perdita.
Il diagramma seguente illustra i passaggi iterativi eseguiti dalla discesa del gradiente per trovare
i pesi e il bias che producono il modello con la perdita più bassa.
Figura 11. La discesa del gradiente è un processo iterativo che trova i pesi e il bias che producono il modello con la perdita più bassa.
Fai clic sull'icona Più per scoprire di più sulla matematica alla base della discesa del gradiente.
A livello concreto, possiamo esaminare i passaggi della discesa del gradiente
utilizzando il seguente piccolo set di dati sull'efficienza del carburante con sette esempi
e l'errore quadratico medio (MSE) come metrica di perdita:
Libbre in migliaia (funzionalità)
Miglia per gallone (etichetta)
3,5
18
3,69
15
3,44
18
3,43
16
4.34
15
4,42
14
2,37
24
Il modello inizia l'addestramento impostando il peso e il bias su zero:
Fai clic sull'icona Più per scoprire come calcolare la pendenza.
Per ottenere la pendenza delle rette tangenti al peso e
al bias, calcoliamo la derivata della funzione di perdita rispetto
al peso e al bias, quindi risolviamo le equazioni.
Scriveremo l'equazione per fare una previsione come:
$ f_{w,b}(x) = (w*x)+b $.
Scriveremo il valore effettivo come: $ y $.
Calcoleremo l'errore quadratico medio utilizzando:
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
dove $i$ rappresenta l'i-esimo esempio di addestramento e $M$ rappresenta
il numero di esempi.
Derivata del peso
La derivata della funzione di perdita rispetto al peso è scritta come:
$ \frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
Innanzitutto sommiamo ogni valore previsto meno il valore effettivo
e poi lo moltiplichiamo per due volte il valore della caratteristica.
Quindi dividiamo la somma per il numero di esempi.
Il risultato è la pendenza della retta tangente al valore del peso.
Se risolviamo questa equazione con un peso e un bias pari a zero,
otteniamo -119,7 per la pendenza della retta.
Derivata del bias
La derivata della funzione di perdita rispetto al
bias è scritta come:
$ \frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
Innanzitutto sommiamo ogni valore previsto meno il valore effettivo
e poi moltiplichiamo il risultato per due. Quindi dividiamo la somma per il
numero di esempi. Il risultato è la pendenza della retta
tangente al valore del bias.
Se risolviamo questa equazione con un peso e un bias pari a
zero, otteniamo -34,3 per la pendenza della retta.
Sposta di poco nella direzione della pendenza negativa per ottenere
il peso e il bias successivi. Per ora, definiamo arbitrariamente
l'"importo ridotto" come 0,01:
Utilizza il nuovo peso e il nuovo bias per calcolare la perdita e ripeti l'operazione. Completando
il processo per sei iterazioni, otterremmo i seguenti pesi, bias
e perdite:
Iterazione
Peso
Bias
Perdita (MSE)
1
0
0
303,71
2
1,20
0,34
170.84
3
2,05
0,59
103,17
4
2,66
0,78
68.70
5
3.09
0,91
51,13
6
3,40
1,01
42,17
Puoi notare che la perdita diminuisce a ogni aggiornamento del peso e del bias.
In questo esempio, ci siamo fermati dopo sei iterazioni. In pratica, un modello
viene addestrato finché non
converge.
Quando un modello converge, le iterazioni aggiuntive non riducono ulteriormente la perdita
perché la discesa del gradiente ha trovato i pesi e il bias che minimizzano quasi
la perdita.
Se il modello continua l'addestramento dopo la convergenza, la perdita inizia a
fluttuare in piccole quantità man mano che il modello aggiorna continuamente i
parametri intorno ai loro valori più bassi. In questo modo può essere difficile
verificare che il modello sia effettivamente convergente. Per confermare che il modello
è convergente, devi continuare l'addestramento finché la perdita non si
stabilizza.
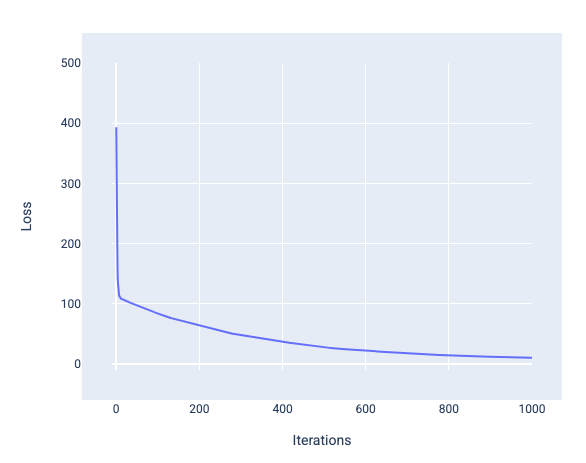
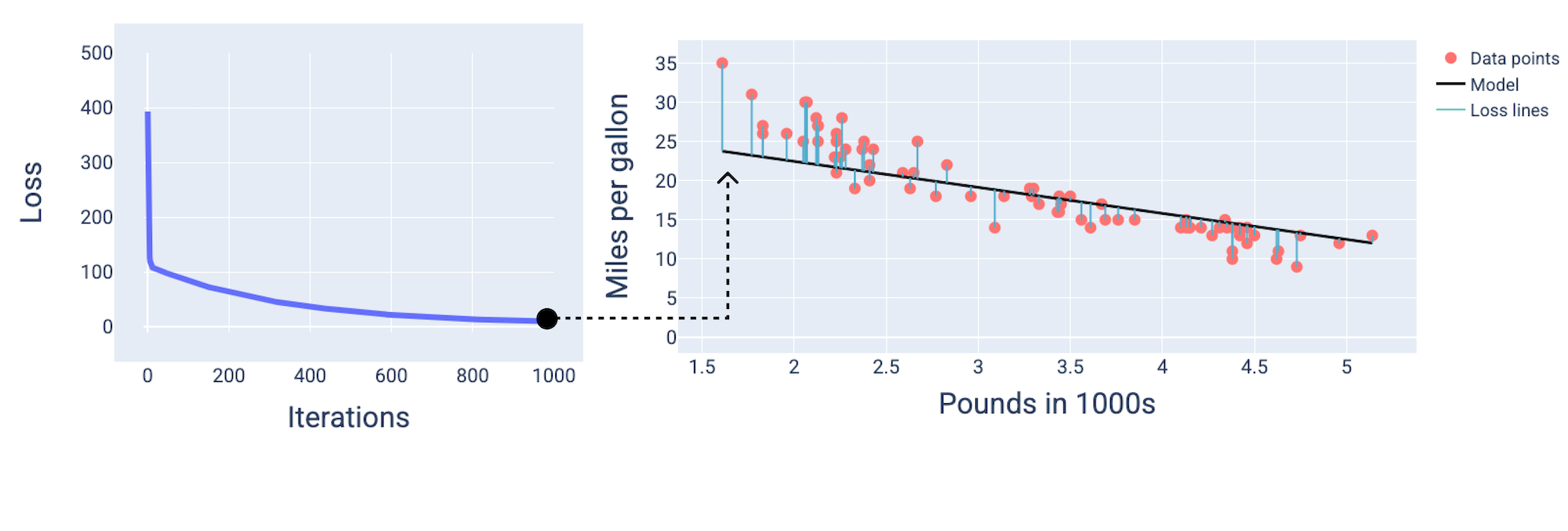
Convergenza del modello e curve di perdita
Quando addestri un modello, spesso esamini una curva di perdita per determinare se il modello ha convergente. La curva di perdita mostra
come cambia la perdita durante l'addestramento del modello. Di seguito è riportato l'aspetto di una tipica curva di perdita. La perdita è sull'asse Y e le iterazioni sono sull'asse X:
Figura 12. Curva di perdita che mostra la convergenza del modello intorno al
segno della millesima iterazione.
Puoi notare che la perdita diminuisce drasticamente durante le prime iterazioni,
poi diminuisce gradualmente prima di stabilizzarsi intorno alla millesima iterazione. Dopo 1000 iterazioni, possiamo essere quasi certi che il modello sia
convergente.
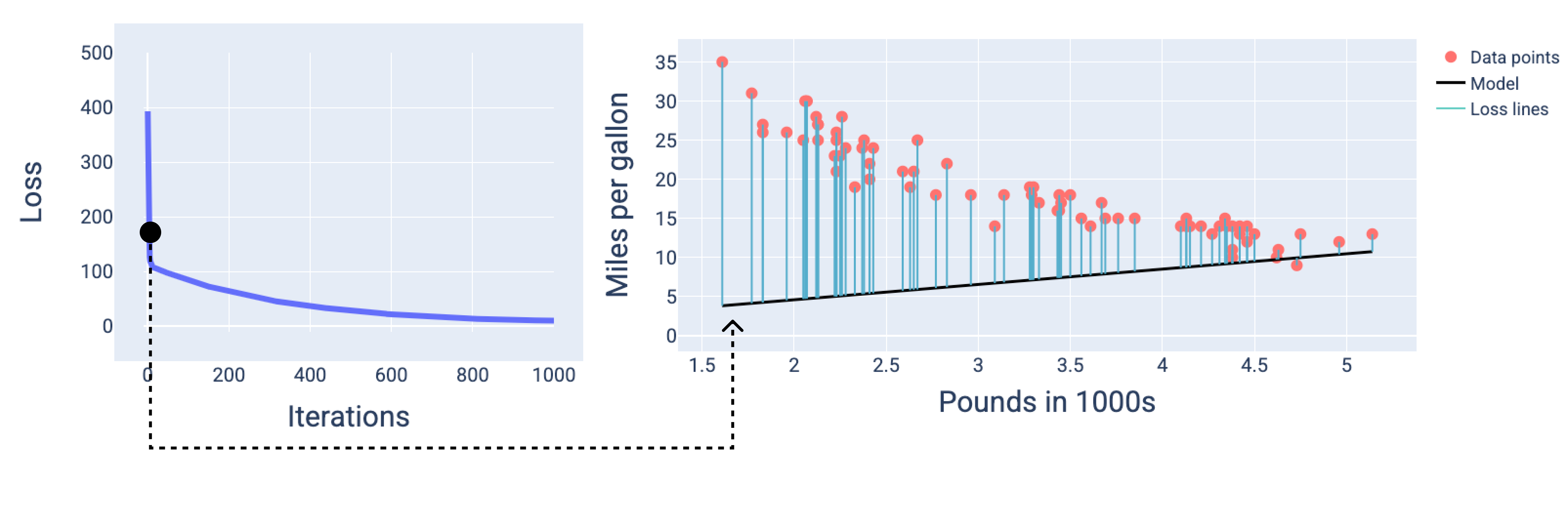
Nelle figure seguenti, disegniamo il modello in tre punti durante il processo di addestramento: l'inizio, la metà e la fine. La visualizzazione dello stato del modello
negli snapshot durante il processo di addestramento consolida il collegamento tra l'aggiornamento
dei pesi e del bias, la riduzione della perdita e la convergenza del modello.
Nelle figure, utilizziamo i pesi e il bias derivati in una particolare iterazione per
rappresentare il modello. Nel grafico con i punti dati e lo snapshot del modello,
le linee blu di perdita dal modello ai punti dati mostrano la quantità di perdita. Più lunghe sono le linee, maggiore è la perdita.
Nella figura seguente, possiamo vedere che intorno alla seconda iterazione il modello
non sarebbe in grado di fare previsioni a causa dell'elevata perdita.
Figura 13. Curva di perdita e snapshot del modello all'inizio del
processo di addestramento.
Intorno alla 400ª iterazione, possiamo vedere che la discesa del gradiente ha trovato la
ponderazione e il bias che producono un modello migliore.
Figura 14. Curva di perdita e snapshot del modello a circa metà dell'addestramento.
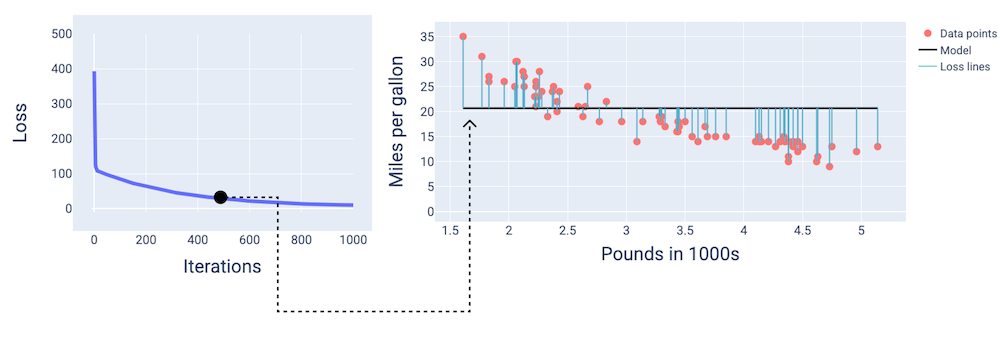
Intorno alla millesima iterazione, possiamo vedere che il modello è convergente,
e produce un modello con la perdita più bassa possibile.
Figura 15. Curva di perdita e istantanea del modello verso la fine del processo di addestramento.
Esercizio: verifica la tua comprensione
Qual è il ruolo della discesa del gradiente nella regressione lineare?
La discesa del gradiente è un processo iterativo che trova i pesi e il bias migliori che riducono al minimo la perdita.
La discesa del gradiente aiuta a determinare il tipo di perdita da utilizzare durante
l'addestramento di un modello, ad esempio L1 o L2.
La discesa del gradiente non è coinvolta nella selezione di una funzione di perdita per l'addestramento del modello.
La discesa del gradiente rimuove i valori anomali dal set di dati per aiutare il modello
a fare previsioni migliori.
La discesa del gradiente non modifica il set di dati.
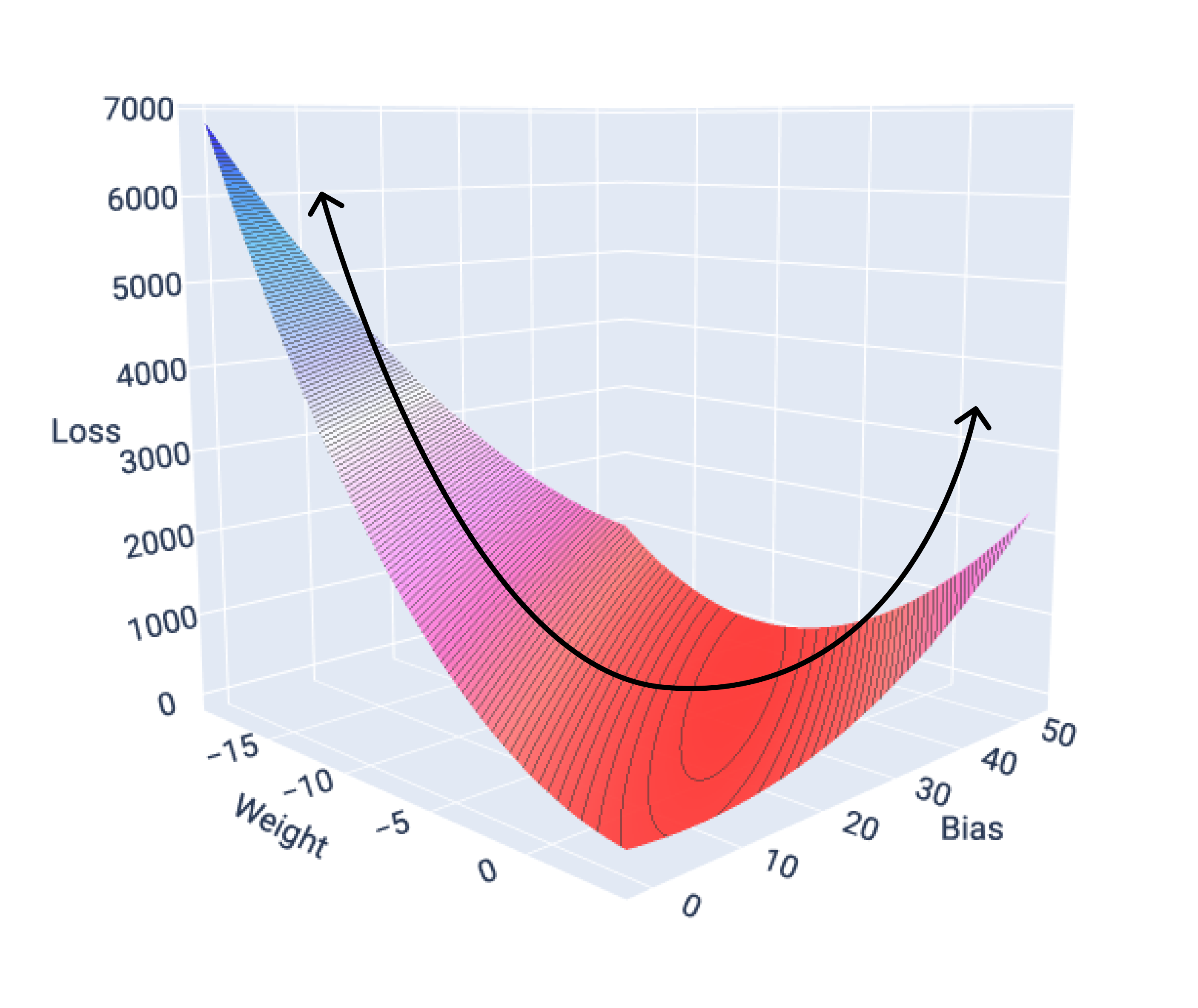
Funzioni di convergenza e convesse
Le funzioni di perdita per i modelli lineari producono sempre una superficie convessa. Grazie a questa proprietà, quando un modello di regressione lineare converge, sappiamo che ha trovato i pesi e il bias che producono la perdita più bassa.
Se rappresentiamo graficamente la superficie di perdita per un modello con una funzionalità, possiamo vedere la sua
forma convessa. Di seguito è riportata la superficie di perdita per un ipotetico set di dati di miglia per
gallone. Il peso è sull'asse x, il bias sull'asse y e la perdita sull'asse z:
Figura 16. Superficie di perdita che mostra la sua forma convessa.
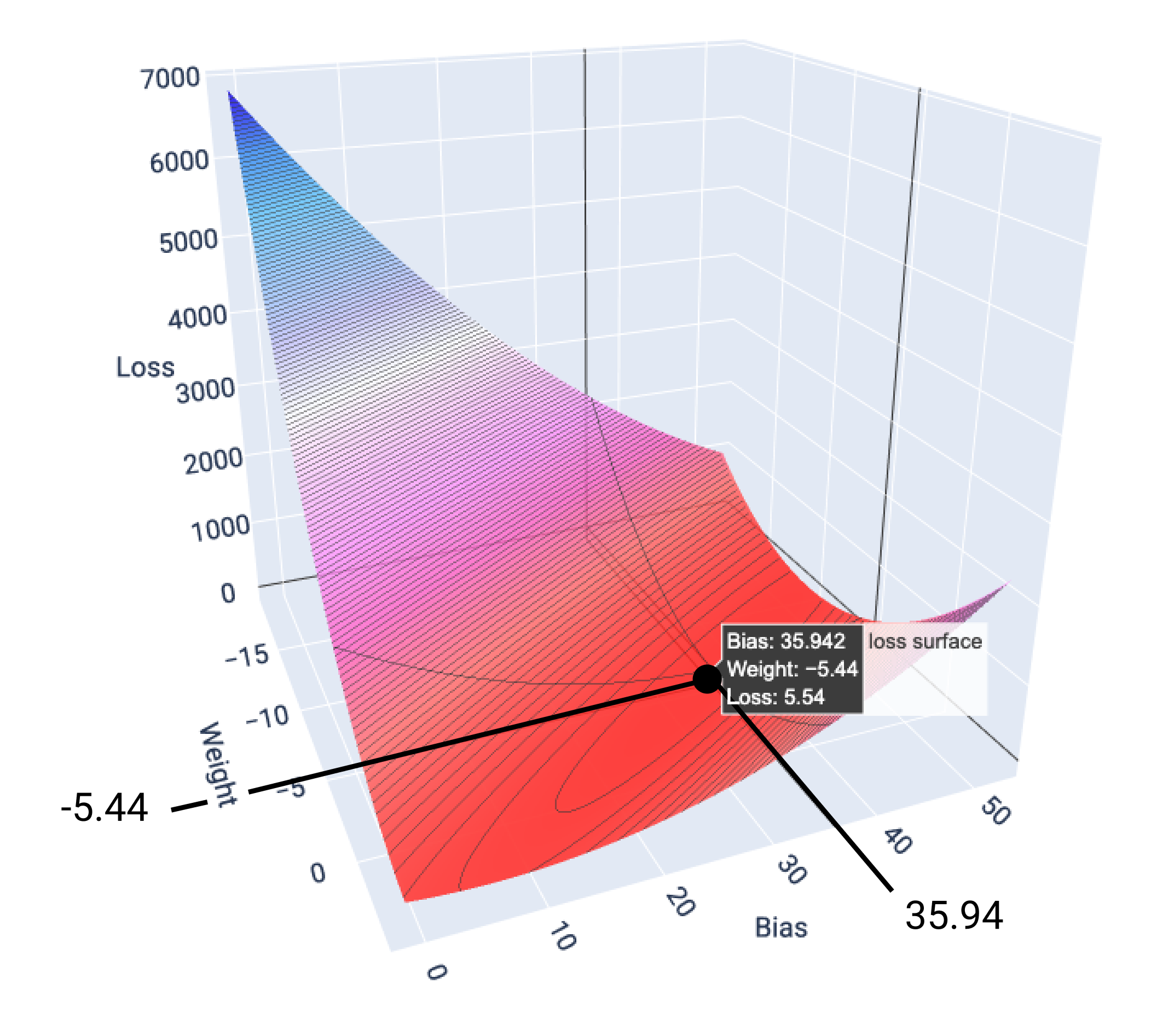
In questo esempio, un peso di -5,44 e un bias di 35,94 producono la perdita più bassa
a 5,54:
Figura 17. Superficie di perdita che mostra i valori di peso e bias che producono
la perdita più bassa.
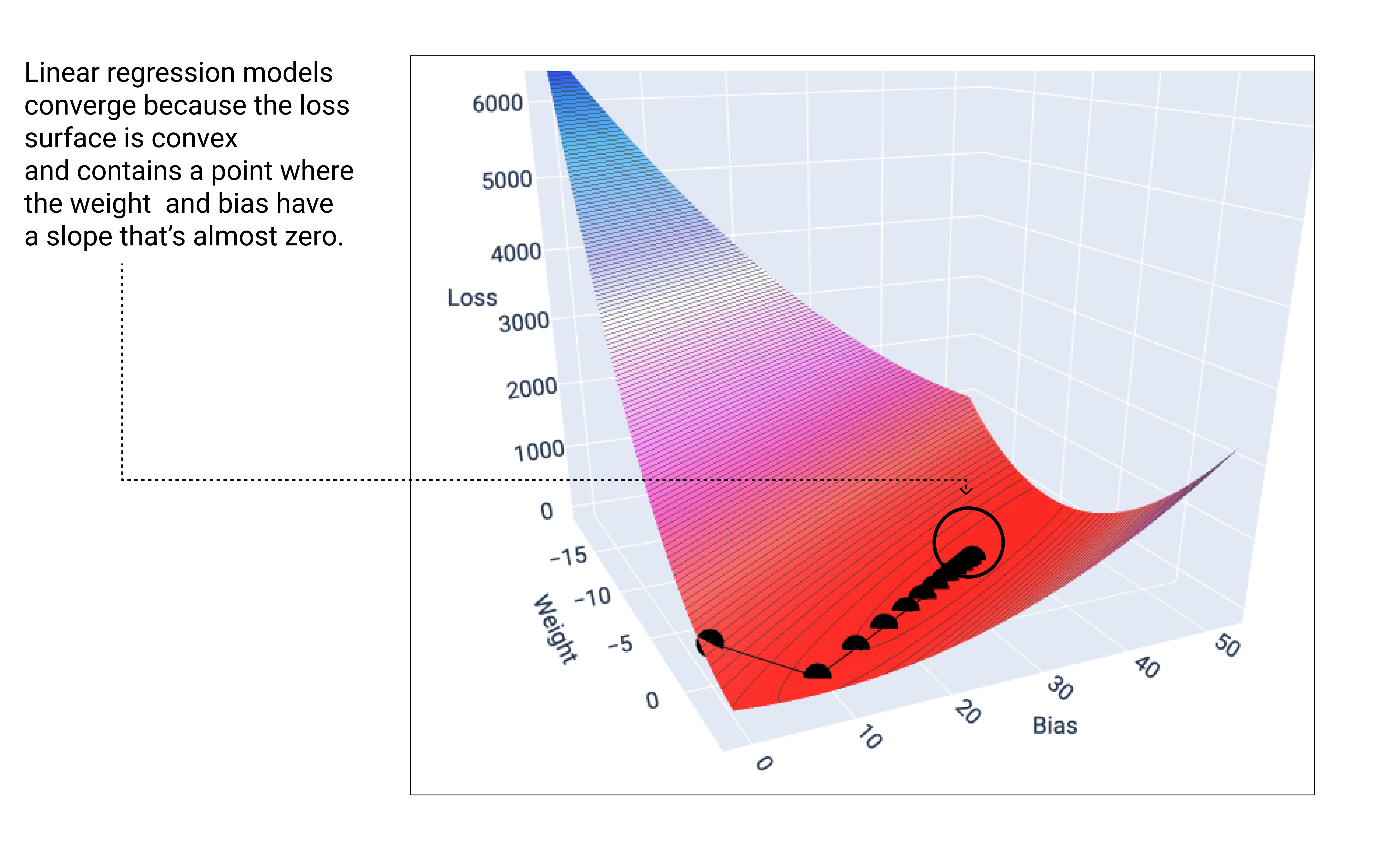
Un modello lineare converge quando trova la perdita minima. Se rappresentassimo graficamente i punti di pesi e bias durante la discesa del gradiente, i punti sembrerebbero una palla che rotola giù per una collina, fermandosi infine nel punto in cui non c'è più pendenza verso il basso.
Figura 18. Grafico di perdita che mostra i punti di discesa del gradiente che si fermano nel punto più basso del grafico.
Nota che i punti di perdita neri creano la forma esatta della curva di perdita: un
forte calo prima di scendere gradualmente fino a raggiungere il punto più basso
della superficie di perdita.
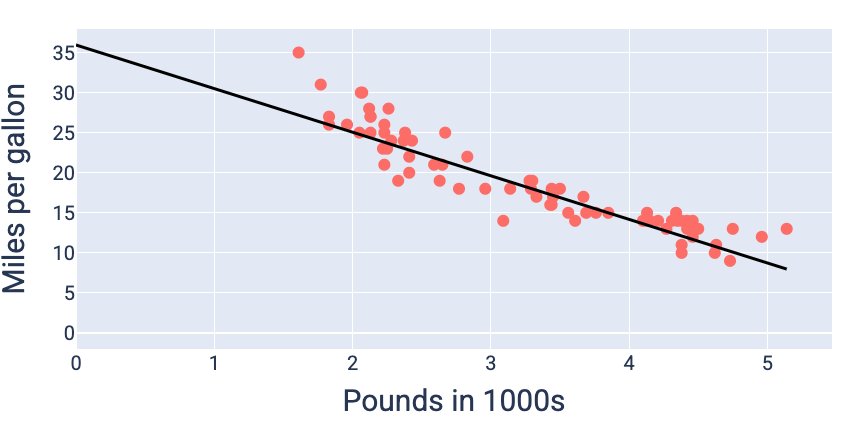
Utilizzando i valori di peso e bias che producono la perdita più bassa, in questo caso
un peso di -5,44 e un bias di 35,94, possiamo rappresentare graficamente il modello per vedere quanto
si adatta bene ai dati:
Figura 19. Modello rappresentato graficamente utilizzando i valori di peso e bias che producono
la perdita più bassa.
Questo sarebbe il modello migliore per questo set di dati perché nessun altro valore di peso e bias
produce un modello con una perdita inferiore.
[[["Facile da capire","easyToUnderstand","thumb-up"],["Il problema è stato risolto","solvedMyProblem","thumb-up"],["Altra","otherUp","thumb-up"]],[["Mancano le informazioni di cui ho bisogno","missingTheInformationINeed","thumb-down"],["Troppo complicato/troppi passaggi","tooComplicatedTooManySteps","thumb-down"],["Obsoleti","outOfDate","thumb-down"],["Problema di traduzione","translationIssue","thumb-down"],["Problema relativo a esempi/codice","samplesCodeIssue","thumb-down"],["Altra","otherDown","thumb-down"]],["Ultimo aggiornamento 2026-02-03 UTC."],[],[]]