Regresja liniowa: spadek wzdłuż gradientu
Zadbaj o dobrą organizację dzięki kolekcji
Zapisuj i kategoryzuj treści zgodnie ze swoimi preferencjami.
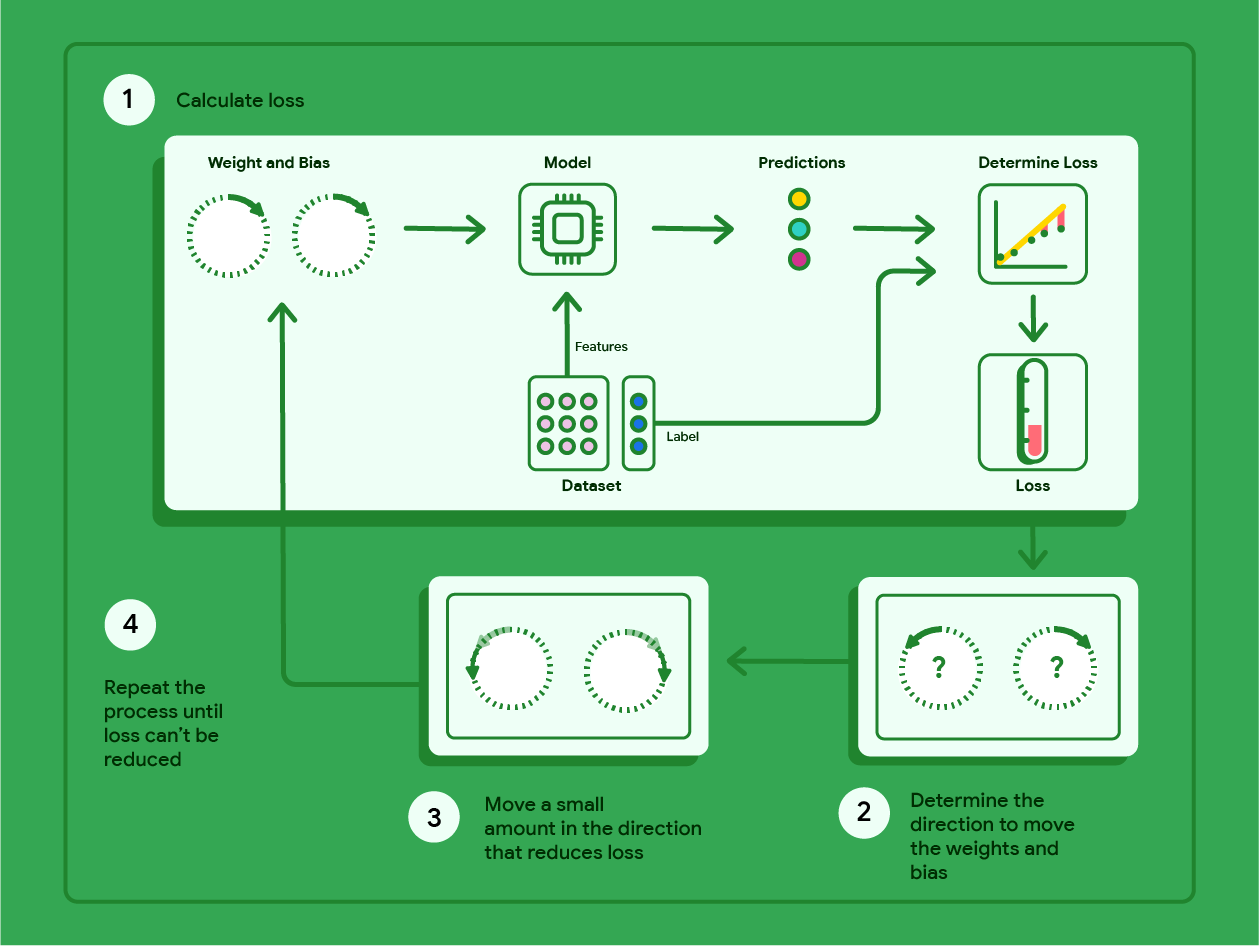
Metoda gradientu prostego to technika matematyczna, która iteracyjnie znajduje wagi i wartości progowe, które dają model o najniższej wartości funkcji straty. Metoda spadku gradientowego znajduje najlepsze wagi i wartości progowe, powtarzając poniższy proces przez określoną przez użytkownika liczbę iteracji.
Model rozpoczyna trenowanie z losowymi wagami i odchyleniami bliskimi zera, a następnie powtarza te czynności:
Oblicz wartość funkcji straty przy użyciu bieżących wag i wartości progowych.
określanie kierunku, w którym należy przesunąć wagi i odchylenia, aby zmniejszyć utratę;
Przesuń wartości wag i odchyleń o niewielką wartość w kierunku, który zmniejsza utratę.
Wróć do kroku 1 i powtarzaj proces, aż model nie będzie w stanie dalej zmniejszać utraty.
Poniższy diagram przedstawia iteracyjne kroki, które wykonuje algorytm spadku gradientu, aby znaleźć wagi i wartość progową, które dają model o najmniejszej utracie.
Rysunek 11. Spadek gradientu to proces iteracyjny, który znajduje wagi i wartości progowe, które tworzą model o najniższej wartości funkcji straty.
Kliknij ikonę plusa, aby dowiedzieć się więcej o matematyce stojącej za metodą gradientu prostego.
Na poziomie konkretnym możemy prześledzić kroki metody gradientu prostego
na podstawie tego małego zbioru danych dotyczących zużycia paliwa, który zawiera 7 przykładów, i średniego błędu kwadratowego (MSE) jako metryki funkcji straty:
Funty w tysiącach (funkcja)
Mile na galon (etykieta)
3,5
18
3,69
15
3,44
18
3,43
16
4,34
15
4.42
14
2,37
24
Model rozpoczyna trenowanie od ustawienia wagi i wartości progowej na zero:
Kliknij ikonę plusa, aby dowiedzieć się, jak obliczyć nachylenie.
Aby uzyskać nachylenie linii stycznych do wagi i wartości progowej, obliczamy pochodną funkcji straty względem wagi i wartości progowej, a następnie rozwiązujemy równania.
Równanie do prognozowania zapiszemy w ten sposób:
$ f_{w,b}(x) = (w*x)+b $.
Rzeczywistą wartość zapiszemy jako: $ y $.
Błąd średniokwadratowy obliczamy za pomocą tego wzoru:
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
gdzie $i$ oznacza $i$-ty przykład trenujący, a $M$ oznacza liczbę przykładów.
Pochodna wagi
Pochodną funkcji straty względem wagi zapisujemy w ten sposób:
$ \frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
i ma wartość:
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2x_{(i)} $
Najpierw sumujemy każdą prognozowaną wartość pomniejszoną o wartość rzeczywistą, a następnie mnożymy ją przez dwukrotność wartości cechy.
Następnie dzielimy sumę przez liczbę przykładów.
Wynikiem jest nachylenie linii stycznej do wartości wagi.
Jeśli rozwiążemy to równanie z wagą i wartością progową równą zero, otrzymamy wartość -119,7 dla nachylenia linii.
Pochodna uprzedzeń
Pochodną funkcji straty względem wyrazu wolnego zapisujemy w ten sposób:
$ \frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
i ma wartość:
$ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2 $
Najpierw sumujemy każdą przewidywaną wartość pomniejszoną o wartość rzeczywistą, a następnie mnożymy ją przez 2. Następnie dzielimy sumę przez liczbę przykładów. Wynikiem jest nachylenie linii stycznej do wartości odchylenia.
Jeśli rozwiążemy to równanie z wagą i wartością progową równą zero, otrzymamy wartość –34,3 dla nachylenia linii.
Przesuń się o niewielką wartość w kierunku ujemnego nachylenia, aby uzyskać następną wagę i następne odchylenie. Na razie zdefiniujemy „niewielką kwotę” jako 0, 01:
Użyj nowych wag i odchyleń, aby obliczyć stratę i powtórzyć proces. Po 6 iteracjach otrzymamy te wagi, odchylenia i wartości funkcji straty:
Iteracja
Waga
Uprzedzenia
Strata (MSE)
1
0
0
303,71
2
1,20
0.34
170,84
3
2,05
0.59
103,17
4
2,66
0,78
68,70
5
3.09
0,91
51,13
6
3,40
1,01
42,17
Widać, że z każdą aktualizacją wagi i odchylenia wartość funkcji straty maleje.
W tym przykładzie zakończyliśmy działanie po 6 iteracjach. W praktyce model trenuje się do momentu, gdy zbiegnie.
Gdy model osiągnie zbieżność, dodatkowe iteracje nie zmniejszają już straty, ponieważ metoda gradientu prostego znalazła wagi i wartości progowe, które niemal minimalizują stratę.
Jeśli model będzie trenowany po osiągnięciu konwergencji, wartość funkcji straty zacznie nieznacznie się wahać, ponieważ model będzie stale aktualizować parametry wokół ich najniższych wartości. Może to utrudniać sprawdzenie, czy model rzeczywiście osiągnął zbieżność. Aby potwierdzić, że model osiągnął zbieżność, trenuj go dalej, aż funkcja straty się ustabilizuje.
Zbieżność modelu i krzywe funkcji straty
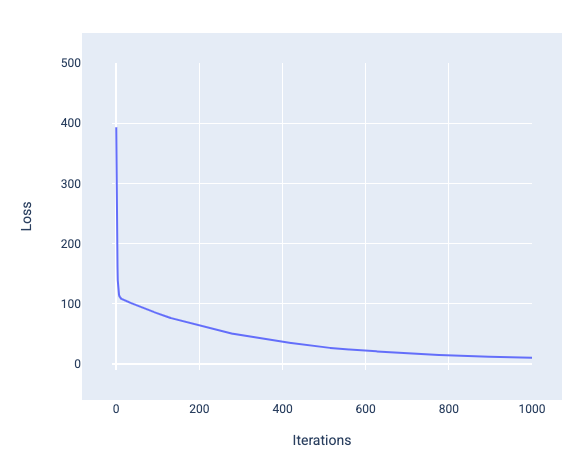
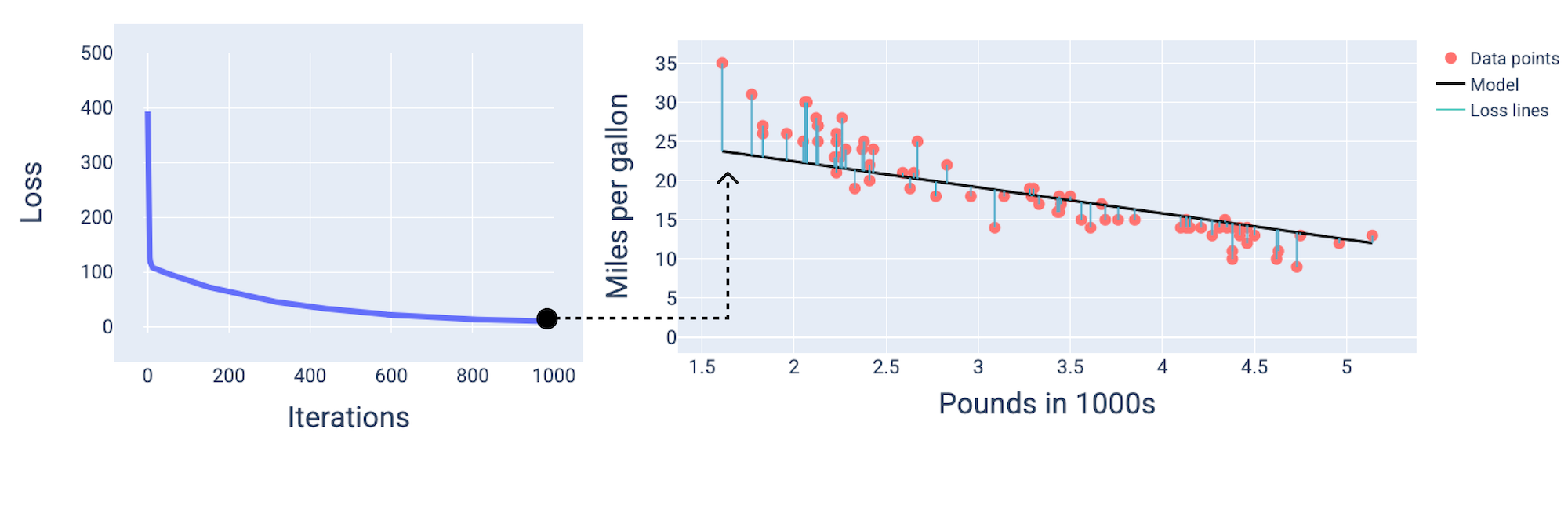
Podczas trenowania modelu często sprawdzasz krzywą straty, aby określić, czy model zbiegł się. Krzywa funkcji straty pokazuje, jak zmienia się funkcja straty w trakcie trenowania modelu. Tak wygląda typowa krzywa strat. Oś Y przedstawia utratę, a oś X – iteracje:
Rysunek 12. Krzywa utraty pokazująca,że model zbiega się w okolicach 1000 iteracji.
Widać, że w pierwszych kilku iteracjach utrata gwałtownie maleje, a potem stopniowo się zmniejsza, aż około tysięcznej iteracji przestaje się zmieniać. Po 1000 iteracji możemy mieć pewność, że model osiągnął zbieżność.
Na poniższych rysunkach przedstawiamy model w 3 momentach procesu trenowania: na początku, w środku i na końcu. Wizualizacja stanu modelu w postaci migawek w trakcie procesu trenowania utrwala związek między aktualizacją wag i wartości progowej, zmniejszaniem straty i zbieżnością modelu.
Na rysunkach używamy wag i odchyleń uzyskanych w danej iteracji, aby przedstawić model. Na wykresie z punktami danych i migawką modelu niebieskie linie strat od modelu do punktów danych pokazują wielkość straty. Im dłuższe linie, tym większe straty.
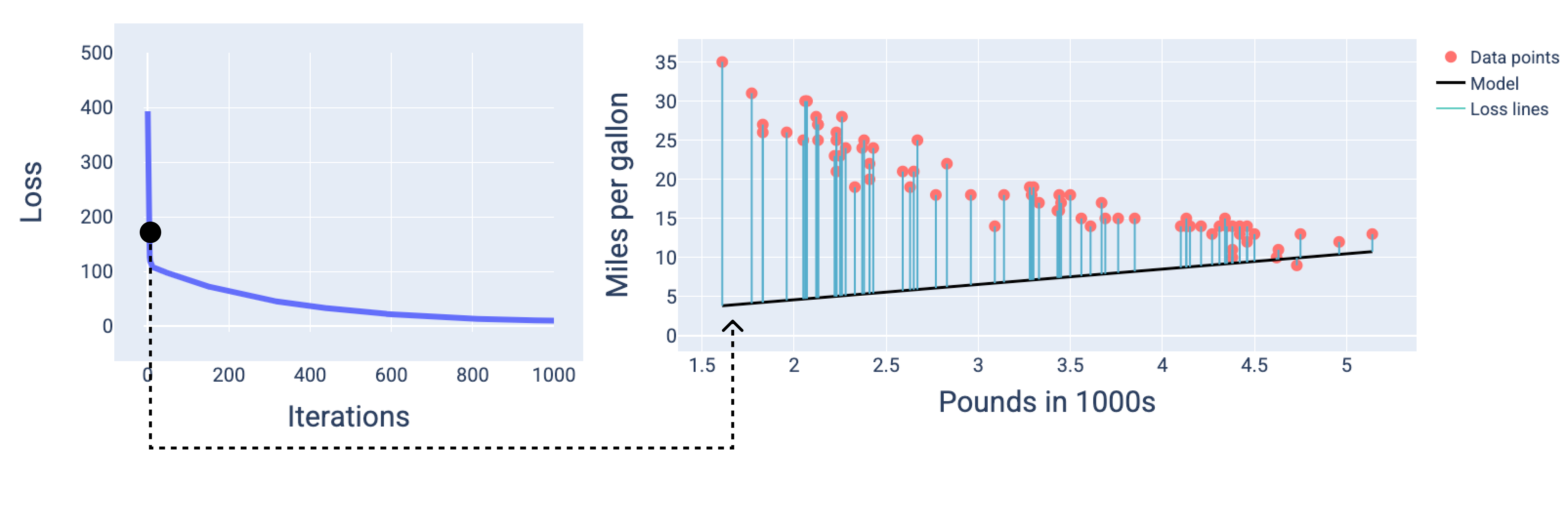
Na poniższym rysunku widać, że około drugiej iteracji model nie będzie dobrze prognozować ze względu na dużą utratę.
Rysunek 13. Krzywa funkcji straty i zrzut modelu na początku procesu trenowania.
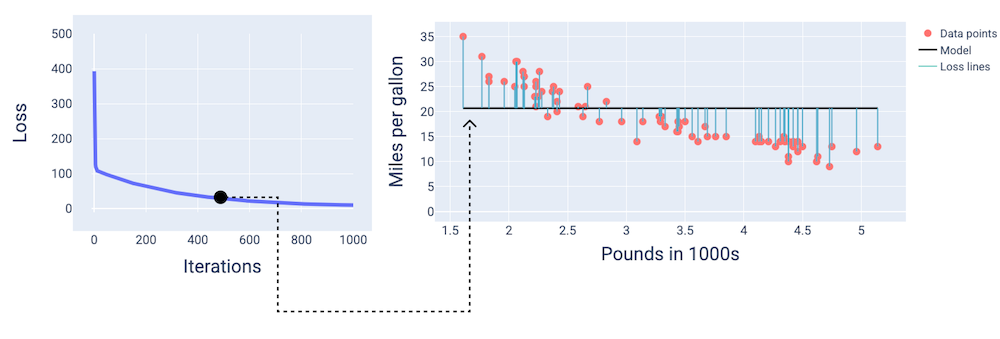
Około 400 iteracji później widzimy, że metoda spadku gradientowego znalazła wagę i odchylenie, które dają lepszy model.
Rysunek 14. Krzywa straty i migawka modelu w połowie trenowania.
Około 1000 iteracji później widać, że model osiągnął zbieżność, uzyskując najniższą możliwą wartość straty.
Rysunek 15. Krzywa funkcji straty i migawka modelu pod koniec procesu trenowania.
Ćwiczenie: sprawdź swoją wiedzę
Jaką rolę odgrywa metoda gradientu prostego w regresji liniowej?
Metoda gradientu prostego to proces iteracyjny, który znajduje najlepsze wagi i wartości progowe minimalizujące funkcję straty.
Metoda spadku gradientowego pomaga określić, jakiego rodzaju funkcji straty użyć podczas trenowania modelu, np. L1 lub L2.
Wybór funkcji straty na potrzeby trenowania modelu nie obejmuje metody spadku gradientowego.
Metoda spadku gradientowego usuwa z zbioru danych wartości odstające, aby pomóc modelowi w dokładniejszym prognozowaniu.
Metoda spadku gradientowego nie zmienia zbioru danych.
Zbieżność i funkcje wypukłe
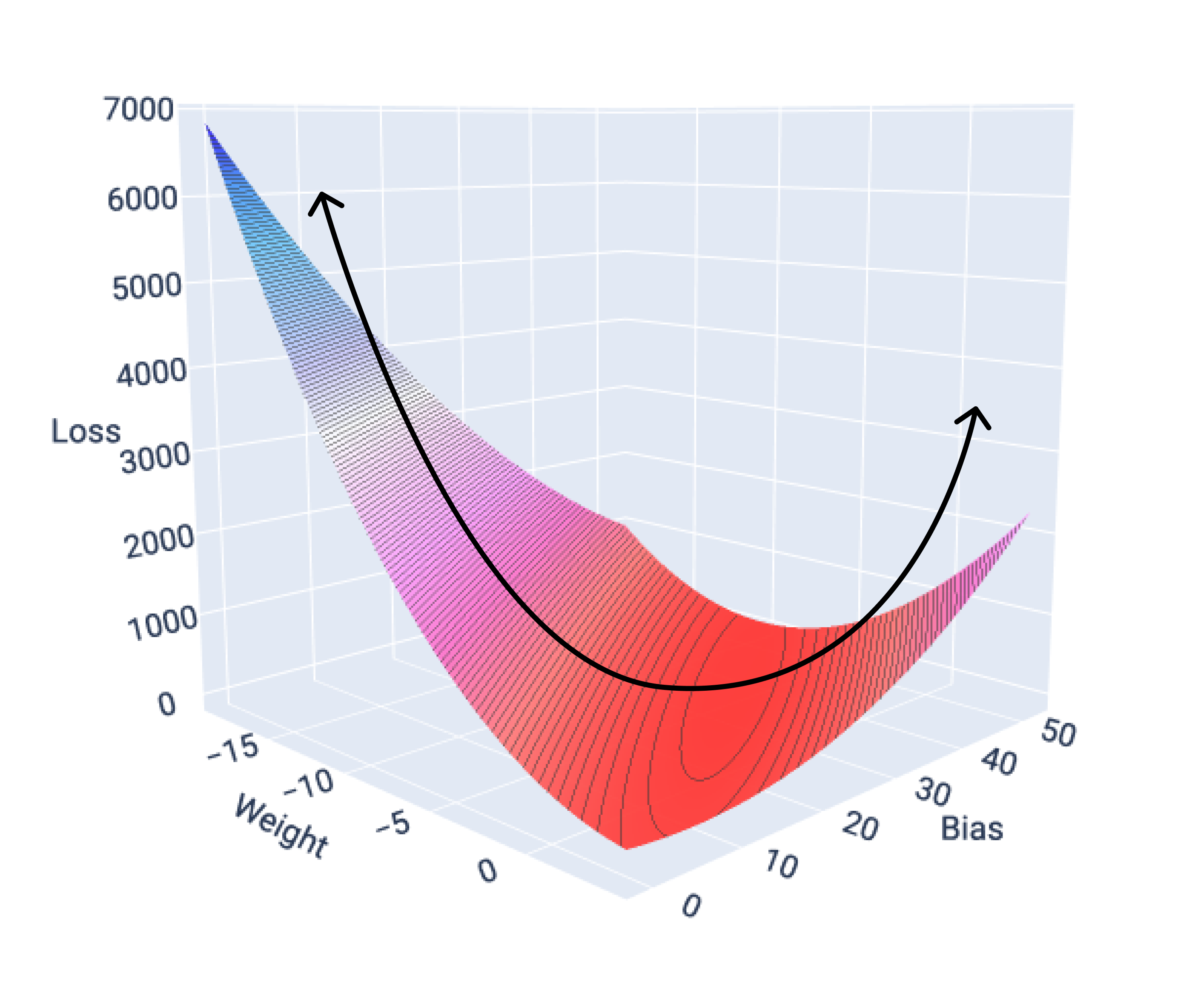
Funkcje straty dla modeli liniowych zawsze tworzą powierzchnię wypukłą. Dzięki tej właściwości, gdy model regresji liniowej zbiega się, wiemy, że znalazł wagi i wartość progową, które dają najniższą wartość funkcji straty.
Jeśli narysujemy wykres powierzchni funkcji straty dla modelu z jedną cechą, zobaczymy jego wypukły kształt. Poniżej przedstawiamy powierzchnię funkcji straty dla hipotetycznego zbioru danych dotyczących liczby mil na galon. Waga jest na osi x, odchylenie na osi y, a strata na osi z:
Rysunek 16. Powierzchnia funkcji straty o wypukłym kształcie.
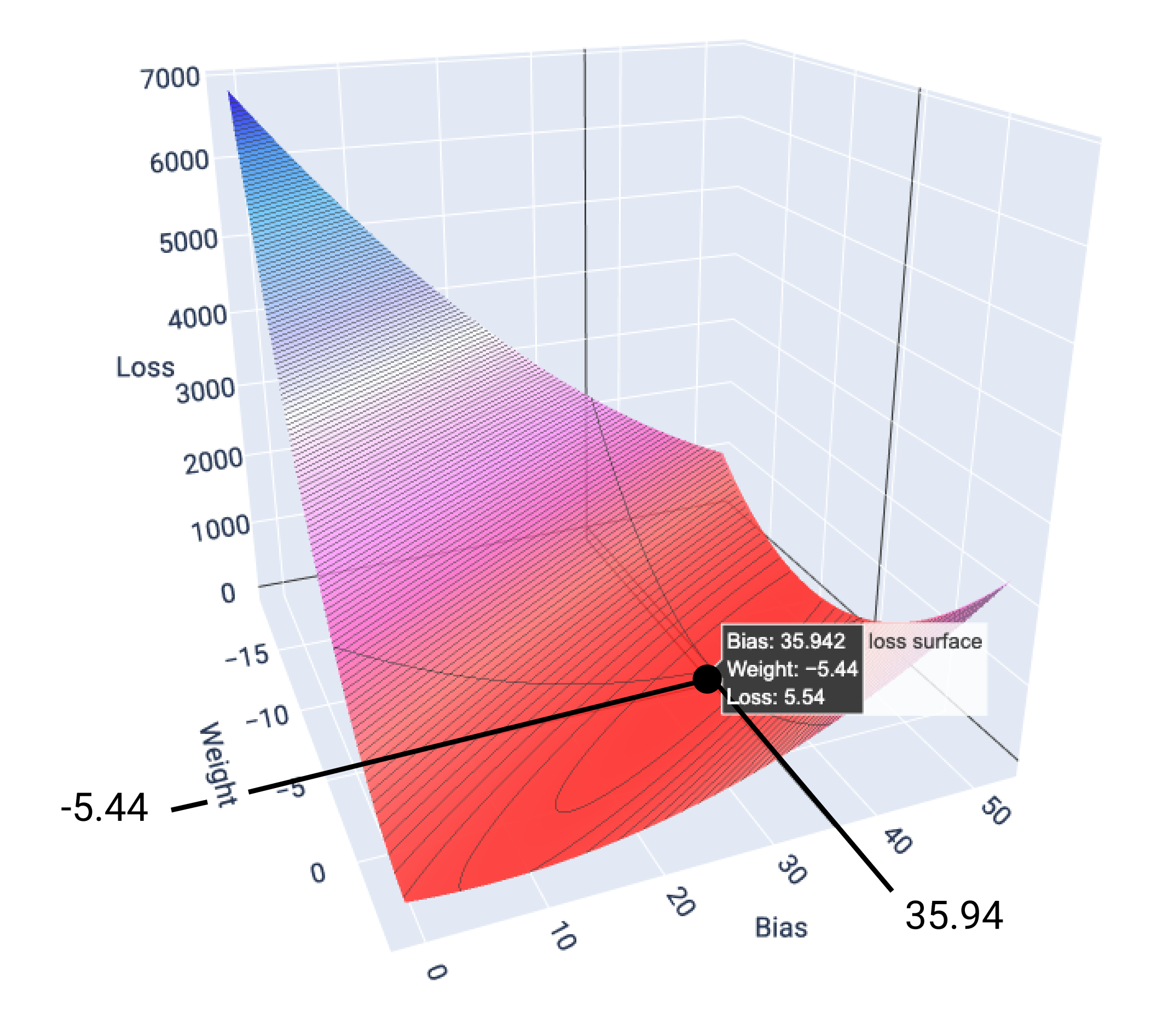
W tym przykładzie waga –5,44 i wartość progowa 35,94 dają najniższą stratę (5,54):
Rysunek 17. Powierzchnia straty pokazująca wartości wagi i odchylenia, które dają najniższą stratę.
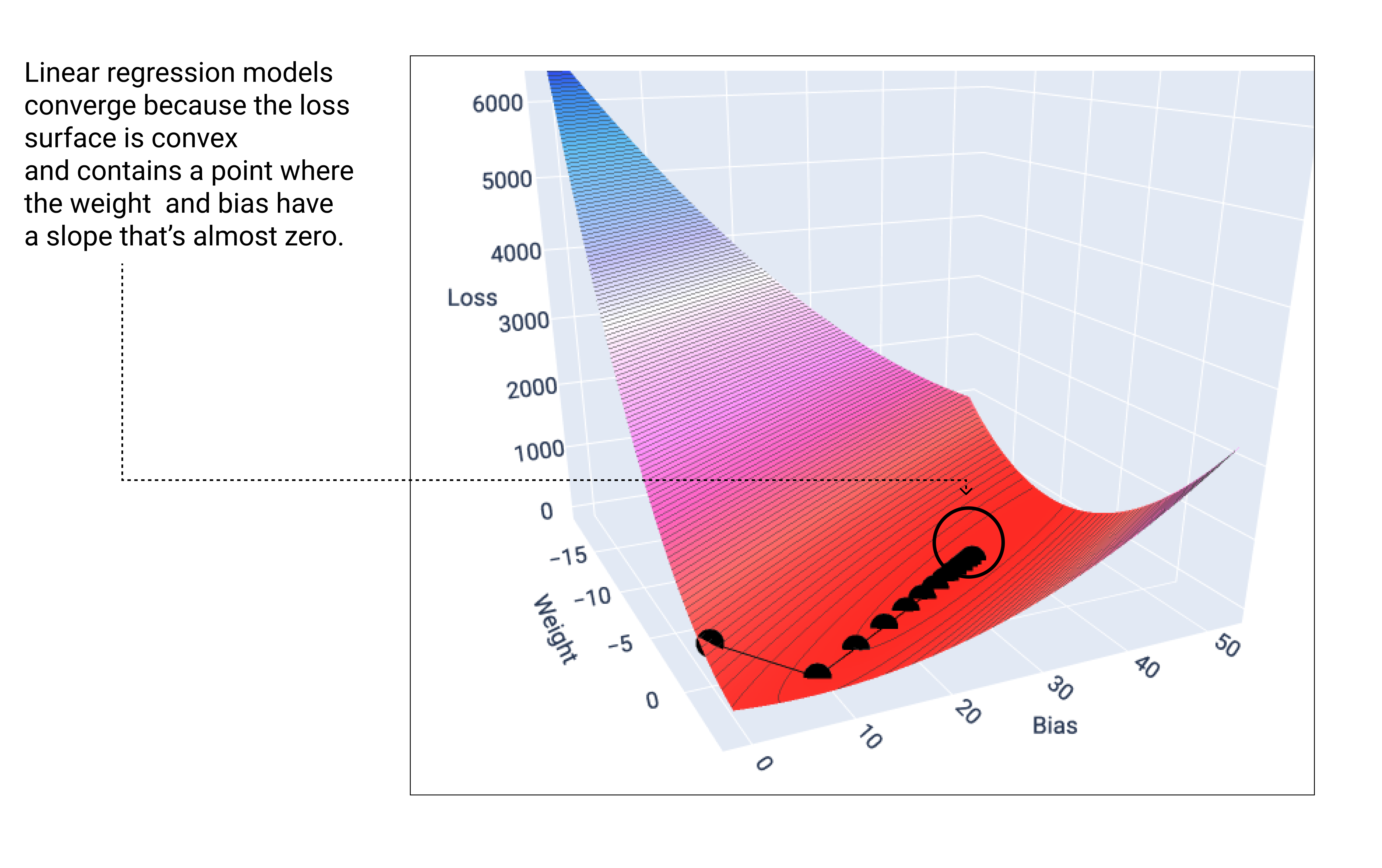
Model liniowy zbiega się, gdy znajdzie minimalną wartość funkcji straty. Gdybyśmy nanieśli na wykres wagi i punkty odchylenia podczas schodzenia gradientowego, punkty wyglądałyby jak piłka tocząca się z góry, która w końcu zatrzymuje się w miejscu, gdzie nie ma już nachylenia w dół.
Rysunek 18. Wykres funkcji straty pokazujący punkty metody gradientu prostego zatrzymujące się w najniższym punkcie wykresu.
Zwróć uwagę, że czarne punkty utraty tworzą dokładny kształt krzywej utraty: gwałtowny spadek, a potem stopniowe opadanie, aż do osiągnięcia najniższego punktu na powierzchni utraty.
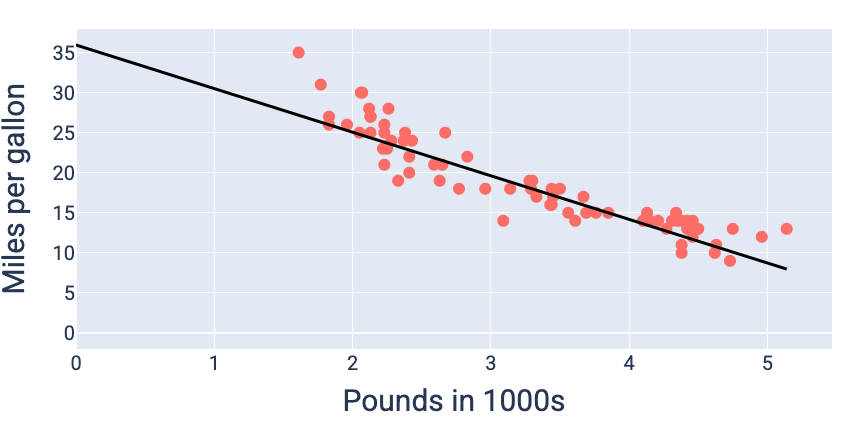
Korzystając z wartości wagi i odchylenia, które dają najmniejszą stratę – w tym przypadku wagę –5,44 i odchylenie 35,94 – możemy narysować wykres modelu, aby zobaczyć, jak dobrze pasuje on do danych:
Rysunek 19. Model przedstawiony na wykresie z użyciem wartości wag i odchyleń, które dają najniższą stratę.
To najlepszy model dla tego zbioru danych, ponieważ żadne inne wartości wag i odchyleń nie dają modelu o mniejszej utracie.
[[["Łatwo zrozumieć","easyToUnderstand","thumb-up"],["Rozwiązało to mój problem","solvedMyProblem","thumb-up"],["Inne","otherUp","thumb-up"]],[["Brak potrzebnych mi informacji","missingTheInformationINeed","thumb-down"],["Zbyt skomplikowane / zbyt wiele czynności do wykonania","tooComplicatedTooManySteps","thumb-down"],["Nieaktualne treści","outOfDate","thumb-down"],["Problem z tłumaczeniem","translationIssue","thumb-down"],["Problem z przykładami/kodem","samplesCodeIssue","thumb-down"],["Inne","otherDown","thumb-down"]],["Ostatnia aktualizacja: 2026-02-03 UTC."],[],[]]