رگرسیون خطی: نزول گرادیان
با مجموعهها، منظم بمانید
ذخیره و طبقهبندی محتوا براساس اولویتهای شما.
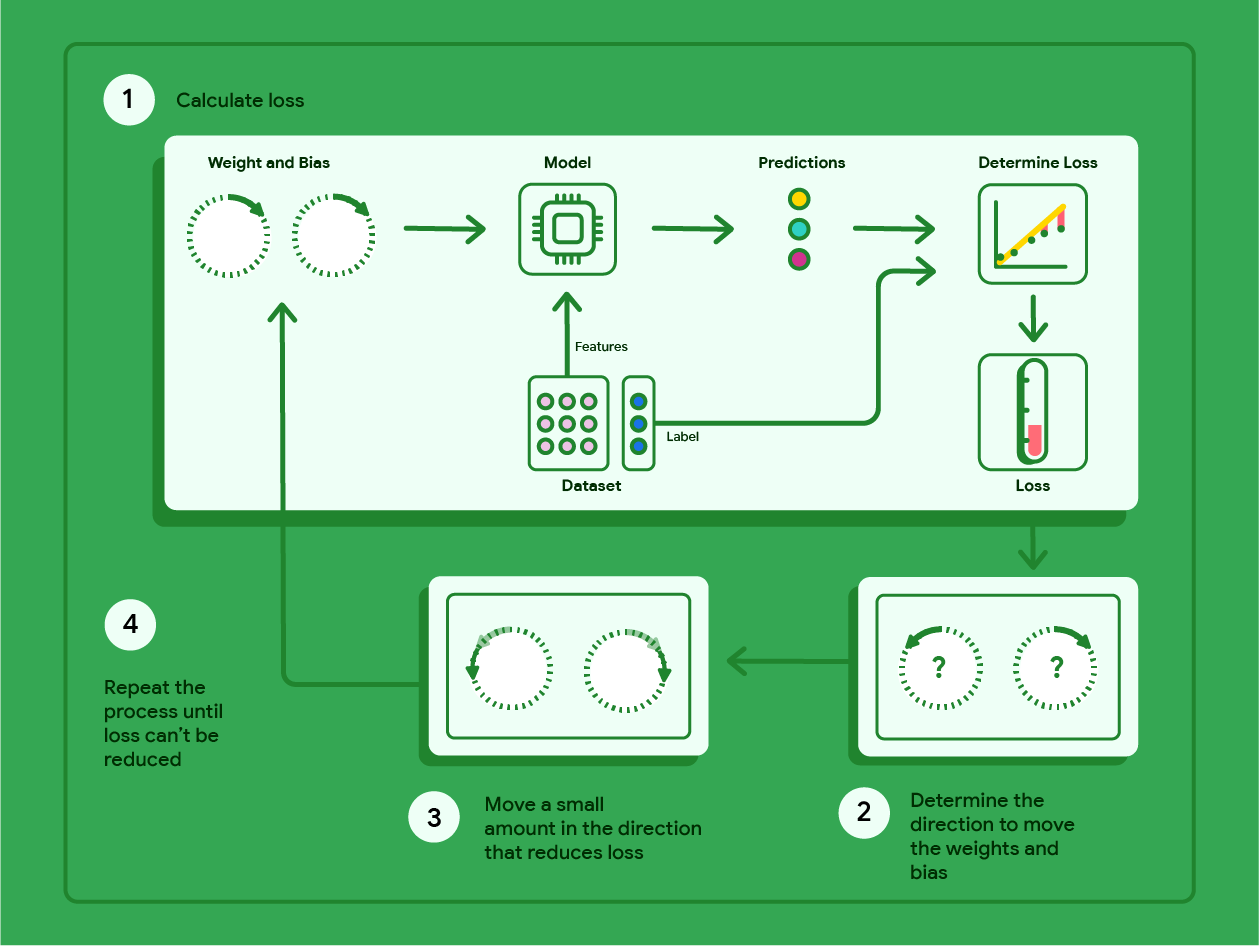
گرادیان نزولی یک تکنیک ریاضی است که به صورت تکراری وزنها و بایاسهایی را پیدا میکند که مدلی با کمترین میزان خطا تولید میکنند. گرادیان نزولی با تکرار فرآیند زیر برای تعدادی تکرار تعریف شده توسط کاربر، بهترین وزن و بایاس را پیدا میکند.
مدل آموزش را با وزنها و بایاسهای تصادفی نزدیک به صفر آغاز میکند و سپس مراحل زیر را تکرار میکند:
ضرر را با وزن و بایاس فعلی محاسبه کنید.
جهت حرکت وزنها و بایاسهایی که تلفات را کاهش میدهند، تعیین کنید.
مقادیر وزن و بایاس را به مقدار کمی در جهتی که تلفات را کاهش میدهد، جابجا کنید.
به مرحله اول برگردید و این فرآیند را تا زمانی که مدل دیگر نتواند تلفات را بیشتر کاهش دهد، تکرار کنید.
نمودار زیر مراحل تکراری که گرادیان کاهشی برای یافتن وزنها و بایاسهایی که مدلی با کمترین میزان خطا تولید میکنند، انجام میدهد را نشان میدهد.
شکل ۱۱. گرادیان نزولی یک فرآیند تکراری است که وزنها و بایاسهایی را پیدا میکند که مدلی با کمترین میزان خطا تولید میکنند.
برای کسب اطلاعات بیشتر در مورد ریاضیات مربوط به گرادیان کاهشی، روی آیکون بعلاوه کلیک کنید.
در سطح ملموس، میتوانیم با استفاده از مجموعه دادههای کوچک بهرهوری سوخت زیر با هفت مثال و میانگین مربعات خطا (MSE) به عنوان معیار تلفات، مراحل گرادیان نزولی را طی کنیم:
پوند در هزار (ویژه)
مایل بر گالن (برچسب)
۳.۵
۱۸
۳.۶۹
۱۵
۳.۴۴
۱۸
۳.۴۳
۱۶
۴.۳۴
۱۵
۴.۴۲
۱۴
۲.۳۷
۲۴
مدل با تنظیم وزن و بایاس روی صفر، آموزش را شروع میکند:
برای یادگیری نحوه محاسبه شیب، روی نماد به علاوه کلیک کنید.
برای بدست آوردن شیب خطوط مماس بر وزن و بایاس، مشتق تابع زیان را نسبت به وزن و بایاس میگیریم و سپس معادلات را حل میکنیم.
معادله پیشبینی را به صورت زیر مینویسیم: تابع f_{w,b}(x) = (w*x)+b است.
ما مقدار واقعی را به صورت زیر خواهیم نوشت: $y $.
ما MSE را با استفاده از موارد زیر محاسبه خواهیم کرد: \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $ که در آن $i$ نشان دهنده $iامین مثال آموزشی و $M$ نشان دهنده تعداد مثالها است.
مشتق وزن
مشتق تابع زیان نسبت به وزن به صورت زیر نوشته میشود: \frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
و ارزیابی میکند تا: \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2x_{(i)} $
ابتدا هر مقدار پیشبینیشده را منهای مقدار واقعی جمع میکنیم و سپس آن را در دو برابر مقدار ویژگی ضرب میکنیم. سپس حاصل جمع را بر تعداد مثالها تقسیم میکنیم. نتیجه، شیب خط مماس بر مقدار وزن است.
اگر این معادله را با وزن و بایاس برابر با صفر حل کنیم، به عدد -۱۱۹.۷ برای شیب خط میرسیم.
مشتق بایاس
مشتق تابع زیان نسبت به بایاس به صورت زیر نوشته میشود: \frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
و ارزیابی میکند تا: \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2 $
ابتدا هر مقدار پیشبینیشده را منهای مقدار واقعی جمع میکنیم و سپس آن را در دو ضرب میکنیم. سپس حاصل جمع را بر تعداد مثالها تقسیم میکنیم. نتیجه، شیب خط مماس بر مقدار بایاس است.
اگر این معادله را با وزن و بایاس برابر با صفر حل کنیم، شیب خط ۳۴.۳- میشود.
مقدار کمی را در جهت شیب منفی حرکت دهید تا وزن و بایاس بعدی را بدست آورید. فعلاً، ما به طور دلخواه "مقدار کم" را 0.01 تعریف میکنیم:
از وزن و بایاس جدید برای محاسبهی ضرر و تکرار استفاده کنید. با تکمیل این فرآیند برای شش تکرار، وزنها، بایاسها و ضررهای زیر را خواهیم داشت:
تکرار
وزن
تعصب
زیان (MSE)
۱
0
0
۳۰۳.۷۱
۲
۱.۲۰
۰.۳۴
۱۷۰.۸۴
۳
۲.۰۵
۰.۵۹
۱۰۳.۱۷
۴
۲.۶۶
۰.۷۸
۶۸.۷۰
۵
۳.۰۹
۰.۹۱
۵۱.۱۳
۶
۳.۴۰
۱.۰۱
۴۲.۱۷
میتوانید ببینید که با هر بهروزرسانی وزن و بایاس، میزان خطا کمتر میشود. در این مثال، ما پس از شش تکرار متوقف شدیم. در عمل، یک مدل تا زمانی که همگرا شود، آموزش میبیند. وقتی یک مدل همگرا میشود، تکرارهای اضافی، خطای بیشتری را کاهش نمیدهند، زیرا روش گرادیان کاهشی، وزنها و بایاسی را پیدا کرده است که تقریباً خطای خطا را به حداقل میرسانند.
اگر مدل به آموزش پس از همگرایی ادامه دهد، زیان شروع به نوسان در مقادیر کم میکند، زیرا مدل به طور مداوم پارامترها را حول کمترین مقادیرشان بهروزرسانی میکند. این امر میتواند تأیید همگرایی واقعی مدل را دشوار کند. برای تأیید همگرایی مدل، باید آموزش را تا زمانی که زیان تثبیت شود، ادامه دهید.
منحنیهای همگرایی و تلفات مدل
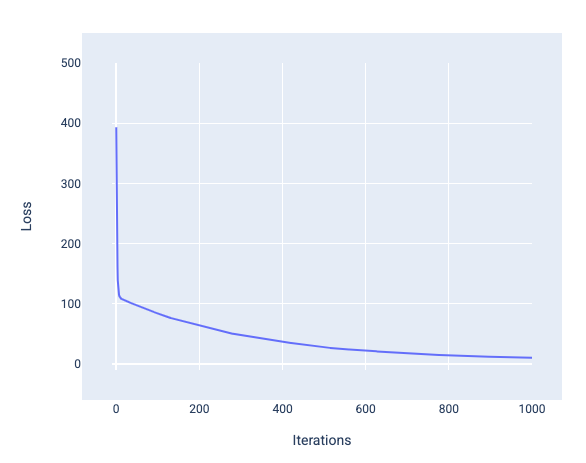
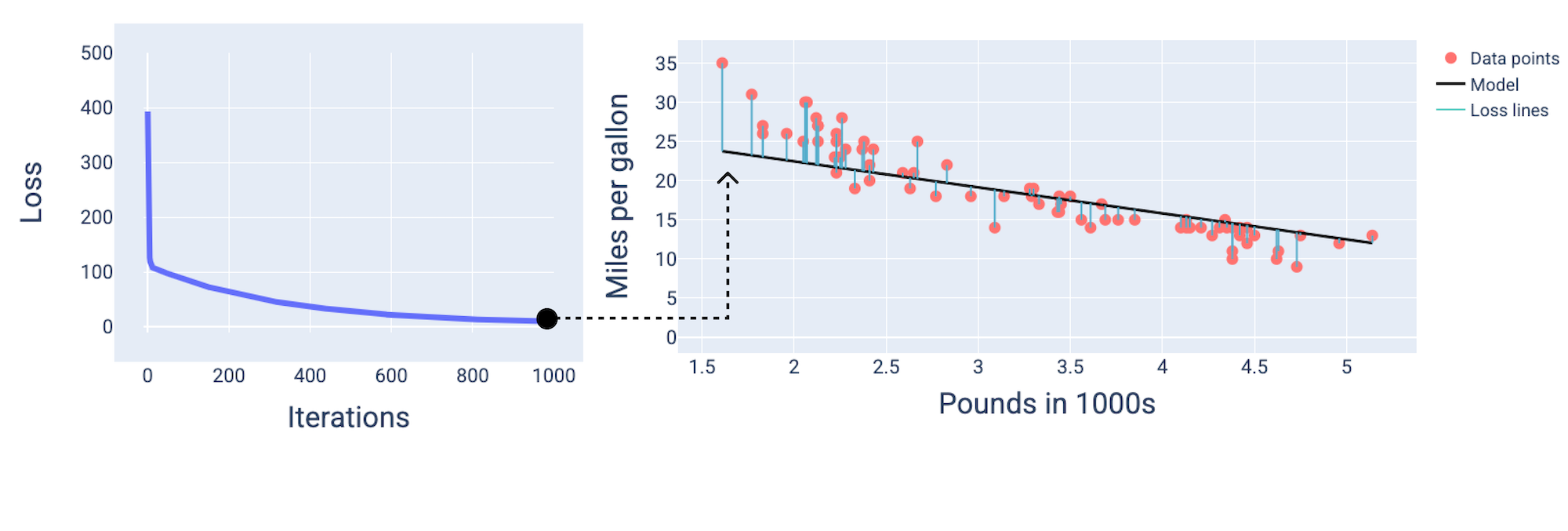
هنگام آموزش یک مدل، اغلب به منحنی تلفات نگاه میکنید تا مشخص شود که آیا مدل همگرا شده است یا خیر. منحنی تلفات نشان میدهد که چگونه تلفات با آموزش مدل تغییر میکند. شکل یک منحنی تلفات معمولی به صورت زیر است. تلفات روی محور y و تکرارها روی محور x هستند:
شکل ۱۲. منحنی تلفات که همگرایی مدل را در حدود ۱۰۰۰مین تکرار نشان میدهد.
میتوانید ببینید که تلفات در طول چند تکرار اول به طور چشمگیری کاهش مییابد، سپس به تدریج کاهش مییابد و در حدود هزارمین تکرار به حالت ثابت میرسد. پس از ۱۰۰۰ تکرار، میتوانیم تقریباً مطمئن باشیم که مدل همگرا شده است.
در شکلهای زیر، مدل را در سه نقطه در طول فرآیند آموزش رسم میکنیم: ابتدا، میانه و انتها. تجسم وضعیت مدل در تصاویر لحظهای در طول فرآیند آموزش، ارتباط بین بهروزرسانی وزنها و بایاس، کاهش تلفات و همگرایی مدل را محکمتر میکند.
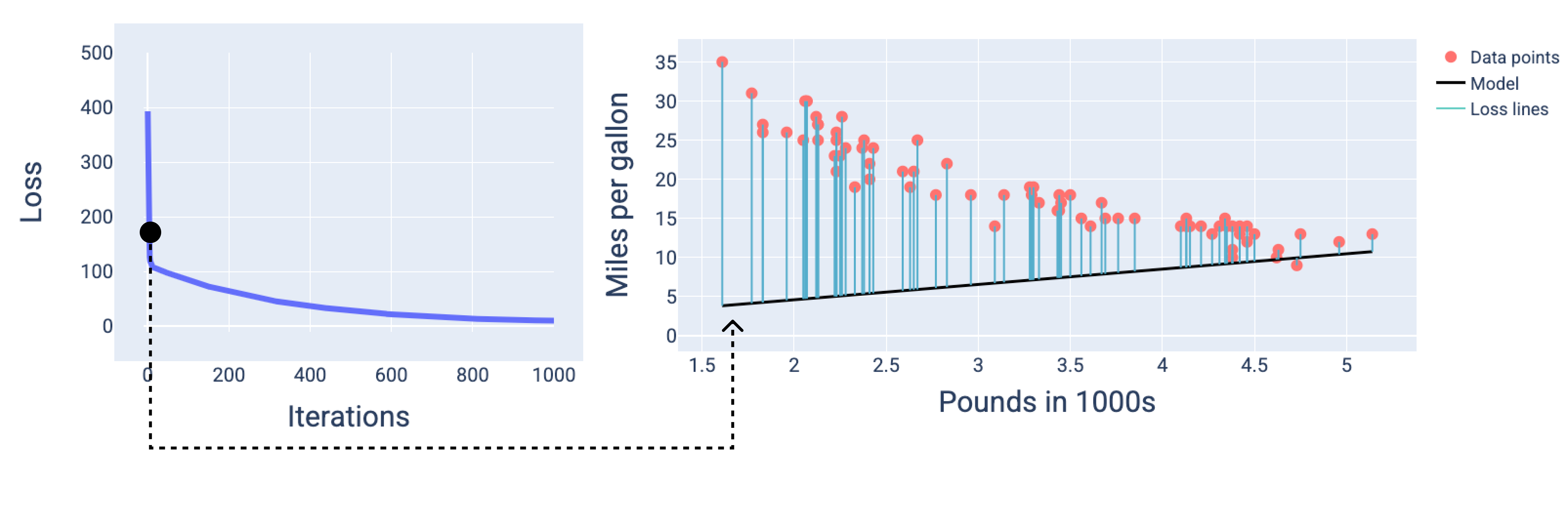
در شکلها، ما از وزنها و بایاس مشتقشده در یک تکرار خاص برای نمایش مدل استفاده میکنیم. در نموداری که شامل نقاط داده و تصویر لحظهای مدل است، خطوط آبی اتلاف از مدل تا نقاط داده، میزان اتلاف را نشان میدهند. هرچه خطوط بلندتر باشند، اتلاف بیشتری وجود دارد.
در شکل زیر، میتوانیم ببینیم که در حدود تکرار دوم، مدل به دلیل میزان بالای تلفات، در پیشبینی خوب عمل نمیکند.
شکل ۱۳. منحنی تلفات و تصویر لحظهای از مدل در ابتدای فرآیند آموزش.
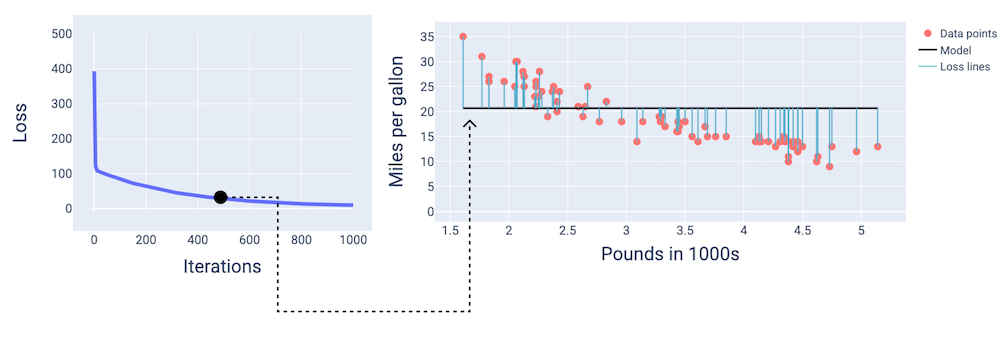
در حدود تکرار ۴۰۰ام، میتوانیم ببینیم که روش گرادیان کاهشی، وزن و بایاس لازم برای تولید مدل بهتر را پیدا کرده است.
شکل ۱۴. منحنی تلفات و تصویر لحظهای مدل در اواسط آموزش.
و در حدود هزارمین تکرار، میتوانیم ببینیم که مدل همگرا شده و مدلی با کمترین تلفات ممکن تولید میکند.
شکل ۱۵. منحنی تلفات و تصویر لحظهای از مدل در نزدیکی پایان فرآیند آموزش.
تمرین: درک خود را بسنجید
نقش گرادیان نزولی در رگرسیون خطی چیست؟
گرادیان نزولی یک فرآیند تکراری است که بهترین وزنها و بایاسها را پیدا میکند که تلفات را به حداقل میرساند.
گرادیان نزولی به تعیین نوع تلفات مورد استفاده هنگام آموزش یک مدل، مثلاً L1 یا L2 ، کمک میکند.
روش گرادیان نزولی در انتخاب تابع زیان برای آموزش مدل دخیل نیست.
روش گرادیان کاهشی، دادههای پرت را از مجموعه دادهها حذف میکند تا به مدل کمک کند پیشبینیهای بهتری انجام دهد.
روش گرادیان کاهشی مجموعه دادهها را تغییر نمیدهد.
توابع همگرایی و محدب
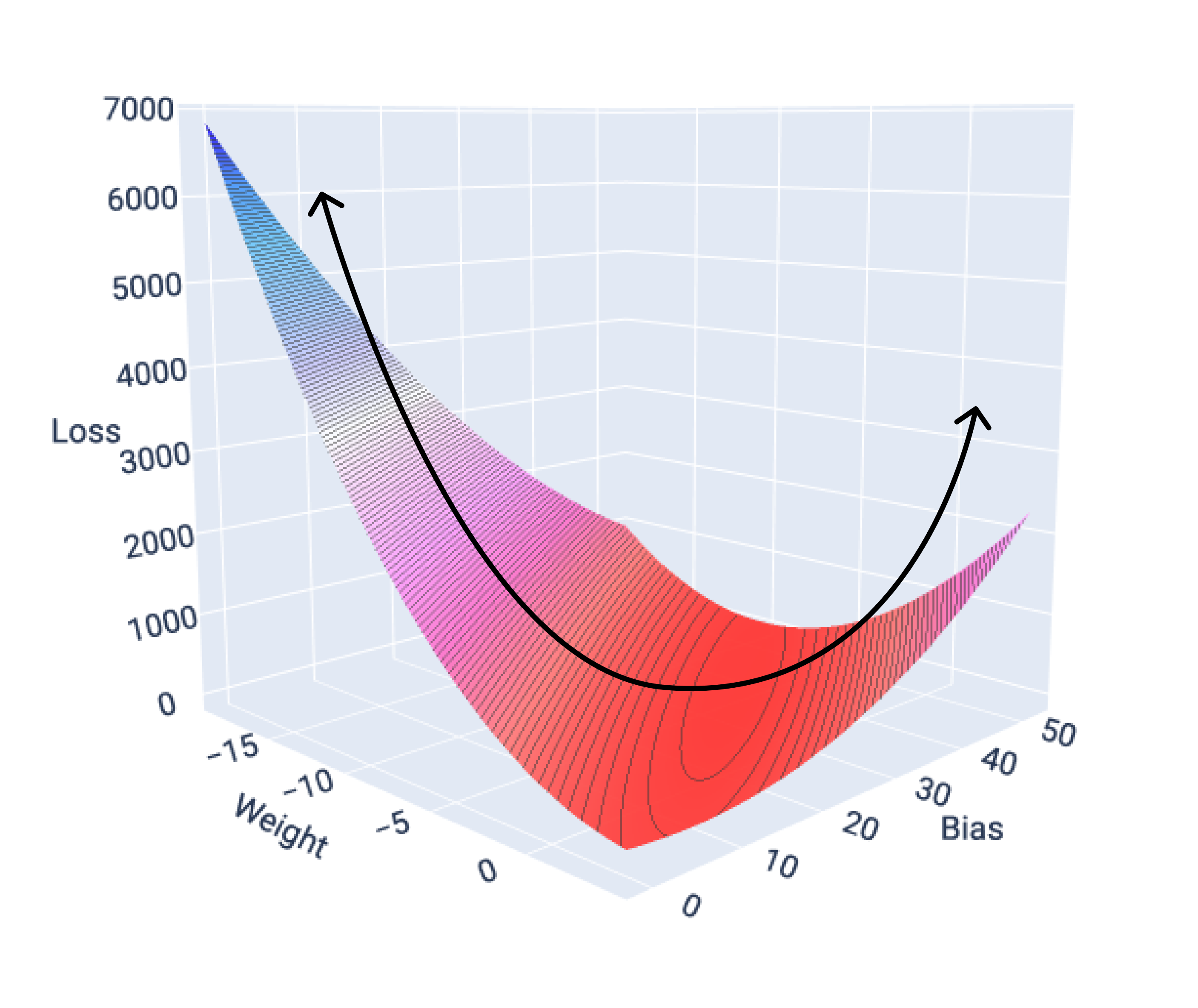
توابع زیان برای مدلهای خطی همیشه یک سطح محدب تولید میکنند. در نتیجه این ویژگی، وقتی یک مدل رگرسیون خطی همگرا میشود، میدانیم که مدل وزنها و بایاسهایی را پیدا کرده است که کمترین زیان را ایجاد میکنند.
اگر نمودار سطح اتلاف را برای مدلی با یک ویژگی رسم کنیم، میتوانیم شکل محدب آن را ببینیم. شکل زیر سطح اتلاف برای یک مجموعه داده فرضی مایل بر گالن را نشان میدهد. وزن روی محور x، بایاس روی محور y و اتلاف روی محور z است:
شکل ۱۶. سطح تلفات که شکل محدب آن را نشان میدهد.
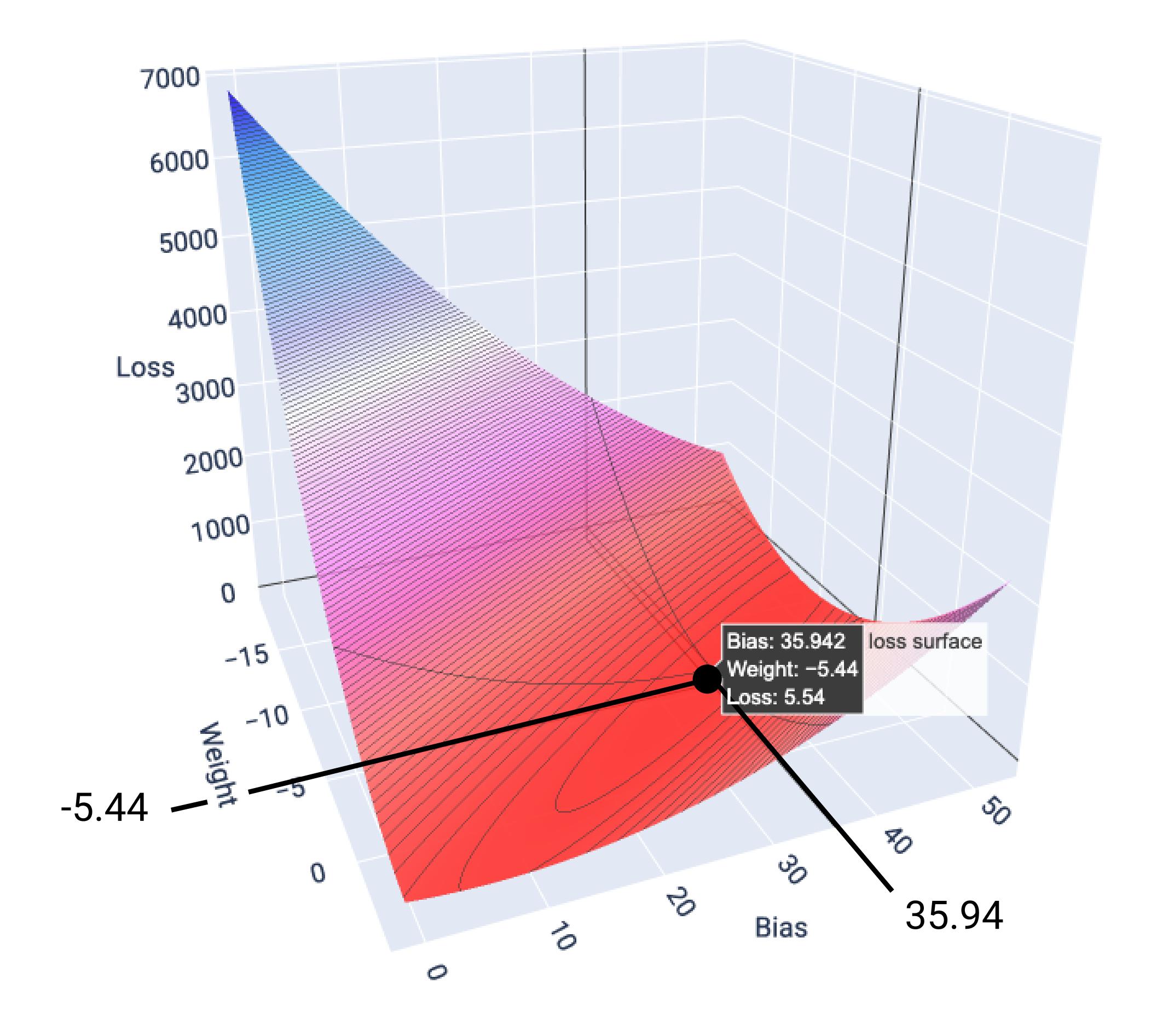
در این مثال، وزن -5.44 و بایاس 35.94 کمترین میزان ضرر را در 5.54 ایجاد میکند:
شکل ۱۷. سطح تلفات که مقادیر وزن و بایاس را نشان میدهد که کمترین تلفات را ایجاد میکنند.
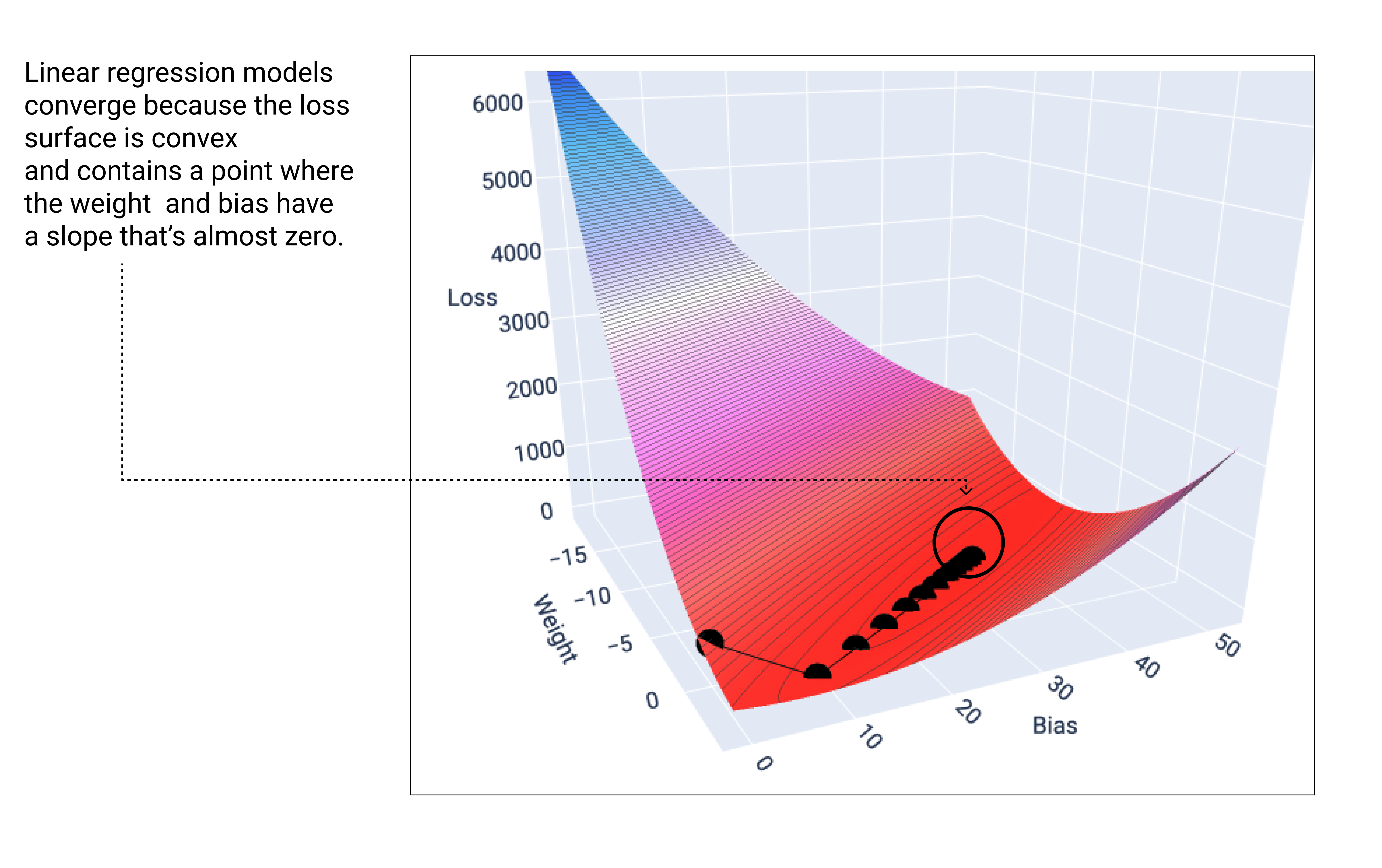
یک مدل خطی زمانی همگرا میشود که حداقل ضرر را پیدا کند. اگر وزنها و نقاط بایاس را در طول گرادیان نزولی رسم کنیم، نقاط مانند توپی به نظر میرسند که از تپهای به پایین میغلتد و در نهایت در نقطهای که دیگر شیب رو به پایین وجود ندارد، متوقف میشود.
شکل ۱۸. نمودار تلفات که نقاط گرادیان نزولی را نشان میدهد که در پایینترین نقطه نمودار متوقف میشوند.
توجه داشته باشید که نقاط ضرر سیاه دقیقاً شکل منحنی ضرر را ایجاد میکنند: یک کاهش شدید قبل از اینکه به تدریج کاهش یابد تا زمانی که به پایینترین نقطه روی سطح ضرر برسند.
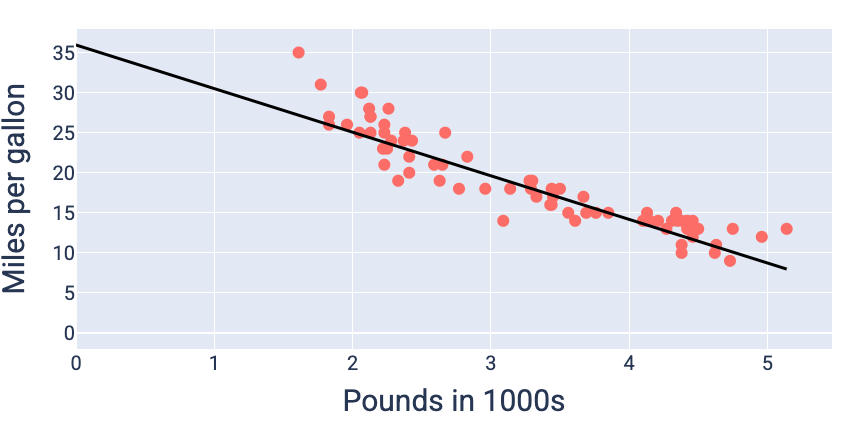
با استفاده از مقادیر وزن و بایاس که کمترین میزان ضرر را ایجاد میکنند - در این مورد وزن -5.44 و بایاس 35.94 - میتوانیم نمودار مدل را رسم کنیم تا ببینیم چقدر با دادهها برازش دارد:
شکل ۱۹. مدل با استفاده از مقادیر وزن و بایاس که کمترین تلفات را ایجاد میکنند، رسم شده است.
این بهترین مدل برای این مجموعه داده خواهد بود، زیرا هیچ مقدار وزن و بایاس دیگری مدلی با تلفات کمتر تولید نمیکند.
تاریخ آخرین بهروزرسانی 2026-02-03 بهوقت ساعت هماهنگ جهانی.
[[["درک آسان","easyToUnderstand","thumb-up"],["مشکلم را برطرف کرد","solvedMyProblem","thumb-up"],["غیره","otherUp","thumb-up"]],[["اطلاعاتی که نیاز دارم وجود ندارد","missingTheInformationINeed","thumb-down"],["بیشازحد پیچیده/ مراحل بسیار زیاد","tooComplicatedTooManySteps","thumb-down"],["قدیمی","outOfDate","thumb-down"],["مشکل ترجمه","translationIssue","thumb-down"],["مشکل کد / نمونهها","samplesCodeIssue","thumb-down"],["غیره","otherDown","thumb-down"]],["تاریخ آخرین بهروزرسانی 2026-02-03 بهوقت ساعت هماهنگ جهانی."],[],[]]