Bei der Bewertung eines Modells werden Messwerte für den gesamten Test oder die gesamte Validierung berechnet. geben nicht immer ein genaues Bild davon, wie fair das Modell ist. Die meisten Beispiele weisen eine gute Modellleistung auf. nur bei einer geringen Anzahl von Beispielen, was zu verzerrten Ergebnissen führen kann. Modellvorhersagen. Mit zusammengefassten Leistungsmesswerten wie präzision, Recall, und Genauigkeit um diese Probleme aufzudecken.
Wir können unser Zulassungsmodell noch einmal durchgehen und einige neue Techniken kennenlernen. wie man seine Vorhersagen auf Verzerrungen und Fairness bewerten kann.
Angenommen, das Klassifizierungsmodell für die Zulassung wählt 20 Schüler aus, die zur Teilnahme Universität aus einem Pool von 100 Bewerbern aus, die zwei demografischen Gruppen angehören: die Mehrheitsgruppe (blaue, 80 Schüler/Studenten) und die Minderheitsgruppe (Orange, 20 Schüler/Studenten).
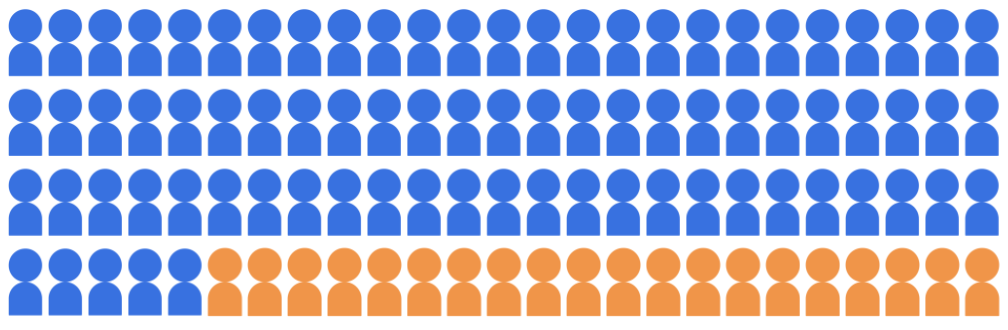
Bei dem Modell müssen qualifizierte Studenten auf eine Weise zugelassen werden, die den für beide demografischen Gruppen geeignet ist.
Wie sollten wir die Vorhersagen des Modells auf Fairness bewerten? Es gibt eine Vielzahl von von Metriken, die wir berücksichtigen können, die alle einen anderen mathematischen der Definition von Fairness. In den folgenden Abschnitten werden drei der diese Fairness-Messwerte genauer ansehen: demografische Gleichheit, Chancengleichheit, und kontrafaktische Fairness.