前のセクションでは、1 つの分類しきい値で計算された一連のモデル指標について説明しました。ただし、考えられるすべてのしきい値でモデルの品質を評価するには、別のツールが必要です。
受信者操作特性曲線(ROC)
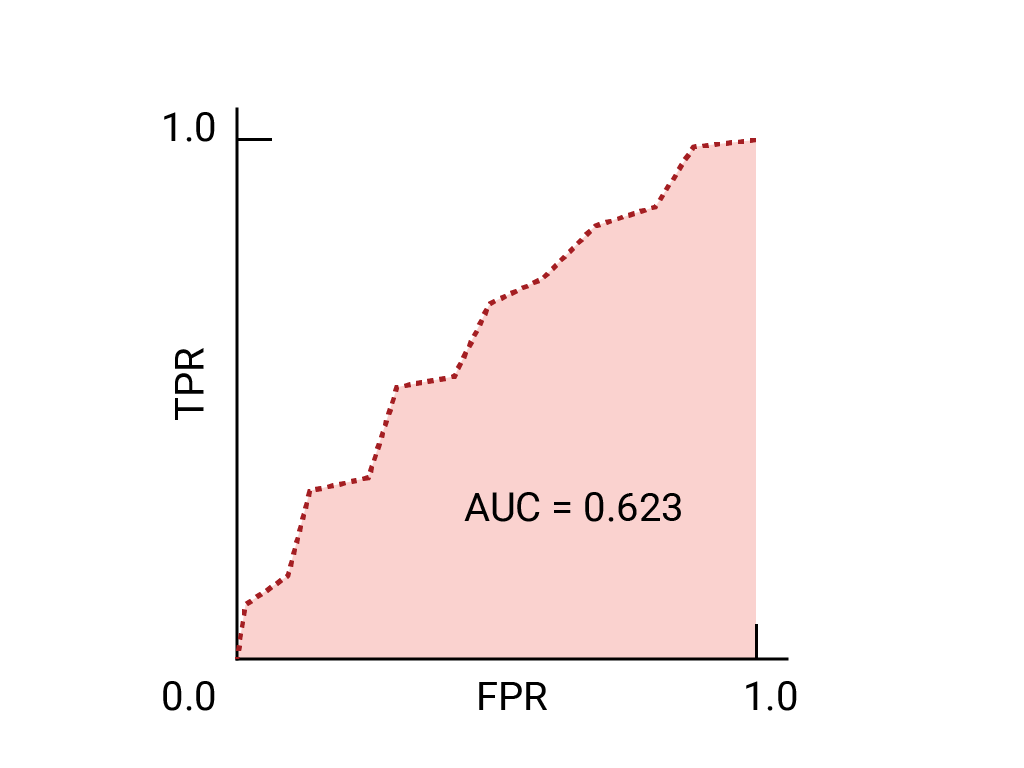
ROC 曲線は、すべてのしきい値におけるモデルのパフォーマンスを視覚的に表したものです。長い名前の「レシーバー動作特性」は、第二次世界大戦のレーダー検出から引き継がれています。
ROC 曲線は、考えられるすべてのしきい値(実際には選択した間隔)で真陽性率(TPR)と偽陽性率(FPR)を計算し、TPR を FPR に対してグラフにプロットすることで描画されます。あるしきい値で TPR が 1.0 で FPR が 0.0 である完全なモデルは、他のすべてのしきい値が無視される場合は(0, 1)の点として表されます。または、次のように表されます。

曲線下面積(AUC)
ROC 曲線の下の面積(AUC)は、ランダムに選択された正例と負例が与えられた場合に、モデルが正例を負例よりも高いランクに付ける確率を表します。
上記の完全なモデル(辺の長さが 1 の正方形を含む)の曲線の下積み(AUC)は 1.0 です。つまり、ランダムに選択された正例が、ランダムに選択された負例よりも高い確率で正しくランク付けされるということです。つまり、下のグラフのデータポイントの分布を見ると、AUC は、しきい値がどこに設定されているかに関係なく、モデルがランダムに選択された正方形をランダムに選択された円の右側に配置する確率を示します。

より具体的には、AUC が 1.0 の迷惑メール分類システムでは、ランダムに選択された迷惑メールには、ランダムに選択された正当なメールよりも迷惑メールである可能性が高い値が常に割り当てられます。各メールの実際の分類は、選択したしきい値によって異なります。
バイナリ分類の場合、ランダムな推測やコイントスと同じくらい優れたモデルの ROC は、(0,0)から(1,1)までの対角線になります。AUC は 0.5 で、ランダムに選択された正例と負例を正しくランク付けする確率が 50% であることを表します。
スパム分類システムの例では、AUC が 0.5 のスパム分類システムは、ランダムに選択されたスパムメールがランダムに選択された正当なメールよりもスパムである可能性が高いと判断する確率が半分だけ高くなります。

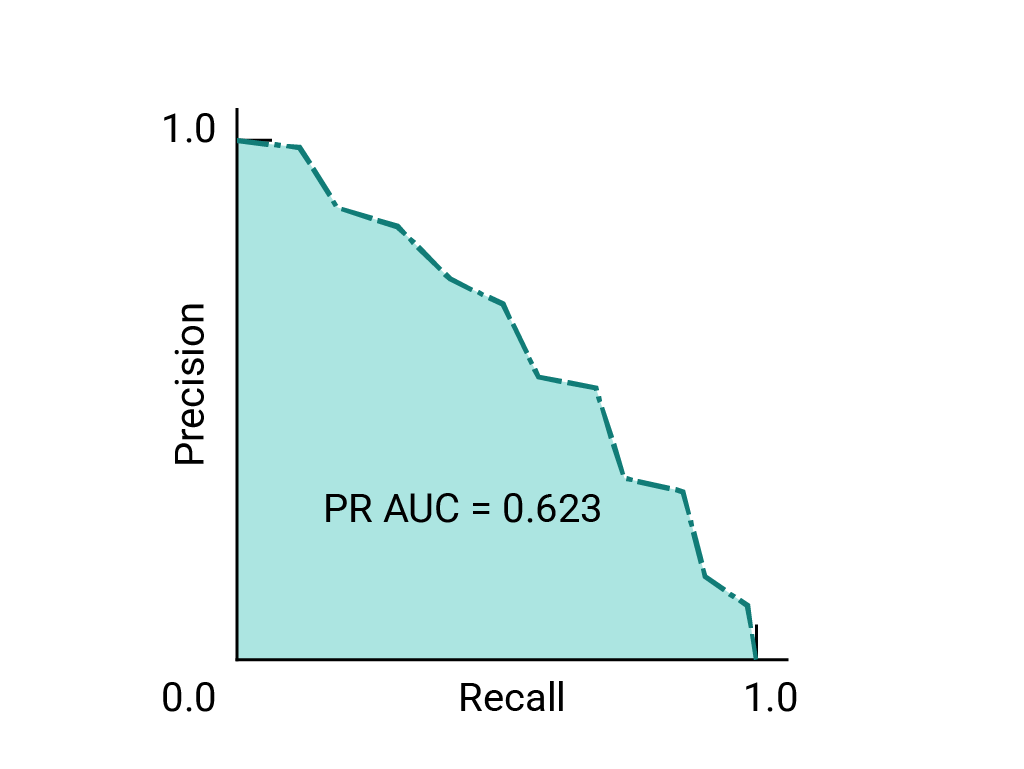
(省略可、上級)適合率と再現率の曲線
AUC と ROC は、データセットのクラス間でバランスが取れている場合にモデルを比較するのに適しています。データセットが不均衡な場合、精度と再現率の曲線(PRC)とその曲線の下の面積は、モデルのパフォーマンスを比較する際に優れた可視化を提供できます。適合率 / 再現率曲線は、すべてのしきい値で適合率を Y 軸に、再現率を X 軸にプロットすることで作成されます。
モデルとしきい値の選択のための AUC と ROC
AUC は、データセットがほぼバランスが取れている限り、2 つの異なるモデルのパフォーマンスを比較するのに役立つ指標です。一般に、曲線の下の面積が大きいモデルが優れたモデルです。


ROC 曲線上で(0,1)に最も近い点は、特定のモデルでパフォーマンスが最も高いしきい値の範囲を表します。しきい値、混同行列、指標の選択とトレードオフのセクションで説明したように、選択するしきい値は、特定のユースケースで最も重要な指標によって異なります。次の図の A、B、C の各ポイントは、しきい値を表しています。

偽陽性(誤検出)のコストが非常に高い場合は、TPR が低下しても、ポイント A のような FPR が低いしきい値を選択することをおすすめします。逆に、偽陽性が低コストで、偽陰性(真陽性を検出できなかった)が非常にコストが高い場合は、TPR を最大化するポイント C のしきい値が適している可能性があります。費用がほぼ同等の場合、点 B は TPR と FPR のバランスが最も良い可能性があります。
前回見たデータの ROC 曲線は次のとおりです。
演習: 理解度を確認する




(省略可、上級者向け)ボーナス質問
ビジネスに不可欠なメールを迷惑メールフォルダに送信するよりも、一部の迷惑メールを受信トレイに届くようにしたほうがよい状況を想像してみてください。ポジティブ クラスがスパム、ネガティブ クラスがスパム以外のこの状況に対して、スパム分類子をトレーニングしました。分類システムの ROC 曲線上で、次のうちどの点が望ましいですか。