W poprzedniej sekcji przedstawiono zestaw danych modelu, które zostały obliczone przy użyciu jednej wartości progowej klasyfikacji. Jeśli jednak chcesz ocenić jakość modelu we wszystkich możliwych progach, musisz użyć innych narzędzi.
Krzywa charakterystyki operacyjnej odbiornika (ROC)
Krzywa ROC to wizualizacja skuteczności modelu w przypadku wszystkich progów. Długa wersja nazwy, charakterystyka operacyjna odbiornika, to pozostałość po wykrywaniu radarowym z czasów II wojny światowej.
Krzywa ROC jest rysowana przez obliczenie współczynnika wyników prawdziwie pozytywnych (TPR) i współczynnika wyników fałszywie pozytywnych (FPR) przy każdym możliwym progu (w praktyce przy wybranych odstępach), a następnie naniesienie TPR na wykresie w powiązaniu z FPR. Idealny model, który przy danej wartości progowej ma TPR 1,0 i FPR 0,0, może być reprezentowany przez punkt w punkcie (0, 1), jeśli wszystkie inne wartości progowe są ignorowane, lub przez:

Obszar pod krzywą (AUC)
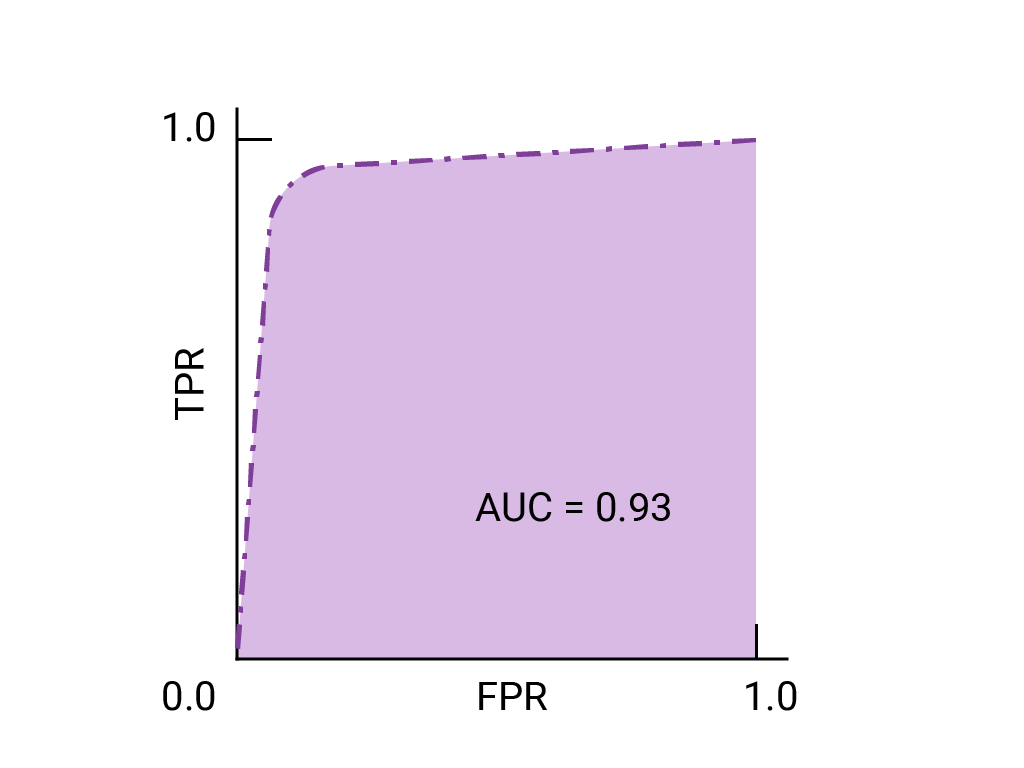
Obszar pod krzywą ROC (AUC) reprezentuje prawdopodobieństwo, że model, jeśli otrzyma losowo wybrany przykład pozytywny i negatywny, sklasyfikuje przykład pozytywny wyżej niż negatywny.
Powyższy idealny model zawierający kwadrat o bokach o długości 1 ma obszar pod krzywą (AUC) równy 1,0. Oznacza to, że z 100% pewnością model prawidłowo oceni losowo wybrany przykład pozytywny wyżej niż losowo wybrany przykład negatywny. Innymi słowy, patrząc na rozproszenie punktów danych poniżej, AUC podaje prawdopodobieństwo, że model umieści losowo wybrany kwadrat po prawej stronie losowo wybranego okręgu, niezależnie od tego, gdzie ustawiono próg.

Konkretniej mówiąc, klasyfikator spamu o AUC równym 1,0 zawsze przypisuje losowemu spamowemu e-mailowi wyższe prawdopodobieństwo bycia spamem niż losowemu wiarygodnemu e-mailowi. Rzeczywista klasyfikacja każdego e-maila zależy od wybranego przez Ciebie progu.
W przypadku klasyfikatora binarnego model, który działa dokładnie tak samo jak przypadkowe zgadywanie lub rzut monetą, ma ROC w postaci linii od punktu (0,0) do (1,1). AUC wynosi 0,5, co oznacza, że prawdopodobieństwo prawidłowego uporządkowania losowego przykładu pozytywnego i negatywnego wynosi 50%.
W przykładzie z klasyfikatorem spamu klasyfikator spamu o AUC 0, 5 przypisuje losowemu spamowemu e-mailowi wyższe prawdopodobieństwo bycia spamem niż losowemu wiarygodnemu e-mailowi tylko w połowie przypadków.

(Opcjonalnie, zaawansowane) Krzywa precyzji i czułości
AUC i ROC dobrze sprawdzają się w przypadku porównywania modeli, gdy zbiór danych jest w przybliżeniu zrównoważony pod względem klas. Jeśli zbiór danych jest niezrównoważony, krzywe czułości i trafności (PRC) oraz obszar pod tymi krzyżami mogą lepiej wizualizować skuteczność modelu w porównaniu z innymi. Krzywe precyzji i czułości są tworzone przez nanoszenie precyzji na osi y, a czułości na osi x dla wszystkich wartości progowych.

AUC i ROC do wyboru modelu i progu
AUC to przydatny wskaźnik do porównywania skuteczności 2 różnych modeli, o ile tylko zbiór danych jest w przybliżeniu zrównoważony. Model z większym obszarem pod krzywą jest zwykle lepszy.

Punkty na krzywej ROC najbliższe wartości (0,1) odpowiadają zakresowi progów o najlepszej skuteczności w danym modelu. Jak już wspomnieliśmy w sekcjach Próg, Macierz błędów i Wybór rodzaju danych i ustępstwa, wybrany próg zależy od tego, które dane są najważniejsze w danym przypadku użycia. Na poniższym diagramie punkty A, B i C odpowiadają progom:

Jeśli wyniki fałszywie dodatnie (fałszywe alarmy) są bardzo kosztowne, warto wybrać próg, który daje niższy FPR, np. w miejscu A, nawet jeśli TPR jest mniejszy. Jeśli natomiast fałszywie pozytywne są tanie, a fałszywie negatywne (niewykryte prawdziwie pozytywne) bardzo kosztowne, preferowany może być próg dla punktu C, który maksymalizuje TPR. Jeśli koszty są mniej więcej takie same, punkt B może zapewnić najlepszy kompromis między TPR a FPR.
Oto krzywa ROC dla danych, które już znamy:
Ćwiczenie: sprawdź swoją wiedzę




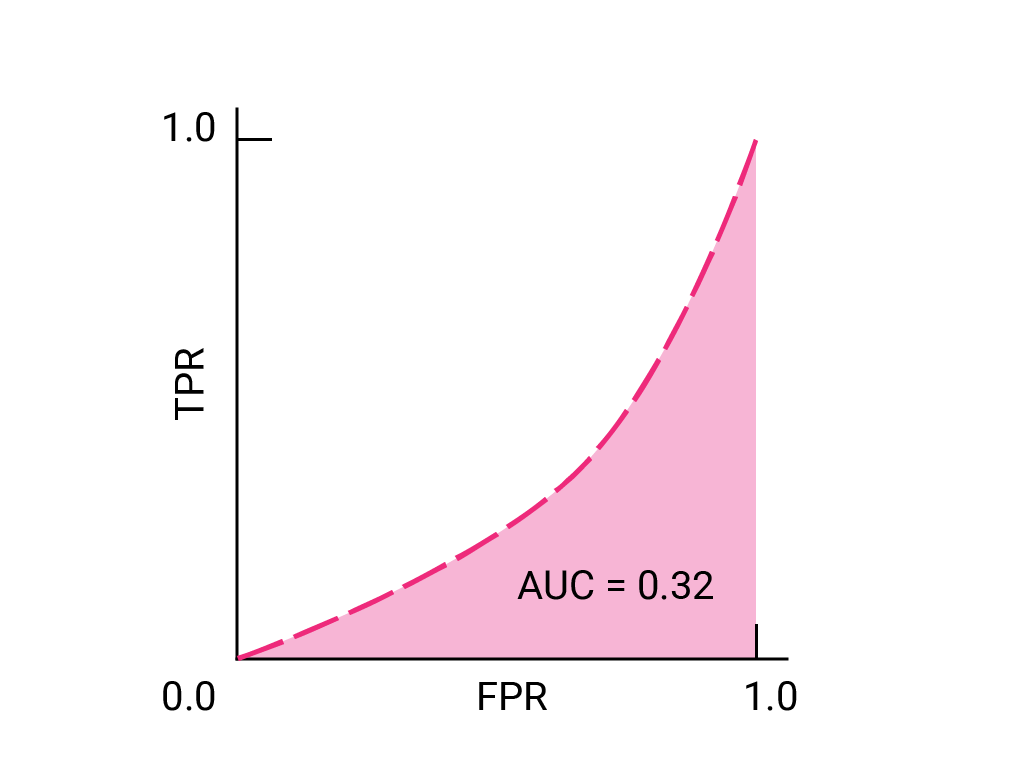
(Opcjonalnie, zaawansowane) Pytanie dodatkowe
Wyobraź sobie sytuację, w której lepiej jest zezwolić na to, aby niektóre spamy trafiały do skrzynki odbiorczej, niż wysyłać ważne e-maile do folderu ze spamem. W tym przypadku masz już przeszkolony klasyfikator spamu, w którym klasa pozytywna to spam, a klasa negatywna to nie-spam. Który z tych punktów na krzywej ROC jest preferowany w przypadku Twojego klasyfikatora?